1 基础
1.1 [1]分布式
01.分布式系统
a.定义
分布式系统是指多个独立的计算机通过网络协作完成任务的系统
它的核心思想是“拆分”,即将系统的功能和数据分布到多个节点上
b.原理
a.横向拆分
将系统按层次结构拆分,如将前端、业务逻辑和数据访问层分开
b.纵向拆分
按业务逻辑拆分,如电商系统中的用户、支付、购物等模块
c.常用API
分布式系统通常使用的技术包括:微服务框架(如Spring Cloud)、消息队列(如Kafka)、分布式数据库(如Cassandra)
d.使用步骤
识别系统的功能模块
选择合适的拆分策略(横向或纵向)
部署和管理分布式组件
e.示例
使用Spring Cloud构建微服务架构,将用户服务、订单服务和支付服务分开部署
1.2 [1]微服务
01.微服务
a.定义
微服务是一种软件架构风格,将应用程序拆分为一组小型服务
每个服务运行在自己的进程中,并通过轻量级机制(通常是HTTP API)进行通信
微服务架构强调服务的独立性和自治性,使得开发、部署和扩展更加灵活
b.原理
服务自治:每个微服务独立开发、部署和运行,拥有自己的数据存储和业务逻辑
轻量级通信:微服务之间通过轻量级协议(如HTTP/REST、gRPC)进行通信
去中心化治理:微服务架构鼓励去中心化的数据管理和服务治理
c.常用API
Spring Cloud:提供微服务架构的基础设施,如服务注册与发现(Eureka)、配置管理(Spring Cloud Config)、负载均衡(Ribbon)、断路器(Hystrix)
Docker:用于微服务的容器化和部署
Kubernetes:用于微服务的容器编排和管理
d.使用步骤
识别业务功能:将应用程序的业务功能拆分为多个独立的服务
定义服务接口:为每个微服务定义清晰的接口和通信协议
选择技术栈:选择合适的技术栈和工具来实现微服务
部署和管理:使用容器化技术(如Docker)和编排工具(如Kubernetes)来部署和管理微服务
e.示例
用户服务:负责用户的注册、登录和管理
订单服务:处理订单的创建、更新和查询
支付服务:管理支付流程和交易记录
1.3 [1]分布式、微服务
00.总结
分布式:拆了就行(横向、纵向)
微服务:纵向拆分,最小化拆分
01.分布式系统
a.定义
分布式系统是指多个独立的计算机通过网络协作完成任务的系统
其核心思想是将系统的功能和数据分布到多个节点上,以提高系统的性能、可靠性和可扩展性
b.特点
节点协作:多个计算节点协同工作,共同完成任务
数据分布:数据和计算任务分布在不同的物理或逻辑节点上
容错性:通过冗余和故障转移机制提高系统的容错能力
c.应用场景
大规模数据处理(如Hadoop、Spark)
分布式数据库(如Cassandra、HBase)
分布式文件系统(如HDFS)
02.微服务架构
a.定义
微服务是一种软件架构风格,将应用程序拆分为一组小型、独立的服务
每个服务运行在自己的进程中,并通过轻量级机制(通常是HTTP API)进行通信
b.特点
服务自治:每个微服务独立开发、部署和运行,拥有自己的数据存储和业务逻辑
轻量级通信:微服务之间通过轻量级协议(如HTTP/REST、gRPC)进行通信
去中心化治理:鼓励去中心化的数据管理和服务治理
c.应用场景
需要快速迭代和部署的应用程序
复杂的企业级应用,需提高开发和运维效率
需要灵活扩展和独立部署的系统
1.4 [1]强一致性、弱一致性、最终一致性
01.强一致性
任何一次读都能读到某个数据的最近一次写的数据
系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致
简言之,在任意时刻,所有节点中的数据是一样的
02.弱一致性
数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性
03.最终一致性
不保证在任意时刻任意节点上的同一份数据都是相同的
但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化
简单说,就是在一段时间后,节点间的数据会最终达到一致状态
1.5 [2]理论:CAP
01.CAP理论
a.定义
在任何分布式系统中,C、A、P不能够同时共存,只能存在两个
一般而言,至少要保证P可行,因为分布式中经常会出现“弱网环境”,因此就需要在C和A之间二选一
b.原理
C.强一致性
子节点中的数据时刻需要保持一致,如果满足一致性,则数据会造成回滚,不会提交,则数据不可用
A.可用性
整体能够使用(在合理的时间范围内,系统能够提供正常的服务)
P.分区容错性
允许部分失败(当分布式系统中的一个或多个节点发生网络故障(网络分区),从而脱离整个系统的网络环境时,系统仍然能够提供可靠的服务)
c.常用API
分布式数据库和协调服务(如Zookeeper)通常涉及CAP理论的权衡
d.使用步骤
确定系统的优先级(C、A或P)
选择合适的技术和架构来实现优先级
02.CAP场景
a.示例
Zookeeper CP系统
Redis主从同步 AP系统
Eureka主从同步 AP系统
MySQL主从异步复制 AP系统
MySQL主从半同步复制 CP系统
b.CAP的现实抉择:C 和 A,注定有一头要舍弃
CP(强一致)、AP(高并发)
03.CAP倾向
a.当女票问"重要还是工作重要?"
A.立刻回家(CP)
B.先回消息稳住(AP)
b.写代码遇到Bug时
A.必须找到根源(CP)
B.先加try-catch上线(AP)
c.玩MOBA游戏时
A.等全员到位再团(CP)
B.先偷塔再说(AP)
1.6 [2]理论:BASE
01.BASE理论
a.定义
弥补CAP的不足,尽最大努力近似地实现CAP三者共同实现
b.核心
用“最终一致性”代替“强一致性”,首选满足A\P,因此不能满足C,但是可以用最终一致性代替C
c.状态
a.软状态
多个节点时,允许中间某个时刻数据不一致
b.强一致性
多个节点时,时时刻刻保持一致
c.最终一致性
多个节点时,最后一致就行
d.常用API
NoSQL数据库(如Cassandra、DynamoDB)通常采用BASE理论
e.使用步骤
设计系统以支持最终一致性
实现数据同步和冲突解决机制
f.示例
使用Cassandra实现最终一致性的数据存储
1.7 [3]原则:高并发
01.高并发原则
a.定义
高并发原则是指通过优化系统架构和资源利用,支持大量并发请求的能力
b.场景
双十一、春晚发红包、12306购票
c.原理
a.垂直扩展
通过增加单个服务器的资源(如CPU、内存)来提高性能
b.水平扩展
通过增加服务器的节点个数,来横向扩充系统的性能
d.常用API
负载均衡器(如Nginx)、缓存系统(如Redis)、消息队列(如RabbitMQ)
e.使用步骤
识别系统的瓶颈
选择合适的扩展策略(垂直或水平)
部署和配置扩展组件
f.示例
使用Nginx进行负载均衡,分发请求到多个应用服务器
1.8 [3]原则:幂等性
01.幂等性原则
a.定义
幂等性原则是对调用服务次数的一种限制,即无论对某个服务提供的接口调用多次或是一次,其结果都是相同的
b.场景
防止重复购买
c.原理
通过算法、去重表、分布式锁等技术实现幂等性
d.常用API
数据库唯一索引、分布式锁(如Redis锁)、状态机
e.使用步骤
识别需要幂等性的操作
选择合适的幂等性实现方式
实现和测试幂等性逻辑
f.示例
使用数据库唯一索引防止重复订单创建
02.实现方式
a.算法
略
b.去重表
1.每次操作在第一次执行时,会生成一个全局唯一D,如订单D
2.在"去重表"中查询"1"中的1D是否已存在
3.如果已存在,直接返回结果;如果不存在,再执行核心操作(如支付),并将”1"中的D存入"去重表"中,最后返回结果
c.其他
insert前先select
加唯一索引
加悲观锁
加乐观锁
建防重表
状态机
分布式锁
token机制
1.9 [3]原则:数据共享
01.数据共享原则
a.定义
数据共享原则是指在分布式系统中,通过不同策略实现数据的共享和一致性
b.原理
a.Session Replication
在多个节点之间同步Session数据
b.Session Sticky
通过负载均衡将请求固定到特定节点
c.独立Session服务器
使用集中式存储管理Session数据
c.常用API
Redis、Memcached用于Session存储
d.使用步骤
选择合适的数据共享策略
配置和部署共享组件
e.示例
使用Redis作为集中式Session存储,所有应用服务器从Redis获取Session数据
02.实现方式
a.Session Replication
在客户端第一次发出请求后,处理该请求的服务端就会创建一个与之对应的Session?
对象,用于保存客户端的状态信息,之后为了让其他服务器也能保存一份此Session对象,就需要将此Session对象在各个服务端节点之间进行同步
优点:数据共享后,客户端只要向该集群中的任何一台机器成功发送过一次请求,就能够在全部的集群节点进行访问
b.Session Stidky
Session Stidky:通过Nginx等负载均衡工具对各个用户进行标记(例如对Cookie标记),使每个用户在经过负载工具后都请求固定的服务节点
优点:固定的请求节点
缺点:不支持高可用,每份数据都需要单独处理
c.独立Session服务器
将系统中所有的Session对象都存放到一个独立的Session服务中,之后各个应用服务器再分别从这个Session服务中获取需要的Session对象
步骤:
1.查询redis中的session是否存在
2.如果存在,则登陆!如果不存在,则不登陆
1.10 [3]原则:无状态
01.无状态原则
a.定义
将状态建立存储,从而实现应用服务的无状态
b.原理
将状态信息存储在外部系统(如数据库、缓存)中,而不是应用服务器内
c.优点
1.在“无状态“的服务中,单个服务的宕机、重启等都不会影响到集群中的其他服务,并且很容易对应用服务进行横向扩展
2.另一方面,将带有数据的服务设置为"有状态”,并进行集群的"集中部署”(如ySQL集群),可以降低集群内部数据同步带来的延迟
d.常用API
数据库、缓存系统(如Redis)
e.使用步骤
识别应用中的状态信息
将状态信息外部化
设计和实现无状态服务
f.示例
将用户会话信息存储在Redis中,实现无状态的Web服务
1.11 [4]高并发、高性能、高可用
00.概念
a.总结
高并发【同时更多的人访问】
高性能【响应时间更短,速度更快】
高可用【小刀电动车,没电也能跑】
b.分布式
分布式更多的一个概念,是为了解决单个物理服务器容量和性能瓶颈问题而采用的优化手段。该领域需要解决的问题极多,在不同的技术层面上,又包括:分布式文件系统、分布式缓存、分布式数据库、分布式计算等,一些名词如Hadoop、zookeeper、MQ等都跟分布式有关。从理念上讲,分布式的实现有两种形式:
水平扩展:当一台机器扛不住流量时,就通过添加机器的方式,将流量平分到所有服务器上,所有机器都可以提供相当的服务;
垂直拆分:前端有多种查询需求时,一台机器扛不住,可以将不同的需求分发到不同的机器上,比如A机器处理余票查询的请求,B机器处理支付的请求。
c.高并发
相对于分布式来讲,高并发在解决的问题上会集中一些,其反应的是同时有多少量:比如在线直播服务,同时有上万人观看。
高并发可以通过分布式技术去解决,将并发流量分到不同的物理服务器上。但除此之外,还可以有很多其他优化手段:比如使用缓存系统,将所有的,静态内容放到CDN等;还可以使用多线程技术将一台服务器的服务能力最大化。
d.多线程
多线程是指从软件或者硬件上实现多个线程并发执行的技术,它更多的是解决CPU调度多个进程的问题,从而让这些进程看上去是同时执行(实际是交替运行的)。
这几个概念中,多线程解决的问题是最明确的,手段也是比较单一的,基本上遇到的最大问题就是线程安全。在JAVA语言中,需要对JVM内存模型、指令重排等深入了解,才能写出一份高质量的多线程代码
01.高并发(同时更多的人访问)
a.简介
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
-----------------------------------------------------------------------------------------------------
高并发(High Concurrency)是一种系统运行过程中遇到的一种“短时间内遇到大量操作请求”的情况,
主要发生在web系统集中大量访问收到大量请求(例如:12306的抢票情况;天猫双十一活动)。
该情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求、数据库的操作等。
b.特点
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
c.如何提高并发能力
a.垂直扩展
增强单机硬件性能(优先):例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G。
提升单机架构性能:例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间。
总结:管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
b.水平扩展
只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,难点在于:如何在架构各层进行可水平扩展的设计。
d.高并发和多线程的关系和区别
a.误区
“高并发和多线程”总是被一起提起,给人感觉两者好像相等,实则 高并发 ≠ 多线程
b.多线程
多线程是Java的特性,因为现在cpu都是多核多线程的,可以同时执行几个任务,为了提高jvm的执行效率,Java提供了这种多线程的机制,以增强数据处理效率。
多线程对应的是cpu,高并发对应的是访问请求,可以用单线程处理所有访问请求,也可以用多线程同时处理访问请求。
在过去单CPU时代,单任务在一个时间点只能执行单一程序。之后发展到多任务阶段,计算机能在同一时间点并行执行多任务或多进程。虽然并不是真正意义上的“同一时间点”,而是多个任务或进程共享一个CPU,并交由操作系统来完成多任务间对CPU的运行切换,以使得每个任务都有机会获得一定的时间片运行。
后来发展到多线程技术,使得在一个程序内部能拥有多个线程并行执行。一个线程的执行可以被认为是一个CPU在执行该程序。当一个程序运行在多线程下,就好像有多个CPU在同时执行该程序。
总之,多线程即可以这么理解:多线程是处理高并发的一种编程方法,即并发需要用多线程实现。
c.高并发
高并发不是JAVA的专有的东西,是语言无关的广义的,为提供更好互联网服务而提出的概念。典型的场景,例如:12306抢火车票,天猫双十一秒杀活动等。
该情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求,数据库的操作等。如果高并发处理不好,不仅仅降低了用户的体验度(请求响应时间过长),同时可能导致系统宕机,严重的甚至导致OOM异常,系统停止工作等。
e.Java多线程并发技术
a.并发编程三要素(volatile)
原子性:即一个不可再被分割的颗粒。在Java中原子性指的是一个或多个操作要么全部执行成功要么全部执行失败。
有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行重排序)
可见性:当多个线程访问同一个变量时,如果其中一个线程对其作了修改,其他线程能立即获取到最新的值。
b.线程的五大状态
创建状态:当用 new 操作符创建一个线程的时候
就绪状态:调用 start 方法,处于就绪状态的线程并不一定马上就会执行 run 方法,还需要等待CPU的调度
运行状态:CPU 开始调度线程,并开始执行 run 方法
阻塞状态:线程的执行过程中由于一些原因进入阻塞状态比如:调用 sleep 方法、尝试去得到一个锁等等
死亡状态:run 方法执行完 或者 执行过程中遇到了一个异常
c.悲观锁与乐观锁
悲观锁:每次操作都会加锁,会造成线程阻塞(synchronized)。
乐观锁:每次操作不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止,不会造成线程阻塞。
d.线程之间的协作
线程间的协作有:wait/notify/notifyAll/Condition/Lock等
e.synchronized 关键字
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
1)修饰一个代码块:被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象
2)修饰一个方法:被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象
3)修改一个静态的方法:其作用的范围是整个静态方法,作用的对象是这个类的所有对象
4)修改一个类:其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
f.CAS
CAS全称是Compare And Swap,即比较替换,是实现并发应用到的一种技术。操作包含三个操作数—内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
CAS存在三大问题:
ABA问题(AtomicReference);
循环时间长开销大;
以及只能保证一个共享变量的原子操作(AtomicInteger、Unsafe);
g.线程池
如果我们使用线程的时候就去创建一个线程,虽然简单,但是存在很大的问题。如果并发的线程数量很多,
并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,
因为频繁创建线程和销毁线程需要时间。线程池通过复用可以大大减少线程频繁创建与销毁带来的性能上的损耗。
f.高并发技术解决方案
a.方案
CDN
限流
缓存
消息队列
降级与熔断
应用拆分
Nosql与RDS
数据库垂直拆
分库分表
b.怎样提高系统的高并发能力?
1、静态资源结合CDN(Content Delivery Network)来解决图片文件等访问
2、分布式缓存:redis、memcached等。
3、消息队列中间件:rocketMq、activeMQ、kafka等,解决大量消息的异步处理能力。
4、应用拆分:一个工程被拆分为多个工程部署,利用RPC(微服务)解决多工程之间的通信。
5、数据库垂直拆分和水平拆分(分库分表)等。
6、数据库读写分离,解决大数据的查询问题。
7、利用nosql ,例如mongoDB配合mysql组合使用。
8、建立大数据访问情况下的服务降级以及限流机制等。
02.高性能(响应时间更短,速度更快)
a.简介
简单的说,高性能(High Performance)就是指程序处理速度快,所占内存少,cpu占用率低。
高并发和高性能是紧密相关的,提高应用的性能,是肯定可以提高系统的并发能力的。
应用性能优化的时候,对于计算密集型和IO密集型还是有很大差别,需要分开来考虑。
增加服务器资源(CPU、内存、服务器数量),绝大部分时候是可以提高应用的并发能力和性能
(前提是应用能够支持多任务并行计算,多服务器分布式计算才行),但也是要避免其中的一些问题,才可以更好的更有效率的利用服务器资源。
b.提高性能的注意事项
避免因为IO阻塞让CPU闲置,导致CPU的浪费。
避免多线程间增加锁来保证同步,导致并行系统串行化。
免创建、销毁、维护太多进程、线程,导致操作系统浪费资源在调度上。
避免分布式系统中多服务器的关联,比如:依赖同一个mysql,程序逻辑中使用分布式锁,导致瓶颈在mysql,分布式又变成串行化运算。
03.高可用(小刀电动车,没电也能跑)
a.简介
高可用性(High Availability)通常来描述一个系统经过专门的设计,
从而减少停工时间,而保持其服务的高度可用性(一直都能用)。
全年停机不能超过31.5秒,
6个9的性能:一直能用的概率为99.9999%
b.高可用注意事项
避免单点:使用单个服务器,一旦该服务器意外宕机,将导致服务不可用
使用“集群”:一台服务器挂了,还有其他后备服务器能够顶上
心跳机制:用于监控服务器状态,挂了就进行故障修复
04.误区
a.问题1
a.描述
@Scheduled(cron = "*/20 * * * * ?")
每个20秒触发,两个进程属于多线程不,会触发锁步不?
b.说明
这不一定属于高并发。高并发通常是指在同一时间内,有大量请求或操作同时发生。如果你只有少数几个进程并且每个进程每20秒只触发一次,那么并发程度较低。
不过,如果你有很多进程同时在运行,每个进程都在定时触发任务,这可能会导致资源竞争,从而影响系统性能。要判断是否属于高并发,需要考虑以下几点:
请求数量:每秒有多少请求。
系统资源:CPU、内存等资源的使用情况。
响应时间:处理请求的时间是否变长。
b.问题2
...
1.12 [4]高并发:15个手段
00.汇总
a.分类1
关于接口高并发的问题,我理解的是当大量用户同时访问接口时,需要采取一些措施来保证系统的稳定运行。
在项目中我们通常会考虑几个方面:
一是通过缓存减轻数据库压力,把经常访问的数据放到Redis里
二是使用消息队列处理非核心业务,让主接口能快速响应
三是在服务器层面做负载均衡,分散请求压力
-----------------------------------------------------------------------------------------------------
如果真的遇到性能瓶颈,还会考虑数据库分库分表和代码层面的优化。
说实话,我对分布式锁、限流算法这些高级技术的了解还不是很深入,主要是通过一些基础的方式解决并发问题。
b.分类2
01.分而治之,横向扩展
02.微服务拆分 (系统拆分)
03.分库分表
04.池化技术
05.主从分离
06.使用缓存
07.CDN,加速静态资源访问
08.消息队列,削峰
09.ElasticSearch
10.降级熔断
11.限流
12.异步
13.接口的常规优化
14.压力测试确定系统瓶颈
15.应对突发流量峰值:扩容+切流
01.分而治之,横向扩展
如果你只部署一个应用,只部署一台服务器,那抗住的流量请求是非常有限的
并且,单体的应用,有单点的风险,如果它挂了,那服务就不可用了
因此,设计一个高并发系统,我们可以分而治之,横向扩展
---------------------------------------------------------------------------------------------------------
也就是说,采用分布式部署的方式,部署多台服务器,把流量分流开
让每个服务器都承担一部分的并发和流量,提升整体系统的并发能力
02.微服务拆分 (系统拆分)
要提高系统的吞吐,提高系统的处理并发请求的能力
除了采用分布式部署的方式外,还可以做微服务拆分,这样就可以达到分摊请求流量的目的,提高了并发能力
---------------------------------------------------------------------------------------------------------
所谓的微服务拆分,其实就是把一个单体的应用,按功能单一性,拆分为多个服务模块
比如一个电商系统,拆分为用户系统、订单系统、商品系统等等
03.分库分表
当业务量暴增的话,MySQL单机磁盘容量会撑爆。并且,我们知道数据库连接数是有限的
在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!高并发场景下,会出现too many connections报错
---------------------------------------------------------------------------------------------------------
所以高并发的系统,需要考虑拆分为多个数据库,来抗住高并发的毒打
而假如你的单表数据量非常大,存储和查询的性能就会遇到瓶颈了,如果你做了很多优化之后还是无法提升效率的时候
就需要考虑做分表了。一般千万级别数据量,就需要分表,每个表的数据量少一点,提升SQL查询性能
---------------------------------------------------------------------------------------------------------
当面试官问要求你设计一个高并发系统的时候,一般都要说到分库分表这个点
04.池化技术
在高并发的场景下,数据库连接数可能成为瓶颈,因为连接数是有限的
---------------------------------------------------------------------------------------------------------
我们的请求调用数据库时,都会先获取数据库的连接,然后依靠这个连接来查询数据,搞完收工,最后关闭连接,释放资源
如果我们不用数据库连接池的话,每次执行SQL,都要创建连接和销毁连接,这就会导致每个查询请求都变得更慢了,相应的,系统处理用户请求的能力就降低了
---------------------------------------------------------------------------------------------------------
因此,需要使用池化技术,即数据库连接池、HTTP 连接池、Redis 连接池等等
使用数据库连接池,可以避免每次查询都新建连接,减少不必要的资源开销,通过复用连接池,提高系统处理高并发请求的能力
同理,我们使用线程池,也能让任务并行处理,更高效地完成任务
05.主从分离
通常来说,一台单机的MySQL服务器,可以支持500左右的TPS和10000左右的QPS,即单机支撑的请求访问是有限的
因此你做了分布式部署,部署了多台机器,部署了主数据库、从数据库
---------------------------------------------------------------------------------------------------------
但是,如果双十一搞活动,流量肯定会猛增的。如果所有的查询请求,都走主库的话,主库肯定扛不住
因为查询请求量是非常非常大的。因此一般都要求做主从分离,然后实时性要求不高的读请求
都去读从库,写的请求或者实时性要求高的请求,才走主库。这样就很好保护了主库,也提高了系统的吞吐
---------------------------------------------------------------------------------------------------------
当然,如果回答了主从分离,面试官可能扩展开问你主从复制原理,问你主从延迟问题等等,这块大家需要全方位复习好哈
06.使用缓存
无论是操作系统,浏览器,还是一些复杂的中间件,你都可以看到缓存的影子
我们使用缓存,主要是提升系统接口的性能,这样高并发场景,你的系统就可以支持更多的用户同时访问
---------------------------------------------------------------------------------------------------------
常用的缓存包括:Redis缓存,JVM本地缓存,memcached等等
就拿Redis来说,它单机就能轻轻松松应对几万的并发,你读场景的业务,可以用缓存来抗高并发
---------------------------------------------------------------------------------------------------------
缓存虽然用得爽,但是要注意缓存使用的一些问题:缓存与数据库的一致性问题、缓存雪崩、缓存穿透、缓存击穿
如果大家打算使用Redis的话,需要知道一些注意点,可以看下我之前的这篇文章哈,挺好的
07.CDN,加速静态资源访问
商品图片,icon等等静态资源,可以对页面做静态化处理,减少访问服务端的请求
如果用户分布在全国各地,有的在上海,有的在深圳,地域相差很远,网速也各不相同
为了让用户最快访问到页面,可以使用CDN。CDN可以让用户就近获取所需内容
---------------------------------------------------------------------------------------------------------
Content Delivery Network/Content Distribution Network
翻译过来就是内容分发网络,它表示将静态资源分发到位于多个地理位置机房的服务器,可以做到数据就近访问
加速了静态资源的访问速度,因此让系统更好处理正常别的动态请求
08.消息队列,削峰
我们搞一些双十一、双十二等运营活动时,需要避免流量暴涨,打垮应用系统的风险。因此一般会引入消息队列,来应对高并发的场景
假设你的应用系统每秒最多可以处理2k个请求,每秒却有5k的请求过来,可以引入消息队列,应用系统每秒从消息队列拉2k请求处理得了
---------------------------------------------------------------------------------------------------------
有些伙伴担心这样可能会出现消息积压的问题:
首先,搞一些运营活动,不会每时每刻都那么多请求过来你的系统(除非有人恶意攻击),高峰期过去后,积压的请求可以慢慢处理
其次,如果消息队列长度超过最大数量,可以直接抛弃用户请求或跳转到错误页面
09.ElasticSearch
Elasticsearch,大家都使用得比较多了吧,一般搜索功能都会用到它
它是一个分布式、高扩展、高实时的搜索与数据分析引擎,简称为ES
---------------------------------------------------------------------------------------------------------
我们在聊高并发,为啥聊到ES呢?因为ES可以扩容方便,天然支撑高并发
当数据量大的时候,不用动不动就加机器扩容,分库等等,可以考虑用ES来支持简单的查询搜索、统计类的操作
10.降级熔断
熔断降级是保护系统的一种手段。当前互联网系统一般都是分布式部署的
而分布式系统中偶尔会出现某个基础服务不可用,最终导致整个系统不可用的情况, 这种现象被称为服务雪崩效应
---------------------------------------------------------------------------------------------------------
比如分布式调用链路A->B->C,
如果服务C出现问题,比如是因为慢SQL导致调用缓慢,那将导致B也会延迟,从而A也会延迟
堵住的A请求会消耗占用系统的线程、IO、CPU等资源。当请求A的服务越来越多
占用计算机的资源也越来越多,最终会导致系统瓶颈出现,造成其他的请求同样不可用,最后导致业务系统崩溃
为了应对服务雪崩, 常见的做法是熔断和降级。最简单是加开关控制,当下游系统出问题时
开关打开降级,不再调用下游系统。还可以选用开源组件Hystrix来支持
你要保证设计的系统能应对高并发场景,那肯定要考虑熔断降级逻辑进来
11.限流
限流也是我们应对高并发的一种方案。我们当然希望,在高并发大流量过来时,系统能全部请求都正常处理
但是有时候没办法,系统的CPU、网络带宽、内存、线程等资源都是有限的。因此,我们要考虑限流
---------------------------------------------------------------------------------------------------------
如果你的系统每秒扛住的请求是一千,如果一秒钟来了十万请求呢?
