1 基础
1.1 [1]定义
01.定义
Redis,全称 Remote Dictionary Server,是一个基于内存的高性能 Key-Value 数据库
它以其卓越的性能和丰富的功能,成为了互联网公司在缓存组件选择中的首选
02.特点
高性能:由于 Redis 是基于内存的数据库,读写速度极快,能够处理每秒数百万次的请求
丰富的数据结构:除了基本的字符串类型,Redis 还支持列表、集合、有序集合、哈希和位图等多种数据结构,满足不同场景的需求
持久化:虽然 Redis 是内存数据库,但它提供了多种持久化机制(如 RDB 快照和 AOF 日志),确保数据的持久性和可靠性
高可用和分布式:Redis 支持主从复制、哨兵模式和集群模式,能够实现高可用和分布式部署,保证系统的稳定性和扩展性
丰富的功能:Redis 提供了事务、Lua 脚本、发布/订阅、键过期等多种高级功能,极大地增强了其应用场景
1.2 [1]优缺点
01.优点
a.读写性能优异
Redis 的读写性能非常出色,读的速度可以达到 110,000 次/秒,写的速度可以达到 81,000 次/秒
这使得 Redis 在高并发场景下表现非常优异
b.支持数据持久化
Redis 支持两种持久化方式:AOF(Append-Only File)和 RDB(Redis Database Backup)
AOF 记录每次写操作,RDB 则是定期对数据进行快照保存,确保数据的持久性
c.支持事务
Redis 的所有操作都是原子性的,同时还支持对多个操作进行合并后的原子性执行
通过 MULTI、EXEC、DISCARD 和 WATCH 命令,可以实现事务操作
d.数据结构丰富
Redis 支持多种数据结构,除了基本的字符串(String)类型外
还支持哈希(Hash)、集合(Set)、有序集合(Sorted Set)和列表(List)等
这些数据结构经过高度优化,能够满足不同场景的需求
e.支持主从复制
Redis 支持主从复制,主机会自动将数据同步到从机,实现数据的冗余备份
通过主从复制,可以实现读写分离,提高系统的读写性能和可用性
02.缺点
a.数据库容量受物理内存限制
Redis 是基于内存的数据库,数据存储在内存中,因此数据库容量受到物理内存的限制
对于海量数据的高性能读写,Redis 并不适用。Redis 适合的场景主要局限在较小数据量的高性能操作和运算上
b.不具备自动容错和恢复功能
Redis 不具备自动容错和恢复功能,主机或从机宕机都会导致前端部分读写请求失败
需要等待机器重启或者手动切换前端的 IP 才能恢复服务
c.数据不一致问题
如果主机宕机,宕机前有部分数据未能及时同步到从机,切换 IP 后可能会引入数据不一致的问题,降低系统的可用性
d.在线扩容较难
Redis 较难支持在线扩容,当集群容量达到上限时,在线扩容会变得非常复杂
为了避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费
1.3 [1]为啥快:4个
01.单线程:所有命令执行都是在一个线程中进行的
零锁竞争:无需处理多线程环境下的锁机制(如synchronized/ReentrantLock)
无上下文切换:避免线程切换带来的CPU缓存失效(L1/L2 Cache Miss)
操作原子性:天然支持原子操作,无需额外并发控制
02.内存操作
数据的读写操作避开了磁盘I/O,内存的访问速度远超硬盘
03.I/O多路复用
Redis 单个线程处理多个 IO 读写的请求
04.高效数据结构
数据类型 底层结构 时间复杂度 典型场景
String SDS o(1) 计数器、缓存
Hash ziplist/hashtable o(1) 对象存储
List quicklist o(N)头尾操作O(1) 消息队列
Set intset/hashtable o(1) 标签系统
ZSet skiplist+hashtable o(logN) 排行榜
1.4 [1]单线程:所有命令执行都是在一个线程中进行的
01.介绍
1.处理客户端请求
2.所有命令执行都是在一个线程中进行的
3.IO多路复⽤
02.工作机制
a.基于内存的数据存储
Redis 将数据存储在内存当中,使得数据的读写操作避开了磁盘 I/O
而内存的访问速度远超硬盘,这是 Redis 读写速度快的根本原因
b.单线程模型
Redis 使用单线程模型来处理客户端的请求,这意味着在任何时刻只有一个命令在执行
这样就避免了线程切换和锁竞争带来的消耗
c.IO多路复⽤
基于 Linux 的 select/epoll 机制
该机制允许内核中同时存在多个监听套接字和已连接套接字,内核会一直监听这些套接字上的连接请求或者数据请求
一旦有请求到达,就会交给 Redis 处理,就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求
d.高效的数据结构
Redis 提供了多种高效的数据结构
如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)等
这些数据结构经过了高度优化,能够支持快速的数据操作
1.5 [1]多线程:处理网络数据的读写和协议解析
01.介绍
Redis6.0引入了多线程机制,但其多线程主要用于处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行的
02.工作机制
a.多线程处理网络数据和协议解析
Redis 6.0 的多线程是用来处理数据的读写和协议解析的,但命令执行仍然是单线程的
因此,不需要考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题
b.多线程默认禁用
Redis 6.0 的多线程默认是禁用的,只使用主线程。如果需要开启多线程,需要修改 redis.conf 配置文件:io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。可以在 redis.conf 配置文件中设置:io-threads <number_of_threads>
c.线程数设置建议
官方建议根据机器的核数设置线程数:
4 核的机器建议设置为 2 或 3 个线程
8 核的机器建议设置为 6 个线程
线程数一定要小于机器核数,且线程数并不是越大越好,官方认为超过 8 个线程基本就没什么意义了
1.6 [1]客户端:Redisson、Jedis、Lettuce、Spring的RedisTemplate
00.汇总
a.Jedis,同步阻塞
Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持
b.Lettuce,异步非阻塞
一个可伸缩线程安全的 Redis 客户端。多个线程可以共享同一个 RedisConnection
它利用优秀 Netty NIO 框架来高效地管理多个连接
c.Redisson,分布式服务
一个高级的分布式协调 Redis 客服端,能帮助用户在分布式环境中轻松实现一些 Java 的对象
d.Spring的RedisTemplate
Spring Boot 1.x默认使用Jedis
Spring Boot 2.x+默认切换为Lettuce
-----------------------------------------------------------------------------------------------------
可通过修改pom.xml显式指定客户端:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
01.Jedis(同步阻塞)
a.特点
最早的Redis Java客户端,采用同步阻塞IO模型
b.代码示例
// 连接池配置
JedisPool pool = new JedisPool("localhost", 6379);
try (Jedis jedis = pool.getResource()) {
// 同步操作
jedis.set("key", "value");
String value = jedis.get("key");
// 管道批处理
Pipeline pipeline = jedis.pipelined();
for (int i=0; i<100; i++) {
pipeline.set("key"+i, "value"+i);
}
pipeline.sync();
}
c.优点
API与Redis命令高度一致
成熟的连接池管理
支持事务/管道/发布订阅
d.缺点
线程不安全(需通过连接池解决)
同步模型性能瓶颈
不支持异步/响应式编程
02.Lettuce(异步非阻塞)
a.特点
基于Netty的异步客户端,支持响应式编程
b.代码示例
RedisClient client = RedisClient.create("redis://localhost:6379");
StatefulRedisConnection<String, String> connection = client.connect();
// 同步操作
RedisCommands<String, String> sync = connection.sync();
sync.set("key", "value");
// 异步操作
RedisAsyncCommands<String, String> async = connection.async();
RedisFuture<String> future = async.get("key");
// 响应式接口
RedisReactiveCommands<String, String> reactive = connection.reactive();
Mono<String> mono = reactive.get("key");
c.优点
线程安全的长连接
支持异步/响应式编程
自动重连机制
更高的并发性能
d.缺点
API相对复杂
需要自行管理连接资源
03.Redisson(分布式服务)
a.特点
提供分布式对象和高级功能
b.代码示例
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
RedissonClient client = Redisson.create(config);
// 分布式Map
RMap<String, Object> map = client.getMap("myMap");
map.put("key", "value");
// 分布式锁
RLock lock = client.getLock("myLock");
lock.lock();
try {
// 业务逻辑
} finally {
lock.unlock();
}
// 布隆过滤器
RBloomFilter<String> bloomFilter = client.getBloomFilter("words");
bloomFilter.tryInit(100000L, 0.03);
bloomFilter.add("word");
c.优点
丰富的分布式数据结构
内置分布式锁/限流器等
支持多种编解码器
与Spring Cache良好集成
d.缺点
学习成本较高
部分功能依赖Lua脚本
04.Spring的RedisTemplate
a.设计定位
Spring Data Redis提供的统一抽象层,默认实现基于Lettuce(Spring Boot 2.x+)
b.核心特点
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(RedisSerializer.json());
return template;
}
}
// 使用示例
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void opsDemo() {
// 值操作
redisTemplate.opsForValue().set("user:1", new User("Alice", 25));
// 哈希操作
redisTemplate.opsForHash().put("userMap", "1", new User("Bob", 30));
// 事务支持
redisTemplate.execute(new SessionCallback<>() {
public <K, V> Object execute(RedisOperations<K, V> operations) {
operations.multi();
operations.opsForValue().set("key1", "value1");
operations.opsForValue().set("key2", "value2");
return operations.exec();
}
});
}
c.优势
统一的操作接口
自动连接管理
内置序列化支持(JSON/Java等)
异常转换为统一异常体系
与Spring事务管理集成
d.局限性
抽象层可能隐藏底层特性
复杂操作仍需底层API
性能略低于直接使用原生客户端
1.7 [2]脑裂
01.Redis脑裂
在Redis集群或主从复制环境中,由于网络故障、配置错误或节点崩溃等原因,导致集群或主从节点之间的通信被意外切断
从而使得集群或主从结构被分割成多个独立的部分,每个部分都认为自己是完整的集群或主节点,并开始独立地处理数据
02.脑裂会带来什么问题?
a.数据不一致性(核心灾难)
当原主节点和新主节点同时接受写请求时,两个数据分叉产生冲突。例如:节点A和节点B分别写入key=100和key=200,恢复后无法自动合并
b.客户端写入冲突
客户端可能同时向两个"主节点"写入数据,出现:订单重复创建(如电商系统)、库存超卖(双主节点同时扣减库存)、分布式锁失效(多个客户端获取相同资源的锁)
c.集群状态混乱
哨兵误判存活节点导致频繁主从切换、客户端连接池持续在旧主和新主之间震荡、Proxy中间件路由表失效(如Codis)
d.数据恢复成本激增
需人工介入处理数据合并
e.业务连续性中断
比如部分客户端写入成功但读取不到数据(半写状态)、支付系统出现掉单/重复支付、监控系统误报大量服务异常
03.什么场景能导致脑裂?
a.网络故障
网络不稳定或网络设备故障可能导致节点之间的通信被切断
b.配置错误
错误的Redis配置可能导致节点无法正确识别其他节点的状态
c.节点崩溃
主节点或关键从节点的崩溃可能导致集群结构发生变化,从而引发脑裂
d.集群规模过大
在大型Redis集群中,由于节点数量众多,网络延迟和通信故障的可能性增加,从而更容易发生脑裂
04.如何避免脑裂?
a.说明
为了避免Redis脑裂问题,可以使用min-slaves-to-write和min-slaves-max-lag这两个参数进行配置
b.min-slaves-to-write
a.参数解释
该参数用于设置主库在执行写命令时,最少需要有多少个健康的从库存活
b.避免脑裂的方式
通过确保主库在执行写命令时,有足够数量的从库处于健康状态并能够及时与主库同步数据
当主库无法与足够数量的从库进行通信时,主库将拒绝执行写命令,从而避免在数据不一致的情况下进行写操作
c.min-slaves-max-lag
a.参数解释
该参数用于配置从库和主库进行数据复制时,ACK消息延迟的最大时间
ACK消息是从库确认已经接收到并应用了主库发送的数据复制消息
b.避免脑裂的方式
通过限制从库与主库之间的数据复制延迟,可以确保从库在指定的时间内与主库保持数据同步
如果ACK消息的延迟超过了配置的最大时间,则主库将拒绝执行写命令
这有助于防止在数据同步延迟较大的情况下进行写操作,从而降低脑裂发生时数据不一致的风险
05.为什么不能彻底解决脑裂问题?
a.说明
尽管参数能显著降低脑裂概率,但以下三个原因导致其无法完全消除脑裂
b.参数配置的局限性
若网络分区时间超过min-slaves-max-lag,主节点可能重新开始接收写入,而此时从节点仍处于不可用状态
若所有从节点均因故障或网络问题离线,主节点将永久拒绝写入,导致服务不可用,需人工干预
c.客户端行为的不可控性
客户端可能在网络分区期间继续向旧主节点发送写请求(如未及时感知主节点切换),而新主节点也在处理其他请求,导致数据分叉
d.最终一致性的本质
Redis主从复制采用异步复制,数据从主节点到从节点的传播存在延迟。在网络分区恢复后,仍需人工或自定义脚本处理冲突数据(如使用LAST-WRITE-WINS策略或业务层校验)
1.8 [2]拓扑:3种
00.汇总
a.分类
a.一主一从
结构:一个主节点(Master)和一个从节点(Slave)
功能:实现基本的数据冗余和读取性能提升
适用场景:适用于小规模应用,提供简单的备份和读写分离
b.一主多从
结构:一个主节点和多个从节点
功能:进一步提升读取性能,通过多个从节点分担读请求
适用场景:适用于读多写少的应用场景,提供更高的读取吞吐量
c.树状主从结构
结构:主节点和从节点形成树状结构,从节点可以有自己的从节点
功能:提供更复杂的读写分离和数据冗余,适合大规模应用
适用场景:适用于需要高可用性和复杂读写分离的场景
b.总结
a.Redis Sentinel(哨兵模式)
最少节点数:3 个 Sentinel 实例
功能:提供高可用性和自动故障转移
适用场景:适用于需要自动故障检测和恢复的场景,确保系统的高可用性
b.Redis Cluster(集群模式)
最少节点数:6 个 Redis 节点(通常是 3 个主节点和 3 个从节点)
功能:提供水平扩展和高可用性,通过数据分片实现负载均衡
适用场景:适用于需要大规模数据存储和高可用性的场景,支持自动分片和故障转移
c.Redis Replication(主从复制)
最少节点数:2 个节点(1 个主节点和 1 个从节点)
功能:提供数据冗余和读取性能提升,通过读写分离实现负载均衡
适用场景:适用于需要简单数据备份和读写分离的场景
01.Redis Sentinel(哨兵模式)(高可用性和自动故障转移)
a.最少节点数
3 个 Sentinel 实例
原因:至少需要 3 个 Sentinel 实例来避免单点故障,确保选举和故障转移的可靠性
b.功能
监控(Monitoring):持续检查主节点和从节点的状态
通知(Notification):在状态变化时通知管理员或应用程序
自动故障转移(Automatic failover):检测到主节点不可用时,自动提升从节点为新的主节点
配置提供者(Configuration provider):提供当前主节点地址给客户端,实现动态配置
c.工作原理
哨兵是一个独立的进程,作为进程,它会独立运行
其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例
通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器
当哨兵监测到 master 宕机,会自动将 slave 切换成 master
然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机
d.组成
哨兵节点:不存储数据,只监控数据节点
数据节点:包括主节点和从节点
02.Redis Cluster(集群模式)(水平扩展和高可用性)
a.最少节点数
6 个 Redis 节点(3 个主节点和 3 个从节点)
原因:至少 3 个主节点进行数据分片,3 个从节点用于数据冗余和容错
根据官方推荐:集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式
b.功能
水平扩展:通过数据分片实现
高可用性:通过从节点冗余实现
03.Redis Replication(主从复制)(数据冗余和读取性能)
a.最少节点数
2 个节点(1 个主节点和 1 个从节点)
主:一个是读写分离,分担"master"的读写压力
从:一个是方便做容灾恢复
原因:实现基本的主从复制功能,进行数据同步和冗余
b.功能
数据冗余:实现数据的热备份
故障恢复:主节点故障时,提升从节点为主节点
负载均衡:通过读写分离,主节点负责写,从节点负责读
高可用基石:为哨兵和集群提供基础
c.工作原理
全量同步:主节点将所有数据发送给从节点
增量同步:主节点只将变化的数据发送给从节点
d.存在问题
主节点故障时需要手动干预
主节点的写能力和存储能力受限于单机
e.数据不一致与问题
原因:由于异步复制,可能导致从节点数据滞后
解决方案:确保良好的网络连接,避免跨机房部署
1.9 [2]持久化:RDB、AOF、混合持久
00.汇总
RDB:快照备份
AOF:保证崩溃后的最大数据完整性
持久化是指将内存中的数据写入磁盘,以防止服务宕机导致数据丢失
01.RDB(Redis DataBase)
a.信息
a.定义
定期将内存数据以快照形式保存到硬盘
b.优点
紧凑的单文件(dump.rdb),适合备份
可以在夜间进行备份,将文件复制到远程服务器
c.缺点
可能丢失最后一次持久化后的数据
d.用途
快照备份
b.使用
a.redis.conf中SNAPSHOTTING(默认开启)
# 表示快照的频率,可以设置多个备份条件
save 900 1
save 300 10 --300秒内进行了10次写操作,那么在第300秒时刻,会将内存数据同步到硬盘文件
save 60 10000
# 快照最后一次备份数据失败后,是否继续处理客户端的写命令来接收数据,默认yes,推荐yes
stop-writes-on-bgsave-error yes
# 是否对快照文件进行压缩,默认yes,但会消耗CPU
rdbcompression yes
# 是否对备份文件使用CRC64算法进行数据校验,默认yes,但校验会增加约10%的性能消耗
rdbchecksum yes
# 表示生成的快照文件名,默认dump.rdb
dbfilename dump.rdb
# 表示生成的快照文件位置
dir ./
b.手动备份
save --将当前内存的数据以RDB文件的形式保存到硬盘中,但此操作会阻塞所有客户端,不建议使用
bgsave --Redis会在后台异步进行备份操作,同时还可以响应客户端请求,并且通过lastsave命令获取最后一次成功备份的时间,用来判断bgsave是否执行成功
c.注意
flushall命令会产生一个新的dump.rdb空文件,因此使用该命令,之前RDB方式备份的数据会被清空
shutdown命令会关闭Redis服务,但也会在关闭之前备份一次RDB数据(产生一个新的dump.rdb文件)
d.停止自动备份
src/redis-cli config set save
02.AOF(Append Only File)
a.信息
a.定义
记录每次写命令到日志文件,重启时通过日志恢复数据
b.优点
灵活,实时性好,可设置不同的 fsync 策略
c.缺点
文件较大,恢复速度慢
d.用途
保证崩溃后的最大数据完整性
b.使用
a.redis.conf中APPEND ONLY MODE(默认不开启,需要手动将appendonly no变yes,同时关闭默认快照)
# 开启 aof 配置
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# 备份的时机,下面的配置表示每秒钟备份一次
appendfsync everysec
# 表示 aof 文件在压缩时,是否还继续进行同步操作
no-appendfsync-on-rewrite no
# 表示当目前 aof 文件大小超过上一次重写时的 aof 文件大小的百分之多少的时候,再次进行重写
auto-aof-rewrite-percentage 100
# 如果之前没有重写过,则以启动时的 aof 大小为依据,同时要求 aof 文件至少要大于 64M
auto-aof-rewrite-min-size 64mb
b.为了避免快照备份的影响,将默认快照备份关闭
#save 900 1
#save 300 10
#save 60 10000
c.使用日志
上述配置,每秒钟备份一次
03.混合持久
a.Redis 混合持久化概述
a.定义
混合持久化是将 RDB 快照和 AOF 日志结合在一起,以提高数据恢复速度和数据完整性
它通过在 AOF 文件的开头嵌入一个 RDB 快照,后续的操作则以 AOF 日志形式记录
b.原理
在 Redis 执行 AOF 重写时,会先生成一个 RDB 快照,然后将该快照嵌入到新的 AOF 文件中
这样在数据恢复时,Redis 可以先加载 RDB 快照,然后重放 AOF 日志中的操作,从而快速恢复数据
b.常用API
a.BGREWRITEAOF
在后台重写 AOF 文件,生成混合持久化文件
b.CONFIG SET aof-use-rdb-preamble yes/no
启用或禁用混合持久化
c.使用步骤
a.启用混合持久化
编辑 `redis.conf` 文件,设置 `aof-use-rdb-preamble yes`
