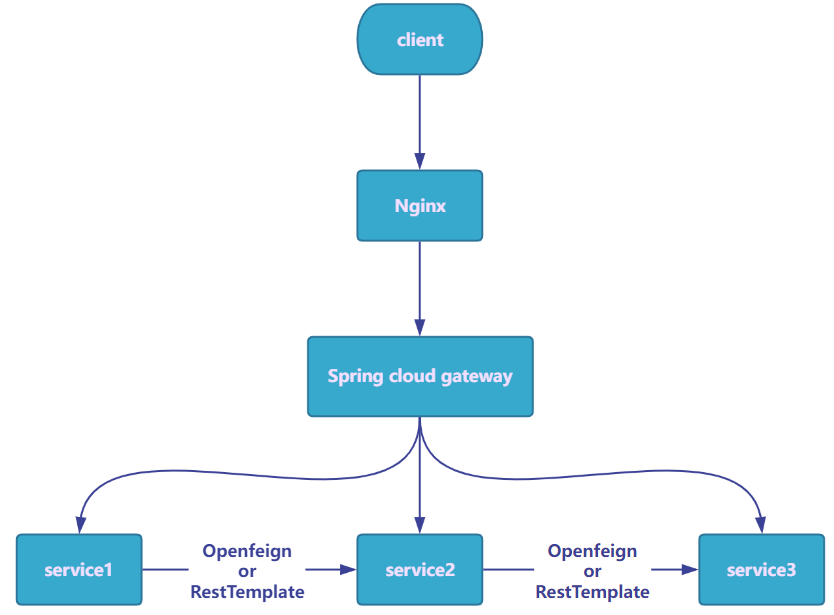
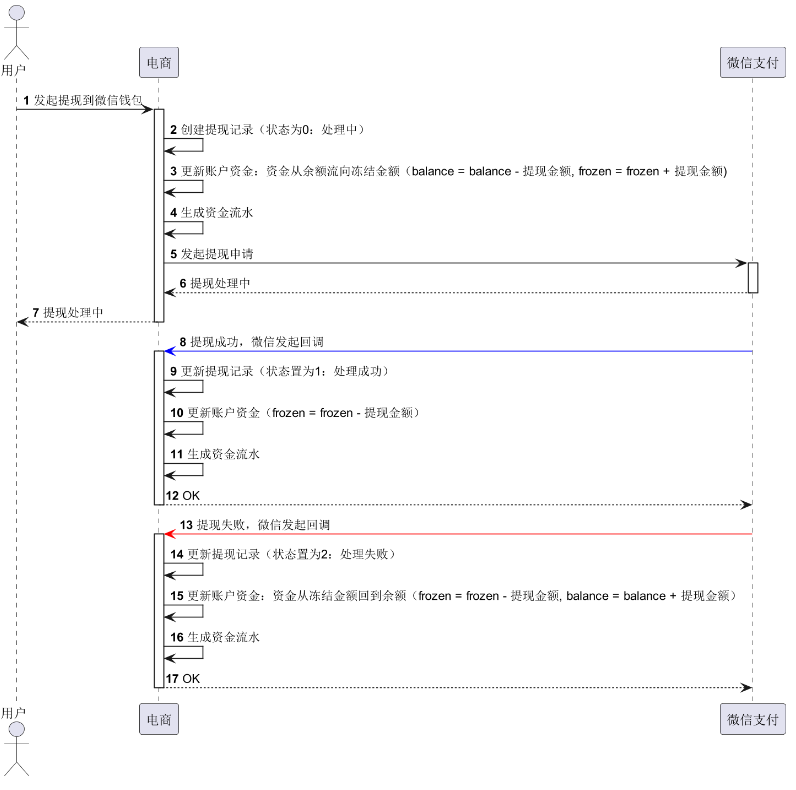
01.分类1
01.分片上传实战
02.通用并发处理工具类实战
03.实现一个好用接口性能压测工具类
04.超卖问题的4种解决方案,也是防止并发修改数据出错的通用方案
05.Semaphore实现接口限流实战
06.并行查询,优化接口响应速度实战
07.接口性能优化之大事务优化
08.通用的Excel动态导出功能实战
09.手写线程池管理器,管理&监控所有线程池
10.动态线程池
02.分类2
11.使用SpringBoot实现动态Job实战
12.幂等的4种解决方案,吃透幂等性问题
13.并行查询,性能优化利器,可能有坑
14.接口通用返回值设计与实现
15.接口太多,各种dto、vo不计其数,如何命名?
16.一个业务太复杂了,方法太多,如何传参?
17.接口报错,如何快速定位日志?
18.线程数据共享必学的3个工具类:ThreadLocal、InheritableThreadLocal、TransmittableThreadLocal
19.通过AOP统一打印请求链路日志,排错效率飞升
20.大批量任务处理常见的方案(模拟余额宝发放收益)
03.分类3
21.并发环境下,如何验证代码是否正常?
22.MySql和Redis数据一致性
23.数据脱敏优雅设计与实现
24.一行代码搞定系统操作日志
25.AOP实现MyBatis分页功能
26.ThreadLocal线程池的坑
27.读写分离实战
28.MQ使用场景
29.MQ确保消息的可靠性
30.MQ落地事务消息
04.分类4
41.一个注解轻松搞定分布式锁
42.微服务中如何传递公共参数
43.接口幂等的通用方案
44.微服务链路日志追踪
45.接口测试利器HTTPClient
46.MyBatis实现通用CRUD框架
47.MyBatisPlus实现多租户数据隔离
48.电商系统的资金账户表设计及实战
49.UML画图神器:PlantUML
50.多线程事务,3秒插入百万数据
05.分类5
51.SpringBoot自动初始化数据库
52.SpringBoot优雅停机
53.一个特好用的集合工具类
54.性能调优:线程死锁相关问题
55.如何排查OOM
56.cpu飙升,快速排查
57.cpu升,使用Arthas,3秒定位问题
58.接口响应慢,使用Arthas,3秒定位问题代码
59.策略模式,轻松消除ifelse
60.生产上,代码未生效,如何排查?
06.分类6
61.使用MySQL,实现一个高性能,分布式id生成器
62.方法执行异常,使用arthas,快速定位问题
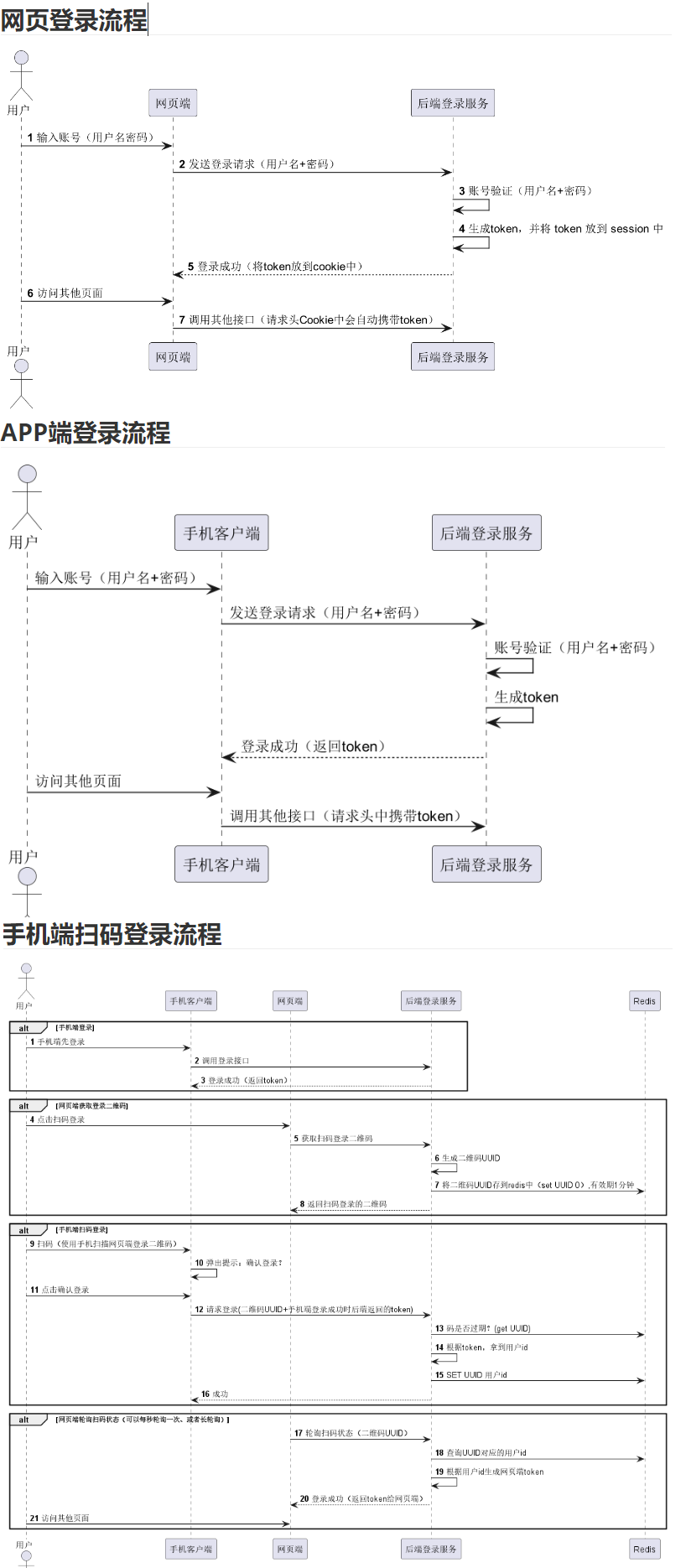
63.扫码登录
64.使用hutool生成解析二维码
65.SpringBoot中,Redis如何实现排行榜
66.SpringBoot中,Redis如何实现查找附近的人功能
67.SpringBoot中,接口签名,通用方案,一次性搞懂
68.SpringBoot中,接口加解密,通用方案实战
69.分库、分表、分库分表,如何选择?
70.分库分表:分表字段如何选择?
07.分类7
70.分库分表:分表字段如何选择?
71.分库分表:分表数量为什么建议是2的n次方?
72.分库分表:如何平滑迁移数据?
73.并发编程有多难?值得反复研究的一个案例
74.使用Redis Pipeline,接口性能提升10倍
75.电商中,重复支付如何解决?
76.千万级数据,全表update的正确姿势
77.优雅实现树形菜单,适用于所有树,太好用了
78.接口调用利器:RestTemplate,吃透它
79.微服务跨库查询,如何解决?一次性搞懂
80.逻辑删除与唯一约束冲突,如何解决?
08.分类8
80.逻辑删除与唯一约束冲突,如何解决?
81.评论系统如何设计,一次性给你讲清楚
82.SpringBoot下载文件的几种方式,一次性搞懂
83.订单超时自动取消,最常见的方案
84.责任链模式优化代码,太好用了
85.CompletableFuture 实现异步任务编排,太好用了
86.idea中的必备debug技巧,高手必备
87.Java动态生成word,太强大了
88.海量据量统计,如何提升性能?
89.MyBatis模糊查询,千万不要再用${}了,容易搞出大事故
90.Spring事务失效,常见的几种场景,带你精通Spring事务
91. idea多线程调试,这个技巧也太棒了吧,你会么?
92. MySQL排序分页,可能有坑,需要注意
93. 涉及到钱的,千万不要用double,请用BigDecimal
09.分类9
90.Spring事务失效,常见的几种场景,带你精通Spring事务
91.idea多线程调试,这个技巧也太棒了吧,你会么?
92.MySQL排序分页,可能有坑,需要注意
93.涉及到钱的,千万不要用double,请用BigDecimal
94.MyBatis动态SQL不要乱用
95.MySQL数据如何同步到ES?靠谱方案
96.订单状态流转代码优化,确实优雅
97.线上问题排查思路
98.经典并发案例分析,确实有点难,一起来挑战下
99.如何优雅的处理线程池内异常?
1 part00
1.1 分片上传
01.普通上传
a.定义
调用接口一次性完成一个文件的上传
b.2个缺点
1.文件无法续传,比如上传了一个比较大的文件,中间突然断掉了,需要重来
2.大文件上传太慢
c.解决方案
分片上传
02.分片上传
a.定义
将源文件切分成很多分片,进行上传,待所有分片上传完毕之后,将所有分片合并,便可得到源文件
这里面的分片可以采用并行的方式上传,提示大文件上传的效率
b.过程
1.创建分片上传任务(分片数量、每个分片文件大小、文件md5值)
2.上传所有分片
3.待所有分片上传完成后,合并文件,便可得到源文件
c.需要用到2张表
a.分片上传任务表(t_shard_upload)
每个分片任务会在此表创建一条记录
-------------------------------------------------------------------------------------------------
create table if not exists t_shard_upload(
id varchar(32) primary key,
file_name varchar(256) not null comment '文件名称',
part_num int not null comment '分片数量',
md5 varchar(128) comment '文件md5值',
file_full_path varchar(512) comment '文件完整路径'
) comment = '分片上传任务表';
b.分片文件表(t_shard_upload_part)
这个表和上面的表是1对多的关系,用与记录每个分片的信息,比如一个文件被切分成10个分片,那么此表会产生10条记录
-------------------------------------------------------------------------------------------------
create table if not exists t_shard_upload_part(
id varchar(32) primary key,
shard_upload_id varchar(32) not null comment '分片任务id(t_shard_upload.id)',
part_order int not null comment '第几个分片,从1开始',
file_full_path varchar(512) comment '文件完整路径',
UNIQUE KEY `uq_part_order` (`shard_upload_id`,`part_order`)
) comment = '分片文件表,每个分片文件对应一条记录';
d.服务端需提供4个接口
a.创建分片上传任务
/shardUpload/init
返回分片任务id(shardUploadId),后续的3个接口均需要用到该id
b.上传分片文件
/shardUpload/uploadPart
c.合并分片、完成上传
/shardUpload/complete
d.获取分片任务详细信息
/shardUpload/detail
可以得到分片任务的状态信息,如分片任务是否上传完毕,哪些分片已上传等信息,网络出现故障,可以借助此接口恢复上传
e.上传途中出现故障如何恢复?
a.说明
比如出现网络故障,导致分片上失败,此时需要走恢复逻辑,分两种情况
b.情况1:浏览器无法读取刚才用户选择的文件了
此时需要用户重新选择文件,重新上传
这个地方也可以给大家提供另外一种思路,第1个接口创建分片任务的时候传入了文件的md5
按说这个值是具有唯一性的,那么就可以通过这个值找到刚才的任务
按照这种思路,就需要后端提供一个新的接口:
通过文件的md5值找到刚才失败的那个任务,然后继续上传未上传的分片
c.情况2:浏览器可以继续读取刚才用户选择的文件
可以先调用第4个接口,通过此接口可以知道那些分片还未上传,然后继续上传这些分片就可以了
1.2 多线程批处理工具类
01.需求
使用线程池批量发送短信,当短信发送完毕之后,方法继续向下走
02.技术点
线程池:ExecutorService
CountDownLatch:可以让一个或者多个线程等待一批任务执行完毕之后,继续向下走
03.代码实现
a.新手版
com.itsoku.SimpleBatchTask
b.高手版
com.itsoku.TaskDisposeUtils
-----------------------------------------------------------------------------------------------------
重点在于下面2行代码,简化了很多
ExecutorService executorService = Executors.newFixedThreadPool(10);
//调用工具类批处理任务
TaskDisposeUtils.dispose(taskList, TaskDisposeUtils::disposeTask, executorService);
1.3 接口性能压测工具类
01.常用的好用的压测工具
1.Apache服务器安装目录的ab.exe
2.Jmeter
3.LoadRunner
02.为什么要自己实现一个压测工具?
高并发有很多知识点
工具类,如:线程池、JUC四个常用工具类【CountDownLatch、CyclicBarrier、Semaphore、ExChange】等
03.涉及的知识点
1.线程池(ThreadPoolExecutor)
2.CountDownLatch
3.AtomicInteger
04.要实现的功能:写一个通用的压测工具类
a.类名
LoadRunnerUtils
b.类中定义一个通用的压测方法
方法定义如下,提供3个参数,可以对第3个参数需要执行的业务进行压测,最终将压测的结果返回。
-----------------------------------------------------------------------------------------------------
/**
* 对 command 执行压测
*
* @param requests 总请求数
* @param concurrency 并发数量
* @param command 需要执行的压测代码
* @param <T>
* @return 压测结果 {@link LoadRunnerResult}
* @throws InterruptedException
*/
public static <T> LoadRunnerResult run(int requests, int concurrency, Runnable command)
c.方法返回压测结果(LoadRunnerResult)
LoadRunnerResult 包含了压测结果,定义如下,主要有下面这些指标
-----------------------------------------------------------------------------------------------------
public static class LoadRunnerResult {
// 请求总数
private int requests;
// 并发量
private int concurrency;
// 成功请求数
private int successRequests;
// 失败请求数
private int failRequests;
// 请求总耗时(ms)
private int timeTakenForTests;
// 每秒请求数(吞吐量)
private float requestsPerSecond;
// 每个请求平均耗时(ms)
private float timePerRequest;
// 最快的请求耗时(ms)
private float fastestCostTime;
// 最慢的请求耗时(ms)
private float slowestCostTime;
}
05.2个测试案例
a.案例1:总请求1000个,并发100,压测一个简单的接口
a.接口代码如下:test1接口,很简单,没有任何逻辑,这个接口效率很高
@GetMapping("/test1")
public String test1() {
log.info("test1");
return "ok";
}
b.对应的压测用例代码
@Test
public void test1() throws InterruptedException {
//需要压测的接口地址,这里我们压测test1接口
//压测参数,总请求数量1000,并发100
int requests = 1000;
int concurrency = 100;
String url = "http://localhost:8080/test1";
System.out.println(String.format("压测接口:%s", url));
RestTemplate restTemplate = new RestTemplate();
//调用压测工具类开始压测
LoadRunnerUtils.LoadRunnerResult loadRunnerResult = LoadRunnerUtils.run(requests, concurrency, () -> {
restTemplate.getForObject(url, String.class);
});
//输出压测结果
print(loadRunnerResult);
}
c.运行test1用例,效果如下
压测接口:http://localhost:8080/test1
11:47:56 - 压测开始......
11:47:57 - 压测结束,总耗时(ms):601
-------------------------------------------------------------------------------------------------
压测结果如下:
请求总数: 1000
并发量: 100
成功请求数: 1000
失败请求数: 0
请求总耗时(ms): 601
每秒请求数(吞吐量): 1663.8936
每个请求平均耗时(ms): 0.601
最快的请求耗时(ms): 0.0
最慢的请求耗时(ms): 565.0
b.案例2:总请求1000个,并发100,压测一个耗时的接口
a.接口代码如下,test2接口,内部休眠了100毫秒,用于模拟业务耗时操作
@GetMapping("/test2")
public String test2() throws InterruptedException {
//接口中休眠100毫秒,用来模拟业务操作
TimeUnit.MILLISECONDS.sleep(100);
return "ok";
}
b.对应的压测用例代码
@Test
public void test2() throws InterruptedException {
//需要压测的接口地址,这里我们压测test2接口
//压测参数,总请求数量10000,并发100
int requests = 1000;
int concurrency = 100;
String url = "http://localhost:8080/test2";
System.out.println(String.format("压测接口:%s", url));
RestTemplate restTemplate = new RestTemplate();
//调用压测工具类开始压测
LoadRunnerUtils.LoadRunnerResult loadRunnerResult = LoadRunnerUtils.run(requests, concurrency, () -> {
restTemplate.getForObject(url, String.class);
});
//输出压测结果
print(loadRunnerResult);
}
c.运行test2用例,效果如下
压测接口:http://localhost:8080/test2
11:48:20 - 压测开始......
11:48:22 - 压测结束,总耗时(ms):1231
-------------------------------------------------------------------------------------------------
压测结果如下:
请求总数: 1000
并发量: 100
成功请求数: 1000
失败请求数: 0
请求总耗时(ms): 1231
每秒请求数(吞吐量): 812.34766
每个请求平均耗时(ms): 1.231
最快的请求耗时(ms): 100.0
最慢的请求耗时(ms): 281.0
1.4 商品超卖的4个方案
00.汇总
方案1:通过update中携带条件判断解决超卖问题 方案1,最靠谱
方案2:使用乐观锁版本号解决这个问题
方案3:对比数据修改前后是否和期望的一致
方案4:通过辅助类解决超卖问题
00.加锁排队
a.说明
本质上是需要加锁,不管是什么锁,只要让减库存的操作排队,便可解决超卖问题,核心点就是:加锁排队
同理:解决并发修改数据出错问题,最终也是靠锁解决
比如乐观锁、悲观锁,本质上都是要靠锁,让并发问题排队执行,只是这个锁的范围大小的问题
b.商品表
-- 商品表
create table if not exists t_goods
(
goods_id varchar(32) primary key comment '商品id',
goods_name varchar(256) not null comment '商品名称',
num int not null comment '库存',
version bigint default 0 comment '系统版本号'
) comment = '商品表';
01.方案1:通过update中携带条件判断解决超卖问题
a.原理
通过下面sql的执行结果,便可确保超卖问题,重点在于需要在update的where条件中加上库存扣减后不能为0
sql会返回影响行数,如果影响行数为0,表示库存不满足要求,扣减失败了,否则,扣减库存成功
b.代码
String goodsId = "商品id";
int num = "本次需要扣减的库存量";
// count表示影响行数
int count = (update t_goods set num = num - #{num} where goods_id = #{goodsId} and num - #{num} >= 0);
// count = 1,表示扣减成功,否则扣减失败
if(count==1){
//扣减库存成功
}else{
//扣减库存失败
}
c.源码
com.itsoku.lesson004.service.GoodsServiceImpl#placeOrder1
d.运行看结果
===========================解决超卖,方案1 开始执行=======================================
模拟 100 人进行抢购
抢购结束啦............
抢购前,商品库存:10
抢购后,商品库存:0
下单成功人数:10
下单失败人数:90
===========================解决超卖,方案1 执行结束=======================================
02.方案2:使用乐观锁版本号解决这个问题
a.原理
需要在库存表加一个version字段,这个version每次更新的时候需要+1,单调递增的
b.代码
String goodsId = "商品id";
int num = "本次需要扣减的库存量";
GoodsPo goods = (select * from t_goods where goods_id = #{goodsId});
// 期望数据库中该数据的version值
int expectVersion = goods.getVerion();
//乐观锁更新数据,where条件中必须带 version = #{expectVersion}
int count = update t_goods set num = num - ${num}, version = version + 1 where goods_id = #{goodsId} and version = #{expectVersion}
// count = 1,表示扣减成功,否则扣减失败
if(count==1){
//扣减库存成功
}else{
//扣减库存失败
}
c.源码
com.itsoku.lesson004.service.GoodsServiceImpl#placeOrder2
d.运行结果
===========================解决超卖,方案2 开始执行=======================================
模拟 100 人进行抢购
抢购结束啦............
抢购前,商品库存:10
抢购后,商品库存:0
下单成功人数:10
下单失败人数:90
===========================解决超卖,方案2 执行结束=======================================
03.方案3:对比数据修改前后是否和期望的一致
a.原理
这种方案虽然看起来很奇怪,但是有些业务场景中,可以解决一些问题
比如批量去修改数据,想判断批量的过程中,数据是否被修改过,可以通过这种方式判断
b.代码
String goodsId = "商品id";
int num = "本次需要扣减的库存量";
//扣减库存前,查出商品库存数量,丢到变量 beforeGoodsNum 中
GoodsPo beforeGoods = (select * from t_goods where goods_id = #{goodsId});
int beforeGoodsNum = beforeGoods.num;
// 执行扣减库存操作,条件中就只有goodsId,说明这个可能将库存扣成负数,出现超卖,继续向下看,后面的步骤将解决超卖
update t_goods set num = num - ${购买的商品数量} where goods_id = #{goodsId}
//扣减库存后,查出商品库存数量,丢到变量 afterGoodsNum 中
GoodsPo afterGoods = (select * from t_goods where goods_id = #{goodsId});
int afterGoodsNum = afterGoods.num;
// 如下判断,库存扣减前后和期望的结果是不是一致的,扣减前的数据 - 本次需要扣减的库存量 == 扣减后的数量,如果是,说明没有超卖
if(beforeGoodsNum - num == afterGoodsNum){
//扣减库存成功
}else{
//扣减库存失败
}
c.源码
com.itsoku.lesson004.service.GoodsServiceImpl#placeOrder3
d.运行结果
===========================解决超卖,方案3 开始执行=======================================
模拟 100 人进行抢购
抢购结束啦............
抢购前,商品库存:10
抢购后,商品库存:0
下单成功人数:10
下单失败人数:90
===========================解决超卖,方案3 执行结束=======================================
04.方案4:通过辅助类解决超卖问题
a.原理
需要添加一张辅助表(t_concurrency_safe)
如下,这张表需要有版本号字段,通过这张表的乐观锁,**将需要保护的业务方法包起来**,解决超卖问题
-----------------------------------------------------------------------------------------------------
create table if not exists t_concurrency_safe
(
id varchar(32) primary key comment 'id',
safe_key varchar(256) not null comment '需要保护的数据的唯一的key',
version bigint default 0 comment '系统版本号,默认为0,每次更新+1',
UNIQUE KEY `uq_safe_key` (`safe_key`)
) comment = '并发安全辅助表';
b.代码
String goodsId = "商品id";
int num = "本次需要扣减的库存量";
// 需要给保护的数据生成一个唯一的:safeKey
String safeKey = "GoodsPO:"+商品id;
// 如下:根据 safe_key 去 t_concurrency_safe 表找这条需要保护的数据
ConcurrencySafePO po = (select * from t_concurrency_safe where safe_key = #{safe_key});
// 这条数据不存在,则创建,然后写到 t_concurrency_safe 表
if(po==null){
po = new ConcurrencySafePO(#{safe_key});
// 向 t_concurrency_safe 表写入一条数据
insert into t_concurrency_safe (safe_key) values (#{safeKey});
}
// 下面执行扣减库存的操作,注意,如果用方案4,那么需要保护的数据的修改,均需要放在这个位置来保护,这块大家细品下
{
//扣减库存前,查出商品库存
GoodsPo beforeGoods = (select * from t_goods where goods_id = #{goodsId});
//判断库存是否足够
if(beforeGoods.num == 0){
//库存不足,秒杀失败
return;
}
// 执行扣减库存操作,条件中就只有goodsId,说明这个可能将库存扣成负数,出现超卖,继续向下看,后面的步骤将解决超卖
update t_goods set num = num - ${购买的商品数量} where goods_id = #{goodsId}
}
//对 ConcurrencySafePO 执行乐观锁更新
int update = update t_concurrency_safe set version = version + 1 where id = #{po.id} and version = #{po.version}
// 若update==1,说明被保护的数据,期间没有发生变化
if(update == 1){
//秒杀成功
}else{
//说明被保护的数据,期间发生变化了,下面要抛出异常,让事务回滚
throw new ConcurrencyFailException("系统繁忙,请重试");
}
c.源码
com.itsoku.lesson004.service.GoodsServiceImpl#placeOrder4
d.运行结果
===========================解决超卖,方案4 开始执行=======================================
模拟 100 人进行抢购
抢购结束啦............
抢购前,商品库存:10
抢购后,商品库存:0
下单成功人数:10
下单失败人数:90
===========================解决超卖,方案4 执行结束=======================================
1.5 Semaphore实现接口限流
00.汇总
工具类:LoadRunnerUtils
测试类:CurrentLimitTest
控制层:TestController
01.工具类:LoadRunnerUtils
@Slf4j
public class LoadRunnerUtils {
@Data
public static class LoadRunnerResult {
// 请求总数
private int requests;
// 并发量
private int concurrency;
// 成功请求数
private int successRequests;
// 失败请求数
private int failRequests;
// 请求总耗时(ms)
private int timeTakenForTests;
// 每秒请求数(吞吐量)
private float requestsPerSecond;
// 每个请求平均耗时(ms)
private float timePerRequest;
// 最快的请求耗时(ms)
private float fastestCostTime;
// 最慢的请求耗时(ms)
private float slowestCostTime;
}
/**
* 对 command 执行压测
*
* @param requests 总请求数
* @param concurrency 并发数量
* @param command 需要执行的压测代码
* @param <T>
* @return 压测结果 {@link LoadRunnerResult}
* @throws InterruptedException
*/
public static <T> LoadRunnerResult run(int requests, int concurrency, Runnable command) throws InterruptedException {
log.info("压测开始......");
//创建线程池,并将所有核心线程池都准备好
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(concurrency, concurrency,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
poolExecutor.prestartAllCoreThreads();
// 创建一个 CountDownLatch,用于阻塞当前线程池待所有请求处理完毕后,让当前线程继续向下走
CountDownLatch countDownLatch = new CountDownLatch(requests);
//成功请求数、最快耗时、最慢耗时 (这几个值涉及到并发操作,所以采用 AtomicInteger 避免并发修改导致数据错误)
AtomicInteger successRequests = new AtomicInteger(0);
AtomicInteger fastestCostTime = new AtomicInteger(Integer.MAX_VALUE);
AtomicInteger slowestCostTime = new AtomicInteger(Integer.MIN_VALUE);
long startTime = System.currentTimeMillis();
//循环中使用线程池处理被压测的方法
for (int i = 0; i < requests; i++) {
poolExecutor.execute(() -> {
try {
long requestStartTime = System.currentTimeMillis();
//执行被压测的方法
command.run();
//command执行耗时
int costTime = (int) (System.currentTimeMillis() - requestStartTime);
//请求最快耗时
setFastestCostTime(fastestCostTime, costTime);
//请求最慢耗时
setSlowestCostTimeCostTime(slowestCostTime, costTime);
//成功请求数+1
successRequests.incrementAndGet();
} catch (Exception e) {
log.error(e.getMessage());
} finally {
countDownLatch.countDown();
}
});
}
//阻塞当前线程,等到压测结束后,该方法会被唤醒,线程继续向下走
countDownLatch.await();
//关闭线程池
poolExecutor.shutdown();
long endTime = System.currentTimeMillis();
log.info("压测结束,总耗时(ms):{}", (endTime - startTime));
//组装最后的结果返回
LoadRunnerResult result = new LoadRunnerResult();
result.setRequests(requests);
result.setConcurrency(concurrency);
result.setSuccessRequests(successRequests.get());
result.setFailRequests(requests - result.getSuccessRequests());
result.setTimeTakenForTests((int) (endTime - startTime));
result.setRequestsPerSecond((float) requests * 1000f / (float) (result.getTimeTakenForTests()));
result.setTimePerRequest((float) result.getTimeTakenForTests() / (float) requests);
result.setFastestCostTime(fastestCostTime.get());
result.setSlowestCostTime(slowestCostTime.get());
return result;
}
private static void setFastestCostTime(AtomicInteger fastestCostTime, int costTime) {
while (true) {
int fsCostTime = fastestCostTime.get();
if (fsCostTime < costTime) {
break;
}
if (fastestCostTime.compareAndSet(fsCostTime, costTime)) {
break;
}
}
}
private static void setSlowestCostTimeCostTime(AtomicInteger slowestCostTime, int costTime) {
while (true) {
int slCostTime = slowestCostTime.get();
if (slCostTime > costTime) {
break;
}
if (slowestCostTime.compareAndSet(slCostTime, costTime)) {
break;
}
}
}
}
02.控制层:TestController
/**
* 使用 Semaphore 实现限流功能
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/3/30 21:01 <br>
* <b>author</b>:ready [email protected]
*/
@RestController
public class TestController {
/**
* Juc中的Semaphore可以实现限流功能,可以将 Semaphore 想象成停车场入口的大爷,
* 大爷手里面拥有一定数量的停车卡(也可以说是令牌),卡的数量是多少呢?就是Semaphore构造方法中指定的,如下就是50个卡,
* 车主想进去停车,先要从大爷手中拿到一张卡,出来的时候,需要还给大爷,如果拿不到卡,就不能进去停车。
* <p>
* semaphore 内部提供了获取令牌,和还令牌的一些方法
*/
private Semaphore semaphore = new Semaphore(50);
/**
* 来个案例,下面是一个下单的方法,这个方法最多只允许 50 个并发,若超过50个并发,则进来的请求,最多等待1秒,如果无法获取到令牌,则快速返回失败,请重试
*
* @return
*/
@GetMapping("/placeOrder")
public String placeOrder() throws InterruptedException {
/**
* semaphore 在上面定义的,里面有50个令牌,也就是同时可以支持50个并发请求
* 下面的代码,尝试最多等待1秒去获取令牌,获取成功,则进入下单逻辑,获取失败,则返回系统繁忙,请稍后重试
*/
boolean flag = this.semaphore.tryAcquire(1, 1L, TimeUnit.SECONDS);
// 获取到令牌,则进入下单逻辑
if (flag) {
try {
//这里休眠2秒,模拟下单的操作
TimeUnit.SECONDS.sleep(2);
return "下单成功";
} finally {
//这里一定不要漏掉了,令牌用完了,要还回去
this.semaphore.release();
}
} else {
return "系统繁忙,请稍后重试";
}
}
}
03.测试类:CurrentLimitTest
/**
* 使用 Semaphore 实现限流功能
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/3/30 21:01 <br>
* <b>author</b>:ready [email protected]
*/
public class CurrentLimitTest {
public static void main(String[] args) throws InterruptedException {
// 记录成功量、失败量
AtomicInteger successNum = new AtomicInteger(0);
AtomicInteger failNum = new AtomicInteger(0);
//下面模拟200个人同时下单,运行,大家看结果
RestTemplate restTemplate = new RestTemplate();
Runnable requestPlaceOrder = () -> {
String result = restTemplate.getForObject("http://localhost:8080/placeOrder", String.class);
System.out.println(result);
if ("下单成功".equals(result)) {
successNum.incrementAndGet();
} else {
failNum.incrementAndGet();
}
};
//模拟100个人同时发送100个请求,待请求结束,看成功量、失败量
LoadRunnerUtils.LoadRunnerResult loadRunnerResult = LoadRunnerUtils.run(100, 100, requestPlaceOrder);
System.out.println(loadRunnerResult);
System.out.println("下单成功数:" + successNum.get());
System.out.println("下单失败数:" + failNum.get());
}
}
1.6 接口优化之并行查询
00.汇总
当接口中,需要执行多个步骤,而多个步骤没有依赖的时候
那么可以采用线程池并行去执行这些步骤,可以大大提升接口的性能
01.需求:后端提供一个接口获取商品信息
接口传入一个商品id,需要返回商品下面这些信息,这些信息都在不同的表中,通过商品id就可以查到
商品基本信息(如商品名称、价格等基本信息)
商品描述信息(可能是富文本,放在单独的表中)
商品收藏量
商品评论量
02.常规版本实现(性能低)
a.说明
按照id一步步查询,组装结果然后返回
b.代码
com.itsoku.lesson006.GoodsController#getGoodsDetail
c.请求
http://localhost:8080/getGoodsDetail?goodsId=1
d.耗时
获取商品信息,普通版耗时:402 ms
03.高性能版本实现(性能高)
a.说明
这里面的4个查询并没有任何依赖,这些没有依赖的查询其实是可以并行查询的
那么我们可以使用线程池同时去拿这4个结果,然后等4个结果都拿到后,组装好,返回,这样效率将大大提升
b.代码
# 使用线程池对4个方法并行查询
com.itsoku.lesson006.GoodsController#getGoodsDetailNew
c.请求
http://localhost:8080/getGoodsDetailNew?goodsId=1
d.耗时
获取商品信息,使用线程池并行查询耗时:106 ms
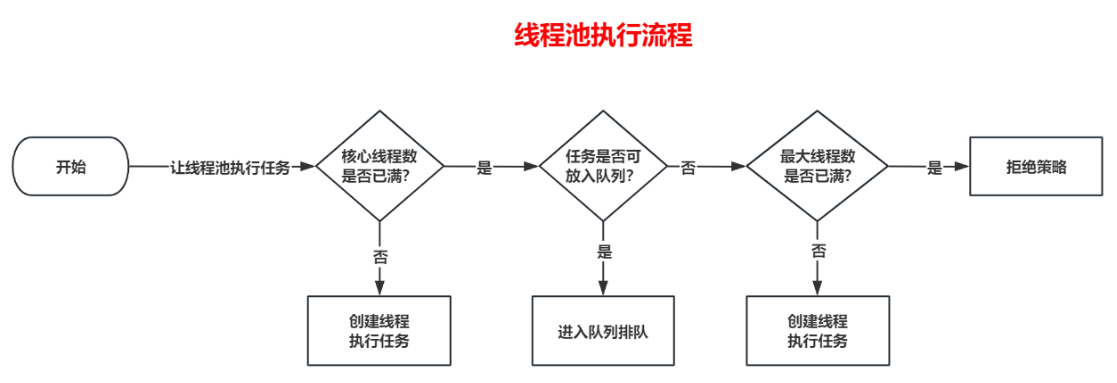
04.并行查询可能存在的问题?