换个角度就是说,高并发的时候,流量洪峰来了,超过系统的承载能力,怎么办呢?
---------------------------------------------------------------------------------------------------------
这时候,我们可以采取限流方案。就是为了保护系统,多余的请求,直接丢弃
什么是限流:在计算机网络中,限流就是控制网络接口发送或接收请求的速率
它可防止DoS攻击和限制Web爬虫。限流,也称流量控制
是指系统在面临高并发,或者大流量请求的情况下,限制新的请求对系统的访问,从而保证系统的稳定性
可以使用Guava的RateLimiter单机版限流,也可以使用Redis分布式限流,还可以使用阿里开源组件sentinel限流
12.异步
什么是异步呢?以方法调用为例,它代表调用方要阻塞等待被调用方法中的逻辑执行完成
这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩
异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调
事件通知等方式将结果反馈给调用方
---------------------------------------------------------------------------------------------------------
因此,设计一个高并发的系统,需要在恰当的场景使用异步。如何使用异步呢
后端可以借用消息队列实现。比如在海量秒杀请求过来时,先放到消息队列中,快速响应用户
告诉用户请求正在处理中,这样就可以释放资源来处理更多的请求。秒杀请求处理完后,通知用户秒杀抢购成功或者失败
13.接口的常规优化
1.批量思想:批量操作数据库
2.异步思想:耗时操作,考虑放到异步执行
3.空间换时间思想:恰当使用缓存
4.预取思想:提前初始化到缓存
5.池化思想:预分配与循环使用
6.事件回调思想:拒绝阻塞等待
7.远程调用由串行改为并行
8.锁粒度避免过粗
9.切换存储方式:文件中转暂存数据
10.索引
11.优化SQL
12.避免大事务问题
13.优化深分页问题
14.优化程序结构
15.压缩传输内容
16.海量数据处理
17.线程池设计要合理
18.机器问题(fullIGC、线程打满等)
14.压力测试确定系统瓶颈
压测完要分析整个调用链路,性能可能出现问题是网络层(如带宽)、Nginx层、服务层、还是数据路缓存等中间件等等
loadrunner是一款不错的压力测试工具,jmeter则是接口性能测试工具,都可以来做下压测
15.应对突发流量峰值:扩容+切流
如果是突发的流量高峰,除了降级、限流保证系统不跨,我们可以采用这两种方案,保证系统尽可能服务用户请求
扩容:比如增加从库、提升配置的方式,提升系统/组件的流量承载能力。比如增加MySQL、Redis从库来处理查询请求
切流量:服务多机房部署,如果高并发流量来了,把流量从一个机房切换到另一个机房
1.13 [4]高并发:同时更多的人访问
00.汇总
关于接口高并发的问题,我理解的是当大量用户同时访问接口时,需要采取一些措施来保证系统的稳定运行。
在项目中我们通常会考虑几个方面:
一是通过缓存减轻数据库压力,把经常访问的数据放到Redis里
二是使用消息队列处理非核心业务,让主接口能快速响应
三是在服务器层面做负载均衡,分散请求压力
---------------------------------------------------------------------------------------------------------
如果真的遇到性能瓶颈,还会考虑数据库分库分表和代码层面的优化。
说实话,我对分布式锁、限流算法这些高级技术的了解还不是很深入,主要是通过一些基础的方式解决并发问题。
01.优化代码
1.少new对象,使用更好的算法
2.使用每一个方法,类时都考虑一下是否有更好的替代方法,类
3.简洁,能快速解决的事儿,不要转圈圈
02.优化数据库
1.能单表一定不多表,能一句完成的一定不多次
2.能不用函数,就不用函数,除非你知道它的效率很高。(但很多的函数效率真的很差)
3.写完自己先试试,实现的方式通常都不止一种,选个最好的。
4.建立索引,这个更加要试试,很可能你的索引会使你的请求更加的慢(会起反作用、或不生效)
5.建表遵循三范式(可以不遵循,使用第四范式 :反三范式,一切为了效率!!!)
6.使用预编译、连接池(这个大概不需要说)
03.尽量少的请求
1.前端做表单验证,尽量保证请求有效
2.后端做请求时间拦截,保证不会在很短的时间里连续请求(防止for循环请求啊,或者用户连续点击)
3.做缓存,对用户经常访问的数据放到缓存中去
4.请求队列,对部分高请求的接口做请求队列,实在太高超出系统的负荷,对后面的请求直接返回“系统繁忙”(抛弃请求,保证大部分请求的成功)
5.做页面缓存,就像用户访问的首页,同样的页面,可以不经过请求程序,直接把缓存的页面返回给用户。
6.批量提交,在一些情况下可以吧用户的插入请求积攒一起提交。
04.增加服务器
1.做负载平衡
2.做微服务(服务模块化)
3.做数据库的读写分离
1.14 [4]高性能:响应时间更短,速度更快
00.汇总
a.分类1
尽量指定类、方法的final修饰符
尽量重用对象
尽可能使用局部变量
及时关闭流
尽量减少对变量的重复计算
尽量采用懒加载的策略,即在需要的时候才创建
慎用异常
不要在循环中使用try…catch…,应该把其放在最外层
如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度
当复制大量数据时,使用System.arraycopy()命令
乘法和除法使用移位操作
循环内不要不断创建对象引用
基于效率和类型检查的考虑,应该尽可能使用array,无法确定数组大小时才使用ArrayList
尽量使用HashMap、ArrayList、StringBuilder,除非线程安全需要,否则不推荐使用Hashtable、Vector、StringBuffer,后三者由于使用同步机制而导致了性能开销
不要将数组声明为public static final
尽量在合适的场合使用单例
尽量避免随意使用静态变量
及时清除不再需要的会话
实现RandomAccess接口的集合比如ArrayList,应当使用最普通的for循环而不是foreach循环来遍历
使用同步代码块替代同步方法
b.分类2
将常量声明为static final,并以大写命名
不要创建一些不使用的对象,不要导入一些不使用的类
程序运行过程中避免使用反射
使用数据库连接池和线程池
使用带缓冲的输入输出流进行IO操作
顺序插入和随机访问比较多的场景使用ArrayList,元素删除和中间插入比较多的场景使用LinkedList
不要让public方法中有太多的形参
字符串变量和字符串常量equals的时候将字符串常量写在前面
请知道,在java中if (i == 1)和if (1 == i)是没有区别的,但从阅读习惯上讲,建议使用前者
不要对数组使用toString()方法
不要对超出范围的基本数据类型做向下强制转型
公用的集合类中不使用的数据一定要及时remove掉
把一个基本数据类型转为字符串,基本数据类型.toString()是最快的方式、String.valueOf(数据)次之、数据+""最慢
使用最有效率的方式去遍历Map
对资源的close()建议分开操作
01.如何实现高性能1
a.尽量指定类、方法的final修饰符
带有final修饰符的类是不可派生的。在Java核心API中,有许多应用final的例子,
例如java.lang.String,整个类都是final的。为类指定final修饰符可以让类不可以被继承,
为方法指定final修饰符可以让方法不可以被重写。如果指定了一个类为final,
则该类所有的方法都是final的。Java编译器会寻找机会内联所有的final方法,
内联对于提升Java运行效率作用重大,具体参见Java运行期优化。此举能够使性能平均提高50%。
b.尽量重用对象
特别是String对象的使用,出现字符串连接时应该使用StringBuilder/StringBuffer代替。
由于Java虚拟机不仅要花时间生成对象,以后可能还需要花时间对这些对象进行垃圾回收和处理,
因此,生成过多的对象将会给程序的性能带来很大的影响。
c.尽可能使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中速度较快,其他变量,
如静态变量、实例变量等,都在堆中创建,速度较慢。
另外,栈中创建的变量,随着方法的运行结束,这些内容就没了,不需要额外的垃圾回收。
d.及时关闭流
Java编程过程中,进行数据库连接、I/O流操作时务必小心,在使用完毕后,及时关闭以释放资源。
因为对这些大对象的操作会造成系统大的开销,稍有不慎,将会导致严重的后果。
e.尽量减少对变量的重复计算
明确一个概念,对方法的调用,即使方法中只有一句语句,也是有消耗的,
包括创建栈帧、调用方法时保护现场、调用方法完毕时恢复现场等。所以例如下面的操作:
for (int i = 0; i < list.size(); i++)
{...}
建议替换为:
for (int i = 0, int length = list.size(); i < length; i++)
{...}
这样,在list.size()很大的时候,就减少了很多的消耗
f.尽量采用懒加载的策略,即在需要的时候才创建
例如:
String str = "aaa";if (i == 1)
{
list.add(str);
}
建议替换为:
if (i == 1)
{
String str = "aaa";
list.add(str);
}
g.慎用异常
异常对性能不利。
抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用名为fillInStackTrace()的本地同步方法,
fillInStackTrace()方法检查堆栈,收集调用跟踪信息。
只要有异常被抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。
异常只能用于错误处理,不应该用来控制程序流程。
h.不要在循环中使用try…catch…,应该把其放在最外层
除非不得已。如果毫无理由地这么写了,只要你的领导资深一点、有强迫症一点,
八成就要骂你为什么写出这种垃圾代码来了
i.如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度
比如ArrayList、LinkedLlist、StringBuilder、StringBuffer、HashMap、HashSet等等,以StringBuilder为例:
(1)StringBuilder() // 默认分配16个字符的空间
(2)StringBuilder(int size) // 默认分配size个字符的空间
(3)StringBuilder(String str) // 默认分配16个字符+str.length()个字符空间
-------------------------------------------------------------------------------------------------
可以通过类(这里指的不仅仅是上面的StringBuilder)的来设定它的初始化容量,这样可以明显地提升性能。
比如StringBuilder吧,length表示当前的StringBuilder能保持的字符数量。
因为当StringBuilder达到最大容量的时候,它会将自身容量增加到当前的2倍再加2,
无论何时只要StringBuilder达到它的最大容量,它就不得不创建一个新的字符数组然后将旧的字符
数组内容拷贝到新字符数组中—-这是十分耗费性能的一个操作。试想,如果能预估到字符数组中大概要存放5000
个字符而不指定长度,最接近5000的2次幂是4096,每次扩容加的2不管,那么:
(1)在4096 的基础上,再申请8194个大小的字符数组,加起来相当于一次申请了12290个大小的字符数组,如果一开始能指定5000个大小的字符数组,就节省了一倍以上的空间
(2)把原来的4096个字符拷贝到新的的字符数组中去
这样,既浪费内存空间又降低代码运行效率。所以,给底层以数组实现的集合、工具类设置一个合理的初始化容量是错不了的,这会带来立竿见影的效果。
但是,注意,像HashMap这种是以数组+链表实现的集合,别把初始大小和你估计的大小设置得一样,
因为一个table上只连接一个对象的可能性几乎为0。初始大小建议设置为2的N次幂,如果能估计到有2000个元素,
设置成new HashMap(128)、new HashMap(256)都可以。
j.当复制大量数据时,使用System.arraycopy()命令
k.乘法和除法使用移位操作
例如:
for (val = 0; val < 100000; val += 5)
{
a = val * 8;
b = val / 2;
}
用移位操作可以极大地提高性能,因为在计算机底层,对位的操作是最方便、最快的,因此建议修改为:
-------------------------------------------------------------------------------------------------
for (val = 0; val < 100000; val += 5)
{
a = val << 3;
b = val >> 1;
}
移位操作虽然快,但是可能会使代码不太好理解,因此最好加上相应的注释。
l.循环内不要不断创建对象引用
例如:
for (int i = 1; i <= count; i++)
{
Object obj = new Object();
}
这种做法会导致内存中有count份Object对象引用存在,count很大的话,就耗费内存了,建议为改为:
-------------------------------------------------------------------------------------------------
Object obj = null;
for (int i = 0; i <= count; i++)
{
obj = new Object();
}
这样的话,内存中只有一份Object对象引用,每次new Object()的时候,Object对象引用指向不同的Object罢了,但是内存中只有一份,这样就大大节省了内存空间了。
m.基于效率和类型检查的考虑,应该尽可能使用array,无法确定数组大小时才使用ArrayList
n.尽量使用HashMap、ArrayList、StringBuilder,除非线程安全需要,否则不推荐使用Hashtable、Vector、StringBuffer,后三者由于使用同步机制而导致了性能开销
o.不要将数组声明为public static final
因为这毫无意义,这样只是定义了引用为static final,数组的内容还是可以随意改变的,将数组声明为public更是一个安全漏洞,这意味着这个数组可以被外部类所改变
p.尽量在合适的场合使用单例
使用单例可以减轻加载的负担、缩短加载的时间、提高加载的效率,但并不是所有地方都适用于单例,简单来说,单例主要适用于以下三个方面:
(1)控制资源的使用,通过线程同步来控制资源的并发访问
(2)控制实例的产生,以达到节约资源的目的
(3)控制数据的共享,在不建立直接关联的条件下,让多个不相关的进程或线程之间实现通信
q.尽量避免随意使用静态变量
要知道,当某个对象被定义为static的变量所引用,那么gc通常是不会回收这个对象所占有的堆内存的,如:
public class A
{
private static B b = new B();
}
此时静态变量b的生命周期与A类相同,如果A类不被卸载,那么引用B指向的B对象会常驻内存,直到程序终止
r.及时清除不再需要的会话
为了清除不再活动的会话,许多应用服务器都有默认的会话超时时间,一般为30分钟。当应用服务器需要保存更多的会话时,如果内存不足,那么操作系统会把部分数据转移到磁盘,应用服务器也可能根据MRU(最近最频繁使用)算法把部分不活跃的会话转储到磁盘,甚至可能抛出内存不足的异常。如果会话要被转储到磁盘,那么必须要先被序列化,在大规模集群中,对对象进行序列化的代价是很昂贵的。
因此,当会话不再需要时,应当及时调用HttpSession的invalidate()方法清除会话。
s.实现RandomAccess接口的集合比如ArrayList,应当使用最普通的for循环而不是foreach循环来遍历
这是JDK推荐给用户的。JDK API对于RandomAccess接口的解释是:
实现RandomAccess接口用来表明其支持快速随机访问,此接口的主要目的是允许一般的算法更改其行为,
从而将其应用到随机或连续访问列表时能提供良好的性能。实际经验表明,实现RandomAccess接口的类实例,
假如是随机访问的,使用普通for循环效率将高于使用foreach循环;
反过来,如果是顺序访问的,则使用Iterator会效率更高。可以使用类似如下的代码作判断:
-------------------------------------------------------------------------------------------------
if (list instanceof RandomAccess)
{ for (int i = 0; i < list.size(); i++){}
}else{
Iterator<?> iterator = list.iterable(); while (iterator.hasNext()){iterator.next()}
}
foreach循环的底层实现原理就是迭代器Iterator,参见Java语法糖1:可变长度参数以及foreach循环原理。所以后半句”反过来,如果是顺序访问的,则使用Iterator会效率更高”的意思就是顺序访问的那些类实例,使用foreach循环去遍历。
t.使用同步代码块替代同步方法
这点在多线程模块中的synchronized锁方法块一文中已经讲得很清楚了,
除非能确定一整个方法都是需要进行同步的,否则尽量使用同步代码块,避免对那些不需要进行同步的代码也进行了同步,
影响了代码执行效率。
02.如何实现高性能2
a.将常量声明为static final,并以大写命名
这样在编译期间就可以把这些内容放入常量池中,避免运行期间计算生成常量的值。
另外,将常量的名字以大写命名也可以方便区分出常量与变量
b.不要创建一些不使用的对象,不要导入一些不使用的类
这毫无意义,如果代码中出现”The value of the local variable i is not used”、”The import java.util is never used”,那么请删除这些无用的内容
c.程序运行过程中避免使用反射
关于,请参见反射。反射是Java提供给用户一个很强大的功能,功能强大往往意味着效率不高。
不建议在程序运行过程中使用尤其是频繁使用反射机制,特别是Method的invoke方法,如果确实有必要,
一种建议性的做法是将那些需要通过反射加载的类在项目启动的时候通过反射实例化出一个对象并放入内存—-
用户只关心和对端交互的时候获取最快的响应速度,并不关心对端的项目启动花多久时间。
d.使用数据库连接池和线程池
这两个池都是用于重用对象的,前者可以避免频繁地打开和关闭连接,后者可以避免频繁地创建和销毁线程
e.使用带缓冲的输入输出流进行IO操作
带缓冲的输入输出流,即BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream,这可以极大地提升IO效率
f.顺序插入和随机访问比较多的场景使用ArrayList,元素删除和中间插入比较多的场景使用LinkedList
这个,理解ArrayList和LinkedList的原理就知道了
g.不要让public方法中有太多的形参
public方法即对外提供的方法,如果给这些方法太多形参的话主要有两点坏处:
1、违反了面向对象的编程思想,Java讲求一切都是对象,太多的形参,和面向对象的编程思想并不契合
2、参数太多势必导致方法调用的出错概率增加
至于这个”太多”指的是多少个,3、4个吧。比如我们用JDBC写一个insertStudentInfo方法,有10个学生信息字段要插如Student表中,可以把这10个参数封装在一个实体类中,作为insert方法的形参
h.字符串变量和字符串常量equals的时候将字符串常量写在前面
这是一个比较常见的小技巧了,如果有以下代码:
String str = "123";
if (str.equals("123")) {
...
}
建议修改为:
String str = "123";
if ("123".equals(str))
{
...
}
这么做主要是可以避免空指针异常
i.请知道,在java中if (i == 1)和if (1 == i)是没有区别的,但从阅读习惯上讲,建议使用前者
平时有人问,”if (i == 1)”和”if (1== i)”有没有区别,这就要从C/C++讲起。
在C/C++中,”if (i == 1)”判断条件成立,是以0与非0为基准的,0表示false,非0表示true,如果有这么一段代码:
int i = 2;
if (i == 1)
{
...
}else{
...
}
C/C++判断”i==1″不成立,所以以0表示,即false。但是如果:
int i = 2;if (i = 1) { ... }else{ ... }
万一程序员一个不小心,把”if (i == 1)”写成”if (i = 1)”,这样就有问题了。在if之内将i赋值为1,if判断里面的内容非0,返回的就是true了,但是明明i为2,比较的值是1,应该返回的false。这种情况在C/C++的开发中是很可能发生的并且会导致一些难以理解的错误产生,所以,为了避免开发者在if语句中不正确的赋值操作,建议将if语句写为:
int i = 2;if (1 == i) { ... }else{ ... }
这样,即使开发者不小心写成了”1 = i”,C/C++编译器也可以第一时间检查出来,因为我们可以对一个变量赋值i为1,但是不能对一个常量赋值1为i。
但是,在Java中,C/C++这种”if (i = 1)”的语法是不可能出现的,因为一旦写了这种语法,Java就会编译报错”Type mismatch: cannot convert from int to boolean”。但是,尽管Java的”if (i == 1)”和”if (1 == i)”在语义上没有任何区别,但是从阅读习惯上讲,建议使用前者会更好些。
j.不要对数组使用toString()方法
看一下对数组使用toString()打印出来的是什么:
public static void main(String[] args)
{ int[] is = new int[]{1, 2, 3};
System.out.println(is.toString());
}
结果是:
[I@18a992f
本意是想打印出数组内容,却有可能因为数组引用is为空而导致空指针异常。不过虽然对数组toString()没有意义,但是对集合toString()是可以打印出集合里面的内容的,因为集合的父类AbstractCollections重写了Object的toString()方法。
k.不要对超出范围的基本数据类型做向下强制转型
这绝不会得到想要的结果:
public static void main(String[] args)
{
long l = 12345678901234L;
int i = (int)l;
System.out.println(i);
}
我们可能期望得到其中的某几位,但是结果却是:
1942892530
解释一下。Java中long是8个字节64位的,所以12345678901234在计算机中的表示应该是:
0000 0000 0000 0000 0000 1011 0011 1010 0111 0011 1100 1110 0010 1111 1111 0010
一个int型数据是4个字节32位的,从低位取出上面这串二进制数据的前32位是:
0111 0011 1100 1110 0010 1111 1111 0010
这串二进制表示为十进制1942892530,所以就是我们上面的控制台上输出的内容。从这个例子上还能顺便得到两个结论:
1、整型默认的数据类型是int,long l = 12345678901234L,这个数字已经超出了int的范围了,所以最后有一个L,表示这是一个long型数。顺便,浮点型的默认类型是double,所以定义float的时候要写成””float f = 3.5f”
2、接下来再写一句”int ii = l + i;”会报错,因为long + int是一个long,不能赋值给int
l.公用的集合类中不使用的数据一定要及时remove掉
如果一个集合类是公用的(也就是说不是方法里面的属性),那么这个集合里面的元素是不会自动释放的,
因为始终有引用指向它们。所以,如果公用集合里面的某些数据不使用而不去remove掉它们,
那么将会造成这个公用集合不断增大,使得系统有内存泄露的隐患。
m.把一个基本数据类型转为字符串,基本数据类型.toString()是最快的方式、String.valueOf(数据)次之、数据+""最慢
把一个基本数据类型转为一般有三种方式,我有一个Integer型数据i,可以使用i.toString()、String.valueOf(i)、i+""三种方式,三种方式的效率如何,看一个测试:
public static void main(String[] args)
{
int loopTime = 50000;
Integer i = 0; long startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++)
{
String str = String.valueOf(i);
}
System.out.println("String.valueOf():" + (System.currentTimeMillis() - startTime) + "ms");
startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++)
{
String str = i.toString();
}
System.out.println("Integer.toString():" + (System.currentTimeMillis() - startTime) + "ms");
startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++)
{
String str = i + "";
}
System.out.println("i + "":" + (System.currentTimeMillis() - startTime) + "ms");
}
-------------------------------------------------------------------------------------------------
运行结果为:
String.valueOf():11ms Integer.toString():5ms i + "":25ms
所以以后遇到把一个基本数据类型转为String的时候,优先考虑使用toString()方法。至于为什么,很简单:
1、String.valueOf()方法底层调用了Integer.toString()方法,但是会在调用前做空判断
2、Integer.toString()方法就不说了,直接调用了
3、i + “”底层使用了StringBuilder实现,先用append方法拼接,再用toString()方法获取字符串
三者对比下来,明显是2最快、1次之、3最慢
n.使用最有效率的方式去遍历Map
遍历Map的方式有很多,通常场景下我们需要的是遍历Map中的Key和Value,那么推荐使用的、效率最高的方式是:
public static void main(String[] args)
{
HashMap<String, String> hm = new HashMap<String, String>();
hm.put("111", "222");
Set<Map.Entry<String, String>> entrySet = hm.entrySet();
Iterator<Map.Entry<String, String>> iter = entrySet.iterator(); while (iter.hasNext())
{
Map.Entry<String, String> entry = iter.next();
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
如果你只是想遍历一下这个Map的key值,那用”Set keySet = hm.keySet();”会比较合适一些
o.对资源的close()建议分开操作
意思是,比如我有这么一段代码:
try{
XXX.close();
YYY.close();
}catch (Exception e)
{
...