启动 Redis
b.执行 AOF 重写
使用 `BGREWRITEAOF` 命令手动触发 AOF 重写
c.数据恢复
当 Redis 重启时,会先加载 AOF 文件中的 RDB 快照,然后重放后续的 AOF 日志
d.每个场景对应的代码示例
a.配置混合持久化
# 编辑 redis.conf 文件
appendonly yes
aof-use-rdb-preamble yes
# 启动 Redis
redis-server /path/to/redis.conf
b.手动触发 AOF 重写
# 使用 redis-cli 触发 AOF 重写
redis-cli BGREWRITEAOF
c.数据恢复示例
当 Redis 重启时,它会自动加载混合持久化文件,无需额外的代码示例
Redis 会先加载 RDB 快照,然后重放 AOF 日志中的操作
1.10 [2]高可用:持久化、多机部署
01.持久化
a.RDB持久化
快照方式持久化,将某一个时刻的内存数据,以二进制的方式写入磁盘
b.AOF持久化
文件追加持久化,记录所有非查询操作命令,并以文本的形式追加到文件中
c.混合持久化:RDB + AOF 混合方式的持久化
Redis 4.0 之后新增的方式,混合持久化是结合了 RDB 和 AOF 的优点
在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头
再将后续的操作命令以 AOF 的格式存入文件
这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险
02.多机部署
哨兵模式
集群模式
主从复制
1.11 [2]主从复制:优点、实现、原理
01.优点
a.高可用性
通过将主数据库的数据复制到一个或多个从数据库,可以在主数据库故障时快速切换到从数据库
以实现系统的高可用性和容错能力,从而保证系统的持续可用性
b.提高整体性能和吞吐量
通过将读请求分散到多个从服务器上进行处理,从而减轻了主服务器的负载压力,提高数据库系统的整体性能和吞吐量
主服务器主要负责写操作,而从服务器主要负责读操作,从而分担了主服务器的压力
c.数据备份和恢复
通过主从同步,可以将主服务器上的数据异步复制到从服务器上,从而实现数据备份和灾难恢复的需求
在应对意外数据丢失、灾难恢复或误操作时,可以使用从服务器作为数据的备份源来进行数据恢复
02.实现
1.配置并重启主服务器
2.创建用于主从复制的用户
3.查看主服务器状态
4.配置并重启从服务器
5.在从服务器上设置主服务器信息
6.启动从服务器的复制进程
7.检查从服务器的复制状态
03.原理
a.异步复制
a.说明
MySQL 主从复制中最常见和默认的模式
在异步复制模式中,主服务器将数据修改操作记录到二进制日志(Binary Log)中
并将日志传输给从服务器。从服务器接收到二进制日志后,会异步地应用这些日志进行数据复制
b.优点
它的优点是及时响应给使用者,主服务器不会受到从服务器的影响而等待确认,可以提高主服务器的性能
c.缺点
由于是异步复制,可能存在数据传输的延迟,且从服务器上的复制过程是不可靠的
如果主服务器故障,尚未应用到从服务器的数据可能会丢失
b.半同步复制
a.说明
半同步复制是 MySQL 主从复制中的一种增强模式
在半同步复制模式中,主服务器将数据修改操作记录到二进制日志
并等待至少一个从服务器确认已接收到并应用了这些日志后才继续执行后续操作
b.优点
可以提供更高的数据一致性和可靠性,确保至少一个从服务器与主服务器保持同步
如果主服务器故障,已经确认接收并应用到从服务器的数据不会丢失
c.缺点
由于半同步复制需要等待从服务器的确认,因此相对于异步复制,会增加一定的延迟,可能会影响主服务器的性能
1.12 [2]过期策略:3种
00.汇总
a.定义
数据过期策略用于管理设置了过期时间的键
b.总结
定期删除 Redis定期检查并删除过期的键
惰性删除 只有在访问键时才检查其是否过期,并在过期时删除
主动删除 当内存达到限制时,Redis 触发内存淘汰机制,删除一部分键
01.定期删除(Periodic Deletion)
a.定义
Redis定期检查并删除过期的键
b.原理
Redis 每隔一段时间(默认每 100 毫秒)随机抽取一部分设置了过期时间的键进行检查
如果发现键已经过期,就删除这些键
c.常用API
EXPIRE key seconds:设置键的过期时间
TTL key:获取键的剩余生存时间
d.使用步骤
1.设置键的过期时间
2.Redis 定期检查并删除过期键
e.场景示例
SET session:abc123 "user data"
EXPIRE session:abc123 1800 # 设置会话30分钟过期
# Redis 每隔一段时间会自动检查并删除过期的键
02.惰性删除(Lazy Deletion)
a.定义
只有在访问键时才检查其是否过期,并在过期时删除
b.原理
当客户端尝试访问某个键时,Redis 检查该键是否过期
如果过期则立即删除,并返回空值
c.常用API
GET key:获取键的值
EXPIRE key seconds:设置键的过期时间
d.使用步骤
1.设置键的过期时间
2.访问键时,Redis 检查并删除过期键
e.场景示例
SET cache:item "value"
EXPIRE cache:item 60 # 设置缓存1分钟过期
# 访问键时检查是否过期
GET cache:item # 如果过期,返回 nil
03.主动删除(Eviction)
a.定义
当内存达到限制时,Redis 触发内存淘汰机制,删除一部分键
b.原理
当 Redis 内存使用达到设置的上限时,触发内存淘汰机制
根据配置的策略(如 LRU、LFU)选择要移除的键
c.常用API
CONFIG SET maxmemory <bytes>:设置最大内存使用量
CONFIG SET maxmemory-policy <policy>:设置内存淘汰策略
d.使用步骤
1.设置最大内存使用量和淘汰策略
2.当内存达到上限时,Redis 根据策略删除键
e.场景示例
# 设置最大内存为 100MB,使用 LRU 策略
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy allkeys-lru
# 当内存达到 100MB 时,Redis 会根据 LRU 策略删除键
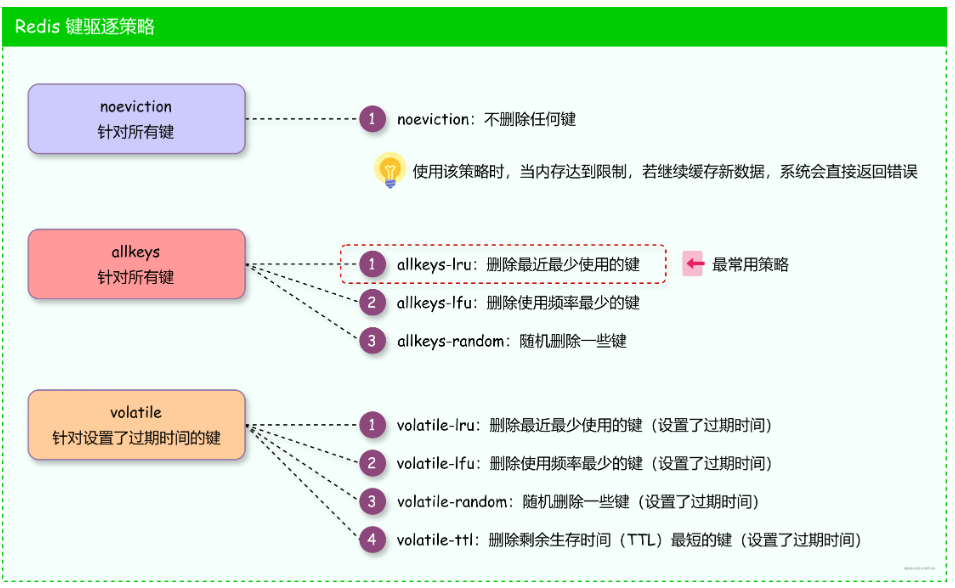
1.13 [2]淘汰策略:6种
00.汇总
a.定义
当内存使用达到限制时,数据淘汰策略决定了哪些数据应该被移除以释放空间
b.3类
策略 概念 核心指标 实现要点 类比记忆
LRU 淘汰最久未访问的键 最近访问时间 近似采样+时间戳比较 图书馆最近借阅的书籍
LFU 淘汰访问频率最低的键 访问频率 概率计数+时间衰减 热门排行榜 (热度会下降)
TTL 淘汰剩余存活时间最短的键 剩余存活时间 过期字典+TTL排序 食品保质期倒计时
c.6个
volatile-lru 在设置了过期时间的键空间中,移除最近最少使用的键
allkeys-lru 在键空间中,移除最近最少使用的键
volatile-ttl 在设置了过期时间的键空间中,优先移除即将过期的键
volatile-random 在设置了过期时间的键空间中,随机移除键
allkeys-random 在键空间中,随机移除键
no-eviction 禁止删除数据,当内存不足以容纳新写入数据时,新写入操作会报错
01.3类
a.LRU:近似算法的精妙设计
a.传统LRU的局限性
a.理想实现
维护双向链表,移动节点至头部,淘汰尾部(时间复杂度O(1))
b.内存问题
每个键需存储前后指针,额外占用16字节(64位系统)
b.Redis的近似LRU实现
a.关键结构
每个Redis对象(redisObject)的lru字段(24位)记录访问时间戳(单位:秒级精度)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; // LRU_BITS=24
int refcount;
void *ptr;
} robj;
b.淘汰流程
随机采样:从所有键中随机选取maxmemory-samples(默认5)个键
淘汰候选:选择采样集中lru最小的键(即最久未访问)
c.源码入口,evict.c/evictionPoolPopulate()
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
// 随机采样键,计算idle时间(当前时间 - lru)
for (j = 0; j < count; j++) {
// 计算idle时间
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
}
// 维护淘汰池,保留idle最大的键
}
}
d.优化点
内存节省:24位lru仅需3字节,精度降低但满足淘汰需求
可调精度:增大maxmemory-samples可逼近真实LRU,但增加CPU开销
b.LFU:频率统计与衰减机制
a.LFU的核心挑战
a.空间限制
精确统计频率需大量内存
b.时间衰减
旧访问记录需降低权重
b.Redis的LFU实现
a.lru字段复用
高16位:访问计数器(对数计数,范围0-255)
低8位:最后一次访问的分钟级时间戳(用于衰减)
---------------------------------------------------------------------------------------------
// 获取计数器与衰减时间
#define LFU_LOG_INCR 5 // 计数器增量基数
#define LFU_DECAY_TIME 1 // 衰减周期(分钟)
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_LOG_INCR;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
return (r < p) ? counter+1 : counter;
}
b.频率更新
每次访问时,计数器按概率增加(类似Morris计数器)
c.衰减机制
若当前时间与低8位时间差超过LFU_DECAY_TIME,计数器减半
d.淘汰流程
选择采样集中lfu值最小的键(频率最低)
c.TTL:时间优先的淘汰逻辑
a.实现原理
a.expires字典
Redis维护一个哈希表,存储所有设置TTL的键及其绝对过期时间(Unix时间戳)
b.淘汰策略
volatile-ttl:从expires字典中随机采样,淘汰剩余存活时间(TTL - 当前时间)最短的键
b.源码片段
// 计算键的剩余存活时间
long long getExpire(redisDb *db, robj *key) {
dictEntry *de = dictFind(db->expires,key->ptr);
if (de) return dictGetSignedIntegerVal(de) - mstime();
return -1;
}
// 在evictionPoolPopulate中处理TTL策略
if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
idle = ULLONG_MAX - (long)getExpire(db,key);
}
02.6类
a.volatile-lru
a.定义
在设置了过期时间的键空间中,移除最近最少使用的键
b.原理
使用 LRU(Least Recently Used)算法,优先移除最近最少使用的键
仅在设置了过期时间的键中进行选择
c.常用API
CONFIG SET maxmemory-policy volatile-lru:设置淘汰策略为 volatile-lru
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 volatile-lru
3.当内存不足时,Redis 自动移除最近最少使用的过期键
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy volatile-lru
b.allkeys-lru
a.定义
在键空间中,移除最近最少使用的键
b.原理
使用 LRU 算法,优先移除最近最少使用的键
在所有键中进行选择,无论是否设置过期时间
c.常用API
CONFIG SET maxmemory-policy allkeys-lru:设置淘汰策略为 allkeys-lru
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 allkeys-lru
3.当内存不足时,Redis 自动移除最近最少使用的键
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy allkeys-lru
c.volatile-ttl
a.定义
在设置了过期时间的键空间中,优先移除即将过期的键
b.原理
根据键的 TTL(Time To Live),优先移除即将过期的键
c.常用API
CONFIG SET maxmemory-policy volatile-ttl:设置淘汰策略为 volatile-ttl
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 volatile-ttl
3.当内存不足时,Redis 自动移除即将过期的键
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy volatile-ttl
d.volatile-random
a.定义
在设置了过期时间的键空间中,随机移除键
b.原理
随机选择一个设置了过期时间的键进行移除
c.常用API
CONFIG SET maxmemory-policy volatile-random:设置淘汰策略为 volatile-random
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 volatile-random
3.当内存不足时,Redis 随机移除一个过期键
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy volatile-random
e.allkeys-random
a.定义
在键空间中,随机移除键
b.原理
随机选择一个键进行移除,无论是否设置过期时间
c.常用API
CONFIG SET maxmemory-policy allkeys-random:设置淘汰策略为 allkeys-random
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 allkeys-random
3.当内存不足时,Redis 随机移除一个键
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy allkeys-random
f.no-eviction
a.定义
禁止删除数据,当内存不足以容纳新写入数据时,新写入操作会报错
b.原理
不进行任何数据淘汰,直接返回错误
c.常用API
CONFIG SET maxmemory-policy no-eviction:设置淘汰策略为 no-eviction
d.使用步骤
1.设置最大内存使用量
2.配置淘汰策略为 no-eviction
3.当内存不足时,Redis 返回错误,不进行数据淘汰
e.场景示例
CONFIG SET maxmemory 100mb
CONFIG SET maxmemory-policy no-eviction
1.14 [2]碎片管理:自动
01.概述
a.说明
内存碎片整理是指对Redis中的内存空间进行重新排列和整理,以减少内存碎片的数量和大小
内存碎片是指已分配但不再使用的内存块,这些内存块虽然被标记为已分配,但实际上并未被有效利用,造成了内存的浪费
b.说明
在Redis中,由于数据的增删改查操作不断进行,会导致内存空间中出现大量的内存碎片
这些内存碎片虽然单个很小,但如果积累起来会导致内存碎片化,降低内存利用率,影响系统的性能和稳定性
c.说明
为了解决内存碎片化的问题,Redis会定期进行内存碎片整理操作
02.内存碎片整理过程
a.遍历内存空间
Redis会遍历整个内存空间,检查每个内存块的状态,包括已分配和未分配的内存块
b.合并相邻的空闲内存块
Redis会尝试合并相邻的空闲内存块,将它们合并成一个更大的内存块
这样可以减少内存碎片的数量,提高内存利用率
c.移动数据
如果有必要,Redis可能会将数据从一个内存块移动到另一个内存块
以便更好地组织内存空间。这个过程可能会比较耗时,因为需要将数据从一个位置复制到另一个位置
d.释放不再使用的内存块
最后,Redis会释放那些不再使用的内存块,以便它们可以被重新分配给新的数据
03.总结
通过定期进行内存碎片整理操作,Redis可以保持内存空间的连续性
减少内存碎片化的程度,提高内存利用率,从而提高系统的性能和稳定性
但是,内存碎片整理过程可能会消耗一定的系统资源,尤其是在内存碎片较多的情况下
所以,通常情况下,Redis会选择在系统负载较低的时候进行碎片整理操作,以避免对系统性能产生不利影响
1.15 [3]Redis、Redisson
00.汇总
Redis:一个数据存储,提供高性能的内存数据结构存储和丰富的操作命令
Redisson:一个用于简化Redis操作的Java库,提供分布式和可伸缩的数据结构和服务
01.Redis
a.定义
Redis 是一个开源的内存数据结构存储,用作数据库、缓存和消息代理
b.功能
支持多种数据结构,如字符串、哈希、列表、集合、有序集合、位图等
提供丰富的操作命令,支持事务、发布/订阅、Lua脚本等高级功能
支持持久化机制(RDB和AOF),确保数据的持久性
支持主从复制、哨兵模式和集群模式,实现高可用和分布式部署
c.使用场景
高性能缓存:通过缓存热点数据,减少数据库压力,提高系统响应速度
实时分析:利用内存存储的高性能,进行实时数据分析和处理
消息队列:通过列表或发布/订阅机制实现消息队列功能
会话存储:存储用户会话信息,实现快速访问和管理
02.Redisson
a.定义
Redisson 是一个基于 Redis 的 Java 客户端,提供分布式和可伸缩的数据结构和服务
b.功能
分布式对象:提供分布式的 Map、Set、List、Queue 等数据结构
分布式锁:实现分布式锁、可重入锁、公平锁、读写锁等,简化分布式系统的开发
同步器:提供分布式的 CountDownLatch、Semaphore、Barrier 等同步器
集合和映射:支持分布式的集合和映射,便于在分布式环境中使用
其他服务:提供分布式的 AtomicLong、AtomicDouble、BloomFilter 等服务
c.使用场景
Java 应用中需要分布式特性和高可用性支持:通过 Redisson 提供的分布式数据结构和服务,简化分布式系统的开发
分布式锁:在分布式环境中实现分布式锁,确保数据的一致性和安全性
分布式同步器:在分布式环境中实现同步器,协调多个线程或进程的操作
1.16 [3]Redis、Memcached
00.汇总
a.数据结构
Redis:支持多种数据结构,如字符串、哈希、列表、集合、有序集合等,适用于多种应用场景
Memcached:主要支持键值对形式的数据存储,数据结构相对简单
b.持久化
Redis:支持 RDB 和 AOF 两种持久化方式,可以将数据持久化到磁盘中
Memcached:不支持持久化,数据存储在内存中,重启后数据会丢失
c.分布式
Redis:支持主从复制、哨兵模式和集群模式,实现高可用和分布式部署
Memcached:支持分布式缓存,多个 Memcached 实例可以组成一个集群,但不支持内置的高可用机制
d.高级功能
Redis:支持事务、Lua 脚本、发布/订阅、键过期等高级功能
Memcached:功能相对简单,主要用于缓存,不支持事务和发布/订阅等高级功能
e.性能
Redis:由于支持多种数据结构和高级功能,性能略低于 Memcached,但仍然非常高效
Memcached:由于功能简单,专注于缓存,性能非常高
f.使用场景
Redis:适用于高性能缓存、实时分析、消息队列、会话存储等多种场景
Memcached:适用于高性能缓存、临时数据存储等简单场景
01.Redis
a.定义
Redis 是一个开源的内存数据结构存储,用作数据库、缓存和消息代理
b.功能
数据结构:支持多种数据结构,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)、位图(Bitmap)等
持久化:支持 RDB(快照)和 AOF(追加文件)两种持久化方式
高性能:由于数据存储在内存中,读写速度极快,适用于高并发场景
分布式:支持主从复制、哨兵模式和集群模式,实现高可用和分布式部署
高级功能:支持事务、Lua 脚本、发布/订阅、键过期等功能
c.使用场景
高性能缓存:缓存热点数据,减少数据库压力,提高系统响应速度
实时分析:利用内存存储的高性能,进行实时数据分析和处理
消息队列:通过列表或发布/订阅机制实现消息队列功能
会话存储:存储用户会话信息,实现快速访问和管理
02.Memcached
a.定义
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态 Web 应用以减轻数据库负载
b.功能
数据结构:主要支持键值对(Key-Value)形式的数据存储,值可以是字符串、对象等
高性能:数据存储在内存中,读写速度极快,适用于高并发场景
分布式:支持分布式缓存,多个 Memcached 实例可以组成一个集群
简单易用:API 简单,易于集成到各种应用中
c.使用场景
高性能缓存:缓存数据库查询结果、会话数据、页面片段等,减少数据库压力,提高系统响应速度
临时数据存储:存储一些临时数据,如计算结果、临时会话数据等
1.17 [3]Redis、关系型数据库
00.汇总
a.数据存储方式
Redis:数据存储在内存中,读写速度极快,但数据量受内存限制
关系型数据库:数据存储在磁盘中,读写速度相对较慢,但数据量不受内存限制
b.数据模型
Redis:支持多种数据结构,如字符串、哈希、列表、集合、有序集合等
关系型数据库:基于关系模型,通过表格形式存储数据,表与表之间通过外键建立关系
c.查询语言
Redis:不支持 SQL 查询,使用命令行进行数据操作
关系型数据库:使用 SQL 进行数据查询和操作,支持复杂的查询和数据操作
d.事务支持
Redis:支持简单的事务操作,但不完全符合 ACID 特性
关系型数据库:支持 ACID 事务,确保数据的一致性和可靠性
e.持久化
Redis:支持 RDB 和 AOF 两种持久化方式,但主要用于内存数据存储
关系型数据库:数据存储在磁盘中,确保数据的持久性
f.使用场景
Redis:适用于高性能缓存、实时分析、消息队列、会话存储等场景
关系型数据库:适用于需要复杂查询和事务支持的业务系统、数据分析和数据存储等场景
01.Redis
a.定义
Redis 是一个开源的内存数据结构存储,用作数据库、缓存和消息代理
b.功能
数据结构:支持多种数据结构,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)、位图(Bitmap)等
持久化:支持 RDB(快照)和 AOF(追加文件)两种持久化方式
高性能:由于数据存储在内存中,读写速度极快,适用于高并发场景
分布式:支持主从复制、哨兵模式和集群模式,实现高可用和分布式部署
高级功能:支持事务、Lua 脚本、发布/订阅、键过期等功能
c.使用场景
高性能缓存:缓存热点数据,减少数据库压力,提高系统响应速度
实时分析:利用内存存储的高性能,进行实时数据分析和处理
消息队列:通过列表或发布/订阅机制实现消息队列功能
会话存储:存储用户会话信息,实现快速访问和管理
02.关系型数据库
a.定义
关系型数据库(RDBMS)是一种基于关系模型的数据库管理系统,通过表格形式存储数据,并使用 SQL(结构化查询语言)进行数据操作
b.功能
数据模型:基于关系模型,通过表格形式存储数据,表与表之间通过外键建立关系
事务支持:支持 ACID(原子性、一致性、隔离性、持久性)事务,确保数据的一致性和可靠性
SQL 查询:使用 SQL 进行数据查询和操作,支持复杂的查询和数据操作
持久化:数据存储在磁盘中,确保数据的持久性
索引:支持多种索引类型,提高数据查询效率
c.使用场景
业务系统:适用于需要复杂查询和事务支持的业务系统,如电商、金融、ERP 等
数据分析:适用于需要进行复杂数据分析和报表生成的场景
数据存储:适用于需要持久化存储和管理大量数据的场景
1.18 [4]Redis内存满了会发生什么?