a.说明
如果上面执行并行查询用到的线程池配置不当,可能导致比较严重的性能问题
b.说明
比如将核心线程数设置为了1,而队列大小没有限制,那么所有的请求都变成串行了,会导致请求响应非常慢,出现大事故
或者核心线程数设置的比较小,比如10,而队列大小没有设置上限,那么这个线程池同时只可支持10个任务并行
其他的请求进入这个接口后都变成串行执行了,进入队列排队,从而导致接口响应特别慢
c.怎么解决这个问题?
a.说明
解决这个问题本质是不要让任务排队或者排队时间不要太长
这个时候我们就要先说一下线程池的原理了,了解原理之后,就知道如何破解这个问题
b.了解了这个过程我们就有优化办法了,如下
1.可以将核心线程数、最大线程数调大,但是也不能随便调,比如调的很大,反而会降低系统性能,建议调的过程中根据业务的指标进行压测得到一个合理的值
2.将队列大小设置的比较小,这样排队的时间大概率会比较短,或者排队失败,直接后面的流程
LinkedBlockingQueue、ArrayBlockingQueue` 容量是不允许为0的,如果需要用到容量为0的队列,则需要使用同步阻塞队列`SynchronousQueue`
3.将队列大小设置为0,这样任务就不会进入队列,而直接创建新的线程去执行,或者走拒绝策略
4.拒绝策略可以使用`CallerRunsPolicy`,这个策略是直接在当前线程执行,即如果线程池执行不了,则自己去执行,这样至少不会一直等着
5.线程池隔离,不同的业务最好使用不同的线程池,互不影响,强烈建议核心业务一定要使用单独的线程池。
c.优化后的线程池配置
@Bean
public ThreadPoolTaskExecutor goodsThreadPool() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setThreadNamePrefix("ThreadPool-Goods-");
// 核心线程数为cpu核数 * 4,最大线程数据为cpu核数 * 8
threadPoolTaskExecutor.setCorePoolSize(Runtime.getRuntime().availableProcessors() * 4);
threadPoolTaskExecutor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 8);
// 队列容量为0,则任务就不会进入队列
threadPoolTaskExecutor.setQueueCapacity(0);
// 拒绝策略使用CallerRunsPolicy,让当前线程去兜底去执行任务
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return threadPoolTaskExecutor;
}
1.7 接口优化之大事务优化
00.汇总
1.系统性能要求很高,可以使用TransactionTemplate编程式事务,精准控制事务的粒度,尽量让事务小型化
2.尽量避免将没有事务的耗时操作放到事务代码中
3.避免在事务中执行远程操作,远程操作是不需要用到本地事务的,所以没有必要放在事务中
4.尽量让事务的操作集中在一起执行,比如都放到方法最后,使用TransactionTemplate执行,这样可使事务最小化
01.示例
a.代码
@Transactional
public void bigTransaction() throws InterruptedException {
// 1、getData()方法模拟一个比较耗时的获取数据的操作,这个方法内部会休眠5秒
String data = this.getData();
//2、将上面获取到的数据写入到db中
Lesson007PO po = new Lesson007PO();
po.setId(UUID.randomUUID().toString());
po.setData(data);
this.lesson007Mapper.insert(po);
}
public String getData() throws InterruptedException {
//休眠5秒
TimeUnit.SECONDS.sleep(5);
return UUID.randomUUID().toString();
}
b.说明
明眼人可能已经看出来了,方法上加了`@Transactional`注解,加了这个注解
说明这个方法会交给Spring来自动管理这个方法的事务,那么这个方法的逻辑就变成了下面这样
-----------------------------------------------------------------------------------------------------
1.Spring去数据库连接池拿到一个数据库连接
2.开启事务
3.执行bigTransaction()中的代码
4.提交事务
5.将数据库连接还给数据库连接池中
-----------------------------------------------------------------------------------------------------
这整个过程中,这个连接都会被占用,数据库连接都是有上限的,是非常稀缺的资源
如果所有人都把连接拿去使用很久而没有释放,那么当连接池里面的连接都被拿走了去使用
此时其他请求就没有数据库连接可以使用了,从而导致无法从连接池中获取有效的连接,会导致获取连接超时,而导致请求失败
02.优化1:小事务化
a.说明
将事务最小化,再来看看这段代码
如下,其实getData()方法中是用不到数据库操作的,这个方法里面并没有数据库操作,只有最后的insert才会用到数据库操作
会向db中写入数据,这个时候才会用到数据库的连接,那么我们能不能把这个代码优化下呢,只让最后写数据的时候才用到事务
b.代码
@Transactional
public void bigTransaction() throws InterruptedException {
// 1、getData()方法模拟一个比较耗时的获取数据的操作,这个方法内部会休眠5秒
String data = this.getData();
//2、将上面获取到的数据写入到db中
Lesson007PO po = new Lesson007PO();
po.setId(UUID.randomUUID().toString());
po.setData(data);
this.lesson007Mapper.insert(po);
}
public String getData() throws InterruptedException {
//休眠5秒
TimeUnit.SECONDS.sleep(5);
return UUID.randomUUID().toString();
}
03.优化2:TransactionTemplate
a.说明
Spring为我们提供了一个工具类`TransactionTemplate`,通过这个类
我们可以灵活的控制事务的粒度,这个类就是我们常说的编程式事务
b.优化
下面将上面大事务的代码优化下,为了和上面方法区分,我们将优化后的代码放到一个新的方法中了,如下:
1.将方法上面的 @Transactional 去掉了
2.将最后需要事务操作的insert代码丢到`this.transactionTemplate.executeWithoutResult`,被这个方法包裹起来的代码才会使用spring事务
c.代码
/**
* 使用 TransactionTemplate 编程式事务,可以灵活的控制事务的范围
*
* @throws InterruptedException
*/
public void smallTransaction() throws InterruptedException {
// 1、调用getData()方法,讲获取的数据写到db中,假设 getData方法比较耗时,比如耗时 5秒
String data = this.getData();
//2、将上面获取到的数据写入到db中
Lesson007PO po = new Lesson007PO();
po.setId(UUID.randomUUID().toString());
po.setData(data);
// this.transactionTemplate.executeWithoutResult可以传入一个Consumer,这个Consumer表述需要在事务中执行的业务操作
this.transactionTemplate.executeWithoutResult(action -> {
this.lesson007Mapper.insert(po);
});
}
04.测试
a.为了方便看到测试效果,需要做下面准备
a.TransactionController
提供2个接口分别调用上面2个方法
b.tomcat连接池配置,配置200,这样可以支持200个请求同时过来,测试更真实
server:
tomcat:
threads:
max: 200
min-spare: 200
c.将连接池最大数量设置为20个,获取连接超时时间为3秒
# 这里我们把数据库连接池的最大量配置为20,最小10,获取链接超时时间为3秒,这样方便看到效果
hikari:
maximum-pool-size: 20
minimum-idle: 10
connection-timeout: 3000
b.运行测试用例
a.说明
对这两种事务的接口进行测试,分别对他们进行模拟200个并发请求,然后输出成功数量和失败的数量
b.代码
TransactionControllerTest
@Test
public void test() throws InterruptedException {
System.out.println("对这两种事务的接口进行测试,分别对他们进行模拟100个并发请求,然后输出成功数量和失败的数量");
//对声明式事务的接口进行测试,这个接口内部是大事务
System.out.println("--------------编程式事务接口压测结果------------------");
test("http://localhost:8080/bigTransaction");
//对编程式事务的接口进行测试,这个接口内部是小事务
System.out.println("--------------编程式事务接口压测结果------------------");
test("http://localhost:8080/smallTransaction");
}
c.输出
对这两种事务的接口进行测试,分别对他们进行模拟200个并发请求,然后输出成功数量和失败的数量
--------------声明式事务接口压测结果------------------
23:41:41 - 压测开始......
23:41:47 - 压测结束,总耗时(ms):5711
请求成功数:20
请求失败数:180
--------------编程式事务接口压测结果------------------
23:41:47 - 压测开始......
23:41:52 - 压测结束,总耗时(ms):5253
请求成功数:200
请求失败数:0
-------------------------------------------------------------------------------------------------
明式式事务的接口失败了180次,而编程式事务都成功了,是不是太顶了
d.声明式事务失败的原因
出现了大量下面这种异常,一眼就可以看出来,主要是获取连接超时弹出了异常,导致接口返回失败
-------------------------------------------------------------------------------------------------
2024-03-31 23:17:27.723 ERROR 15124 --- [io-8080-exec-28] c.i.l.controller.TransactionController : 声明式事务 执行异常:Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 3034ms.
2024-03-31 23:17:27.724 ERROR 15124 --- [io-8080-exec-91] c.i.l.controller.TransactionController : 声明式事务 执行异常:Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 3028ms.
2024-03-31 23:17:27.724 ERROR 15124 --- [io-8080-exec-61] c.i.l.controller.TransactionController : 声明式事务 执行异常:Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 3030ms.
2024-03-31 23:17:27.724 ERROR 15124 --- [o-8080-exec-188] c.i.l.controller.TransactionController : 声明式事务 执行异常:Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 3030ms.
1.8 一个通用Excel导出功能
00.汇总
非常通用,能够满足大部分项目中99%的导出功能,代码复用性很强
导出的列可以由前端自定义(比如哪些列需要导出、列的顺序、名称等都是可以由前端自定义)
01.代码实战
a.说明
启动 com.itsoku.lesson007.Lesson008Application
启动好之后,浏览器中打开 http://localhost:8080/userList
b.入参(ExcelExportRequest)
public class ExcelExportRequest {
/**
* excel名称
*/
private String excelName;
/**
* sheet的名称
*/
private String sheetName;
/**
* 导出字段有序列表
*/
private List<ExcelExportField> fieldList;
}
c.出参(ExcelExportResponse)
public class ExcelExportResponse {
//导出的excel文件名称
private String excelName;
// sheet列表数据
private List<ExcelSheet> sheetList;
}
d.Aop拦截请求,将 ExcelExportResponse 处理成excel导出
@Component
@Aspect
public class ExcelExportAspect {
@Around(value = "execution(* com.itsoku..*Controller.*(..))")
public Object around(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
Object result = proceedingJoinPoint.proceed();
if (result instanceof ExcelExportResponse) {
//下载excel
ExcelExportUtils.writeExcelToResponse((ExcelExportResponse) result);
return null;
} else {
return result;
}
}
}
1.9 自定义一个线程池管理器
00.汇总
系统中所有线程池,负责所有线程池的创建、监控等操作
01.示例
a.代码
com.itsoku.lesson009.common.ThreadPoolManager
b.主要2个方法
newThreadPool:创建一个线程池
threadPoolInfoList:获取线程池管理器中所有的线程池列表,包含每个线程池的各种指标(名称、核心线程数、最大线程数、当前活动线程数、队列容量、队列当前大小等信息),监控系统采集这些信息进行监控告警等处理
02.案例
a.ThreadPoolConfiguration
使用线程池创建2个线程池,一个用户发送邮件,一个用户发送短信
在业务上,通常不同的业务使用不同的线程池,这也叫线程池隔离,互不影响
如果用同一个线程池,比如发邮件和发短信共用一个,那么邮件太多的时候,会导致短信发送延后,影响业务
b.EmailSendService
模拟使用线程池发送邮件
c.ThreadPoolManagerController
暴露了一个接口用于获取线程池管理器中所有线程池列表,可用于监控
d.启动应用
Lesson009Application
e.访问
http://localhost:8080/threadPoolManager/threadPoolInfoList
f.返回
[{
"name": "emailThreadPool",
"corePoolSize": 5,
"maxPoolSize": 10,
"activeCount": 5,
"queueCapacity": 1000,
"queueSize": 84
}, {
"name": "smsThreadPool",
"corePoolSize": 16,
"maxPoolSize": 32,
"activeCount": 0,
"queueCapacity": 1000,
"queueSize": 0
}]
1.10 自定义一个动态线程池
01.定义
无需重启的情况下,可以对线程池进行扩缩容,比如改变线程池的核心线程数量、最大线程数量、队列容量等
02.使用
a.说明
我们会创建一个线程池,然后让其去处理任务,然后对其进行扩缩容
并查看扩缩容前后线程池的各个指标的变化(核心线程数、最大线程数、活动线程数、队列容量、队列中当前元素数量)
b.创建一个线程池
线程池名称:emailThreadPool
核心线程数:10
最大线程数:20
队列容量:1000
-----------------------------------------------------------------------------------------------------
@Bean
public ThreadPoolTaskExecutor emailThreadPool() {
//使用线程池管理器创建线程池
return ThreadPoolManager.newThreadPool("emailThreadPool", 10, 20, 1000);
}
c.启动应用
com.itsoku.lesson009.Lesson009Application
-----------------------------------------------------------------------------------------------------
为了能看到效果,系统中会使用上面刚创建的这个线程池去模拟批量发邮件的一个操作
这样线程池中的一些数据才会发生变化(如:活动线程数、队列中当前元素的数量queueSize 这些指标)
d.看下线程池的信息
系统中暴露了一个接口可以查看到线程池管理器中所有线程池的信息
浏览器中访问:http://localhost:8080/threadPoolManager/threadPoolInfoList
返回如下:
{
"code": "1",
"data": [
{
"name": "emailThreadPool", // 线程池名称
"corePoolSize": 10, // 核心线程数
"maxPoolSize": 20, // 最大线程数
"activeCount": 10, // 活动线程数
"queueCapacity": 1000, // 队列容量
"queueSize": 288 // 队列中当前元素数量
}
],
"msg": null
}
03.演示扩容
a.扩缩容接口
com.itsoku.lesson009.controller.ThreadPoolManagerController#threadPoolChange
-----------------------------------------------------------------------------------------------------
/**
* 线程池扩缩容
*
* @return
*/
@PostMapping("/threadPoolChange")
public Result<Boolean> threadPoolChange(@RequestBody ThreadPoolChange threadPoolChange) {
ThreadPoolManager.changeThreadPool(threadPoolChange);
return ResultUtils.ok(true);
}
b.执行扩容
核心线程数、最大线程数、容量都扩容一倍
-----------------------------------------------------------------------------------------------------
### 测试扩容
POST http://localhost:8080/threadPoolManager/threadPoolChange
Accept: application/json
Content-Type: application/json
{
"name": "emailThreadPool",
"corePoolSize": 50,
"maxPoolSize": 100,
"queueCapacity": 2000
}
c.看下扩容后线程池的信息
浏览器中访问:http://localhost:8080/threadPoolManager/threadPoolInfoList,返回如下:
{
"code": "1",
"data": [
{
"name": "emailThreadPool",
"corePoolSize": 50,
"maxPoolSize": 100,
"activeCount": 50,
"queueCapacity": 2000,
"queueSize": 408
}
],
"msg": null
}
04.演示缩容
a.执行缩容
核心线程数、最大线程数、容量都扩容一倍
-----------------------------------------------------------------------------------------------------
### 测试缩容
POST http://localhost:8080/threadPoolManager/threadPoolChange
Accept: application/json
Content-Type: application/json
{
"name": "emailThreadPool",
"corePoolSize": 5,
"maxPoolSize": 10,
"queueCapacity": 500
}
b.看下扩容后线程池的信息
浏览器中访问:http://localhost:8080/threadPoolManager/threadPoolInfoList,返回如下:
{
"code": "1",
"data": [
{
"name": "emailThreadPool",
"corePoolSize": 5,
"maxPoolSize": 10,
"activeCount": 2,
"queueCapacity": 500,
"queueSize": 0
}
],
"msg": null
}
05.代码示例
a.剖析
a.说明
线程池中会用到Java中的阻塞队列`java.util.concurrent.BlockingQueue`
目前jdk中自带几个阻塞队列都不支持动态扩容,比如`java.util.concurrent.LinkedBlockingQueue`
他里面的capacity是final的,不支持修改,为了是队列容量能够支持调整
我们创建了一个可扩容的阻塞队列`ResizeLinkedBlockingQueue`
代码是从`LinkedBlockingQueue`中拷贝过来的,然后添加了一个可以修改容量capacity的方法
如下,然后创建线程池的时候,我们使用自定义的这个阻塞队列便可以实现线程池的动态扩容
b.代码
/**
* 设置容量
* @param capacity
*/
public void setCapacity(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
if (count.get() > capacity) {
throw new IllegalArgumentException();
}
this.capacity = capacity;
} finally {
putLock.unlock();
}
}
b.剖析
a.说明
线程池扩容的方法
b.代码
com.itsoku.lesson009.comm.ThreadPoolManager#changeThreadPool
2 part01
2.1 动态job实战
01.功能
会创建一个job表
可以通过接口,对这些job表进行增删改查
支持动态增加、删除、修改、启动、停止Job等
系统均无需重启,会自动监控job表的变化,实现job的动态执行
02.用到的技术
SpringBoot
MyBatis-Plus
MySql
cron表达式(job执行的一种表达式,如`* * * * * *`表示每秒执行一次 )
03.代码实战
a.系统启动后会自动执行下面的脚本
-- 创建job表
create table if not exists t_job
(
id varchar(50) primary key comment 'id,主键',
name varchar(100) not null comment 'job名称,可以定义一个有意义的名称',
cron varchar(50) not null comment 'job的执行周期,cron表达式',
bean_name varchar(100) not null comment 'job需要执行那个bean,对应spring中bean的名称',
bean_method varchar(100) not null comment 'job执行的bean的方法',
status smallint not null default 0 comment 'job的状态,0:停止,1:执行中'
);
-- 为了方便测试,清理数据
delete from t_job;
-- 创建2个测试用的job,job1每1秒执行1次,job2每2秒执行一次
insert ignore into t_job values ('1', '第1个测试job', '* * * * * *', 'job1', 'execute', 1);
insert ignore into t_job values ('2', '第2个测试job', '*/2 * * * * *', 'job2', 'execute', 1);
b.原理
应用启动后,会自动去job表拉取需要执行的job,进行执行
并每隔5秒对这个 job 表进行一次监控,监控其有没有发生变化
比如这个表中的 job 发生变化(有新增、删除、修改、暂停、启动等操作)都会被自动监控到
然后便实现了 job 的动态执行
c.系统中定义了3个测试用的job
com.itsoku.lesson011.test.Job1
com.itsoku.lesson011.test.Job2
com.itsoku.lesson011.test.Job3
d.启动应用
com.itsoku.lesson011.Lesson011Application
e.可以看到job1和job2在执行了
[main] 18:02:17 :Tomcat started on port(s): 8080 (http) with context path ''
[main] 18:02:17 :Started Lesson011Application in 4.123 seconds (JVM running for 5.989)
[main] 18:02:17 :启动 job 成功:{"id":"1","name":"第1个测试job","cron":"* * * * * *","beanName":"job1","beanMethod":"execute"}
[main] 18:02:17 :启动 job 成功:{"id":"2","name":"第2个测试job","cron":"*/2 * * * * *","beanName":"job2","beanMethod":"execute"}
[taskExecutor-2] 18:02:18 :job1
[taskExecutor-3] 18:02:18 :job2
[taskExecutor-4] 18:02:19 :job1
[taskExecutor-1] 18:02:20 :job2
[taskExecutor-1] 18:02:20 :job1
[taskExecutor-3] 18:02:21 :job1
[taskExecutor-6] 18:02:22 :job1
f.测试各种场景
### 停止job1
POST http://localhost:8080/jobStop?id=1
Accept: application/json
### 启动job1
POST http://localhost:8080/jobStart?id=1
Accept: application/json
### 删除job1
POST http://localhost:8080/jobDelete?id=1
Accept: application/json
### 变更job2,将其执行周期改为每5秒一次
POST http://localhost:8080/jobUpdate
Accept: application/json
Content-Type: application/json
{
"id": "2",
"name": "第2个job",
"cron": "*/5 * * * * *",
"beanName": "job2",
"beanMethod": "execute",
"status": 1
}
### 添加一个job3,每秒执行一次
POST http://localhost:8080/jobCreate
Content-Type: application/json
Accept: application/json
{
"name": "第3个job",
"cron": "* * * * * *",
"beanName": "job3",
"beanMethod": "execute",
"status": 1
}
04.源码解析
a.JobController:job对外暴露的接口
提供对job表的增删改查、job的暂停、启动等接口
b.ThreadPoolTaskScheduler:Spring 框架中用于任务调度的组件
系统中最终job的执行,就是调用`ThreadPoolTaskScheduler`这个类的一些方法去执行的,稍后带大家看下源码。
-----------------------------------------------------------------------------------------------------
@Bean
public ThreadPoolTaskScheduler threadPoolTaskScheduler() {
ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
//线程池大小
threadPoolTaskScheduler.setPoolSize(100);
//线程名称前缀
threadPoolTaskScheduler.setThreadNamePrefix("taskExecutor-");
//等待时长
threadPoolTaskScheduler.setAwaitTerminationSeconds(60);
//关闭任务线程时是否等待当前被调度的任务完成
threadPoolTaskScheduler.setWaitForTasksToCompleteOnShutdown(true);
return threadPoolTaskScheduler;
}
c.SpringJobRunManager:动态job执行的的核心代码
这个类是自己写的,内部会监控job表变化,然后动态执行job,目前系统默认是5秒监控一次
05.扩展
a.如何让job支持集群?
目前这个job是单机版本的,可能有朋友会问,线上会是集群的方式执行,那怎么办?这里给2个方案
1.可以在配置文件中加个开关,用开关配置,是否需要这台机器执行,这个方案可能不太友好
2.对每个job加分布式锁,加锁成功才去执行
b.让job支持其他方式调用
案例中job是通过beanName、beanMethod结合反射去调用的,不够灵活
大家可以对这个进行改造,比如支持http接口的方式去调用job或者其他更多方式
大家自由扩展,这样你开发出来的这个job就是比较通用的了
可以直接当成公司的一个job平台去用,会让领导对你刮目相看,同时也提升了技术,双赢
2.2 幂等的4种解决方案
00.汇总
方案1:update时将status=0作为条件判断解决
方案2:乐观锁
方案3:唯一约束 一种通用的方案
方案4:分布式锁
00.概述
a.定义
幂等指多次操作产生的影响只会跟一次执行的结果相同
通俗的说:某个行为重复的执行,最终获取的结果是相同的,不会因为重复执行对系统造成变化
b.例子
比如说咱们有个网站,网站上支持购物,但只能用网站上自己的金币进行付款。
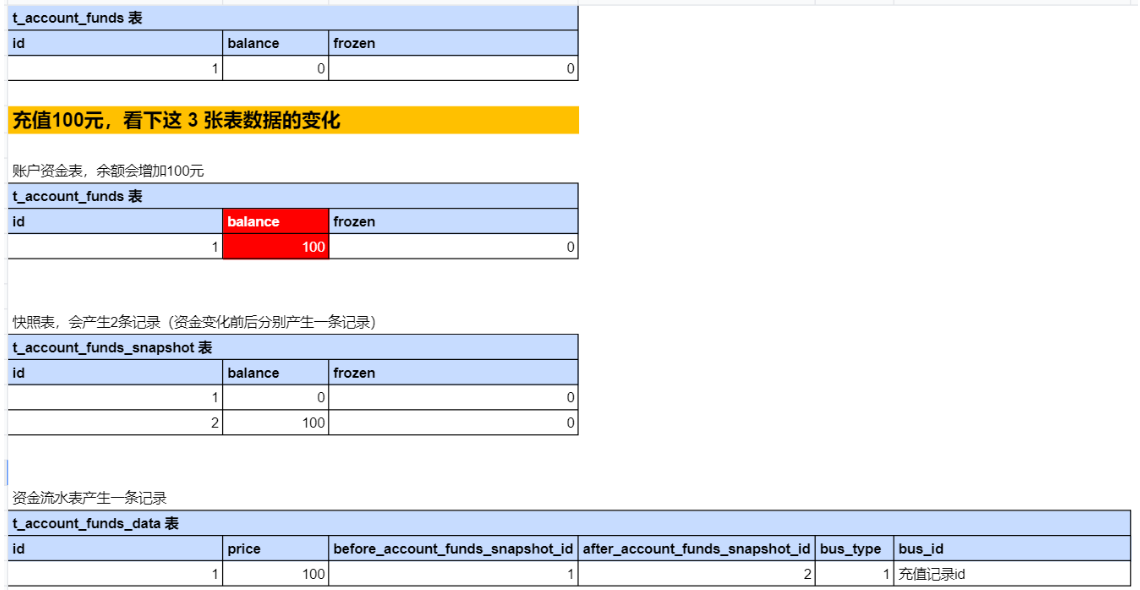
金币从哪里来呢?可通过支付宝充值来,1元对1金币,充值的过程如下
图片说明:充值过程示意图
上图中的第7步,这个地方支付宝会给商家发送通知,商家收到支付宝的通知后会执行下面逻辑
-----------------------------------------------------------------------------------------------------
step1.判.断订单是否处理过
step2.若订单已处理,则直接返回SUCCESS,否则继续向下走
step3.将订单状态置为成功
step4.给用户在平台的账户加金币
step5.返回SUCCESS
-----------------------------------------------------------------------------------------------------
由于网络存在不稳定的因素,这个通知可能会发送多次
极端情况下,同一笔订单的多次通知可能同时到达商户端,若商家这边不做幂等操作,那么同一笔订单就可能被处理多次
比如2次通知同时走到step2,都会看到订单未处理,则会继续向下走,那么账户就会被加2次钱
这将出现严重的事故,搞不好公司就被干倒闭了
c.如何解决这个问题?
本文中,我会给大家提供4种方案,每种方案都会有代码落地,以及会对每种方案进行并发压测,验证其可靠性
d.先添加2张表(账户表、充值订单表)
-- 创建账户表
create table if not exists t_account
(
id varchar(50) primary key comment '账户id',
name varchar(50) not null comment '账户名称',
balance decimal(12, 2) not null default '0.00' comment '账户余额'
) comment '账户表';
-- 充值记录表
create table if not exists t_recharge
(
id varchar(50) primary key comment 'id,主键',
account_id varchar(50) not null comment '账户id,来源于表t_account.id',
price decimal(12, 2) not null comment '充值金额',
status smallint not null default 0 comment '充值记录状态,0:处理中,1:充值成功',
version bigint not null default 0 comment '系统版本号,默认为0,每次更新+1,用于乐观锁'
) comment '充值记录表';
-- 准备测试数据,
-- 账号数据来一条,
insert ignore into t_account values ('1', '路人', 0);
-- 充值记录来一条,状态为0,稍后我们模拟回调,会将状态置为充值成功
insert ignore into t_recharge values ('1', '1', 100.00, 0, 0);
-----------------------------------------------------------------------------------------------------
下面我们将实现,业务方这边给支付宝提供的回调方法,在这个回调方法中会处理刚才上面sql中插入的那个订单
会将订单状态置为成功,成功也就是1,然后给用户的账户余额中添加100金币
这个回调方法,下面会提供4种实现,都可以确保这个回调方法的幂等性,余额只会加100
01.方案1:update时将status=0作为条件判断解决
a.原理
逻辑如下,重点在于更新订单状态的时候要加上status = 0这个条件
如果有并发执行到这条sql的时候,数据库会对update的这条记录加锁,确保他们排队执行,只有一个会执行成功
-----------------------------------------------------------------------------------------------------
String rechargeId = "充值订单id";
// 根据rechargeId去找充值记录,如果已处理过,则直接返回成功
RechargePO rechargePo = select * from t_recharge where id = #{rechargeId};
// 充值记录已处理过,直接返回成功
if(rechargePo.status==1){
return "SUCCESS";
}
-----------------------------------------------------------------------------------------------------
// 开启Spring事务
// 下面这个sql是重点,重点在where后面要加 status = 0 这个条件;count表示影响行数
int count = (update t_recharge set status = 1 where id = #{rechargeId} and status = 0);
// count = 1,表示上面sql执行成功
if(count!=1){
// 走到这里,说明有并发,直接抛出异常
throw new RuntimeException("系统繁忙,请重试")
}else{
//给账户加钱
update t_account set balance = balance + #{rechargePo.price} where id = #{rechargePo.accountId}
}
// 提交Spring事务
b.源码
com.itsoku.lesson012.controller.RechargeController#rechargeCallBack1
c.运行看结果
RechargeControllerTest#rechargeCallBack1
-----------------------------------------------------------------------------------------------------
并发100次请求对这个方案进行压测,在压测前后,我们会打印出订单的状态、账户的余额,大家注意看着几个数据。
预期的结果,订单状态应该是1,账户余额应该是100
-----------------------------------------------------------------------------------------------------
-----------------------------方案1 幂等测试----------------------------------------
测试前,充值订单&账户信息:充值订单号:1,状态:0,账户余额:0.00
接口:http://localhost:8080/rechargeCallBack1?rechargeId=1
[main] 22:08:26 :压测开始......共发送请求数量:100,并发量:100
[main] 22:08:27 :压测结束,总耗时(ms):170
测试后,充值订单&账户信息:充值订单号:1,状态:1,账户余额:100.00
02.方案2:乐观锁
a.原理
String rechargeId = "充值订单id";
// 根据rechargeId去找充值记录,如果已处理过,则直接返回成功
RechargePO rechargePo = select * from t_recharge where id = #{rechargeId};
// 充值记录已处理过,直接返回成功
if(rechargePo.status==1){
return "SUCCESS";
}
// 开启Spring事务
// 期望的版本号
Long exceptVersion = rechargePo.version;
// 下面这个sql是重点,重点在set后面要有version = version + 1,where后面要加 status = 0 这个条件;count表示影响行数
int count = (update t_recharge set status = 1,version = version + 1 where id = #{rechargeId} and version = #{exceptVersion});
// count = 1,表示上面sql执行成功
if(count!=1){
// 走到这里,说明有并发,直接抛出异常
throw new RuntimeException("系统繁忙,请重试")
}else{
//给账户加钱
update t_account set balance = balance + #{rechargePo.price} where id = #{rechargePo.accountId}
}
// 提交spring事务
-----------------------------------------------------------------------------------------------------
重点在于update t_recharge set status = 1,version = version + 1 where id = #{rechargeId} and version = #{exceptVersion}这条sql
set 后面必须要有 version = version + 1
where后面必须要有 version = #{exceptVersion}
这样乐观锁才能起作用
b.源码
com.itsoku.lesson012.controller.RechargeController#rechargeCallBack2
c.运行看结果
RechargeControllerTest#rechargeCallBack2
并发100次请求对这个方案进行压测,在压测前后,我们会打印出订单的状态、账户的余额,大家注意看着几个数据。
预期的结果,订单状态应该是1,账户余额应该是100
-----------------------------------------------------------------------------------------------------
-----------------------------方案2 幂等测试----------------------------------------
测试前,充值订单&账户信息:充值订单号:1,状态:0,账户余额:0.00
接口:http://localhost:8080/rechargeCallBack2?rechargeId=1
[main] 22:08:44 :压测开始......共发送请求数量:100,并发量:100
[main] 22:08:44 :压测结束,总耗时(ms):156
测试后,充值订单&账户信息:充值订单号:1,状态:1,账户余额:100.00
03.方案3:唯一约束
a.需要添加一张唯一约束辅助表
如下,这个表重点关注第二个字段idempotent_key,这个字段添加了唯一约束
说明同时向这个表中插入同样值的idempotent_key,则只有一条记录会执行成功,其他的请求会报异常
而失败,让事务回滚,这个知识点了解后,方案就容易看懂了
-----------------------------------------------------------------------------------------------------
-- 幂等辅助表
create table if not exists t_idempotent
(
id varchar(50) primary key comment 'id,主键',
idempotent_key varchar(200) not null comment '需要确保幂等的key',
unique key uq_idempotent_key (idempotent_key)
) comment '幂等辅助表';
b.原理
String idempotentKey = "幂等key";
// 幂等表是否存在记录,如果存在说明处理过,直接返回成功
IdempotentPO idempotentPO = select * from t_idempotent where idempotent_key = #{idempotentKey};
if(idempotentPO!=null){
return "SUCCESS";
}
// 开启Spring事务(这里千万不要漏掉,一定要有事务)
// 这里放入需要幂等的业务代码,最好是db操作的代码。。。。。
String idempotentId = "";
// 这里是关键一步,向 t_idempotent 插入记录,如果有并发过来,只会有一个成功,其他的会报异常导致事务回滚
insert into t_idempotent (id, idempotent_key) values (#{idempotentId}, #{idempotentKey});
// 提交spring事务
c.用这种方案来处理支付回调通知,伪代码如下
String rechargeId = "充值订单id";
// 根据rechargeId去找充值记录,如果已处理过,则直接返回成功
RechargePO rechargePo = select * from t_recharge where id = #{rechargeId};
// 充值记录已处理过,直接返回成功
if(rechargePo.status==1){
return "SUCCESS";
}
// 生成idempotentKey,这里可以使用,业务id:业务类型,那么我们这里可以使用rechargeId+":"+"RECHARGE_CALLBACK"
String idempotentKey = rechargeId+":"+"RECHARGE_CALLBACK";
// 幂等表是否存在记录,如果存在说明处理过,直接返回成功
IdempotentPO idempotentPO = select * from t_idempotent where idempotent_key = #{idempotentKey};
if(idempotentPO!=null){
return "SUCCESS";
}
// 开启Spring事务(这里千万不要漏掉,一定要有事务)
// count表示影响行数,这个sql比较特别,看起来并发会出现问题,实际上配合唯一约束辅助表,就不会有问题了
int count = update t_recharge set status = 1 where id = #{rechargeId};
// count != 1,表示未成功
if(count!=1){
// 走到这里,直接抛出异常,让事务回滚
throw new RuntimeException("系统繁忙,请重试")
}else{
//给账户加钱
update t_account set balance = balance + #{rechargePo.price} where id = #{rechargePo.accountId}
}
String idempotentId = "";
// 这里是关键一步,向 t_recharge 插入记录,如果有并发过来,只会有一个成功,其他的会报异常导致事务回滚,上面的
insert into t_recharge (id, idempotent_key) values (#{idempotentId}, #{idempotentKey});
// 提交spring事务
d.源码
com.itsoku.lesson012.controller.RechargeController#rechargeCallBack3
e.运行看结果
RechargeControllerTest#rechargeCallBack3
并发100次请求对这个方案进行压测,在压测前后,我们会打印出订单的状态、账户的余额,大家注意看着几个数据。
预期的结果,订单状态应该是1,账户余额应该是100
-----------------------------------------------------------------------------------------------------
-----------------------------方案3 幂等测试----------------------------------------
测试前,充值订单&账户信息:充值订单号:1,状态:0,账户余额:0.00
接口:http://localhost:8080/rechargeCallBack3?rechargeId=1
[main] 22:08:59 :压测开始......共发送请求数量:100,并发量:100
[main] 22:08:59 :压测结束,总耗时(ms):127
测试后,充值订单&账户信息:充值订单号:1,状态:1,账户余额:100.00
04.方案4:分布式锁
上面三种方式都是依靠数据库的功能解决幂等性的问题,所以比较适合对数据库操作的业务
若业务没有数据库操作,需要实现幂等,可用分布式锁解决
2.3 并行查询,可能有坑
01.并行查询可能存在的问题?
a.说明
如果上面执行并行查询用到的线程池配置不当,可能导致比较严重的性能问题
b.说明
比如将核心线程数设置为了1,而队列大小没有限制,那么所有的请求都变成串行了,会导致请求响应非常慢,出现大事故
或者核心线程数设置的比较小,比如10,而队列大小没有设置上限,那么这个线程池同时只可支持10个任务并行
其他的请求进入这个接口后都变成串行执行了,进入队列排队,从而导致接口响应特别慢
c.怎么解决这个问题?
a.说明
解决这个问题本质是不要让任务排队或者排队时间不要太长
这个时候我们就要先说一下线程池的原理了,了解原理之后,就知道如何破解这个问题
b.了解了这个过程我们就有优化办法了,如下
1.可以将核心线程数、最大线程数调大,但是也不能随便调,比如调的很大,反而会降低系统性能,建议调的过程中根据业务的指标进行压测得到一个合理的值
2.将队列大小设置的比较小,这样排队的时间大概率会比较短,或者排队失败,直接后面的流程
LinkedBlockingQueue、ArrayBlockingQueue` 容量是不允许为0的,如果需要用到容量为0的队列,则需要使用同步阻塞队列`SynchronousQueue`
3.将队列大小设置为0,这样任务就不会进入队列,而直接创建新的线程去执行,或者走拒绝策略
4.拒绝策略可以使用`CallerRunsPolicy`,这个策略是直接在当前线程执行,即如果线程池执行不了,则自己去执行,这样至少不会一直等着
5.线程池隔离,不同的业务最好使用不同的线程池,互不影响,强烈建议核心业务一定要使用单独的线程池。
c.优化后的线程池配置
@Bean
public ThreadPoolTaskExecutor goodsThreadPool() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setThreadNamePrefix("ThreadPool-Goods-");
// 核心线程数为cpu核数 * 4,最大线程数据为cpu核数 * 8
threadPoolTaskExecutor.setCorePoolSize(Runtime.getRuntime().availableProcessors() * 4);
threadPoolTaskExecutor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 8);
// 队列容量为0,则任务就不会进入队列
threadPoolTaskExecutor.setQueueCapacity(0);
// 拒绝策略使用CallerRunsPolicy,让当前线程去兜底去执行任务
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return threadPoolTaskExecutor;
}
2.4 接口通用返回值设计与实现
01.接口返回值通用格式
a.通常会有4个字段
public class Result<T> {
/**
* 请求是否处理成功?