}
建议修改为:
try{ XXX.close(); }catch (Exception e) { ... }try{ YYY.close(); }catch (Exception e) { ... }
虽然有些麻烦,却能避免资源泄露。我们想,如果没有修改过的代码,万一XXX.close()抛异常了,那么就进入了cath块中了,YYY.close()不会执行,YYY这块资源就不会回收了,一直占用着,这样的代码一多,是可能引起资源句柄泄露的。而改为下面的写法之后,就保证了无论如何XXX和YYY都会被close掉。
2 微服务
2.1 [0]组件:3类
01.汇总
a.替代
SpringCloud
mini-spring-cloud
SpringCloudTencent
b.图示
特点 Dubbo Spring Cloud Netflix Spring Cloud Alibaba
开发语言 Java Java Java
服务治理 提供完整的服务治理功能 提供部分服务治理功能 提供完整的服务治理功能
服务注册与发现 ZooKeeper/Nacos Eureka/Consul Nacos
负载均衡 自带负载均衡策略 Ribbon Ribbon\Dubbo 负载均衡策略
服务调用 RPC 方式 RestTemplate/Feign Feign/RestTemplate/Dubbo
熔断器 Sentinel Hystrix Sentinel/Resilience4j
配置中心 Apollo Spring Cloud Config Nacos Config
API 网关 Higress/APISIX Zuul/Gateway Spring Cloud Gateway
分布式事务 Seata 不支持分布式事务 Seata
限流和降级 Sentinel Hystrix Sentinel
分布式追踪和监控 Skywalking Spring Cloud Sleuth + Zipkin SkyWalking 或 Sentinel Dashboard
微服务网格 Dubbo Mesh 不支持微服务网格 Service Mesh(Nacos+Dubbo Mesh)
社区活跃度 相对较高 目前较低 相对较高
孵化和成熟度 孵化较早,成熟度较高 成熟度较高 孵化较新,但迅速发展
02.组件
a.注册中心
Eureka:注册中心
Nacos:注册中心(Eureka) + 配置中心(Config)组合
rNacos:注册中心(Eureka) + 配置中心(Config)组合,rust版本
Apollo:注册中心(Eureka) + 配置中心(Config)组合,携程部门
b.负载均衡
Ribbon:负载均衡,客户端负载均衡
Feign:声明式REST客户端,基于接口注解
Dubbo+TripleX:负载均衡,RPC框架,自带负载均衡
c.服务调用
Feign-面向接口
Ribbon-面向URL
OpenFeign
Dubbo RPC
d.服务配置中心
Nacos Config:统一管理
Spring Cloud Config:官方
e.服务网关
Kong
Zuul1×
Zuul2.x
Linkred
Spring Cloud Gateway:统一入口、路由转发、过滤器、限流等
f.服务熔断
hystrix:奈飞,停止维护
sentinel:熔断降级、网关限流和QPS限制,带有Dashboard监控界面
resilience4j:轻量级熔断器
g.服务链路
CAT:美团+携程
Sleuth:Spring
Zipkin:Twitter
Pinpoint:韩国人
Eagleeye:阿里巴巴
skywalking:国人,移交Apache
快速入门:Spring Boot Admin、Micrometer + MailSender
企业级监控:Prometheus + Alertmanager、SkyWalking
免运维需求:Datadog、New Relic
h.分布式
seata:事务,支持AT、TCC、SAGA、XA模式
xxl-job:任务
redisson:锁
i.其他
arthas:在线诊断工具
03.Sentinel组件
a.替代Hystrix熔断降级
服务熔断、服务降级、依赖隔离
b.替代Guava RateLimiter限流
流量控制、QPS 限制、并发线程控制
c.替代Resilience4j服务容错
熔断器模式、舱壁模式、重试机制
d.部分替代Spring Cloud Gateway网关限流
网关流控、请求过滤、黑白名单
e.替代Eureka负载均衡的部分功能
服务保护、流量调度、集群流控
2.2 [1]断路器
01.概述
a.定义
断路器(Circuit Breaker)是一种用于防止系统在调用外部服务或组件时因故障而导致级联失败的设计模式
它通过监控服务调用的状态,在检测到故障时,快速失败并返回预定义的响应,从而保护系统的稳定性
b.原理
监控服务调用的成功和失败率,动态调整服务调用的状态
c.三种状态
a.关闭(Closed)
正常状态,允许请求通过。当失败率超过阈值时,断路器切换到打开状态
b.打开(Open)
断路器阻止请求通过,直接返回失败响应。经过一段时间后,断路器进入半开状态
c.半开(Half-Open)
允许部分请求通过以测试服务是否恢复。如果请求成功率达到要求,断路器切换回关闭状态;否则,重新进入打开状态
02.常用API
a.Hystrix(已停止维护)
HystrixCommand:用于定义断路器命令
HystrixCircuitBreaker:用于监控和管理断路器状态
b.Resilience4j
CircuitBreaker:核心接口,用于定义和管理断路器
CircuitBreakerConfig:用于配置断路器参数,如失败率阈值、等待时间等
03.使用步骤
a.选择库
选择合适的断路器库,如Resilience4j
b.配置断路器
定义断路器的参数,如失败率阈值、等待时间等
c.包装服务调用
使用断路器包装外部服务调用
d.监控和调整
监控断路器状态和服务调用情况,必要时调整配置
04.使用Resilience4j实现断路器
import io.github.resilience4j.circuitbreaker.CircuitBreaker;
import io.github.resilience4j.circuitbreaker.CircuitBreakerConfig;
import io.github.resilience4j.circuitbreaker.CircuitBreakerRegistry;
import java.time.Duration;
import java.util.function.Supplier;
public class CircuitBreakerExample {
public static void main(String[] args) {
// 配置断路器
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率阈值
.waitDurationInOpenState(Duration.ofSeconds(5)) // 打开状态等待时间
.slidingWindowSize(10) // 滑动窗口大小
.build();
// 创建断路器注册表
CircuitBreakerRegistry registry = CircuitBreakerRegistry.of(config);
// 获取或创建断路器
CircuitBreaker circuitBreaker = registry.circuitBreaker("myCircuitBreaker");
// 包装服务调用
Supplier<String> decoratedSupplier = CircuitBreaker.decorateSupplier(circuitBreaker, CircuitBreakerExample::callExternalService);
// 执行服务调用
try {
String result = decoratedSupplier.get();
System.out.println("Service call result: " + result);
} catch (Exception e) {
System.out.println("Service call failed: " + e.getMessage());
}
}
// 模拟外部服务调用
private static String callExternalService() {
// 模拟服务调用失败
throw new RuntimeException("Service not available");
}
}
05.断路器的应用场景
a.微服务架构
在微服务之间调用时,使用断路器防止单个服务故障影响整个系统
b.外部API调用
在调用第三方API时,使用断路器处理网络故障或服务不可用的情况
c.高可用系统
在高可用系统中,使用断路器提高系统的稳定性和容错能力
2.3 [1]灰度发布
00.总结
a.概念
灰度发布,又称为金丝雀发布
b.实现方案
a.请求路由
通过请求中的标识(如用户ID、设备ID、请求头等)来决定是否将请求路由到灰度环境
可以使用反向代理(如Nginx、Envoy)或API网关(如Kong、Apigee)来实现路由规则
b.权重控制
将流量按照一定的权重比例分配到不同的环境中
可以通过负载均衡器(如HAProxy、Kubernetes Ingress)或代理服务器(如Nginx、Envoy)来实现权重控制
c.特性开关
通过在代码中嵌入特性开关(Feature Flag)来控制功能的开启与关闭
可以使用配置文件、数据库、键值存储或特性管理平台(如LaunchDarkly、Unleash)来管理特性开关
d.分阶段发布
将功能的发布分为多个阶段,从内部测试到灰度环境再到全量发布
可以使用部署工具(如Jenkins、GitLab CI/CD)或云平台(如AWS、Azure)来支持分阶段发布
e.A/B测试
将流量分为多个不同版本的应用程序,比较它们的性能和用户反馈
可以使用A/B测试平台(如Optimizely、Google Optimize)来管理和监控A/B测试
f.金丝雀发布
将新版本的应用程序逐步引入生产环境,仅将少量流量导向新版本,并根据其性能和稳定性逐步增加流量
可以使用部署工具、容器编排平台或云平台来实现金丝雀发布
c.发布方案
a.基于用户ID的灰度发布
基于用户ID来划分灰度用户或百分比灰度,例如根据用户ID的哈希值或随机数来决定用户是否路由到灰度环境
b.基于IP地址的灰度发布
根据用户的IP地址来划分灰度用户,例如将某一范围的IP地址指定为灰度用户,将请求从这些IP地址路由到灰度环境
c.Cookie/Session的灰度发布
通过在用户的Cookie或会话中设置特定的标识来划分灰度用户
例如,将特定的Cookie或会话变量设置为灰度标识,将具有该标识的请求路由到灰度环境
d.请求头的灰度发布
基于请求头中的特定标识来划分灰度用户。例如,根据请求头中的自定义标识或特定的HTTP Header来路由请求到灰度环境
e.权重或百分比的灰度发布
将请求随机分配给不同的环境,可以通过给不同环境设置不同的权重或百分比来控制流量的分配
f.A/B测试
将流量分为多个不同版本的应用程序,在实验期间比较它们的性能和用户反馈,最终选择最佳版本进行全量发布
01.概述
a.定义
灰度发布是一种软件发布策略,旨在逐步将新版本的应用程序或功能推送给用户群体的一部分,而不是一次性推送给所有用户
通过这种方式,可以在真实环境中验证新版本的稳定性和性能,同时减少对用户的影响
b.原理
灰度发布的核心思想是通过控制流量和用户群体,逐步引入新版本,以便在小范围内观察其效果和潜在问题
通过监控和反馈,可以及时调整和优化新版本,确保最终的全面发布是稳定和可靠的
c.作用
a.降低风险
通过逐步发布,可以在小范围内发现和解决问题,降低对整个系统的影响
b.提高稳定性
在真实环境中验证新版本的稳定性,确保最终发布的版本质量
c.用户反馈
通过早期用户的反馈,及时调整和优化新版本
d.持续交付
支持持续交付和快速迭代,提升开发和发布效率
d.常用API
a.流量管理
使用Nginx、Traefik等反向代理工具进行流量控制
b.监控工具
使用Prometheus、Grafana等工具进行系统性能监控
c.用户分组
使用Redis、数据库等存储用户群体信息
02.关键步骤
a.流量分割
根据一定的策略(如用户 ID、请求头信息、IP 地址等)将流入的请求分配给不同版本的服务实例。
使用 Spring Cloud Gateway、Zuul 等 API 网关组件实现路由规则,将部分请求定向至新版本的服务节点。
b.版本标识
新版本服务启动时会注册带有特定版本标签的服务实例到服务注册中心(如 Eureka 或 Nacos)。
请求在路由时可以根据版本标签选择相应版本的服务实例。
c.监控与评估
在灰度发布的阶段,运维团队会对新版本服务的性能、稳定性以及用户体验等方面进行实时监控和评估。
如果新版本表现良好,则可以逐渐扩大灰度范围直至全面替换旧版本。
d.故障恢复与回滚
若新版本出现问题,可通过快速撤销灰度发布策略,使所有流量恢复到旧版本服务,实现快速回滚,确保服务整体可用性。
03.发布方式
a.按用户群体
选择特定的用户群体进行发布,如VIP用户、内部员工等
b.按地理位置
根据用户的地理位置进行发布,如某个城市或国家
c.按设备类型
根据用户的设备类型进行发布,如移动端或桌面端
d.按时间段
在特定的时间段内进行发布,如夜间或非高峰时段
04.使用步骤
a.规划发布策略
确定灰度发布的目标和范围,选择合适的用户群体和发布方式
b.监控和反馈
在灰度发布过程中,实时监控系统性能和用户反馈
c.调整和优化
根据监控数据和用户反馈,及时调整和优化新版本
d.全面发布
在灰度发布成功后,将新版本推送给所有用户
05.每个场景对应的代码示例
public class FeatureToggleService {
private Set<String> betaUsers;
public FeatureToggleService(Set<String> betaUsers) {
this.betaUsers = betaUsers;
}
public boolean isFeatureEnabled(String userId) {
// 检查用户是否在灰度发布的用户群体中
return betaUsers.contains(userId);
}
}
// 使用示例
public class Application {
public static void main(String[] args) {
Set<String> betaUsers = new HashSet<>(Arrays.asList("user1", "user2", "user3"));
FeatureToggleService featureToggleService = new FeatureToggleService(betaUsers);
String currentUserId = "user1";
if (featureToggleService.isFeatureEnabled(currentUserId)) {
System.out.println("新功能已启用");
} else {
System.out.println("新功能未启用");
}
}
}
2.4 [1]通讯方式:4种
00.汇总
HTTP/REST
RPC(Remote Procedure Call)
消息队列
GraphQL
01.HTTP/REST
a.定义
使用HTTP协议进行通信,通常采用RESTful风格的API
b.原理
REST(Representational State Transfer)是一种架构风格,使用HTTP动词(GET、POST、PUT、DELETE等)进行操作
c.常用API
Spring Boot中的RestTemplate或WebClient
JAX-RS(Java API for RESTful Web Services)
d.使用步骤
定义RESTful API接口
使用HTTP客户端发送请求
接收并处理响应
e.示例
// 使用RestTemplate发送GET请求
RestTemplate restTemplate = new RestTemplate();
String response = restTemplate.getForObject("http://service-url/api/resource", String.class);
System.out.println(response);
02.RPC(Remote Procedure Call)
a.定义
远程过程调用,通过网络调用远程服务的方法
b.原理
RPC允许程序调用远程服务的方法,就像调用本地方法一样
c.常用API
gRPC(Google Remote Procedure Call)
Apache Thrift
d.使用步骤
定义服务接口和消息格式
使用RPC框架生成客户端和服务端代码
部署服务并进行调用
e.示例
// gRPC客户端调用示例
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 50051).usePlaintext().build();
MyServiceGrpc.MyServiceBlockingStub stub = MyServiceGrpc.newBlockingStub(channel);
MyResponse response = stub.myMethod(MyRequest.newBuilder().setMessage("Hello").build());
System.out.println(response.getMessage());
channel.shutdown();
03.消息队列
a.定义
使用消息队列进行异步通信
b.原理
消息队列允许服务之间通过消息进行异步通信,解耦服务之间的依赖
c.常用API
RabbitMQ
Apache Kafka
d.使用步骤
配置消息队列
发送消息到队列
消费者从队列中接收消息
e.示例
// 发送消息到RabbitMQ队列
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection(); Channel channel = connection.createChannel()) {
channel.queueDeclare("myQueue", false, false, false, null);
String message = "Hello, World!";
channel.basicPublish("", "myQueue", null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
04.GraphQL
a.定义
使用GraphQL进行查询和数据获取
b.原理
GraphQL是一种查询语言,允许客户端指定需要的数据结构
c.常用API
Apollo GraphQL
GraphQL Java
d.使用步骤
定义GraphQL schema
使用GraphQL客户端发送查询
处理响应数据
e.示例
// GraphQL查询示例
query {
user(id: "1") {
name
email
}
}
2.5 [2]nacos:概况
00.三个角色
a.服务提供者
提供具体业务功能的服务实例
b.服务消费者
调用其他服务来完成自身业务逻辑的服务实例
c.服务注册中心
一个服务注册表,记录了每个服务的名称、对应的服务实例列表以及实例的详细信息
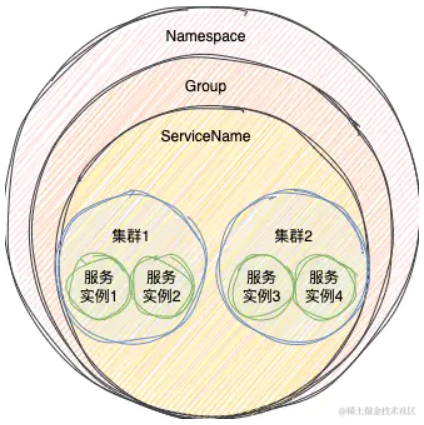
01.一个服务:由三部分信息组成
a.命名空间(Namespace)
多租户隔离用的,默认是public
b.分组(Group)
可以用来做环境隔离,服务注册时可以指定服务的分组,比如是测试环境或者是开发环境,默认是DEFAULT_GROUP
c.服务名(ServiceName)
这个就不用多说了
02.发现模式:2种
a.主动查询,pull
1.x:通过Http请求
2.x:通过gRPC请求
主动查询就是指客户端主动向服务端查询需要关注的服务实例,也就是拉(pull)的模式
b.服务订阅,push
1.x:通过UDP推送
2.x:基于gRPC长连接
服务订阅就是指客户端向服务端发送一个订阅服务的请求
当被订阅的服务有信息变动就会主动将服务实例的信息推送给订阅的客户端,本质就是推(push)模式
03.心跳机制:临时实例,用来保护的机制
a.定义
心跳机制,也可以被称为保活机制,它的作用就是服务实例告诉注册中心我这个服务实例还活着
b.说明
在正常情况下,服务关闭了,那么服务会主动向Nacos服务端发送一个服务下线的请求
Nacos服务端在接收到请求之后,会将这个服务实例从服务注册表中剔除
但是对于异常情况下,比如出现网络问题,可能导致这个注册的服务实例无法提供服务,处于不可用状态,也就是不健康
而此时在没有任何机制的情况下,服务端是无法知道这个服务处于不可用状态
所以为了避免这种情况,一些注册中心,就比如Nacos、Eureka,就会用心跳机制来判断这个服务实例是否能正常
在Nacos中,心跳机制仅仅是针对临时实例来说的,临时实例需要靠心跳机制来保活
c.1.x心跳实现
在1.x中,心跳机制实现是通过客户端和服务端各存在的一个定时任务来完成的
在服务注册时,发现是临时实例,客户端会开启一个5s执行一次的定时任务
d.2.x心跳实现
在2.x版本之后,由于通信协议改成了gRPC,客户端与服务端保持长连接,所以2.x版本之后它是利用这个gRPC长连接本身的心跳来保活
一旦这个连接断开,服务端就会认为这个连接注册的服务实例不可用,之后就会将这个服务实例从服务注册表中提出剔除
04.健康检查:永久实例,判断服务实例是否活着
a.说明
健康检查跟心跳机制刚好相反,心跳机制是服务实例向服务端发送请求
而所谓的健康检查就是服务端主动向服务实例发送请求,去探测服务实例是否活着
b.健康检查机制在1.x和2.x的实现机制是一样的
Nacos服务端在会去创建一个健康检查任务,这个任务每次执行时间间隔会在2000~7000毫秒之间
当任务触发的时候,会根据设置的健康检查的方式执行不同的逻辑,目前主要有以下三种方式:
TCP:根据服务实例的ip和端口去判断是否能连接成功,如果连接成功,就认为健康,反之就任务不健康
HTTP:向服务实例的ip和端口发送一个Http请求,请求路径是需要设置的,如果能正常请求,说明实例健康,反之就不健康
MySQL:一种特殊的检查方式,他可以执行下面这条Sql来判断数据库是不是主库
05.CP(强一致)、AP(高并发)
a.Nacos的CP实现
a.说明
Nacos的CP实现是基于Raft算法来实现的
在1.x版本早期,Nacos是自己手动实现Raft算法
在2.x版本,Nacos移除了手动实现Raft算法,转而拥抱基于蚂蚁开源的JRaft框架
b.在Raft算法,每个节点主要有三个状态
Leader,负责所有的读写请求,一个集群只有一个
Follower,从节点,主要是负责复制Leader的数据,保证数据的一致性
Candidate,候选节点,最终会变成Leader或者Follower
c.过程
集群启动时都是节点Follower,经过一段时间会转换成Candidate状态,再经过一系列复杂的选择算法,选出一个Leader
当有写请求时,如果请求的节点不是Leader节点时,会将请求转给Leader节点,由Leader节点处理写请求
比如,有个客户端连到的上图中的Nacos服务2节点,之后向Nacos服务2注册服务
Nacos服务2接收到请求之后,会判断自己是不是Leader节点,发现自己不是
此时Nacos服务2就会向Leader节点发送请求,Leader节点接收到请求之后,会处理服务注册的过程
b.Nacos的AP实现
a.说明
对于AP来说,Nacos使用的是阿里自研的Distro协议
b.过程
在这个协议中,每个服务端节点是一个平等的状态,每个服务端节点正常情况下数据是一样的
每个服务端节点都可以接收来自客户端的读写请求
当某个节点刚启动时,他会向集群中的某个节点发送请求,拉取所有的服务实例数据到自己的服务注册表中
这样其它客户端就可以从这个服务节点中获取到服务实例数据了
当某个服务端节点接收到注册临时服务实例的请求,不仅仅会将这个服务实例存到自身的服务注册表
同时也会向其它所有服务节点发送请求,将这个服务数据同步到其它所有节点
所以此时从任意一个节点都是可以获取到所有的服务实例数据的
即使数据同步的过程发生异常,服务实例也成功注册到一个Nacos服务中
对外部而言,整个Nacos集群是可用的,也就达到了AP的效果
c.同时为了满足BASE理论,Nacos也有下面两种机制保证最终节点间数据最终是一致的
失败重试机制:当数据同步给其它节点失败时,会每隔3s重试一次,直到成功
定时对比机制:每个Nacos服务节点会定时向所有的其它服务节点发送一些认证的请求
2.6 [2]nacos:2种调用
00.汇总
使用 RestTemplate + Spring Cloud LoadBalancer
使用 OpenFeign + Spring Cloud LoadBalancer
01.使用 RestTemplate + Spring Cloud LoadBalancer
a.使用
1.添加依赖:nacos + loadbalancer
2.设置配置文件
3.编写调用代码
b.添加依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
c.设置配置文件
spring:
application:
name: nacos-discovery-business
cloud:
nacos:
discovery:
server-addr: localhost:8848
username: nacos
password: nacos
register-enabled: false
d.编写调用代码
a.给 RestTemplate 增加 LoadBalanced 支持
a.说明
在 Spring Boot 启动类上添加“@EnableDiscoveryClient”注解
并使用“@LoadBalanced”注解替换 IoC 容器中的 RestTemplate
b.代码
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableDiscoveryClient
public class BusinessApplication {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(BusinessApplication.class, args);
}
}
b.使用 RestTemplate 调用接口
a.说明
略
b.代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@RequestMapping("/business")
public class BusinessController2 {
@Autowired
private RestTemplate restTemplate;
@RequestMapping("/getnamebyid")
public String getNameById(Integer id){
return restTemplate.getForObject("http://nacos-discovery-demo/user/getnamebyid?id="+id,
String.class);
}
}
02.使用 OpenFeign + Spring Cloud LoadBalancer
a.使用
1.添加依赖:nacos + openfeign + loadbalancer
2.设置配置文件
3.开启 openfeign 支持
4.编写 service 代码
5.调用 service 代码
b.添加依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
c.设置配置文件
spring:
application:
name: nacos-discovery-business
cloud:
nacos:
discovery:
server-addr: localhost:8848
username: nacos
password: nacos
register-enabled: false
d.开启OpenFeign
在 Spring Boot 启动类上添加 @EnableFeignClients 注解
e.编写Service
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
@Service
@FeignClient(name = "nacos-producer") // name 为生产者的服务名
public interface UserService {
@RequestMapping("/user/getinfo") // 调用生产者的接口
String getInfo(@RequestParam String name);
}
f.调用Service
import com.example.consumer.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OrderController {
@Autowired
private UserService userService;
@RequestMapping("/order")
public String getOrder(@RequestParam String name){
return userService.getInfo(name);
}
}
2.7 [2]nacos:配置文件
00.汇总
a.多配置文件加载机制
extension-configs
spring.cloud.nacos.config.extension-configs
spring.cloud.nacos.config.import
share-configs
b.处理配置名称冲突
唯一命名
使用配置分组
显式引用
01.多配置文件加载机制
a.extension-configs
a.说明
extension-configs 是 Nacos 提供的一种机制,允许你在一个配置文件中引用多个其他配置文件
这种方式适用于在同一个命名空间内加载多个配置文件
b.假设你有以下三个配置文件
database-config.yaml
redis-config.yaml
application.yaml
c.可以在 application.yaml 中引用其他两个配置文件
# application.yaml
spring:
cloud:
nacos:
config:
extension-configs:
- data-id: database-config.yaml
group: DEFAULT_GROUP
refresh: true
- data-id: redis-config.yaml
group: DEFAULT_GROUP
refresh: true
b.spring.cloud.nacos.config.extension-configs
a.说明
在 Spring Cloud Nacos 中,使用 spring.cloud.nacos.config.extension-configs 属性来引用多个配置文件
这种方式适用于在同一个命名空间内加载多个配置文件
b.示例配置
# application.yaml
spring:
cloud:
nacos:
config:
extension-configs:
- data-id: database-config.yaml
group: DEFAULT_GROUP
refresh: true
- data-id: redis-config.yaml
group: DEFAULT_GROUP
refresh: true
c.spring.cloud.nacos.config.import
a.说明
在 Spring Cloud Nacos 2.2.0 及以上版本中
你可以使用 spring.cloud.nacos.config.import 属性来引用多个配置文件
这种方式适用于在同一个命名空间内加载多个配置文件
b.示例配置
# application.yaml
spring:
cloud:
nacos:
config:
import:
- nacos:database-config.yaml?group=DEFAULT_GROUP&refresh=true
- nacos:redis-config.yaml?group=DEFAULT_GROUP&refresh=true
d.share-configs
a.内容
share-configs 是 Nacos 提供的一种机制,允许你在不同的命名空间之间共享配置文件
通过共享配置,你可以在一个命名空间中定义配置,然后在其他命名空间中引用这些配置
从而减少配置的重复定义,并确保配置的一致性
b.假设你有两个命名空间
dev 和 test,并且它们都有一个名为 common-config.yaml 的配置文件
c.在 dev 命名空间中定义共享配置
a.配置名称
share-configs.common-config.yaml
b.配置内容
database:
url: jdbc:mysql://localhost:3306/mydb
username: root
password: secret
d.在 test 命名空间中引用共享配置
a.配置名称
application.yaml
b.配置内容
spring:
cloud:
nacos:
config:
shared-configs:
- data-id: share-configs.common-config.yaml
group: DEFAULT_GROUP
refresh: true
e.在同一个命名空间内加载多个配置文件
a.内容
除了跨命名空间共享配置,extension-configs 和 import 机制还可以用于在同一个命名空间内加载多个配置文件
b.假设你在 dev 命名空间中有以下三个配置文件
database-config.yaml
redis-config.yaml
application.yaml
c.可以在 application.yaml 中引用其他两个配置文件
# application.yaml
spring:
cloud:
nacos:
config:
extension-configs:
- data-id: database-config.yaml
group: DEFAULT_GROUP
refresh: true
- data-id: redis-config.yaml
group: DEFAULT_GROUP
refresh: true
d.或者使用 import 机制
# application.yaml
spring:
cloud:
nacos:
config:
import:
- nacos:database-config.yaml?group=DEFAULT_GROUP&refresh=true
- nacos:redis-config.yaml?group=DEFAULT_GROUP&refresh=true
02.处理配置名称冲突
b.唯一命名
确保每个配置文件的名称在整个 Nacos 系统中是唯一的
可以在配置文件名称中包含命名空间的信息,例如 dev-config.yaml 和 test-config.yaml
c.使用配置分组
Nacos 支持配置分组(Group),可以在不同的命名空间中使用不同的分组来区分配置文件
例如,在 dev 命名空间中使用 DEV_GROUP,在 test 命名空间中使用 TEST_GROUP
d.显式引用