00.回答
当Redis的内存数据满了,它不会立即宕机
当Redis的内存满了会导致写入失败、读取延迟增加、内存碎片和程序崩溃等问题
Redis会根据一些内存管理策略来处理内存数据满的情况,具体行为取决于你的Redis配置和所使用的版本
01.当 Redis 内存数据满了,以下是可能发生的情况
a.写入操作失败
如果 Redis 没有配置开启持久化(如 RDB 或 AOF),并且达到了最大内存限制
默认行为是不接受写操作并返回错误
这是为了保护数据的一致性,防止数据丢失
b.内存淘汰策略
Redis 提供了多种内存淘汰策略来处理内存数据满的情况
当数据满时,根据配置的淘汰策略,Redis 可能会自动删除一些数据来腾出空间
c.持久化策略
如果 Redis 配置了持久化(如 RDB 或 AOF)
当内存数据满时,Redis 可以将数据持久化到磁盘,从而腾出内存空间
这样可以保证数据的持久性,并继续接受写入操作
d.后果与影响
a.性能影响
当Redis不断接近内存限制时,它可能需要频繁地进行数据淘汰操作
这会增加CPU的负载,从而影响Redis服务器的响应时间和吞吐量
b.数据丢失
根据淘汰策略,一些数据可能会被删除以释放内存
这意味着应用程序可能无法再访问这些数据
c.写入失败
在noeviction策略下,当内存满时,所有写命令都将被拒绝
这可能导致应用程序无法正常工作
e.内存淘汰策略
a.noeviction
不会淘汰任何键,达到内存限制后返回错误
b.allkeys-random
在所有键中,随机删除键
c.volatile-random
在设置了过期时间的键中,随机删除键
d.allkeys-lru
通过LRU算法淘汰最近最少使用的键,保留最近使用的键
e.volatile-lru
从设置了过期时间的键中,通过LRU算法淘汰最近最少使用的键
f.allkeys-lfu
从所有键中淘汰使用频率最少的键,从所有键中驱逐使用频率最少的键
g.volatile-lfu
从设置了过期时间的键中,通过LFU算法淘汰使用频率最少的键
h.volatile-ttl
从设置了过期时间的键中,淘汰马上就要过期的键
f.应对策略
a.优化数据结构
优化数据使用结构,例如使用压缩列表或整数集合等,可以减少内存的使用
b.内存分析
定期使用Redis的内存分析工具,如MEMORY USAGE命令,来找出内存使用的热点
c.垂直或水平扩展
通过增加更多的Redis实例来分散数据,或升级现有实例的内存容量
d.监控与告警
实施监控系统以跟踪内存使用情况,并在接近限制时发出告警,以便及时采取行动
1.19 [4]RedisIdWorker全局ID生成器
01.概述
a.定义
一种分布式系统下用来生成全局唯一 ID 的工具
b.特点
唯一性,满足优惠券需要唯一的 ID 标识用于核销
高可用,随时能够生成正确的 ID
高性能,生成 ID 的速度很快
递增性,生成的 ID 是逐渐变大的,有利于数据库形成索引
安全性,生成的 ID 无明显规律,可以避免间接泄露信息
生成量大,可满足优惠券订单数据量大的需求
c.ID组成部分
符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
02.代码实现
a.目标
手动实现一个简单的全局 ID 生成器
b.实现流程
创建生成器:在 utils 包下创建 RedisIdWorker 类,作为 ID 生成器
创建时间戳:创建一个时间戳,即 RedisId 的高32位
获取当前日期:创建当前日期对象 date,用于自增 id 的生成
count:设置 Id 格式,保证 Id 严格自增长
拼接 Id 并将其返回
c.代码实现
@Component
public class RedisIdWorker {
// 开始时间戳
private static final long BEGIN_TIMESTAMP = 1640995200L;
// 序列号的位数
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
// 获取下一个自动生成的 id
public long nextId(String keyPrefix){
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 3.获取当前日期
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 4.获取自增长值:生成一个递增计数值。每次调用 increment 方法时,它会在这个key之前的自增值的基础上+1(第一次为0)
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 5.拼接并返回
return timestamp << COUNT_BITS | count;
}
}
1.20 [4]Redis不做主数据库,只做缓存
01.虽然Redis非常快,但它也有一些局限性,不能完全替代主数据库
a.事务处理
Redis只支持简单的事务处理,对于复杂的事务无能为力,比如跨多个键的事务处理
b.数据持久化
Redis是内存数据库,数据存储在内存中,如果服务器崩溃或断电,数据可能丢失
虽然Redis提供了数据持久化机制,但有一些限制
c.数据处理
Redis只支持一些简单的数据结构,比如字符串、列表、哈希表等
如果需要处理复杂的数据结构,比如关系型数据库中的表,那么Redis可能不是一个好的选择
d.数据安全
Redis没有提供像主数据库那样的安全机制,比如用户认证、访问控制等等
1.21 [4]缓存用Redis,而不用map/guava
01.选择使用Redis而不是本地的Map或Guava缓存库
a.本地的Map或Guava缓存库
本地缓存
最主要的特点是轻量以及快速,生命周期随着jvm的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性
b.Redis
分布式缓存
在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性
2 数据结构
2.1 注意:8个
00.汇总
1.FLUSHALL和FLUSHDB
2.KEYS
3.CONFIG
4.MONITOR
5.直接删除BIGKEY
6.动辄全量操作
7.不设置客户端连接数
8.不设置密码
01.FLUSHALL和FLUSHDB
a.描述
这两个命令会分别清空所有数据库或当前数据库中的所有数据
由于它们会删除大量数据,数据量大的时候会对性能产生明显影响。并且如果使用不当,可能会导致数据丢失
b.建议
为了避免误操作,可以考虑在配置文件中禁用或重命名这些命令
02.KEYS
a.描述
这个命令用于查找所有匹配给定模式的键
这个命令会扫描整个键空间,可能会导致性能问题,因为它会锁定数据库直到搜索完成
b.建议
一个比较好的替代是使用 SCAN 命令,它提供了一种逐步迭代 Redis 中的键的方式,而不会阻塞服务器
03.CONFIG
a.描述
这个命令允许客户端动态地修改 Redis 配置
出于安全考虑,应该避免使用此命令,因为这可能会被用来更改重要的配置,从而影响服务器的稳定性和安全性
b.建议
Redis 配置建议最好都在 redis.conf 中直接配置好再启动,这是最佳实践
04.MONITOR
a.描述
这个命令用来实时监控 Redis 服务器接收到的命令
在高负载的情况下使用它可能会导致性能问题
因为它会增加 Redis 的输出缓冲区的内存使用,命令多的时候可能会造成缓冲区溢出
05.直接删除BIGKEY
a.描述
在 Redis 中,直接删除 bigkey 会对性能产生负面影响
因为 Redis 是单线程处理请求的,删除 bigkey 会占用较长时间,从而阻塞其他请求的处理
b.建议
分批删除:可以尝试分批删除 bigkey 中的元素,例如使用 LREM 命令从列表中移除元素,或者使用 ZREM 命令从有序集合中移除元素
使用 UNLINK 命令:在 Redis4.0 及以上版本中,可以使用 UNLINK 命令来异步删除 key
使用 SCAN 命令:如果需要删除多个 bigkey,可以使用 SCAN 命令配合 DEL 命令来分批次删除
使用 lazy-free 机制:在 Redis4.0 及以上版本中,可以开启 lazy-free 机制,使得内存释放操作在后台线程中进行
避免创建 bigkey:设计应用程序时,应该尽量将数据分割成更小的块
06.动辄全量操作
a.描述
全量操作是指使用 hgetall、lrange(0,-1),smembers 等命令一次性获取所有数据
b.建议
如果想要遍历所有数据,可以考虑使用 hscan、sscan 以及 zscan 这一类逐步分批扫描的命令
07.不设置客户端连接数
a.描述
为了确保 Redis 服务器的稳定性和性能,建议根据实际的应用场景和服务器资源情况,合理配置客户端连接数
b.建议
可以根据服务器的硬件资源和操作系统的限制,合理设置 maxclients 参数
08.不设置密码
a.描述
不设置密码会带来很多安全性问题
b.建议
requirepass yourpassword
c.在生产环境中,还应该考虑使用更高级的安全措施
使用 SSL/TLS 加密客户端和服务器之间的连接
配置防火墙规则,只允许特定的 IP 地址访问 Redis 服务器
定期更新和打补丁,以保护 Redis 服务器不受已知漏洞的影响
2.2 优化:18招
00.汇总
01.选择合适的数据结构
02.避免使用过大的key和value
03.使用RedisPipeline
04.控制连接数量
05.合理使用过期策略
06.使用Redis集群
07.充分利用内存优化
08.使用Lua脚本
09.监控与调优
10.避免热点key
11.使用压缩
12.使用Geo位置功能
13.控制数据的持久化
14.尽量减少事务使用
15.合理配置客户端
16.使用RedisSentinel
17.优化网络配置
18.定期清理不必要的数据
01.选择合适的数据结构
a.描述
Redis支持多种数据结构,如字符串、哈希、列表、集合和有序集合。根据实际需求选择合适的数据结构可以提高性能
b.示例
如果要存储用户信息,考虑使用哈希而不是多个字符串
jedis.hset("user:1001", "name", "Alice");
jedis.hset("user:1001", "age", "30");
这样可以高效地存储和访问多个属性
02.避免使用过大的key和value
a.描述
较长的key和value会占用更多内存,还可能影响性能
保持key简短,并使用简洁的命名约定
b.示例
将“user:1001:profile”简化为“u:1001:p”
还可以做压缩等其他优化
03.使用Redis Pipeline
a.描述
对多个命令的批量操作,使用Pipeline可以显著降低网络延迟,提升性能
b.示例
批量设置key可以这样做:
Pipeline p = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
p.set("key:" + i, "value:" + i);
}
p.sync();
这样一次性可以发送多个命令,减少了网络往返时间,能够提升性能
04.控制连接数量
a.描述
过多的连接会造成资源浪费,使用连接池可以有效管理连接数量
b.示例
使用JedisPool:
JedisPool pool = new JedisPool("localhost");
try (Jedis jedis = pool.getResource()) {
jedis.set("key", "value");
}
有了连接池,这样连接就会被复用,而不是每次都创建新连接,使用完之后,又放回连接池
05.合理使用过期策略
a.描述
设置合理的过期策略,能防止内存被不再使用的数据占满。
b.示例
对会话数据设置过期时间:
jedis.setex("session:12345", 3600, "data");
Redis内部会定期清理过期的缓存
06.使用Redis集群
a.描述
数据量增大时,使用Redis集群可以将数据分散到多个节点,提升并发性能
b.说明
可以将数据哈希分片到多个Redis实例
07.充分利用内存优化
a.描述
选择合适的内存管理策略,Redis支持LRU(Least Recently Used)策略,可以自动删除不常用的数据
b.示例
配置Redis的maxmemory:
maxmemory 256mb
maxmemory-policy allkeys-lru
08.使用Lua脚本
a.描述
Lua脚本让多条命令在Redis中原子性执行,减少网络延迟
b.示例
使用Lua防止多个命令的网络延迟:
EVAL "redis.call('set', KEYS[1], ARGV[1]) return redis.call('get', KEYS[1])" 1 "key" "value"
使用Lua脚本,可以保证Redis的多个命令是原子性操作
09.监控与调优
a.描述
使用INFO命令监控Redis性能数据,如命令支持、内存使用等,及时调优
b.示例
使用命令获取监控信息:
INFO memory
INFO clients
10.避免热点key
a.描述
热点key会造成单一节点的压力,通过随机化访问来避免
b.示例
可以为热点key加随机后缀:
String key = "hotkey:" + (System.currentTimeMillis() % 10);
jedis.incr(key);
11.使用压缩
a.描述
存储大对象时,考虑使用压缩技术来节省内存
b.示例
可以使用GZIP压缩JSON数据:
byte[] compressed = gzipCompress(jsonString);
jedis.set("data", compressed);
12.使用Geo位置功能
a.描述
Redis支持地理位置存储和查询,使用GEOADD可以高效管理地理数据
b.示例
存储地点信息:
jedis.geoadd("locations", longitude, latitude, "LocationName");
13.控制数据的持久化
a.描述
合理设置RDB和AOF的持久化策略,避免频繁写盘造成性能下降
b.示例
设置持久化的时间间隔:
save 900 1
appendonly yes
14.尽量减少事务使用
a.描述
在高并发场景下,避免过度使用MULTI/EXEC,因为事务会锁住key
b.说明
可以直接使用单条命令替代事务
15.合理配置客户端
a.描述
调整客户端的连接超时和重连策略,以适应高负载场景,确保连接稳定
b.示例
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(128); // 最大连接数
poolConfig.setMaxIdle(64); // 最大空闲连接
poolConfig.setMinIdle(16); // 最小空闲连接
poolConfig.setTestOnBorrow(true);
poolConfig.setTestOnReturn(true);
poolConfig.setTestWhileIdle(true);
JedisPool jedisPool = new JedisPool(poolConfig, "localhost", 6379, 2000); // 连接超时2000ms
16.使用Redis Sentinel
a.描述
使用Sentinel进行监控,实现高可用性,确保系统在故障时能够快速切换
b.说明
配置Sentinel进行主从复制
17.优化网络配置
a.描述
保证Redis服务器有良好的网络带宽,避免网络瓶颈
b.说明
使用服务器内部专线,减少延迟
18.定期清理不必要的数据
a.描述
生命周期管理很关键,定期删除过期或不必要的数据,保持内存高效利用
b.说明
可以设置Cron任务定期清理
2.3 汇总:5+6=11
00.汇总
a.分类1
string:字符串
hash:哈希
list:列表
set:无序集合
zset:有序集合
b.分类2
stream:消息队列
pub/sub:发布/订阅
bitmap:位图
bitfield:位域
geo:地理
hyperloglog:基数统计
01.通用
select 0 --选择数据库
exists mykey --返回1或0标识给定key的值是否存在
del mykey --删除key对应的值
type mykey --返回key对应的值的存储类型
-----------------------------------------------------------------------------------------------------
set name lisi ex 10 --赋值 不存在/存在
set name lisi ex 10 nx --赋值 不存在创建 存活10秒
set name lisi ex 10 xx --赋值 存在时创建 存活10秒
-----------------------------------------------------------------------------------------------------
setex name lisi 10 xa --setex 存活10秒
setnx name lisi --setnx 不存在创建
pexpire kl 10 --毫秒
expire age 5 --秒
-----------------------------------------------------------------------------------------------------
keys * --全部 *
keys k --指定
keys k? --模糊
flushdb --清空当前数据库
flushall --清空全部数据库
02.字符串 (String)
set name zs --赋值
get name --取值
strlen name --获取长度
getrange name 0 1 --截取字符串
-----------------------------------------------------------------------------------------------------
mset k1 v1 k2 v2 --批量赋值
mget k1 k2 k3 --批量取值
-----------------------------------------------------------------------------------------------------
incr num --自增1
decr num --自减1
incrby num 100 --增加100
decrby num 50 --减少50
03.哈希 (Hash)
hset p name zs --赋值
hset p name --取值
hmset p name zs age 23 --批量赋值
hmget p name age --批量取值
hkeys p --显示全部key
hvals p --显示全部value
hgetall p --显示全部key+全部value
hdel p name age --删除
hincrby p age 11 --整数增加11
hincrby p age -11 --整数增加-11
hincrby float p age 1.5 --浮点数增加1.5
hincrby float p age -1.5 --浮点数增加-1.5
04.列表 (List)
lpush names zs ls ww --lpush 左
rpush names zhangsan lisi wangwu --rpush 左
lrange names 0 -1 --范围:全部
lrange names 0 3 --范围:0~3
rpop names --rpop
lpop names --lpop
-----------------------------------------------------------------------------------------------------
ltrim names 0 2 --截取范围:0~2
lset names 1 QQ --修改索引为1
linsert names before QQ ww --在QQ左侧插入WW
linsert names before QQ PP --在QQ右侧插入WW
05.集合 (Set)
sadd set h1 h2 h3 --添加
smembers set --查看全部
sismember set h2 --是否存在
srem set h2 --移除
srandmember set 1 --随机获取1个元素(不删除)
spop set 1 --随机获取1个元素(删除)
-----------------------------------------------------------------------------------------------------
smove set set2 a2 --smove:将set中的a2元素,移动至set2中
-----------------------------------------------------------------------------------------------------
smembers set --查看集合set:a1 a3
smembers set2 --查看集合set2:a1 a2
sdiff set set2 --交集
sinter set set2 --差集
sunion set set2 --并集
06.有序集合 (Sorted Set)
zadd persons 8 zs 9 ls 10 ww --增加
zrange persons 1 2 --正序查询
zrangep persons 1 2 withscores --正序查询带scores
zrevrange persons 1 2 --逆序查询
-----------------------------------------------------------------------------------------------------
zrangebyscore persons 8 9 --根据score正序查询(闭区间)
zrangebyscore persons (8 (10 --根据score正序查询(开区间)
zrangebyscore persons 8 10 withscores limit 1 2 --根据score正序查询(闭区间),从1开始,显示2条
-----------------------------------------------------------------------------------------------------
zrem persons ls --移除
zcount persons 8 10 --计数
zrank persons ww --下标
zscore persons ww --查看score
2.4 本质:KV结构
00.本质
a.KV结构
每种数据结构都以键值对的形式存在,键是唯一的字符串,值可以是不同的数据结构(字符串、哈希、列表、集合、有序集合)
b.过期时间(TTL)
可以为每个键设置一个过期时间。当设置了过期时间后,Redis 会在后台监控这些键,并在过期时间到达时自动删除它们
c.删除行为
当键过期时,Redis 会删除整个键值对,键(K)会被删除
与该键关联的值(V),无论是简单的字符串还是复杂的数据结构(如列表或哈希),都会被删除
删除是彻底的,不会保留任何与该键相关的信息
01.String(字符串)
a.使用
字符串是 Redis 中最基本的数据结构,可以存储文本、数字、二进制数据等
b.代码
# 设置字符串值并设置过期时间为10秒
SET mykey "Hello, Redis!" EX 10
# 获取字符串值
GET mykey # 返回 "Hello, Redis!",如果在10秒内访问
# 10秒后,mykey 将被自动删除
02.Hash(哈希)
a.使用
哈希用于存储键值对集合,类似于一个小型的键值数据库,适合存储对象的属性
b.代码
# 设置哈希字段和值
HSET myhash field1 "value1"
HSET myhash field2 "value2"
# 设置哈希的过期时间为10秒
EXPIRE myhash 10
# 获取哈希字段的值
HGET myhash field1 # 返回 "value1",如果在10秒内访问
# 10秒后,myhash 将被自动删除
03.List(列表)
a.使用
列表是一个有序的字符串列表,支持从两端进行插入和删除操作
b.代码
# 从列表左侧插入元素
LPUSH mylist "element1"
LPUSH mylist "element2"
# 设置列表的过期时间为10秒
EXPIRE mylist 10
# 获取列表中的所有元素
LRANGE mylist 0 -1 # 返回 ["element2", "element1"],如果在10秒内访问
# 10秒后,mylist 将被自动删除
04.Set(集合)
a.使用
集合是一个无序的字符串集合,支持集合运算如并集、交集和差集
b.代码
# 添加元素到集合
SADD myset "member1"
SADD myset "member2"
# 设置集合的过期时间为10秒
EXPIRE myset 10
# 获取集合中的所有元素
SMEMBERS myset # 返回 ["member1", "member2"],如果在10秒内访问
# 10秒后,myset 将被自动删除
05.ZSet(有序集合)
a.使用
有序集合类似于集合,但每个元素都有一个关联的分值(score),元素按分值排序
b.代码
# 添加元素到有序集合并设置分值
ZADD myzset 1 "member1"
ZADD myzset 2 "member2"
# 设置有序集合的过期时间为10秒
EXPIRE myzset 10
# 获取有序集合中的所有元素
ZRANGE myzset 0 -1 # 返回 ["member1", "member2"],如果在10秒内访问
# 10秒后,myzset 将被自动删除
2.5 脚本:lua原子性
01.Lua脚本
a.定义
Redis的Lua脚本功能允许用户在 Redis 服务器上执行复杂的操作
通过使用 Lua 脚本,用户可以将多个 Redis 命令组合成一个原子操作,从而提高性能并确保数据一致性
b.原理
原子性:Lua 脚本在 Redis 中是原子执行的,这意味着在脚本执行期间不会有其他命令插入
性能:通过减少客户端与服务器之间的通信次数,Lua 脚本可以提高操作的性能
灵活性:Lua 脚本可以执行复杂的逻辑,支持条件判断、循环等编程结构
c.常用API
EVAL script numkeys key [key ...] arg [arg ...]:执行 Lua 脚本
EVALSHA sha1 numkeys key [key ...] arg [arg ...]:通过脚本的 SHA1 校验和执行 Lua 脚本
SCRIPT LOAD script:将脚本加载到缓存中并返回其 SHA1 校验和
SCRIPT FLUSH:清空脚本缓存。
d.使用步骤
1.编写 Lua 脚本:编写需要执行的 Lua 脚本
2.执行脚本:使用 EVAL 命令执行脚本,传递键和参数
3.使用脚本缓存:通过 SCRIPT LOAD 将脚本加载到缓存中,使用 EVALSHA 执行缓存中的脚本
02.Lua语法
a.变量和数据类型
Lua 是动态类型语言,变量不需要事先声明类型。常用的数据类型包括
nil:表示无效值
boolean:包含两个值:true 和 false
number:表示数字,Lua 的数字类型一般是双精度浮点数
string:字符串,使用双引号或单引号定义
table:Lua 中唯一的数据结构,类似于 Python 的字典或 JavaScript 的对象
function:函数在 Lua 中是一等公民
-----------------------------------------------------------------------------------------------------
-- 变量示例
local name = "Lua"
local version = 5.4
local isAwesome = true
b.控制结构
Lua 提供了常用的控制结构,如条件语句和循环
-----------------------------------------------------------------------------------------------------
-- if 语句
local score = 85
if score >= 90 then
print("优秀")
elseif score >= 75 then
print("良好")
else
print("及格")
end
-----------------------------------------------------------------------------------------------------
-- while 循环
local count = 1
while count <= 5 do
print("Count:", count)
count = count + 1
end
-----------------------------------------------------------------------------------------------------
-- for 循环
for i = 1, 5 do
print("Iteration:", i)
end
c.函数
Lua 中的函数是头等公民,可以赋值给变量,也可作为参数传递
-----------------------------------------------------------------------------------------------------
-- 定义函数
local function add(x, y)
return x + y
end
-- 调用函数
print(add(3, 4))
-- 匿名函数
local subtract = function(x, y)
return x - y
end
print(subtract(10, 5))
d.表 (Table)
表可以用来表示数组、字典、集合等多种数据结构,灵活性极高
-----------------------------------------------------------------------------------------------------
-- 数组示例
local fruits = {"apple", "banana", "orange"}
for i, fruit in ipairs(fruits) do
print("Fruit:", fruit)
end
-- 字典示例
local capitals = {
China = "Beijing",
Japan = "Tokyo",
USA = "Washington D.C."