*/
private boolean success;
/**
* 数据,泛型类型,后端需要返回给前端的业务数据可以放到这个里面
*/
public T data;
/**
* 提示消息,如success为false的时给用户的提示信息
*/
private String msg;
/**
* 错误编码,某些情况下,后端可以给前端提供详细的错误编码,前端可以根据不同的编码做一些不同的操作
*/
private String code;
}
b.接口示例代码如下,返回值为Result类型
@RestController
public class TestController {
@GetMapping("/hello")
public Result<String> hello() {
return ResultUtils.success("欢迎大家学习《高并发 & 微服务 & 性能调优实战案例 100 讲》");
}
}
c.前端调用此接口,看到的结果如下
{
"success": true,
"data": "欢迎大家学习《高并发 & 微服务 & 性能调优实战案例 100 讲》",
"msg": null,
"code": null
}
02.异常情况处理
a.说明
后端的接口中,通常,都是有一些校验功能的
比如登录接口中,需要验证用户名或密码是否正确,如果不正确需要提示前端:用户名或密码不正确,给前端返回下面的数据
b.代码
{
"success": false,
"data": null,
"msg": "1001",
"code": "用户名或密码错误"
}
c.说明
代码中我们可以怎么写呢?后端校验不通过的时候,可以抛出一个业务异常
然后在全局异常处理中去处理这个异常,返回通用格式的结果
03.具体怎么做呢?
a.自定义一个业务异常类
public class BusinessException extends RuntimeException {
private String code;
/**
* @param code 错误编码
* @param message 错误提示
*/
public BusinessException(String code, String message) {
super(message);
this.code = code;
}
public BusinessException(String code, String message, Throwable cause) {
super(message, cause);
this.code = code;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
b.接口中抛出业务异常
登录接口可以用下面这种写法了,用户名不对的时候,抛出一个业务异常BusinessException
-----------------------------------------------------------------------------------------------------
@GetMapping("/login")
public Result<String> login(String name) {
if (!"路人".equals(name)) {
throw new BusinessException("1001", "用户名错误");
} else {
return ResultUtils.success("登录成功");
}
}
04.全局异常中对BusinessException异常进行统一处理
a.说明
BusinessException这个异常可以使用springboot中的全局异常处理器去处理
b.定义一个全局异常处理器
a.说明
类上使用 @RestControllerAdvice 注解标注
注意看handleBusinessException方法,这个方法上有个 @ExceptionHandler(BusinessException.class) 注解
这个注解的值是 BusinessException,表示接口中抛出这个异常的时候,会进入到 handleBusinessException 方法中去处理
这个方法最后返回的也是通用的结果Result类型
b.代码
@RestControllerAdvice
public class GlobalExceptionHandler {
private Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* 处理业务异常
*
* @param e
* @param request
* @return
*/
@ExceptionHandler(BusinessException.class)
public Result handleBusinessException(BusinessException e, HttpServletRequest request) {
logger.info("请求:{},发生异常:{}", request.getRequestURL(), e.getMessage(), e);
return ResultUtils.error(e.getCode(), e.getMessage());
}
}
c.此时我们验证下上面这个登录接口
a.用户名正确
http://localhost:8080/login?name=路人
{
"success": true,
"data": "登录成功",
"msg": null,
"code": null
}
c.用户名错误
http://localhost:8080/login?name=张三
{
"success": false,
"data": null,
"msg": "用户名或密码错误",
"code": "1001"
}
05.案例:SpringBoot自带的参数校验功能异常处理
a.用户注册接口
com.itsoku.lesson013.controller.TestController#register
@PostMapping("/userRegister")
public Result<Void> userRegister(@Validated @RequestBody UserRegisterRequest req) {
return ResultUtils.success();
}
b.当参数校验不通过的时候
会自动抛出一个org.springframework.validation.BindException异常
c.对应的全局异常处理方法
@ExceptionHandler(BindException.class)
public Result handleBindException(BindException e, HttpServletRequest request) {
logger.info("请求:{},发生异常:{}", request.getRequestURL(), e.getMessage(), e);
String message = e.getAllErrors().get(0).getDefaultMessage();
return ResultUtils.error(message);
}
06.全局其他异常处理
a.说明
当上面的异常处理方法都无法匹配接口中的异常的时候,将走下面这个方法去处理异常,这个是用来对异常处理进行兜底的
b.代码
/**
* 处理其他异常
*
* @param e
* @param request
* @return
*/
@ExceptionHandler(Exception.class)
public Result handleException(Exception e, HttpServletRequest request) {
logger.info("请求:{},发生异常:{}", request.getRequestURL(), e.getMessage(), e);
//会返回code为500的一个异常
return ResultUtils.error(ErrorCode.SERVER_ERROR,"系统异常,请稍后重试");
}
07.提供的几个工具类
com.itsoku.lesson013.common.ResultUtils:提供了创建Result对象的一些静态方法
com.itsoku.lesson013.common.BusinessExceptionUtils:提供了创建BusinessException的一些静态方法
com.itsoku.lesson013.common.ErrorCode:将系统中所有的错误编码可以放到这个类中集中化管理
2.5 接口太多,解决DTO、VO泛滥
01.问题
有些项目接口很多,而接口入参一般我们使用XxxDTO这种类型参数,返回值通常使用XxxVO这种类型
很多开发按照自己项目搞事情,时间久了,导致系统中充斥着大量的dto、vo命名的类,各种命名千奇百怪
问题来了,然后我们再添加新的接口的时候,入参和返回值不知道如何命名了,大家有没有这种经历?
02.elasticsearch示例
a.说明
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
b.springboot端提供的一个用于调用elasticsearch服务端接口的工具类
co.elastic.clients.elasticsearch.ElasticsearchClient
IndexResponse index(IndexRequest request)
ReindexResponse reindex(ReindexRequest request)
DeleteResponse delete(DeleteRequest request)
DeleteByQueryResponse deleteByQuery(DeleteByQueryRequest request)
DeleteScriptResponse deleteScript(DeleteScriptRequest request)
c.上面方法的特点
入参的类型是:方法名称+Request
返回值的类型是:方法名称+Response
2.6 复杂业务,如何传参
00.汇总
优化前
优化后
使用上下文对象来解决
01.优化前
a.代码
package com.itsoku.lesson016;
public class XxxService {
/**
* 这个方法是对外暴露的接口
*
* @param request
*/
public void execute(M1Request request) {
//m1方法中会产生Obj1,Obj2
this.m1(request);
//下面m2方法中要用到m1方法中产生的Obj1、Obj2,而m2本身又会返回obje3
Obj1 obj1 = null;
Obj2 obj2 = null;
Obj3 obj3 = this.m2(obj1, obj2);
//m3方法中又会用到4个参数:request、obj1、obj2、obj3
this.m3(request, obj1, obj2, obj3);
}
private void m1(M1Request request) {
System.out.println(request);
//这里会产生2个对象
Obj1 obj1 = new Obj1();
Obj2 obj2 = new Obj2();
}
private Obj3 m2(Obj1 obj1, Obj2 obj2) {
System.out.println(obj1);
System.out.println(obj2);
//这里需要用到 obj1,obj2
Obj3 obj3 = new Obj3();
return obj3;
}
private void m3(M1Request request, Obj1 obj1, Obj2 obj2, Obj3 obj3) {
System.out.println(request);
System.out.println(obj1);
System.out.println(obj2);
System.out.println(obj3);
}
}
b.上面代码如何拿到m1方法中创建的2个对象呢?
// 我们可以创建一个类,用来作为m1方法的返回值,用来存放m1方法中的ojb1、obj2
public class M1Result {
private Obj1 obj1;
private Obj2 obj2;
public Obj1 getObj1() {
return obj1;
}
public void setObj1(Obj1 obj1) {
this.obj1 = obj1;
}
public Obj2 getObj2() {
return obj2;
}
public void setObj2(Obj2 obj2) {
this.obj2 = obj2;
}
}
02.优化后
a.代码
package com.itsoku.lesson016;
public class XxxService1 {
/**
* 这个方法是对外暴露的接口
*
* @param request
*/
public void execute(M1Request request) {
//m1方法中会产生Obj1,Obj2
M1Result m1Result = this.m1(request);
//下面m2方法中要用到m1方法中产生的Obj1、Obj2
Obj1 obj1 = m1Result.getObj1();
Obj2 obj2 = m1Result.getObj2();
Obj3 obj3 = this.m2(obj1, obj2);
//m3方法中又会用到4个参数:request、obj1、obj2、obj3
this.m3(request, obj1, obj2, obj3);
}
private M1Result m1(M1Request request) {
System.out.println(request);
Obj1 obj1 = new Obj1();
Obj2 obj2 = new Obj2();
M1Result result = new M1Result();
result.setObj1(obj1);
result.setObj2(obj2);
return result;
}
private Obj3 m2(Obj1 obj1, Obj2 obj2) {
System.out.println(obj1);
System.out.println(obj2);
//这里需要用到 obj1,obj2
Obj3 obj3 = new Obj3();
return obj3;
}
private void m3(M1Request request, Obj1 obj1, Obj2 obj2, Obj3 obj3) {
System.out.println(request);
System.out.println(obj1);
System.out.println(obj2);
System.out.println(obj3);
}
}
b.假如execute方法中还有后续代码,如下
public void execute(M1Request request) {
//m1方法中会产生Obj1,Obj2
M1Result m1Result = this.m1(request);
//下面m2方法中要用到m1方法中产生的Obj1、Obj2
Obj1 obj1 = m1Result.getObj1();
Obj2 obj2 = m1Result.getObj2();
Obj3 obj3 = this.m2(obj1, obj2);
//m3方法中又会用到4个参数:request、obj1、obj2、obj3
this.m3(request, obj1, obj2, obj3);
// 下面还有其他业务方法,内部也会产生一些对象,后续一些方法可能需要用到这些对象,有没有更好的解决方案呢?
}
03.使用上下文对象来解决
a.说明
可以创建一个上下文对象,为这个业务服务,上下文对象中存放了这个业务中所有需要用到的对象
这些对象都可以放到里面,后面的方法如果需要用到相关对象的时候,直接从上下文对象中存取就可以了
b.代码
// 定义一个上下文对象,通常以Context作为后缀,定义如下,目前这个案例中需要用到4个对象,都在这个类中包含了
package com.itsoku.lesson016;
public class XxxContext {
private M1Request request;
private Obj1 obj1;
private Obj2 obj2;
private Obj3 obj3;
// getter、setter方法
}
c.代码
// 引入这个上下文对象后,优化后的代码,如下,重点在于方法的参数类型都改成了 XxxContext
// 这样在方法中就可以从这个上线文中获取到需要使用的对象了,产生的新对象也可以丢到里面,是不是方便了很多?
package com.itsoku.lesson016;
public class XxxService3 {
/**
* 这个方法是对外暴露的接口
*
* @param request
*/
public void execute(M1Request request) {
XxxContext context = new XxxContext();
//m1方法中会产生Obj1,Obj2
this.m1(context);
//下面m2方法中要用到m1方法中产生的Obj1、Obj2
this.m2(context);
//m3方法中又会用到4个参数:request、obj1、obj2、obj3
this.m3(context);
// 下面还有其他业务方法,内部也会产生一些对象,后续一些方法可能需要用到这些对象,有没有更好的解决方案呢?
this.otherMethod(context);
}
private void m1(XxxContext context) {
System.out.println(context.getRequest());
Obj1 obj1 = new Obj1();
Obj2 obj2 = new Obj2();
context.setObj1(obj1);
context.setObj2(obj2);
}
private void m2(XxxContext context) {
//这里需要用到 obj1,obj2
System.out.println(context.getObj1());
System.out.println(context.getObj2());
Obj3 obj3 = new Obj3();
context.setObj3(obj3);
}
private void m3(XxxContext context) {
System.out.println(context.getRequest());
System.out.println(context.getObj1());
System.out.println(context.getObj2());
System.out.println(context.getObj3());
}
private void otherMethod(XxxContext context) {
}
}
2.7 接口报错,如何快速定位日志?
00.思考拓展?
1.如果接口中有子线程,那么子线程中能获取到这个traceId么?
2.如果接口涉及到内部的多个服务,那么多个服务中如何共享这个traceId呢?
01.要解决的问题?
接口报错,如何快速定位问题?这个需要日志的辅助,一般错误日志中有详细的堆栈信息,具体是哪行代码报错,都可以看到
要想快速定位问题,前提是要能够快速定位日志
海量日志,如何定位呢?日志量一般都是很大的,如何能够从大量日志中找到自己需要的日志呢?
02.解决方案
1.服务端入口处可以生成一个唯一的id,记做:traceId
2.日志中均需要输出traceId的值
3.接口返回值中,添加一个通用的字段:traceId,将上面的traceId作为这个字段的值
4.这样前端发现接口有问题的时候,直接将这个traceId提供给我们,我们便可以在日志中快速查询出对应的日志
03.代码实战
a.添加一个TraceFilter
// 拦截所有请求,入口生成一个唯一的traceId,放到ThreadLocal中
@Order(Ordered.HIGHEST_PRECEDENCE)
@WebFilter(urlPatterns = "/**", filterName = "TraceFilter")
public class TraceFilter extends OncePerRequestFilter {
public static Logger logger = LoggerFactory.getLogger(TraceFilter.class);
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String traceID = IdUtil.fastSimpleUUID();
TraceUtils.setTraceId(traceID);
long st = System.currentTimeMillis();
try {
filterChain.doFilter(request, response);
} finally {
long et = System.currentTimeMillis();
logger.info("请求地址:{},耗时(ms):{}", request.getRequestURL().toString(), (et - st));
TraceUtils.removeTraceId();
}
}
}
b.日志中输出traceId
需要在MDC中设置一下traceId:MDC.put("traceId", traceId);
MDC是logback为我们提供的一个扩展的入口,可以向里面放入一些键值对,然后在logback中的日志中就可以通过这个traceId获取到对应的值
如下,logback.xml中使用`%X{traceId}`可以获取到MDC中设置的traceId
c.返回值中添加通用字段traceId
public class Result<T> {
private boolean success;
public T data;
private String msg;
private String code;
// 链路追踪id
private String traceId;
d.通过aop将traceId写入响应结果的Result中
// 下面我们使用aop创建了一个环绕通知,会拦截controller的所有方法,以及全局异常处理器的方法
// 对Result类型的返回值进行统一处理,将traceId设置到Result中traceId字段中
@Aspect
@Order(Ordered.LOWEST_PRECEDENCE)
public class ResultTraceIdAspect {
@Pointcut("execution(* com.itsoku..*Controller.*(..)) ||execution(* com.itsoku.lesson017.web.GlobalExceptionHandler.*(..))")
public void pointCut() {
}
@Around("pointCut()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
Object object = pjp.proceed();
if (object instanceof Result) {
((Result<?>) object).setTraceId(TraceUtils.getTraceId());
}
return object;
}
}
e.测试效果
访问接口`http://localhost:8080/`,输出
{
"success": true,
"data": "欢迎和路人一起学习《高并发 & 微服务 & 性能调优实战案例100讲》",
"msg": null,
"code": null,
"traceId": "92558e52c28845b39c6bf4b76235ffdd"
}
通过这个traceId可以去控制台找到对应的日志
f.测试异常情况,快速定位日志
a.下面提供了一个测试接口,这个接口会抛出异常,代码中有:10/0,除数是零,会报异常
@GetMapping("/exception")
public Result<String> exception() throws InterruptedException {
logger.info("开始执行业务");
//这里模拟了一个错误,10/0,会报错
System.out.println(10/0);
logger.info("业务执行结束");
return ResultUtils.success("欢迎和路人一起学习《高并发 & 微服务 & 性能调优实战案例100讲》");
}
b.访问下这个接口`http://localhost:8080/exception`,输出
{
"success": false,
"data": null,
"msg": "系统异常,请稍后重试",
"code": "500",
"traceId": "b9141d327de645f9ba2f736009a35dc7"
}
c.通过这个traceId去查找下日志
略
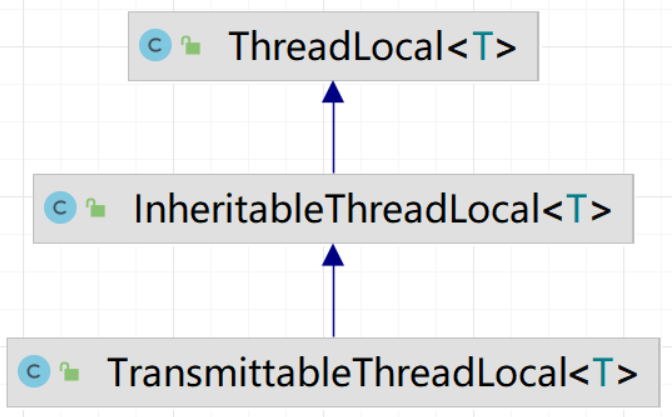
2.8 线程局部变量:TL、ITL、TTL
00.汇总
1.ThreadLocal:在当前线程中共享数据的,JUC 中提供的
2.InheritableThreadLocal:也是JUC中的一个工具类,解决 ThreadLocal 难以解决的问题
3.TransmittableThreadLocal:阿里开源的一个工具类,解决上面2个ThreadLocal 难以搞定的问题
01.案例1:ThreadLocal 可以在当前线程中共享数据
a.用法
在当前线程中,调用 ThreadLocal.set()可以向当前线程中存入数据
然后在当前线程的其他位置可以调用 ThreadLocal.get() 获取当刚才放入的数据
要点:ThreadLocal.set() 和 ThreadLocal.get() 需要再同一个线程中执行
b.原理
当前线程有个Map,key就是ThreadLocal对象,value就是通过ThreadLocal.set方法放入的值,如下
当前线程.map.put(threadLocal对象,threadLocal.set的值);
然后通过这个map和threadLocal就可以取到值了,如下
当前线程.map.get(threadLocal对象);
c.代码
//①:这里创建了一个 ThreadLocal
ThreadLocal<String> userNameTL = new ThreadLocal<>();
/**
* ThreadLocal 可以在当前线程中存储数据
* @throws InterruptedException
*/
@Test
public void threadLocalTest1() throws InterruptedException {
//这里是主线程,将用户名放入 userNameTL 中
userNameTL.set("张三");
//在m1中,取上面放入用户名名,看看是不是张三?
m1();
//这里创建了线程 thread1,里面放入了李四,然后在m1中取出用户名,看看是不是李四?
new Thread(() -> {
userNameTL.set("李四");
m1();
}, "thread1").start();
//这里创建了线程 thread2,里面放入了王五,然后在m1中取出用户名,看看是不是王五
new Thread(() -> {
userNameTL.set("王五");
m1();
}, "thread2").start();
TimeUnit.SECONDS.sleep(1);
}
public void m1() {
logger.info("userName:{}", userNameTL.get());
}
d.运行输出
17:13:40 [main] m1 - userName:张三
17:13:40 [thread1] m1 - userName:李四
17:13:41 [thread2] m1 - userName:王五
-----------------------------------------------------------------------------------------------------
1.主线程(线程名称:main)中放入了张三,取出来也是张三
2.线程 thread1 中放入了李四,取出来也是李四
3.线程 thread2 中放入了王五,取出来也是王五
e.结论
通过ThreadLocal可以在当前线程中共享数据,通过其set方法在当前线程中设置值
然后在当前线程的其他任何位置,都可以通过ThreadLocal的get方法获取到这个值
02.案例2:子线程是否可以获取ThreadLocal中的值呢?
a.代码
@Test
public void threadLocalTest2() throws InterruptedException {
//这里是主线程,ThreadLocal中设置了值:张三
userNameTL.set("张三");
logger.info("userName:{}", userNameTL.get());
//创建了一个子线程thread1,在子线程中去ThreadLocal中拿值,能否拿到刚才放进去的“张三”呢?
new Thread(() -> {
logger.info("userName:{}", userNameTL.get());
}, "thread1").start();
TimeUnit.SECONDS.sleep(1);
}
b.执行输出
15:08:47 [main] threadLocalTest2 - userName:张三
15:08:47 [thread1] lambda$threadLocalTest2$2 - userName:null
-----------------------------------------------------------------------------------------------------
子线程中没有拿到父线程中放进去的"张三",说明ThreadLocal只能在当前线程中共享数据
c.结论
子线程无法获取父线程ThreadLocal中的set数据
通过上面2个案例,可知ThreadLocal生效的条件是:其set和get方法必须在同一个线程才能共享数据
那么有没有方法解决这个问题呢?(父线程中set数据,子线程中可以get到这个数据的)
JUC中的工具类 InheritableThreadLocal 可以解决这个问题
03.案例3:InheritableThreadLocal(子线程可以获取父线程中存放的数据)
a.代码
// 这里定义了一个 InheritableThreadLocal 对象
private InheritableThreadLocal<String> userNameItl = new InheritableThreadLocal<>();
@Test
public void inheritableThreadLocal1() throws InterruptedException {
//这里是主线程,使用 InheritableThreadLocal.set 放入值:张三
userNameItl.set("张三");
logger.info("userName:{}", userNameItl.get());
//创建了一个子线程thread1,在子线程中去ThreadLocal中拿值,能否拿到刚才放进去的“张三”呢?
new Thread(() -> {
logger.info("userName:{}", userNameItl.get());
}, "thread1").start();
TimeUnit.SECONDS.sleep(1);
}
b.执行输出
19:35:48 [main] inheritableThreadLocal1 - userName:张三
19:35:48 [thread1] lambda$inheritableThreadLocal1$3 - userName:张三
c.结论
使用 InheritableThreadLocal ,子线程可以访问到父线程中通过InheritableThreadLocal.set进去的值
04.案例4:InheritableThreadLocal:遇到线程池,会怎么样呢?
a.代码
private InheritableThreadLocal<String> userNameItl = new InheritableThreadLocal<>();
@Test
public void inheritableThreadLocal2() throws InterruptedException {
//为了看到效果,这里创建大小为1的线程池,注意这里为1才能方便看到效果
ExecutorService executorService = Executors.newFixedThreadPool(1);
//主线程中,放入了张三
userNameItl.set("张三");
logger.info("userName:{}", userNameItl.get());
//在线程池中通过 InheritableThreadLocal 拿值,看看能否拿到 刚才放入的张三?
executorService.execute(() -> {
logger.info("第1次获取 userName:{}", userNameItl.get());
});
//这里稍微休眠一下,等待上面的任务结束
TimeUnit.SECONDS.sleep(1);
//这里又在主线程中放入了李四
userNameItl.set("李四");
logger.info("userName:{}", userNameItl.get());
//这里又在线程池中通过 InheritableThreadLocal.get 方法拿值,看看能否拿到 刚才放入的李四?
executorService.execute(() -> {
//在线程池中通过 inheritableThreadLocal 拿值,看看能否拿到?
logger.info("第2次获取 userName:{}", userNameItl.get());
});
TimeUnit.SECONDS.sleep(1);
}
b.执行输出
20:52:03 [main] inheritableThreadLocal2 - userName:张三
20:52:03 [pool-1-thread-1] lambda$inheritableThreadLocal2$4 - 第1次获取 userName:张三
20:52:04 [main] inheritableThreadLocal2 - userName:李四
20:52:04 [pool-1-thread-1] lambda$inheritableThreadLocal2$5 - 第2次获取 userName:张三
c.分析下结果
从结果中看,线程池执行了2次任务,2次拿到的都是张三,和主线程第一次放入的值是一样的
而第二次主线程中放入的是李四啊,但是第二次线程池中拿到的却是张三,这是什么原因?
-----------------------------------------------------------------------------------------------------
上面线程池的大小是1,也就是说这个线程池中只有一个线程,所以让线程池执行的2次任务用到的都是一个线程
从上面的日志中可以看到线程名称都是`pool-1-thread-1`,说明这两次任务,都是线程池中同一个线程执行的
-----------------------------------------------------------------------------------------------------
线程池中的线程是重复利用的,线程池中的`pool-1-thread-1`这个线程是什么时候创建的呢?谁创建的?他的父线程是谁?
1. 是主线程中第一次调用executorService.execute让线程池执行任务的时候,线程池发现当前线程数小于核心线程数,所以会创建一个线程
2. 他的父线程是谁?是创建他的线程,也就是执行第一次执行executorService.execute的线程,即主线程
-----------------------------------------------------------------------------------------------------
子线程创建的时候,子线程会将父线程中InheritableThreadLocal的值复制一份到子线程的InheritableThreadLocal中
从上面代码中可以看到,父线程InheritableThreadLocal中第一次丢入的是张三,之后就调用线程池的execute方法执行任务
此时,会在线程池中创建子线程,这个子线程会将父线程中InheritableThreadLocal中设置的张三
复制到子线程的InheritableThreadLocal中,此时子线程中的用户名就是从父线程复制过来的,即:张三
-----------------------------------------------------------------------------------------------------
复制之后,父子线程中的InheritableThreadLocal就没有关系了,父线程中InheritableThreadLocal的值再修改
也不会影响子线程中的值了,所以两次输出的都是张三
d.存在的问题
InheritableThreadLocal 用在线程池上,会有问题,可能导致严重事故,这个一定要知道。
如何解决这个问题呢?
阿里的:TransmittableThreadLocal,这个就是为解决这个问题而来的。
05.案例5:TransmittableThreadLocal:解决线程池中不能够访问外部线程数据的问题
a.依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.14.3</version>
</dependency>
b.说明
使用 TransmittableThreadLocal 代替 InheritableThreadLocal 和 ThreadLocal
线程池需要用 TtlExecutors.getTtlExecutorService 包裹一下,这个一定不要漏掉
ExecutorService executorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(1));
c.示例代码
TransmittableThreadLocal<String> userNameTtl = new TransmittableThreadLocal<String>();
@Test
public void transmittableThreadLocal1() throws InterruptedException {
//为了看到效果,这里创建大小为1的线程池,注意这里为1才能方便看到效果
ExecutorService executorService = Executors.newFixedThreadPool(1);
//这里需要用 TtlExecutors.getTtlExecutorService 将原线程池包装下
executorService = TtlExecutors.getTtlExecutorService(executorService);
// 主线程中设置 张三
userNameTtl.set("张三");
logger.info("userName:{}", userNameTtl.get());
//在线程池中通过 TransmittableThreadLocal 拿值,看看能否拿到 刚才放入的张三?
executorService.execute(() -> {
logger.info("第1次获取 userName:{}", userNameTtl.get());
});
TimeUnit.SECONDS.sleep(1);
//这里放入了李四
userNameTtl.set("李四");
logger.info("userName:{}", userNameTtl.get());
//在线程池中通过 TransmittableThreadLocal 拿值,看看能否拿到 刚才放入的李四?
executorService.execute(() -> {
//在线程池中通过 inheritableThreadLocal 拿值,看看能否拿到?
logger.info("第2次获取 userName:{}", userNameTtl.get());
});
TimeUnit.SECONDS.sleep(1);
}
d.执行输出
20:02:28 [main] transmittableThreadLocal1 - userName:张三
20:02:28 [pool-1-thread-1] lambda$transmittableThreadLocal1$6 - 第1次获取 userName:张三
20:02:29 [main] transmittableThreadLocal1 - userName:李四
20:02:29 [pool-1-thread-1] lambda$transmittableThreadLocal1$7 - 第2次获取 userName:李四
2.9 通过AOP统一打印请求链路日志
01.思考一个问题:当一个接口报错的时候,如何能够快速定位问题?
如果能够满足下面这些条件,咱们就可以快速定位错误
1.能够快速找到接口的详细调用日志
2.日志中最好知道出错的是哪个接口的哪个方法,即哪个controller的哪个方法
3.日志中最好有接口的入参、返参
4.日志中含有异常的详细堆栈信息(即:哪行代码报的错)
02.代码实战
a.启动案例
com.itsoku.lesson019.Lesson019Application
b.访问一个正常的接口
http://localhost:8080/userAdd?userName=路人&age=35&password=123456
c.先看下接口的返回值,里面有个traceId
{
"success": true,
"data": true,
"msg": null,
"code": null,
"traceId": "b910649f02514cae8b015a862c7f6dca"
}
d.拿着这个traceId的值,可以找到这个请求完整的日志
看后端控制台,通过traceId的值去检索
如下,可以看到接口的详细执行日志
包含(接口url、开始时间、结束时间、及处理这个请求的controller和方法、还有方法的入参、返回值,都输出了)
前端给我们这个traceId,我们便可以快速定位到这个请求的完整调用日志
e.再来看请求一个异常的接口,浏览器中打开下面地址
http://localhost:8080/login?name=张三
f.浏览器中显示如下,可以看出接口报错了
{
"success": false,
"data": null,
"msg": "用户名无效",
"code": null,
"traceId": "a3b2d88c85134e5dad4d3d7ccd8cd892"
}
g.可以拿着上面的traceId的值,去后端控制台找对应的日志
[traceId:9e0dcfad49064c99a5913b3bec61cfaa] 请求start:http://localhost:8080/loqin
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] 接口方法:com.itsoku.lesson019.controller.UserController.login
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] 方法参数列表:{"name":"张三"}
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] 方法返回值:nutl
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] 请求:http://Localhost:8080/Loqin,发生异常:用户名无效
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] com.itsoku.lesson019.common.BusinessExceptionCreatebreakpoint:用户名无效
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] at com.itsoku.lesson019.common.BusinessExceptionUtils.businessException(BusinessExceptionUtils.iava:16)
[traceId:a3b2d88c85134e5dad4d3d7ccd8cd892] 请求end:http://Localhost:8080/Loqin,耗时(ms):3
03.源码解析
a.ControllerLogAspect
打印接口的详细日志
b.TraceFilter
生成唯一的traceId,日志中会输出这个tracId
c.ResultTraceIdAspect
将traceId统一丢到响应结果Result类的traceId字段中
2.10 大批量任务处理常见方案
00.开头说的还有一些需求我们没有考虑到
a.收益不能重复发送,这个如何解决?
也就是发送的逻辑需要幂等,对谁做幂等?(userId+当天的日期),即每个用户当天不能重发幂等的解决方案
b.对于每天发放的结果需要进行汇报(发放人数、成功人数、失败人数、还未发放的人数),这个如何搞呢?
可以创建一张收益发放记录表(t_user_profit),字段如下,通过这个表就可以统计到上面要的信息
userId:用户id
day:发放日期,格式:YYYYMMDD,比如:20240414
status:状态,0:未发放,1:已发放,2:发放失败
fail_reason:发放失败的原因
create_time:创建时间
c.那这个表如何使用呢?
在job中分发MQ消息的时候,同时向这个表中插入对应的记录,也就是每天要写入1亿条记录,这个地方可能有性能瓶颈,建议压测下
如果感觉太慢,可以分表,按天分表,每天一张表,这样这个表就只有一个亿的数据了
如果还是感觉慢,分表字段可以使用:日期+userId,每个日期开100个表,然后根据userId再进行路由
d.发放逻辑中需要调整下
1.收益发放成功修改这条记录的状态
2.收益发放失败也需要修改状态,并记录失败原因
e.发放逻辑可以考虑失败做一些重试
发放的逻辑中,对于失败的情况,可以稍微休眠会,然后重试,比如重试3次,这样可最大程度使其成功
f.提供一个运营后台
最好能够提供一个后台,看到每天发放的情况,如(发放人数、成功人数、失败人数、还未发放的人数、总金额等)
对于发放失败的,支持手动点击按钮进行重试
01.场景
假如余额宝每天发放收益的功能让咱们来实现,用户量有1个亿,每天早上9点之前需要将发放完毕,咱们会采用什么方案呢?
下面我们会采用2种方法来实现,以后遇到同类问题的时候,大家可以作为参考
02.需求分析
1.这用户量相当大,有1个亿
2.当天的收益要在 9 点之前发放完毕,也就是说,如果从零点开始执行,中间有 9 个小时来处理这个业务
3.用户的收益不能出现重复发送的情况
4.对于每天发放的结果需要进行汇报(发放人数、成功人数、失败人数、还未发放的人数、总金额)
5.最好有个后台可以看到这些统计信息,并支持对失败的进行手动补偿
03.方案1:使用job+线程池去跑
a.原理
step1:拉取待处理的数据,比如拉取10000条记录
step2:交给线程池去去处理,比如线程池的大小是100
step3:等待step2中的批处理结束
step4:回到step1,继续拉取用户进行处理,如果step1中发现已经没有用户需要处理了,则直接退出。
b.这个方法有没有问题?
我们假设每次发放收益需要耗时1秒,我们来算一下,1亿用户跑完需要多久
1亿/100个线程/24小时/每小时是3600秒 = 100000000/100/24/3600 = 如下 ≈ 11.57 天左右。
这个结果完全是无法接受的,那么有些朋友说可以将100个线程开到1000个,但是这样也需要1.15天啊,也无法满足需求
有些同学说,可以将线程池开到1万个,那么就只需要0.115天了,大家可以试试,单台机器跑1万个线程,会是什么个情况,大多数机器都是扛不住的,即使能抗住,数据库也是扛不住的。
如果用户量比较少,比如100万以内的用户,用这种方式可以搞定。
c.有没有更好的办法?