在引用配置文件时,显式指定配置文件所在的命名空间和分组,以避免歧义
-----------------------------------------------------------------------------------------------------
# application.yaml (在 test 命名空间中引用 dev 命名空间的配置)
spring:
cloud:
nacos:
config:
shared-configs:
- data-id: common-config.yaml
group: DEV_GROUP
refresh: true
2.8 [2]nacos:动态路由
00.汇总
a.添加依赖
在 Spring Cloud Gateway 应用的 pom.xml 文件中添加 Nacos 相关依赖
b.配置Nacos
在 application.yml 或 application.properties 文件中配置 Nacos 服务地址。
c.启用动态路由
在配置文件中启用 Nacos 动态路由功能
d.创建动态路由配置
在 Nacos 配置中心创建动态路由的配置信息。
e.监听配置变化
在 Spring Cloud Gateway 应用中监听 Nacos 配置变化,动态更新路由规则
01.添加依赖
<dependencies>
<!-- Spring Cloud Gateway -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Spring Cloud Alibaba Nacos Discovery -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- Spring Cloud Alibaba Nacos Config -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
</dependencies>
02.配置Nacos
spring:
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848 # Nacos 服务地址
config:
server-addr: 127.0.0.1:8848 # Nacos 配置中心地址
file-extension: yml # 配置文件格式
group: DEFAULT_GROUP # 配置分组
namespace: # 配置命名空间
03.本地yml:启用动态路由
spring:
cloud:
gateway:
discovery:
locator:
enabled: true # 开启从注册中心动态创建路由的功能
lower-case-service-id: true # 使用小写服务名,默认是大写
04.Nacos配置:gateway-routes.yml
spring:
cloud:
gateway:
routes:
- id: my-service-route
uri: lb://MY-SERVICE
predicates:
- Path=/my-service/**
filters:
- StripPrefix=1
05.监听配置变化
a.配置类:监听Nacos配置变化,并刷新路由规则
a.说明
这个类会监听环境变化事件,当检测到 spring.cloud.gateway.routes 配置项发生变化时,会重新加载和刷新路由规则
我们通过使用 Nacos 实现 Spring Cloud Gateway 的动态路由
通过在 Nacos 配置中心维护路由配置,可以实现不重启网关服务的情况下动态更新路由规则,这对于微服务架构中的服务治理非常有用
b.代码
import org.springframework.cloud.context.environment.EnvironmentChangeEvent;
import org.springframework.cloud.gateway.route.RouteDefinitionLocator;
import org.springframework.cloud.gateway.route.RouteDefinitionWriter;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
@Component
public class DynamicRouteService {
private final RouteDefinitionWriter routeDefinitionWriter;
private final RouteDefinitionLocator routeDefinitionLocator;
public DynamicRouteService(RouteDefinitionWriter routeDefinitionWriter,
RouteDefinitionLocator routeDefinitionLocator) {
this.routeDefinitionWriter = routeDefinitionWriter;
this.routeDefinitionLocator = routeDefinitionLocator;
}
@EventListener
public void onEnvironmentChange(EnvironmentChangeEvent event) {
if (event.getKeys().contains("spring.cloud.gateway.routes")) {
routeDefinitionLocator.getRouteDefinitions()
.subscribe(routeDefinitions -> {
routeDefinitionWriter.delete("*").subscribe();
routeDefinitionWriter.save(routeDefinitions).subscribe();
});
}
}
}
b.在使用 Nacos 动态路由时,如果服务下线了,Spring Cloud Gateway 会如何响应?
a.说明
当使用 Nacos 动态路由时
如果服务下线,Spring Cloud Gateway 会通过 Nacos 的服务发现机制感知到这一变化
并根据配置的动态路由规则进行调整。如何配置 Spring Cloud Gateway 以响应服务下线的情况呢?
确保咱们的项目中已经添加了 Spring Cloud Gateway 和 Spring Cloud Alibaba Nacos Discovery 的依赖
b.application.yml
spring:
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848 # Nacos 服务地址
gateway:
routes:
- id: my-service-route
uri: lb://MY-SERVICE
predicates:
- Path=/my-service/**
filters:
- StripPrefix=1
discovery:
locator:
enabled: true
lower-case-service-id: true
c.Nacos配置中心的动态路由配置,创建gateway-routes.json文件
{
"spring": {
"cloud": {
"gateway": {
"routes": [
{
"id": "my-service-route",
"uri": "lb://MY-SERVICE",
"predicates": [
{
"name": "Path",
"args": {
"_genkey_0": "/my-service/**"
}
}
],
"filters": [
{
"name": "StripPrefix",
"args": {
"_genkey_1": "1"
}
}
]
}
]
}
}
}
}
d.动态路由配置监听,并刷新路由规则
import com.alibaba.cloud.nacos.NacosConfigManager;
import com.alibaba.cloud.nacos.NacosConfigProperties;
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.model.Properties;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.cloud.gateway.route.RouteDefinition;
import org.springframework.cloud.gateway.route.RouteDefinitionRepository;
import org.springframework.cloud.gateway.route.RoutesRefreshedEvent;
import org.springframework.context.ApplicationEventPublisher;
import org.springframework.stereotype.Component;
import java.util.Properties as JavaProperties;
@Component
public class NacosDynamicRoute implements ApplicationRunner {
@Autowired
private RouteDefinitionRepository routeDefinitionRepository;
@Autowired
private ApplicationEventPublisher publisher;
private ConfigService configService;
public NacosDynamicRoute(NacosConfigProperties properties) throws NacosException {
JavaProperties javaProperties = new JavaProperties();
javaProperties.setProperty("serverAddr", properties.getServerAddr());
javaProperties.setProperty("namespace", properties.getNamespace());
configService = NacosFactory.createConfigService(javaProperties);
}
@Override
public void run(ApplicationArguments args) {
try {
String routeJson = configService.getConfig("gateway-routes.json", "DEFAULT_GROUP", 5000);
refreshRoutes(routeJson);
configService.addListener("gateway-routes.json", "DEFAULT_GROUP", s -> refreshRoutes(s));
} catch (NacosException e) {
e.printStackTrace();
}
}
private void refreshRoutes(String routeJson) {
SpringCloudRouteDefinition routeDefinition = JsonUtils.deserialize(routeJson, SpringCloudRouteDefinition.class);
routeDefinitionRepository.delete("*").subscribe();
routeDefinitionRepository.save(routeDefinition.getRouteDefinitions()).subscribe();
publisher.publishEvent(new RoutesRefreshedEvent(this));
}
// 内部类,用于反序列化 Nacos 配置
static class SpringCloudRouteDefinition {
private RouteDefinition[] routeDefinitions;
// getter 和 setter 省略
}
}
2.9 [3]gateway:概念
01.常见信息1
a.分类1
作为系统的入口,统一【处理请求】
b.分类2
一是【路由转发】,根据请求路径转发到不同的服务
二是【身份验证】,统一处理登录验证和权限检查
三是【负载均衡】,分发请求到多个服务实例
四是【限流和监控】,保护系统不被过多的请求打垮
c.分类3
在微服务架构中,网关能让客户端不需要知道具体每个服务的地址,只需要访问网关就可以了
我之前接触过Spring Cloud Gateway,主要是用来做一些简单的路由和认证功能。
2.10 [3]gateway:示例
01.概述
微服务框架中网关提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能
例如:安全,监控/指标,和限流等。网关作为整个系统的访问入口
我们希望外部请求系统服务都需要通过网关访问,禁止通过ip端口直接访问
特别是一些重要的内部服务(外部无法直接访问的服务)
02.实现思路
请求服务添加密钥传递验证,通过网关请求的服务会生成一串密钥
这个密钥会向下游服务彻底,下游服务在接收到请求的时候会先验证密钥的合法性
如未携带密钥或密钥不合法则拒绝响应,以此来达到避免各个微服务绕过网关被直接访问
03.基本实现
a.网关模块
a.说明
添加全局过滤器拦截处理,将密钥放入请求头中,键名为gatewayKey
b.代码
/**
* 全局网关
*/
@Component
public class GatewayFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
PathContainer pathContainer = request.getPath().pathWithinApplication();
// 添加gatewayKey,防止下游接口直接被访问
ServerHttpRequest.Builder mutate = request.mutate();
mutate.header("gatewayKey", "key");
return chain.filter(exchange.mutate().request(mutate.build()).build());
}
}
b.服务模块
a.说明
实现Filter接口,拦截所有请求,对所有请求的合法性做校验
b.代码
/**
* 请求拦截,避免服务绕过接口被直接访问
*/
@Component
@WebFilter(filterName = "BaseFilter",urlPatterns = {"/user/**"})
public class BaseFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init filter");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("进入过滤器========");
HttpServletRequest request = (HttpServletRequest)servletRequest;
String gateway = request.getHeader("gatewayKey");
if(gateway == null || gateway.equals("") || !gateway.equals("key")){
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
System.out.println("destroy filter");
}
}
c.服务之间请求传递请求头
a.说明
实现RequestInterceptor接口,将请求放入请求头中,往下传递密钥
b.代码
@Configuration
public class FeignConfiguration implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
ServletRequestAttributes attributes = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
// 获取request请求头信息,传递给下一层
Enumeration<String> headerNames = request.getHeaderNames();
if (headerNames != null) {
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
String values = request.getHeader(name);
template.header(name, values);
}
}
// 独立设置参数
template.header("token","tokenKey");
}
}
04.代码结构优化
a.网关拦截注解
a.注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Import({GatewayFilter.class})
@Inherited
public @interface EnableGatewayFilter {
}
b.过滤器
public class GatewayFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
System.out.println("init gateway filter");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest)servletRequest;
String gateway = request.getHeader(GatewayFilterConstant.FILTER_KEY_NAME);
if(gateway == null || gateway.equals("") || !gateway.equals(GatewayFilterConstant.FILTER_KEY_SECRET)){
System.out.println("======无权访问=======");
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
Filter.super.destroy();
System.out.println("destroy gateway filter");
}
}
b.密钥传递注解
a.注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Import({CommunicationInterceptor.class})
@Inherited
public @interface EnableInnerCommunication {
}
b.拦截器
public class CommunicationInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
// 独立设置参数
template.header(GatewayFilterConstant.FILTER_KEY_NAME,GatewayFilterConstant.FILTER_KEY_SECRET);
}
}
c.组合注解(网关拦截+密钥传递)
a.注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@EnableInnerCommunication
@EnableGatewayFilter
public @interface EnableGatewayCommunication {
}
b.实际使用
@SpringBootApplication
@EnableDiscoveryClient
@EnableGatewayFilter
public class ServiceBasicApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceBasicApplication.class, args);
System.out.println("=========启动成功========");
}
}
2.11 [3]gateway:鉴权
00.背景
a.说明
分布式环境下为什么Session会失效?
因为用户在一个节点对会话做出的更改无法实时同步到其它的节点
这就导致一个很严重的问题:
如果用户在节点一上已经登录成功,那么当下一次的请求落在节点二上时
对节点二来讲,此用户仍然是未登录状态
b.解决
建立会话中心,将Session存储在专业的缓存中间件上,使每个节点都变成了无状态服务
例如:Redis,再由网关层进行统一鉴权,从redis中读取数据进行鉴权处理
c.实现
网关统一鉴权(Sa-Token + Redis)
01.依赖
<!-- Sa-Token 权限认证(Reactor响应式集成) -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-reactor-spring-boot-starter</artifactId>
<version>1.39.0</version>
</dependency>
<!-- Sa-Token 整合 Redis(使用 jackson 序列化方式) -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-redis-jackson</artifactId>
<version>1.39.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
02.添加网关配置文件
# redis配置
redis:
# Redis数据库索引(默认为0)
database: 1
# Redis服务器地址
host: 117.72.118.73
# Redis服务器连接端口
port: 6379
# Redis服务器连接密码(默认为空)
password: ssm030927
# 连接超时时间
timeout: 10s
lettuce:
pool:
# 连接池最大连接数
max-active: 200
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
# 连接池中的最大空闲连接
max-idle: 10
# 连接池中的最小空闲连接
min-idle: 0
sa-token:
# token 名称(同时也是 cookie 名称)
token-name: satoken
# token 有效期(单位:秒) 默认30天,-1 代表永久有效
timeout: 2592000
# token 最低活跃频率(单位:秒),如果 token 超过此时间没有访问系统就会被冻结,默认-1 代表不限制,永不冻结
active-timeout: -1
# 是否允许同一账号多地同时登录 (为 true 时允许一起登录, 为 false 时新登录挤掉旧登录)
is-concurrent: true
# 在多人登录同一账号时,是否共用一个 token (为 true 时所有登录共用一个 token, 为 false 时每次登录新建一个 token)
is-share: true
# token 风格(默认可取值:uuid、simple-uuid、random-32、random-64、random-128、tik)
token-style: random-32
# 是否输出操作日志
is-log: true
token-prefix: ssm
03.重写redisTemplate
a.说明
redis默认jdk序列化方式,会导致序列化和反序列化过程中出现乱码
b.代码
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
//把redis键key的值序列化为string字符串类型
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//把String、Hash类型的key序列化设置为String类型
redisTemplate.setKeySerializer(redisSerializer);
redisTemplate.setHashKeySerializer(redisSerializer);
//把value的序列化也设为String类型
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer());
return redisTemplate;
}
private Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer() {
Jackson2JsonRedisSerializer<Object> jsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
jsonRedisSerializer.setObjectMapper(objectMapper);
return jsonRedisSerializer;
}
}
c.说明
redisConnectionFactory:是 Spring Data Redis 用于创建与 Redis 数据库连接的工厂类
Jackson2JsonRedisSerializer:可以将 Java 对象序列化为 JSON 格式的字符串存储到 Redis中
ObjectMapper:控制 JSON序列化和反序列化
objectMapper.setVisibility:设置可见性规则(避免因为默认的可见性限制导致部分属性无法正确序列化或反序列化的问题):
PropertyAccessor.ALL:所有属性
JsonAutoDetect.Visibility.ANY:在序列化和反序列化时都能够被检测到(可见性为任意,即都可处理)
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false):在反序列化时,当json数据没有对应的java实体属性时,会忽略,不抛出异常
objectMapper.enableDefaultTyping: 启用了默认类型信息的处理:
ObjectMapper.DefaultTyping.NON_FINAL:指定了对于非最终类型(NON_FINAL)的对象
As.PROPERTY:在序列化时会将对象的类型信息作为一个属性(As.PROPERTY)添加到 JSON 数据中,方便在反序列化时能够准确地还原对象类型,尤其在处理复杂的继承结构或者多态场景下非常有用
04.定义redisUtil工具类
@Component
public class RedisUtil {
@Resource
private RedisTemplate redisTemplate;
private static final String CACHE_KEY_SEPARATOR = ".";
/**
* 构建缓存key
* String... : 可变参数,参数个数为0个或多个
* Stream.of 字符数组转化为stream流
* collect:收集器,终止操作;通过Collectors类把字符数组内的元素以.进行拼接
*/
public String buildKey(String... strObjs) {
return Stream.of(strObjs).collect(Collectors.joining(CACHE_KEY_SEPARATOR));
}
/**
* 是否存在key
* @param key
* @return
*/
public boolean exist(String key) {
return redisTemplate.hasKey(key);
}
/**
* 删除key
* @param key
* @return
*/
public boolean del(String key) {
return redisTemplate.delete(key);
}
/**
* set(无过期时间)
* @param key
* @param value
*/
public void set(String key, String value) {
redisTemplate.opsForValue().set(key, value);
}
/**
* setNx
* @param key
* @param value
* @param time
* @param timeUnit
* @return
*/
public boolean setNx(String key, String value, Long time, TimeUnit timeUnit) {
return redisTemplate.opsForValue().setIfAbsent(key, value, time, timeUnit);
}
/**
* get
* @param key
* @return
*/
public String get(String key) {
return (String) redisTemplate.opsForValue().get(key);
}
05.自定义权限验证接口扩展
@Component
public class StpInterfaceImpl implements StpInterface {
@Resource
private RedisUtil redisUtil;
private String authPermissionPrefix = "auth.permission"; //权限key
private String authRolePrefix = "auth.role"; //角色key
@Override
public List<String> getPermissionList(Object loginId, String loginType) {
// 返回此 loginId 拥有的权限列表
return getAuth(loginId.toString(), authPermissionPrefix);
}
@Override
public List<String> getRoleList(Object loginId, String loginType) {
// 返回此 loginId 拥有的角色列表
return getAuth(loginId.toString(), authRolePrefix);
}
private List<String> getAuth(String loginId, String prefix) {
String authKey = redisUtil.buildKey(prefix, loginId);
String authValue = redisUtil.get(authKey);
if(StringUtils.isBlank(authValue)) {
return Collections.emptyList();
}
List<String> authList = new Gson().fromJson(authValue, List.class);
return authList;
}
}
06.编写Satoken配置类用来定义全局过滤器
@Configuration
public class SaTokenConfigure {
// 注册 Sa-Token全局过滤器
@Bean
public SaReactorFilter getSaReactorFilter() {
return new SaReactorFilter()
// 拦截地址
.addInclude("/**") /* 拦截全部path */
// 鉴权方法:每次访问进入
.setAuth(obj -> {
// auth权限校验 -- 拦截所有auth微服务相关路由,并排除/auth/user/doLogin 用于开放登录, 只有具有admin角色才通行
SaRouter.match("/auth/**", "/auth/user/doLogin", r -> StpUtil.checkRole("admin"));
// oss权限校验 -- 拦截所有oss微服务相关路由, 只有登录成功才能上传图片
SaRouter.match("/oss/**", r -> StpUtil.checkLogin());
// 新增题目权限校验 -- 拦截所有/subject/subject/add路由,只有具有新增题目权限才可通行
SaRouter.match("/subject/subject/add", r -> StpUtil.checkPermission("subject:add"));
// 题目权限路由 -- 拦截所有subject微服务相关路由,只有登录才可通行
SaRouter.match("/subject/**", r -> StpUtil.checkLogin());
})
;
}
}
2.12 [3]gateway:限流
00.汇总
1.使用内置 Filter(过滤器)实现限流
2.使用限流组件 Spring Cloud Alibaba Sentinel 或者 Spring Cloud Netflix Hystrix 实现限流
01.使用内置 Filter(过滤器)实现限流
a.概述
a.说明
1.内置的限流器为 RequestRateLimiter GatewayFilter Factory
2.支持和 Redis 一起来实现限流功能
b.限流实现算法
a.Spring Cloud Gateway 内置限流功能算法
令牌桶限流算法
b.令牌桶限流算法
令牌按固定的速率被放入令牌桶中,桶中最多存放 N 个令牌(Token),当桶装满时,新添加的令牌被丢弃或拒绝
当请求到达时,将从桶中删除 1 个令牌
通过控制往令牌桶里加令牌的速度从而控制接口的流量
c.常见的限流算法还有
计数器算法、滑动计数器算法、漏桶算法等
c.限流实现原理
a.Spring Cloud Gateway执行过程
所有的请求来了之后,会先走过滤器,只有过滤器通过之后,才能调用后续的内部微服务
过滤器是基于令牌桶算法来限制请求的速率
b.令牌桶的执行过程
初始化:在加载过滤器工厂时,会基于给定的限流规则创建一个限流器
请求处理:每当有请求进来时,限流器会检查当前令牌桶中是否有可用的令牌
令牌桶填充:限流器会定期填充令牌桶
令牌桶容量控制:限流器还会根据限流规则中配置的令牌桶容量,控制令牌桶中的令牌数量
d.思路
在网关项目中添加 Redis 框架依赖
创建限流规则
配置限流过滤器
b.依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
c.创建限流规则
新建一个限流规则定义类,实现一下根据 IP 进行限流的功能
-----------------------------------------------------------------------------------------------------
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class IpAddressKeyResolver implements KeyResolver {
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getRemoteAddress().