}
print("Capital of China:", capitals["China"])
e.元表与元方法
元表允许你改变 Lua 中操作 table 的默认行为,例如可以用来实现运算符重载
-----------------------------------------------------------------------------------------------------
local mt = {
__add = function(t1, t2)
local result = {}
for k, v in pairs(t1) do
result[k] = v + t2[k]
end
return result
end
}
local vector1 = {x = 1, y = 2}
local vector2 = {x = 3, y = 4}
setmetatable(vector1, mt)
local vector3 = vector1 + vector2
print("Vector3:", vector3.x, vector3.y)
03.场景及代码示例
a.场景1:原子性递增操作
a.说明
将多个递增操作合并为一个原子操作
b.Lua脚本
local current = redis.call('GET', KEYS[1])
if not current then
current = 0
end
local new_value = current + tonumber(ARGV[1])
redis.call('SET', KEYS[1], new_value)
return new_value
c.执行脚本
EVAL "local current = redis.call('GET', KEYS[1]) if not current then current = 0 end local new_value = current + tonumber(ARGV[1]) redis.call('SET', KEYS[1], new_value) return new_value" 1 mycounter 5
b.场景2:检查并设置值
a.说明
如果键不存在,则设置值
b.Lua脚本
if redis.call('EXISTS', KEYS[1]) == 0 then
redis.call('SET', KEYS[1], ARGV[1])
return true
else
return false
end
c.执行脚本
EVAL "if redis.call('EXISTS', KEYS[1]) == 0 then redis.call('SET', KEYS[1], ARGV[1]) return true else return false end" 1 mykey "myvalue"
c.场景3:批量删除键
a.说明
删除多个键
b.Lua脚本
for i, key in ipairs(KEYS) do
redis.call('DEL', key)
end
return #KEYS
c.执行脚本
EVAL "for i, key in ipairs(KEYS) do redis.call('DEL', key) end return #KEYS" 3 key1 key2 key3
2.6 区别:set、zset
00.汇总
a.排序
set:无序
zset:有序,元素按分值排序
b.用途
set:用于存储唯一元素的集合
zset:用于需要排序的场景,比如排行榜、优先级队列等
c.元素
set:不可重复的,一个集合最多能存储232-1个元素,支持对多个集合取交集、并集、差集
zset:不可重复的,不能包含相同的元素,但是不同元素的分数可以相同
01.Set(集合)
a.无序性
set 是一个无序集合,元素没有顺序
b.唯一性
集合中的每个元素都是唯一的,不能有重复元素
c.操作
sadd:添加一个或多个元素到集合中
srem:移除集合中的一个或多个元素
smembers:返回集合中的所有元素
sismember:检查指定元素是否在集合中
scard:返回集合中元素的数量
sunion/sinter/sdiff:集合的并集、交集和差集操作
02.ZSet(有序集合)
a.有序性
zset 是一个有序集合,每个元素都有一个关联的分值(score),元素按分值排序
b.唯一性
元素的唯一性由成员值决定,但可以有相同的分值
c.操作
zadd:添加元素到有序集合中,并设置分值
zrange:按分值范围返回有序集合中的元素
zscore:返回指定元素的分值
zrem:移除有序集合中的一个或多个元素
zrank:返回指定元素在有序集合中的排名
zcount:返回指定分值范围内的元素数量
zincrby:对指定元素的分值进行增量操作
2.7 区别:pipeline、mset、mget
01.原子性
a.原生批处理命令
MSET:用于一次性设置多个键值对,确保所有键值对在一个操作中设置
MSET key1 "value1" key2 "value2" key3 "value3"
MGET:用于一次性获取多个键的值,确保所有键的值在一个操作中获取
MGET key1 key2 key3
b.管道(Pipeline):将多个命令打包发送,但每个命令的执行是独立的
MULTI
SET key1 "value1"
SET key2 "value2"
GET key1
GET key2
EXEC
02.灵活性
a.原生批处理命令,MSET 和 MGET仅限于批量设置或获取键值对
MSET key1 "value1" key2 "value2"
MGET key1 key2
b.管道(Pipeline):可以组合多种命令,比如同时进行读写操作
MULTI
SET key1 "value1"
INCR counter
GET key1
GET counter
EXEC
03.适用场景
a.原生批处理命令:适用于一次性处理多个键值对或获取多个键的值的场景
MSET user:1001:name "Alice" user:1002:name "Bob"
MGET user:1001:name user:1002:name
b.Pipeline:更适用于需要一次性处理多个命令的场景
MULTI
SET user:1001:name "Alice"
SET user:1002:name "Bob"
INCR page:views
GET user:1001:name
GET page:views
EXEC
2.8 [1]string:字符串,不允许重复
00.汇总
set 设置指定键的值
get 获取指定键的值
append 在字符串值的末尾追加数据
incr/decr 对字符串值进行递增或递减操作(假定值为整数)
strlen 获取字符串值的长度
01.常用1
select 0 --选择数据库
set name zs --赋值
get name --取值
strlen name --获取长度
getrange name 0 1 --截取字符串
02.常用2
mset k1 v1 k2 v2 --批量赋值
mget k1 k2 k3 --批量取值
03.常用3
set num 10
incr num --自增1
incr num
decr num --自减1
decr num
incrby num 100 --增加100
decrby num 50 --减少50
04.常用4
set mykey hello
exists mykey --返回1或0标识给定key的值是否存在
del mykey --删除key对应的值
type mykey --返回key对应的值的存储类型
05.常用5
set key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]
set key Value [EX秒|PX毫秒] [NX不存在|XX存在]
---------------------------------------------------------------------------------------------------------
set name lisi ex 10 nx --赋值 不存在时创建 存活10秒
set name lisi ex 10 xx --赋值 存在时创建 存活10秒
set name wangwu --赋值 不存在/存在
---------------------------------------------------------------------------------------------------------
set kl vl
pexpire kl 10 --pexpire key milliseconds
set age 20
expire age 5 --expire key seconds
---------------------------------------------------------------------------------------------------------
set grade 100 ex 10 --创建值的时候设置超时时间
ttl grade --TTL命令用来查看key对应的值剩余存活时间
setex address 10 xa --setex 存活10s
ttl address
setnx age 23 --setnx 不存在时创建
06.常用6
set k2 v2
keys * --全部 *
keys k --指定
keys k? --模糊
flushdb --清空当前数据库
flushall --清空全部数据库
2.9 [1]底层:SDS动态字符串
00.底层
SDS(动态字符串):自动扩展和缩减,由长度、空闲空间和字节数组三部分组成
01.概述
存储任意类型的数据,比如文本、数字、图片或者序列化的对象
一个string类型的键最大可以存储512MB的数据
02.SDS有3种编码类型
embstr:占用64Bytes的空间,存储44Bytes的数据
raw:存储大于44Bytes的数据
int:存储整数类型
embstr和raw存储字符串数据,int存储整型数据
03.应用场景
缓存数据,提高访问速度和降低数据库压力
计数器,利用 incr 和 decr 命令实现原子性的加减操作
分布式锁,利用 setnx 命令实现互斥访问
限流,利用 expire 命令实现时间窗口内的访问控制
04.底层原理
a.embstr结构
embstr 结构存储小于等于44个字节的字符串,embstr 每次开辟64个byte的空间
前19个byte用于存储embstr 结构
中间的44个byte存储数据
最后为\0符号
b.raw结构
略
c.embstr和raw的转换
在存储字符串的时候,redis会根据数据的长度判断使用哪种结构
如果长度小于等于44个字节,就会选择embstr 结构
如果长度大于44个byte,就会选择raw结构
05.操作
127.0.0.1:6379> object encoding str
"embstr"
# str赋值44个字节的字符串
127.0.0.1:6379> set str 1234567890123456789012345678901234567890abcd
OK
127.0.0.1:6379> object encoding str
"embstr"
# str2赋值45个字节的字符串
127.0.0.1:6379> set str2 1234567890123456789012345678901234567890abcde
OK
127.0.0.1:6379> object encoding str2
"raw"
127.0.0.1:6379> set num 123
OK
127.0.0.1:6379> object encoding num
"int"
2.10 [1]场景:缓存、计数、共享Session、限速、分布式锁、唯一ID生成
01.缓存功能
a.说明
使用字符串可以快速缓存和读取数据,适合用于存储用户的基本信息、热门商品的详情等
b.使用
SET key value:用于设置缓存数据
GET key:用于获取缓存数据
EXPIRE key seconds:设置缓存的过期时间,以秒为单位
c.示例
SET user:1001:name "Alice"
EXPIRE user:1001:name 3600 # 设置缓存1小时过期
GET user:1001:name # 返回 "Alice"
02.计数
a.说明
字符串可以存储整数值,并通过原子性操作进行递增或递减,适合用于统计网页访问量、投票数等
b.使用
INCR key:将键的整数值递增1
DECR key:将键的整数值递减1
INCRBY key increment:将键的整数值增加指定数值
DECRBY key decrement:将键的整数值减少指定数值
c.示例
INCR page:views # 增加页面访问量
INCRBY votes:article:1001 5 # 增加文章投票数
03.共享Session
a.说明
通过 Redis 的分布式特性,可以在多个服务器之间共享会话数据
b.使用
SET session_id user_data:存储用户会话数据
GET session_id:获取会话数据
EXPIRE session_id seconds:通过设置过期时间来自动清理过期会话
c.示例
SET session:abc123 "{'user_id': 1001, 'username': 'Alice'}"
EXPIRE session:abc123 1800 # 设置会话30分钟过期
GET session:abc123 # 返回会话数据
04.限速
a.说明
可以使用字符串存储用户的操作时间戳或计数器,实现对用户操作的限速控制
通过限制某个操作在一定时间内的次数,可以防止滥用或攻击
b.使用
SET key value PX milliseconds:设置带有过期时间的键值对来限制操作频率
可以结合计数器和时间戳来实现更复杂的限速策略
c.示例
# 假设我们限制用户在一分钟内只能进行一次某操作
SET user:1001:action "1" PX 60000 NX # 设置操作标记,过期时间为60秒
# 检查是否存在
GET user:1001:action # 如果返回 "1",则表示操作在限速时间内
05.分布式锁
a.说明
主要依赖于字符串的原子性操作
b.使用
SETNX 命令:SETNX key value(SET if Not eXists)命令用于在键不存在时设置键的值。如果键已经存在,命令将返回 0;如果键不存在并成功设置,返回 1。这确保了只有一个客户端能够成功设置锁
设置过期时间:使用 EXPIRE key seconds 或者在 Redis 2.6.12 及以上版本中使用 SET key value NX PX milliseconds 来设置锁的过期时间,防止死锁
释放锁:客户端完成任务后,使用 DEL key 释放锁
c.示例
import redis
import time
r = redis.Redis()
def acquire_lock(lock_name, acquire_timeout=10, lock_timeout=10):
end = time.time() + acquire_timeout
while time.time() < end:
if r.set(lock_name, "locked", nx=True, ex=lock_timeout):
return True
time.sleep(0.01) # 等待一段时间后重试
return False
def release_lock(lock_name):
r.delete(lock_name)
# 使用锁
if acquire_lock("my_lock"):
try:
# 执行需要同步的操作
print("Lock acquired, performing operation...")
finally:
release_lock("my_lock")
else:
print("Failed to acquire lock.")
06.唯一ID生成
a.说明
自增操作
b.使用
INCR 命令:INCR key 命令用于将键的整数值递增 1。由于 Redis 的单线程特性,这个操作是原子的,确保每次递增操作都是唯一的
初始值设置:可以使用 SET key value 来设置初始值,通常从 0 或 1 开始
c.示例
import redis
r = redis.Redis()
def generate_unique_id(key="unique_id"):
return r.incr(key)
# 生成唯一ID
unique_id = generate_unique_id()
print(f"Generated unique ID: {unique_id}")
2.11 [2]hash:哈希,不允许重复
00.汇总
hset 设置哈希表中指定字段的值,如果字段不存在,则创建新字段
hget 获取哈希表中指定字段的值
hdel 删除一个或多个字段
hlen 返回哈希表中字段的数量
hkeys 返回哈希表中所有字段的名称
hvals 返回哈希表中所有字段的值
hgetall 返回哈希表中所有字段和对应的值
hexists 检查哈希表中是否存在指定字段
hincrby 对哈希表中指定字段的整数值进行增量操作
hmset 同时设置多个字段的值
hmget 获取多个字段的值
01.常用1
hset p name zs --赋值
hset p name --取值
hmset p name zs age 23 --批量赋值
hmget p name age --批量取值
hkeys p --显示全部key
hvals p --显示全部value
hgetall p --显示全部key+全部value
hdel p name age --删除
02.常用2
hincrby p age 1
hgetall p --显示全部key+全部value
hincrby p age 11 --整数增加11
hincrby p age -11 --整数增加-11
hincrby float p age 1.5 --浮点数增加1.5
hincrby float p age -1.5 --浮点数增加-1.5
2.12 [2]底层:哈希表+压缩列表
00.底层
版本不同,底层实现不同
redis6及之前:使用压缩列表(ziplist)和哈希表(hashtable)组合实现
redis7及之后:使用紧凑列表(listpack)和哈希表(hashtable)组合实现
---------------------------------------------------------------------------------------------------------
hashtable(哈希表):当哈希表的元素数量较多或元素较大时,Redis使用哈希表来存储键值对,哈希表允许快速的查找、插入和删除操作
ziplist(压缩列表):当哈希表的元素数量较少且每个元素较小时,Redis使用压缩列表来节省内存,压缩列表是一种特殊编码的序列,适用于小型数据集
01.概述
hash是一个键值对集合,它可以存储多个字段和值,类似于编程语言中的map对象
一个hash类型的键最多可以存储 2^32 - 1个字段
02.底层实现有三种
ziplist:压缩列表,当hash达到一定的阈值时,会自动转换为hashtable结构
listpack:紧凑列表,在Redis7.0之后,listpack正式取代ziplist。同样的,当hash达到一定的阈值时,会自动转换为hashtable结构
hashtable:哈希表,类似map
03.应用场景
用户信息,利用 hset 和 hget 命令实现对象属性的增删改查
购物车,利用 hincrby 命令实现商品数量的增减
配置信息,利用 hmset 和 hmget 命令实现批量设置和获取配置项
04.底层原理
a.总结
a.Redis在存储hash结构的数据,为了达到内存和性能的平衡,也针对少量存储和大量存储分别设计了两种结构,分别为
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)
hashTable
b.从ziplist/listpack编码转换为hashTable编码是通过判断元素数量或单个元素Key或Value的长度决定的
hash-max-ziplist-entries:表示当hash中的元素数量小于或等于该值时,使用ziplist编码,否则使用hashtable编码。ziplist是一种压缩列表,它可以节省内存空间,但是访问速度较慢。hashtable是一种哈希表,它可以提高访问速度,但是占用内存空间较多。默认值为512
hash-max-ziplist-value:表示当 hash中的每个元素的 key 和 value 的长度都小于或等于该值时,使用 ziplist编码,否则使用 hashtable编码。默认值为 64
b.ziplist与listpack
a.总结
ziplist/listpack都是hash结构用来存储少量数据的结构。从Redis7.0后,hash默认使用listpack结构。
因为 ziplist有一个致命的缺陷,就是连锁更新,当一个节点的长度发生变化时,可能会导致后续所有节点的长度字段都要重新编码,这会造成极差的性能
b.ziplist结构
ziplist是一种紧凑的链表结构,它将所有的字段和值顺序地存储在一块连续的内存中。
-------------------------------------------------------------------------------------------------
Redis中ziplist源码
typedef struct {
/* 当使用字符串时,slen表示为字符串长度 */
unsigned char *sval;
unsigned int slen;
/* 当使用整形时,sval为NULL,lval为ziplistEntry的value */
long long lval;
} ziplistEntry;
c.listpack结构
略
d.zipList的连锁更新问题
ziplist的每个entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个byte:
- 如果前一节点的长度小于254个byte,则采用1个byte来保存这个长度值
- 如果前一节点的长度大于等于254个byte,则采用5个byte来保存这个长度值,第一个byte为0xfe,后四个byte才是真实长度数据
假设,现有有N个连续、长度为250~253个byte的entry,因此entry的previous_entry_length属性占用1个btye
当第一节长度大于等于254个bytes,导致第二节previous_entry_length变为5个bytes,第二节的长度由250变为254。
而第二节长度的增加必然会影响第三节的previous_entry_length。
ziplist这种特殊套娃的情况下产生的连续多次空间扩展操作成为连锁更新。新增、删除都可能导致连锁更新的产生。
e.listpack是如何解决的
由于ziplist需要倒着遍历,所以需要用previous_entry_length记录前一个entry的长度。而listpack可以通过total_bytes和end计算出来。所以previous_entry_length不需要了。
listpack 的设计彻底消灭了 ziplist 存在的级联更新行为,元素与元素之间完全独立,不会因为一个元素的长度变长就导致后续的元素内容会受到影响。
与ziplist做对比的话,牺牲了内存使用率,避免了连锁更新的情况。从代码复杂度上看,listpack相对ziplist简单很多,再把增删改统一做处理,从listpack的代码实现上看,极简且高效。
c.hashTable
a.总结
hashTable是一种散列表结构,它将字段和值分别存储在两个数组中,并通过哈希函数计算字段在数组中的索引
b.Redis中hashTable源码
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* 当进行rehash时,rehashidx为-1 */
int16_t pauserehash; /* 如果rehash暂停,pauserehash则大于0,(小于0表示代码错误)*/
signed char ht_size_exp[2]; /* 哈希桶的个数(size = 1<<exp) */
};
typedef struct dict {
dictEntry **table;
dictType *type;
unsigned long size;
unsigned long sizemask;
unsigned long used;
void *privdata;
} dict;
typedef struct dictEntry {
void *key;
void *val;
struct dictEntry *next;
} dictEntry;
d.ziplist和hashTable的转换
a.操作
127.0.0.1:6379> hset h1 id 123456789012345678901234567890123456789012345678901234567890abcd
(integer) 1
127.0.0.1:6379> object encoding h1
"ziplist"
127.0.0.1:6379> hset h2 id 123456789012345678901234567890123456789012345678901234567890abcde
(integer) 1
127.0.0.1:6379> object encoding h2
"hashtable"
b.ziplist的废弃
显然是ziplist在field个数太大、key太长、value太长三者有其一的时候会有以下问题:
1.ziplist每次插入都有开辟空间,连续的
2.查询的时候,需要从头开始计算,查询速度变慢
e.hashTable变得越来越长怎么办
a.rehash步骤
扩展哈希和收缩哈希都是通过执行rehash来完成,这其中就涉及到了空间的分配和释放,主要经过以下五步:
为字典dict的ht[1]哈希表分配空间,其大小取决于当前哈希表已保存节点数(即:ht[0].used):
如果是扩展操作则ht[1]的大小为2的n次方中第一个大于等于ht[0].used * 2属性的值(比如used=3,此时ht[0].used * 2=6,故2的3次方为8就是第一个大于used * 2的值(2 的 2 次方 6))。
如果是收缩操作则ht[1]大小为 2 的 n 次方中第一个大于等于ht[0].used的值
将字典中的属性rehashidx的值设置为0,表示正在执行rehash操作
将ht[0]中所有的键值对依次重新计算哈希值,并放到ht[1]数组对应位置,每完成一个键值对的rehash之后rehashidx的值需要自增1
当ht[0]中所有的键值对都迁移到ht[1]之后,释放ht[0],并将ht[1]修改为ht[0],然后再创建一个新的ht[1]数组,为下一次rehash做准备
将字典中的属性rehashidx设置为-1,表示此次rehash操作结束,等待下一次rehash
b.渐进式rehash
Redis中的这种重新哈希的操作因为不是一次性全部rehash,而是分多次来慢慢的将ht[0]中的键值对rehash到ht[1],故而这种操作也称之为渐进式rehash。渐进式rehash可以避免集中式rehash带来的庞大计算量,是一种分而治之的思想。
在渐进式rehash过程中,因为还可能会有新的键值对存进来,此时Redis的做法是新添加的键值对统一放入ht[1]中,这样就确保了ht[0]键值对的数量只会减少。
当正在执行rehash操作时,如果服务器收到来自客户端的命令请求操作,则会先查询ht[0],查找不到结果再到ht[1]中查询
2.13 [2]冲突:链地址法
01.Redis遇到哈希冲突怎么办?