一台机器搞不定这个问题,那么我们可以搞个100台机器,目前使用云来扩展机器还是很容易的。
如果换成100台机器来同时干这个事情,每个机器负责跑100万用户,这个问题就解决了。
但是如何让100台机器同时来干这个事情呢?看方案2
04.方案2:使用集群+MQ来解决
a.说明
需要有一台机器来分发任务,将1个亿的用户转换成1亿条消息丢到MQ中,然后下面有100台机器从MQ中拉取这些消息去消费
b.需要有个job来做任务分发
job从db中分多批拉出1亿用户,每个用户生成一条MQ消息,投递到MQ中,差不多1个亿的消息
如果这里感觉消息太多,那么一条消息中也可以放10个或者100个用户
这里投递MQ消息也可以使用线程池来进行投递,提升速度
c.MQ消费者集群
这里我们会将发放收益的服务,部署100个,每个服务中开100个消费者从MQ中拉取消息,相当于同时有10000个消费者同时消费消息
d.这种方式耗时多久?我们来估算下
1.发送1亿条消息,预估0.5小时
2.1亿条消息,交给1万个消费者,这样每个消费者消费1万个,每个耗时1秒,也就是1万秒 = 3小时左右,预计耗时 3.5 个小时,达到了预期
3 part02
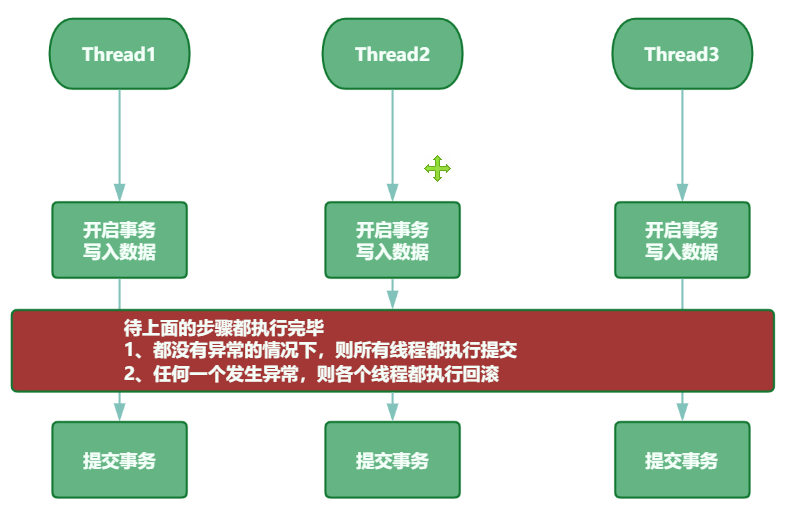
3.1 判断代码在并发情况下会否安全
00.背景
a.说明
1.比如我们写了个扣库存的方法,怎么知道此方法在并发情况下,是否会超卖?
2.或者其他一些类似的业务操作,怎么知道他们在并发的情况下,有没有问题?
这种问题统称为:在并发情况下,如何确定咱们的代码是否和预期的一致
b.常用的方法
并发压测,但是有些情况可能不一定好测试
c.那么我们没有更简单的方法可以验证呢?
本文给大家介绍一种我自己用过的,感觉还不错
下面通过2个案例,让大家看下这种方法怎么使用
01.案例1:下面来看一个减库存的操作
a.商品表(t_goods)
字段 类型 说明
goodsId int 商品id
stock int 库存
b.扣减库存代码
public class Goods{
//商品id
String goodsId;
//库存
Integer stock;
}
/**
* 扣减库存
* @param goodsId 商品id
* @param num 扣减的数量
*/
@Transaction(rollback=Exception.class)
public void reduceStock(String goodsId,int num){
//step1:根据商品id查询出商品信息
Goods goods = select goodsId, stock where t_goods where goodsId = #{goodsId};
//step2:扣减库存
goods.stock = goods.stock - num;
//step3:将商品信息保存到db
update t_goods set stock = #{goods.stock} where goodsId = #{goodsId};
}
c.验证
假设goodsId=1的商品库存是10,下面模拟2个线程同时对这个商品下单,购买的数量都是10
-----------------------------------------------------------------------------------------------------
时间点 步骤 thread1 thread2
T1 入参:(goodsId:1,num:10) 入参:(goodsId:1,num:10)
T2 step1 goodsId:1,stock:10 goodsId:1,stock:10
T3 step2 goods.stock = 10-10 = 0 goods.stock = 10-10 = 0
T4 step3 update t_goods set stock = 0 where goodsId = 1; update t_goods set stock = 0 where goodsId = 1;
T5 更新成功,库存变成0了 更新成功,库存变成0了
-----------------------------------------------------------------------------------------------------
这样最后两个线程都下单成功了,原本库存是10,但是2个线程共买了20件商品,超卖了
02.案例2:调整扣减库存的代码
a.代码
/**
* 扣减库存
* @param goodsId 商品id
* @param num 扣减的数量
*/
@Transaction(rollback=Exception.class)
public void reduceStock(String goodsId,int num){
//step1:通过sql扣减库存,where中加了个条件 stock-#{num}>=0
int upCount = (update t_goods
set stock = stock - #{num}
where
goodsId = #{goodsId}
and stock-#{num}>=0);
//step2
if(upCount==1){
//扣减库存成功,执行后续业务代码
}else{
//扣减库存失败,抛出异常,让事务回滚
throw new RuntimeException("库存不足,下单失败");
}
}
b.验证
同样,也是模拟2个线程对商品1同时下单,购买数量都是10
时间点 步骤 thread1 thread2
T1 入参:(goodsId:1,num:10) 入参:(goodsId:1,num:10)
T2 spring开启db事务 spring开启db事务
T3 step1 intupCount=(update t_goods int upCount = (update t_goods
setstock= stock-10 set stock = stock - 10
where where
goodsld = 1 goodsId = 1
and stock-10>=0 and stock-10>=0
T4 step2 upCount = 1 upCount = 0
扣减库存成功 throw new RuntimeException("库存不足,下单失败");
T5 spring提交事务 spring回滚事务
3.2 MySql和Redis数据一致性
00.背景
假如我们有个电商系统,为了提升商品详情页访问速度,我们使用redis来缓存商品信息,提升效率
获取商品信息,先从redis中获取,如果没有,则从db中获取后丢到redis,然后返回
而后台又可以修改商品的信息,这时如何确保redis和缓存数据一致呢?
即:如何确保通过商品详情接口返回的数据和db中的数据是一致的?
01.方案1
a.准备一张表:商品表(t_goods)
字段 类型 说明
goodsId int 商品id
stock int 库存
b.获取商品详情接口逻辑
step1:先从redis中获取,若能获取到,则直接返回,若没有继续向下
step2:从db中获取出商品信息
step3:放入redis
step4:返回商品信息
c.后台更新商品逻辑
step1:更新商品到db
step2:删除redis中的对应的商品记录
d.预期
预期并发情况下,数据库中和redis中的数据应该是一致的,即看到的商品信息应该是一致的
比如db中库存是10,那么通过商品详情接口获取到的一定也是10
e.验证
下面咱们来验证下,并发情况下,是否能够达到预期
假如现在商品1的库存是10,下面模拟3个线程同时对商品1进行操作
-----------------------------------------------------------------------------------------------------
时间点 thread1(执行更新商品) thread2(调用获取商品信息接口) thread3(调用获取商品信息接口)
T1 step1:从redis中发现没有商品
T2 step2:从db中取出商品信息(goodsId:1,stock:10)
T3 step1:修改库存为0,此时db中商品信息:goodsId:1,stock:0)
T4 step2:删除redis中商品1的记录
T5 step3:将数据写入redis(goodsId:1,stock:10)
T6 step4:返回商品信息(goodsId:1,stock:10)
T7 step1:从redis获取商品信息,此时缓存中有数据
T8 step2:返回商品信息(goodId:1,stock:10)
-----------------------------------------------------------------------------------------------------
此时db中的数据和redis的数据并不是一致的
02.方案2
a.如何解决这个问题
这个问题,大家应该看到很多相关的文章,比如提到的双删
双删可以最大限度的解决这个问题,但是极端情况下没有解决这个问题
还有根据binlog更新缓存、通过MQ更新缓存,但是binlog的日志、mq的日志还未消费的这个时间段内
通过详情接口获取的数据可能和db中是不一致的,短暂的不一致,如果可以接受短暂的不一致,可以使用这两种方法
b.解决
下面给大家介绍一种可以实现强一致的方案,让详情接口返回的数据和db的商品数据是强一致的
-----------------------------------------------------------------------------------------------------
先分析下,导致这个不一致的原因,定位原因,解决方案就容易了。
如下图,主要是下图红框中的2个部分出现了并行导致的,如果让他们排队执行,这个问题是不是就化解了?
-----------------------------------------------------------------------------------------------------
时间点 thread1(执行更新商品) thread2(调用获取商品信息接口) thread3(调用获取商品信息接口)
T1 step1:从redis中发现没有商品
T2 step2:从db中取出商品信息(goodsId:1,stock:10)
T3 step1:修改库存为0,此时db中商品信息:goodsId:1,stock:0)
T4 step2:删除redis中商品1的记录
T5 step3:将数据写入redis(goodsId:1,stock:10)
T6 step4:返回商品信息(goodsId:1,stock:10)
T7 step1:从redis获取商品信息,此时缓存中有数据
T8 step2:返回商品信息(goodId:1,stock:10)
c.如何让他们排队执行呢
加互斥锁,即其中一个在执行的时候,另一个需要等待,等前一个执行完毕之后,后一个才能执行
由于我们的系统是集群部署的,所以需要分布式锁,这里我们我们使用数据的锁来解决这个问题
下面带大家看下怎么实现的。
d.商品更新逻辑调整如下
大家先看下,重点在于step3,这里会对这条商品记录for update
如果有其他线程同样执行这个sql的时候,会等待,一直等待下面这个事务执行完毕才能继续
-----------------------------------------------------------------------------------------------------
step1:开启数据库事务
step2:更新商品信息到db
step3:select * from t_goods where t_goods = #{goodsId} for update;
step4:删除redis中的对应的商品记录
step5:提交数据库事务
e.获取商品信息的接口调整如下
这样如果商品信息在更新过程中,还没有提交事务的时候,此时如果有其他线程来获取商品信息
会走到获取商品信息接口的step3,这个地方会执行for update,会等待,等待商品更新的事务提交后,才能继续
-----------------------------------------------------------------------------------------------------
step1:通过商品id,从redis中查询商品信息,如果可以找到,直接返回,否则继续向下
step2:开启数据库事务
step3:获取商品信息,获取的sql:select * from t_goods where t_goods = #{goodsId} for update;
step4:将商品信息写入redis
step5:提交事务
3.3 数据脱敏优雅设计与实现
01.先带大家看下效果
a.接口代码
@RestController
public class TestController {
@GetMapping("/getUser")
public Result<User> getUser() {
User user = new User();
user.setId("001");
user.setName("路人");
user.setPhone("18612345678");
user.setEmail("[email protected] ");
user.setIdCard("420123432112121332");
user.setPassword("123456");
user.setAddress("上海市闵行区漕河泾开发区");
user.setBankCard("6226090211114567");
return ResultUtils.success(user);
}
}
b.访问接口输出如下,敏感信息自动按照某种格式脱敏了
{
"success": true,
"data": {
"id": "001",
"name": "路*",
"phone": "186****5678",
"email": "l********@163.com",
"idCard": "4***************32",
"password": "******",
"address": "上海市闵********",
"bankCard": "6226 **** **** 4567"
},
"msg": null,
"code": null
}
02.代码实战
a.思路
Controler方法的返回值,会被SpringBoot统一处理
其内部会使用jackson将对象序列化为json字符,然后由SpringBoot输出到客户端
所以,我们只需在jackson序列化这一步,将需要脱敏的数据统一处理就可以了
-----------------------------------------------------------------------------------------------------
我们可以自定义一个脱敏的注解,注解中指定脱敏的策略,这个策略其实就是一个字符串替换的函数
可以将这个注解标注在需要脱敏的字段上面
然后自定义一个脱敏的jackson序列化器,这个序列化器会对标注了脱敏注解的字段进行处理
会将注解上的脱敏策略取出来,使用脱敏策略对原字符串进行替换,然后输出替换后的字符串
b.代码
a.脱敏注解
如下,需要添加
@JacksonAnnotationsInside
@JsonSerialize(using = DesensitizationJsonSerializable.class)
-------------------------------------------------------------------------------------------------
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@JacksonAnnotationsInside
@JsonSerialize(using = DesensitizationJsonSerializable.class)
public @interface Desensitization {
/**
* 脱敏策略
*
* @return
*/
DesensitizationStrategy value();
}
b.脱敏策略
如下,脱敏策略就是一个字符串替换函数,参数就是原本的字符串,返回值是脱敏后的字符串
下面默认定义了 7 种,这里脱敏方法,使用到了hutool中自带的工具,这个工具内部已经提供了场景的一些数据脱敏的函数
如果感觉不够用,也可以自己拓展。
-------------------------------------------------------------------------------------------------
public enum DesensitizationStrategy {
// 手机号脱敏策略,保留前三位和后四位
PHONE(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.MOBILE_PHONE)),
// 邮箱脱敏策略,保留邮箱用户名第一个字符和@符号前后部分
EMAIL(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.EMAIL)),
// 身份证号脱敏策略,保留前四位和后四位
ID_CARD(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.ID_CARD)),
// 地址脱敏策略,保留省市信息,其余部分脱敏为**
ADDRESS(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.ADDRESS)),
// 银行卡号脱敏策略,保留前四位和后三位
BANK_CARD(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.BANK_CARD)),
// 姓名脱敏策略,保留姓氏第一个字符,其余部分脱敏为**
NAME(s -> DesensitizedUtil.desensitized(s, DesensitizedUtil.DesensitizedType.CHINESE_NAME)),
// 密码脱敏策略,统一显示为******
PASSWORD(s -> "******");
private final Function<String, String> desensitization;
DesensitizationStrategy(Function<String, String> desensitization) {
this.desensitization = desensitization;
}
public Function<String, String> getDesensitization() {
return desensitization;
}
}
c.jackson脱敏序列化器
public class DesensitizationJsonSerializable extends JsonSerializer<String> implements ContextualSerializer {
//脱敏策略
private DesensitizationStrategy desensitizationStrategy;
@Override
public void serialize(String s, JsonGenerator gen, SerializerProvider serializers) throws IOException {
// 使用脱敏策略将字符串处理后序列化到json中
gen.writeString(desensitizationStrategy.getDesensitization().apply(s));
}
@Override
public JsonSerializer<?> createContextual(SerializerProvider prov, BeanProperty property) throws JsonMappingException {
// 获取属性上的 Desensitization 注解
Desensitization annotation = property.getAnnotation(Desensitization.class);
// 注解不为空 && 属性类型必须是字符串类型
if (Objects.nonNull(annotation) && Objects.equals(String.class, property.getType().getRawClass())) {
//设置脱敏策略
this.desensitizationStrategy = annotation.value();
return this;
}
// 返回默认的序列化器
return prov.findValueSerializer(property.getType(), property);
}
}
d.使用
public class User {
// id
private String id;
// 姓名
@Desensitization(DesensitizationStrategy.NAME)
private String name;
// 手机号
@Desensitization(DesensitizationStrategy.PHONE)
private String phone;
// 邮箱
@Desensitization(DesensitizationStrategy.EMAIL)
private String email;
// 银行卡
@Desensitization(DesensitizationStrategy.ID_CARD)
private String idCard;
// 密码
@Desensitization(DesensitizationStrategy.PASSWORD)
private String password;
// 地址
@Desensitization(DesensitizationStrategy.ADDRESS)
private String address;
@Desensitization(DesensitizationStrategy.BANK_CARD)
private String backCard;
//getter setter方法省略...
}
3.4 一行代码搞定系统操作日志
01.思路
a.说明
通过aop统一记录系统操作日志,只需在接口方法上加个自定义的注解,不论接口成功还是失败,都可自动记录操作日志到db中
b.操作日志包含的信息有
日志描述
状态,0:异常,1:正常
请求参数json格式
响应结果json格式
错误信息(状态=0时,记录异常堆栈信息)
接口耗时(毫秒)
操作ip地址
操作ip地址归属地
操作人用户名
操作时间
c.涉及到的技术
SpringBoot 2.7.13
MyBatis Plus
MySQL
ip2region:准确率99.9%的离线IP地址定位库,用于获取ip归属地
02.效果
a.启动应用
com.itsoku.lesson024.Lesson024Application
b.接口代码
com.itsoku.lesson024.controller.UserController
c.测试用例代码
UserController.http
03.源码解析
a.操作日志表
create table if not exists t_oper_log_lesson024
(
id varchar(50) primary key comment 'id,主键',
log varchar(500) not null comment '操作日志',
status smallint not null default 1 comment '状态,0:异常,1:正常',
param_json text comment '请求参数json',
result_json text comment '响应结果json',
error_msg text comment '错误信息(status=0时,记录错误信息)',
cost_time long comment '耗时(毫秒)',
oper_ip varchar(50) comment '操作ip地址',
oper_ip_address varchar(50) comment '操作ip地址归属地',
oper_user_name varchar(50) comment '操作人用户名',
oper_time datetime comment '操作时间'
) comment '操作日志表';
b.自定义注解
用于标注在Controller中需要记录操作日志的方法上
-----------------------------------------------------------------------------------------------------
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface OperLog {
//日志内容
String log();
}
c.记录日志切面类
使用环绕通知,会拦截所有controller中标注有@OperLog注解的方法,会对这些方法记录日志,不管方法是成功还是失败都会记录
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson024.log.OperLogAspect
d.如何使用
接口上标注@OprLog就可以了
-----------------------------------------------------------------------------------------------------
@PostMapping("/add")
@OperLog(log = "用户管理-新增用户")
public Result<String> add(@Validated @RequestBody UserAddRequest req) {
return ResultUtils.success(this.userService.add(req));
}
04.技术点
a.操作日志中如何获取到操作人用户名的?
a.说明
咱们定义了一个接口,接口中有2个方法,一个用户设置用户名,一个用于获取用户名
b.代码
public interface IUserNameProvider {
/**
* 获取用户名
*
* @return
*/
String getUserName();
/**
* 设置用户名
*
* @param userName
*/
void setUserName(String userName);
}
c.说明
这个接口有个默认实现,是将用户名放在ThreadLocal中,大家可以根据自己的项目情况,去自己实现一个IUserNameProvider
d.代码
@Component
public class ThreadLocalUserNameProvider implements IUserNameProvider {
private ThreadLocal<String> userNameTl = new ThreadLocal<>();
@Override
public String getUserName() {
return this.userNameTl.get();
}
@Override
public void setUserName(String userName) {
this.userNameTl.set(userName);
}
}
e.说明
那么这个用户名什么时候放进去的呢?代码如下,咱们搞了个拦截器,拦截请求
从请求中我们可以想办法拿到用户名,然后将其塞到IUserNameProvider中,这样记录操作日志的aop中
就可以通过IUserNameProvider获取到了
f.代码
@Component
public class UserNameInterceptor implements HandlerInterceptor {
@Autowired
private IUserNameProvider userNameProvider;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//这里从请求中得到用户名,然后塞到userNameProvider中
String userName = "路人";
this.userNameProvider.setUserName(userName);
return HandlerInterceptor.super.preHandle(request, response, handler);
}
}
b.ip地址如何获取的?
a.说明
这里我们提供了一个工具类,可以通过请求拿到ip,具体代码在下面这个位置
b.代码
com.itsoku.lesson024.ip.IpUtils#getIpAddr()
c.ip归属地如何获取的?
a.说明
对应的方法在下面这个位置,传入ip,可以获取到ip对应的归属地
com.itsoku.lesson024.ip.IpAddressUtils#getRegion
b.ip2region,准确率99.9%的离线IP地址定位库
https://gitee.com/lionsoul/ip2region
3.5 使用AOP简化MyBatis分页功能
00.思路
a.说明
PageHelper实现MyBatis分页
使用AOP简化MyBatis分页
b.技术
SpringBoot 2.7.13
MyBatis
PageHelper:一个很好用的 MyBatis 分页工具
AOP环绕通知
01.案例1:PageHelper实现Mybatis分页
a.PageHelper原理
使用Mybatis的拦截器,对sql进行改写,进而实现分页功能
b.使用
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.7</version>
</dependency>
c.配置
pagehelper:
helper-dialect: mysql # 数据方言
d.分页查询
//开启分页
PageHelper.startPage(pageNum, pageSize, true);
try {
//Mapper接口中任意查询,返回List的方法
} finally {
//清理分页信息
PageHelper.clearPage();
}
e.案例代码
com.itsoku.lesson025.service.UserService#selectPage
public PageResult<UserPO> selectPage(int pageNum, int pageSize) {
//开启分页
PageHelper.startPage(pageNum, pageSize, true);
try {
List<UserPO> users = this.userMapper.selectPage();
return PageResult.of(users);
} finally {
//清理分页信息
PageHelper.clearPage();
}
}
f.测试用例
http://localhost:8080/user/selectPage?pageNum=2&pageSize=10
g.存在问题
a.说明
上面的案例有个问题,代码如下,就是每次写的时候,都需要PageHelper.startPage,结束的时候,需要PageHelper.clearPage
b.代码
//开启分页
PageHelper.startPage(pageNum, pageSize, true);
try {
//调用mapper中的方法分页查询数据
} finally {
//清理分页信息
PageHelper.clearPage();
}
c.如何解决这个问题?
我们可以通过aop搞个环绕通知,将这部分公共的代码丢到aop中,这样,就可以大大简化这个操作
下面的案例2,将实现这个套方案
02.案例2:使用AOP简化案例1中的分页
a.原理
com.itsoku.lesson025.service.UserService#selectPageNew
b.测试用例地址
http://localhost:8080/user/selectPageNew?pageNum=1&pageSize=10
c.IPageQuery:分页顶层接口
我们定义了一个分页的顶层接口,如下,有3个方法,用于获取分页信息
当我们mapper中的方法中有这个类型的参数的时候,就会被aop统一处理,进行分页
-----------------------------------------------------------------------------------------------------
public interface IPageQuery {
/**
* 页码
*
* @return
*/
int getPageNum();
/**
* 每页大小
*
* @return
*/
int getPageSize();
/**
* 是否需要分页
*
* @return
*/
boolean count();
}
d.PageQuery:IPageQuery默认实现
public class PageQuery implements IPageQuery {
private int pageNum = 1;
private int pageSize = 10;
private boolean count = true;
/**
* 获取分页请求参数
*
* @param pageNum 页码
* @param pageSize 每页大小
* @param count 是否需要分页
* @return
*/
public static PageQuery of(int pageNum, int pageSize, boolean count) {
return new PageQuery(pageNum, pageSize, count);
}
}
e.IPageQuery这个接口如何使用呢?
咱们的Mapper接口中需要分页的方法,方法的参数中,有任意一个参数是 IPageQuery 类型
那么这个方便自动拥有了分页功能,这个是通过aop实现的,稍后会介绍这块aop的代码
比如下面这个方法,第一个参数是 IPageQuery 类型,那么这个方法就自动拥有了分页功能
-----------------------------------------------------------------------------------------------------
@Select("select id,name from t_user_lesson025 order by id asc")
List<UserPO> selectPageNew(IPageQuery pageQuery);
f.原理:通过AOP统一处理IPageQuery参数,进行分页
通过AOP统一处理IPageQuery参数,实现分页功能,如下我们搞了个环绕通知,会拦截Mapper中的所有方法
判断方法的参数是否有IPageQuery类型参数,如果有,则从 IPageQuery 中拿到分页的信息
然后调用 PageHelper.startPage 开启分页,方法执行完毕之后,然后调用 PageHelper.clearPage 清理分页
-----------------------------------------------------------------------------------------------------
@Aspect
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class PageQueryAspect {
/**
* 拦截mapper中的素有方法
*
* @param pjp
* @return
* @throws Throwable
*/
@Around("execution(* com.itsoku..*Mapper.*(..))")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
boolean pageFlag = false;
try {
//遍历参数,参数中如果有 IPageQuery 类型的,则从 IPageQuery 取出分页信息,则使用 PageHelper 开启分页
Object[] args = pjp.getArgs();
for (Object arg : args) {
if (arg instanceof IPageQuery) {
IPageQuery pageQuery = (IPageQuery) arg;
PageHelper.startPage(pageQuery.getPageNum(), pageQuery.getPageSize(), pageQuery.count());
pageFlag = true;
break;
}
}
return pjp.proceed();
} finally {
if (pageFlag) {
//清理分页信息
PageHelper.clearPage();
}
}
}
}
03.案例3:案例2拓展实战
a.说明
分页查询用户信息,支持根据关键字模糊检索用户名
com.itsoku.lesson025.service.UserService#userPage
b.测试
检索用户名中包含路人的用户列表,浏览器中访问
http://localhost:8080/user/userPage?pageNum=1&pageSize=10&keyword=路人
3.6 ThreadLocal线程池的坑
00.思路
a.说明
演示 ThreadLocal 遇到线程池出现的故障
演示 InheritableThreadLocal 遇到线程池出现的故障
通过自定义线程池解决这些问题,也是通用的一个方案,大家一定要掌握
b.技术
ThreadLocal:当前线程数据共享的一个工具类,java中自带的
InheritableThreadLocal:父子线程数据共享的一个工具类,java中自带的
自定义线程池
01.案例1:测试 ThreadLocal 遇到线程池会怎么样?
a.代码
/**
* 1、测试 ThreadLocal 遇到线程池会怎么样?
*
* @throws InterruptedException
*/
@Test
public void threadLocalTest() throws InterruptedException {
//1、创建一个ThreadLocal,用来存放用户名
ThreadLocal<String> userNameTl = new ThreadLocal<>();
//2、当前线程,即主线程中,放入用户名:路人
userNameTl.set("路人");
//3、在当前线程中从ThreadLocal获取用户名
this.log(userNameTl.get());
//4、创建大小为2的线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
//5、循环5次,通过线程池去执行任务,任务中去从 userNameTl 获取用户名,看看是否可以获取到?
for (int i = 0; i < 5; i++) {
executorService.execute(() -> {
String userName = userNameTl.get();
this.log(userName);
});
}
//关闭线程池,并等待结束
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.MINUTES);
}
private void log(String s) {
System.out.println(Thread.currentThread().getName() + ":" + s);
}
b.运行输出
main:路人
pool-1-thread-1:null
pool-1-thread-2:null
pool-1-thread-2:null
pool-1-thread-2:null
pool-1-thread-2:null
c.结论
ThreadLocal 只能在当前线程共享数据, 在线程池中无法获取到外面线程中ThreadLocal中的数据
d.疑问?
InheritableThreadLocal 可以实现父子线程共享数据,他能解决这个问题么?看案例2
02.案例2:测试 InheritableThreadLocal 遇到线程池会怎么样?
a.代码
/**
* 2、测试 InheritableThreadLocal 遇到线程池会怎么样?
*
* @throws InterruptedException
*/
@Test
public void InheritableThreadLocalTest() throws InterruptedException {
//1、创建一个InheritableThreadLocal,用来存放用户名
InheritableThreadLocal<String> userNameItl = new InheritableThreadLocal<>();
//2、创建大小为2的线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
//3、循环5次,通过线程池去执行任务,执行任务之前会生成一个用户名放入 userNameItl,然后在线程池中的任务中,将用户再取出来,看看和外面丢进去的是不是一样的?
for (int i = 0; i < 5; i++) {
//主线程中用户名,丢到userNameItl中
String mainThreadUserName = "路人-" + i;
userNameItl.set(mainThreadUserName);
executorService.execute(() -> {
//线程池中获取用户名
String threadPoolThreadUserName = userNameItl.get();
this.log(String.format("mainThreadUserName:" + mainThreadUserName + ",threadPoolThreadUserName:" + threadPoolThreadUserName));
});
TimeUnit.SECONDS.sleep(1);
}
//关闭线程池,并等待结束
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.MINUTES);
}
b.运行输出
大家重点关注:mainThreadUserName的值和threadPoolThreadUserName的值是否一致
从输出中可以看出,前2行是一样的,后面3行不一样了
-----------------------------------------------------------------------------------------------------
pool-1-thread-1:mainThreadUserName:路人-0,threadPoolThreadUserName:路人-0
pool-1-thread-2:mainThreadUserName:路人-1,threadPoolThreadUserName:路人-1
pool-1-thread-1:mainThreadUserName:路人-2,threadPoolThreadUserName:路人-0
pool-1-thread-2:mainThreadUserName:路人-3,threadPoolThreadUserName:路人-1
pool-1-thread-1:mainThreadUserName:路人-4,threadPoolThreadUserName:路人-0
c.原因
线程中的2个子线程是重复使用,他的父线程都是main线程,子线程创建的时候
会将父线程中InheritableThreadLocal中的数据复制到子线程中
后续父线程中InheritableThreadLocal的数据再变化的时候,对子线程是没有影响的,所以出现了上面的现象
d.结论
InheritableThreadLocal 也无法解决外面线程和线程池中线程数据共享的问题
03.案例3:自定义线程池解决这个问题
a.思路
我们可以通过自定义线程池解决,需要重写线程池的execute和submit方法
在线程池执行任务前,先将需要在线程池中共享的数据取出来,然后在执行任务的时候
再将这个数据塞到线程池执行任务的线程中就可以了
案例3将对这个方案进行落地
b.代码
/**
* 3、自定义线程池解决这个问题
*/
@Test
public void threadLocalTestNew() throws InterruptedException {
//1、创建一个ThreadLocal,用来存放用户名
ThreadLocal<String> userNameTl = new ThreadLocal<>();
//2、创建大小为2的线程池,大家先不用过度关注这块代码,稍后会解释
ExecutorService executorService = new MyThreadPoolExecutor(new MyThreadPoolExecutor.ThreadLocalContext<String>() {
@Override
public String getContext() {
return userNameTl.get();
}
@Override
public void setContext(String userName) {
userNameTl.set(userName);
}
}, 2, 2, 5, TimeUnit.MINUTES, new LinkedBlockingQueue<>(100));
//3、循环5次,通过线程池去执行任务,执行任务之前会生成一个用户名放入 userNameTl,然后在线程池中的任务中,将用户再取出来,看看和外面丢进去的是不是一样的?
for (int i = 0; i < 5; i++) {
//主线程中用户名,丢到userNameTl中
String mainThreadUserName = "路人-" + i;
userNameTl.set(mainThreadUserName);
executorService.execute(() -> {
//线程池中获取用户名
String threadPoolThreadUserName = userNameTl.get();
this.log(String.format("mainThreadUserName:" + mainThreadUserName + ",threadPoolThreadUserName:" + threadPoolThreadUserName));
});
TimeUnit.SECONDS.sleep(1);
}
//关闭线程池,并等待结束
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.MINUTES);
}
c.运行输出
可以看下,mainThreadUserName和threadPoolThreadUserName的值都是一致的
说明当前这个案例解决了线程池共享外部ThreadLocal数据的问题
-----------------------------------------------------------------------------------------------------
pool-1-thread-1:mainThreadUserName:路人-0,threadPoolThreadUserName:路人-0
pool-1-thread-2:mainThreadUserName:路人-1,threadPoolThreadUserName:路人-1
pool-1-thread-1:mainThreadUserName:路人-2,threadPoolThreadUserName:路人-2
pool-1-thread-2:mainThreadUserName:路人-3,threadPoolThreadUserName:路人-3
pool-1-thread-1:mainThreadUserName:路人-4,threadPoolThreadUserName:路人-4
d.源码解析
import java.util.concurrent.*;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/4/24 13:27 <br>
* <b>author</b>:ready [email protected]
*/
public class MyThreadPoolExecutor extends ThreadPoolExecutor {
private ThreadLocalContext threadLocalContext;
public MyThreadPoolExecutor(ThreadLocalContext context, int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
this.threadLocalContext = context;
}
public MyThreadPoolExecutor(ThreadLocalContext context, int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
this.threadLocalContext = context;
}
@Override
public void execute(Runnable command) {
super.execute(this.new RunnableWrap(command));
}
@Override
public <T> Future<T> submit(Callable<T> task) {
return super.submit(task);
}
/**
* 线程本地变量上下文接口,用于解决线程池中共享外部线程ThreadLocal数据的问题
*
* @param <T>
*/
public interface ThreadLocalContext<T> {
/**
* 获取线程池中需要共享的上下文对象,将任务交给线程时会被调用
*
* @return
*/
T getContext();
/**
* 设置上下文,线程池中的线程执行任务的时候会调用
*
* @param context {@link #getContext()} 返回的对象
*/
void setContext(T context);
}
private class CallableWrap<V> implements Callable<V> {
private Callable<V> target;
private Object context;
public CallableWrap(Callable<V> target) {
this.target = target;
this.context = MyThreadPoolExecutor.this.threadLocalContext.getContext();
}
@Override
public V call() throws Exception {
MyThreadPoolExecutor.this.threadLocalContext.setContext(this.context);
return this.target.call();
}
}
private class RunnableWrap implements Runnable {
private Runnable target;
private Object context;
public RunnableWrap(Runnable target) {
this.target = target;
this.context = MyThreadPoolExecutor.this.threadLocalContext.getContext();
}
@Override
public void run() {
MyThreadPoolExecutor.this.threadLocalContext.setContext(this.context);
this.target.run();
}
}
}
e.扩展
SpringBoot中有个@Async注解,标注在方法上,可以让这个方法异步执行
如果刚好用到了ThreadLocal来共享数据,那么就可能碰到本文中的问题
比如:调用@Async标注的方法之前,向ThreadLocal中放入了数据
然后在@Async标注的方法中,通过ThreadLocal却取不到数据,这个时候大家应该知道如何解决了吧
3.7 读写分离实战
00.思路
a.说明
通过一个注解搞定读写分离
支持查询强制路由到主库
b.技术
SpringBoot 2.7.13
MyBatis
多数据源路由
AOP环绕通知
01.背景
大多数系统都是读多写少,为了降低数据库的压力,可以对主库创建多个从库
从库自动从主库同步数据,程序中将写的操作发送到主库,将读的操作发送到从库去执行
也可以强制读主库,这种可以解决,主从延迟的情况下,主库写入数据后立即查询从库,查询不到的问题
02.实现思路
a.可以定义一个读写分离的注解:@ReadWrite(value=路由策略),路由策略主要有下面3种
public enum ReadWriteRoutingStrategy {
MASTER, //路由到主库
SLAVE, //路由到从库
HIT_MASTER //强制路由到主库
}
b.@ReadWrite注解用于标注在service层需要做读写分离的方法上
若没有该注解,则自动路由到主库
c.通过Aop拦截@ReadWrite标注的方法,从@ReadWrite这个注解中取出读写策略,放到ThreadLocal中,如下
ThreadLocal<ReadWriteRoutingStrategy> readWriteRoutingStrategyThreadLocal = new ThreadLocal<>();
//从@ReadWrite注解中取出读写策略,放到ThreadLocal中
ReadWrite readWrite;
readWriteRoutingStrategyThreadLocal.set(readWrite.value());
d.需要一个有路由功能够的数据源,他里面需要有个targetDataSourcesMap,用于维护路由策略和真实数据源的映射关系,如下
//路由策略和数据源映射关系,放在一个map中(key:路由策略,value:对应的实际数据源)
Map<Object, Object> targetDataSourcesMap = new HashMap<>();
//主库路由配置
targetDataSourcesMap.put(ReadWriteRoutingStrategy.MASTER, 主库数据源);
//从库路由配置
targetDataSourcesMap.put(ReadWriteRoutingStrategy.SLAVE, 从库数据源);
//强制路由主库的配置
targetDataSourcesMap.put(ReadWriteRoutingStrategy.HIT_MASTER, 从库数据源);
e.操作数据库的时候
先从 readWriteRoutingStrategyThreadLocal.get() 中获取路由的策略
作为查找的key,然后从上面路由数据源的targetDataSourcesMap中找到实际的数据源,然后去执行db操作就可以了
03.先看下效果
a.创建主从库
下面准备2个数据库:javacode2018_master(主库)、javacode2018_slave(从库)
2个库中都创建一个t_user表,分别插入了一条用户数据,数据内容不一样,稍后用这个数据来验证走的是主库还是从库
-----------------------------------------------------------------------------------------------------
DROP DATABASE IF EXISTS javacode2018_master;
CREATE DATABASE IF NOT EXISTS javacode2018_master;
USE javacode2018_master;
DROP TABLE IF EXISTS t_user;
CREATE TABLE t_user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(256) NOT NULL DEFAULT ''
COMMENT '姓名'
);
INSERT INTO t_user (id, name) VALUE (1, 'master库');
DROP DATABASE IF EXISTS javacode2018_slave;
CREATE DATABASE IF NOT EXISTS javacode2018_slave;
USE javacode2018_slave;
DROP TABLE IF EXISTS t_user;
CREATE TABLE t_user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(256) NOT NULL DEFAULT ''
COMMENT '姓名'
);
INSERT INTO t_user (id, name) VALUE (1, 'slave库');
b.启动springboot应用
com.itsoku.lesson027.Lesson027Application
c.测试用例
这个案例会演示4种情况
1.没有标注@RreadWrite的方法,默认情况会走主库
2.标注有@ReadWrite(Master)会走主库
3.标注有@ReadWrite(Slave)会走从库
4.标注有@ReadWrite(Slave)的方法,可以通过硬编码,强制将其路由到主库
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson027.controller.UserController#test
d.浏览器中访问
http://localhost:8080/test
e.输出
{
"success": true,
"data": {
"user": {
"id": 1,
"name": "master库"
},
"userFromMaster": {
"id": 1,
"name": "master库"
},
"userFromSlave": {
"id": 1,
"name": "slave库"
},
"userHitMaster": {
"id": 1,
"name": "master库"
}
},
"msg": null,
"code": null
}
04.源码解析
a.@ReadWrite注解
标注在service上需要做读写分离的方法上
-----------------------------------------------------------------------------------------------------
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadWrite {
/**
* 获取路由策略(主库、从库、还是强制路由到主库?)