getHostString());
}
}
d.配置限流过滤器
spring:
cloud:
gateway:
routes:
- id: retry
uri: lb://nacos-discovery-demo
predicates:
- Path=/retry/**
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 1
keyResolver: '#{@ipAddressKeyResolver}' # spEL表达式
data:
redis:
host: 127.0.0.1
port: 16379
database: 0
-----------------------------------------------------------------------------------------------------
其中,name 必须等于“RequestRateLimiter”内置限流过滤器,其他参数的含义如下:
redis-rate-limiter.replenishRate:令牌填充速度:每秒允许请求数
redis-rate-limiter.burstCapacity:令牌桶容量:最大令牌数
keyResolver:根据哪个 key 进行限流,它的值是 spEL 表达式
e.限流测试
http://localhost:10086/retry/test
02.使用限流组件 Spring Cloud Alibaba Sentinel 或者 Spring Cloud Netflix Hystrix 实现限流
参考【Sentinel】
2.13 [3]gateway:过滤器
00.汇总
a.局部过滤器
只作用于某一个路由(route)
b.全局过滤器:对所有的路由都有效
a.内置全局过滤器
Spring Cloud Gateway 自带的 30+ 过滤器
b.自定义全局过滤器
开发者自行实现的过滤器
01.局部过滤器
a.代码
spring:
cloud:
gateway:
routes:
- id: userservice
uri: http://192.168.1.7:56628
predicates:
- Path=/user/**
filters:
- AddResponseHeader=gateway-flag, javacn.site
b.说明
在输出对象 Response 中添加 Header 信息,key 为“gateway-flag”,value 为“javacn.site”
02.全局过滤器
a.内置全局过滤器
a.代码
spring:
cloud:
gateway:
routes:
- id: userservice
uri: http://192.168.1.7:51627
predicates:
- Weight=group1,50
- id: userservice2
uri: http://192.168.1.7:56628
predicates:
- Weight=group1,50
filters:
- AddResponseHeader=gateway-flag, javacn.site
default-filters:
- AddResponseHeader=gateway-default-filters, www.javacn.site
b.说明
其中的“default-filters”就是全局内置过滤器,它对所有的路由(route)有效
它的含义是在输出对象 Response 中添加 Header 信息
key 为“gateway-default-filters”,value 为“www.javacn.site”
b.自定义全局过滤器
a.说明
Spring Cloud Gateway 中自定义全局过滤器的实现是,定义一个类
使用 @Component 注解将其存入 IoC 容器,然后再实现 GlobalFilter 接口
重写 filter 方法,在 filter 中写自己的过滤方法即可
b.代码
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class AuthFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 得到 request、response 对象
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
// 业务逻辑代码
if(request.getQueryParams().getFirst("auth")==null){
// 权限有问题返回,并结束执行
response.setStatusCode(HttpStatus.FORBIDDEN);
return response.setComplete();
}
// 此步骤正常,执行下一步
return chain.filter(exchange);
}
@Override
public int getOrder() {
// 此值越小越早执行
return 1;
}
}
c.说明
以上代码是验证请求参数中是否有“auth”参数,如果没有的话就认为未登录
调用“response.setComplete()”终止继续执行,反之则认为已经登录,可以执行后续流程了
使用“chain.filter(exchange)”来实现
2.14 [3]gateway:升级的坑
00.汇总
a.旧版
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<groupId>2.2.9.RELEASE</groupId>
</dependency>
b.新版
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<groupId>3.1.8</groupId>
</dependency>
c.总结
坑1:Feign组件无法使用,程序假死卡在启动中
坑2:Feign请求导致同步阻塞
坑3:Get请求中带+号的字符转发到下游会被当成空格处理
坑4:QPS上不去
01.坑1:Feign 组件无法使用,程序假死卡在启动中
a.原因
a.说明
因为有组件需要鉴权,所以引入了鉴权的中心类。原先的引入方式是:
@Autowired
private AuthClient authClient;
b.说明
经过 debug 发现代码在进入 WeightCalculatorWebFilter.java的时候会触发RefreshRoutesEvent事件
新版的源码这里有个 blockLast,而旧版的是subscribe
b.区别
a.subscribe
订阅(consume)一个 Flux 流以触发数据的处理
非阻塞: 调用后不会阻塞当前线程,订阅操作会异步执行
触发流: Flux 中的数据只有在 subscribe 调用后才会开始流动
回调处理: 支持通过参数指定数据、错误和完成信号的处理逻辑
b.blockLast
阻塞当前线程,直到 Flux 流中的最后一个元素被处理完
阻塞: 当前线程会等待直到流结束或出现错误
同步返回: 返回 Flux 的最后一个元素(如果存在),或者抛出异常
触发流: 同样会触发 Flux 的流动,但是在阻塞模式下执行
c.代码分析
else if (event instanceof RefreshRoutesEvent && routeLocator != null) {
// forces initialization
if (routeLocatorInitialized.compareAndSet(false, true)) {
// on first time, block so that app fails to start if there are errors in
// routes
// see gh-1574
// 如果是首次注册则应该要强制等待路由刷新完毕,为了保证路由能够正常加载
routeLocator.ifAvailable(locator -> locator.getRoutes().blockLast());
}
else {
// this preserves previous behaviour on refresh, this could likely go away
// 如果是后续的刷新注册则可以异步加载刷新
routeLocator.ifAvailable(locator -> locator.getRoutes().subscribe());
}
}
d.问题分析
根据这个注释找到了 github 的 issue,同时看到有个讨论问题WeightCalculatorWebFilter.onApplicationEvent method causes a deadlock
FeignClientFactoryBean 在初始化对应的客户端的时候通过工厂创建出 FeignClient 对象,并会触发 refresh,发出 RefreshRoutesEvent 事件
主线程在实例化的过程中 DefaultSingletonBeanRegistry.getSingleton 方法中持有锁
如果WeightCalculatorWebFilter首次收到RefreshRoutesEvent,它会调用blockLast(),而blockLast()实际上调用的是CountDownLatch.wait(),所以主线程会挂断并解除锁(LockSupport.Park)
另一个线程(boundedElastic)尝试获取主线程 DefaultSingletonBeanRegistry.getSingleton 锁定的锁
调用链如下:RouteDefinitionRouteLocator.convertToRoute() -> CombinePredicates() -> Lookup() -> ConfigurationService.bind() -> DoBind() -> ObjectProvider.getIfAvailable
这个时候两个线程互相持有此锁导致的死锁以至于应用僵死在这
e.解决方案
既然是加载顺序的问题,于是乎,把所有 Feign 的引用方式改成了懒加载
-----------------------------------------------------------------------------------------------------
@Autowired
@Lazy
private AuthClient authClient;
-----------------------------------------------------------------------------------------------------
程序能够正常启动,似乎问题得到了解决
02.坑2:Feign 请求导致同步阻塞
a.问题描述
接着上面说到的问题,这里把所有的 Feign改成了 Lazy Load 的方式加载,但是通过网关去请求其他接口的时候带来了新的问题
-----------------------------------------------------------------------------------------------------
java.lang.IllegalStateException: block()/blockFirst()/blockLast() are blocking, which is not supported in thread reactor-http-nio-4
at reactor.core.publisher.BlockingSingleSubscriber.blockingGet(BlockingSingleSubscriber.java:83)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
b.问题分析
这里主要描述了在响应式编程中不使用 非响应式的请求逻辑。断点请求进去发现这段逻辑
block 这几个字符见如其名,那就是这里堵了,在feign进行负载均衡选择路由实例,是个同步等待的过程
c.解决方案
在响应式编程中不应该使用同步的请求或者方法来实现接口调用,Feign这种同步的请求客户端那指定是不能使用了
在一番调研之后选择了官方开发者都主推的 WebClient
03.坑3:Get请求中带+号(加号)的字符转发到下游会被当成空格处理
a.问题描述
这里发现的情况是Get请求的过程中带了加密串,加密串中有+号和=号
传递到下游的时候只有等号会被正常传递,加号会被当成空格
-----------------------------------------------------------------------------------------------------
正常请求:cipherText=kvZopjbXFA1q++YBlVPhxQ==
下游请求:cipherText=kvZopjbXFA1q YBlVPhxQ==
b.问题分析
webClient和webflux都有在请求到下游前对url先做decoded +号就会被转换成空格
再传递到下游的时候就会缺失对应的信息
c.解决方案
正解是实现自己的url编码格式
-----------------------------------------------------------------------------------------------------
@Slf4j
public class CustomUrlEncodeFilter implements WebFilter, Ordered {
@Override
public int getOrder() {
// 定义过滤器的优先级,值越小优先级越高
return Ordered.LOWEST_PRECEDENCE - 4; // 在AuthFilter之前执行
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
ServerHttpRequest originalRequest = exchange.getRequest();
if (!needEncode(originalRequest)) {
return chain.filter(exchange);
}
// 重写路径逻辑
String newUri = rewriteUri(originalRequest);
// 创建新的请求对象
ServerHttpRequest modifiedRequest = originalRequest.mutate()
.uri(URI.create(newUri))// 替换为新的 URI
.build();
// 将修改后的请求传递到后续过滤器
return chain.filter(exchange.mutate().request(modifiedRequest).build());
}
/**
* 重写uri
*
* @param request
* @return
*/
private String rewriteUri(ServerHttpRequest request) {
// 获取当前请求 URI
String originalUri = request.getURI().toString();
Map<String, String> map = extractQueryParams(originalUri);
log.info("Original URI:" + originalUri);
log.info("Original param:" + map);
Map<String, String> encodeQueryParams = encodeQueryParams(map);
log.info("Encode param:" + encodeQueryParams);
String newUrl = request.getURI().getScheme() + "://"
+ request.getURI().getAuthority() + request.getURI().getPath() + "?" + mapToQueryString(encodeQueryParams);
log.info("NewUrl:" + newUrl);
return newUrl;
}
public static String mapToQueryString(Map<String, String> params) {
if (params == null || params.isEmpty()) {
return "";
}
return params.entrySet().stream()
.map(entry -> {
String key = entry.getKey();
String value = entry.getValue() != null ? entry.getValue() : "";
return key + "=" + value;
})
.collect(Collectors.joining("&"));
}
public static Map<String, String> extractQueryParams(String url) {
Map<String, String> queryParams = new HashMap<>();
if (url == null || !url.contains("?")) {
return queryParams;
}
try {
String queryString = url.substring(url.indexOf('?') + 1);
String[] pairs = queryString.split("&");
for (String pair : pairs) {
String[] keyValue = pair.split("=", 2);
String key = decodeIfNeededPreservePlus(keyValue[0]);
String value = keyValue.length > 1 ? decodeIfNeededPreservePlus(keyValue[1]) : "";
queryParams.put(key, value);
}
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Failed to decode query parameters", e);
}
return queryParams;
}
/**
* 加密查询参数
*
* @param map
* @return
*/
public static Map<String, String> encodeQueryParams(Map<String, String> map) {
Map<String, String> newMap = new HashMap<>();
map.forEach((k, v) -> {
newMap.put(k, URLEncodeUtil.encodeAll(v));
});
return newMap;
}
/**
* 解密如果是需要解密的,支持带加号
*
* @param value
* @return
* @throws UnsupportedEncodingException
*/
private static String decodeIfNeededPreservePlus(String value) throws UnsupportedEncodingException {
if (value.contains("%")) {
value = value.replaceAll("\+", "%2B");
value = URLDecoder.decode(value, StandardCharsets.UTF_8);
return value.replaceAll("%2B", "+");
}
return value;
}
/**
* 判断是否需要加密
*
* @param request
* @return
*/
private boolean needEncode(ServerHttpRequest request) {
// get请求 且包含关键字
MultiValueMap<String, String> queryParams = request.getQueryParams();
HttpHeaders headers = request.getHeaders();
return Objects.equals(request.getMethod(), HttpMethod.GET)
&& !headers.containsKey("skipEncode")
&& (queryParams.containsKey("cipherText") || queryParams.containsKey("sign"));
}
}
-----------------------------------------------------------------------------------------------------
以webflux转发为例子,这段代码是核心代码,只需要在请求之前将url的参数encoding再发出去就好了
04.坑4:QPS上不去
a.问题描述
填好上面的坑,又发现了一个新坑,上线后测试发现QPS压不上去。之前一度怀疑是网关配置的问题
怀疑是连接数不够的问题导致的,后来调大对应的连接数和工作线程发现都提升不大,直到对比了另一个网关
发现此网关拥有好多路由断言的配置信息。
b.问题分析
本地调试的过程中把断言去掉后发现果然并发上去了,但是这些路由是之前就有的,能否直接去掉呢
去掉是否会带来一系列的兼容性问题呢,带着这些疑问,又重新研究了下gateway的源码
发现路由相关的代码由org.springframework.cloud.gateway.handler.RoutePredicateHandlerMapping#lookupRoute
这里的this.routeLocator.getRoutes() 获取到的是所有的路由列表
每次都会对其做路由的过滤、断言的校验,当路由数量达到一定规模之后这里也会成为现在性能的瓶颈所在
c.解决方案
a.说明
我结合公司的业务场景,定制了一套获取路由的规则的方法,我们大多数的路由地址其实是知道要路由到哪个服务的,且有对应的服务发现地址
例如:
---
http://gateway-host/serviceA/request1
http://gateway-host/serviceA/request2
http://gateway-host/serviceB/request1
http://gateway-host/serviceB/request2
ws://gateway-host/serviceC/request1 // websocket
---
可以解析出url的第一个名称做为服务名当成Map-Key,对应的路由断言作为Map-Value,构造出一个路由缓存,就能实现O(1)的时间复杂度获取到对应的路由信息
b.定义缓存路由的缓存器,并在路由变更的时候能够触发更新缓存信息
@Slf4j
public class CustomerRouteCache {
private final RouteLocator routeLocator;
private final Map<String, Route> routeMap = new ConcurrentHashMap<>();
public CustomerRouteCache(RouteLocator routeLocator) {
this.routeLocator = routeLocator;
refreshRoutes();
log.info("输出 routeMap {}", routeMap);
}
@EventListener
public void handleRouteUpdateEvent(RefreshRoutesEvent event) {
refreshRoutes(); // 路由更新时刷新缓存
}
private void refreshRoutes() {
this.routeLocator.getRoutes()
.collectMap(Route::getId, route -> route)
.doOnNext(routeMap::putAll)
.subscribe();
}
public Route getRouteById(String routeId) {
return routeMap.get(routeId);
}
}
c.继承RoutePredicateHandlerMapping并重写部分逻辑,核心逻辑是getRoteByCache
@Slf4j
public class CustomerRoutePredicateHandlerMapping extends RoutePredicateHandlerMapping {
private final FilteringWebHandler webHandler;
private final RouteLocator routeLocator;
private final Integer managementPort;
private final ManagementPortType managementPortType;
private final CustomerRouteCache routeCache;
public CustomerRoutePredicateHandlerMapping(CustomerRouteCache routeCache,FilteringWebHandler webHandler, RouteLocator routeLocator, GlobalCorsProperties globalCorsProperties, Environment environment) {
super(webHandler, routeLocator, globalCorsProperties, environment);
this.routeCache = routeCache;
this.webHandler = webHandler;
this.routeLocator = routeLocator;
this.managementPort = getPortProperty(environment, "management.server.");
this.managementPortType = getManagementPortType(environment);
log.info("初始化自定义的路由断言处理器");
}
@Override
protected Mono<?> getHandlerInternal(ServerWebExchange exchange) {
exchange.getAttributes().put(GATEWAY_HANDLER_MAPPER_ATTR, getSimpleName());
return lookupRoute(exchange)
.flatMap((Function<Route, Mono<?>>) r -> {
exchange.getAttributes().remove(GATEWAY_PREDICATE_ROUTE_ATTR);
logger.debug("Mapping [" + getExchangeDesc(exchange) + "] to " + r);
exchange.getAttributes().put(GATEWAY_ROUTE_ATTR, r);
return Mono.just(webHandler);
}).switchIfEmpty(Mono.empty().then(Mono.fromRunnable(() -> {
exchange.getAttributes().remove(GATEWAY_PREDICATE_ROUTE_ATTR);
if (logger.isTraceEnabled()) {
logger.trace("No RouteDefinition found for [" + getExchangeDesc(exchange) + "]");
}
})));
}
@Override
protected Mono<Route> lookupRoute(ServerWebExchange exchange) {
return getRoteByCache(exchange);
}
private Mono<Route> getRoteByCache(ServerWebExchange exchange) {
// 获取到对应的服务名
String serviceName = extractServiceName(exchange);
// 根据服务发现拼接获取对应的route
Route route = routeCache.getRouteById("ReactiveCompositeDiscoveryClient_" + serviceName);
if (route != null) {
log.debug("输出 route: " + route);
// 校验 Predicate,通过就用服务发现的route,反之使用父类的路由选择规则方式
return Mono.just(route)
.filterWhen(r -> r.getPredicate().apply(exchange))
.switchIfEmpty(Mono.defer(() -> {
log.warn("Predicate did not pass for route: " + route.getId());
return super.lookupRoute(exchange);
}));
}
return super.lookupRoute(exchange);
}
public String extractServiceName(ServerWebExchange exchange) {
String path = exchange.getRequest().getURI().getPath();
int firstSlash = path.indexOf('/');
int secondSlash = path.indexOf('/', firstSlash + 1);
if (secondSlash > firstSlash) {
return path.substring(firstSlash + 1, secondSlash);
}
return path.substring(firstSlash + 1); // 没有第二个斜杠时返回剩余部分
}
private String getExchangeDesc(ServerWebExchange exchange) {
StringBuilder out = new StringBuilder();
out.append("Exchange: ");
out.append(exchange.getRequest().getMethod());
out.append(" ");
out.append(exchange.getRequest().getURI());
return out.toString();
}
private static Integer getPortProperty(Environment environment, String prefix) {
return environment.getProperty(prefix + "port", Integer.class);
}
private ManagementPortType getManagementPortType(Environment environment) {
Integer serverPort = getPortProperty(environment, "server.");
if (this.managementPort != null && this.managementPort < 0) {
return DISABLED;
}
return ((this.managementPort == null || (serverPort == null && this.managementPort.equals(8080))
|| (this.managementPort != 0 && this.managementPort.equals(serverPort))) ? SAME : DIFFERENT);
}
}
d.测试结果
修改后重新测试后,相同接口QPS从1KQps提升至5K+Qps,提升了至少有5倍
2.15 [3]gateway:@RefreshScope
01.介绍
通常情况下,Spring Boot 的 Bean 在初始化时就注册完毕,其内部的配置信息在生命周期内不会再发生变更
然而,当我们需要修改这些配置信息并使其生效时,如何刷新相关的 Bean 成为了一个需要解决的问题
尽管实现这一目标的方法有很多,但本文将基于 @RefreshScope 和数据库配置来实现手动刷新 Bean,从而支持配置的动态变更
02.@RefreshScope
a.说明
Spring Cloud 提供的一个功能注解,用于使被注解的 Bean 在运行时可以动态刷新配置
b.从数据库读取配置,并且在初始化的时候将ldap连接进行注册
@Bean
@RefreshScope
public LdapContextSource contextSource() {
//从数据库查询配置
LambdaQueryWrapper<SystemConfig> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(SystemConfig::getConfigType, "ldap");
List<SystemConfig> systemConfigList = systemConfigMapper.selectList(queryWrapper);
Map<String, Object> dictMap = systemConfigList.stream().collect(HashMap::new, (map, item) -> map.put(item.getConfigName(), item.getConfigValue()), HashMap::putAll);
//配置LDAP连接属性
LdapContextSource contextSource = new LdapContextSource();
Map<String, Object> config = new HashMap();
contextSource.setUrl(dictMap.get("url").toString());
contextSource.setBase(dictMap.get("base").toString());
contextSource.setUserDn(dictMap.get("username").toString());
contextSource.setPassword(dictMap.get("password").toString());
// 解决乱码
config.put("java.naming.ldap.attributes.binary", "objectGUID");
//关闭ldap pooling
contextSource.setPooled(false);
contextSource.setBaseEnvironmentProperties(config);
return contextSource;
}
//创建ldap的连接bean
@Bean
public LdapTemplate ldapTemplate() {
return new LdapTemplate(contextSource());
}
c.手动触发bean刷新
@Component
public class RefreshService {
private final RefreshScope refreshScope;
@Autowired
public RefreshService(RefreshScope refreshScope) {
this.refreshScope = refreshScope;
}
public void refreshMyBean() {
// 这里 "contextSource,userRepository" 是 @RefreshScope Bean 的名称
refreshScope.refresh("contextSource");
refreshScope.refresh("userRepository");
}
}
-----------------------------------------------------------------------------------------------------
//在需要触发的地方进行注入
@Resource
private RefreshService refreshService;
//直接调用即可动态从数据库读取配置,进行刷新
refreshService.refreshMyBean();
2.16 [4]oenfeign:概况
00.总结
a.原理
OpenFeign 会扫描带有 @FeignClient 注解的接口,然后为其生成一个动态代理
动态代理里面包含有接口方法的 MethodHandler,MethodHandler 里面又包含经过 MVC Contract 解析注解后的元数据
发起请求时,MethodHandler 会生成一个 Request
负载均衡器 Ribbon 会从服务列表中选取一个 Server,拿到对应的 IP 地址后,拼接成最后的 URL,就可以发起远程服务调用了
b.设计点
1.如何使远程调用像本地方法调用简单
2.Feign如何找到远程服务的地址的
3.Feign是如何进行负载均衡的
01.理解远程调用
a.说明1
远程调用和本地调用是相对的,那我们先说本地调用更好理解些,本地调用就是同一个 Service 里面的方法 A 调用方法 B
那远程调用就是不同 Service 之间的方法调用。Service 级的方法调用,就是我们自己构造请求 URL和请求参数,就可以发起远程调用了
在服务之间调用的话,我们都是基于 HTTP 协议,一般用到的远程服务框架有 OKHttp3,Netty, HttpURLConnection 等
-----------------------------------------------------------------------------------------------------
但是这种虚线方框中的构造请求的过程是很繁琐的,有没有更简便的方式呢
Feign 就是来简化我们发起远程调用的代码的,那简化到什么程度呢?简化成就像调用本地方法那样简单
b.说明2
//远程调用拿到该用户的学习时长
R memberStudyTimeList = studyTimeFeignService.getMemberStudyTimeListTest(id);
02.Feign和OpenFeign
a.说明1
OpenFeign 组件的前身是 Netflix Feign 项目,它最早是作为 Netflix OSS 项目的一部分,由 Netflix 公司开发
后来 Feign 项目被贡献给了开源组织,于是才有了我们今天使用的 Spring Cloud OpenFeign 组件
Feign 和 OpenFeign 有很多大同小异之处,不同的是 OpenFeign 支持 MVC 注解
可以认为 OpenFeign 为 Feign 的增强版
b.说明2
OpenFeign 能用来做什么:
OpenFeign 是声明式的 HTTP 客户端,让远程调用更简单
提供了HTTP请求的模板,编写简单的接口和插入注解,就可以定义好HTTP请求的参数、格式、地址等信息
整合了Ribbon(负载均衡组件)和 Hystix(服务熔断组件),不需要显示使用这两个组件
Spring Cloud Feign 在 Netflix Feign的基础上扩展了对SpringMVC注解的支持
03.OpenFeign如何用?
a.说明
OpenFeign 的使用也很简单,这里还是用我的开源 SpringCloud 项目 PassJava 作为示例
开源地址: https://github.com/Jackson0714/PassJava-Platform
Member 服务远程调用 Study 服务的方法 memberStudyTime()
b.第一步:Member 服务需要定义一个 OpenFeign 接口
@FeignClient("passjava-study")
public interface StudyTimeFeignService {
@RequestMapping("study/studytime/member/list/test/{id}")
public R getMemberStudyTimeListTest(@PathVariable("id") Long id);
}
我们可以看到这个 interface 上添加了注解@FeignClient,而且括号里面指定了服务名:passjava-study。显示声明这个接口用来远程调用 passjava-study服务
c.第二步:Member 启动类上添加 @EnableFeignClients注解开启远程调用服务,且需要开启服务发现
@EnableFeignClients(basePackages = "com.jackson0714.passjava.member.feign")
@EnableDiscoveryClient
d.第三步:Study 服务定义一个方法,其方法路径和 Member 服务中的接口 URL 地址一致即可
URL 地址:"study/studytime/member/list/test/{id}"
@RestController
@RequestMapping("study/studytime")
public class StudyTimeController {
@RequestMapping("/member/list/test/{id}")
public R memberStudyTimeTest(@PathVariable("id") Long id) {
...