a.解决
当多个键被分配到哈希表数组的同一个索引时,发生哈希冲突,Redis使用链地址法(separate chaining)解决冲突
b.链地址法
每个哈希表节点有一个 next 指针,多个节点可以通过 next 指针构成一个单向链表
被分配到同一个索引的多个节点通过链表连接,解决冲突
2.14 [2]扩容:当元素数量大于当前哈希表大小的负载因子(默认 1)
01.底层
字典结构,底层为哈希表
02.动态扩容
a.触发扩容
当字典中的元素数量超过当前哈希表大小的负载因子(默认 1)时,触发扩容操作
负载因子是指哈希表中元素的数量与哈希表大小的比值
b.创建新哈希表
创建一个新的、更大的哈希表,新的哈希表大小通常是当前哈希表大小的两倍
c.渐进式rehash
Redis采用渐进式rehash(rehashing)机制,将旧哈希表中的元素逐步迁移到新哈希表中
渐进式rehash的目的是避免一次性迁移大量数据导致的性能问题
d.rehash过程
在渐进式rehash过程中,Redis会在每次对字典进行增删改查操作时,顺便将旧哈希表中的一部分元素迁移到新哈希表中
具体来说,每次操作会迁移一个或多个桶(bucket)中的所有元素,直到所有元素都迁移完成
e.完成扩容
当所有元素都迁移完成后,Redis将旧哈希表释放,并将新哈希表设置为当前哈希表
03.Redis会根据负载因子决定是否进行扩容或缩容
a.负载因子
计算公式为 负载因子 = 哈希表已保存节点的数量 / 哈希表的大小
b.扩容条件
负载因子 ≥ 1:如果没有执行 RDB 快照或 AOF 重写,则进行 rehash
负载因子 ≥ 5:无论是否执行持久化操作,都会强制进行 rehash
c.缩容条件
负载因子 < 0.1:进行缩容操作
2.15 [2]缩容:当元素数量小于当前哈希表大小的10%
01.底层
字典结构,底层为哈希表
02.动态缩容
a.触发缩容
当字典中的元素数量小于当前哈希表大小的10%时,触发缩容操作
例如,如果当前哈希表大小为100,元素数量小于10时,触发缩容
b.创建新哈希表
创建一个新的、更小的哈希表,新的哈希表大小通常是当前哈希表大小的一半
c.渐进式rehash
Redis采用渐进式rehash机制,将旧哈希表中的元素逐步迁移到新哈希表中
渐进式rehash的目的是避免一次性迁移大量数据导致的性能问题
d.rehash过程
在渐进式rehash过程中,Redis会在每次对字典进行增删改查操作时,顺便将旧哈希表中的一部分元素迁移到新哈希表中
具体来说,每次操作会迁移一个或多个桶中的所有元素,直到所有元素都迁移完成
e.完成缩容
当所有元素都迁移完成后,Redis将旧哈希表释放,并将新哈希表设置为当前哈希表
03.Redis会根据负载因子决定是否进行扩容或缩容
a.负载因子
计算公式为 负载因子 = 哈希表已保存节点的数量 / 哈希表的大小
b.扩容条件
负载因子 ≥ 1:如果没有执行 RDB 快照或 AOF 重写,则进行 rehash
负载因子 ≥ 5:无论是否执行持久化操作,都会强制进行 rehash
c.缩容条件
负载因子 < 0.1:进行缩容操作
2.16 [2]场景:缓存用户信息、缓存对象、用户会话管理、商品库存管理、配置管理、购物车、文章属性存储、统计信息、任务队列
01.缓存用户信息
a.说明
哈希(Hash)结构适合用于存储和缓存用户的详细信息,因为它可以将多个字段和对应的值存储在一个键下
这种方式使得访问和更新特定字段变得更加高效,适合用于存储用户的属性信息,如用户名、邮箱、年龄等
b.使用
HSET key field value:设置哈希表中指定字段的值
HGET key field:获取哈希表中指定字段的值
HDEL key field:删除哈希表中指定字段
HEXPIRE key seconds:设置哈希表的过期时间,以秒为单位(需要通过设置整个哈希的过期时间)
c.示例
HSET user:1001 name "Alice"
HSET user:1001 email "[email protected] "
HSET user:1001 age "30"
EXPIRE user:1001 3600 # 设置缓存1小时过期
HGET user:1001 name # 返回 "Alice"
HGET user:1001 email # 返回 "[email protected] "
02.缓存对象
a.说明
哈希结构也非常适合用于缓存对象的属性和状态
通过将对象的各个属性存储为哈希表的字段,可以方便地进行属性的增删改查操作
b.使用
HMSET key field1 value1 [field2 value2 ...]:同时设置多个字段的值
HGETALL key:获取哈希表中所有字段和值
HINCRBY key field increment:对哈希表中指定字段的整数值进行增量操作
c.示例
HMSET product:2001 name "Laptop" price "1500" stock "30"
EXPIRE product:2001 7200 # 设置缓存2小时过期
HGETALL product:2001
# 返回 {"name": "Laptop", "price": "1500", "stock": "30"}
HINCRBY product:2001 stock -1 # 减少库存
HGET product:2001 stock # 返回 "29"
03.用户会话管理
a.说明
哈希结构可以用于存储用户会话信息,包括登录状态、最后活动时间等。通过设置过期时间,可以自动清理过期会话
b.示例
HSET session:abc123 user_id "1001"
HSET session:abc123 login_time "2023-01-01T12:00:00Z"
EXPIRE session:abc123 3600 # 设置会话1小时过期
HGET session:abc123 user_id # 返回 "1001"
04.商品库存管理
a.说明
哈希结构可以用于存储商品的库存信息,包括商品名称、价格、库存数量等。可以方便地进行库存的增减操作
b.示例
HSET product:2001 name "Laptop"
HSET product:2001 price "1500"
HSET product:2001 stock "30"
HINCRBY product:2001 stock -1 # 减少库存
HGET product:2001 stock # 返回 "29"
05.配置管理
a.说明
哈希结构可以用于存储应用程序的配置参数,支持动态更新配置。每个配置项作为哈希表的一个字段
b.示例
HSET config:app timeout "30"
HSET config:app max_connections "100"
HGET config:app timeout # 返回 "30"
HGET config:app max_connections # 返回 "100"
06.购物车
a.说明
哈希结构可以用于实现购物车功能,每个用户的购物车作为一个哈希表,商品ID作为字段,数量作为值
b.示例
HSET cart:1001 product:2001 2 # 用户1001的购物车中,商品2001的数量为2
HSET cart:1001 product:2002 1 # 用户1001的购物车中,商品2002的数量为1
HINCRBY cart:1001 product:2001 1 # 增加商品2001的数量
HGET cart:1001 product:2001 # 返回 "3"
07.文章属性存储
a.说明
哈希结构可以用于存储文章的属性信息,包括标题、作者、发布时间等
b.示例
HSET article:3001 title "Redis in Action"
HSET article:3001 author "John Doe"
HSET article:3001 published_date "2023-01-01"
HGET article:3001 title # 返回 "Redis in Action"
HGET article:3001 author # 返回 "John Doe"
08.统计信息
a.说明
哈希结构可以用于存储各种统计信息,如网站访问量、用户行为统计等
b.示例
HINCRBY stats:page_views home 1 # 增加首页访问量
HINCRBY stats:page_views about 1 # 增加关于页面访问量
HGET stats:page_views home # 返回首页访问量
HGET stats:page_views about # 返回关于页面访问量
09.任务队列
a.说明
哈希结构可以用于存储任务队列中的任务信息,包括任务ID、状态、创建时间等
b.示例
HSET task:4001 status "pending"
HSET task:4001 created_at "2023-01-01T12:00:00Z"
HGET task:4001 status # 返回 "pending"
HSET task:4001 status "completed" # 更新任务状态
2.17 [2]场景:验证码(先存后发)、高频数据
00.对比
String字符串:适用于简单场景,验证码较短且安全性要求不高
Hash哈希:适用于需要存储额外信息的场景,特别是在高并发或长期存储时
01.验证码(先存后发)
a.定义
使用 Redis Hash 存储验证码及其相关信息,如生成时间和验证码类型
b.原理
通过哈希结构将验证码及附加信息结构化地存储在一个键下,便于管理和检索
c.常用API
HSET:设置哈希表中的字段值
HGET:获取哈希表中的字段值
d.使用步骤
选择哈希键:选择一个合适的键来存储哈希数据,例如 captcha:user123
定义字段:在哈希中定义存储验证码及附加信息的字段,例如 code、created_at、type
存储数据:使用 HSET 命令将验证码及其相关信息存储到 Redis 哈希中
e.场景示例
# 存储验证码及附加信息
HSET captcha:user123 code 4567
HSET captcha:user123 created_at 1687995600
HSET captcha:user123 type "email_verification"
# 获取验证码
HGET captcha:user123 code
f.基本流程
1.前端:访问登录页面
2.后端:第1步,生成【key】+【code】,并将该kv键值存到redis,【code经base64输出codeBase64 Image】
第2步,发送【key】、【codeBase64 Image】
3.前端:发送【用户名】、【密码】、【key】、【codelnput】
4.后端:用【key】获取【code】,然后【code比较codelnput】
5.前端:将【比较结果】进行显示,【验证码不正确/正确】
g.示例代码
import redis
import base64
from datetime import datetime
# 连接 Redis
r = redis.Redis()
# 后端生成验证码
def generate_captcha(user_id):
code = "4567" # 生成验证码
key = f"captcha:{user_id}"
created_at = int(datetime.now().timestamp())
type = "email_verification"
# 存储验证码及附加信息
r.hset(key, mapping={"code": code, "created_at": created_at, "type": type})
# 生成验证码图像并转换为 Base64
code_image = base64.b64encode(code.encode()).decode()
return key, code_image
# 后端验证验证码
def verify_captcha(user_id, input_code):
key = f"captcha:{user_id}"
stored_code = r.hget(key, "code").decode()
if stored_code == input_code:
return "验证码正确"
else:
return "验证码不正确"
# 示例使用
user_id = "user123"
key, code_image = generate_captcha(user_id)
print(f"Key: {key}, Code Image: {code_image}")
result = verify_captcha(user_id, "4567")
print(result)
02.高频数据
a.定义
Banner:包含多个字段,如标题、图片 URL、链接
首页通告:通常按时间顺序排列
菜单结构:通常具有层级和多个字段
公司组织:通常是一个复杂的树状结构,可能需要存储大量的嵌套数据
b.原理
字符串:适用于结构固定且不复杂的组织架构,使用 JSON 格式存储
哈希:适用于需要存储多个字段且经常访问部分字段的场景
c.常用API
SET:存储字符串
HSET:存储哈希字段
d.示例代码
import redis.clients.jedis.Jedis;
public class RedisHashExample {
private static Jedis jedis = new Jedis("localhost");
public static void main(String[] args) {
// 公司组织架构
jedis.hset("organization:dept:1", "name", "HR");
jedis.hset("organization:dept:1", "manager", "John Doe");
// 首页通告
jedis.hset("notice:1", "title", "System Maintenance");
jedis.hset("notice:1", "date", "2023-10-01");
// 菜单结构数据
jedis.hset("menu:main", "home", "/home");
jedis.hset("menu:main", "about", "/about");
// Banner
jedis.hset("banner:1", "title", "Summer Sale");
jedis.hset("banner:1", "image", "summer_sale.jpg");
jedis.hset("banner:1", "link", "http://example.com/summer_sale");
// 示例:获取数据
System.out.println("Organization HR Manager: " + jedis.hget("organization:dept:1", "manager"));
System.out.println("Notice Title: " + jedis.hget("notice:1", "title"));
System.out.println("Menu Home Link: " + jedis.hget("menu:main", "home"));
System.out.println("Banner Title: " + jedis.hget("banner:1", "title"));
}
}
2.18 [3]list:列表,允许重复
00.汇总
lpush/rpush 从列表的左侧/右侧添加数据
lrange 指定索引范围,并返回这个范围内的数据
lindex 返回指定索引处的数据
lpop/rpop 从列表的左侧/右侧弹出一个数据
blpop/brpop 从列表的左侧/右侧弹出一个数据,若列表为空则进入阻塞状态
01.常用1
lpush names zs ls ww --lpush 左
rpush names zhangsan lisi wangwu --rpush 左
lrange names 0 -1 --范围:全部
lrange names 0 3 --范围:0~3
rpop names --rpop
lpop names --lpop
02.常用2
ltrim names 0 2 --截取范围:0~2
lrange names 0 -1
03.常用3
lset names 1 QQ --修改索引为1
lrange names 0 -1
04.常用4
linsert names before QQ ww --在QQ左侧插入WW
lrange names 0 -1
linsert names before QQ PP --在QQ右侧插入WW
lrange names 0 -1
2.19 [3]底层:双端链表+压缩列表、快速列表
00.底层
版本不同,底层实现不同
在Redis3.2之前,list使用的是linkedlist(双端链表)和ziplist(压缩列表)
在Redis3.2~Redis7.0之间,list使用的是quickList(快速列表),是linkedlist和ziplist的结合
在Redis7.0之后,list使用的也是quickList,只不过将ziplist转为listpack,它是listpack、linkedlist结合版
---------------------------------------------------------------------------------------------------------
linkedlist(双端链表):当列表元素较多或元素较大时,Redis使用双端链表来实现,这种结构允许快速的头部和尾部插入删除操作
ziplist(压缩列表):当列表元素较少且每个元素较小时,Redis使用压缩列表来节省内存
01.概述
list 是一个有序的字符串列表,它按照插入顺序排序,并且支持在两端插入或删除元素
一个 list 类型的键最多可以存储 2^32 - 1 个元素
02.应用场景
消息队列:利用 lpush 和 rpop 命令实现生产者消费者模式
最新消息:利用 lpush 和 ltrim 命令实现固定长度的时间线
历史记录:利用 lpush 和 lrange 命令实现浏览记录或者搜索记录
03.底层原理
a.linkedlist与ziplist
在Redis3.2之前,linkedlist和ziplist两种编码可以选择切换,它们之间的转换关系如图
同样地,ziplist转为linkedlist的条件可在redis.conf配置
list-max-ziplist-entries 512
list-max-ziplist-value 64
b.quickList(ziplist、linkedlist结合版)
quicklist存储了一个双向列表,每个列表的节点是一个ziplist,
所以实际上quicklist并不是一个新的数据结构,它就是linkedlist和ziplist的结合,然后被命名为快速列表。
-----------------------------------------------------------------------------------------------------
ziplist内部entry个数可在redis.conf配置
list-max-ziplist-size -2
# -5: 每个ziplist最多为 64 kb <-- 影响正常负载,不推荐
# -4: 每个ziplist最多为 32 Kb <-- 不推荐
# -3: 每个ziplist最多为 16 Kb <-- 最好不要使用
# -2: 每个ziplist最多为 8 Kb <-- 好
# -1: 每个ziplist最多为 4 Kb <-- 好
# 正数为ziplist内部entry个数
-----------------------------------------------------------------------------------------------------
ziplist通过特定的LZF压缩算法来将节点进行压缩存储,从而更进一步的节省空间,
而很多场景都是两端元素访问率最高,我们可以通过配置list-compress-depth来排除首尾两端不压缩的entry个数。
list-compress-depth 0
# - 0:不压缩(默认值)
# - 1:首尾第 1 个元素不压缩
# - 2:首位前 2 个元素不压缩
# - 3:首尾前 3 个元素不压缩
# - 以此类推
c.listList(listpack、linkedlist结合版)
和Hash结构一样,因为ziplist有连锁更新问题,redis7.0将ziplist替换为listpack,下面是新quickList的结构图
-----------------------------------------------------------------------------------------------------
Redis中listpack源码
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* 所有列表包中所有条目的总数,占用16 bits,最大65536 */
unsigned long len; /* quicklistNode 的数量 */
signed int fill : QL_FILL_BITS; /* 单个节点的填充因子 */
unsigned int compress : QL_COMP_BITS; /* 不压缩的端节点深度;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
-----------------------------------------------------------------------------------------------------
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* 当前entry占用字节 */
unsigned int count : 16; /* listpack元素个数,最大65535 */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* 当前listpack是否需要再次压缩 */
unsigned int attempted_compress : 1; /* 测试用 */
unsigned int extra : 10; /* 备用 */
} quicklistNode;
-----------------------------------------------------------------------------------------------------
listpack内部entry个数可在redis.conf配置
List-Max-listpack-size -2
# -5: 每个listpack最多为 64 kb <-- 影响正常负载,不推荐
# -4: 每个listpack最多为 32 Kb <-- 不推荐
# -3: 每个listpack最多为 16 Kb <-- 最好不要使用
# -2: 每个listpack最多为 8 Kb <-- 好
# -1: 每个listpack最多为 4 Kb <-- 好
# 正数为listpack内部entry个数
2.20 [3]场景:队列、栈、任务调度、日志存储、分页数据
01.队列
a.定义
先进先出
b.使用
插入元素:使用 LPUSH 命令将元素插入到列表的头部
移除元素:使用 RPOP 命令从列表的尾部移除元素
c.应用场景
任务队列:将任务按顺序放入队列中,消费者从队列中取出任务进行处理
消息队列:生产者将消息放入队列,消费者从队列中取出消息进行处理
日志收集:将日志信息按时间顺序放入队列,便于后续分析和处理
d.示例
# 插入元素到队列
LPUSH myQueue "element1"
LPUSH myQueue "element2"
# 从队列移除元素
RPOP myQueue # 返回 "element1"
02.栈
a.定义
后进先出
b.使用
插入元素:使用 LPUSH 命令将元素插入到列表的头部
移除元素:使用 LPOP 命令从列表的头部移除元素
c.应用场景
浏览器历史记录:用户访问的页面按顺序入栈,用户点击“后退”时从栈中弹出页面。
递归计算:在递归算法中使用栈来保存中间状态,便于回溯。
撤销操作:在文本编辑器等应用中,用户的操作按顺序入栈,用户点击“撤销”时从栈中弹出操作。
d.示例
# 插入元素到栈
LPUSH myStack "element1"
LPUSH myStack "element2"
# 从栈移除元素
LPOP myStack # 返回 "element2"
03.任务调度
a.说明
列表可以用于存储待处理的任务,支持按顺序处理任务
可以将任务以字符串形式存储在列表中,使用 LPUSH 添加任务,使用 RPOP 取出任务进行处理
b.使用
LPUSH key value:将任务添加到列表
RPOP key:从列表中取出任务进行处理
c.示例
LPUSH task_queue "task1"
LPUSH task_queue "task2"
RPOP task_queue # 返回 "task1"
04.日志存储
a.说明
列表可以用于存储日志信息,支持按时间顺序记录日志
可以使用 RPUSH 将日志信息添加到列表末尾,使用 LRANGE 获取日志信息
b.使用
RPUSH key value:将日志信息添加到列表末尾
LRANGE key start stop:获取指定范围内的日志信息
c.示例
RPUSH log_list "log entry 1"
RPUSH log_list "log entry 2"
LRANGE log_list 0 -1 # 返回 ["log entry 1", "log entry 2"]
05.分页数据
a.说明
列表可以用于存储分页数据,支持按页获取数据
可以使用 LRANGE 命令来实现简单的分页功能,通过指定索引范围来获取列表中的一部分数据
b.使用
LPUSH key value:将数据添加到列表
LRANGE key start stop:获取指定范围内的数据
c.示例
LPUSH data_list "data1"
LPUSH data_list "data2"
LPUSH data_list "data3"
LRANGE data_list 0 1 # 返回 ["data3", "data2"]
2.21 [4]set:无序集合,不允许重复
00.汇总
sadd 添加一个或多个元素到集合中
srem 移除集合中的一个或多个元素
smembers 返回集合中的所有元素
sismember 检查指定元素是否在集合中
scard 返回集合中元素的数量
01.常用1
zadd persons 8 zs 9 ls 10 ww --增加
zrange persons 1 2 --正序查询
zrangep persons 1 2 withscores --正序查询带scores
zrevrange persons 1 2 --逆序查询
02.常用2
zrangebyscore persons 8 9 --根据score正序查询(闭区间)
zrangebyscore persons (8 (10 --根据score正序查询(开区间)