*
* @return
*/
ReadWriteRoutingStrategy value();
}
b.ReadWriteRoutingStrategy:读写路由策略类(3个策略)
public enum ReadWriteRoutingStrategy {
MASTER, //路由到主库
SLAVE, //路由到从库
HIT_MASTER //强制路由到主库
}
c.ReadWriteDataSource:读写分离的数据源
这是一个复合型的数据源,他继承了org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource
他里面会维护一个数据源的map,这个map的key就是路由的策略,value就是实际的数据源
里面还有个 determineCurrentLookupKey方法,如下 ,用于获取路由的策略,通过这个方法的返回值,就可以找到目标数据源
-----------------------------------------------------------------------------------------------------
public class ReadWriteDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
//这里我们从ThreadLocal中获取路由的策略
return ReadWriteRoutingStrategyHolder.getReadWriteRoutingStrategy();
}
}
d.ReadWriteRoutingStrategyHolder:使用ThreadLocal记录当前读写路由策略
public class ReadWriteRoutingStrategyHolder {
private static ThreadLocal<ReadWriteRoutingStrategy> readWriteRoutingStrategyThreadLocal = new ThreadLocal<>();
public static void setReadWriteRoutingStrategy(ReadWriteRoutingStrategy readWriteRoutingStrategy) {
readWriteRoutingStrategyThreadLocal.set(readWriteRoutingStrategy);
}
/**
* 路由到主库
*/
public static void master() {
setReadWriteRoutingStrategy(ReadWriteRoutingStrategy.MASTER);
}
/**
* 路由到从库
*/
public static void slave() {
setReadWriteRoutingStrategy(ReadWriteRoutingStrategy.SLAVE);
}
/**
* 强制走主库执行 execute的代码
*
* @param execute
* @param <T>
* @return
*/
public static <T> T hitMaster(Supplier<T> execute) {
ReadWriteRoutingStrategy old = getReadWriteRoutingStrategy();
try {
setReadWriteRoutingStrategy(ReadWriteRoutingStrategy.HIT_MASTER);
return execute.get();
} finally {
readWriteRoutingStrategyThreadLocal.set(old);
}
}
/**
* 获取读写策略
*
* @return
*/
public static ReadWriteRoutingStrategy getReadWriteRoutingStrategy() {
return readWriteRoutingStrategyThreadLocal.get();
}
}
e.ReadWriteAspect:AOP环绕通知
拦截所有标注有 @ReadWrite注解的方法,从这个注解中取出读写策略
将读写策略放到上面ReadWriteRoutingStrategyHolder中的readWriteRoutingStrategyThreadLocal中
-----------------------------------------------------------------------------------------------------
@Aspect
public class ReadWriteAspect {
/**
* 环绕通知,拦截所有方法上标注有 @ReadWrite注解的方法
*
* @param joinPoint
* @param readWrite
* @return
* @throws Throwable
*/
@Around("@annotation(readWrite)")
public Object around(ProceedingJoinPoint joinPoint, ReadWrite readWrite) throws Throwable {
//从ThreadLocal中获取读写策略
ReadWriteRoutingStrategy readWriteRoutingStrategy = ReadWriteRoutingStrategyHolder.getReadWriteRoutingStrategy();
// 若选择了强制路由到主库,则执行执行业务
if (readWriteRoutingStrategy == ReadWriteRoutingStrategy.HIT_MASTER) {
return joinPoint.proceed();
}
// 否则,从@ReadWrite注解中获取读写策略,放到ThreadLocal中,然后去执行业务
ReadWriteRoutingStrategyHolder.setReadWriteRoutingStrategy(readWrite.value());
return joinPoint.proceed();
}
}
f.ReadWriteConfiguration:读写分离Spring配置类
定义读写分离需要用到的bean,重点关注数据源的配置。
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson027.ds.ReadWriteConfiguration
g.使用
在需要做读写分离的方法上标注@ReadWrite注解,并通过其value属性指定路由策略,是走主库还是从库
-----------------------------------------------------------------------------------------------------
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
/**
* 从主库获取用户
*
* @return
*/
@ReadWrite(ReadWriteRoutingStrategy.MASTER)
public UserPO getUserFromMaster() {
return this.userMapper.getUser(1);
}
/**
* 从库获取用户
*
* @return
*/
@ReadWrite(ReadWriteRoutingStrategy.SLAVE)
public UserPO getUserFromSlave() {
return this.userMapper.getUser(1);
}
}
05.其他问题
a.不加@ReadWrite注解会怎么样?
通过ReadWriteDataSource.setDefaultTargetDataSource方法设置兜底的数据源
如下,这里用主数据源进行兜底,也就是说没有路由策略或者根据路由策略找不到对应的数据源时
就会用setDefaultTargetDataSource指定的这个数据源进行兜底
-----------------------------------------------------------------------------------------------------
//创建我们自定义的路由数据源
ReadWriteDataSource readWriteDataSource = new ReadWriteDataSource();
//设置默认兜底的数据源
readWriteDataSource.setDefaultTargetDataSource(this.masterDataSource());
b.强制走主库如何使用?
为什么需要强制走主库?
由于主从同步需要一个时间,数据写入主库后,立即去读从库,此时若数据还未同步到从库,会导致读取不到的问题
这个时候可以强制走主库查询解决这个问题
-----------------------------------------------------------------------------------------------------
使用下面这个方法,传入需要执行的查询逻辑,便可强制走主库查询
com.itsoku.lesson027.ds.ReadWriteRoutingStrategyHolder#hitMaster(Supplier<T> execute)
3.8 MQ使用场景
01.异步解耦
a.描述:异步处理
之前单个任务的响应时间为同步操作时间和执行时间之和
将任务拆分为两部分后,可以显著减少平均响应时间
b.方式
一个任务由多个子任务构成,且某个子任务完成时需要异步通知其他子任务执行
将任务队列中的子任务按顺序处理,可以避免长时间等待
通过MQ可以实现任务的异步解耦和处理
02.流量削峰
a.描述:流量控制
在高峰期,流量可能会超出系统处理能力
使用MQ可以将流量削峰,将请求暂时存储,稍后再处理
b.方法
将请求放入MQ中,系统以较稳定的速度消费请求
03.延迟消息
a.描述:消息延迟处理
需要在指定时间后执行某个任务
MQ可以实现消息的定时或延迟发送
b.方法
通过设置消息的延迟属性,可以控制消息的发送时间
04.分布式事务
a.描述:跨系统一致性
分布式系统中,事务的执行需要保证数据一致性
b.方法
使用MQ作为事务协调者,确保消息在所有子系统中的一致性
05.日志收集
a.描述:日志处理
在分布式系统中,日志收集和分析是常见需求
b.方法
将日志信息通过MQ进行集中收集和处理
06.任务分发模型1:实现负载均衡和故障恢复
a.描述:任务分发与调度
MQ可以实现任务的均匀分发,支持负载均衡
任务队列中可以保存任务状态,支持任务的恢复
b.方法
通过监控任务的执行状态,实现故障恢复和重新分发
07.任务分发模型2:实现一个简单的Job服务
a.描述:Job服务实现
通过MQ实现Job的创建、调度和执行
b.方法
定义Job的结构,包括任务ID、任务内容、执行状态等
使用MQ管理Job的调度和执行过程
3.9 MQ确保消息的可靠性
00.汇总
a.整个过程中消息可靠性需要考虑3个问题
1.如何确保生产者这边业务执行成功,消息一定会投递到MQ?
2.如何确保消息到达MQ后,MQ这边不会丢失?
3.如何确保消费者一定能消费到这条消息?
b.如何确保生产者这边业务执行成功,消息一定投递成功?
这块涉及到消息投递的整个过程,下面咱们来通过一个案例来了解消息投递的整个过程
以及在这个过程中,如何确保业务执行成功,消息一定会投递成功
c.电商中有这样的一个场景
下单成功之后送积分的操作,我们使用mq来实现
下单成功之后,投递一条消息到mq,积分系统消费消息,给用户增加积分
下面会介绍4种方式,来看下这个业务中消息投递的一个过程
这些方案,面试的时候,如果你能够说出来,会让面试官对你刮目先看
01.消息投递方式一:业务事务中投递消息
a.正常流程
step1:开启本地事务
step2:生成购物订单
step3:投递消息到mq
step4:提交本地事务
-----------------------------------------------------------------------------------------------------
这种方式是将发送消息放在了事务提交之前
b.异常情况
step3发生异常:导致step4失败,商品下单失败,直接影响到商品下单业务
step4发生异常,其他step成功:商品下单失败,消息投递成功,给用户增加了积分
02.消息投递方式二:业务事务提交后、后投递消息
a.正常流程
step1:开启本地事务
step2:生成购物订单
step3:提交本地事务
step4:投递消息到mq
b.异常情况
step4发生异常,其他step成功:导致商品下单成功,投递消息失败,用户未增加积分
上面两种是比较常见的做法,也是最容易出错的
03.消息投递方式三:事务消息(二阶段投递)
a.需要再本地业务库添加一张本地消息表(t_msg_record)
id
body:消息体
status:消息状态:0:待投递,1:投递成功,2:投递失败
b.正常流程
step1:开启本地事务
step2:生成购物订单
step3:本地库中插入一条需要发送消息的记录t_msg_record,status为0(待投递)
step4:提交本地事务
step5:若事务提交成功,则投递消息到MQ,然后将t_msg_record中的status置为1(投递成功);若本地事务提交失败,则将t_msg_record表中的消息记录删掉
c.说明
这种方式借助了数据库的事务,业务和消息记录作为了一个原子操作,业务成功之后,消息记录必定是存在的
d.异常情况
若step4成功,step5失败了,会导致业务执行成功,而消息投递失败,此时我们需要有个job对待发送的消息进行补偿投递
e.消息投递补偿job
这个job负责从本地t_msg_record表中查询出状态为0记录,重新投递
对于投递失败的,采用衰减的方式进行重试,比如第1次失败了,则10秒后,继续重试
若还是失败,则再过20秒,再次重试,需要设置一个最大重试次数,最终还是投递失败,则需要告警+人工干预
f.建议
若公司微服务比较多,都会用到MQ这块,那么可以将这块做成一个springboot的starter,使用起来更容易
04.消息投递方式四:独立出来一个消息服务
a.说明
增加一个消息服务及消息库,负责消息的落库、将消息发送投递到mq
注意这里新增的一个消息服务可以是一个SpringBoot应用
如果你是做架构的可以考虑这种方式,或者面试的时候也可以给面试官介绍下这种方案
b.业务库需要添加一张消息日志表(t_msg_log)
id
bus_id:业务id
bus_type:业务类型
c.消息服务需要一张消息表(t_msg)
id:主键,消息id
msg_log_id:业务方t_msg_log表的id
body:消息体
msg_log_url:业务方t_msg_log记录回查的接口
status:状态,0:待投递,1:投递成功,2:投递失败
fail_msg:投递失败原因
d.消息投递的过程
step1:开启本地事务
step2:生成购物订单
step3:本地库t_msg_log表写入一条记录:insert into t_msg_log (bus_id,bus_type) values ('订单id','CREATE_ORDER')
step4:调用消息服务,需携带(t_msg_log.id,消息体,消息日志回查的url),消息服务接收到请求后,向t_msg表插入记录(status=0,待发送),并返回消息id:msg_id
step5:提交本地事务
step6:如果上面都成功,使用step4中的msg_id调用消息服务,消息服务则将消息投递到mq中,修改消息记录状态为投递成功(t_msg.status=1);如果上面有失败的情况,则消息服务将消息删掉
e.可能存在的问题
若step6失败,消息服务t_msg表中的这条消息,将处于待发送状态,但是业务库订单已经生成了
以及t_msg_log表也是有记录的,对于这种情况,消息服务需新增一个job
对于t_msg表中记录为0的消息,拿到t_msg表中的msg_log_id去回查msg_log_url这个接口
去查一下业务库中的t_msg_log 表是否有记录,有记录说明业务是执行成功的
此时消息服务补发消息到MQ就可以了;对于回查不到的,有可能业务方本地事务还未提交
不能认定为业务方本地事务执行失败了,建议等到1天之后,再清理下这种消息
05.如何确保消息到达MQ后,在MQ这边不会丢失?
a.说明1
有些MQ为了性能,收到消息后,会将消息放在内存中,并没有立即持久化到磁盘,此时MQ挂了,消息会丢失
b.说明2
若要确保MQ收到消息后,消息不会丢失,则收到投递过来的消息后,立即持久化
这个操作基本上所有的MQ都是支持的,使用的时候配置一下就可以了
c.说明3
为了防止MQ单节点故障,MQ还需要做主备,这样才可以最大限度的确保消息不会丢失
06.消费者如何确保消息一定会被消费?
a.消费者这边可以采用下面的过程,可以确保消息一定会被消费
step1:从MQ中拉取消息
step2:执行业务逻辑(需要做幂等)
step3:通知MQ删除这条消息
b.说明
由于step3这个步骤涉及到网络通信,网络通信存在不可靠的因素,可能会失败
导致消息没有被删掉,就会出现该消息再次消费的情况,所以step2需要做幂等处理
这种方式可以确保消息必然会被成功消费一次
3.10 MQ落地事务消息
01.本文主要内容
1.事务消息代码落地,可直接拿去使用
2.若消息投递到MQ失败,会由Job进行补偿,衰减式自动重试
02.回顾下事务消息
a.什么是事务消息?
事务消息是投递消息的一种方式,可以确保业务执行成功,消息一定会投递成功
b.需要在业务本地库创建一个消息表(t_msg)
create table if not exists t_msg
(
id varchar(32) not null primary key comment '消息id',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
fail_msg text comment 'status=2 时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
create_time datetime comment '创建时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表'
c.事务消息投递的过程
step1:开启本地事务
step2:执行本地业务
step3:消息表t_msg写入记录,status为0(待投递到MQ)
step4:提交本地事务
step5:若事务提交成功,则投递消息到MQ,然后将t_msg中的status置为1(投递成功);本地事务失败的情况不用考虑,此时消息记录也没有写到db中
d.异常情况
step5失败了,其他步骤都成功,此时业务执行成功,但是消息投递失败了,此时需要有个job来进行补偿,对于投递失败的消息进行重试
e.消息投递补偿job
这个job负责从本地t_msg表中查询出状态为0记录或者失败需要重试的记录,然后进行重新投递到MQ
对于投递失败的,采用衰减的方式进行重试,比如第1次失败了,则10秒后,继续重试,若还是失败,则再过20秒,再次重试,需要设置一个最大重试次数,最终还是投递失败,则需要告警+人工干预
本文将上面这些过程,都进行代码落地
03.同样,还是先看效果
a.说明
我们会模拟用户注册的一个操作,用户注册成功后,需要给MQ发送一条用户注册的消息,其他服务可能会用到这条消息
b.准备db初始化脚本
lesson030/src/main/resources/db/init.sql,此文件在当前案例应用启动的时候会自动执行
-----------------------------------------------------------------------------------------------------
-- 创建用户表
drop table if exists t_user_lesson030;
create table if not exists t_user_lesson030
(
id varchar(32) not null primary key comment '用户id',
name varchar(500) not null comment '用户名'
) comment '用户表';
-- 创建本地消息表
drop table if exists t_msg_lesson030;
create table if not exists t_msg_lesson030
(
id varchar(32) not null primary key comment '消息id',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
fail_msg text comment 'status=0时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
create_time datetime comment '创建时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表';
c.启动SpringBoot应用
Lesson030Application
d.案例1:演示正常情况:用户注册成功,消息投递成功
a.接口代码
com.itsoku.lesson030.controller.UserController#register
b.测试代码
### 1、演示正常情况:用户注册成功,消息投递成功
POST http://localhost:8080/user/register
Accept: application/json
Content-Type: application/json
{
"name": "路人"
}
c.观察控制台以及db中数据的变化
控制台可以看到消息投递成功了
db中也可以看到用户表(t_user)新增了一条记录,消息表(t_msg)也新增了一条投递成功的记录
e.案例2:演示业务执行失败,消息不会投递
a.接口代码
com.itsoku.lesson030.controller.UserController#registerError
b.测试代码
### 2、演示业务异常情况:用户注册的事务中有异常,消息投递会被自动取消
POST http://localhost:8080/user/registerError
Accept: application/json
Content-Type: application/json
{
"name": "路人"
}
c.观察控制台以及db中数据的变化
控制台看可以到有异常发生,且消息没有投递
db中用户表没有记录、消息表也没有记录
f.案例3:演示投递到MQ失败,则由job会自动重试
a.接口代码
com.itsoku.lesson030.controller.UserController#register
b.测试代码
### 3、演示投递到MQ失败,则由job会自动重试(我们在消息投递的地方,故意加了一段代码:消息体超过100投递失败)
POST http://localhost:8080/user/register
Accept: application/json
Content-Type: application/json
{
"name": "路人《Java高并发&微服务&性能调优实战案例100讲》,59块钱,含源码 & 文档 & 技术支持,有需要的朋友可以点击左下角小黄车了解,或者加我微信itsoku了解"
}
c.观察控制台以及db中数据的变化
db中消息表(t_msg)可以看到这条消息投递失败的信息(失败的原因、下次重试投递时间)
控制台可以看到job会对投递失败的消息,进行重试投递,job目前是每20秒执行一次
04.源码解析
a.源码位置
源码主要在lesson030模块中,而mq相关的所有核心代码在`com.itsoku.lesson030.mq`包中
若咱们很多项目都要用到这块代码,大家可以直接把这个包中的代码做成一个springboot的starter,这样其他项目中使用就非常方便
b.IMsgSender:负责消息投递
业务方直接使用这个类进行消息投递,将这个类注入到自己的类中,然后调用send相关的方法,便可投递消息
-----------------------------------------------------------------------------------------------------
public interface IMsgSender {
/**
* 批量发送消息
*
* @param msgList
*/
void send(List<Object> msgList);
/**
* 发送单条消息
*
* @param msg
*/
default void send(Object msg) {
Objects.nonNull(msg);
this.send(Arrays.asList(msg));
}
/**
* 投递重试
*
* @param msgPO
*/
void sendRetry(MsgPO msgPO);
}
c.DefaultMsgSender:消息投递默认实现类,核心类
从下面这个方法开始看,事务消息的代码就在这个方法中
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson030.mq.sender.DefaultMsgSender#send
d.MqSendRetryJob:消息投递补偿的job
这个job默认会20秒执行一次,会从本地消息表查询出需要投递重试的消息,然后会进行再次投递,入口代码如下,我们来看下
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson030.mq.sender.MqSendRetryJob#sendRetry
e.业务方如何使用IMsgSender投递消息(2步)
a.先注入 IMsgSender
@Autowired
private IMsgSender msgSender;
b.调用 msgSender.send方法投递消息,如下
@Override
@Transactional(rollbackFor = Exception.class)
public String register(UserRegisterRequest req) {
UserPO userPO = new UserPO();
userPO.setId(IdUtil.fastSimpleUUID());
userPO.setName(req.getName());
this.save(userPO);
//发送用户注册消息
this.msgSender.send(userPO);
return userPO.getId();
}
4 part03
4.1 一个延迟任务处理工具类
01.延迟队列
a.说明
延迟队列是一种特殊的队列,它允许将消息或任务延迟一段时间后再进行处理
延迟队列基于优先级队列实现,每个元素都有一个指定的延迟时间,在到达延迟时间之前,元素无法从延迟队列中获取
b.java中已提供了一个延迟队列工具类
java.util.concurrent.DelayQueue
c.使用场景
1.订单超时处理
2.定时任务
3.消息重试与退避策略
4.缓存失效与刷新
02.代码示例
a.代码
DelayTaskProcessorTest#test1
b.运行输出
task-5:放入任务成功
task-4:放入任务成功
task-3:放入任务成功
task-2:放入任务成功
task-1:放入任务成功
处理任务:task-1,任务延迟时间(ms):1000,任务实际处理的时间 - 任务放入的时间 (ms):1002
处理任务:task-2,任务延迟时间(ms):2000,任务实际处理的时间 - 任务放入的时间 (ms):2002
处理任务:task-3,任务延迟时间(ms):3000,任务实际处理的时间 - 任务放入的时间 (ms):3000
处理任务:task-4,任务延迟时间(ms):4000,任务实际处理的时间 - 任务放入的时间 (ms):4001
处理任务:task-5,任务延迟时间(ms):5000,任务实际处理的时间 - 任务放入的时间 (ms):5002
c.源码解析
com.itsoku.lesson031.DelayTaskProcessor
4.2 MQ延迟消息通用方案实战
00.汇总
a.主要内容
本文将带大家手写一个MQ延迟消息的通用方案
本文的方案不依赖于MQ中间件,依靠MySQL和DelayQueue解决
不管大家用的是什么MQ,具体是RocketMQ、RabbitMQ还是kafka
本文这个方案你都可以拿去直接使用,可以轻松实现任意时间的延迟消息投递
b.技术点
1.SpringBoot2.7
2.MyBatisPlus
3.MySQL
4.线程池
5.java中的延迟队列:DelayQueue
6.分布式锁
01.延迟消息常见的使用场景
a.订单超时处理
比如下单后15分钟,未支付,则自动取消订单,回退库存
可以采用延迟队列实现:下单的时候可以投递一条延迟15分钟的消息,15分钟后消息将被消费
b.消息消费失败重试
比如MQ消息消费失败后,可以延迟一段时间再次消费
可以采用延迟消息实现:消费失败,可以投递一条延迟消息,触发再次消费
c.其他任意需要延迟处理的业务
业务中需要延迟处理的场景,都可以使用延迟消息来搞定
02.延迟消息常见的实现方案
a.方案1:MySQL + job定时轮询
由于延迟消息的时间不确定,若要达到实时性很高的效果
也就是说消息的延迟时间是不知道的,那就需要轮询每一秒才能确保消息在指定的延迟时间被处理
这就要求job需要每秒查询一次db中待投递的消息
这种方案访问db的频率比较高,对数据库造成了一定的压力
b.方案2:RabbitMQ 中的TTL+死信队列
rabbitmq中可以使用TTL消息 + 死信队列实现,也可以安装延时插件
此方案对中间件有依赖,不同的MQ实现是不一样的,若换成其他的MQ,方案要重新实现
c.方案3:MySQL + job定时轮询 + DelayQueue
可以对方案1进行改进,引入java中的 DelayQueue。
job可以采用1分钟执行一次,每次拉取未来2分钟内需要投递的消息
将其丢到java自带的 DelayQueue 这个延迟队列工具类中去处理
这样便能做到实时性很高的投递效果,且对db的压力也降低了很多
这种方案对db也没什么压力,实时性非常高,且对MQ没有依赖,这样不管切换什么MQ,这种方案都不需要改动
我比较推荐这种,但是实现可能有点难度,本文将落地该方案
03.需要一张本地消息表(t_msg)
create table if not exists t_msg_lesson032
(
id varchar(32) not null primary key comment '消息id',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
expect_send_time datetime not null comment '消息期望投递时间,大于当前时间,则为延迟消息,否则会立即投递',
actual_send_time datetime comment '消息实际投递时间',
create_time datetime comment '创建时间',
fail_msg text comment 'status=2 时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表';
04.先看效果
a.数据库初始化脚本
lesson032/src/main/resources/db/init.sql,系统启动的时候会自动执行,创建2张表,一个订单表,一个本地消息表
-----------------------------------------------------------------------------------------------------
-- 创建订单表
drop table if exists t_order_lesson032;
create table if not exists t_order_lesson032
(
id varchar(32) not null primary key comment '订单id',
goods varchar(100) not null comment '商品',
price decimal(12, 2) not null comment '订单金额'
) comment '订单表';
-- 创建本地消息表
drop table if exists t_msg_lesson032;
create table if not exists t_msg_lesson032
(
id varchar(32) not null primary key comment '消息id',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
expect_send_time datetime not null comment '消息期望投递时间,大于当前时间,则为延迟消息,否则会立即投递',
actual_send_time datetime comment '消息实际投递时间',
create_time datetime comment '创建时间',
fail_msg text comment 'status=2 时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表';
b.启动应用
com.itsoku.lesson032.Lesson032Application
c.案例1:演示:创建订单,模拟立即投递消息
a.运行测试用例
POST http://localhost:8080/order/createOrder
Accept: application/json
Content-Type: application/json
{
"goods": "立即投递消息",
"price": "59.00",
"delaySeconds": 0
}
b.说明
执行完毕后看下数据库中的t_msg_lesson032表的记录,关注下消息的状态,创建时间,期望投递时间,具体投递时间
select * from t_msg_lesson032;
d.案例2:演示:创建订单,模拟投递延迟消息,延迟时间是 5 秒
a.运行测试用例
POST http://localhost:8080/order/createOrder
Accept: application/json
Content-Type: application/json
{
"goods": "投递延迟消息,延迟时间 5s",
"price": "59.00",
"delaySeconds": 5
}
b.说明
执行完毕后看下数据库中的t_msg_lesson032表的记录,关注下消息的状态,创建时间,期望投递时间,具体投递时间
select * from t_msg_lesson032;
05.源码解析
a.源码位置
源码主要在lesson032模块中,而mq相关的所有核心代码在`com.itsoku.lesson032.mq`包中
b.IMsgSender:负责消息投递
业务方直接使用这个类进行消息投递,将这个类注入到自己的类中,然后调用send相关的方法,便可投递消息
主要看4个send方法。
com.itsoku.lesson032.mq.sender.IMsgSender
c.DefaultMsgSender:IMsgSender默认实现类
消息投递的逻辑都在这个类中
com.itsoku.lesson032.mq.sender.DefaultMsgSender
d.MqSendRetryJob:消息投递补偿的job
每分钟执行一次,会从本地消息表中查询出未来2分钟内需要投递的消息,然后会进行投递重试,入口代码
com.itsoku.lesson032.mq.sender.MqSendRetryJob#sendRetry
e.业务方如何使用IMsgSender投递消息(2步)
a.先注入 IMsgSender
@Autowired
private IMsgSender msgSender;
b.调用 msgSender.send方法投递消息
//投递普通消息
this.msgSender.send(消息);
//投递延迟消息
this.msgSender.send(延迟时间, 延迟时间单位, 消息);
06.使用注意
a.替换分布式锁
生产上,服务都是集群部署的,同一条消息可能会被多个服务同时处理
会出现重复投递,为了避免这个问题,系统中使用了分布锁
本文的代码中,分布锁默认是使用java中的ReentrantLock搞的
集群中会有问题,大家用的时候,一定要把这个分布式锁给替换掉,可以引入redisson分布式锁来解决这个问题
b.本地消息表性能问题
本文中用到了一个本地消息表t_msg,会存储所有消息,数据量大了会有性能问题
建议将投递成功的和投递失败不需要重试的消息,移到备份表,这样可以确保t_msg表的压力比较小,性能也就上去了
4.3 MQ幂等消费和失败重试
00.汇总
a.内容
a.消息投递的通用代码
非事务消息的投递
事务消息的投递
任意延迟消息的投递,不依赖于任何MQ
上面这些投递都支持批量的方式
投递失败自动重试的代码
b.幂等消费的通用代码
c.消费失败,衰减式自动重试的通用代码
b.技术
1.SpringBoot2.7
2.MyBatisPlus
3.MySQL
4.线程池
5.java中的延迟队列:DelayQueue
6.分布式锁
7.RabbitMQ
01.消费者如何确保消息一定会被消费?
a.步骤
step1:从MQ中拉取消息,此时不要从mq中删除消息
step2:执行业务逻辑(需要做幂等)
step3:通知MQ删除这条消息
b.说明
若上面过程失败了,则采用衰减式的方式进行自动重试
比如第一次消费失败后,延迟10秒后,将消息再次丢入队列,进行消费重试
若还是失败,再延迟20秒后丢入队列,继续重试,但是得有个上限,比如最多50次,达到上限需要进行告警人工干预
这里的关键技术点就是:幂等+重试+开启消费者手动ack
02.什么是消费失败后衰减式重试?
失败后,会过一会,再次重试,若还是失败,则过一会,再次重试。
比如累计失败次数在1-5次内,每次失败后会间隔10秒进行重试
在6-10次内,间隔20秒,在11-20次内,间隔30秒,但是有个次数上限
比如50次,达到最大次数,将不再重试,报警,人工干预
03.衰减重试是如何实现的?
通过延迟消息实现的,消费失败后,会投递一条延迟消息,消息的内容和原本消息的内容是一样的
延迟时间到了后,这个消息会进入消息原本的队列,会触发再次消费
04.什么是消费者手动ack(acknowledgemenet)?
a.方式1:MQ自动删除
消费者从mq中拉取消息后,mq立即就把消息删掉了,此时消费者还未消费
这种可能会有问题,比如消费者拿到消息后,消费失败了,但是此时消息已经被mq删除了,结果会导致消息未被成功消费
b.方式2:消费者通知MQ删除(也叫手动ack)
消费者从mq拉取消息后,做业务处理,业务处理完成之后,通知mq删除消息,这种就叫做消费者手动ack
这种会存在通知mq删除消息失败的情况,会导致同一条消息会被消费者消费多次,消费端需要避免重复消费
本文中用的是这种ack的方式
05.什么是幂等消费?
同一条消息,即使出现了重复的消息,被同一个消费者消费,也只会成功消费一次
06.为什么要考虑幂等消费?
a.重复投递的情况
生产者投递消息到MQ,由于网络问题,未收到回执,生产者以为消息投递失败了
会重试,这就可能会导致同一条消息被投递多次
b.消费者ACK失败,消息会被再次消费
消费者拉取消息消费后,会通知MQ中删除此消息,通知MQ删除消息这个过程又涉及网络通信
可能会失败,此时会导致消息被消费者消费了,但是却未从mq中删除,这样消息就会被再次拉取进行消费
上面2种情况,会导致同一条消息,会被消费者处理多次,消费端若未考虑幂等性,可能导致严重的事故
07.如何解决这个问题?
a.说明
搞定下面2个问题,幂等消费的问题就解决了
b.说明
1.如何确定MQ中的多条消息是同一条业务消息?
2.消费者如何确保同一条消息只被成功消费一次?
08.如何确定MQ中的多条消息是同一条业务消息?
a.我们可以定义一种通用的消息的格式,格式如下,生产者发送的所有消息,都必须采用这个格式
public class Msg<T> {
/**
* 生产者名称
*/
private String producer;
/**
* 生产者这边消息的唯一标识
*/
private String producerBusId;
/**
* 消息体,主要是消息的业务数据
*/
private T body;
}
b.说明
对于多条消息,通过(producer、producerBusId)这两个字段来判断是否是同一条消息
若他们的这两个字段的值是一样的,则表示他们是同一条消息
producer:可以使用服务名称
producerBusId:生产者这边消息的唯一标识,比如可以使用UUID
09.消费者如何确保同一条消息只被成功消费一次?
a.使用唯一约束实现
需要一个幂等辅助表,如下,idempotent_key 添加了唯一约束,多个线程同时向这个表写入数据
若idempotent_key是一样的,则只有一个会成功,其他的会违反唯一约束触发异常,导致失败
-----------------------------------------------------------------------------------------------------
create table if not exists t_idempotent_lesson033
(
id varchar(50) primary key comment 'id,主键',
idempotent_key varchar(500) not null comment '需要确保幂等的key',
unique key uq_idempotent_key (idempotent_key)
) comment '幂等辅助表';
b.消费端幂等消费如何实现呢?