}
}
e.第四步:Member 服务的 POM 文件中引入 OpenFeign 组件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
f.第五步:引入 studyTimeFeignService,Member 服务远程调用 Study 服务即可
Autowired
private StudyTimeFeignService studyTimeFeignService;
studyTimeFeignService.getMemberStudyTimeListTest(id);
g.总结
通过上面的示例,我们知道,加了 @FeignClient 注解的接口后,我们就可以调用它定义的接口,然后就可以调用到远程服务了
这里你是否有疑问:为什么接口都没有实现,就可以调用了?
OpenFeign 使用起来倒是简单,但是里面的原理可没有那么简单,OpenFeign 帮我们做了很多事情,接下来我们来看下 OpenFeign 的架构原理
04.梳理OpenFeign的核心流程
1.在 Spring 项目启动阶段,服务 A 的OpenFeign 框架会发起一个主动的扫包流程
2.从指定的目录下扫描并加载所有被 @FeignClient 注解修饰的接口,然后将这些接口转换成 Bean,统一交给 Spring 来管理
3.根据这些接口会经过 MVC Contract 协议解析,将方法上的注解都解析出来,放到 MethodMetadata 元数据中
4.基于上面加载的每一个 FeignClient 接口,会生成一个动态代理对象,指向了一个包含对应方法的 MethodHandler 的 HashMap。MethodHandler 对元数据有引用关系。生成的动态代理对象会被添加到 Spring 容器中,并注入到对应的服务里
5.服务 A 调用接口,准备发起远程调用
6.从动态代理对象 Proxy 中找到一个 MethodHandler 实例,生成 Request,包含有服务的请求 URL(不包含服务的 IP)
7.经过负载均衡算法找到一个服务的 IP 地址,拼接出请求的 URL
8.服务 B 处理服务 A 发起的远程调用请求,执行业务逻辑后,返回响应给服务 A
05.OpenFeign包扫描原理
a.注解
涉及到了一个 OpenFeign 的注解:@EnableFeignClients。根据字面意思可以知道,可以注解是开启 OpenFeign 功能的
b.包扫描的基本流程如下
开启OpenFeign:@EnableFeignClientS
Import FeignClientsRegistrar类
查找带有@FeignClient注解的类、接口findCandidateComponents
是否是接口?只保留带有@FeignClient的接口
c.流程
a.@EnableFeignClients 这个注解使用 Spring 框架的 Import 注解导入了 FeignClientsRegistrar 类,开始了 OpenFeign 组件的加载
// 启动类加上这个注解
@EnableFeignClients(basePackages = "com.jackson0714.passjava.member.feign")
// EnableFeignClients 类还引入了 FeignClientsRegistrar 类
@Import(FeignClientsRegistrar.class)
public @interface EnableFeignClients {
...
}
b.FeignClientsRegistrar 负责 Feign 接口的加载
@Override
public void registerBeanDefinitions(AnnotationMetadata metadata,
BeanDefinitionRegistry registry) {
// 注册配置
registerDefaultConfiguration(metadata, registry);
// 注册 FeignClient
registerFeignClients(metadata, registry);
}
c.registerFeignClients 会扫描指定包
核心源码如下,调用 find 方法来查找指定路径 basePackage 的所有带有 @FeignClients 注解的带有 @FeignClient 注解的类、接口
Set<BeanDefinition> candidateComponents = scanner.findCandidateComponents(basePackage);
d.只保留带有 @FeignClient 的接口
// 判断是否是带有注解的 Bean
if (candidateComponent instanceof AnnotatedBeanDefinition) {
// 判断是否是接口
AnnotatedBeanDefinition beanDefinition = (AnnotatedBeanDefinition) candidateComponent;
AnnotationMetadata annotationMetadata = beanDefinition.getMetadata();
// @FeignClient 只能指定在接口上
Assert.isTrue(annotationMetadata.isInterface(),
"@FeignClient can only be specified on an interface");
06.注册FeignClient到Spring的原理
a.还是在 registerFeignClients 方法中,当 FeignClient 扫描完后,就要为这些 FeignClient 接口生成一个动态代理对象
顺藤摸瓜,进到这个方法里面,可以看到这一段代码
BeanDefinitionBuilder definition = BeanDefinitionBuilder
.genericBeanDefinition(FeignClientFactoryBean.class);
-----------------------------------------------------------------------------------------------------
核心就是 FeignClientFactoryBean 类,根据类的名字我们可以知道这是一个工厂类,用来创建 FeignClient Bean 的
我们最开始用的 @FeignClient,里面有个参数 "passjava-study"
这个是注解的属性,当 OpenFeign 框架去创建 FeignClient Bean 的时候,就会使用这些参数去生成 Bean
b.流程
解析 @FeignClient 定义的属性
将注解@FeignClient 的属性 + 接口 StudyTimeFeignService的信息构造成一个 StudyTimeFeignService 的 beanDefinition
然后将 beanDefinition 转换成一个 holder,这个 holder 就是包含了 beanDefinition, alias, beanName 信息
最后将这个 holder 注册到 Spring 容器中
c.源码如下
// 生成 beanDefinition
AbstractBeanDefinition beanDefinition = definition.getBeanDefinition();
// 转换成 holder,包含了 beanDefinition, alias, beanName 信息
BeanDefinitionHolder holder = new BeanDefinitionHolder(beanDefinition, className,
new String[] { alias });
// 注册到 Spring 上下文中。
BeanDefinitionReaderUtils.registerBeanDefinition(holder, registry);
-----------------------------------------------------------------------------------------------------
上面我们已经知道 FeignClient 的接口是如何注册到 Spring 容器中了。后面服务要调用接口的时候,就可以直接用 FeignClient 的接口方法了
@Autowired
private StudyTimeFeignService studyTimeFeignService;
// 省略部分代码
// 直接调用
studyTimeFeignService.getMemberStudyTimeListTest(id);
-----------------------------------------------------------------------------------------------------
但是我们并没有细讲这个 FeignClient 的创建细节,下面我们看下 FeignClient 的创建细节,这个也是 OpenFeign 核心原理
07.OpenFeign动态代理原理
a.在创建 FeignClient Bean 的过程中就会去生成动态代理对象。调用接口时,其实就是调用动态代理对象的方法来发起请求的
分析动态代理的入口方法为 getObject()。源码如下所示:
Targeter targeter = get(context, Targeter.class);
return (T) targeter.target(this, builder, context,
new HardCodedTarget<>(this.type, this.name, url));
-----------------------------------------------------------------------------------------------------
接着调用 target 方法这一块,里面的代码真的很多很细,我把核心的代码拿出来给大家讲下,这个 target 会有两种实现类
DefaultTargeter 和 HystrixTargeter。而不论是哪种 target,都需要去调用 Feign.java 的 builder 方法去构造一个 feign client
b.在构造的过程中,依赖 ReflectiveFeign 去构造,源码如下
// 省略部分代码
public class ReflectiveFeign extends Feign {
// 为 feign client 接口中的每个接口方法创建一个 methodHandler
public <T> T newInstance(Target<T> target) {
for(...) {
methodToHandler.put(method, handler);
}
// 基于 JDK 动态代理的机制,创建了一个 passjava-study 接口的动态代理,所有对接口的调用都会被拦截,然后转交给 handler 的方法
InvocationHandler handler = factory.create(target, methodToHandler);
T proxy = (T) Proxy.newProxyInstance(target.type().getClassLoader(),
new Class<?>[] {target.type()}, handler);
}
c.说明
ReflectiveFeign 做的工作就是为带有 @FeignClient 注解的接口,创建出接口方法的动态代理对象
比如示例代码中的接口 StudyTimeFeignService,会给这个接口中的方法 getMemberStudyTimeList 创建一个动态代理对象
@FeignClient("passjava-study")
public interface StudyTimeFeignService {
@RequestMapping("study/studytime/member/list/test/{id}")
public R getMemberStudyTimeList(@PathVariable("id") Long id);
}
d.流程
解析 FeignClient 接口上各个方法级别的注解,比如远程接口的 URL、接口类型(Get、Post 等)、各个请求参数等。这里用到了 MVC Contract 协议解析,后面会讲到
然后将解析到的数据封装成元数据,并为每一个方法生成一个对应的 MethodHandler 类作为方法级别的代理。相当于把服务的请求地址、接口类型等都帮我们封装好了,这些 MethodHandler 方法会放到一个 HashMap 中
然后会生成一个 InvocationHandler 用来管理这个 hashMap,其中 Dispatch 指向这个 HashMap
然后使用 Java 的 JDK 原生的动态代理,实现了 FeignClient 接口的动态代理 Proxy 对象。这个 Proxy 会添加到 Spring 容器中
当要调用接口方法时,其实会调用动态代理 Proxy 对象的 methodHandler 来发送请求
08.解析MVC注解的原理
a.说明
接口上是有一些注解的,比如 @RequestMapping,@PathVariable,这些注解统称为 Spring MVC 注解
但是由于 OpenFeign 是不理解这些注解的,所以需要进行一次解析
b.而解析的类就是 SpringMvcContract 类,调用 parseAndValidateMetadata 进行解析。解析完之后,就会生成元数据列表
List<MethodMetadata> metadata = contract.parseAndValidateMetadata(target.type());
https://github.com/spring-cloud/spring-cloud-openfeign/blob/main/spring-cloud-openfeign-core/src/main/java/org/springframework/cloud/openfeign/support/SpringMvcContract.java
-----------------------------------------------------------------------------------------------------
这个元数据 MethodMetadata 里面有什么东西呢?
方法的定义,如 StudyTimeFeignService 的 getMemberStudyTimeList 方法
方法的参数类型,如 Long
发送 HTTP 请求的地址,如 /study/studytime/member/list/test/{id}
-----------------------------------------------------------------------------------------------------
然后每个接口方法就会有对应的一个 MethodHandler,它里面就包含了元数据
当我们调用接口方法时,其实是调用动态代理对象的 MethodHandler 来发送远程调用请求的
-----------------------------------------------------------------------------------------------------
上面我们针对 OpenFeign 框架如何为 FeignClient 接口生成动态代理已经讲完了
下面我们再来看下当我们调用接口方法时,动态代理对象是如何发送远程调用请求的
09.OpenFeign发送请求的原理
a.还是在 ReflectiveFeign 类中,有一个 invoke 方法,会执行以下代码
dispatch.get(method).invoke(args);
-----------------------------------------------------------------------------------------------------
这个 dispatch 我们之前已经讲解过了,它指向了一个 HashMap,里面包含了 FeignClient 每个接口的 MethodHandler 类
这行代码的意思就是根据 method 找到 MethodHandler,调用它的 invoke 方法,并且传的参数就是我们接口中的定义的参数
b.那我们再跟进去看下这个 MethodHandler invoke 方法里面做了什么事情
public Object invoke(Object[] argv) throws Throwable {
RequestTemplate template = buildTemplateFromArgs.create(argv);
...
}
-----------------------------------------------------------------------------------------------------
我们可以看到这个方法里面生成了 RequestTemplate,它的值类似如下:
GET /study/list/test/1 HTTP/1.1
-----------------------------------------------------------------------------------------------------
RequestTemplate 转换成 Request,它的值类似如下:
GET http://passjava-study/study/list/test/1 HTTP/1.1
-----------------------------------------------------------------------------------------------------
这路径不就是我们要 study 服务的方法,这样就可以直接调用到 study 服了呀
OpenFeign 帮我们组装好了发起远程调用的一切,我们只管调用就好了
接着 MethodHandler 会执行以下方法,发起 HTTP 请求
-----------------------------------------------------------------------------------------------------
client.execute(request, options);
从上面的我们要调用的服务就是 passjava-study,但是这个服务的具体 IP 地址我们是不知道的,那 OpenFeign 是如何获取到 passjava-study 服务的 IP 地址的呢?
回想下最开始我们提出的核心问题:OpenFeign 是如何进行负载均衡的?
我们是否可以联想到上一讲的 Ribbon 负载均衡,它不就是用来做 IP 地址选择的么?
那我们就来看下 OpenFeign 又是如何和 Ribbon 进行整合的
10.OpenFeign如何与Ribbon整合的原理
a.前提
为了验证 Ribbon 的负载均衡,我们需要启动两个 passjava-study 服务
这里我启动了两个服务,端口号分别为 12100 和 12200,IP 地址都是本机 IP:192.168.10.197
b.流程
client.execute() 方法其实会调用 LoadBalancerFeignClient 的 exceute 方法
将服务名称 passjava-study 从 Request 的 URL 中删掉,剩下的如下所示:GET http:///study/list/test/1 HTTP/1.1
根据服务名从缓存中找 FeignLoadBalancer,如果缓存中没有,则创建一个 FeignLoadBalancer
FeignLoadBalancer 会创建出一个 command,这个 command 会执行一个 sumbit 方法
submit 方法里面就会用 Ribbon 的负载均衡算法选择一个 server。源码如下:Server svc = lb.chooseServer(loadBalancerKey);
通过 debug 调试,我们可以看到两次请求的端口号不一样,一个是 12200,一个是 12100,说明确实进行了负载均衡。
然后将 IP 地址和之前剔除掉服务名称的 URL 进行拼接,生成最后的服务地址
最后 FeignLoadBalancer 执行 execute 方法发送请求
c.Ribbon 是如何拿到服务地址列表的
Ribbon 的核心组件 ServerListUpdater,用来同步注册表的,它有一个实现类 PollingServerListUpdater
专门用来做定时同步的。默认1s 后执行一个 Runnable 线程,后面就是每隔 30s 执行 Runnable 线程
这个 Runnable 线程就是去获取注册中心的注册表的
11.OpenFeign处理响应的原理
当远程服务 passjava-study 处理完业务逻辑后
就会返回 reponse 给 passjava-member 服务了,这里还会对 reponse 进行一次解码操作
Object result = decode(response);
这个里面做的事情就是调用 ResponseEntityDecoder 的 decode 方法,将 Json 字符串转化为 Bean 对象
2.17 [4]oenfeign:示例1
01.概况
a.介绍
Spring Cloud OpenFeign 是一个声明式的 HTTP 客户端,旨在简化微服务之间的通信
它使得开发者能够通过简单的接口定义和注解来调用 RESTful API,极大地减少了样板代码
b.应用场景
a.微服务间调用
在微服务架构中,服务之间需要频繁地进行 HTTP 调用,OpenFeign 提供了一种简洁的方式来实现这些调用
b.RESTful API 客户端
当需要与外部 RESTful API 进行交互时,OpenFeign 可以帮助快速构建客户端
c.服务发现
与 Eureka 等服务发现组件结合使用时,OpenFeign 可以自动处理服务的负载均衡和故障转移
d.动态配置
在需要根据不同环境或条件动态配置请求时,OpenFeign 提供了灵活的解决方案
02.原理
a.内容
Spring Cloud OpenFeign 的核心原理是利用 Java 的动态代理和注解来简化 HTTP 请求的构建
开发者只需定义接口,并使用注解描述请求的细节(如 HTTP 方法、路径、参数等)
在运行时,OpenFeign 会生成实现类并处理请求
b.主要组件
a.Feign Client
定义服务接口,使用注解描述请求
b.Request Interceptor
用于在请求发送之前对请求进行修改(如添加 header)
c.Encoder/Decoder
用于请求和响应的编码和解码,支持 JSON、XML 等格式
d.错误处理
提供自定义的错误处理机制,以便在请求失败时进行处理
03.代码示例
a.依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springcloud-demo</artifactId>
<groupId>com.et</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>spring-cloud-openfeign</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>
b.启用 OpenFeign:在 Spring Boot 应用的主类上添加 @EnableFeignClients 注解
package com.et;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
c.创建一个 Feign Client 接口,使用注解定义请求
package com.et.service;
import com.et.model.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(name = "user-service", url = "http://localhost:8088")
public interface UserServiceClient {
@GetMapping("/user/{id}")
User getUserById(@PathVariable("id") Long id);
}
d.在服务中使用 Feign Client
package com.et.controller;
import com.et.model.User;
import com.et.service.UserService;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/users/{id}")
public User getUser(@PathVariable Long id) {
return userService.getUser(id);
}
@GetMapping("/user/{id}")
public User user(@PathVariable Long id, HttpServletRequest request) {
// get username and password from header
String userHeader = request.getHeader("user");
String passwordHeader = request.getHeader("password");
// print params
System.out.println("User Header: " + userHeader);
System.out.println("Password Header: " + passwordHeader);
User user = new User();
user.setId(id);
user.setEmail("[email protected]");
user.setName("test");
return user;
}
}
04.拦截器
a.内容
OpenFeign 允许你使用请求拦截器来修改请求,例如添加 header、日志记录等。以下是如何实现一个简单的请求拦截器
b.创建拦截器
package com.et.interceptor;
import feign.RequestInterceptor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JSONPlaceHolderInterceptor {
@Value("${feign.client.config.default.username}")
private String username;
@Value("${feign.client.config.default.password}")
private String password;
@Bean
public RequestInterceptor requestInterceptor() {
return requestTemplate -> {
requestTemplate.header("user", username);
requestTemplate.header("password", password);
requestTemplate.header("Accept", "application/json");
};
}
}
c.在 Feign Client 中使用拦截器
server:
port: 8088
feign:
client:
config:
default:
username: xxxx
password: password
requestInterceptors:
com.et.interceptor.JSONPlaceHolderInterceptor
05.测试
a.内容
启动Spring CLoud应用,访问http://127.0.0.1:8088/users/1,返回结果如下
{"id":1,"name":"test","email":"[email protected]"}
b.查看控制台
发现获得拦截器设置的值
User Header: xxxx
Password Header: password
2.18 [4]oenfeign:示例2
00.说明
配合1:Feign + Eureka
配合2:openFeign + Nacos
01.依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 添加 nacos 框架依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>0.2.2.RELEASE</version>
</dependency>
<!-- 添加 openfeign 框架依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
</dependencies>
02.启动类上添加@EnableFeignClients注解
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
public class OpenFeignApplication {
public static void main(String[] args) {
SpringApplication.run(OpenFeignApplication.class, args);
}
}
03.创建生产者
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class EchoController {
// 处理来自 Feign 客户端的 GET 请求
@GetMapping("/echo/{str}")
public String echo(@PathVariable String str) {
// 返回请求的字符串,前面加上 "Echo: "
return "Echo: " + str;
}
}
04.创建openFeign的client:调用生产者接口
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
@FeignClient("service-provider")
public interface ConsumeClient {
@RequestMapping(value = "/echo/{str}", method = RequestMethod.GET)
String echo(@PathVariable String str);
}
---------------------------------------------------------------------------------------------------------
@FeignClient 填写生产者的服务名称
@RequestMapping填写生产者的rest路径
05.添加openFeign的controller接口
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class ConsumerController {
@Autowired
ConsumeClient client;
@RequestMapping(value = "/echo/{str}", method = RequestMethod.GET)
public String echo(@PathVariable String str) {
return client.echo(str);
}
}
06.编写启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
public class OpenFeignApplication {
public static void main(String[] args) {
SpringApplication.run(OpenFeignApplication.class, args);
}
}
---------------------------------------------------------------------------------------------------------
注意添加@EnableFeignClients注解开启feign
07.配置文件
spring:
application:
name: openfeign-consumer
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
08.启动生产者和消费者
注册中心的作用只是告诉消费者服务端的地址
类似 RestTemplate,本质上是 OpenFeign 的底层会用到 JDK 的 HttpURLConnection 发出 HTTP 请求
2.19 [4]oenfeign:替换http
01.默认
在 Feign 默认配置下,通常使用 HttpURLConnection 作为底层 HTTP 客户端
这种实现简单直接,但并不高效,尤其是在高并发场景下,每次请求都会创建新的连接
而连接的创建和销毁是非常昂贵的操作,可能导致资源浪费、延迟增加,甚至请求失败
02.替换Feign的默认客户端,支持连接池
a.方式1:使用Apache HttpClient
a.说明
Apache HttpClient 是一个功能强大的 HTTP 客户端库,支持连接池管理和多种优化配置
b.代码
@Bean
public ApacheHttpClient feignClient() {
return new ApacheHttpClient(HttpClients.custom()
.setMaxConnTotal(200) // 设置最大连接数
.setMaxConnPerRoute(50) // 设置每个路由的最大连接数
.setDefaultRequestConfig(RequestConfig.custom()
.setConnectTimeout(5000) // 设置连接超时时间
.setSocketTimeout(5000) // 设置读超时时间
.build())
.build());
}
b.方式2:使用OkHttp
a.说明
OkHttp 是另一个高效的 HTTP 客户端库,默认支持连接池并提供更轻量的实现
b.代码
@Bean
public OkHttpClient okHttpClient() {
return new OkHttpClient.Builder()
.connectionPool(new ConnectionPool(50, 5, TimeUnit.MINUTES)) // 配置连接池大小与存活时间
.connectTimeout(5, TimeUnit.SECONDS) // 设置连接超时时间
.readTimeout(5, TimeUnit.SECONDS) // 设置读取超时时间
.build();
}
c.在使用 OkHttp 时,需要添加 Feign 的 OkHttp 适配器
@Bean
public Feign.Builder feignBuilder(OkHttpClient okHttpClient) {
return Feign.builder().client(new feign.okhttp.OkHttpClient(okHttpClient));
}
03.连接池的关键配置
a.最大连接数(Max Connections)
定义连接池中允许的最大连接数。对于高并发场景,应该根据系统的吞吐量需求适当增大此值
b.每个路由的最大连接数(Max Connections Per Route)
控制同一目标服务的最大连接数,以避免单个服务占用过多连接资源
c.空闲连接的存活时间(Keep-Alive Time)