zrangebyscore persons 8 10 withscores limit 1 2 --根据score正序查询(闭区间),从1开始,显示2条
03.常用3
zrem persons ls --移除
zcount persons 8 10 --计数
zrank persons ww --下标
zscore persons ww --查看score
2.22 [4]底层:哈希表+整数集合、哈希表+整数集合+列表包
00.底层
版本不同,底层实现不同
在Redis7.2之前,set使用的是hashtable(哈希表)、intset(整数集合)
在Redis7.2之后,set使用的是hashtable(哈希表)、intset(整数集合)、istpack(列表包)
---------------------------------------------------------------------------------------------------------
hashtable(哈希表):当集合中的元素较多或较大时,Redis 使用哈希表来存储集合元素
intset(整数集合):当集合中的元素都是整数且数量较少时,Redis 使用整数集合来节省内存
01.概述
set是一个无序的字符串集合,它不允许重复的元素,一个set类型的键最多可以存储2^32 - 1个元素
02.底层实现有两种
a.intset
整数集合
b.hashtable(哈希表)
哈希表和 hash 类型的哈希表相同,它将元素存储在一个数组中,并通过哈希函数计算元素在数组中的索引
c.自动转换编码方式
Redis 会根据 set 中元素的数量和类型来选择合适的编码方式,当 set 达到一定的阈值时,会自动转换编码方式。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
02.应用场景
去重:利用 sadd 和 scard 命令实现元素的添加和计数
交集:并集,差集,利用 sinter,sunion 和 sdiff 命令实现集合间的运算
随机抽取:利用 srandmember 命令实现随机抽奖或者抽样
03.底层原理
a.intset
intset是一种紧凑的数组结构,它只保存int类型的数据,它将所有的元素按照从小到大的顺序存储在一块连续的内存中。
intset会根据传入的数据大小,encoding分为int16_t、int32_t、int64_t
-----------------------------------------------------------------------------------------------------
127.0.0.1:6379> sadd set 123
(integer) 1
127.0.0.1:6379> object encoding set
"intset"
127.0.0.1:6379> sadd set abcd
(integer) 1
127.0.0.1:6379> object encoding set
"hashtable"
b.intset 和 hashtable 的转换
在Redis7.2之前,当一个集合满足以下两个条件时,Redis 会选择使用intset编码:
集合对象保存的所有元素都是整数值
集合对象保存的元素数量小于等于512个(默认)
-----------------------------------------------------------------------------------------------------
intset最大元素数量可在redis.conf配置
set-max-intset-entries 512
c.为什么加入了listpack
a.总结
在redis7.2之前,sds类型的数据会直接放入到编码结构式为hashtable的set中。其中,sds其实就是redis中的string类型。
而在redis7.2之后,sds类型的数据,首先会使用listpack结构当 set 达到一定的阈值时,才会自动转换为hashtable。
添加listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比较高。
b.hashtable 的空间开销高
hashtable 的空间开销高是因为它需要预先分配一个固定大小的数组来存储键值对,而这个数组的大小通常要大于实际存储的元素个数,以保证较低的装载因子。装载因子是指 hashtable 中已经存储的元素个数和数组大小的比值,它反映了 hashtable 的空间利用率
如果装载因子过高,那么 hashtable 的性能会下降,因为碰撞的概率会增加
如果装载因子过低,那么 hashtable 的空间利用率会下降,因为数组中会有很多空闲的位置
因此,hashtable 需要在装载因子和空间利用率之间做一个平衡,通常装载因子的推荐值是 0.75
c.hashtable 的碰撞概率高
hashtable 的碰撞概率高是因为它使用了一个散列函数来将任意长度的键映射到一个有限范围内的整数,作为数组的索引
散列函数的设计很重要,它应该尽可能地保证不同的键能够均匀地分布在数组中,避免出现某些位置过于拥挤,而其他位置过于稀疏的情况。然而,由于散列函数的输出范围是有限的,而键的取值范围是无限的,所以不可能完全避免两个不同的键被散列到同一个位置上,这就产生了碰撞。碰撞会影响 hashtable 的性能,因为它需要额外的处理方式来解决冲突,比如开放寻址法或者链地址法
举例说明,假设有一个大小为8的hashtable,使用取模运算作为散列函数,即h(k) = k mod 8。现在有四个键:5,13,21,29,它们都被散列到索引1处
-------------------------------------------------------------------------------------------------
这就是一个碰撞的例子,因为四个键都映射到了同一个索引。这种情况可能是由于以下原因造成的:
- 散列函数的选择不合适,没有充分利用hashtable的空间。
- 键的分布不均匀,有些区间的键出现的频率更高。
- hashtable的大小太小,不能容纳所有的键。
为了解决碰撞,redis采用了链地址法。就是在每个索引处维护一个链表,存储所有散列到该索引的键。但是,如果链表过长,查找效率会降低。因此,一般建议保持hashtable的负载因子(即键的数量除以hashtable的大小)在一定范围内,比如0.5到0.75之间。如果负载因子过高或过低,可以通过扩容或缩容来调整hashtable的大小
d.intset 、listpack和hashtable的转换
a.总结
intset 、listpack和hashtable这三者的转换时根据要添加的数据、当前set的编码和阈值决定的。
b.如果要添加的数据是整型,且当前set的编码为intset,如果超过阈值由intset直接转为hashtable
阈值条件为:
set-max-intset-entries ,intset最大元素个数,默认512
c.如果要添加的数据是字符串,分为三种情况
当前set的编码为intset:如果没有超过阈值,转换为listpack;否则,直接转换为hashtable
当前set的编码为listpack:如果超过阈值,就转换为hashtable
当前set的编码为hashtable:直接插入,编码不会进行转换
-------------------------------------------------------------------------------------------------
阈值条件为:
set-max-listpack-entries:最大元素个数,默认128
set_max_listpack_value:最大元素大小,默认64
以上两个条件需要同时满足才能进行编码转换
2.23 [4]场景:标签管理、用户关注、共同好友、黑名单、唯一访问者统计
01.标签管理
a.说明
集合适合用于存储标签(tags),因为每个标签都是唯一的。可以方便地进行标签的添加、删除和查询操作。
b.使用
SADD key member [member ...]:添加一个或多个元素到集合中。
SREM key member [member ...]:从集合中移除一个或多个元素。
SMEMBERS key:返回集合中的所有元素。
c.示例
SADD post:1001:tags "redis" "database" "nosql"
SREM post:1001:tags "nosql"
SMEMBERS post:1001:tags # 返回 ["redis", "database"]
02.用户关注功能
a.说明
集合可以用于实现用户关注功能,存储用户关注的其他用户ID。集合的唯一性确保不会重复关注
b.使用
SADD key member:添加关注的用户ID
SREM key member:取消关注的用户ID
SCARD key:获取关注的用户数量
SISMEMBER key member:检查是否关注某用户
c.示例
SADD user:1001:following 2002 2003
SREM user:1001:following 2003
SCARD user:1001:following # 返回 1
SISMEMBER user:1001:following 2002 # 返回 1(表示已关注)
03.共同好友
a.说明
集合可以用于计算两个用户的共同好友,通过集合的交集操作实现
b.使用
SINTER key [key ...]:返回所有给定集合的交集
c.示例
SADD user:1001:friends 2002 2003 2004
SADD user:1002:friends 2003 2004 2005
SINTER user:1001:friends user:1002:friends # 返回 ["2003", "2004"]
04.黑名单管理
a.说明
集合可以用于存储黑名单用户ID,方便进行快速查询和管理
b.使用
SADD key member:将用户ID添加到黑名单
SREM key member:从黑名单中移除用户ID
SISMEMBER key member:检查用户是否在黑名单中
c.示例
SADD blacklist 3001 3002
SISMEMBER blacklist 3001 # 返回 1(表示在黑名单中)
SREM blacklist 3001
05.唯一访问者统计
a.说明
集合可以用于统计网站的唯一访问者,通过存储访问者的IP地址或用户ID实现
b.使用
SADD key member:添加访问者ID
SCARD key:获取唯一访问者数量
c.示例
SADD unique_visitors "192.168.1.1" "192.168.1.2"
SCARD unique_visitors # 返回 2
2.24 [5]zset:有序集合,不允许重复
00.汇总
zadd 添加元素到有序集合中,并设置分值
zrange 按分值范围返回有序集合中的元素
zscore 返回指定元素的分值
zrem 移除有序集合中的一个或多个元素
zrank 返回指定元素在有序集合中的排名
01.常用1
sadd set h1 h2 h3 --添加
smembers set --查看全部
sismember set h2 --是否存在
srem set h2 --移除
srandmember set 1 --随机获取1个元素(不删除)
spop set 1 --随机获取1个元素(删除)
02.常用2
smove set set2 a2 --smove:将set中的a2元素,移动至set2中
03.常用3
smembers set --查看集合set:a1 a3
smembers set2 --查看集合set2:a1 a2
sdiff set set2 --交集
sinter set set2 --差集
sunion set set2 --并集
2.25 [5]zset:score相同时,成员值中添加时间戳
00.回答
成员值中添加时间戳
01.排序策略
a.字典顺序排序
默认情况下,Redis 会根据成员值的字典顺序进行排序
因此,可以设计成员值以确保字典顺序符合业务需求
例如,可以在成员值中包含时间戳或唯一标识符
b.成员值设计
在成员值中包含额外的信息,如时间戳、用户ID等,以确保在分数相同时能够按照预期顺序排序
例如,使用格式化字符串 "{score}:{timestamp}:{user_id}" 作为成员值
c.业务逻辑调整
在应用层处理分数相同的情况,通过额外的业务逻辑来调整排序结果
例如,优先展示最近更新的内容
02.示例
a.场景
假设我们有两个微博用户的点赞数相同,可以通过在成员值中添加时间戳来确保排序
# 添加微博用户及其点赞数,使用时间戳确保排序
ZADD weibo_rank 100 "user1:20231001" 100 "user2:20231002"
# 获取排名,分数相同情况下按字典顺序排序
ZREVRANGE weibo_rank 0 -1
b.说明
在这个示例中,虽然 user1 和 user2 的分数相同,但由于 user2 的时间戳较大,user2 会排在 user1 之前
2.26 [5]底层:跳表+压缩列表
00.底层
SkipList(跳表):当有序集合的元素数量较多或元素较大时,Redis 使用跳表来实现有序集合
跳表是一种可以在平均 O(log N) 时间内进行插入、删除和查找的概率性数据结构
一个多层索引的链表,每一层索引的元素在最底层的链表中可以找到的元素
Ziplist(压缩列表):当有序集合的元素数量较少且每个元素较小时,Redis 使用压缩列表来节省内存
01.概述
Redis 中的 zset 是一种有序集合类型,它可以存储不重复的字符串元素,并且给每个元素赋予一个排序权重值(score)
Redis 通过权重值来为集合中的元素进行从小到大的排序。zset 的成员是唯一的,但权重值可以重复
一个 zset 类型的键最多可以存储 2^32 - 1 个元素
02.Redis中zset源码
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
03.应用场景
排行榜:利用 zadd 和 zrange 命令实现分数的更新和排名的查询
延时队列:利用 zadd 和 zpopmin 命令实现任务的添加和执行,并且可以定期地获取已经到期的任务
访问统计:可以使用 zset 来存储网站或者文章的访问次数,并且可以按照访问量进行排序和筛选
04.底层原理
a.总结
a.结构
Redis在存储zset结构的数据,为了达到内存和性能的平衡,针对少量存储和大量存储分别设计了两种结构,分别为:
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)
skiplist
b.说明
当 zset 中的元素个数和元素值的长度比较小的时候,Redis 使用ziplist/listpack来节省内存空间。
当 zset 中的元素个数和元素值的长度达到一定阈值时,Redis 会自动将ziplist/listpack转换为skiplist,以提高操作效率
具体来说,当 zset 同时满足以下两个条件时,会使用 listpack作为底层结构:
元素个数小于 zset_max_listpack_entries ,默认值为 128
元素值的长度小于zset_max_listpack_value,默认值为 64
当 zset 中不满足以上两个条件时,会使用 skiplist 作为底层结构。
b.跳表
a.定义
一个多层索引的链表,每一层索引的元素在最底层的链表中可以找到的元素
b.说明
跳跃表是一种随机化的数据结构,实质就是一种可以进行二分查找的有序链表
跳跃表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找
跳跃表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
c.优点
实现简单,易于理解和调试
插入和删除操作只需要修改局部节点的指针,不需要像平衡树那样进行全局调整
可以利用空间换时间,通过增加索引层来提高查找效率
支持快速的范围查询,可以方便地返回指定区间内的所有元素
c.缺点
空间复杂度较高,需要额外存储多级索引
随机性太强,性能不稳定,最坏情况下可能退化成链表
不支持快速的倒序遍历,需要额外的指针来实现
c.跳表实现
a.结构定义
zskiplist:跳表的整体结构,包括头节点、尾节点、节点数和层数。
zskiplistNode:跳表节点,包含值、分值(score)、后向指针(backward)和多个层(level)。
b.节点层(level)定义
每个节点的层数是随机生成的,层中包含指向后续节点的指针(forward)和跨度(span),用于跳跃计算。
c.随机层数生成
插入新节点时,随机决定节点的层数,使用几何分布,节点有 1/2 的概率被分配到下一层,这样大部分节点只在底层,少数节点在高层。
d.基本操作
插入:找到插入位置,更新相关指针和跨度。
删除:找到并移除节点,更新相关指针和跨度。
查找:从高层开始,逐层向下查找目标节点。
d.redis的跳表
skiplist有一个层数上的问题,当层数过多,会影响查询效率。
而Redis 使用了一个随机函数来决定每个节点的层数,这个随机函数的期望值是 1/(1-p) ,
其中 p 是一个概率常数,Redis 中默认为 0.25。这样可以保证跳跃表的平均高度为 log (1/p) n ,
其中 n 是节点数。Redis 还限制了跳跃表的最大层数为 32 ,这样可以避免过高的索引层造成空间浪费
2.27 [5]场景:排行榜、延迟队列、事件调度、投票系统、任务优先级队列
01.排行榜
a.说明
有序集合适合用于实现排行榜功能,因为每个元素都有一个关联的分值(score),可以根据分值对元素进行排序
b.使用
ZADD key score member [score member ...]:添加元素到有序集合中,并设置分值
ZRANGE key start stop [WITHSCORES]:按分值范围返回有序集合中的元素
ZREVRANGE key start stop [WITHSCORES]:按分值从高到低返回有序集合中的元素
c.示例
ZADD leaderboard 100 "Alice"
ZADD leaderboard 200 "Bob"
ZADD leaderboard 150 "Charlie"
ZRANGE leaderboard 0 -1 WITHSCORES # 返回 [("Alice", 100), ("Charlie", 150), ("Bob", 200)]
ZREVRANGE leaderboard 0 -1 WITHSCORES # 返回 [("Bob", 200), ("Charlie", 150), ("Alice", 100)]
02.延迟队列
a.说明
有序集合可以用于实现延迟队列,通过将任务的执行时间作为分值,按时间顺序处理任务
b.使用
ZADD key score member:添加任务到有序集合中,并设置执行时间为分值
ZRANGEBYSCORE key min max:按分值范围返回有序集合中的元素
c.示例
ZADD delay_queue 1633036800 "task1" # 时间戳表示任务执行时间
ZADD delay_queue 1633036900 "task2"
ZRANGEBYSCORE delay_queue 0 1633036850 # 返回 ["task1"]
03.事件调度
a.说明
有序集合可以用于事件调度系统,通过将事件的触发时间作为分值,按时间顺序触发事件
b.使用
ZADD key score member:添加事件到有序集合中,并设置触发时间为分值
ZPOPMIN key [count]:移除并返回有序集合中分值最小的元素
c.示例
ZADD event_scheduler 1633036800 "event1"
ZADD event_scheduler 1633036900 "event2"
ZPOPMIN event_scheduler # 返回 ["event1"]
04.投票系统
a.说明
有序集合可以用于实现投票系统,通过将票数作为分值,按票数对选项进行排序
b.使用
ZINCRBY key increment member:对有序集合中指定成员的分值进行增量操作
ZRANGE key start stop [WITHSCORES]:按分值范围返回有序集合中的元素
c.示例
ZADD poll 0 "option1"
ZADD poll 0 "option2"
ZINCRBY poll 1 "option1" # 给选项1增加一票
ZINCRBY poll 2 "option2" # 给选项2增加两票
ZRANGE poll 0 -1 WITHSCORES # 返回 [("option1", 1), ("option2", 2)]
05.任务优先级队列
a.说明
有序集合可以用于实现任务优先级队列,通过将优先级作为分值,按优先级顺序处理任务
b.使用
ZADD key score member:添加任务到有序集合中,并设置优先级为分值
ZRANGE key start stop [WITHSCORES]:按分值范围返回有序集合中的元素
c.示例
ZADD priority_queue 1 "low_priority_task"
ZADD priority_queue 10 "high_priority_task"
ZRANGE priority_queue 0 -1 # 返回 ["low_priority_task", "high_priority_task"]
2.28 [5]场景:排行榜、本周热议、分值计算
01.排行榜
a.定义
使用ZSet实现一个简单的排行榜系统,通过分数对玩家进行排名
b.原理
使用ZSet的分数排序特性,添加玩家及其分数,获取排名,更新分数
c.常用API
ZADD:添加玩家及其分数
ZREVRANGE:获取排名
ZINCRBY:更新玩家分数
d.使用步骤
1.使用ZADD命令添加玩家及其分数
2.使用ZREVRANGE命令获取排名
3.使用ZINCRBY命令更新玩家分数
e.场景示例
# 添加玩家及其分数
ZADD leaderboard 100 "player1"
ZADD leaderboard 200 "player2"
ZADD leaderboard 150 "player3"
# 获取排名
ZREVRANGE leaderboard 0 -1 WITHSCORES
# 更新玩家分数
ZINCRBY leaderboard 50 "player1"
# 获取某个元素的排名
ZRANK leaderboard "player1"
02.本周热议
a.定义
使用ZSet实现本周热议的文章排行榜,通过评论数量进行排序
b.原理
使用ZSet的分数排序特性,缓存热评文章,评论数量排行
c.常用 API
ZADD:添加文章及其评论数量
ZREVRANGE:展示排行榜
ZUNIONSTORE:并集运算
d.使用步骤
1.项目启动前,获取近7天文章
2.初始化文章的总评论量,使用ZADD
3.对文章做并集运算,使用ZUNIONSTORE
4.根据评论量从大到小展示,使用ZREVRANGE
e.场景示例
# 初始化操作
ZADD weekly_articles 10 "article1"
ZADD weekly_articles 20 "article2"
ZADD weekly_articles 15 "article3"
# 并集运算
ZUNIONSTORE total_comments 2 weekly_articles other_articles
# 展示排行榜
ZREVRANGE total_comments 0 -1 WITHSCORES
03.分值计算:计算前7天内的热点文章
a.定义
通过 Redis 的有序集合(ZSet),可以实现对前7天内的文章进行分值计算和排序,以确定热点文章
分值计算基于文章的阅读、点赞、评论和收藏等指标
b.原理
a.定时任务
每天凌晨执行任务,查询前7天的文章
b.分值计算
根据阅读、点赞、评论和收藏的权重计算每篇文章的分值
c.排序和存储
将计算出的分值用于排序,并将结果存入Redis的ZSet中
c.常用API
a.ZADD
添加元素到有序集合中,并设置分值
b.ZREVRANGE
按分值从高到低获取有序集合中的元素
c.ZREM
删除有序集合中的元素
d.使用步骤
a.定时任务
每天凌晨执行,查询前7天的文章
b.查询文章
从数据库获取过去7天的文章数据
c.计算分值
根据权重计算每篇文章的分值
d.排序和存储
使用 ZADD 将文章及其分值存入 Redis 的 ZSet
e.获取热点文章
使用 ZREVRANGE 获取分值最高的前30篇文章
e.场景示例
import redis
from datetime import datetime, timedelta
# 连接 Redis
r = redis.Redis()
# 定时任务:每天凌晨执行
def daily_task():
# 查询前7天的文章
articles = query_articles_from_db()
# 计算分值并存入 Redis
for article in articles:
score = calculate_score(article)
r.zadd("hot_articles", {article['id']: score})
# 获取分值最高的前30篇文章
top_articles = r.zrevrange("hot_articles", 0, 29, withscores=True)
print("Top 30 Hot Articles:", top_articles)
# 查询数据库中的文章
def query_articles_from_db():
# 模拟数据库查询
return [
{'id': 'article1', 'reads': 100, 'likes': 20, 'comments': 10, 'favorites': 5},
{'id': 'article2', 'reads': 150, 'likes': 30, 'comments': 15, 'favorites': 10},
# 更多文章...
]
# 计算文章分值
def calculate_score(article):
reads_weight = 1
likes_weight = 3
comments_weight = 5
favorites_weight = 8
score = (article['reads'] * reads_weight +
article['likes'] * likes_weight +
article['comments'] * comments_weight +
article['favorites'] * favorites_weight)
return score
# 执行定时任务
daily_task()
f.说明
a.定时任务
使用调度工具(如 cron 或 APScheduler)每天凌晨执行 daily_task 函数
b.分值计算
根据业务需求调整权重,确保分值计算符合实际情况
c.Redis 存储
使用 ZSet 存储文章及其分值,确保快速排序和检索
2.29 [5]场景:统计在线人数
00.如何认定用户是否在线?