用上面的幂等辅助表,便可实现幂等消费,过程如下
-----------------------------------------------------------------------------------------------------
// 这里的幂等key,由消息里面的(producer,producerBusId)加上消费者完整类名组成,也就是同一条消息只能被同一个消费者消费一次
String idempotentKey = (producer,producerBusId,消费者完整类名);
// 幂等表是否存在记录,如果存在说明处理过,直接返回成功
IdempotentPO idempotentPO = select * from t_idempotent_lesson033 where idempotent_key = #{idempotentKey};
if(idempotentPO!=null){
return "SUCCESS";
}
// 开启Spring事务(这里千万不要漏掉,一定要有事务)
这里放入消息消费的实际业务逻辑,最好是db操作的代码。。。。。
String idempotentId = "";
// 这里是关键一步,向 t_idempotent 插入记录,如果有并发过来,只会有一个成功,其他的会报异常导致事务回滚
insert into t_idempotent_lesson033 (id, idempotent_key) values (#{idempotentId}, #{idempotentKey});
// 提交spring事务
10.下面先看案例
a.概述
a.说明
会模拟电商中下单后,投递一条订单消息,然后会搞一个消费者来消费这个消息
本案例会用到RabbitMQ,大家先安装rabbitmq,然后修改`lesson033/src/main/resources/application.yml`中rabbitmq相关配置
RabbitMQ的安装可以参考:http://itsoku.com/course/22/381
b.会有3个案例代码
投递普通订单消息,模拟消费
投递延迟订单消息,延迟5秒,模拟消费
投递普通消息,模拟消费失败,自动重试的情况
c.案例中会用到5个表
先不用记,大概有个印象,知道每个表是干什么用的就行了
-----------------------------------------------------------------------------------------------------
-- 创建订单表
drop table if exists t_order_lesson033;
create table if not exists t_order_lesson033
(
id varchar(32) not null primary key comment '订单id',
goods varchar(100) not null comment '商品',
price decimal(12, 2) comment '订单金额'
) comment '订单表';
-- 创建本地消息表
drop table if exists t_msg_lesson033;
create table if not exists t_msg_lesson033
(
id varchar(32) not null primary key comment '消息id',
exchange varchar(100) comment '交换机',
routing_key varchar(100) comment '路由key',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
expect_send_time datetime not null comment '消息期望投递时间,大于当前时间,则为延迟消息,否则会立即投递',
actual_send_time datetime comment '消息实际投递时间',
create_time datetime comment '创建时间',
fail_msg text comment 'status=2 时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表';
-- 创建消息和消费者关联表,(producer, producer_bus_id, consumer_class_name)相同时,此表只会产生一条记录,就是同一条消息被同一个消费者消费,此表只会产生一条记录
drop table if exists t_msg_consume_lesson033;
create table if not exists t_msg_consume_lesson033
(
id varchar(32) not null primary key comment '消息id',
producer varchar(100) not null comment '生产者名称',
producer_bus_id varchar(100) not null comment '生产者这边消息的唯一标识',
consumer_class_name varchar(300) not null comment '消费者完整类名',
queue_name varchar(100) not null comment '队列名称',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待消费,1:消费成功,2:消费失败',
create_time datetime comment '创建时间',
fail_msg text comment 'status=2 时,记录消息消费失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
consume_retry smallint not null default 1 comment '消费失败后,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
update_time datetime comment '最近更新时间',
key idx_status (status),
unique uq_msg (producer, producer_bus_id, consumer_class_name)
) comment '消息和消费者关联表';
drop table if exists t_msg_consume_log_lesson033;
create table if not exists t_msg_consume_log_lesson033
(
id varchar(32) not null primary key comment '消息id',
msg_consume_id varchar(32) not null comment '消息和消费者关联记录',
status smallint not null default 0 comment '消费状态,1:消费成功,2:消费失败',
create_time datetime comment '创建时间',
fail_msg text comment 'status=2 时,记录消息消费失败的原因',
key idx_msg_consume_id (msg_consume_id)
) comment '消息消费日志';
-- 幂等辅助表
drop table if exists t_idempotent_lesson033;
create table if not exists t_idempotent_lesson033
(
id varchar(50) primary key comment 'id,主键',
idempotent_key varchar(500) not null comment '需要确保幂等的key',
unique key uq_idempotent_key (idempotent_key)
) comment '幂等辅助表';
c.启动SpringBoot应用
com.itsoku.lesson033.Lesson033Application
d.测试代码
com.itsoku.lesson033.controller.OrderController#createOrder:测试接口入口
com.itsoku.lesson033.service.impl.OrderServiceImpl#createOrder:创建订单,投递消息
com.itsoku.lesson033.service.OrderConsumer:订单消息消费者,会输出日志
b.案例1:投递普通订单消息,模拟消费
a.清理下数据
-- 清理下数据
delete from t_msg_lesson033;
delete from t_msg_consume_lesson033;
delete from t_msg_consume_log_lesson033;
delete from t_idempotent_lesson033;
b.运行测试用例
### 案例1:投递普通订单消息,模拟消费
POST http://localhost:8080/order/createOrder
Accept: application/json
Content-Type: application/json
{
"goods": "立即投递消息",
"price": "59.00",
"delaySeconds": 0
}
c.控制台输出
[http-nio-8080-exec-1] 18:13:34 :***************投递普通消息:OrderPO(id=2ec57ce4b5b1445ca668f8321ffb52d0, goods=立即投递消息, price=59.00)
[org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] 18:13:35 :***************收到订单消息:OrderPO(id=2ec57ce4b5b1445ca668f8321ffb52d0, goods=立即投递消息, price=59)
d.查看结果
-- 本地消息表
select * from t_msg_lesson033;
-- 消息和消费者关联表
select * from t_msg_consume_lesson033;
-- 消息消费日志表
select * from t_msg_consume_log_lesson033 order by create_time asc;
-- 幂等辅助表
select * from t_idempotent_lesson033;
c.案例2:投递延迟订单消息,延迟5秒,模拟消费
a.清理下数据
-- 清理下数据
delete from t_msg_lesson033;
delete from t_msg_consume_lesson033;
delete from t_msg_consume_log_lesson033;
delete from t_idempotent_lesson033;
b.运行测试用例
### 案例2:投递延迟订单消息,延迟5秒,模拟消费
POST http://localhost:8080/order/createOrder
Accept: application/json
Content-Type: application/json
{
"goods": "投递延迟消息,延迟时间 5s",
"price": "59.00",
"delaySeconds": 5
}
c.查看结果
-- 本地消息表
select * from t_msg_lesson033;
-- 消息和消费者关联表
select * from t_msg_consume_lesson033;
-- 消息消费日志表
select * from t_msg_consume_log_lesson033 order by create_time asc;
-- 幂等辅助表
select * from t_idempotent_lesson033;
d.案例3:投递普通消息,模拟消费失败,自动重试的情况
a.清理下数据
-- 清理下数据
delete from t_msg_lesson033;
delete from t_msg_consume_lesson033;
delete from t_msg_consume_log_lesson033;
delete from t_idempotent_lesson033;
b.运行测试用例
消费的时候,有判断金额,如果为null,则会抛出一个异常,会触发衰减式消费重试的逻辑。
-------------------------------------------------------------------------------------------------
### 案例3:投递普通消息,模拟消费失败,自动重试的情况
POST http://localhost:8080/order/createOrder
Accept: application/json
Content-Type: application/json
{
"goods": "尝试消费失败重试的情况,金额为空,消费的时候会失败",
"price": null
}
c.查看结果
-- 本地消息表
select * from t_msg_lesson033;
-- 消息和消费者关联表
select * from t_msg_consume_lesson033;
-- 消息消费日志表
select * from t_msg_consume_log_lesson033 order by create_time asc;
-- 幂等辅助表
select * from t_idempotent_lesson033;
11.源码解析
a.开启rabbitmq消费者ack
lesson033/src/main/resources/application.yml 添加下面配置
auto表示消费者消费消息的过程中没有向最外层抛出异常,则mq才会将消息从队列中删除
-----------------------------------------------------------------------------------------------------
rabbitmq:
listener:
simple:
acknowledge-mode: auto # 消费过程没有向外抛出异常自动ack
b.IMsgSender:负责投递各种类型消息
里面send开头的方法,都是用于投递消息的,消息类型必须为Msg类型
sendWithBody开头的方法会将丢进来的消息包装为Msg类型的消息,然后投递
c.AbstractIdempotentConsumer:幂等消费+消费失败衰减式自动重试
如下,用法可以参考OrderConsumer,继承AbstractIdempotentConsumer就可以了
然后写两个方法如下,业务方消费逻辑写在disposeIn方法中,那么便可以自动确保幂等消费
以及消费失败后会自动重试,默认会采用衰减的方式进行重试,最多50次
-----------------------------------------------------------------------------------------------------
@Slf4j
@Component
public class OrderConsumer extends AbstractIdempotentConsumer<OrderPO, Msg<OrderPO>> {
@RabbitListener(queues = RabbitMQConfiguration.Order.QUEUE)
public void dispose(Message message) {
super.dispose(message);
}
@Override
protected void disposeIn(Message message, OrderPO body) {
log.info("***************收到订单消息:{}", body);
//这里是为了演示消费异常重试的场景,这里加了个判断,金额为空的时候,弹出异常
if (body.getPrice() == null) {
throw BusinessExceptionUtils.businessException("订单金额有误啊!");
}
}
}
12.最佳实战
a.如何投递事务消息?
将消息投递的代码放在有事务的方法中,投递的便是事务消息,消息一定会投递成功
如下,方法上有@Transaction注解,这个方法就会有事务
-----------------------------------------------------------------------------------------------------
//1、注入消息发送器
@Autowired
private IMsgSender msgSender;
//2、投递消息的方法在事务中,那么投递的消息就是事务消息,如下案例
@Override
@Transactional(rollbackFor = Exception.class)
public String createOrder(CreateOrderRequest req) {
this.msgSender.sendWithBody(RabbitMQConfiguration.Order.EXCHANGE, RabbitMQConfiguration.Order.ROUTING_KEY, orderPO);
}
b.如何投递延迟消息?
如下,调用 msgSender 中投递延迟消息的方法,便可投递延迟消息
-----------------------------------------------------------------------------------------------------
this.msgSender.sendWithBody(RabbitMQConfiguration.Order.EXCHANGE, RabbitMQConfiguration.Order.ROUTING_KEY, req.getDelaySeconds(), TimeUnit.SECONDS, orderPO);
c.幂等消费如何实现
继承 AbstractIdempotentConsumer,便可实现幂等消费,参考 com.itsoku.lesson033.service.OrderConsumer 的代码,如下,非常简单
-----------------------------------------------------------------------------------------------------
@Slf4j
@Component
public class OrderConsumer extends AbstractIdempotentConsumer<OrderPO, Msg<OrderPO>> {
@RabbitListener(queues = RabbitMQConfiguration.Order.QUEUE)
public void dispose(Message message) {
super.dispose(message);
}
@Override
protected void disposeIn(Message message, OrderPO body) {
log.info("***************收到订单消息:{}", body);
//这里是为了演示消费异常重试的场景,这里加了个判断,金额为空的时候,弹出异常
if (body.getPrice() == null) {
throw BusinessExceptionUtils.businessException("订单金额有误啊!");
}
}
}
d.如何查看消息发送记录?
目前只有事务消息在db的本地消息表中会有记录,如下
-- 本地消息表
select * from t_msg_lesson033;
e.如何查看消息消费日志?下面2张表
-- 消息和消费者关联表
select * from t_msg_consume_lesson033;
-- 消息消费日志表
select * from t_msg_consume_log_lesson033 order by create_time asc;
4.4 MQ顺序消息
01.什么是顺序消息
投递消息的顺序和消费消息的顺序一致
比如生产者按顺序投递了1/2/3/4/5 这 5 条消息,那么消费的时候也必须按照1到5的顺序消费这些消息
02.顺序消息如何实现?
a.方案1
生产者串行发送+同一个队列+消费者单线程消费
b.方案2
生产方消息带上连续递增编号+同一个队列+消费按编号顺序消费消息
03.方案1:生产者串行发送+同一个队列+消费者单线程消费
a.生产者串行发送消息
使用分布式锁,让消息投递串行执行
确保顺序消息到达同一个队列
b.消费者单线程消费
消费者这边只能有一个线程,拉取一个消费一个,消费完成后再拉取下一个消费
04.方案2:生产方消息带上连续递增编号+同一个队列+消费按编号顺序消费消息
a.生产方消息带上连续递增编号
顺序消息携带连续递增的编号,从1开始,连续递增,比如发送了3条消息,编号分别是1、2、3,后面再投递消息,编号就从4开始了
确保顺序消息到达同一个队列
b.消费方按照编号顺序消费消息
消费方需要记录消息消费的位置:当前轮到哪个编号的消息了
收到消息后,将消息的编号和当前消费的位置对比下,是不是轮着这条消息消费了
如果是则进行消费,如果不是,则排队等待,等待前一个到达后,且消费成功后,将自己唤醒进行消费
-----------------------------------------------------------------------------------------------------
这里举个例子,如下
生产者发送了编号为看1、2、3 的3条消息
到达的消费端顺序刚好相反,3先到,发现没有轮到自己,会进行排队
然后2到了,发现也没有轮到自己,也会排队
然后过了一会1到了,发现轮到自己了,然后1被消费了
1消费后,会唤醒下一个编号的2进行消费
2消费完了,会唤醒下一个编号的3进行消费。
05.落地方案2
a.发送顺序消息
如下模拟发送订单相关的5条顺序消息
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson034.controller.TestController#sendSequential
@PostMapping("/sendSequential")
public Result<Void> sendSequential() {
String orderId = IdUtil.fastSimpleUUID();
List<String> list = Arrays.asList("订单创建消息",
"订单支付消息",
"订单已发货",
"买家确认收货",
"订单已完成");
for (String type : list) {
msgSender.sendSequentialWithBody(orderId,
RabbitMQConfiguration.Order.EXCHANGE,
RabbitMQConfiguration.Order.ROUTING_KEY,
OrderMsg.builder().orderId(orderId).type(type).build());
}
return ResultUtils.success();
}
b.演示:没有确保顺序消费的情况
com.itsoku.lesson034.consume.TestConsumer.dispose
@Override
@RabbitListener(queues = RabbitMQConfiguration.Order.QUEUE, concurrency = "5")
public void dispose(Message message) {
Msg<OrderMsg> msg = getMsg(message);
String log = "☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:" + msg.getSequentialMsgNumbering() + ",消息体:" + JSONUtil.toJsonStr(msg.getBody());
System.err.println(log);
// super.dispose(message);
}
-----------------------------------------------------------------------------------------------------
输出:
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:4,消息体:{"orderId":"06e7e2d9195444a4a145c31c28297b20","type":"买家确认收货"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:1,消息体:{"orderId":"06e7e2d9195444a4a145c31c28297b20","type":"订单创建消息"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:2,消息体:{"orderId":"06e7e2d9195444a4a145c31c28297b20","type":"订单支付消息"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:3,消息体:{"orderId":"06e7e2d9195444a4a145c31c28297b20","type":"订单已发货"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:5,消息体:{"orderId":"06e7e2d9195444a4a145c31c28297b20","type":"订单已完成"}
c.演示:顺序消费的情况
需要调整:com.itsoku.lesson034.consume.TestConsumer.dispose 代码,如下
-----------------------------------------------------------------------------------------------------
@Override
@RabbitListener(queues = RabbitMQConfiguration.Order.QUEUE, concurrency = "5")
public void dispose(Message message) {
super.dispose(message);
}
-----------------------------------------------------------------------------------------------------
然后重启服务,测试效果,输出如下:
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:1,消息体:{"orderId":"0ca696d9fb6340a2a3b3133428de90b7","type":"订单创建消息"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:2,消息体:{"orderId":"0ca696d9fb6340a2a3b3133428de90b7","type":"订单支付消息"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:3,消息体:{"orderId":"0ca696d9fb6340a2a3b3133428de90b7","type":"订单已发货"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:4,消息体:{"orderId":"0ca696d9fb6340a2a3b3133428de90b7","type":"买家确认收货"}
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:5,消息体:{"orderId":"0ca696d9fb6340a2a3b3133428de90b7","type":"订单已完成"}
06.源码解析
a.投递顺序消息
com.itsoku.lesson034.mq.sender.IMsgSender#sendSequentialWithBody
-----------------------------------------------------------------------------------------------------
/**
* 发送顺序消息,可确保(busId+exchange+routingKey)相同的情况下,消息的顺序性
* 这里我们使用的是rabbitmq,rabbitmq中 exchange+routingKey 可以确保消息被路由到相同的队列
* <p>
* 这里为什么要加入busId?
* 以订单消息举例,所有订单消息都会进入同样的队列,订单有3种类型消息(创建、支付、发货)
* 同一个订单的这3种类型的消息是要有序的,但是不同订单之间,他们不需要有序,所以这里加了个busId,此时就可以将订单id作为busId
*
* @param busId 业务id
* @param exchange
* @param routingKey
* @param msgBody 消息体
*/
default void sendSequentialWithBody(String busId, String exchange, String routingKey, Object msgBody) {
this.sendSequentialMsg(busId, exchange, routingKey, this.build(msgBody));
}
b.消费端确保顺序消费
参考:com.itsoku.lesson034.consume.TestConsumer,需要继承 AbstractSequentialMsgConsumer 类,如下,便可确保顺序消费
-----------------------------------------------------------------------------------------------------
@Component
@Slf4j
public class TestConsumer extends AbstractSequentialMsgConsumer<OrderMsg, Msg<OrderMsg>> {
@Override
@RabbitListener(queues = RabbitMQConfiguration.Order.QUEUE, concurrency = "5")
public void dispose(Message message) {
super.dispose(message);
}
@Override
protected void sequentialMsgConsume(Msg<OrderMsg> msg) {
String log = "☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆顺序消息消费,消息编号:" + msg.getSequentialMsgNumbering();
System.err.println(log);
//这里休眠500ms,模拟耗时的业务操作
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
4.5 MQ消息积压
01.如何发现消息出现了堆积?
a.指标监控系统
待消费的数量
最后一条消费时间:距离当前时间太久,说明消费端长时间不处理
消息发送/生产速度的比值:比值偏大,说明消息太多了
对上层监控端进行告警、发邮件、进行审查
消费端监控告警,比如消费者脱机或进程崩溃时发现,可以对消费者进行监控告警
b.Prometheus
Prometheus是一个开源的监控和报警工具,主要用于指标大规模数据的高吞吐量
Prometheus可以与Grafana等可视化工具结合使用,提供丰富的指标和监控功能
c.Grafana
Grafana是一个开源的可视化和监控平台,可以与多种数据源(如Prometheus、InfluxDB等)结合使用
它用于丰富多样的数据监控图表、视图与告警。Grafana支持多语言的数据面板,并且可以与多种数据源集成
02.常见的原因及解决方案
a.原因
大多数问题是因为消息消费速度跟不上生产的速度
b.解决方案
优化消费慢的代码
增加消费线程,提升消费端消费效率
如果服务效率已经很高了,扩展副本
消费端可以通过输出消费日志(比如消费耗时)
排查消费链路日志,找慢耗时的代码
c.常用的一些工具
arthas
jstack
03.消息出现了大量堆积如何解决?
消息数超过百万后,紧急间断当前业务流量了
提前报警,当消息数超过百万时发告警,然后需要考虑流量控制措施
可以将接触消息的部分服务列为停机计划,这样可以从休息端逐个将停机端排除出队列,让目前的业务能够继续正常运行
优化消费端代码,增强消费速度
将消费端消费者进行优化
04.建议
务必要配置报警:对MQ进行的监控,发现问题要提前的业务进行告警,等到消息积压再处理
压力测试:在上线前进行压力测试,评估产品的性能,做到心中有数
4.6 MQ最终一致性:跨库转账
01.前言
a.说明
接下来三四节,属于分布式事务专题,会带来:分布式事务相关的一些解决方案+案例+代码落地
基本上可以解决工作中碰到的分布式事务问题
b.主要会给大家介绍2种方案
MQ最终一致性解决分布式事务
TCC 的方式解决分布式事务
02.MQ解决分布式事务问题
1.跨库转账
2.平台账户-提现到微信钱包
03.前置知识
a.分布式事务相关的一些概念知识
什么是分布式事务:http://itsoku.com/course/7/160
CAP原则:http://itsoku.com/course/7/161
BASE理论:http://itsoku.com/course/7/162
b.第12节
幂等性4种方案
c.第28-35节
MQ专题相关
04.案例:使用MQ解决跨库转账
1.上游我们只需要写扣减余额和投递消息的代码
2.下游只需要写给收款方加钱的代码
05.先带大家看下效果
a.先准备一个表
drop table if exists t_account_lesson036;
create table if not exists t_account_lesson036
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额'
) comment '账户表';
insert ignore into t_account_lesson036 value ('1','路人1','1000.00');
insert ignore into t_account_lesson036 value ('2','路人2','0.00');
-----------------------------------------------------------------------------------------------------
跨库转账这个案例中,为了方便,我们将付款方和收款方,用的是同一个库中的同一个账户表
但是在应用层面,我们用的是分布式事务解决的
b.跨库转账接口
com.itsoku.lesson036.controller.AccountController#transfer
-----------------------------------------------------------------------------------------------------
这个方法中主要对应付款方的代码,干了2件事情:
1.付款方扣减余额
2.投递一条转账消息到MQ(这里投递的是事务消息,可以去报扣减余额成功,消息一定会投递成功)
c.下游:消费转账消息,给收款方加钱
com.itsoku.lesson036.consume.TransferMsgConsumer#idempotentConsume
-----------------------------------------------------------------------------------------------------
在这个方法中,只需要给收款方加钱就可以了
下面是这个类的一个类图,他上面有2个父类,父类中是通用的代码
分别帮我们实现了失败自动重试、消费幂等性的工作,所以我们只需要写业务代码就行了,大大节省了我们的工作量
d.启动应用
com.itsoku.lesson036.Lesson036Application
e.先看db中账户余额
select * from t_account_lesson036;
f.执行测试用例
src/test/resources/AccountController.http
-----------------------------------------------------------------------------------------------------
### 跨库转账
POST http://localhost:8080/account/transfer
Accept: application/json
Content-Type: application/json
{
"fromAccountId": "1",
"toAccountId": "2",
"transferPrice": "10.00"
}
g.查看db中2个账户的余额
select * from t_account_lesson036;
06.MQ最终一致性适用的场景
适合分布式事务中有2个事务参与者,且后面一个一定会成功的场景,这种比较适合采用MQ最终一致性来解决
第一个参与者:执行本地业务+投递事务消息
第二个参与者:幂等消费消息+消费失败衰减式重试+重试达到上线人工干预
4.7 MQ最终一致性:平台余额提现微信钱包
01.场景
a.描述
假如咱们做个电商系统,商户可以在上面卖东西,卖东西会产生交易,交易产生的收入在平台账户的余额中,这就涉及到商户提现的操作
需支持:商户将平台上账户余额提现到微信钱包,这个功能如果交给我们,该如何实现?
本文将大家搞定这个问题,这个场景算是分布式事务中比较有代表性的一个案例,大家大概率会遇到类似的场景,望大家掌握
b.方案
使用MQ最终一致性解决
02.代码实战
a.准备2个表
账号表和提现记录表,账户表插入了一个用户,等会会模拟从这个账号中提现100到微信钱包
-----------------------------------------------------------------------------------------------------
-- 创建账户表
drop table if exists t_account_lesson037;
create table if not exists t_account_lesson037
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额'
) comment '账户表';
insert ignore into t_account_lesson037 value ('1','路人1','1000.00');
-- 提现记录表
drop table if exists t_cash_out_lesson037;
create table if not exists t_cash_out_lesson037
(
id varchar(32) not null primary key comment '用户id',
account_id varchar(32) not null comment '账号id',
price decimal(12, 2) not null comment '提现金额',
status smallint not null comment '状态,0:待处理,100:提现成功',
create_time datetime not null comment '创建时间',
update_time datetime comment '最后更新时间'
) comment '提现记录表';
b.提现接口
com.itsoku.lesson037.controller.AccountController#cashOut
-----------------------------------------------------------------------------------------------------
主要干了3件事情
1.扣减账户余额
2.创建提现记录,状态为0(处理中)
3.发送提现消息(这块必须是事务消息,可以确保业务执行成功,消息一定会投递成功,不会丢失)
c.提现消息消费者
com.itsoku.lesson037.consume.CashOutMsgConsumer#consume
-----------------------------------------------------------------------------------------------------
主要干了2件事
1.调用微信支付接口给个人钱包打款:微信支付接口天然支幂等,如果也遇到了需要调用第三方接口的场景,也需要对方做幂等,这块可以参考微信支付接口或者支付宝接口
2.将提现记录状态置为成功(status=100)
-----------------------------------------------------------------------------------------------------
CashOutMsgConsumer 类继承了 com.itsoku.lesson037.mq.consumer.AbstractRetryConsumer,自动拥有了失败自动重试的功能
d.启动应用
com.itsoku.lesson037.Lesson037Application
e.先看db中账户余额
select * from t_account_lesson037;
f.执行测试用例
src/test/resources/AccountController.http
4.8 手写一个通用的TCC分布式事务框架
01.TCC相关概念
1.自研TCC框架设计思路
2.自研TCC框架,代码已落地,大家可以直接拿去用
3.演示效果(演示跨库转账3个场景)
4.源码解析
5.小结
02.什么是TCC?
a.分布式事务中的角色
TM:事务管理器,可以理解为分布式事务的发起者
分支事务:事务中的多个参与者,可以理解为一个个独立的事务
b.TCC的定义
TCC是 try、confirm、cancel三个词语的缩写,是分布式事务的一种解决方案
TCC要求每个分支事务实现三个操作:预处理try、确认confirm、撤销cancel
try:做业务检查及资源预留
confirm:做业务确认操作
cancel:实现一个与Try相反的操作即回滚操作
try有可能失败,但是confirm和cancel是一定会成功的,如果不成功,则经过重试一定会成功
c.正常流程
try阶段:依次调用参与者的try方法,都返回成功
confirm阶段:依次调用参与者的confirm方法,都返回成功
事务完成。
d.异常流程
try阶段:依次调用参与者的try方法,前面2个参与者try方法返回yes,而参与者3返回no
cancel阶段:对已经成功的参与者执行cancel操作,注意了:cancel阶段参与者调用的顺序和try阶段参与者的顺序相反,即先调用参与者2的cancel,然后调用参与者1的cancel
03.TCC场景案例
a.案例1:跨库转账
a.举例,场景为 A 转账 100 元给 B,A和B账户在不同的服务以及不同的库中
// 2个库都有一个账户表
create table if not exists t_account_lesson038
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额',
frozen decimal(12, 2) not null comment '冻结金额'
) comment '账户表';
b.采用tcc执行流程如下
a.账户A
try:
try幂等校验
检查余额是否够100元
A账户:可用余额-100,冻结金额+100
confirm:
try幂等校验
A账户:冻结金额-100
cancel:
cancel幂等校验
A账户:可用余额+100,冻结金额-100
b.账户B
try:
try幂等校验
B账户:冻结金额+100
confirm:
confirm幂等校验
B账户:冻结金额-100元,可用余额+100
cancel:
cancel幂等校验
B账户:冻结金额-100
b.案例2:提现到支付宝
a.说明
举例,大家玩过抖音,有些朋友抖音上面有收益,可以将收益提现到支付宝,假如提现100到支付宝
b.tcc事务分支1
try:
try幂等校验
检查余额是否够100元
抖音账户表余额-100,冻结金额+100
confirm:
confirm幂等校验
抖音账户冻结金额-100
cancel:
cancel幂等校验
抖音账户表余额+100,冻结金额-100
c.tcc事务分支2
try:
空
confirm:
confirm幂等校验
调用支付宝打款接口,打款100元(对于商户同一笔订单支付宝接口是支持幂等的)
cancel:
空
04.TCC常见框架
a.框架列表
框架名称 github地址 star数量
tcc-transaction https://github.com/changmingxie/tcc-transaction 5750
hmily https://github.com/Dromara/hmily 2900
ByteTCC https://github.com/liuyangming/ByteTCC 2450
EasyTransaction https://github.com/QNJR-GROUP/EasyTransaction 2100
b.说明
本文给大家分享的是自研
05.自研TCC框架设计思路(本文已落地实现)
a.涉及到的角色(事务发起者、事务参与者、TCC服务)
a.事务发起者(TM)
发起分布式事务:调用tcc服务注册一个分布式事务订单
调用分支:依次调用每个分支
上报结果:最终将事务所有分支的执行结果汇报给TCC服务
提供补偿接口:给TCC服务使用,tcc服务会调用这个补偿接口进行补偿操作
b.事务参与者
提供3个方法:try、confirm、cancel
确保3个方法的幂等性
3个方法返回的结果状态码只有3种(成功、失败、处理中),处理中相当于状态未知,对于状态未知的,会在补偿的过程中进行重试
c.TCC服务
是一个独立的服务
提供分布式事务订单注册接口:给事务发起者使用【事务发起者调用tcc服务生成一个分布式事务订单(订单状态:0:处理中,1:处理成功,2:处理失败),获取一个分布式订单id:TID】
提供分布式事务结果上报接口:给事务发起者使用【事务发起者在事务的执行过程中将事务的执行结果汇报给TCC服务】
提供事务补偿操作:启动一个job轮询tcc订单中状态为0的订单,继续调用事务发起者进行补偿,最终经过多次补偿,这个订单最终的状态应该为1(成功)或者2(失败);否则人工介入进行处理
b.自研TCC框架技术要点
a.框架应该考虑的地方
开发者应该只用关注分支中3个方法的代码,其他的应该全部交由框架去完成。
b.tcc服务中的事务记录表设计
id:tcc记录id
bus_id:业务方业务id
bus_type:业务类型 (bus_id& bus_type需唯一)
request_data:业务请求数据,json格式存储
status:状态,0:处理中,1:处理成功,2:处理失败,初始状态为0,最终必须为1或者2
c.关于分支中3个方法幂等的设计
以java中的spring为例,可以通过拦截器来实现,拦截器对分支的3个方法进行拦截,拦截器中实现幂等性的操作。
可以用一张表来实现【分支方法执行记录表:tccRecordId(也就是上面说的tid,分布式事务记录id)、分支、方法(try、confirm、cancel)、状态(0:处理中;1:成功;2:失败)、request_json(请求参数)、response_json(响应参数)】
关于请求参数:这个用来记录整个方法请求的完整参数,内部包含了业务参数,可以采用json格式存储。
响应参数:分支方法的执行结果,以json格式存储。
拦截器中,通过分支 & 方法 这2个条件去查询分支方法执行记录表,如果查询的记录状态为1或者2,那么直接将response_json返回。
d.try阶段同步、其他阶段异步
如果try阶段全部成功,那么confirm阶段最终应该一定是成功的,try阶段如果有失败的,那么需要执行cancel,最终所有的cancel应该也是一定可以成功的;所以try阶段完成之后,其实已经知道最终的结果了,所以try阶段完成之后,后面的confirm或者cancel可以采用异步的方式去执行;提升系统整体的性能。
e.异步上报事务执行结果
发起方将所有分支每个步骤的执行结果及最终事务的执行结果上报给tcc服务,由tcc服务落库,方便运营人员查看事务执行结果以及排错。
f.关于补偿
tcc服务中添加一个补偿job,定时轮询tcc分布式订单表,将状态为处理中的记录撸出来,订单表request_data包含了请求参数,使用request_data去调用事务发起者提供的补偿接口进行补偿操作,直到订单的状态为最终状态(成功或者失败)。
补偿采用衰减的形式,对应同一笔订单采用时间间隔衰减的方式补偿,每次间隔时间:10s、20s、40s、80s、160s、320s。。。
g.人工干预
tcc分布式订单如果长期处于处理中,经过了很多次的补偿,也未能到达最终状态,此时可能业务有问题,需要人工进行补偿,对于这对订单记录需要有监控系统进行报警,提醒开发者进行干预处理。
06.先看效果
a.演示跨库转账3个场景
跨库转账:执行成功的情况
跨库转账:执行失败的情况
跨库转账:测试自动补偿的情况
b.跨库转账涉及到3个服务
TccService:TCC服务
TccBranch1Service:跨库转账操作的发起者,也是转账第1个分支,负责发起分布式事务,操作付款人账户,从付款人账户扣款
TccBranch2Service:跨库转账第2个分支,操作收款人账户,给收款人账户打款
c.3个服务对应3个数据库
/* tcc 分布式事务服务库*/
DROP DATABASE IF EXISTS tcc;
CREATE DATABASE tcc;
/*tcc_service1:付款人账户所在库*/
DROP DATABASE IF EXISTS tcc_service1;
CREATE DATABASE tcc_service1;
/*tcc_service2:收款人账户所在库*/
DROP DATABASE IF EXISTS tcc_service2;
CREATE DATABASE tcc_service2;
d.2个账户库:创建表和测试数据
use tcc_service1;
drop table if exists t_account_lesson038;
create table if not exists t_account_lesson038
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额',
frozen decimal(12, 2) not null comment '冻结金额'
) comment '账户表';
insert ignore into t_account_lesson038 value ('1','A','1000.00','0.00');
use tcc_service2;
drop table if exists t_account_lesson038;
create table if not exists t_account_lesson038
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额',
frozen decimal(12, 2) not null comment '冻结金额'
) comment '账户表';
insert ignore into t_account_lesson038 value ('2','B','0.00','0.00');
f.启动3个服务
com.ms.dts.service.TccService
com.itsoku.lesson038.service1.TccBranch1Service
com.itsoku.lesson038.service2.TccBranch2Service
g.演示:跨库转账:执行成功的情况
a.lesson038/service1/src/test/resources/TransferController.http
### 1、跨库转账:正常情况
POST http://localhost:9101/transfer
Accept: application/json
Content-Type: application/json
{
"fromAccountId": "1",
"toAccountId": "2",
"transferPrice": "10.00"
}
b.查看2个库账户的资金信息
-- 付款方
select * from tcc_service1.t_account_lesson038;
-- 收款方
select * from tcc_service2.t_account_lesson038;
c.查看tcc分布式事务记录
http://localhost:9100/tccRecord/list
h.演示:跨库转账:执行失败的情况
a.lesson038/service1/src/test/resources/TransferController.http
# 下面转账人账户不存在,会导致分布式事务第二个分支的try方法执行失败
### 2、跨库转账:异常情况,目标账户不存在
POST http://localhost:9101/transfer
Accept: application/json
Content-Type: application/json
{
"fromAccountId": "1",
"toAccountId": "3",
"transferPrice": "10.00"
}
b.查看2个库账户的资金信息
-- 付款方
select * from tcc_service1.t_account_lesson038;
-- 收款方
select * from tcc_service2.t_account_lesson038;
c.查看tcc分布式事务记录
http://localhost:9100/tccRecord/list
i.演示:跨库转账:测试自动补偿的情况
a.lesson038/service1/src/test/resources/TransferController.http
# 把TccBranch2Service停掉,然后执行下面测试代码
### 3、跨库转账:测试自动补偿,把TccBranch2Service停掉,会导致第2个分支调用失败,然后再重启,重试
POST http://localhost:9101/transfer
Accept: application/json
Content-Type: application/json
{
"fromAccountId": "1",
"toAccountId": "2",
"transferPrice": "10.00"
}
b.查看2个库账户的资金信息
-- 付款方
select * from tcc_service1.t_account_lesson038;
-- 收款方
select * from tcc_service2.t_account_lesson038;
c.查看tcc分布式事务记录
http://localhost:9100/tccRecord/list
启动TccBranch2Service,在http://localhost:9100/tccRecord/list中点击重试,进行补偿,可以看到分布式事务执行成功了
07.源码解析
a.DefaultTccProcessor:TCC分布式事务的核心代码
入口:com.ms.dts.business.service.tcc.DefaultTccProcessor#dispose,主要逻辑如下:
1.调用TccServcie服务,创建分布式事务记录
2.依次调用分支的try方法
3.依次调用分支的confirm方法(如果try阶段失败了,则会走分支的cancel方法)
4.将分支的每个方法(try、confirm、cancel)执行日志上报给TccService服务
b.2个核心拦截器
com.ms.dts.business.service.tcc.interceptor.TccBranchStepBeforeInterceptor:在Spring事务拦截器之前执行
com.ms.dts.business.service.tcc.interceptor.TccBranchStepAfterInterceptor:在Spring事务拦截器后面执行
-----------------------------------------------------------------------------------------------------
1.负责拦截分支中的3个方法(try、confirm、cancel)
2.分支中3个方法的幂等性是依靠这2个拦截器实现的
3.这2个拦截器会记录分支中3个方法的执行日志(包含了方法的入参、返回值,都会序列化为json数据存储到db中)
c.tcc服务中3个关键表
-- tcc分布式事务记录表
drop table if exists t_tcc_record;
create table if not exists t_tcc_record
(
id varchar(32) not null primary key comment '订单id',
bus_type varchar(100) not null comment '业务类型',
bus_id varchar(100) not null comment '业务id',
classname varchar(500) not null comment '事务发起者',
status smallint not null default 0 comment '状态,0:待处理,1:处理成功,2:处理失败',
service_application_name varchar(1000) not null comment '事务发起者服务名称,也可能是服务地址',
beanname varchar(500) not null comment '事务发起者bean名称',
request_data longtext not null comment '请求参数json格式',
next_dispose_time bigint not null default 0 comment '下次处理时间',
max_failure int not null default 50 comment '最大允许失败次数',
failure int not null default 0 comment '当前已失败次数',
addtime bigint not null default 0 comment '创建时间',
uptime bigint not null default 0 comment '最后更新时间',
version bigint not null default 0 comment '版本号,每次更新+1',
unique key uk_1 (bus_type, bus_id)
) comment 'tcc分布式事务记录表';
-----------------------------------------------------------------------------------------------------
-- tcc分布式事务->分支日志记录表
drop table if exists t_tcc_branch_log;
create table if not exists t_tcc_branch_log
(
id varchar(32) not null primary key comment '主键',
tcc_record_id varchar(32) not null comment '事务记录id发,来源于t_tcc_record表的id',
classname varchar(500) not null comment '分支完整类名',
method varchar(100) not null comment '方法,0:try1,1:confirm,2:cancel',
msg varchar(200) comment '分支执行结果',
status smallint not null default 0 comment '状态,0:待处理,1:处理成功,2:处理失败',
context longtext not null comment '上下文信息,json格式',
addtime bigint not null default 0 comment '创建时间',
uptime bigint not null default 0 comment '最后更新时间',
version bigint not null default 0 comment '版本号,每次更新+1',
unique key uk_1 (tcc_record_id, classname, method),
key idx_tcc_record_id (tcc_record_id)
) comment 'tcc分布式事务->分支日志记录表';
-----------------------------------------------------------------------------------------------------
-- tcc分布式事务->补偿日志表
drop table if exists t_tcc_dispose_log;
create table if not exists t_tcc_dispose_log
(
id varchar(32) not null primary key comment '主键',
tcc_record_id varchar(32) not null comment '事务记录id发,来源于t_tcc_record表的id',
msg longtext comment '执行结果',
starttime bigint not null default 0 comment '开始时间(时间戳)',
endtime bigint not null default 0 comment '结束时间(时间戳)',
addtime bigint not null default 0 comment '创建时间(时间戳)',
key idx_tcc_record_id (tcc_record_id)
) comment 'tcc分布式事务->补偿日志表';
d.业务库:分支日志记录表
分支中3个方法的执行日志,都会记录到下面这个表中,包含了方法入参、返回值
都会被序列化为json格式的字符串保存到这个表中
-----------------------------------------------------------------------------------------------------
-- tcc分布式事务->业务库->分支日志记录表
drop table if exists t_tcc_bus_branch_log;
create table if not exists t_tcc_bus_branch_log
(
id varchar(32) not null primary key comment '主键',
tcc_record_id varchar(32) not null comment '事务记录id发,来源于t_tcc_record表的id',
classname varchar(500) not null comment '分支完整类名',
method varchar(100) not null comment '方法,0:try1,1:confirm,2:cancel',
msg varchar(200) comment '分支执行结果',
status smallint not null default 0 comment '状态,0:待处理,1:处理成功,2:处理失败',
context longtext not null comment '上下文信息,json格式',
addtime bigint not null default 0 comment '创建时间',
uptime bigint not null default 0 comment '最后更新时间',
version bigint not null default 0 comment '版本号,每次更新+1',
unique key uk_1 (tcc_record_id, classname, method),
key idx_tcc_record_id (tcc_record_id)
) comment 'tcc分布式事务->业务库->分支日志记录表';
e.com.ms.dts.tcc.branch.ITccBranch:Tcc分支接口
该接口中定义了分支用到的3个方法,TCC中的分支需要实现该接口,然后实现里面的3个方法
-----------------------------------------------------------------------------------------------------
public interface ITccBranch<T extends ITccBranchRequest> {
String TRY1_METHOD = "try1";
String CONFIRM_METHOD = "confirm";
String CANCEL_METHOD = "cancel";
/**
* tcc->try方法
*
* @param context
* @return
*/
ResultDto<TccBranchContext<T>> try1(TccBranchContext<T> context);
/**
* tcc->confirm方法
*
* @param context
* @return
* @throws Exception
*/
ResultDto<TccBranchContext<T>> confirm(TccBranchContext<T> context);
/**
* tcc->confirm方法
*
* @param context
* @return
* @throws Exception
*/
ResultDto<TccBranchContext<T>> cancel(TccBranchContext<T> context);
}
f.TCC 补偿相关代码
下面这个方法,可以对某个tcc记录进行补偿
-----------------------------------------------------------------------------------------------------
com.ms.dts.service.tcc.bus.impl.TccBusImpl#recover
g.TCC 补偿JOB
处理需要补偿的tcc记录,会对这些记录发起重试
-----------------------------------------------------------------------------------------------------
com.ms.dts.service.tcc.job.TccJob#recover
08.如何使用?
a.引入maven配置
<dependency>
<groupId>com.itsoku</groupId>
<artifactId>p-dts-business-service-starter</artifactId>
</dependency>
b.参考跨库转账案例
com.itsoku.lesson038.service1.controller.TransferController#transfer
c.定义TCC事务处理器
需要继承DefaultTccProcessor,如问案例中的跨库转账
com.itsoku.lesson038.service1.bus.TransferTccProcess
d.定义分支,并实现3个方法
分支需要实现com.ms.dts.tcc.branch.ITccBranchBus接口,然后实现其内部的3个方法,如下:跨库转账的2个分支
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson038.service1.bus.TransferTccBranch1
com.itsoku.lesson038.service2.bus.TransferTccBranch2
-----------------------------------------------------------------------------------------------------
程序如何判断分支中某个方法是否执行成功?