设置空闲连接在连接池中的存活时间,过短会导致频繁的连接关闭与创建,过长则可能浪费资源
d.连接超时与读取超时
连接超时:控制连接建立的最大时间,防止因目标服务不可用导致的长时间阻塞
读取超时:设置等待响应数据的最大时间,避免长时间的无效等待
2.20 [5]sentinel:概况
00.概述
a.定义
Sentinel是阿里巴巴开源的一个流量控制和熔断降级组件
主要用于分布式系统中的流量控制、熔断降级和系统自适应保护
它帮助开发者在微服务架构中实现高可用性和稳定性
b.功能
1.熔断降级
2.限流
3.系统自适应保护:根据系统的负载情况自动调整限流策略
4.热点参数限流:对请求中的参数进行限流
5.集群流量控制:支持集群模式下的流量控制
6.实时监控:通过 Sentinel Dashboard 实时监控流量、规则和异常
7规则持久化:支持将规则持久化到数据存储中,如 Nacos、Apollo
01.熔断降级(Circuit Breaking)
a.定义
熔断降级是指在服务不可用或响应时间过长时,提供一个降级的服务或默认的响应,保证系统的基本功能可用
b.原理
通过在服务调用失败或超时时,执行预先定义的降级逻辑,返回默认值或执行备用逻辑,确保系统的稳定性和用户体验
c.常用API
DegradeRule:定义熔断降级规则
DegradeRuleManager:管理熔断降级规则
d.使用步骤
引入 Sentinel 依赖
配置熔断降级规则
在代码中使用熔断降级规则
e.代码示例
a.配置熔断降级规则
DegradeRule rule = new DegradeRule();
rule.setResource("someResource");
rule.setGrade(RuleConstant.DEGRADE_GRADE_RT);
rule.setCount(100);
rule.setTimeWindow(10);
DegradeRuleManager.loadRules(Collections.singletonList(rule));
b.使用熔断降级规则
Entry entry = null;
try {
entry = SphU.entry("someResource");
// 被保护的业务逻辑
System.out.println("Request passed");
} catch (BlockException e) {
// 熔断降级逻辑处理
System.out.println("Request degraded");
} finally {
if (entry != null) {
entry.exit();
}
}
02.限流(Rate Limiting)
a.定义
限流是指在高并发场景下,通过限制请求的数量或速率,保护系统不被过载,保证系统的稳定性
b.原理
通过设置请求的最大并发数或速率,当请求超过设定的阈值时
拒绝或延迟处理部分请求,确保系统在高负载下仍能稳定运行
c.常用API
FlowRule:定义限流规则
FlowRuleManager:管理限流规则
d.使用步骤
引入 Sentinel 依赖
配置限流规则
在代码中使用限流规则
e.代码示例
a.引入依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.0</version>
</dependency>
b.配置限流规则
FlowRule rule = new FlowRule();
rule.setResource("someResource");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(10);
FlowRuleManager.loadRules(Collections.singletonList(rule));
c.使用限流规则
Entry entry = null;
try {
entry = SphU.entry("someResource");
// 被保护的业务逻辑
System.out.println("Request passed");
} catch (BlockException e) {
// 限流逻辑处理
System.out.println("Request blocked");
} finally {
if (entry != null) {
entry.exit();
}
}
03.系统自适应保护
a.定义
系统自适应保护是 Sentinel 提供的一种根据系统的负载情况自动调整限流策略的功能
b.原理
通过监控系统的关键指标(如 CPU 使用率、内存使用率等),动态调整限流策略
以确保系统在高负载情况下仍能稳定运行
c.常用API
SystemRule:定义系统保护规则
SystemRuleManager:管理系统保护规则
d.使用步骤
引入 Sentinel 依赖
配置系统保护规则
在代码中使用系统保护规则
e.代码示例
SystemRule rule = new SystemRule();
rule.setResource("someResource");
rule.setHighestSystemLoad(3.0); // 设置系统负载阈值
SystemRuleManager.loadRules(Collections.singletonList(rule));
04.热点参数限流
a.定义
热点参数限流是指对请求中的参数进行限流,以防止某些参数的请求过多导致系统过载
b.原理
通过对请求参数进行统计和分析,设置限流规则,限制特定参数的请求数量
c.常用API
ParamFlowRule:定义参数限流规则
ParamFlowRuleManager:管理参数限流规则
d.使用步骤
引入 Sentinel 依赖
配置参数限流规则
在代码中使用参数限流规则
e.代码示例
ParamFlowRule rule = new ParamFlowRule("someResource")
.setParamIdx(0) // 针对第一个参数进行限流
.setCount(10); // 每秒最多允许 10 次请求
ParamFlowRuleManager.loadRules(Collections.singletonList(rule));
05.集群流量控制
a.定义
集群流量控制是指在集群模式下进行流量控制,确保整个集群的流量在可控范围内
b.原理
通过在集群中部署 Sentinel 集群客户端和服务端,统一管理和控制集群中的流量
c.常用API
ClusterFlowRule:定义集群流量控制规则
ClusterFlowRuleManager:管理集群流量控制规则
d.使用步骤
引入 Sentinel 依赖
配置集群流量控制规则
在代码中使用集群流量控制规则
e.代码示例
ClusterFlowRule rule = new ClusterFlowRule("someResource")
.setCount(100); // 集群中每秒最多允许 100 次请求
ClusterFlowRuleManager.loadRules(Collections.singletonList(rule));
06.实时监控
a.定义
实时监控是通过 Sentinel Dashboard 实时监控流量、规则和异常的功能
b.原理
通过在应用中集成 Sentinel 客户端,向 Sentinel Dashboard 发送实时数据,Dashboard 展示流量、规则和异常信息
c.常用API
Sentinel Dashboard 提供的监控接口
d.使用步骤
启动 Sentinel Dashboard
在应用中配置 Sentinel 客户端连接 Dashboard
在 Dashboard 中查看实时监控数据
e.代码示例
spring.cloud.sentinel.transport.dashboard=localhost:8080
07.规则持久化
a.定义
规则持久化是指将 Sentinel 的规则持久化到数据存储中,如 Nacos、Apollo 等
b.原理
通过将规则存储在外部配置中心,实现规则的集中管理和持久化
c.常用API
Sentinel 提供的规则持久化接口
d.使用步骤
引入 Sentinel 依赖
配置规则持久化存储
在代码中使用持久化规则
e.代码示例
// 使用 Nacos 作为规则持久化存储
NacosDataSource<String, List<FlowRule>> flowRuleDataSource = new NacosDataSource<>(
"localhost:8848", "group", "dataId",
source -> JSON.parseObject(source, new TypeReference<List<FlowRule>>() {})
);
FlowRuleManager.register2Property(flowRuleDataSource.getProperty());
2.21 [5]sentinel:限流
00.汇总
1.通过代码实现限流
2.通过控制台实现限流
01.通过代码实现限流
a.定义资源
a.说明
定义资源可以通过代码方式或注解方式来实现
b.通过代码定义资源
a.说明
可以通过代码的的方式 SphU.entry("resourceName") 来定义资源
b.代码
@RequestMapping("/getuser")
public String getUser() {
try (Entry entry = SphU.entry("getuser")) {
// 被保护逻辑
return "User";
} catch (Exception e) {
// 限流之后的业务逻辑
return "被限流了";
}
}
c.通过注解方式定义资源
a.说明
通过注解 @SentinelResource 也可以实现资源的定义
b.代码
// 定义资源和限流后触发的方法
@SentinelResource(value = "resourceName", blockHandler = "myBlockHandler")
@RequestMapping("/getnamebyid")
public String getNameById(Integer id) {
return id + "-lei";
}
// 限流后触发的方法
public String myBlockHandler(Integer id, BlockException blockException) {
String msg = "Do myBlockHandler method.";
System.out.println(msg);
return msg;
}
c.说明
其中,value 属性定义的资源名称,blockHandler 定义的是原方法被限流/降级/系统保护之后执行的方法
b.定义限流规则
a.说明
在 Spring Boot 项目中,只需要将限流规则添加到项目启动时执行即可
b.代码
public static void main(String[] args) {
SpringApplication.run(SentinelDemoApplication.class, args);
// 加载限流规则
initFlowRules();
}
c.限流规则定义
private static void initFlowRules() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("resourceName"); // 资源名称
rule.setGrade(RuleConstant.FLOW_GRADE_QPS); // 根据 QPS 限流
rule.setCount(1); // QPS 阈值【每秒只允许通过一个请求】
rule.setStrategy(RuleConstant.STRATEGY_DIRECT); // 调用关系限流策略【非必须设置】
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT); // 流控效果【非必须设置】
rule.setClusterMode(false); // 是否集群限流【非必须设置,默认非集群】
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
d.说明
setStrategy:设置调用关系限流策略,包含的值有:
直接(RuleConstant.STRATEGY_DIRECT)【默认值】
链路(RuleConstant.STRATEGY_RELATE)
关联 (RuleConstant.STRATEGY_CHAIN)
setControlBehavior:设置流控效果,包含的值有:
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)【默认值】
冷启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)
匀速启动(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)
冷启动+匀速启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP_RATE_LIMITER)
02.通过控制台实现限流
a.说明
Sentinel 还可以使用控制台的方式进行限流,不过默认情况下限流规则是保存在内存中,所以重启之后规则会丢失
b.实现步骤如下
下载并运行 Sentinel Dashboard(控制台)
在程序中加入并配置 Sentinel Dashboard
在 Sentinel Dashboard 配置限流/熔断等规则
验证效果
c.下载并运行控制台
https://github.com/alibaba/Sentinel/releases
java -jar sentinel-dashboard.jar --server.port=18080
从 Sentinel 1.6.0 起,Sentinel 控制台引入基本的登录功能,默认用户名和密码都是 sentinel
d.程序中加入Sentinel
a.依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
b.配置
spring:
application:
name: sentinel-dashboard-demo
cloud:
sentinel:
transport:
dashboard: localhost:18080
client-ip: 127.0.0.1
port: 8721
heartbeat-interval-ms: 10000
e.设置规则、新增限流规则
a.针对来源
Sentinel 可以针对调用者进行限流,填写具体微服务名时,指定对此微服务进行限流
默认值为 default(不区分来源,全部限制)
b.阈值类型/单机阈值
用于限制和控制流量的一种度量标准的类型,可以为 QPS(Queries Per Second,每秒请求数)也可以为“并发线程数”
QPS:每秒请求达到此值开始限流
并发线程数:请求此资源的线程达到某个值时限流。每个请求分配一个线程,当请求执行时间长时,很快就会触发限流,相反如果线程执行速度快,那么限流触发就会概率就会比较小
c.流控模式:流量控制模式
直接:接口达到限流条件时,直接限流
关联:当关联的资源达到阈值时,就限流自己
链路:指定资源从入口资源进来的流量,如果达到阈值,就进行限流
d.流控效果:流量控制效果
a.快速失败
该方式是默认的流量控制方式,比如 QPS 超过任意规则的阈值后,新的请求就会被立即拒绝
拒绝方式为抛出 FlowException。这种方式适用于对系统处理能力确切已知的情况下
比如通过压测确定了系统的准确水位时
b.排队等待(也叫匀速通过)
排队等待会严格控制请求通过的间隔时间,让请求稳定且匀速的通过,可以用来处理间隔性突发的高流量
例如抢票软件,在某一秒或者一分钟内有大量的请求到来,而接下来的一段时间里处于空闲状态
我们希望系统能够在接下来的空余时间里也能出去这些请求,而不是直接拒绝
在设置排队等待时,需要填写超时时间
c.Warm Up
此项叫做预热或者冷启动方式,此模式主要是防止流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮
通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限
给冷系统一个预热的时间,避免冷系统被压垮。当使用 Warm Up 模式时
我们还需要指定启动时开放的 QPS 比例(DEFAULT_COLD_FACTOR,默认值为 3,代表 30%)
以及系统预热所需时长(warmUpPeriodSec,默认值是 10 秒)
d.失败退化
a.当配置选项为"是"时
表示当 Token Server 不可用时,Sentinel 会自动切换为单机限流模式
在单机限流模式中,Sentine 会从本地的限流规则进行流量控制,不再依赖 Token Server
这样可以保证即使 Token Server 不可用,也能够继续对流量进行限制
b.当配置选项为"否"时
表示当 Token Server 不可用时,Sentinel 不会自动切换为单机限流模式,流量控制会被暂停
即无法进行限流,可能会导致服务负载过高
2.22 [5]sentinel:持久化
01.Sentinel规则持久化
Sentinel是Redis的高可用解决方案,它通过监控Redis主从架构来实现故障转移和高可用性
在使用Sentinel时,规则持久化是一个重要的方面,确保在Sentinel重启后能够恢复之前的配置和状态
02.Sentinel配置文件
a.说明
Sentinel的配置通常在`sentinel.conf`文件中进行设置
你可以在这个配置文件中定义监控的Redis实例、故障转移策略等
b.sentinel.conf
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
03.持久化机制
a.配置文件
Sentinel会在启动时读取`sentinel.conf`文件中的配置。你可以在这个文件中定义所有的监控规则和参数
b.运行时持久化
Sentinel会在运行时将其状态持久化到一个名为`sentinel-<master-name>.conf`的文件中
这个文件会在Sentinel运行时自动生成,包含当前监控的Redis实例和状态信息
04.持久化步骤
a.启动Sentinel
# 使用配置文件启动Sentinel
redis-sentinel /path/to/sentinel.conf
b.动态更新配置
# 在Sentinel运行时,你可以使用`SENTINEL`命令动态更新监控规则
SENTINEL MONITOR mymaster 127.0.0.1 6379 2
c.保存运行时状态
Sentinel会在运行时自动保存状态到`sentinel-<master-name>.conf`文件中
你可以在Sentinel重启后使用这个文件恢复状态
05.恢复配置
当Sentinel重启时,它会读取`sentinel.conf`文件中的配置
并加载`sentinel-<master-name>.conf`文件中的状态信息,以恢复之前的监控状态
06.基于Redis的持久化
a.RDB(快照)
定期将数据快照保存到磁盘
b.AOF(追加文件)
记录每个写操作,以便在重启时重放
2.23 [5]sentinel:自定义异常
00.汇总
自定义局部异常
自定义(Sentinel)全局异常
自定义系统异常
01.自定义局部异常
a.说明
自定义局部异常是在使用 @SentinelResource 注解时,直接定义的 blockHandler 异常方法
b.代码
@SentinelResource(value = "/user/getuser",
blockHandler = "myBlockHandler")
@RequestMapping("getuser")
public String getUser(Integer uid) {
return "User:" + uid;
}
/**
* 定义限流/熔断等异常
*/
public String myBlockHandler(Integer uid, BlockException e) {
String msg = "未知异常";
if (e instanceof FlowException) {
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
}
return msg;
}
c.说明
在定义 blockHandler 方法时,需要注意以下 3 个问题
1.自定义的 blockHandler 方法的返回值,必须要和原方法(使用 @SentinelResource 注解修饰的方法)的返回值保持一致
2.自定义的 blockHandler 方法的参数必须和原方法参数保持一致
3.自定义的 blockHandler 方法的方法参数中必须包含 BlockException 参数
如果不满足以上事项中的任何一项,那么就不能正常匹配到自定义的 blockHandler 方法,并且程序也会报错。
02.自定义(Sentinel)全局异常
a.说明
自定义 Sentinel 全局异常需要实现 BlockExceptionHandler 类,并重写 handle 方法
b.代码
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.BlockExceptionHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知异常";
int status = HttpStatus.TOO_MANY_REQUESTS.value();
if (e instanceof FlowException) {
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
status = HttpStatus.UNAUTHORIZED.value();
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{\"msg\": " + msg + ", \"code\": " + status + "}");
}
}
c.说明
自定义 Sentinel 全局异常是在执行 Sentinel 控制台设置的限流和熔断异常时,执行的全局自定义异常方法
但是,如果是程序中出现的 Sentinel 报错信息,例如使用热点限流时,因为要配合使用 @SentinelResource 注解时
此时只自定义了 value 属性,未定义局部 blockHandler 方法,此时系统就会报错
但这个时候并不会执行 Sentinel 全局自定义异常,而是程序报错
此时就需要使用系统自定义异常来重新定义异常信息了
03.自定义系统异常
a.说明
自定义系统异常需要新建一个异常类,并且使用 @RestControllerAdvice 注解修饰此类
并配合 @ExceptionHandler 注解来完成全局系统异常的获取和定义
b.代码
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.util.HashMap;
import java.util.Map;
@RestControllerAdvice
public class CustomExceptionHandler {
/**
* 限流全局异常
*/
@ExceptionHandler(FlowException.class)
public Map handlerFlowException(){
return new HashMap(){{
put("code", HttpStatus.TOO_MANY_REQUESTS.value());
put("msg", "被限流");
}};
}
/**
* 熔断全局异常
*/
@ExceptionHandler(DegradeException.class)
public Map handlerDegradeException(){
return new HashMap(){{
put("code", HttpStatus.TOO_MANY_REQUESTS.value());
put("msg", "被熔断");
}};
}
/**
* 热点限流异常
*/
@ExceptionHandler(ParamFlowException.class)
public Map handlerparamFlowException(){
return new HashMap(){{
put("code", HttpStatus.TOO_MANY_REQUESTS.value());
put("msg", "热点限流");
}};
}
/**
* Sentinel 权限拦截全局异常
*/
@ExceptionHandler(AuthorityException.class)
@ResponseBody
public Map handlerAuthorityException(){
return new HashMap(){{
put("code", HttpStatus.UNAUTHORIZED.value());
put("msg", "暂无权限");
}};
}
}
c.说明
只要是系统中出现的 Sentinel 报错信息,都会被此方法所捕获,并通过自定义的代码完成自定义异常信息的返回
2.24 [5]sentinel:熔断、降级、限流
00.汇总
a.服务熔断
应对【雪崩效应】的一种微服务链路保护机制
当某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用
快速返回“错误”的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路
在Spring Cloud框架里熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的状况
当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制
b.服务降级
一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用
此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值
这样做,虽然水平下降,但好歹可用,比直接挂掉强
c.服务限流
可以认为是【服务降级的一种】,限流就是通过限制系统请求的输出和输出
从而实现对于系统的保护,这个和降级的概念很像,都是为了保证核心功能的正常运行
01.服务熔断(Circuit Breaker)
a.定义
服务熔断是一种保护机制,当某个服务的调用失败率达到一定阈值时
自动熔断该服务的调用,避免对下游服务造成更大的影响
b.原理
服务熔断器通过监控服务调用的成功和失败次数,当失败次数超过设定的阈值时,熔断器会进入“熔断”状态
短时间内不再调用该服务。经过一段时间后,熔断器会进入“半开”状态,允许部分请求通过
如果这些请求成功,熔断器会恢复到“闭合”状态,否则继续保持“熔断”状态
c.常用API
Hystrix:HystrixCommand
Resilience4j:CircuitBreaker
d.使用步骤
1.引入依赖
2.配置熔断器参数
3.在服务调用处使用熔断器
e.代码示例
a.Hystrix示例
public class HelloWorldCommand extends HystrixCommand<String> {
private final String name;
public HelloWorldCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
return "Hello " + name;
}
@Override
protected String getFallback() {
return "Fallback Hello " + name;
}
}
public static void main(String[] args) {
HelloWorldCommand command = new HelloWorldCommand("World");
String result = command.execute();
System.out.println(result);
}
b.Resilience4j示例
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("backendService");
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, () -> "Hello World");
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback")
.get();
System.out.println(result);
02.服务降级(Fallback)
a.定义
服务降级是指在服务不可用或响应时间过长时,提供一个降级的服务或默认的响应,保证系统的基本功能可用
b.原理
通过在服务调用失败或超时时,执行预先定义的降级逻辑,返回默认值或执行备用逻辑,确保系统的稳定性和用户体验
c.常用API
Hystrix:HystrixCommand的getFallback方法
Resilience4j:Fallback
d.使用步骤
1.引入依赖
2.配置降级逻辑
3.在服务调用处使用降级逻辑
e.代码示例
a.Hystrix示例
public class HelloWorldCommand extends HystrixCommand<String> {
private final String name;
public HelloWorldCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
throw new RuntimeException("Failed");
}
@Override
protected String getFallback() {
return "Fallback Hello " + name;
}
}
public static void main(String[] args) {
HelloWorldCommand command = new HelloWorldCommand("World");
String result = command.execute();
System.out.println(result);
}
b.Resilience4j示例
Supplier<String> supplier = () -> {
throw new RuntimeException("Failed");
};
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, supplier);
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback")
.get();
System.out.println(result);
03.服务限流(Rate Limiting)
a.定义
服务限流是指在高并发场景下,通过限制请求的数量或速率,保护系统不被过载,保证系统的稳定性
b.原理
通过设置请求的最大并发数或速率,当请求超过设定的阈值时,拒绝或延迟处理部分请求,确保系统在高负载下仍能稳定运行
c.常用API
Guava:RateLimiter
Resilience4j:RateLimiter
d.使用步骤
1.引入依赖
2.配置限流参数
3.在服务调用处使用限流器
e.代码示例
a.Guava示例
RateLimiter rateLimiter = RateLimiter.create(10.0); // 每秒10个请求
public void processRequest() {
if (rateLimiter.tryAcquire()) {
// 处理请求
System.out.println("Request processed");
} else {
// 拒绝请求
System.out.println("Request rejected");
}
}
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
new Thread(() -> processRequest()).start();
}
}
b.Resilience4j示例
RateLimiter rateLimiter = RateLimiter.ofDefaults("backendService");
Supplier<String> decoratedSupplier = RateLimiter
.decorateSupplier(rateLimiter, () -> "Hello World");
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback")
.get();
System.out.println(result);
2.25 [6]xxl-job:分布式任务
01.调度中心调度原理
a.说明
执行器内部会开启一个http服务器,用于接受调度中心的调度请求
每次的调度请求都会复用Http连接,避免多次连接消耗资源
b.调度步骤
调度中心从连接池中获取连接
调度中心发送调度请求(带有RequestId,JobLogId),并阻塞线程等待执行器响应
执行器返回调度响应,并异步执行定时任务
调度中心收到调度响应,根据回传的RequestId,回写数据库调取状态
执行器执行任务后,回调调度中心更新任务执行状态接口,根据JobLogId回写任务执行情况
3 说明
3.1 [1]ddd
01.介绍
a.说明
DDD(Domain-Driven Design,领域驱动设计)是一种软件设计方法,特别适用于复杂领域的应用程序开发
DDD的核心思想是通过关注业务领域的核心概念和逻辑,将软件设计与业务需求紧密结合
b.领域模型(Domain Model)
领域模型是对业务领域的抽象
通常由实体(Entity)、值对象(Value Object)、聚合(Aggregate)、聚合根(Aggregate Root)等组成
它们共同描述了业务逻辑和规则
c.实体(Entity)
具有唯一标识的对象,其生命周期内的状态可能会发生变化。例如,用户、订单等
d.值对象(Value Object)
没有唯一标识,通常是不可变的对象,用于描述某些属性或特征。例如,货币、地址等
e.聚合(Aggregate)和聚合根(Aggregate Root)
聚合是一个或多个实体和值对象的集合,聚合根是聚合的入口点,负责维护聚合内部的一致性
d.领域服务(Domain Service)
当某些业务逻辑无法归属于单个实体或值对象时,可以使用领域服务来实现
e.应用服务(Application Service)
负责协调领域对象以完成某个用例或业务流程,通常不包含业务逻辑
f.仓储(Repository)
用于持久化和检索聚合根
02.电商系统
a.实体
public class Order {
private String orderId;
private List<OrderItem> items;
private Customer customer;
// 业务逻辑方法
public void addItem(Product product, int quantity) {
// 添加商品到订单
}
public void removeItem(Product product) {
// 从订单中移除商品
}
}
b.值对象
public class Address {
private String street;
private String city;
private String postalCode;
// 构造函数、getters等
}
c.聚合根
public class Customer {
private String customerId;
private String name;