a.登录网站
如果网站需要登录才能进入,那么这种网站就是根据用户的token令牌有效性判断是否在线
b.公开网站
a.说明
如果网站是公开的,是那种不需要登录就可以浏览的,那么这种网站一般就需要自定一个规则来识别用户
也有很多方式实现如IP、deviceId、浏览器指纹,推荐使用浏览器指纹的方式实现
浏览器指纹可能包括以下信息的组合:用户代理字符串 (User-Agent string)、HTTP请求头信息
屏幕分辨率和颜色深度、时区和语言设置、浏览器插件详情等。现成的JavaScript库
像 FingerprintJS 或 ClientJS,可以帮助简化这个过程,因为它们已经实现了收集上述信息并生成唯一标识的算法
b.代码
// 安装:npm install @fingerprintjs/fingerprintjs
// 使用示例:
import FingerprintJS from '@fingerprintjs/fingerprintjs';
// 初始化指纹JS Library
FingerprintJS.load().then(fp => {
// 获取访客ID
fp.get().then(result => {
const visitorId = result.visitorId;
console.log(visitorId);
});
});
c.说明
这样就可以获取一个访问公开网站的用户的唯一ID了,当用户访问网站的时候
将这个ID放到访问链接的Cookie或者header中传到后台,后端服务根据这个ID标示用户
01.zadd命令添加在线用户
a.zadd命令
a.参数
key:有序集合的名称
score1、score2 等:分数值,可以是整数值或双精度浮点数
member1、member2 等:要添加到有序集合的成员
b.说明
向名为 myzset 的有序集合中添加一个成员:ZADD myzset 1 "one"
b.添加在线用户标识到有序集合中
a.代码
// expireTime给用户令牌设置了一个过期时间
LocalDateTime expireTime = LocalDateTime.now().plusSeconds(expireTimeout);
String expireTimeStr = DateUtil.formatFullTime(expireTime);
// 添加用户token到有序集合中
redisService.zadd("user.active", Double.parseDouble(expireTimeStr), userToken);
b.说明
由于一个用户可能会重复登录,这就导致userToken也会重复,但为了不重复计算这个用户的访问次数,zadd命令的第二个参数很好的解决了这个问题
这里的逻辑是:每次添加一个在线用户时,利用当前时间加上过期时间计算出一个分数,可以有效保证当前用户只会存在一个最新的登录态
02.zrangeByScore命令查询在线人数
a.zrangeByScore命令介绍
key:指定的有序集合的名字
min 和 max:定义了查询的分数范围,也可以是 -inf 和 +inf(分别表示“负无穷大”和“正无穷大”)
例子:查询分数在 1 到 3之间的所有成员:ZRANGEBYSCORE myzset 1 3
b.查询当前所有的在线用户
利用zrangeByScore方法可以查询这个有序集合指定范围内的用户
这个userOnlineStringSet也就是在线用户集,它的size就是在线人数了
03.zremrangeByScore命令定时清除在线用户
a.zremrangeByScore命令介绍
key:指定的有序集合的名字
min 和 max:定义了查询的分数范围,也可以是 -inf 和 +inf(分别表示“负无穷大”和“正无穷大”)
例子:删除分数在 1 到 3之间的所有成员:ZREMRANGEBYSCORE myzset 1 3
b.定时清除在线用户
由于有序集合不会自动清理下线的用户,所以这里我们需要写一个定时任务去定时删除下线的用户
04.zrem命令用户退出登录时删除成员
a.zrem命令介绍
key:指定的有序集合的名字
members:需要删除的成员
例子:删除名为xxx的成员:ZREM myzset "xxx"
b.定时清除在线用户
删除 zset中的记录,确保主动退出的用户下线
2.30 [5]常见:商品搜索记录
01.需求背景
a.功能描述
基于缓存实现一个商品最近搜索记录功能
存在一个商品搜索功能,用户每次搜索商品需要把搜索过的商品记录缓存起来,缓存信息包括商品ID、商品名称
b.关键点
使用Java和Redis实现最近搜索记录
每次搜索可能涉及多个商品,需要批量处理
每个用户的记录不超过10个,避免内存过大
需要存储商品ID和名称,可能涉及数据结构的选择
02.需求分析
a.数据结构选择
使用Redis的Sorted Set(ZSet)来存储浏览记录,并结合时间戳排序
使用Hash结构来存储商品详情
b.记录数量限制
每次添加后检查ZSet的长度,如果超过10个,就移除最旧的记录
c.批量搜索处理
将多个商品一次性添加到ZSet中,并更新它们的score为当前时间
d.获取最近记录
从ZSet中取出最新的10个ID,再从Hash中获取详细信息
03.技术方案设计
a.数据结构选择
使用ZSET结构存储用户搜索记录(用户ID为key,商品ID为value,时间戳为score)
使用HASH结构存储商品详情(商品ID为key,商品名称等为field)
b.核心逻辑
每次搜索时更新ZSET中的时间戳
控制ZSET最大长度不超过10
批量处理商品ID时保证原子性操作
c.实现步骤
使用ZSet存储用户最近搜索的商品ID,按时间排序
使用Hash存储商品ID和名称的映射
每次搜索批量添加商品,更新ZSet的score为当前时间
维护ZSet长度不超过10,移除旧记录
提供获取最近搜索记录的方法,从ZSet和Hash中联合查询
04.代码实现
a.RedisTemplate配置
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
}
b.服务层实现
@Slf4j
@Component
public class LatestSearchUtils {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 存储搜索记录(批量)
public void addSearchHistory(String userId, List<ZbProduct> zbProducts) {
String zsetKey = "lastest:search:history:" + userId;
String hashKey = "zbproduct:info";
// 批量更新ZSET和HASH
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
long now = System.currentTimeMillis();
for (ZbProduct product : zbProducts) {
// 更新ZSET(时间倒序)
redisTemplate.opsForZSet().add(zsetKey, product.getId(), now--);
// 存储商品详情
redisTemplate.opsForHash().put(hashKey, product.getId(), product.getName());
}
// 修剪ZSET保留最新10条
redisTemplate.opsForZSet().removeRange(zsetKey, 0, -11);
return null;
});
}
// 获取最近搜索记录
public List<ZbProduct> getRecentHistory(String userId) {
String zsetKey = "lastest:search:history:" + userId;
String hashKey = "zbproduct:info";
Set<Object> productIds = redisTemplate.opsForZSet().reverseRange(zsetKey, 0, 9);
return redisTemplate.executePipelined((RedisCallback<ZbProduct>) connection -> {
for (Object id : productIds) {
String name = (String) redisTemplate.opsForHash().get(hashKey, id);
if(name != null) {
return new ZbProduct(id.toString(), name);
}
}
return null;
});
}
}
// 商品实体类
@Data
@AllArgsConstructor
class ZbProduct {
private String id;
private String name;
}
05.关键实现逻辑说明
a.ZSET时间戳倒序
使用递减时间戳(now--)实现相同批次商品按输入顺序存储
reverseRange方法实现从新到旧排序读取
b.内存控制策略
removeRange修剪超过10条的旧记录
商品详情统一存储HASH,避免重复存储名称
c.性能优化
使用管道(pipelined)提升批量操作性能
商品详情分离存储,支持多业务复用
2.31 [6]stream:消息队列,允许重复消息,每条消息都有唯一的ID
00.汇总
xadd 向流中添加一个新的消息
xrange 返回指定范围内的消息
xread 读取流中的消息,支持阻塞读取
xdel 删除指定的消息
xlen 返回流中的消息数量
01.介绍
a.概念
Redis Stream 是 Redis 5.0 版本新增加的数据结构
提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建
b.组成
Consumer Group(消费组):使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)
lastdeliveredid(游标):每个消费组会有个游标 lastdeliveredid,任意一个消费者读取了消息都会使游标 lastdeliveredid 往前移动
pendingids(消费者的状态变量):维护消费者的未确认的id,pendingids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)
c.主要特征
1.数据结构:Redis Stream是一个由有序消息组成的日志数据结构,每个消息都有一个全局唯一的ID,确保消息的顺序性和可追踪性。
2.消息ID:消息的ID由两部分组成,分别是毫秒级时间戳和序列号。这种设计确保了消息ID的单调递增性,即新消息的ID总是大于旧消息的ID。
3.消费者组:Redis Stream支持消费者组的概念,允许多个消费者以组的形式订阅Stream,并且每个消息只会被组内的一个消费者处理,避免了消息的重复消费。
d.主要优势
1.持久化存储:Stream中的消息可以被持久化存储,确保数据不会丢失,即使在Redis服务器重启后也能恢复消息。
2.有序性:消息按照产生顺序生成消息ID, 被添加到Stream中,并且可以按照指定的条件检索消息,保证了消息的有序性。
3.多播与分组消费:支持多个消费者同时消费同一流中的消息,并且可以将消费者组织成消费组,实现消息的分组消费。
4.消息确认机制:消费者可以通过XACK命令确认是否成功消费消息,保证消息至少背消费一次,确保消息不会被重复处理。
5.阻塞读取:消费者可以选择阻塞读取模式,当没有新消息时,消费者会等待直至新消息到达。
6.消息可回溯: 方便补数、特殊数据处理, 以及问题回溯查询
02.对比
a.Stream
获取元素高效,复杂度为O(logN)
支持offset,每个消息元素有唯一id。不会因为新元素加入或者其他元素淘汰而改变id。
支持消息元素持久化,可以保存到AOF和RDB中
支持消费分组
支持ACK(消费确认)
Stream性能与消费者数量无明显关系
允许按时间线逐出历史数据,支持block,给予radix tree和listpack,内存开销少
不能从中间删除消息元素
b.List
List获取元素的复杂度为O(N)
List没有offset概念,如果有元素被逐出,无法确定最新的元素
不支持消息确认机制,没有很好的ACK应答
不支持消息回溯,无法排查问题和做消息分析
List按照FIFO机制执行,所以存在消息堆积的风险。
查询效率低,作为线性结构,List中定位一个数据需要进行遍历,O(N)的时间复杂度
不存在消费组(Consumer Group)的概念,无法实现多个消费者组成分组进行消费
c.Pub/Sub
Pub/Sub不支持持久化消息
Pub/Sub不支持消费分组
Pub/Sub不支持ACK(消费确认)
Pub/Sub性能与客户端数量负相关
消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃
d.Zset
Zset不能重复添加相同元素,不支持逐出和block,内存开销大
Zet支持删除任意元素
03.常见命令
a.消息队列
XADD 添加消息到末尾
XTRIM 对流进行修剪,限制长度
XDEL 删除消息
XLEN 获取流包含的元素数量,即消息长度
XRANGE 获取消息列表,会自动过滤已经删除的消息
XREVRANGE 反向获取消息列表,ID 从大到小
XREAD 以阻塞或非阻塞方式获取消息列表
b.消费者组
XGROUP CREATE 创建消费者组
XREADGROUP GROUP 读取消费者组中的消息
XACK 将消息标记为"已处理"
XGROUP SETID 为消费者组设置新的最后递送消息ID
XGROUP DELCONSUMER 删除消费者
XGROUP DESTROY 删除消费者组
XPENDING 显示待处理消息的相关信息
XCLAIM 转移消息的归属权
XINFO 查看流和消费者组的相关信息
XINFO GROUPS 打印消费者组的信息
XINFO STREAM 打印流信息
04.常见命令
a.XADD
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
XADD key ID field value [field value ...]
key :队列名称,如果不存在就创建
ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。
field value : 记录。
-----------------------------------------------------------------------------------------------------
redis> XADD mystream * name Sara surname OConnor
"1601372323627-0"
redis> XADD mystream * field1 value1 field2 value2 field3 value3
"1601372323627-1"
redis> XLEN mystream
(integer) 2
redis> XRANGE mystream - +
1) 1) "1601372323627-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
2) 1) "1601372323627-1"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis>
b.XTRIM
使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count
key :队列名称
MAXLEN :长度
count :数量
-----------------------------------------------------------------------------------------------------
127.0.0.1:6379> XADD mystream * field1 A field2 B field3 C field4 D
"1601372434568-0"
127.0.0.1:6379> XTRIM mystream MAXLEN 2
(integer) 0
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1601372434568-0"
2) 1) "field1"
2) "A"
3) "field2"
4) "B"
5) "field3"
6) "C"
7) "field4"
8) "D"
127.0.0.1:6379>
c.XDEL
使用 XDEL 删除消息,语法格式:
XDEL key ID [ID ...]
key:队列名称
ID :消息 ID
-----------------------------------------------------------------------------------------------------
127.0.0.1:6379> XADD mystream * a 1
1538561698944-0
127.0.0.1:6379> XADD mystream * b 2
1538561700640-0
127.0.0.1:6379> XADD mystream * c 3
1538561701744-0
127.0.0.1:6379> XDEL mystream 1538561700640-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) 1538561698944-0
2) 1) "a"
2) "1"
2) 1) 1538561701744-0
2) 1) "c"
2) "3"
d.XLEN
使用 XLEN 获取流包含的元素数量,即消息长度,语法格式:
XLEN key
key:队列名称
-----------------------------------------------------------------------------------------------------
redis> XADD mystream * item 1
"1601372563177-0"
redis> XADD mystream * item 2
"1601372563178-0"
redis> XADD mystream * item 3
"1601372563178-1"
redis> XLEN mystream
(integer) 3
redis>
e.XRANGE
使用 XRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XRANGE key start end [COUNT count]
key :队列名
start :开始值, - 表示最小值
end :结束值, + 表示最大值
count :数量
-----------------------------------------------------------------------------------------------------
redis> XADD writers * name Virginia surname Woolf
"1601372577811-0"
redis> XADD writers * name Jane surname Austen
"1601372577811-1"
redis> XADD writers * name Toni surname Morrison
"1601372577811-2"
redis> XADD writers * name Agatha surname Christie
"1601372577812-0"
redis> XADD writers * name Ngozi surname Adichie
"1601372577812-1"
redis> XLEN writers
(integer) 5
redis> XRANGE writers - + COUNT 2
1) 1) "1601372577811-0"
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) "1601372577811-1"
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
redis>
f.XREVRANGE
使用 XREVRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XREVRANGE key end start [COUNT count]
key :队列名
end :结束值, + 表示最大值
start :开始值, - 表示最小值
count :数量
-----------------------------------------------------------------------------------------------------
redis> XADD writers * name Virginia surname Woolf
"1601372731458-0"
redis> XADD writers * name Jane surname Austen
"1601372731459-0"
redis> XADD writers * name Toni surname Morrison
"1601372731459-1"
redis> XADD writers * name Agatha surname Christie
"1601372731459-2"
redis> XADD writers * name Ngozi surname Adichie
"1601372731459-3"
redis> XLEN writers
(integer) 5
redis> XREVRANGE writers + - COUNT 1
1) 1) "1601372731459-3"
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
redis>
g.XREAD
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
count :数量
milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
key :队列名
id :消息 ID
-----------------------------------------------------------------------------------------------------
# 从 Stream 头部读取两条消息
redis> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
2) 1) 1526999352406-0
2) 1) "duration"
2) "812"
3) "event-id"
4) "9"
5) "user-id"
6) "388234"
2) 1) "writers"
2) 1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
h.XGROUP CREATE
使用 XGROUP CREATE 创建消费者组,语法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
key :队列名称,如果不存在就创建
groupname :组名。
$ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
-----------------------------------------------------------------------------------------------------
从头开始消费:
XGROUP CREATE mystream consumer-group-name 0-0
从尾部开始消费:
XGROUP CREATE mystream consumer-group-name $
i.XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
group :消费组名
consumer :消费者名。
count : 读取数量。
milliseconds : 阻塞毫秒数。
key : 队列名。
ID : 消息 ID。
-----------------------------------------------------------------------------------------------------
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >
2.32 [6]底层:列表包+拉链索引
00.底层
RadixTree(拉链索引):存储streamID
Listpack(列表包):存储对应的值
01.概述
stream 是一个类似于日志的数据结构,它可以记录一系列的键值对,每个键值对都有一个唯一的 ID
一个 stream 类型的键最多可以存储 2^64 - 1 个键值对
stream 类型的底层实现是 rax(基数树),它是一种压缩的前缀树结构
它将所有的键值对按照 ID 的字典序存储在一个树形结构中。rax 可以快速地定位、插入、删除任意位置的键值对
02.应用场景
消息队列:利用 xadd 和 xread 命令实现生产者消费者模式
操作日志:利用 xadd 和 xrange 命令实现操作记录和回放
数据同步:利用 xadd 和 xreadgroup 命令实现多个消费者组之间的数据同步
03.RadixTree
a.总结
rax tree是一种基于基数树(radix tree)的变体,也叫做压缩前缀树(compressed prefix tree),
它被应用于redis stream中,用来存储streamID,其数据结构为
typedef struct raxNode {
uint32_t iskey:1; /* Does this node contain a key? */
uint32_t isnull:1; /* Associated value is NULL (don't store it). */
uint32_t iscompr:1; /* 前缀是否压缩 */
uint32_t size:29; /* Number of children, or compressed string len. */
unsigned char data[];
} raxNode;
-----------------------------------------------------------------------------------------------------
iskey:是否包含key
isnull:是否存储value值
iscompr:前缀是否压缩。决定了size存储的是什么和data的数据结构
size:
iscompr=0:节点为非压缩节点,size是孩子节点的数量
iscompr=1:节点为压缩节点,size是已压缩的字符串长度
data:
iscompr=0:节点为非压缩节点,数据格式为[header strlen=0][abc][a-ptr][b-ptr][c-ptr](value-ptr?)。其有size个字符,
iscompr=1:节点为压缩节点,数据格式为[header strlen=3][xyz][z-ptr](value-ptr?)。
b.场景一:只插入foot
数据结构为
其中,z-ptr指向的叶子节点的iskey=1,标识foot这个key。下图为使用树状图的形式来展现其数据结构
c.场景二:插入foot后,插入footer
数据结构为:
其插入过程为:
与foot节点中每个字符进行比较,获得最大公共前缀foot
将er作为foot的子节点,其iskey=1,标识foot这个key
将er的子节点的iskey=1,标识footer这个key
下图为使用树状图的形式来展现其数据结构
d.场景三:插入foot后,插入fo
数据结构为:
其插入过程为:
与foot节点中每个字符进行比较,获得最大公共前缀fo
将foot拆成fo和ot
将ot作为fo的子节点,其iskey=1,标识fo这个key
设置ot的子节点的iskey=1,标识foot这个key
下图为使用树状图的形式来展现其数据结构
e.场景四:插入foot后,插入foobar
数据结构为:
其插入过程为:
与foot节点中每个字符进行比较,获得最大公共前缀foo
将foot拆成foo和t
将footbar拆成foo、b、ar
将t、b作为foo的子节点
设置ot的子节点的iskey=1,标识foot这个key
将ar作为b的子节点
设置ar的子节点的iskey=1,标识footbar这个key
下图为使用树状图的形式来展现其数据结构
2.33 [6]场景:消息队列、日志记录、实时数据处理、事件驱动系统、任务调度
01.消息队列
a.说明
stream 可以用于实现消息队列,支持消息的生产和消费
每条消息都有一个唯一的 ID,消费者可以按顺序读取消息
b.使用
XADD key * field value [field value ...]:向流中添加一条消息
XREAD COUNT count STREAMS key ID:读取流中的消息
c.示例
XADD message_stream * sender "Alice" message "Hello, Bob!"
XADD message_stream * sender "Bob" message "Hi, Alice!"