方法上有@Transactional,表示有事务,若方法没有异常,表示当前方法执行成功
方法上没有@Transactional,表示没有事务,方法内部需要告知调用方是否成功,需通过context.getResponse().setResultStatus设置当前方法的执行结果
e.将2个分支添加到TCC事务处理器中,并指定顺序
这里参考跨库转账的代码,如下,下面引入了2个分支,并在分支上需要使用`@TccBranchOrder`注解标注分支的执行顺序
-----------------------------------------------------------------------------------------------------
@Component
public class TransferTccProcess extends DefaultTccProcessor<TransferTccBranchRequest> {
@TccBranchOrder(1)
@Autowired
private TransferTccBranch1 transferTccBranch1;
@TccBranchOrder(2)
@Autowired
private TransferTccBranch2Client transferTccBranch2;
}
09.TCC对代码入侵性非常强
业务逻辑的每个分支都需要实现try、confirm、cancel三个操作,代码量比较大,对于事务参与者很多的场景,可以使用
比如某个业务涉及到>=3个以上的分支事务时,可以采用TCC的方式,若只有2个参与者,可以考虑使用MQ最终一致性解决
4.9 分布式锁详解
01.本文主要内容
什么是分布式锁?
使用场景
分布式锁的一些特性
分布式锁需要考虑的一些问题
分布式锁常见的 3 种实现方案
分布式锁100%可靠么?
02.什么是分布式锁?
java中的synchronized、ReentrantLock大家都有用过吧,可以确保在单个jvm中,多线程访问共享资源安全性
当多个线程访问共享资源的时候,用 synchronized、ReentrantLock 将共享资源包裹起来,可确保共享资源只能被串行访问
通常我们的系统都是集群部署的,一套代码会部署很多份,遇到这种情况,上面的解决方式就失效了,而分布式锁便可以解决这个问题
如下图,3个客户端都想访问左边的共享资源,但是这个共线资源同一时间只允许一个客户端访问
那么这个地方就可以使用分布式锁,客户端需要先获取分布式锁,获取到锁之后才能访问共享资源
03.使用场景
防止重复处理
04.分布式锁的需要具备的一些特性
a.互斥性
在任何时刻,只能有一个客户端持有锁,其他客户端不能同时持有该锁
b.安全性
在锁被释放之前,任何其他客户端都不能获得该锁
c.可重入性
同一个线程获取锁之后,也可以再次获取这个锁
d.支持尝试获取锁和等待获取锁,通常需要支持2种方式获取锁
a.无等待时间的
不管能否获取到,都应该立即返回,比如ReentrantLock中的`public boolean tryLock()`,分布式也应该支持这种方式
b.时等待时间的
可以指定一个超时时间,在这个时间内尝试获取锁,超过了这个时间还未获取到锁,也应该返回,比如下面这个方法
public boolean tryLock(long timeout, TimeUnit unit)
e.高效性
加锁和解锁需要高效
05.分布式锁需要考虑的一些问题
a.防止死锁
a.为什么会出现死锁?
使用者获取锁之后,锁还未被释放前,使用者突然挂掉了,此时其他使用者要能够获取到此锁
b.这种情况如何解决?引入超时时间
引入超时时间,上锁时,给锁设置一个超时时间,超时时间到了之后,锁自动释放
这里又会出现另外一个问题,锁的超时时间设置多长时间比较合适呢?
这个时间难以评估,比如超时时间设置了10秒,但是程序使用锁的时间可能会超过10秒
此时由于超时锁被释放了,导致其他使用者获取了锁,此时相当于多个使用者同时持有锁
会出现意想不到的问题,如何避免这个问题呢?可以引入锁自动续期功能
b.锁自动续期功能
锁的过期时间,不好评估,设置比较短的话会有提前过期的风险,设置的长,可能导致锁长时间得不到释放
这种情况,我们可以引入自动续期的功能,可以开启一个线程,定时的去看下
使用锁的线程是否还活着,如果还在使用,则对锁进行续期,及延长锁的过期时间
java中的Redisson就用到这个功能(watch dog),俗称看门狗
c.如何防止锁的误删?
a.什么是误删?
锁使用完成之后,会进行释放,释放通常就是把锁删掉,这里存在误删的可能性
比如:A获取到分布式锁LOCK1之后,去执行业务,由于机器卡主了,导致锁超时了
此时B获取了分布式锁LOCK1,过了一会,A又恢复过来了,然后执行完业务之后,去释放锁,此时会把B持有的锁给释放掉
b.如何避免误删?
A获取锁的时候,可以生成一个唯一标识,将这个唯一标识放在锁中,释放锁的时候
判断这个唯一标识和A手中的唯一标识是不是一致,若一致,则执行锁的释放操作
大致过程如下,不过这个过程一定要具有原子性
也就是说当有多个线程同时执行下面这个操作的时候,会排队执行,这种情况便可避免误删
-------------------------------------------------------------------------------------------------
if(判断锁是不是自己持有的){
释放锁
}
-------------------------------------------------------------------------------------------------
可以参考Redisson 中释放锁的逻辑,他里面使用lua脚本实现的。
在Redis中,Lua脚本能够保证原子性的主要原因还是Redis采用了单线程执行模型
也就是说,当Redis执行Lua脚本时,Redis会把Lua脚本作为一个整体并把它当作一个任务加入到一个队列中
然后单线程按照队列的顺序依次执行这些任务,在执行过程中Lua脚本是不会被其他命令或请求打断
因此可以保证每个任务的执行都是原子性的
06.分布式锁常见的实现方式(3种)
a.方式1:redis 实现分布式锁
a.使用Redisson
这块推荐大家使用Redisson,非常好用的一个java版本的redis工具包,里面已经帮我们实现了分布式锁
b.加锁核心代码
采用lua脚本实现的,主要代码如下
redis中命令的执行是单线程的,lua 脚本(下面一整段命令)也被当做一个命令执行
意味着同一时间只有一个命令在redis中运行,所以下面命令可以确保多客户端同时获取锁的情况下,只有一个可以成功获取锁
-------------------------------------------------------------------------------------------------
org.redisson.RedissonLock#tryLockInnerAsync
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
// 上锁成功的条件:锁不存在 || 锁是当前线程持有的
"if ((redis.call('exists', KEYS[1]) == 0) " + // 判断锁是否不存在?
"or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then " + // 判断锁是否是自己持有的?hash结构
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + // 将锁的持有次数+1
"redis.call('pexpire', KEYS[1], ARGV[1]); " + // 设置过期时间
"return nil; " + // 返回 null
"end; " +
"return redis.call('pttl', KEYS[1]);", // 若未获取到锁,则返回锁的过期时间,获取则拿到这个时间可以知道自己应该等待多久
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
c.释放锁的核心代码
采用lua脚本实现的,主要代码如下
-------------------------------------------------------------------------------------------------
org.redisson.RedissonLock#unlockInnerAsync
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 判断锁 key 是否存在
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
// 将该客户端对应的锁的 hash 结构的 value 值递减为 0 后再进行删除
// 然后再向通道名为 redisson_lock__channel publish 一条 UNLOCK_MESSAGE 信息
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getRawName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}
-------------------------------------------------------------------------------------------------
主要干了2件事情
1.删除锁(删除的过程件上面的描述,由于锁是可重入的,获取锁的次数为0的时候,才会将锁删除)
2.广播一条消息,锁删除之后,会广播锁释放的消息,这样其他等待获取该锁的线程会被唤醒
-------------------------------------------------------------------------------------------------
这里说一下,如果一个线程没有获取到这个分布式锁,那么这个线程就会订阅这个分布式锁的释放事件
接着阻塞自己,如果锁释放的时候,就会广播事件,那么阻塞的线程就会被唤醒,被唤醒后会再次尝试去获得锁
b.方式2:zookeeper临时顺序节点+watch机制
a.临时节点
当zk的客户端和zk断开连接的时候,临时节点会自动删除
zk客户端有2种下线方式
主动的方式,客户端主动和zk断开连接
被动的方式:zk客户端会按照指定的频率向zk发送心跳,超过某个时间zk未收到客户端的心跳,则zk认为客户端已断开连接了连接,此时临时节点会被删除
b.顺序节点
zk可以确保确保某个某个节点下创建的所有子节点的顺序性
c.watch机制
zk客户端可以去监听zk中的某个节点,当被监听的节点被删掉的时候,会给客户端的监听者发送通知
d.加锁过程
1.在/lock节点下创建一个临时顺序节点
2.判断自己创建的节点是不是/lock下面编号最小的顺序节点
是,则获取锁成功
不是,则对前一个节点进行监听(watch)
e.释放锁的过程
将自己这个临时节点删掉
zk会自动给监听这个节点的客户端发送通知,下一个节点会被唤醒,然后又会进入上面加锁的第2步
c.方式3:数据库实现
可以看我之前写的这篇文章,使用唯一约束+乐观锁实现的
07.如何选择?
性能上来说:redis版性能最高,zk随后,不过都需要引入中间件,对运维要求比较高
若不想引入第三方中间件,且对性能要求没有那么高,可以采用数据库实现
08.分布式锁100%靠谱么?
a.分布式锁并非100%靠谱
分布式锁99.99%的情况下,是靠谱的
以redisson为例,当程序A获取到分布锁,cpu切换到其他程序了,此时程序A就像卡主了一样
A中的所有线程都卡主了,假如卡了1分钟后,恢复了,此时锁由于超时被释放了,会导致同一个锁被多个客户端获取
zk也一样,zk客户端获取分布式锁以后,假如程序也卡主了,导致无法向zk发送心跳
zk以为客户端挂掉了,此时锁会被释放,也会导致同一个锁被多个客户端获取的可能性
数据库版的分布式锁也存在这个问题,主要是锁存在超时时间,过了超时时间锁会被自动释放,但是程序可能并没有释放锁导致的
Redisson中还有红锁,同样也会出现这个问题,只是可能性更小一些
b.业务上做好兜底
虽然分布式锁理论上可能存在问题,但是这并不影响我们使用它,分布式锁性能高,我们将其作为第一道防线,程序本身自己还要去做兜底的工作
比如幂等操作,分布式锁能帮忙拦一道,但是最终幂等业务方自己还需要兜底,比如使用数据库的唯一约束兜底,这个不可少
4.10 一个Redis分布式锁工具类
01.本文主要内容
分享一个特别好用redis分布式锁工具类,使用Redisson实现的,对其进行了封装,用起来特别优雅,方便
02.核心代码
com.itsoku.lesson040.lock.DistributeLock
com.itsoku.lesson040.lock.RedisDistributeLock
---------------------------------------------------------------------------------------------------------
工具里面的方法都包含了获取锁的过程、执行业务、释放锁的过程,使用者不用关注锁的获取和释放了,这样使用起来特别方便
03.测试类
a.测试用例1:无阻塞式获取锁
com.itsoku.lesson040.TestController#tryLockRun
测试地址:http://localhost:8080/tryLockRun
b.测试用例2:获取锁有超时时间
com.itsoku.lesson040.TestController#tryLockRunWaitTime
测试地址:http://localhost:8080/tryLockRunWaitTime
c.测试用例3:获取锁会阻塞,直到成功获取锁
com.itsoku.lesson040.TestController#lockRun
测试地址:http://localhost:8080/lockRun
04.如何使用?
a.引入redisson配置
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.20.1</version>
<exclusions>
<exclusion>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-data-30</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-data-24</artifactId>
<version>3.20.1</version>
</dependency>
<!-- redisson -->
b.application.yml中配置锁的前置
锁设置前缀,一个为了避免和其他系统命名冲突,另外一点是方便知道这个key是来自于哪个服务,可以采用下面的方式命令
-----------------------------------------------------------------------------------------------------
distribute:
lock:
prefix: '${spring.application.name}:lock:'
c.业务中注入 DistributeLock
@Autowired
private DistributeLock distributeLock;
d.使用 DistributeLock 接口中的方法加锁执行业务
// 无阻塞的方式获取锁,然后执行业务,释放锁,返回true
boolean lockResult = this.distributeLock.tryLockRun("lock1", () -> {
log.info("获取锁成功,执行业务");
});
// 尝试获取锁,最多等待5秒,获取锁成功则执行业务,释放锁,返回true;5秒还未获取到锁,则返回false
boolean lockResult = this.distributeLock.tryLockRun("lock1", () -> {
log.info("获取锁成功,执行业务");
}, 5, TimeUnit.SECONDS);
// 获取锁的过程会阻塞,直到获取锁成功,然后执行业务,释放锁
this.distributeLock.lockRun("lock1", () -> {
log.info("获取锁成功,执行业务");
});
5 part04
5.1 一个注解轻松搞定分布式锁
01.说明
通过一个@Lock注解,轻松搞定接口加分布式锁。
02.代码
com.itsoku.lesson041.OrderController#orderPay
5.2 微服务中如何传递公共参数
01.背景
微服务调用的流程图
02.有5个地方需要考虑
a.gateway将公共参数放到请求中传递给下层服务
gateway转发请求前,将公共的参数添加请求头中向下传递便可
b.微服务中需要一个Filter读取公共参数丢到ThreadLocal中
com.itsoku.lesson042.common.context.SystemContextFilter
com.itsoku.lesson042.common.context.SystemContext
com.itsoku.lesson042.common.context.SystemContextHolder
c.OpenFeign发送请求前,将公共参数丢到请求头中进行传递
com.itsoku.lesson042.common.context.SystemContextRequestInterceptor
public class SystemContextRequestInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
// 从ThreadLocal中拿到公共上线文参数,放到 OpenFeign 请求头中
for (Pair<String, String> header : SystemContextHolder.getSystemContext().toHeaders()) {
template.header(header.getKey(), header.getValue());
}
}
}
d.RestTemplate发送请求前,将公共参数丢到请求头中进行传递
com.itsoku.lesson042.common.context.SystemContextRestTemplateRequestCustomizer
public class SystemContextRestTemplateRequestCustomizer implements RestTemplateRequestCustomizer {
@Override
public void customize(ClientHttpRequest request) {
// 从ThreadLocal中拿到公共上线文参数,放到 RestTemplate 请求头中
for (Pair<String, String> header : SystemContextHolder.getSystemContext().toHeaders()) {
request.getHeaders().add(header.getKey(), header.getValue());
}
}
}
-----------------------------------------------------------------------------------------------------
RestTemplate定义需要采用下面这种方式
@Bean
public RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder) {
return restTemplateBuilder.build();
}
e.线程池中需要要能够读取到这些公共参数
需要使用我们自定义的线程池,如下
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson042.common.thread.CommonThreadPoolExecutor
-----------------------------------------------------------------------------------------------------
重写了submit和execute方法,可以实现调用者和线程池间ThreadLocal中的数据共享。
看个案例,代码如下,这里会将公共参数放到线程池的线程中
-----------------------------------------------------------------------------------------------------
private ThreadPoolExecutor threadPoolExecutor = new CommonThreadPoolExecutor(new CommonThreadPoolExecutor.ThreadLocalContext() {
@Override
public Object getContext() {
return SystemContextHolder.getSystemContext().getContextMap();
}
@Override
public void setContext(Object context) {
SystemContextHolder.getSystemContext().getContextMap().putAll((Map<? extends String, ? extends String>) context);
}
}, 5, 5, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
04.测试用例
a.准备2个服务
service1:com.itsoku.lesson042.service1.Lesson042Service1Application
service2:com.itsoku.lesson042.service2.Lesson042Service2Application
b.service1中测试5中情况,代码如下
com.itsoku.lesson042.service1.Service1Controller#test1
c.运行看效果
src/test/resources/Service1Controller.http
-----------------------------------------------------------------------------------------------------
### 上下文测试
GET http://localhost:8080/service1/test1
itsoku-header-user_id: 10001
itsoku-header-local: zh_cn
itsoku-header-user_name: luren
d.走gateway看下效果
启动gateway服务
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson042.gateway.Lesson042GatewayApplication
-----------------------------------------------------------------------------------------------------
通过gateway去访问刚才上面的接口
-----------------------------------------------------------------------------------------------------
### 走 gateway 访问 service1中的test1 接口
GET http://localhost:8080/lesson042-service1/service1/test1
itsoku-header-local: zh_cn
token: itsoku
-----------------------------------------------------------------------------------------------------
这个请求会打到gateway,gateway中我们搞了个拦截器,如下,这里面会校验token,验证通过后,会放入用户id和用户名
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson042.gateway.AuthFilter
-----------------------------------------------------------------------------------------------------
运行测试用例看效果
5.3 接口幂等的通用方案
01.幂等
a.定义
幂等指多次操作产生的影响只会跟一次执行的结果相同,通俗的说:某个行为重复的执行,最终获取的结果是相同的
b.接口
同一个接口,对于同一个请求,不管调用多少次,产生的最终结果都应该是一样的
b.例子
比如账户A给账户B转账100元,最终要么成功要么失败
对于成功的情况,这个请求不管再请求多少次,最终的结果:A给B只成功转入了100元,不会出现重复处理的情况
对于失败的情况,这个请求不管再请求多少次,转账都是失败
即成功或者失败后,不管如何重试,结果都不会再发生变化,这点大家一定要理解
02.接口幂等需要考虑的点
a.如何确定是同一个请求?
可以在请求参数中添加一个通用的参数requestId,多个请求requestId相同的,则表示他们是相同的请求
b.接口的执行结果只有3种情况
对于幂等性的接口,执行结果可以抽象为下面3种情况
0:处理中
1:处理成功
-1:处理失败
-----------------------------------------------------------------------------------------------------
返回给调用方的结果,只能是其中一种状态
但是最终,接口的状态只能是成功或者失败,比如刚开始状态可能返回的是0(处理中),经过调用方多次重试以后,状态必须为终态(成功或失败)
03.接口幂等通用方案如何实现?
a.方案
如下,咱们可以借助一张幂等辅助表,如下,通过这张表便可实现接口幂等通用方案
幂等接口对于同一个requestId,此表都会产生一条记录
此表会记录幂等接口调用的详细信息:请求id、请求的状态、请求参数json字符串、响应结果json格式字符串
记录的最终状态,一定会1或者-1,对于状态为0的,经过调用方的不断重试,status会变为1或者-1
当status为1或者-1后,response_json即为接口最终返回值
-----------------------------------------------------------------------------------------------------
create table t_idempotent_call
(
id varchar(50) primary key comment 'id,主键',
request_id varchar(128) not null comment '请求id,唯一',
status smallint not null default 0 comment '状态,0:处理中,1:处理成功,-1:处理失败',
request_json mediumtext comment '请求参数json格式',
response_json mediumtext comment '响应数据json格式',
version bigint not null default 0 comment '版本号,用于乐观锁,每次更新+1',
create_time datetime comment '创建时间',
update_time datetime comment '最后更新时间',
unique key uq_request_id (request_id)
) comment '幂等调用辅助表';
04.代码
a.IdempotentCall:幂等调用顶层接口
需要实现幂等业务,需要实现该接口
b.DefaultIdempotentCall:IdempotentCall接口默认实现
核心代码,上面流程图中除了红色的代码,其他的部分都在这个类中实现了
05.案例
a.需求
提供一个转账接口,此接口需要支持幂等
b.准备测试数据
-- 创建账户表
drop table if exists t_account_lesson043;
create table t_account_lesson043
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额'
) comment '账户表';
insert ignore into t_account_lesson043 value ('1','路人1','100.00');
insert ignore into t_account_lesson043 value ('2','路人2','0.00');
c.源码
com.itsoku.lesson043.controller.AccountController#transfer
d.场景测试1:模拟正常转账
测试代码如下,从账号1中给账号2转10元,请求id为100000001,我们执行两次,观察执行结果,以及db中数据的变化
-----------------------------------------------------------------------------------------------------
src/test/resources/AccountController.http
-----------------------------------------------------------------------------------------------------
### 正常转账
POST http://localhost:8080/account/transfer
Content-Type: application/json
Accept: application/json
{
"requestId": "100000001",
"data": {
"fromAccountId": "1",
"toAccountId": "2",
"transferPrice": "10.00"
}
}
e.场景测试2:模拟失败的情况
测试代码如下,从账号1中给账号2转200元,请求id为100000002,账户1由于余额不足,下面的执行会失败
-----------------------------------------------------------------------------------------------------
src/test/resources/AccountController.http
-----------------------------------------------------------------------------------------------------
### 转账失败,余额不足
POST http://localhost:8080/account/transfer
Content-Type: application/json
Accept: application/json
{
"requestId": "100000002",
"data": {
"fromAccountId": "1",
"toAccountId": "2",
"transferPrice": "200.00"
}
}
-----------------------------------------------------------------------------------------------------
执行输出
-----------------------------------------------------------------------------------------------------
{
"success": true,
"data": {
"status": -1,
"code": null,
"message": "付款方余额不足",
"data": null
},
"msg": null,
"code": null
}
-----------------------------------------------------------------------------------------------------
我们把上面请求金额改为1元,按说余额是够的,然后再次执行看看
执行结果还是和第一次是一样的,因为结果已经保存到t_idempotent_call表了,对于同一个requestId
当t_idempotent_call表中的记录状态为1或者-1后,那么本次调用的结果就不会再发生变化了,这样完全符合接口幂等性要求
06.如何使用
a.转账案例
1.自定义一个类,继承DefaultIdempotentCall
2.实现 disposeLocalBus 方法,在里面写对应的业务代码
5.4 微服务链路日志追踪
01.微服务中,接口报错,如何快速定位问题?
需要日志的辅助,一般错误日志中有详细的堆栈信息,具体是哪行代码报错,都可以看到
要想快速定位问题,前提是要能够快速定位日志
但是微服务调用链路通常比较复杂,先来看下微服务常见的调用流程,如下图,一个请求可能会调用多个服务
02.解决方案:链路日志追踪
1.务端入口处,也就是gateway接收到请求后,可以生成一个唯一的id,记做:traceId,然后传给被调用的服务
2.个请求过程中,所有参与者,均需要将traceId向下传递,且日志中需要输出traceId的值
3.客户端的返回值中,添加一个通用的字段:traceId,将上面的traceId作为这个字段的值
4.客户端发现接口有问题的时候,直接将这个traceId提供给我们,我们便可以在日志中快速查询出对应的日志
系统需要将所有日志收集起来,存到ElasticSearch中,可以就可以通过traceId快速检索了
03.代码落地
a.gateway改造
所有的请会先到达gateway,这里可以添加一个拦截器,拦截所有的请求,在请求转发前,生成一个traceId,放到请求头中,向下传递即可
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson044.gateway.TraceFilter
b.下层微服务改造
下层微服务,也就是上图中最下面的部分:service1、service2、service3
添加一个Filter,拦截所有请求,从请求头中读取调用者传递过来的traceId,然后丢到ThreadLocal中和Logback中,这样日志中就会输出traceId
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson044.common.trace.TraceFilter
-----------------------------------------------------------------------------------------------------
MDC是logback为我们提供的一个扩展的入口,可以向里面放入一些键值对,然后在logback中的日志中就可以通过这个traceId获取到对应的值
如下,logback.xml中使用`%X{traceId}`可以获取到MDC中设置的traceId
c.OpenFeign改造
拦截 OpenFeign 所有请求,在 OpenFeign 发送请求前,将traceId放到请求头中,传递给被调用者
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson044.common.trace.TraceRequestInterceptor
d.RestTemplate 改造
拦截RestTemplate所有请求,在 RestTemplate 发送请求前,将traceId放到请求头中,传递给被调用者
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson044.common.trace.TraceRestTemplateRequestCustomizer
e.线程池改造
为什么需要改造线程池?
Logback日志中能输出traceId,底层是将traceId放到ThreadLocal中
但是ThreadLocal中的数据,在线程池中是获取不到的,所以需要对线程池进行改造
-----------------------------------------------------------------------------------------------------
需要使用我们自定义的线程池,如下
com.itsoku.lesson044.common.thread.CommonThreadPoolExecutor
-----------------------------------------------------------------------------------------------------
重写了submit和execute方法,可以实现调用者和线程池间ThreadLocal中的数据共享,这个自定义线程池,更详细的介绍可以看 26 节
这个自定义线程池,如何使用呢?
看个案例,代码如下,可以实现线程池使用者和线程池中的线程间traceId共享。
-----------------------------------------------------------------------------------------------------
private ThreadPoolExecutor threadPoolExecutor = new CommonThreadPoolExecutor(new CommonThreadPoolExecutor.ThreadLocalContext() {
@Override
public Object getContext() {
return TraceUtils.getTraceId();
}
@Override
public void setContext(Object traceId) {
TraceUtils.setTraceId((String) traceId);
}
}, 5, 5, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
-----------------------------------------------------------------------------------------------------
原理比较简单:使用线程池执行任务,最终都会调用execute、submit这两个方法,自定义线程池重写了这2个方法
调用这两个方法执行任务之前,会先调用ThreadLocalContext的第一个方法getContext从当前线程中拿到traceId
然后线程池内部真正执行任务的时候,又会调用ThreadLocalContext的第二个方法setContext
把第一个方法的返回值作为参数传递进去,这样线程池中执行任务的线程就可以拿到这个traceId了
04.测试效果
a.测试代码
com.itsoku.lesson044.service1.Service1Controller#test1
b.启动3个springboot应用
com.itsoku.lesson044.gateway.Lesson044GatewayApplication
com.itsoku.lesson044.service1.Lesson044Service1Application
com.itsoku.lesson044.service2.Lesson044Service2Application
c.浏览器中访问
http://localhost:8080/lesson044-service1/service1/test1
-----------------------------------------------------------------------------------------------------
此请求链路:gateway->service1->service2
大家注意看geteway以及2个服务中,输出的日志中traceId是不是一样
5.5 接口测试利器HTTP Client
01.基本使用
a.接口代码
com.itsoku.lesson045.IndexController
b.HTTP Client接口测试文件
### get 请求
GET http://localhost:8080/get
### post 提交表单
POST http://localhost:8080/post
Content-Type: application/x-www-form-urlencoded
name=路人&age=30
### body 中传递json数据
POST http://localhost:8080/body
Content-Type: application/json
[3,10,40]
### put请求
PUT http://localhost:8080/put
### 多文件上传文件接口测试
POST http://localhost:8080/upload
Content-Type: multipart/form-data; boundary=WebAppBoundary
--WebAppBoundary
Content-Disposition: form-data; name="file1"; filename="1.png"
< D:\code\likun_557\luren\document\img\MQ常见使用场景.png
--WebAppBoundary--
Content-Disposition: form-data; name="file2"; filename="2.png"
< D:\code\likun_557\luren\document\img\幂等接口通用实现.png
--WebAppBoundary--
Content-Disposition: form-data;name=userName
tom
--WebAppBoundary--
Content-Disposition: form-data;name=age
23
03.不同环境的支持
a.环境变量文件
{
"dev": {
"url": "http://localhost:8080"
},
"test": {
"url": "http://localhost:8080"
}
}
-----------------------------------------------------------------------------------------------------
引用环境变量,可以通过{{变量名称}},来引用环境的值
5.6 MyBatis实现通用CRUD框架
01.本文主要内容
对Mybatis进行封装,实现一个通用的无 SQL 版的 CRUD 功能 ORM 框架
MyBatis-plus 大家应该都比较熟悉吧,本文实现的功能,类似与Mybatis-plus功能,实现的原理非常的简单,这样方便大家扩展
不需要写一行sql,便可实现对数据库的 增、删、改、查、分页、统计、乐观锁更新数据等操作
02.本框架涵盖的功能
a.插入
1.插入记录:com.itsoku.orm.IService#insert
2.批量插入:com.itsoku.orm.IService#insertBatch
b.删除
1.根据主键删除记录:com.itsoku.orm.IService#deleteById
2.根据主键批量删除记录:com.itsoku.orm.IService#deleteByIds
3.根据条件删除记录:com.itsoku.orm.IService#delete
c.更新
1.根据主键,更新一条记录:com.itsoku.orm.IService#update
2.根据主键,更新一条记录,只更新非 null 字段:com.itsoku.orm.IService#updateNonNull
3.根据主键,更新一条记录,只更新指定的字段:com.itsoku.orm.IService#updateWith
4.根据主键+乐观锁,更新一条记录:com.itsoku.orm.IService#optimisticUpdate
5.根据主键+乐观锁,更新一条记录,只更新非 null 字段:com.itsoku.orm.IService#optimisticUpdateNonNull
6.根据主键+乐观锁,更新一条记录,只更新指定的字段:com.itsoku.orm.IService#optimisticUpdateWith
d.查询
1.根据条件查询记录:com.itsoku.orm.IService#find,基本上所有的查询条件都支持、支持查询部分列
2.查询满足的条件的一条记录:com.itsoku.orm.IService#findOne
3.根据主键查询记录:com.itsoku.orm.IService#findById
4.根据主键列表查询多条记录:com.itsoku.orm.IService#findByIds
5.根据主键列表查询记录,返回Map,key为主键,value为记录:com.itsoku.orm.IService#findMapByIds
e.数量统计
1.查询满足条件的记录数:com.itsoku.orm.IService#count
f.分页查询
1.通用分页查询方法:com.itsoku.orm.IService#findPage
03.效果演示
a.准备2张表
-- 创建用户表
drop table if exists t_user_lesson046;
create table t_user_lesson046
(
id bigint not null auto_increment primary key,
user_name varchar(100),
age int
);
insert into t_user_lesson046 (user_name, age)
values ('路人1', 10),
('路人2', 11),
('路人3', 20),
('路人4', 21),
('路人5', 22),
('路人6', 23),
('路人7', 30),
('路人8', 31),
('路人9', 32);
-----------------------------------------------------------------------------------------------------
-- 创建账户表
drop table if exists t_account_lesson046;
create table if not exists t_account_lesson046
(
id varchar(32) not null primary key comment '用户id',
name varchar(50) not null comment '用户名',
balance decimal(12, 2) not null comment '账户余额',
version bigint not null default 0 comment '版本号,默认为0,每次更新+1'
) comment '账户表';
-----------------------------------------------------------------------------------------------------
insert ignore into t_account_lesson046 value ('1', '路人1', '1000.00', 0);
-----------------------------------------------------------------------------------------------------
这两张表有点区别,用户表的id是自动增长的,账户表的id是插入的时候调用方填充进来的
第二张表有version字段,可以用于演示乐观锁更新数据
b.先演示对用户表的一些操作
a.用户实体类
com.itsoku.lesson046.po.UserPO
b.用户Mapper接口
com.itsoku.lesson046.mapper.UserMapper
需要继承`com.itsoku.orm.BaseMapper`,然后就拥有了上面说的增删改查分页通用的功能
c.用户service接口
com.itsoku.lesson046.service.IUserService
需要继承`com.itsoku.orm.IService`,这个接口中定义了通用的增删改查分页通用的功能
d.创建用户service接口实现类
com.itsoku.lesson046.service.impl.UserServiceImpl
需要继承`com.itsoku.orm.ServiceImpl`,这个类中包含了通用的增删改查分页通用的功能
c.测试效果
| 查询用户所有记录 | com.itsoku.lesson046.Lesson046ApplicationTest#test001 |
| -------------------------- | ----------------------------------------------------- |
| 查询需要的字段(id,name) | com.itsoku.lesson046.Lesson046ApplicationTest#test002 |
| 复杂条件分页查询 | com.itsoku.lesson046.Lesson046ApplicationTest#test003 |
| 插入用户记录 | com.itsoku.lesson046.Lesson046ApplicationTest#test101 |
d.演示对账户表的一些操作
主要演示乐观锁更新数据:com.itsoku.lesson046.Lesson046ApplicationTest#test204
04.更多案例
a.说明
下面所有案例均在`com.itsoku.lesson046.Lesson046ApplicationTest`类中
b.查询
| 测试方法 | 说明 | |
| -------- | --------------------------------------------------- | ---- |
| test001 | 查询所有用户 | |
| test002 | 要的字段(id、name) | |
| test003 | 复杂条件分页查询 | |
| test004 | 根据id查询 | |
| test005 | 根据id列表批量查询 | |
| test006 | 根据主键列表查询记录,返回Map,key为主键,map为记录 | |
| test007 | 查询满足条件的一条记录 | |
c.统计数量
| 测试方法 | 说明 |
| -------- | ---------------------- |
| test020 | 查询满足条件的记录数量 |
d.分页查询
| 测试方法 | 说明 |
| -------- | ------------------ |
| test030 | 分页查询用户记录 |
| test031 | 按条件分页查询 |
| test032 | 分页查询带转换功能 |
e.插入单条记录
a.id是自动增长类型的
com.itsoku.lesson046.Lesson046ApplicationTest#test101
主键上需要标注`@TableId(type = IdType.AUTO)`,参考`com.itsoku.lesson046.po.UserPO`
b.id 手动填充
com.itsoku.lesson046.Lesson046ApplicationTest#test101
f.批量插入
com.itsoku.lesson046.Lesson046ApplicationTest#test104
g.更新记录-普通更新
| 测试方法 | 说明 |
| -------- | ---------------------------------------- |
| test201 | 按照主键更新一个对象 |
| test202 | 按照主键更新一个对象,只更新非 null 字段 |
| test203 | 键更新一个对象,只更新指定的属性 |
h.更新记录-主键+乐观锁更新
对应的PO必须要有@Version标注的字段,字段类型只能是int、Integer、long、Long类型,参考AccountPO
| 测试方法 | 说明 |
| -------- | ----------------------------------------------------- |
| test204 | 按照主键和version字段作为条件更新 |
| test205 | 按照主键和version字段作为条件更新,只更新非 null 字段 |
| test206 | 按照主键和version字段作为条件更新,只更新指定的属性 |
i.删除记录
| 测试方法 | 说明 |
| -------- | -------------------- |
| test301 | 根据主键删除记录 |
| test302 | 根据主键批量删除记录 |
| test303 | 根据条件删除记录 |
05.源码解析
a.核心源码:com.itsoku.orm.BaseMapper
原理是使用MyBatis中的动态sql生成功能实现的,比如插入的方法
-----------------------------------------------------------------------------------------------------
/**
* 插入
*
* @param po
* @return
*/
@InsertProvider(type = SqlProvider.class, method = "insert")
int _insert(@Param("po") T po);
-----------------------------------------------------------------------------------------------------
这里用到了MyBatis提供的一个注解`@InsertProvider`,当执行上面这个插入方法的时候,会通过`SqlProvider#insert`方法获取需要执行的sql
Mybatis还提供3个类似的注解,如下
@UpdateProvider:动态生成更新的sql
@DeleteProvider:动态生成删除的sql
@SelectProvider:动态生成查询的sql
b.com.itsoku.orm.IService
里面定义的方法和 BaseMapper接口中定义的方法基本上一样
c.com.itsoku.orm.ServiceImpl
IServcie接口的默认实现,我们的service需要继承这个类,便拥有了增、删、改、查、分页、统计所有功能
06.注意事项
a.@TableName 注解
用户标注在PO上面,value为表名,如
-----------------------------------------------------------------------------------------------------
@Table("t_user_lesson046")
public class UserPO {
@TableId(type = IdType.AUTO)
private Long id;
@TableField("user_name")
private String userName;
private Integer age;
}
b.@TableFiled注解
标注在字段上,value为字段名称
表中字段的名称一般采用下划线分割多个单词,对应的java中属性的名称,会采用驼峰命名法
比如字段的名称为 user_name,对应的java中属性名称为userName
当字段满足上面这个规则的时候,@TableFiled字段可以省略,比如案例中的 UserPo中的@TableFiled可以省略
c.@TableId
实体类中,必须有主键,且上面必须加上 @TableId注解,标识这个字段是主键
-----------------------------------------------------------------------------------------------------
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})
public @interface TableId {
IdType type() default IdType.NONE;
}
---
注解有个 type属性,值如下,当主键是自增的时候,type的值为 AUTO
---
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO,
/**
* 该类型为未设置主键类型
*/
NONE;
}
5.7 MyBatisPlus实现多租户数据隔离
00.汇总
a.请求头中传递租户id
略
b.添加一个全局拦截器
将租户id读取出来,放到ThreadLocal中
c.添加一个mybatisplus多租户的拦截器:TenantLineInnerInterceptor
这个拦截器需要用到一个 TenantLineHandler 对象:自定义一个类实现TenantLineHandler接口
实现getTenantId方法,从step2中的ThreadLocal中拿到租户id,作为这个方法的返回值
01.多租户系统
a.概念
比如我们开发了一个 WEB 版的 CRM 系统,部署在网上,任何公司都可以使用,那么这个系统就相当于一个多租户系统
每个公司相当于一个租户,系统中每个租户的数据是需要隔离的
b.多租户系统数据隔离有3种方案
1.每个租户一个数据库
2.所有租户共用同一个数据库,通过租户id隔离,也就是表里面需要有个租户id(tenant_id)字段,操作租户数据的时候,sql中都需要带上租户id
3.上面2种方案的混合体,比如有1000个租户,每100个租户共用一个数据库,表里面也需要用租户id进行隔离
本文将采用第2种方案,也就是所有租户共用一个数据库,表中的数据通过租户id进行隔离
02.使用MyBatis-plus实现数据隔离
a.说明
MyBatis-plus 本身已经帮我们提供了多租户数据隔离的功能。
这里简单说下原理:当我们通过mybatisplus对数据库执行sql的时候,mybatisplus会拦截sql的执行
对sql进行改写,自动在sql上追加加上租户id,这样就实现了多租户数据隔离的功能
b.效果演示
a.查询租户1所有用户
### 获取租户 1 所有用户
GET http://localhost:8080/user/list
Content-Type: application/json
tenant_id: 1
b.创建用户,租户id是:1
### 创建用户,租户id是:1
POST http://localhost:8080/user/insert
Content-Type: application/x-www-form-urlencoded
Content-Type: application/json
tenant_id: 1
userName=luren
5.8 电商系统的资金账户表设计及实战
01.本文主要内容
电商系统资金账户相关表设计及代码落地
案例:电商平台余额提现到微信钱包
02.看一个需求
比如咱们需要开发一个电商系统,电商系统中每个用户都有一个资金账户,相当于我们在电商系统中给用户开了一张银行卡一样,这个账户需要支持以下功能
1.支持通过第三方支付进行充值
2.支持将余额提现到微信钱包
3.支持通过账户余额购买商品
03.资金账户表如何设计?