private Address address;
// 业务逻辑方法
public void changeAddress(Address newAddress) {
this.address = newAddress;
}
}
d.领域服务
public class ShippingService {
public void shipOrder(Order order) {
// 实现发货逻辑
}
}
e.仓储接口
public interface OrderRepository {
Order findById(String orderId);
void save(Order order);
}
f.应用服务
public class OrderApplicationService {
private OrderRepository orderRepository;
private ShippingService shippingService;
public void placeOrder(Order order) {
// 处理下单逻辑
orderRepository.save(order);
shippingService.shipOrder(order);
}
}
g.总结
在这个示例中,Order是一个实体,Address是一个值对象,Customer是一个聚合根
ShippingService是一个领域服务,OrderRepository是一个仓储接口,而OrderApplicationService是一个应用服务
通过这种方式,DDD架构帮助我们将业务逻辑与技术实现分离,使代码更易于理解和维护
3.2 [1]saas
01.三个概念
a.PaaS
英文就是 Platform-as-a-Service(平台即服务)
PaaS,某些时候也叫做中间件。就是把客户采用提供的开发语言和工具(例如Java,python, .Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去
客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置
PaaS 在网上提供各种开发和分发应用的解决方案,比如虚拟服务器和特定的操作系统。底层的平台3/4帮你铺建好了,你只需要开发自己的上层应用
这即节省了你在硬件上的费用,也让各类应用的开发更加便捷,不同的工作互相打通也变得容易,因为在同一平台上遵循的是同样的编程语言、协议和底层代码
b.IaaS
英文就是 Infrastructure-as-a-Service(基础设施即服务)
IaaS 提供给消费者的服务是对所有计算基础设施的利用,包括处理 CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序
消费者不管理或控制任何云计算基础设施,但能控制操作系统的选择、存储空间、部署的应用,也有可能获得有限制的网络组件(例如路由器、防火墙、负载均衡器等)的控制
IaaS 会提供场外服务器,存储和网络硬件,你可以租用。节省了维护成本和办公场地,公司可以在任何时候利用这些硬件来运行其应用
我们最熟悉的IaaS服务是我们服务器托管业务,多数的IDC都提供这样的服务,用户自己不想要再采购价格昂贵的服务器和磁盘阵列了
所有的硬件都由 IaaS 提供,你还能获得品质更高的网络资源
c.SaaS
英文就是 Software-as-a-Service(软件即服务)
SaaS提供给客户的服务是运行在云计算基础设施上的应用程序,用户可以在各种设备上通过客户端界面访问,如浏览器
消费者不需要管理或控制任何云计算基础设施,包括网络、服务器、操作系统、存储等等
SaaS 与我们普通使用者联系可能是最直接的,简单地说任何一个远程服务器上的应用都可以通过网络来运行,就是SaaS了
国内的互联网巨头竭力推荐的 SaaS 应用想必大家已经耳熟能详了
比如阿里的钉钉,腾讯的企业微信,这些软件里面应用平台上的可供使用的各类SaaS小软件数不胜数
从OA,到ERP到CRM等等,涵盖了企业运行所需的几乎所用应用
d.SaaS服务、传统服务、互联网服务
a.SaaS服务
介于传统与互联网之间,通过租用的方式提供服务,服务部署在云端,任何用户通过注册后进行订购后获得需要的服务,
可以理解成服务器及软件归供应商所有,用户通过付费获得使用权
b.传统软件
出售软件及配套设备,将软件部署在客户服务器或客户指定云服务器,出售的软件系统及运维服务为盈利来
c.互联网应用供应商
服务器部署在云端,所有用户可以通过客户端注册进行使用,广告及付费增值服务作为盈利来源
02.SaaS系统
a.两大特征
部署在供应商的服务器上,而不是部署在甲方的服务器上
订购模式,服务商提供大量功能供客户选择,客户可以选择自己需要的进行组合,支付所需的价格,并支持按服务时间付费
b.分类
a.业务型SaaS
定义:为客户的赚钱业务提供工具以及服务的SaaS,直面的是用户的生意,例如有赞微盟等电商SaaS以及销售CRM工具,为B2B2C企业
架构以及商业模式:在产品的成长期阶段,为了扩充业务规模和体量,业务SaaS产品会拓展为“多场景+多行业”的产品模式,为不同行业或者不同场景提供适应的解决方案,例如做电商独立站的有赞,后期发展为“商城、零售、美业、教育”多行业的解决方案进行售卖
b.效率型SaaS
定义:为客户效率提升工具的SaaS,如项目管理工具、Zoom等会议工具,提升办公或者生产效率,为B2B企业
架构以及商业模式:不同于业务型的SaaS,效率SaaS思考得更多的是企业内存在一个大共性的效率的问题,不同的企业对于CRM销售系统的需求是不一样的,但都需要一个协同办公的产品来提升协作效率。对于效率类SaaS来说,从哪来到哪去是非常清晰的,就是要解决优化或者解决一个流程上的问题
c.混合型SaaS
定义:即兼顾企业业务和效率效用SaaS,例如近几年在私域流量上大做文章的企业微信,其本身就是一个办公协同工具,但为企业提供了一整套的私域管理能力,实现业务的提升,同时也支持第三方服务
架构以及商业模式:混合SaaS是业务和效率SaaS的结合体,负责企业业务以及企业管理流程的某类场景上的降本增效;因混合SaaS核心业务的使用场景是清晰且通用的,非核心业务是近似于锦上添花的存在,所以在中台产品架构上更接近为“1+X”组合方式——即1个核心业务+X个非核心功能,两者在产品层级上是属于同一层级的
c.核心组件
a.安全组件
在SaaS产品中,系统安全永远是第一位需要考虑的事情
b.数据隔离组件
安全组件解决了用户数据安全可靠的问题,但数据往往还需要解决隐私问题,各企业之间的数据必须相互不可见,即相互隔离。
c.可配置组件
SaaS产品在设计之初就考虑了大多数通用的功能,让租户开箱即用,但任然有为数不少的租户需要定制服务自身业务需求的配置项,如UI布局、主题、标识(Logo)等信息
d.可扩展组件
SaaS产品应该具备水平扩展的能力。如通过网络负载均衡其和容器技术,在多个服务器上部署多个软件运行示例并提供相同的软件服务,以此实现水平扩展SaaS产品的整体服务性能
e.0停机时间升级产品
实现在不重启原有应用程序的情况下,完成应用程序的升级修复工作
f.多租户组件
SaaS产品需要同时容纳多个租户的数据,同时还需要保证各租户之间的数据不会相互干扰,保证租户中的用户能够按期望索引到正确的数据
d.如何SaaS化
进行云化部署,性能升级,能够支持更大规模的用户访问
用户系统改造,支持2C用户登录(手机号一键登录、小程序登录、短信验证码登录)
网关服务,限流,接口防篡改等等
租户系统开发,包含租户基础信息管理、租户绑定资源(订购的功能)、租户服务期限等等
客户端改造(通常SaaS系统主要提供WEB端服务),页面权限控制,根据租户系统用户资源提供用户已购买的模块或页面
官网开发,功能报价单,功能试用、用户选购及支付
服务端接口数据权限改造、租户级别数据权限
03.SaaS多租户
a.多租户核心概念
租户:一般指一个企业客户或个人客户,租户之间数据与行为是隔离的
用户:在某个租户内的具体使用者,可以通过使用账户名、密码等登录信息,登录到SaaS系统使用软件服务
组织:如果租户是一个企业客户,通常会拥有自己的组织架构
员工:是指组织内部具体的某位员工
解决方案:为了解决客户的某类型业务问题,SaaS服务商将产品与服务组合在一起,为商家提供整体的打包方案
产品能力:指的是SaaS服务商对客户售卖的产品应用,特指能够帮助客户实现端到端场景解决方案闭环的能力
资源域:用来运行1个或多个产品应用的一套云资源环境
云资源:SaaS产品一般都部署在各种云平台上,例如阿里云、腾讯云、华为云等。对这些云平台提供的计算、存储、网络、容器等资源,抽象为云资源
b.三大模式
a.竖井隔离模式
a.优势
满足强隔离需求:一些客户为了系统和数据的安全性,可能提出非常严格的隔离需求,期望软件产品能够部署在一套完全独立的环境中,不和其他租户的应用实例、数据放在一起
计费逻辑简单:SaaS服务商需要针对租户使用资源进行计费,对于复杂的业务场景,计算、存储、网络资源间的关系同样也会非常复杂,计费模型是很有挑战的,但在竖井模式下,计费模型相对来说是比较简单的
降低故障影响面:因为每个客户的系统都部署在自己的环境中,如果其中一个环境出现故障,并不会影响其他客户使用软件服务
b.劣势
规模化问题:由于租户的SaaS环境是独立的,所以每入驻一个租户,就需要创建和运营一套SaaS环境,如果只是少量的租户,还可能可以管理,但如果是成千上万的租户,管理和运营这些环境将会是非常大的挑战
成本问题:每个租户都有独立的环境,花费在单个客户上的成本将非常高,会大幅削弱SaaS软件服务的盈利能力
敏捷迭代问题:SaaS模式的一个优势是能够快速响应市场需求,迭代产品功能。但竖井隔离策略会阻碍这种敏捷迭代能力,因为更新、管理、支撑这些租户的SaaS环境,会变得非常复杂和低效
统一管理与监控:在同一套环境中,对部署的基础设施进行管理与监控,是较为简单的。但每个租户都有独立的环境,在这种非中心化的模式下,对每个租户的基础设施进行管理与监控,同样也是非常复杂、困难的
b.共享模式
a.优势
高效管理:在共享策略下,能够集中化地管理、运营所有租户,管理效率非常高。同时,对基础设施配置管理、监控,也将更加容易。相比竖井策略,产品的迭代更新会更快
成本低:SaaS服务商的成本结构中,很大一块是基础设施的成本。在共享模型下,服务商可以根据租户们的实际资源负载情况,动态伸缩系统,这样基础设施的利用率将非常高
b.劣势
租户相互影响:由于所有租户共享一套资源,当其中一个租户大量占用机器资源,其他租户的使用体验很可能受到影响,在这种场景下,需要在技术架构上设计一些限制措施(限流、降级、服务器隔离等),让影响面可控
租户计费困难:在竖井模型下,非常容易统计租户的资源消耗。然而,在共享模型下,由于所有租户共享一套资源,需要投入更多的精力统计单个租户的合理费用
c.分域隔离模式
略
c.多租户系统需要具备的能力
多个租户支持共享一套云资源,如计算、存储、网络资源等。单个租户也可以独占一套云资源
多个租户间能够实现数据与行为的隔离,能够对租户进行分权分域控制
租户内部能够支持基于组织架构的管理,可以对产品能力进行授权和管理
不同的产品能力可以根据客户需求,支持运行在不同的云资源上
3.3 [2]dubbo
01.定义
Dubbo是一款高性能、轻量级的开源RPC框架,提供服务自动注册、自动发现等高效服务治理方案,可以和Spring框架无缝集成
02.原理
Dubbo通过服务注册中心实现服务的自动注册与发现,消费者通过注册中心获取服务提供者的地址列表
并基于软负载均衡算法选择合适的服务提供者进行调用,Dubbo的核心功能包括网络通信、服务框架和服务注册
03.常用API
@Service:用于暴露服务
@Reference:用于引用服务
ApplicationConfig:配置应用信息
RegistryConfig:配置注册中心信息
ProtocolConfig:配置协议信息
ServiceConfig:配置服务提供者信息
ReferenceConfig:配置服务消费者信息
04.使用步骤
引入依赖:在项目中引入Dubbo相关依赖
配置注册中心:配置注册中心地址
配置服务提供者:使用@Service注解暴露服务
配置服务消费者:使用@Reference注解引用服务
启动应用:启动服务提供者和消费者应用
05.使用场景代码示例
a.透明化的远程方法调用
a.服务提供者
@Service
public class HelloServiceImpl implements HelloService {
@Override
public String sayHello(String name) {
return "Hello, " + name;
}
}
b.服务消费者
public class HelloConsumer {
@Reference
private HelloService helloService;
public void sayHello() {
String message = helloService.sayHello("Dubbo");
System.out.println(message);
}
}
b.软负载均衡及容错机制
a.配置文件
<dubbo:service interface="com.example.HelloService" ref="helloService" loadbalance="roundrobin"/>
c.服务自动注册与发现
a.配置文件
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:application name="hello-world-app"/>
3.4 [2]zookeeper
01.概述
a.定义
Zookeeper 是一个开源的分布式协调服务,它为分布式应用提供一致性服务
支持数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能
b.部署模式
单机部署:一台服务器上运行Zookeeper
集群部署:多台服务器上运行Zookeeper,提供高可用性
伪集群部署:一台服务器上启动多个Zookeeper实例,模拟集群环境
c.应用场景
数据发布/订阅:配置管理
负载均衡:动态发现服务提供者
命名服务:分布式系统中的命名服务
分布式协调/通知:分布式系统中的协调和通知
集群管理:监控节点状态
Master选举:选举主节点
分布式锁:实现分布式锁
分布式队列:实现分布式队列
d.功能
集群管理:监控节点存活状态、运行请求等
主节点选举:主节点挂掉后选举新的主节点
分布式锁:提供独占锁和共享锁
命名服务:根据名字获取资源或服务的地址
02.原理
通过原子广播机制保证各个服务器之间的同步,使用 Zab 协议实现
Zab 协议有两种模式:恢复模式和广播模式
恢复模式用于选举新的 Leader,广播模式用于同步数据
03.常用API
create:创建节点
delete:删除节点
exists:检查节点是否存在
getData:获取节点数据
setData:设置节点数据
getChildren:获取子节点列表
addWatch:添加节点监听
04.使用步骤
安装和启动Zookeeper:下载并配置Zookeeper,启动Zookeeper服务
连接Zookeeper:使用客户端连接到Zookeeper服务器
节点操作:创建、删除、检查、获取和设置节点数据
监听机制:添加节点监听,处理节点变化
05.使用场景代码示例
a.数据发布/订阅
a.发布者
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, null);
zk.create("/config", "configData".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
b.订阅者
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
byte[] data = zk.getData("/config", false, null);
System.out.println("Config updated: " + new String(data));
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
zk.getData("/config", true, null);
b.负载均衡
a.服务注册
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, null);
zk.create("/services/service1", "server1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
b.服务发现
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, null);
List<String> servers = zk.getChildren("/services", false);
for (String server : servers) {
byte[] data = zk.getData("/services/" + server, false, null);
System.out.println("Found server: " + new String(data));
}
3.5 [3]dubbo、dubbox
01.Dubbo、Dubbox
a.区别
Dubbox是当当网基于Dubbo扩展的项目,增加了Restful调用等功能,更新了部分开源组件
b.说明
Dubbox是在Dubbo停止维护后的一种延续和扩展
3.6 [3]dubbo、zookeeper
01.定义
Zookeeper是一个分布式协调服务,主要用于分布式应用中的数据管理,如配置管理、命名服务、分布式同步和集群管理等
Dubbo则是一个高性能的RPC框架,用于服务治理和远程方法调用
Zookeeper在Dubbo中主要用作服务注册中心,负责服务的注册与发现
02.具体关系如下
a.服务注册
a.服务提供者(Provider)
在启动时,将自己提供的服务注册到Zookeeper中。Zookeeper会记录服务提供者的地址和服务信息
b.服务消费者(Consumer)
在启动时,向Zookeeper订阅自己所需的服务。Zookeeper会返回服务提供者的地址列表给消费者
b.服务发现
a.动态发现
服务消费者通过Zookeeper动态发现服务提供者的地址列表
Zookeeper会基于长连接推送变更数据给消费者,当服务提供者的地址发生变化时,消费者能够及时感知到
c.负载均衡
a.地址列表
服务消费者从Zookeeper获取服务提供者的地址列表后,基于软负载均衡算法选择合适的服务提供者进行调用
d.高可用性
a.故障转移
当某个服务提供者不可用时,Zookeeper会及时更新服务提供者的地址列表
消费者可以选择其他可用的服务提供者进行调用,保证服务的高可用性
03.Zookeeper在Dubbo中的配置示例
a.配置文件示例(XML配置)
a.服务提供者(Provider)配置
<dubbo:application name="provider-app"/>
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:protocol name="dubbo" port="20880"/>
<dubbo:service interface="com.example.HelloService" ref="helloService"/>
b.服务消费者(Consumer)配置
<dubbo:application name="consumer-app"/>
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference id="helloService" interface="com.example.HelloService"/>
b.配置文件示例(Java配置)
a.服务提供者(Provider)配置
@Configuration
public class ProviderConfig {
@Bean
public ApplicationConfig applicationConfig() {
ApplicationConfig applicationConfig = new ApplicationConfig();
applicationConfig.setName("provider-app");
return applicationConfig;
}
@Bean
public RegistryConfig registryConfig() {
RegistryConfig registryConfig = new RegistryConfig();
registryConfig.setAddress("zookeeper://127.0.0.1:2181");
return registryConfig;
}
@Bean
public ProtocolConfig protocolConfig() {
ProtocolConfig protocolConfig = new ProtocolConfig();
protocolConfig.setName("dubbo");
protocolConfig.setPort(20880);
return protocolConfig;
}
@Bean
public ServiceConfig<HelloService> helloServiceConfig(HelloService helloService) {
ServiceConfig<HelloService> serviceConfig = new ServiceConfig<>();
serviceConfig.setInterface(HelloService.class);
serviceConfig.setRef(helloService);
return serviceConfig;
}
}
b.服务消费者(Consumer)配置
@Configuration
public class ConsumerConfig {
@Bean
public ApplicationConfig applicationConfig() {
ApplicationConfig applicationConfig = new ApplicationConfig();
applicationConfig.setName("consumer-app");
return applicationConfig;
}
@Bean
public RegistryConfig registryConfig() {
RegistryConfig registryConfig = new RegistryConfig();
registryConfig.setAddress("zookeeper://127.0.0.1:2181");
return registryConfig;
}
@Bean
public ReferenceConfig<HelloService> helloServiceConfig() {
ReferenceConfig<HelloService> referenceConfig = new ReferenceConfig<>();
referenceConfig.setInterface(HelloService.class);
return referenceConfig;
}
}
3.7 [3]dubbo、springcloud
01.Dubbo、SpringCloud
a.关系
Dubbo和Spring Cloud都是用于微服务架构的框架,但Dubbo主要关注服务调用和治理,而Spring Cloud则提供了更全面的微服务治理方案
b.区别
通信协议:Dubbo基于TCP协议,使用Netty进行NIO通信;Spring Cloud基于HTTP协议,使用REST接口
依赖关系:Dubbo的服务提供方和消费方存在代码级别的依赖;Spring Cloud通过契约进行服务调用,依赖较为松散
适用场景:Dubbo适用于需要高性能RPC通信的场景;Spring Cloud适用于需要快速演化和灵活性的微服务环境
3.8 [4]feign、openfeign
00.汇总
a.集成组件
Feign 是一个独立的 HTTP 客户端库
OpenFeign 是 Spring Cloud 对 Feign 的增强,集成了 Ribbon 和 Hystrix,提供了负载均衡和熔断功能
b.注解支持
Feign 通过 @FeignClient 注解声明客户端接口
OpenFeign 也通过 @FeignClient 注解声明客户端接口,但支持更多的 Spring Cloud 特性,如负载均衡和熔断
c.功能扩展
Feign 主要用于简化 HTTP 客户端的编写
OpenFeign 在 Feign 的基础上,提供了更强大的功能,如负载均衡、熔断和监控
01.Feign
a.定义
Feign 是一个声明式的 HTTP 客户端,它使得编写 HTTP 客户端变得更加简单
通过使用 Feign,只需要创建一个接口并在接口上添加注解,即可完成对 HTTP API 的调用
b.原理
Feign 通过注解的方式,将 HTTP 请求映射到接口的方法上,并通过动态代理生成接口的实现类,最终发起 HTTP 请求
c.常用API
@FeignClient:声明一个 Feign 客户端
@RequestMapping、@GetMapping、@PostMapping 等:映射 HTTP 请求
d.使用步骤
引入依赖
配置 Feign 客户端
创建 Feign 接口并添加注解
在服务中使用 Feign 客户端
e.代码示例
a.引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
b.配置 Feign 客户端
@SpringBootApplication
@EnableFeignClients
public class FeignApplication {
public static void main(String[] args) {
SpringApplication.run(FeignApplication.class, args);
}
}
c.创建 Feign 接口并添加注解
@FeignClient(name = "hello-service", url = "http://localhost:8080")
public interface HelloClient {
@GetMapping("/hello")
String sayHello();
}
d.在服务中使用 Feign 客户端
@RestController
public class HelloController {
@Autowired
private HelloClient helloClient;
@GetMapping("/sayHello")
public String sayHello() {
return helloClient.sayHello();
}
}
02.OpenFeign
a.定义
OpenFeign 是 Spring Cloud 对 Feign 的增强,它集成了 Ribbon 和 Hystrix,提供了负载均衡和熔断功能
OpenFeign 使得在 Spring Cloud 项目中使用 Feign 更加方便
b.原理
OpenFeign 在 Feign 的基础上,集成了 Spring Cloud 的组件
如 Ribbon 和 Hystrix,通过注解的方式,提供了负载均衡和熔断功能
c.常用API
@FeignClient:声明一个 Feign 客户端
@RequestMapping、@GetMapping、@PostMapping 等:映射 HTTP 请求
@HystrixCommand:配置熔断器
d.使用步骤
引入依赖
配置 OpenFeign 客户端
创建 Feign 接口并添加注解
在服务中使用 Feign 客户端
e.代码示例
a.引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
b.配置 OpenFeign 客户端
@SpringBootApplication
@EnableFeignClients
@EnableCircuitBreaker
public class OpenFeignApplication {
public static void main(String[] args) {
SpringApplication.run(OpenFeignApplication.class, args);
}
}
c.创建 Feign 接口并添加注解
@FeignClient(name = "hello-service", url = "http://localhost:8080", fallback = HelloClientFallback.class)
public interface HelloClient {
@GetMapping("/hello")
String sayHello();
}
@Component
class HelloClientFallback implements HelloClient {
@Override
public String sayHello() {
return "Fallback Hello";
}
}
d.在服务中使用 Feign 客户端
@RestController
public class HelloController {
@Autowired
private HelloClient helloClient;
@GetMapping("/sayHello")
public String sayHello() {
return helloClient.sayHello();
}
}
3.9 [4]eureka、zookeeper
00.汇总
a.设计目标
Eureka:主要用于微服务架构中的服务注册与发现,设计目标是高可用和最终一致性
Zookeeper:主要用于分布式系统中的数据管理和协调,设计目标是强一致性
b.一致性模型
Eureka:采用 AP(Availability and Partition tolerance)模型,保证高可用性和分区容错性,允许数据不一致
Zookeeper:采用 CP(Consistency and Partition tolerance)模型,保证强一致性和分区容错性,可能会牺牲可用性
c.使用场景
Eureka:适用于微服务架构中的服务注册与发现,特别是在需要高可用性和容错性的场景下
Zookeeper:适用于分布式系统中的数据管理和协调,如配置管理、命名服务、分布式锁和集群管理等
d.实现机制
Eureka:通过心跳机制和租约机制来维护服务的注册信息,服务提供者定期发送心跳来续约
Zookeeper:通过原子广播机制和 Zab 协议来保证各个服务器之间的同步,使用 Leader 选举和数据同步机制
01.Eureka
a.定义
Eureka 是 Netflix 开源的一个服务注册和发现组件,主要用于微服务架构中的服务注册与发现
Eureka 分为 Eureka Server 和 Eureka Client,Eureka Server 作为服务注册中心,Eureka Client 作为服务提供者和消费者
b.原理
Eureka 通过心跳机制和租约机制来维护服务的注册信息
服务提供者在启动时向 Eureka Server 注册自己的服务,并定期发送心跳来续约
服务消费者从 Eureka Server 获取服务提供者的地址列表,并通过负载均衡算法选择合适的服务提供者进行调用
c.常用API
@EnableEurekaServer:启用 Eureka Server
@EnableEurekaClient:启用 Eureka Client
EurekaClient:获取服务实例信息
d.使用步骤
引入依赖
配置 Eureka Server
配置 Eureka Client
在服务中使用 Eureka Client 获取服务实例信息
e.代码示例
a.引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
b.配置 Eureka Server
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
c.配置 Eureka Client
@SpringBootApplication
@EnableEurekaClient
public class EurekaClientApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaClientApplication.class, args);
}
}
d.在服务中使用 Eureka Client 获取服务实例信息
@RestController
public class ServiceController {
@Autowired
private EurekaClient eurekaClient;
@GetMapping("/service-instances/{applicationName}")
public List<ServiceInstance> serviceInstancesByApplicationName(
@PathVariable String applicationName) {
return eurekaClient.getInstancesByVipAddress(applicationName, false);
}
}
02.Zookeeper
a.定义
Zookeeper 是一个开源的分布式协调服务,主要用于分布式应用中的数据管理
如配置管理、命名服务、分布式同步和集群管理等,Zookeeper 在分布式系统中提供一致性服务
支持数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能
b.原理
Zookeeper 通过原子广播机制保证各个服务器之间的同步,使用 Zab 协议实现
Zab 协议有两种模式:恢复模式和广播模式。恢复模式用于选举新的 Leader,广播模式用于同步数据
c.常用API
create:创建节点
delete:删除节点
exists:检查节点是否存在
getData:获取节点数据
setData:设置节点数据
getChildren:获取子节点列表
addWatch:添加节点监听
d.使用步骤
安装和启动 Zookeeper
连接 Zookeeper
节点操作:创建、删除、检查、获取和设置节点数据
监听机制:添加节点监听,处理节点变化
e.代码示例
a.连接 Zookeeper
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("Event received: " + event);
}
});
b.节点操作
// 创建节点
zk.create("/my-node", "my-data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 获取节点数据
byte[] data = zk.getData("/my-node", false, null);
System.out.println("Data: " + new String(data));
// 设置节点数据
zk.setData("/my-node", "new-data".getBytes(), -1);
// 删除节点
zk.delete("/my-node", -1);
c.监听机制
zk.exists("/my-node", new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
byte[] data = zk.getData("/my-node", false, null);
System.out.println("Node data changed: " + new String(data));
} catch (Exception e) {
e.printStackTrace();
}
}
}
});