XREAD COUNT 2 STREAMS message_stream 0 # 读取两条消息
02.日志记录
a.说明
stream 可以用于存储和管理日志信息,支持按时间顺序记录日志
每条日志记录都有一个唯一的 ID
b.使用
XADD key * field value [field value ...]:添加日志记录
XRANGE key start end:按 ID 范围获取日志记录
c.示例
XADD log_stream * level "INFO" message "System started"
XADD log_stream * level "ERROR" message "An error occurred"
XRANGE log_stream - + # 获取所有日志记录
03.实时数据处理
a.说明
stream 可以用于实时数据处理系统,支持高吞吐量的数据写入和读取
适合用于处理传感器数据、用户行为数据等
b.使用
XADD key * field value [field value ...]:添加实时数据
XREAD BLOCK milliseconds STREAMS key ID:阻塞读取流中的数据
c.示例
XADD sensor_data * temperature 22.5 humidity 60
XADD sensor_data * temperature 23.0 humidity 58
XREAD BLOCK 1000 STREAMS sensor_data 0 # 阻塞读取数据
04.事件驱动系统
a.说明
stream 可以用于事件驱动系统,支持事件的发布和订阅
每个事件都有一个唯一的 ID,消费者可以按顺序处理事件
b.使用
XADD key * field value [field value ...]:发布事件
XREADGROUP GROUP group_name consumer_name STREAMS key ID:消费事件
c.示例
XADD event_stream * event_type "user_signup" user_id "1001"
XADD event_stream * event_type "user_login" user_id "1002"
XREADGROUP GROUP mygroup consumer1 STREAMS event_stream > # 消费事件
05.任务调度
a.说明
stream 可以用于任务调度系统,支持任务的发布和消费
每个任务都有一个唯一的 ID,消费者可以按顺序处理任务
b.使用
XADD key * field value [field value ...]:发布任务
XREADGROUP GROUP group_name consumer_name STREAMS key ID:消费任务
c.示例
XADD task_stream * task_id "task1" description "Process data"
XADD task_stream * task_id "task2" description "Generate report"
XREADGROUP GROUP task_group worker1 STREAMS task_stream > # 消费任务
2.34 [7]pub/sub:发布/订阅,事件驱动架构+高效消息传递机制
00.底层
事件驱动架构+高效消息传递机制
01.定义
Pub/Sub 是一种消息传递模式,发布者(Publisher)发送消息,订阅者(Subscriber)接收消息
发布者和订阅者之间通过频道(Channel)进行通信,彼此不直接联系
02.原理
发布者:将消息发送到一个或多个频道
订阅者:订阅一个或多个频道,接收发布到这些频道的消息
频道:消息的传递通道,订阅者通过频道接收消息
03.常用API
PUBLISH channel message:将消息发布到指定频道
SUBSCRIBE channel [channel ...]:订阅一个或多个频道
UNSUBSCRIBE [channel ...]:取消订阅一个或多个频道
PSUBSCRIBE pattern [pattern ...]:订阅与模式匹配的一个或多个频道
PUNSUBSCRIBE [pattern ...]:取消订阅与模式匹配的一个或多个频道
04.使用步骤
1.启动 Redis 服务器
2.订阅者订阅一个或多个频道
3.发布者向频道发布消息
4.订阅者接收并处理消息
05.场景及代码示例
a.简单的消息传递
a.订阅者
import redis
def message_handler(message):
print(f"Received message: {message['data']}")
r = redis.Redis()
p = r.pubsub()
p.subscribe(**{'my_channel': message_handler})
print("Subscribed to 'my_channel'. Waiting for messages...")
p.run_in_thread(sleep_time=0.001)
b.发布者
import redis
r = redis.Redis()
r.publish('my_channel', 'Hello, Redis!')
b.模式匹配订阅
a.订阅者
import redis
def message_handler(message):
print(f"Received message from {message['channel']}: {message['data']}")
r = redis.Redis()
p = r.pubsub()
p.psubscribe(**{'my_*': message_handler})
print("Subscribed to pattern 'my_*'. Waiting for messages...")
p.run_in_thread(sleep_time=0.001)
b.发布者
import redis
r = redis.Redis()
r.publish('my_channel1', 'Hello, Channel 1!')
r.publish('my_channel2', 'Hello, Channel 2!')
2.35 [8]bitset:商品预约
01.定义
Redis 的 BitSet 是一种用于操作位数组(bit array)的数据结构,允许在 Redis 中以高效的方式存储和操作位信息
在 Redis 中,BitSet 是通过字符串类型实现的,每个字符串可以看作是一个位数组。每个位可以是 0 或 1,表示布尔值
02.原理
a.存储
在 Redis 中,BitSet 是通过字符串类型存储的。每个字符串可以包含多个字节,每个字节包含 8 位
b.操作
Redis 提供了一组命令来操作这些位,包括设置、获取、统计和逻辑运算
c.高效性
由于每个位只占用一个二进制位,BitSet 在存储和操作布尔值时非常高效
03.常用 API
a.SETBIT key offset value
# 设置指定偏移量的位为 0 或 1
SETBIT mykey 10 1
b.GETBIT key offset
# 获取指定偏移量的位的值
GETBIT mykey 10
c.BITCOUNT key [start end]
# 统计位数组中值为 1 的位的数量,可以指定范围
BITCOUNT mykey
d.BITOP operation destkey key [key ...]
# 对一个或多个位数组执行位运算(AND、OR、XOR、NOT),并将结果存储在目标键中
BITOP AND resultkey key1 key2
04.使用步骤
a.初始化
选择一个 Redis 键作为 BitSet 的存储
b.设置位
使用 SETBIT 命令设置特定位的值
c.获取位
使用 GETBIT 命令获取特定位的值
d.统计位
使用 BITCOUNT 命令统计位数组中值为 1 的位的数量
e.逻辑运算
使用 BITOP 命令对多个位数组进行逻辑运算
05.场景及代码示例
a.场景1:用户活跃状态跟踪
# 记录用户在某一天是否活跃
# 设置用户 1001 在某一天活跃
SETBIT user_activity 1001 1
# 检查用户 1001 是否活跃
GETBIT user_activity 1001
# 统计活跃用户的数量
BITCOUNT user_activity
b.场景2:权限管理
# 使用 BitSet 表示用户或角色的权限集合
# 设置用户权限
SETBIT user_permissions 0 1 # 读权限
SETBIT user_permissions 1 0 # 写权限
SETBIT user_permissions 2 1 # 执行权限
# 检查用户是否有读权限
GETBIT user_permissions 0
c.场景3:布隆过滤器
# 用于快速判断一个元素是否在集合中
# 添加元素到布隆过滤器
SETBIT bloom_filter 12345 1
# 检查元素是否可能在集合中
GETBIT bloom_filter 12345
06.场景:电商商品预约
a.业务场景
a.电商类行业
针对一些热点商品,提供预约功能,需要提前预约才能购买
b.校园抢课系统
针对一些热点选修课,提供预约抢课功能,需要提前预约才能抢
b.BitSet的使用
为了记录哪些用户预约过,并且能够快速查询,同时减少存储空间,选择使用 BitSet
Redis 支持 BitSet 数据结构,可以高效地进行位操作
为了避免 Redis 挂掉,数据也会存储在数据库中做持久化
c.BitSet的好处
a.节省内存
每个位只占用 1 位(bit),相比于布尔数组或整数数组,BitSet 可以显著减少内存占用
b.高效的操作
Redis 提供了丰富的命令来操作 BitSet,例如 SETBIT、GETBIT、BITCOUNT 等
c.原子性操作
Redis 的 BitSet 操作是原子性的,多个客户端可以同时对同一个 BitSet 进行操作而不会产生竞争条件
d.实现思路
a.第1步
用户 ID 是唯一且可转换为 integer,因此每个用户可以映射到一个唯一的 bit 上
b.第2步
商品 id 作为 key,存储一个 bitset,bitset 中存储的是已经预约过的用户的 id 列表
e.具体实现
a.商品预约
@Transactional(rollbackFor = Exception.class)
public GoodsBookResponse book(GoodsBookRequest request) {
RBitSet bookedUsers = redissonClient.getBitSet(BOOK_KEY + request.getGoodsType() + CacheConstant.CACHE_KEY_SEPARATOR + request.getGoodsId());
bookedUsers.set(Integer.parseInt(request.getBuyerId()));
GoodsBook existBook = goodsBookMapper.selectByGoodsIdAndBuyerId(request.getGoodsId(), request.getGoodsType().name(), request.getBuyerId());
if (existBook != null) {
return new GoodsBookResponse.GoodsBookResponseBuilder().bookId(existBook.getId()).buildSuccess();
}
GoodsBook goodsBook = GoodsBook.createBook(request);
boolean result = save(goodsBook);
Assert.isTrue(result, () -> new BizException(RepoErrorCode.INSERT_FAILED));
Thread.ofVirtual().start(() -> {
long bookedCount = bookedUsers.cardinality();
if (bookedCount > HOT_GOODS_BOOK_COUNT) {
hotGoodsService.addHotGoods(request.getGoodsId(), request.getGoodsType().name());
}
});
return new GoodsBookResponse.GoodsBookResponseBuilder().bookId(goodsBook.getId()).buildSuccess();
}
b.查询用户是否预约
public boolean isBooked(String goodsId, GoodsType goodsType, String buyerId) {
RBitSet bookedUsers = redissonClient.getBitSet(BOOK_KEY + goodsType + CacheConstant.CACHE_KEY_SEPARATOR + goodsId);
return bookedUsers.get(Integer.parseInt(buyerId));
}
-------------------------------------------------------------------------------------------------
以上操作相当于执行命令:GETBIT "goods:book:COLLECTION:10085" "39"
2.36 [8]bitmap:位图,位数组
00.底层
位数组,本质是SDS(动态字符串),自动扩展和缩减,只是在操作时会将每个字节拆分成 8 个二进制位
01.概述
bitmap 不是一个独立的数据类型,而是一种特殊的 string 类型
它可以将一个 string 类型的值看作是一个由二进制位组成的数组
并提供了一系列操作二进制位的命令。一个 bitmap 类型的键最多可以存储 2^32 - 1 个二进制位
02.应用场景
a.背景
bitmap 类型的应用场景主要是利用二进制位的特性
统计用户活跃度,利用 setbit 和 bitcount 命令实现每天或每月用户登录次数的统计
实现布隆过滤器,利用 setbit 和 getbit 命令实现快速判断一个元素是否存在于一个集合中
实现位图索引,利用 bitop 和 bitpos 命令实现对多个条件进行位运算和定位
b.假如需要统计每个用户的当天登录次数统计
首先,需要规定bitmap的格式,假设为{userid}:{年份}:{第几天} {秒数} {是否登录}
将userid为100的用户,记录他在2024年第100天中第1秒,是否登录
SETBIT 1000:2024:100 1 1
0
-----------------------------------------------------------------------------------------------------
将userid为100的用户,记录他在2024年第100天中第10240 秒,是否登录
SETBIT 1000:2024:100 10240 1
0
-----------------------------------------------------------------------------------------------------
将userid为100的用户,记录他在2024年第100天中第86400 秒,是否登录
SETBIT 1000:2024:100 86400 1
0
-----------------------------------------------------------------------------------------------------
统计userid为100的用户,在2024年第100天的登录次数
BITCOUNT 1000:2024:100
3
2.37 [8]bitmap:40亿QQ去重
01.概况
a.定义
BitMap(位图)是一种非常高效的数据结构,特别适合处理大规模数据的去重和查询问题
它的基本思想是使用一个bit位来表示一个数字是否存在
b.示例
如果BitMap的第0位是1,表示数字0存在
如果BitMap的第1位是1,表示数字1存在
如果BitMap的第2位是1,表示数字2存在
以此类推
c.存储效率
用BitMap记录QQ号码9、5、2、7,只需要10位
传统方法用整型4字节,4个QQ号码需要16字节(128位)
BitMap显著减少存储空间
d.优点
空间效率高:相比哈希表存储原始数据,Bitmap仅用1位/元素。对于密集数据(如连续QQ号),空间利用率极高
操作非常高效:插入和查询均为O(1)复杂度,位运算速度快,适合海量数据实时处理
去重逻辑简单:只需遍历数据,置位存在标记,无需复杂结构
e.缺点
存储空间依赖值域范围:若值域范围大但稀疏,空间浪费严重。例如,若QQ号上限为1万亿,需125GB内存,难以承受
无法存储额外信息:仅记录是否存在,无法保存出现次数等元数据
02.用BitMap给40亿QQ去重
a.内存需求
40亿位的BitMap需要的内存:
4,000,000,000/8 = 500,000,000
500,000,000/1024/1024/1024 ≈ 0.466GB
-----------------------------------------------------------------------------------------------------
只需要0.466GB的内存,符合不超过1GB的限制
b.去重流程
1.初始化40亿位的BitMap
2.遍历40亿QQ,将每个QQ号码映射到BitMap中,对应位置的bit设置为1
3.遍历BitMap,收集所有设置为1的位对应的QQ号码,即为去重后的QQ号码
c.简单代码实现
import java.util.*;
public class QQDeduplication {
private static final long BITMAP_SIZE = 1L << 32; // 2^32
private static final int BYTE_SIZE = 8; // 每个字节有8位
private static List<Long> deduplicateQQNumbers(long[] qqNumbers) {
byte[] bitmap = new byte[(int) (BITMAP_SIZE / BYTE_SIZE)];
for (long qqNumber : qqNumbers) {
if (qqNumber >= 0 && qqNumber < BITMAP_SIZE) {
int index = (int) (qqNumber / BYTE_SIZE);
int bitPosition = (int) (qqNumber % BYTE_SIZE);
bitmap[index] |= (1 << bitPosition);
}
}
List<Long> uniqueQQNumbers = new ArrayList<>();
for (int i = 0; i < bitmap.length; i++) {
for (int j = 0; j < BYTE_SIZE; j++) {
if ((bitmap[i] & (1 << j)) != 0) {
long qqNumber = (long) i * BYTE_SIZE + j;
uniqueQQNumbers.add(qqNumber);
}
}
}
return uniqueQQNumbers;
}
}
2.38 [8]bitmap:统计活跃用户
01.定义
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态
key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)
02.原理
a.说明
如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key
然后用户 ID 为 offset如果当日活跃过就设置为 1
b.初始化数据
SETBIT 20210308 1 1
(integer) 0
SETBIT 20210308 2 1
(integer) 0
SETBIT 20210309 1 1
(integer) 0
c.统计 20210308~20210309 总活跃用户数
BITOP and desk1 20210308 20210309
(integer) 1
BITCOUNT desk1
(integer) 1
d.统计 20210308~20210309 在线活跃用户数:
BITOP or desk2 20210308 20210309
(integer) 1
BITCOUNT desk2
(integer) 2
2.39 [8]bitfield:位域,二进制编码的Redis字符串
00.底层
使用二进制编码的Redis字符串来存储的bitfield结构支持原子的读,写和增加操作,使它们成为管理计数器和类似数值的好选择
01.概述
bitfield结构是基于字符串类型的一种扩展,可以让你对一个字符串中的任意位进行设置,增加和获取操作,就像一个位数组一样
可以操作任意位长度的整数,从无符号的1位整数到有符号的63位整数。这些值是使用二进制编码的Redis字符串来存储的
bitfield结构支持原子的读,写和增加操作,使它们成为管理计数器和类似数值的好选择
02.应用场景
a.场景1
Bitfield的使用场景与bitmap 类似,主要是一些需要用不同位长度的整数来表示状态或属性的场合,例如:
用一个32位的无符号整数来表示用户的金币数量,用一个32位的无符号整数来表示用户杀死的怪物数量,可以方便地对这些数值进行设置,增加和获取
用一个16位的有符号整数来表示用户的等级,用一个16位的有符号整数来表示用户的经验值,可以方便地对这些数值进行设置,增加和获取
用一个8位的无符号整数来表示用户的性别,用一个8位的无符号整数来表示用户的年龄,可以方便地对这些数值进行设置,增加和获取
b.场景2
bitfield和bitmap都是基于string类型的位操作,但是有一些区别:
bitmap只能操作1位的无符号整数,而bitfield可以操作任意位长度的有符号或无符号整数
bitmap只能设置或获取指定偏移量上的位,而bitfield可以对指定偏移量上的位进行增加或减少操作
bitmap可以对多个字符串进行位运算,而bitfield只能对单个字符串进行位操作
bitmap的偏移量是从0开始的,而bitfield的偏移量是从最高有效位开始的
c.例如,使用bitfield存储用户的个人信息,
用一个8位的无符号整数来表示用户的性别,0表示男,1表示女
用一个8位的无符号整数来表示用户的年龄,范围是0-255
用一个16位的无符号整数来表示用户的身高,单位是厘米,范围是0-65535
用一个16位的无符号整数来表示用户的体重,单位是克,范围是0-65535
d.假设有一个用户,性别是女,年龄是25,身高是165厘米,体重是50千克,可以用以下命令来存储和获取这些信息:
> BITFIELD user:1:info SET u8 #0 1 SET u8 #1 25 SET u16 #2 165 SET u16 #3 50000
0
0
0
0
e.然后,获取这个用户的信息,性别、年龄、身高、体重
> BITFIELD user:1:info GET u8 #0 GET u8 #1 GET u16 #2 GET u16 #3
1
25
165
50000
2.40 [9]geo:地理,zset结构,将经纬度编码作为score值
00.底层
它基于sorted set数据结构实现,利用geohash算法将经纬度编码为二进制字符串,并作为sorted set的score值
01.概述
geospatial 是一种用于存储和查询地理空间位置的数据类型,
它基于 sorted set 数据结构实现,利用 geohash 算法将经纬度编码为二进制字符串,
并作为 sorted set 的 score 值。
---------------------------------------------------------------------------------------------------------
Redis geospatial 提供了一系列的命令来添加、删除、搜索和计算地理空间位置,例如:
GEOADD key longitude latitude member [longitude latitude member …]:将一个或多个地理空间位置(经度、纬度、名称)添加到指定的 key 中
GEOPOS key member [member …]:返回一个或多个地理空间位置的经纬度
GEODIST key member1 member2 [unit]:返回两个地理空间位置之间的距离,可以指定单位(m, km, mi, ft)
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:返回指定圆心和半径内的地理空间位置,可以指定返回坐标、距离、哈希值、数量、排序方式等,也可以将结果存储到另一个 key 中
GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]: 返回以指定成员为圆心的指定半径内的地理空间位置,其他参数同 GEORADIUS
02.应用场景
geospatial 的应用是地理位置搜索、分析和展示,例如地图应用、导航应用、位置服务应用等。例如,可以使用 geospatial 来实现以下功能:
统计某个区域内的商家或用户数量
查询某个位置附近的餐馆或酒店
计算两个位置之间的距离或行驶时间
显示某个位置周围的景点或活动
2.41 [9]hyperloglog:基数统计,稀疏矩阵
00.底层
hyperloglog 类型的底层实现是 SDS(simple dynamic string),它和 string 类型相同,只是在操作时会使用一种概率算法来计算基数
hyperloglog 的误差率为 0.81%,也就是说如果真实基数为 1000,那么 hyperloglog 计算出来的基数可能在 981 到 1019 之间
01.概述
HyperLogLog 是一种概率数据结构,用于在恒定的内存大小下估计集合的基数(不同元素的个数)。
它不是一个独立的数据类型,而是一种特殊的 string 类型,它可以使用极小的空间来统计一个集合中不同元素的数量,
也就是基数。一个 hyperloglog 类型的键最多可以存储 12 KB 的数据
---------------------------------------------------------------------------------------------------------
hyperloglog 类型的底层实现是 SDS(simple dynamic string),
它和 string 类型相同,只是在操作时会使用一种概率算法来计算基数。
hyperloglog 的误差率为 0.81%,也就是说如果真实基数为 1000,
那么 hyperloglog 计算出来的基数可能在 981 到 1019 之间
02.应用场景
a.hyperloglog 类型的应用场景主要是利用空间换时间和精度,比如:
统计网站的独立访客数(UV)
统计在线游戏的活跃用户数(DAU)
统计电商平台的商品浏览量
统计社交网络的用户关注数
统计日志分析中的不同事件数
b.假如需要统计某商品的用户关注数,可以通过以下方式:
> PFADD goodA "1"
1
> PFADD goodA "2"
1
> PFADD goodA "3"
1
> PFCOUNT goodA
3
2.42 [9]bloomfilter:布隆过滤器
00.布隆过滤器能否处理1亿的数据?
a.回答
可以
可以通过调整参数(如位数组的大小和哈希函数的数量)来控制误判率和内存使用之间的平衡
b.说明
布隆过滤器是一种数据结构,用于快速检索一个元素是否可能存在于一个集合(bit 数组)中
它的基本原理是利用多个哈希函数,将一个元素映射成多个位,然后将这些位设置为 1
当查询一个元素时,如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在
所以,布隆过滤器可以准确的判断
01.定义
布隆过滤器(Bloom Filter)是一种空间效率很高的概率数据结构,用于测试一个元素是否属于一个集合
它特别适合处理大规模数据集,比如1亿个元素
布隆过滤器的优点在于它能够以较小的内存占用来快速判断元素是否存在于集合中
但它有一定的误判率,即可能会误判一个不存在的元素为存在
02.原理
a.数据结构
布隆过滤器由一个位数组(bit array)和一组哈希函数(hash functions)组成
位数组的初始状态是全为0
b.添加元素
对于每个要添加的元素,使用多个哈希函数计算出多个哈希值
每个哈希值对应位数组中的一个位置,将这些位置的值设为1
c.查询元素
对于要查询的元素,使用相同的哈希函数计算出多个哈希值
检查这些哈希值对应的位数组中的位置是否全为1
如果全为1,则元素可能存在(存在误判的可能);如果有任何一个位置为0,则元素一定不存在
d.误判率
布隆过滤器的误判率与位数组的大小、哈希函数的数量以及插入的元素数量有关
通过增加位数组的大小和哈希函数的数量,可以降低误判率,但会增加内存使用
03.优缺点
a.优点
空间效率高:相比于直接存储所有元素,布隆过滤器使用的内存要少得多
插入和查询速度快:时间复杂度为O(k),其中k是哈希函数的数量
b.缺点
误判率:可能会误判一个不存在的元素为存在
不支持删除:一旦元 素被添加到布隆过滤器中,就无法删除
04.使用场景
a.缓存系统
在缓存中使用布隆过滤器可以减少对后端数据库的查询次数
b.垃圾邮件过滤
快速判断邮件地址是否在黑名单中
c.网络爬虫
判断URL是否已经被访问过