a.账户资金表:t_account_funds_lesson048
每个用户会有一条记录
-----------------------------------------------------------------------------------------------------
CREATE TABLE `t_account_funds_lesson048`
(
`account_id` bigint NOT NULL COMMENT '账户id',
`balance` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '余额',
`frozen` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '冻结金额',
`version` bigint DEFAULT '0' COMMENT '版本号,默认为0,每次+1',
`create_time` datetime(6) DEFAULT NULL COMMENT '创建时间',
`update_time` datetime(6) DEFAULT NULL COMMENT '最后修改时间',
PRIMARY KEY (`account_id`)
) COMMENT ='账户资金表';
b.账户资金流水表:t_account_funds_data_lesson048
记录账户资金的变化,余额和冻结金额发生任何变化,此表都会产生记录
-----------------------------------------------------------------------------------------------------
CREATE TABLE `t_account_funds_data_lesson048`
(
`id` bigint NOT NULL auto_increment COMMENT '主键',
`account_id` bigint NOT NULL COMMENT '账号id,t_account_funds.account_id',
`price` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '交易金额',
`income` tinyint NOT NULL DEFAULT '0' COMMENT '进出标志位,0:账户总金额余额不变,1:账户总金额增加,-1:账户总余额减少 (总金额 = account_funds.balance + account_funds.frozen)',
`bus_type` smallint NOT NULL COMMENT '交易关联的业务类型',
`bus_id` bigint NOT NULL COMMENT '交易关联的业务id',
`before_account_funds_snapshot_id` bigint NOT NULL COMMENT '本交易前资金快照id,快照是指交易时将(account_funds)当时的记录备份一份',
`after_account_funds_snapshot_id` bigint NOT NULL COMMENT '本交易后资金快照id,快照是指交易后将(account_funds)当时的记录备份一份',
`create_time` datetime(6) DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) COMMENT ='账户资金流水表'
c.账户资金快照表:t_account_funds_snapshot_lesson048
这个表是第1个表的一个快照,每条资金流水,这个表会产生2条记录
交易前账户资金的快照
交易后账户资金的快照
-----------------------------------------------------------------------------------------------------
CREATE TABLE `t_account_funds_snapshot_lesson048`
(
`id` bigint NOT NULL auto_increment COMMENT '主键',
`account_id` bigint NOT NULL COMMENT '账号id,t_account_funds.account_id',
`balance` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '余额',
`frozen` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '冻结金额',
`create_time` datetime(6) DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) COMMENT ='账户资金快照表'
04.资金相关操作+代码
a.资金表相关的操作主要有6个
a.余额增加 + 生成快照 + 记录流水
总金额(balance+frozen)增加
b.余额减少 + 生成快照 + 记录流水
总金额(balance+frozen)减少
c.资金冻结(余额减少、冻结金额增加) + 生成快照 + 记录流水
资金会从余额流向冻结金额中,总金额(balance+frozen)不变
d.资金解冻(冻结金额减少、余额增加) + 生成快照 + 记录流水
资金会从冻结金额流向余额,总金额(balance+frozen)不变
e.冻结金额增加 + 生成快照 + 记录流水
总金额(balance+frozen)增加
f.冻结金额减少 + 生成快照 + 记录流水
总金额(balance+frozen)减少
b.对应的代码
com.itsoku.lesson048.service.IAccountFundsService
com.itsoku.lesson048.service.impl.AccountFundsServiceImpl
05.案例演示:余额提现到微信钱包
a.需要一个提现记录表
create table if not exists t_cash_out_lesson048
(
`id` bigint NOT NULL auto_increment COMMENT '提现记录id',
account_id varchar(32) not null comment '账号id',
price decimal(12, 2) not null comment '提现金额',
status smallint not null comment '状态,0:处理中,1:提现成功,2:提现失败',
fail_msg varchar(1000) comment '提现失败原因',
create_time datetime not null comment '创建时间',
update_time datetime comment '最后更新时间',
PRIMARY KEY (`id`)
) comment '提现记录表';
b.提现到微信钱包-时序图
略
c.提现案例代码
com.itsoku.lesson048.controller.CashOutController
-----------------------------------------------------------------------------------------------------
主要有2个接口
用户发起提现到微信钱包的接口:com.itsoku.lesson048.controller.CashOutController#cashOut
给微信提供的回调接口:com.itsoku.lesson048.controller.CashOutController#cashOutCallback
d.效果演示
a.模拟提现成功的场景
a.用户发起提现10元
### 1、用户发起提现10元
POST http://localhost:8080/cashOut
Accept: application/json
Content-Type: application/json
{
"accountId": 1,
"price": "10.00"
}
b.查看表中数据的变化
-- 提现记录表
select * from t_cash_out_lesson048;
-- 账户资金表
select * from t_account_funds_lesson048;
-- 账户资金流水表
select * from t_account_funds_data_lesson048;
-- 账户资金快照表
select * from t_account_funds_snapshot_lesson048;
c.模拟微信支付-提现成功回调
### 2、模拟微信支付-提现成功回调
POST http://localhost:8080/cashOutCallback
Accept: application/json
Content-Type: application/json
{
"cashOutId": 1,
"success": true
}
d.查看表中数据的变化
-- 提现记录表
select * from t_cash_out_lesson048;
-- 账户资金表
select * from t_account_funds_lesson048;
-- 账户资金流水表
select * from t_account_funds_data_lesson048;
-- 账户资金快照表
select * from t_account_funds_snapshot_lesson048;
b.模拟提现失败的场景
a.用户发起提现10元
### 1、用户发起提现10元
POST http://localhost:8080/cashOut
Accept: application/json
Content-Type: application/json
{
"accountId": 1,
"price": "10.00"
}
b.查看表中数据的变化
-- 提现记录表
select * from t_cash_out_lesson048;
-- 账户资金表
select * from t_account_funds_lesson048;
-- 账户资金流水表
select * from t_account_funds_data_lesson048;
-- 账户资金快照表
select * from t_account_funds_snapshot_lesson048;
c.模拟微信支付-提现成功回调
### 3、模拟第三方支付-提现失败回调
POST http://localhost:8080/cashOutCallback
Accept: application/json
Content-Type: application/json
{
"cashOutId": 2,
"success": false,
"failMsg": "账户余额不足"
}
d.查看表中数据的变化
-- 提现记录表
select * from t_cash_out_lesson048;
-- 账户资金表
select * from t_account_funds_lesson048;
-- 账户资金流水表
select * from t_account_funds_data_lesson048;
-- 账户资金快照表
select * from t_account_funds_snapshot_lesson048;
06.注意事项
a.防止余额和冻结金额更新为负数
本案例中,我们使用的是乐观锁解决这个问题的,账户资金表有个version字段
-----------------------------------------------------------------------------------------------------
com.itsoku.lesson048.service.impl.AccountFundsServiceImpl#updateFunds
5.9 UML画图神器:PlantUML
00.官网
https://plantuml.com/
5.10 多线程事务,3秒插入百万数据
01.本文内容
1.多线程事务效果演示
2.多线程事务原理详解
## 3.手写了一个非常好用的多线程事务工具类,大家拿去用
02.演示:单线程插入50 万数据
com.itsoku.lesson050.Lesson050ApplicationTest#singleThreadInsert
-----------------------------------------------------------------------------------------------------
select count(*) from t_test_1;
select count(*) from t_test_2;
select count(*) from t_test_3;
select count(*) from t_test_4;
select count(*) from t_test_5;
-----------------------------------------------------------------------------------------------------
平均耗时 6 秒左右
03.演示:多线程插入50万数据
com.itsoku.lesson050.Lesson050ApplicationTest#moreThreadInsert
-----------------------------------------------------------------------------------------------------
select count(*) from t_test_1;
select count(*) from t_test_2;
select count(*) from t_test_3;
select count(*) from t_test_4;
select count(*) from t_test_5;
-----------------------------------------------------------------------------------------------------
平均耗时 3 秒左右
04.演示:多线程插入50万数据,其中一个失败,是否会全部回滚?
com.itsoku.lesson050.Lesson050ApplicationTest#moreThreadInsertFail
-----------------------------------------------------------------------------------------------------
select count(*) from t_test_1;
select count(*) from t_test_2;
select count(*) from t_test_3;
select count(*) from t_test_4;
select count(*) from t_test_5;
05.非常好用的多线程工具类
com.itsoku.lesson050.utils.MoreThreadTransactionUtils
6 part05
6.1 SpringBoot自动初始化数据库
01.背景
a.说明
大部分系统都会用到数据库,这就涉及系统发布前数据库初始化的一些操作
b.通常的做法是
1.提申请让dba去执行数据库脚本
2.数据库脚本执行完成后,由运维发布应用
c.有没有更简单的方法呢?
比如我们把数据库的初始化脚本写在程序中某个文件中,系统启动的时候去自动执行这个文件,是不是会方便很多?
SpringBoot已经帮我们提供了这个功能,来看下如何使用
02.效果演示
a.配置数据源
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/your_database?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: your_username
password: your_password
b.配置SQL脚本位置
在配置文件中指定SQL脚本的位置,Spring Boot在启动时会自动执行这些脚本
可以通过`schema-locations`和`data-locations`属性来指定模式脚本和数据脚本的位置
-------------------------------------------------------------------------------------------------
spring:
sql:
init:
# 数据库ddl脚本位置
schema-locations: classpath:db/schema.sql
# 数据库dml脚本位置
data-locations: classpath:db/data.sql
# always:应用每次启动都执行,never:禁用
mode: always
c.编写SQL脚本
在指定的位置(如`src/main/resources/db/`)下创建SQL脚本文件,如`schema.sql`里面写数据库的ddl脚本,`data.sql`中写dml脚本
d.启动Spring Boot应用
启动Spring Boot应用时,它会自动读取配置,连接到数据库,并执行指定的SQL脚本
03.原理
a.SpringBoot自动装配功能实现的,源码在下面这个自动配置类中
org.springframework.boot.autoconfigure.sql.init.SqlInitializationAutoConfiguration
b.最终执行脚本是由下面这个方法负责的
org.springframework.boot.sql.init.AbstractScriptDatabaseInitializer#afterPropertiesSet
6.2 SpringBoot优雅停机
01.SpringBoot优雅停机是什么意思?
a.说明
Spring优雅停机,通俗点说就是如何优雅的停止SpringBoot应用,
b.优雅停机,应满足下面3点:
1.SpringBoot应用不再接收新的请求
2.SpringBoot应用将已经进来的请求处理完成
3.然后关闭SpringBoot应用
02.什么是立即停机?
a.说明
直接把springboot应用强制关掉,比如linux中的:`kill -9 进程id`,这个命令就会触发强制关闭进程,相当于突然断电一样
b.这种可能导致严重的问题
1.用户体验差,用户请求还在处理中,springboot突然下线,会导致用户收到错误响应
2.可能会引起系统中数据不一致
03.举例:餐馆营业
a.说明
假如咱们开了一个餐馆,现在不想营业了,有2种方案
b.方案1:优雅关门
1.门口挂个牌:已打样,这样顾客看到后,就不会进来了
2.将店内已经在就餐的顾客服务完毕
3.关门
c.方案2:暴力关门
1.将餐馆内还在就餐的顾客直接轰出去
2.关门
04.SpringBoot优雅停机步骤
a.applicaiton.yml中添加配置
server:
# 停机方式,immediate:立即停机,默认值;graceful:优雅停机
shutdown: graceful
b.触发停机常见的方式
a.linux中:kill 进程pid
jps
kill 进程id
-------------------------------------------------------------------------------------------------
注意,`kill -9 进程id`是强制结束进程,不会触发优雅停机,相当于直接断电一样
b.命令窗口中
ctrl+c
05.原理:JVM退出钩子
a.说明
JVM退出钩子是指在JVM关闭时会被调用的回调方法
在JVM关闭时,会执行所有的`shutdown hooks`
可以使用`Runtime.getRuntime().addShutdownHook()`方法来注册一个退出钩子
b.以下是一个简单的Java示例,演示了如何注册和使用JVM退出钩子:
public class ShutdownHookDemo {
public static void main(String[] args) {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
System.out.println("优雅停机测试1....");
}
});
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
System.out.println("优雅停机测试2....");
}
});
}
}
c.执行输出
优雅停机测试2....
优雅停机测试1....
06.SpringBoot优雅退出原理:通过jvm钩子实现的
a.源码位置
org.springframework.boot.SpringApplicationShutdownHook#addRuntimeShutdownHook
b.在jvm退出的时候会干一些事情,主要的事情
1.让web服务器(如Tomcat、Undertow、Jetty)不在接收新的请求
2.将已经进来的请求处理完成
3.销毁spring容器中的bean
4.退出jvm
07.拓展:SpringCloud优雅停机步骤
a.将服务从服务注册中心下线
SpringCloud 涉及到服务注册中心,若服务下线前,没有提前告诉注册中心,而直接把服务下线了,而注册中心、以及其他服务消费者以为这个服务还活着,则还会有请求过来,会导致请求报错
所以下线前需要先从注册中心中将服务摘除,然后需要等到注册中心最新的数据同步到其他服务消费者后,才可以将服务优雅停机
常用的注册中心有eureka,nacos,他们都有服务下线的相关api,可以先调用这些api让服务从注册中心下线
具体的api,大家可以查询相关文档,或者咨询AI
b.休眠一段时间:等待注册中心数据同步给其他服务消费者
当我们的服务从注册中心摘除后,其他服务可能并不知道
而其他服务会定期从注册中心中拉取数据,所以需要等待一段时间,等到其他服务从注册中心获取到最新的服务列表后,才能对要停机的服务执行优雅停机
比如微服务从服务注册中心同步的频率是 5 秒
则建议在这个步骤中,休眠 10 秒以确保所有服务都拉取了注册中心最新的数据
c.对需要下线的服务执行优雅停机
1.通过ps命令查询到进程id
2.执行:kill 进程id,触发优雅停机
d.轮询进程状态 + 超时强制结束
有些情况,执行了`kill 进程id`进程是无法正常结束的,可以通过linux命令去轮询,看下刚才kill的进程是否已结束
可以设置一个超时时间,比如轮询60秒之后,进程还是会无法结束,那么可以执行`kill -9 进程id`强制结束进程
这样,SpringCloud中的服务就可以优雅下线了
6.3 一个特好用的集合工具类
01.前言
集合是咱们日常开发中最常用到的一个功能,如果有一个特别好用的集合工具类,那么咱们的开发效率将大幅提升
这里给大家分享一个我日常工作中经常会用到的一个集合工具类,基本涵盖了集合常见的各种操作
建议大家抽时间把这个工具类过一遍,用起来,开发效率将轻松翻倍
02.工具类
com.itsoku.lesson053.utils.CollUtils
6.4 性能调优:线程死锁相关问题
01.什么是线程死锁?
两个或多个线程在执行过程中,因争夺共享资源而被阻塞,且无法继续执行下去的一种状态
02.示例
a.说明
比如下面这个案例,定义了两个线程:thread1和thread2
thread1对resource1上锁,然后尝试获取resource2的锁;
thread2对resource2上锁,然后尝试获取resource1的锁;
运行下,2个线程会相互等待,出现死锁
b.代码
public class DeadlockDemo {
// 创建两个共享资源
private static final String resource1 = new String();
private static final Object resource2 = new Object();
public static void main(String[] args) {
/**
* 两个线程
* thread1对resource1上锁,然后尝试获取resource2的锁;
* thread2对resource2上锁,然后尝试获取resource1的锁;
* 2个线程会相互等待,出现死锁
*/
Thread thread1 = new Thread(() -> {
synchronized (resource1) {
System.out.println("Thread 1: Locked resource 1");
try {
Thread.sleep(100); // 假设这里有其他操作,需要一些时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 1: Attempting to lock resource 2");
//尝试索取resource2的锁
synchronized (resource2) {
System.out.println("Thread 1: Locked resource 2");
}
}
}, "thread1");
Thread thread2 = new Thread(() -> {
synchronized (resource2) {
System.out.println("Thread 2: Locked resource 2");
try {
Thread.sleep(100); // 假设这里有其他操作,需要一些时间
} catch (InterruptedException e) {
e.printStackTrace();
}
//尝试索取resource1的锁
System.out.println("Thread 2: Attempting to lock resource 1");
synchronized (resource1) {
System.out.println("Thread 2: Locked resource 1");
}
}
}, "thread2");
// 启动线程
thread1.start();
thread2.start();
}
}
03.死锁会导致什么问题?
线程阻塞,这个是最直接的影响
若有大量线程死锁,会导致线程被耗尽,最终将导致系统崩溃,无法对外提供服务
04.如何发现死锁?
需要依赖监控系统:监控系统可以定时使用jstack命令采集线程信息,jstack命令中可以查看到死锁的详细信息,进行告警,人工介入干预
05.3种方法定位死锁代码
a.方案1:jps+jstack命令
a.jps查找进程id
jdk自带工具,可以查看所有的java进程:jsp
b.jstack命令查看死锁信息
jdk自带的工具,可以查看某个java进程中所有的线程快照,可以看到死锁的相信信息:jstack 进程id
b.方案2:jvisualvm
jvisualvm工具:jdk自带的工具
cmd中运行:jvisualvm,即可打开这个工具
c.方案3:arthas
arthas:阿里提供的一个特好用的jvm线上问题诊断利器,详情见:https://arthas.aliyun.com/doc/quick-start.html
06.死锁常见的解决方案
1.避免使用多个锁:通过合理设计程序,尽量避免多个线程同时争用相同的资源
2.保持锁的有序性:当使用多个锁时,保持所有线程获取锁的顺序一致,以避免因顺序不一致而导致的死锁
3.超时等待:设置锁的超时时间,当等待超过一定时间后,放弃对锁的请求,进行其他的处理
4.死锁检测和恢复:使用工具来检测和恢复死锁,一旦检测到死锁,可以通过中断线程、释放资源等方式来恢复程序的执行
6.5 如何排查OOM
01.排查oom:2个步骤
1.导出内存快照
2.使用Eclipse MAT工具分析内存快照,定位问题代码
02.步骤1:导出堆内存快照文件
a.方式1:jmap命令导出文件
jmap -dump:format=b,file=E:/dump/dump.hprof pid
方式1适合程序没有没有退出的情况,若程序退出了,需采用方式2
b.方式2:系统oom时自动生成堆内存快照
在java -jar 后面添加2个启动参数
-XX:+HeapDumpOnOutOfMemoryError:开启内存溢出时自动生成内存快照
-XX:HeapDumpPath=/xxx/dump.hprof:指定dump文件的位置和文件名称
java -jar -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=E:/dump/heap-dump.hprof -Xmx1000m lesson055-0.0.1-SNAPSHOT.jar
03.步骤2:使用Eclipse MAT工具定位问题代码
Eclipse MAT工具是Eclipse提供的一个非常强大的java内存分析工具,可以快速定位oom问题代码
6.6 cpu飙升,快速排查
01.问题代码
a.代码
public class CpuLoadTest {
public static void main(String[] args) {
System.out.println("程序已启动");
while (true){
;
}
}
}
b.执行上面这段代码,会导致cpu飙升
javac CpuLoadTest.java
java CpuLoadTest
02.定位cpu飙升
a.步骤1
使用top命令找到cpu飙升进程id
b.步骤2
根据进程id找到导致cpu飙升的线程
ps H -eo pid,tid,%cpu | grep 进程id
c.步骤3:将线程id转换为16进制
printf '0x%x\n' 线程id
d.步骤4:根据线程定位问题代码
jstack 进程id | grep 16进制线程id -A 20
jstack:jdk内置命令,用于查看某个java进程所有线程快照,里面包含了线程详细的堆栈信息
grep:linux中的用于内容查找的命令,可以从大量文本中快速找到某个关键字所在的行,-A参数后面的20,表示找到内容所在行后面20行记录
6.7 cpu飙升,使用Arthas,3秒定位问题
01.Arthas
arthas:阿里开源的一款Java问题诊断利器,详情见:https://arthas.aliyun.com/doc/quick-start.html
02.演示:使用Arthas,3秒定位cpu飙升的代码
a.问题代码
public class CpuLoadTest {
public static void main(String[] args) {
System.out.println("程序已启动");
while (true){
;
}
}
}
-----------------------------------------------------------------------------------------------------
执行上面这段代码,会导致cpu飙升
javac CpuLoadTest.java
java CpuLoadTest
b.使用Arthas定位问题代码(5个步骤)
a.下载`arthas-boot.jar`
curl -O https://arthas.aliyun.com/arthas-boot.jar
b.然后用`java -jar`的方式启动`arthas`
java -jar arthas-boot.jar
c.选择需要诊断的java进程
# java -jar arthas-boot.jar
* [1]: 3219613 CpuLoadTest
d.使用thread命令查看cpu占比最高的线程
略
e.使用`thread 线程id`查看线程堆栈,定位问题代码
[arthas@3219613]$ thread 1
"main" Id=1 RUNNABLE
at CpuLoadTest.main(CpuLoadTest.java:4)
6.8 接口响应慢,使用Arthas,3秒定位问题代码
01.Arthas
arthas:阿里开源的一款Java问题诊断利器,详情见:https://arthas.aliyun.com/doc/quick-start.html
02.演示:使用Arthas,快速定位接口慢的代码
a.案例代码
package com.itsoku.lesson058;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/7/3 19:15 <br>
* <b>author</b>:ready [email protected]
*/
@RestController
@Slf4j
public class TestController {
@GetMapping("/test")
public String test() throws InterruptedException {
log.info("start");
this.m1();
this.m2();
this.m3();
log.info("end");
return "ok";
}
private void m1() throws InterruptedException {
//休眠100毫秒
TimeUnit.MILLISECONDS.sleep(100);
log.info("m1");
}
private void m2() throws InterruptedException {
//休眠100毫秒
TimeUnit.MILLISECONDS.sleep(100);
log.info("m1");
}
private void m3() throws InterruptedException {
//休眠1秒
TimeUnit.MILLISECONDS.sleep(1000);
log.info("m1");
}
}
b.使用Arthas快速定位慢接口代码(5个步骤)
a.下载arthas-boot.jar
curl -O https://arthas.aliyun.com/arthas-boot.jar
b.启动arthas
java -jar arthas-boot.jar
c.选择需要诊断的java进程
# java -jar arthas-boot.jar
* [1]: 3221212 lesson058-0.0.1-SNAPSHOT.jar
-------------------------------------------------------------------------------------------------
编号1是咱们需要监控的进程,输入1 便可让arthas监控这个进程
d.使用trace命令监控接口详细的耗时情况
trace命令可以显示指定类和方法内部调用的详细路径,以及每个节点上的耗时情况。
这对于分析方法执行过程中的性能瓶颈非常有用,尤其是当方法调用链较长或涉及多个层级时
-------------------------------------------------------------------------------------------------
trace com.itsoku.lesson058.TestController test -n 5 --skipJDKMethod false
e.访问接口,观察第4步trace命令的输出
curl http://localhost:8080/test
6.9 策略模式,轻松消除if else
00.汇总
策略模式,轻松消除if else
6.10 生产上,代码未生效,如何排查?
01.问题
a.代码上线后结果不符合预期
我们的代码,由运维发布上线了,但是运行的结果和我们预期的不一样,怎么办?
b.怀疑:代码未生效
可能怀疑:运维没有发布成功,生产上运行的是老的代码
大家有没有遇到过这种情况?
02.如何解决?
a.检查生产环境代码
让运维帮忙将生产上的代码拉下来,我们进行反编译,看下编译后的源码是不是最新的
如果发现代码是最新,但是生产上跑的依旧是旧的代码,怎么办?
b.反编译正在运行的代码
能否进入正在运行的java程序中,反编译正在运行代码,获得其源码,便可解决问题
arthas解决这个问题
03.arthas
a.arthas简介
arthas:阿里开源的一款Java问题诊断利器,详情见:https://arthas.aliyun.com/doc/quick-start.html
b.arthas jad命令可以解决这个问题
arthas中的jad命令,可以进入正在运行的java程序,将程序中正在运行的类进行反编译,得到其源码
04.如何使用?(4个步骤)
a.运行示例代码
import java.util.concurrent.TimeUnit;
public class ArthasJadTest {
public static void main(String[] args) throws InterruptedException {
System.out.println("程序已启动");
//防止程序退出,休眠1小时
TimeUnit.HOURS.sleep(1);
}
}
b.下载arthas
curl -O https://arthas.aliyun.com/arthas-boot.jar
c.启动arthas
java -jar arthas-boot.jar
d.选择需要诊断的java进程
# java -jar arthas-boot.jar
* [1]: 3219613 ArthasJadTest
e.使用jad命令获取类的源码
# jad 类的完整名称
jad ArthasJadTest
7 part06
7.1 使用MySQL,实现一个高性能,分布式id生成器
01.效果演示
com.itsoku.lesson061.Lesson061ApplicationTest
02.原理
a.说明
基于数据库号段模式,可以理解为从数据库批量的获取自增id
每次从数据库取出一个号段范围,例如 [1,100] 代表100个Id
然后将这100个id加载到内存,以供调用方慢慢使用,等这批id用完之后,再次向数据库申请100个
b.需要用到一张表
CREATE TABLE if not exists `t_id_generator_lesson061`
(
`code` varchar(128) not null primary key COMMENT '业务编码(唯一)',
`max_id` bigint not null default 1 comment '当前最大id'
) COMMENT ='id生成器';
c.说明
比如code是ORDER_ID,每次申请100个
那么首次申请的时候,会向此表插入一条记录
-----------------------------------------------------------------------------------------------------
insert t_id_generator_lesson061 values ('ORDER_ID',100);
-----------------------------------------------------------------------------------------------------
再次申请的时候,会执行下面sql进行更新,为了防止并发,条件中带上了`max_id`旧值,采用乐观锁更新,直到更新成功
-----------------------------------------------------------------------------------------------------
while(true){
int updateCount = update t_id_generator_lesson061 set max_id = max_id + 100 where code = 'ORDER_ID' and max_id = #{旧值};
if(updateCount==1){
break;
}
}
03.源码解析
com.itsoku.lesson061.service.impl.IdGeneratorServiceImpl#getId
04.如何使用
a.参考测试用例
com.itsoku.lesson061.Lesson061ApplicationTest
b.获取一个id
com.itsoku.lesson061.service.IdGeneratorService#getId
c.批量获取id
com.itsoku.lesson061.service.IdGeneratorService#getIdList
7.2 方法执行异常,使用arthas,快速定位问题
01.先来看一个问题
当生产上某个方法的执行结果和我们期望的结果不一致时,咱们怎么办?
02.常见的做法
修改代码,添加一些日志,在日志中输出方法的入参和返参
然后发布上线,拿到入参、返参
在本地进行重现,定位问题
03.是否有更简单的方法呢?
可以使用阿里的arthas工具,在不调整代码的情况下,拿到任意一个方法的入参、返参值,帮助我们更快的定位问题
04.arthas
arthas:阿里开源的一款Java问题诊断利器,详情见:https://arthas.aliyun.com/doc/quick-start.html
05.arthas watch命令
watch命令可以用来观察某个方法的调用情况
具体点说,可以用来观察任意一个方法,方法被调用的时候,可以拿到这个方法的入参、方法的返回值、方法抛出的异常等信息
06.如何使用?
a.代码示例
先运行下面这段代码,然后演示用arthas watch命令获取add方法的入参和返回值
-----------------------------------------------------------------------------------------------------
import java.util.concurrent.TimeUnit;
public class WatchTest {
public static void main(String[] args) throws InterruptedException {
System.out.println("程序已启动");
for (int i = 1; i < 1000000; i++) {
add(i, i + 1);
TimeUnit.SECONDS.sleep(1);
}
}
public static int add(int a, int b) {
return a + b;
}
}
b.步骤
a.下载arthas
curl -O https://arthas.aliyun.com/arthas-boot.jar
b.启动arthas
java -jar arthas-boot.jar
c.选择需要诊断的java进程
# java -jar arthas-boot.jar
* [1]: 4047112 WatchTest
d.使用watch查看add方法的入参和返回值
watch WatchTest add "{params,returnObj}" -x 2
这个命令会观察WatchTest类中的add方法,每次该方法被调用时,都会输出其参数和返回值
7.3 扫码登录
01.网页端登录流程
02.APP端登录流程
03.手机端扫码登录流程
01.前言
二维码,在日常开发中用的挺多的,最常见的2个功能:生成二维码、解析二维码
hutool工具中已经包含了二维码的各种工具类,非常好用
本文将给大家演示,springboot中,如何使用hutool中的工具类实现这2个功能
02.生成二维码
a.引入二维码相关maven工具包
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.2</version>
</dependency>
<dependency>
<groupId>com.google.zxing</groupId>
<artifactId>javase</artifactId>
<version>3.5.3</version>
</dependency>
b.生成二维码的接口
com.itsoku.lesson064.QRCodeController#generateQrCode
-----------------------------------------------------------------------------------------------------
/**
* 生成二维码
*
* @param content 二维码内容
* @param width 二维码宽度
* @param height 二维码高度
* @return
*/
@GetMapping("/generateQrCode")
@ResponseBody
public ResponseEntity<byte[]> generateQrCode(@RequestParam("content") String content, @RequestParam("width") int width, @RequestParam("height") int height) {
//生成二维码(hutool工具类QrCodeUtil)
byte[] bytes = QrCodeUtil.generatePng(content, width, height);
//返回二维码图片(png格式)
return ResponseEntity.ok().header(HttpHeaders.CONTENT_TYPE, MediaType.IMAGE_PNG_VALUE).body(bytes);
}
c.查看效果
浏览器中访问:http://localhost:8080/generateQrCode?width=300&height=300&content=http://www.itsoku.com
d.小结
QrCodeUtil 工具类,默认生成白底黑色的二维码,也可以自定义二维码的样式
比如:设置背景色、前景色、设置边距以及在二维码中心显示自定义的 logo 等等
如下图,generate相关的方法有很多,都是用于生成二维码的,大家可以去体验下
03.二维码解析
a.介绍
二维码解析也比较简单,用的也是 hutool 中的 QrCodeUtil工具类,此类中有多个decode方法,如下图,都是用于解析二维码的
b.案例代码
import cn.hutool.extra.qrcode.QrCodeUtil;
import org.junit.jupiter.api.Test;
import java.io.File;
public class QRCodeTest {
@Test
public void qrCodeDecode() {
//二维码文件
File qrCodeFile = new File("D:\\code\\likun_557\\luren\\lesson064\\src\\test\\resources\\二维码.png");
//使用hutool中的工具类解析二维码,得到二维码中的内容
String content = QrCodeUtil.decode(qrCodeFile);
System.out.println(content);
}
}
7.5 SpringBoot中,Redis如何实现排行榜
01.本文内容
1.Redis 如何实现排行榜?
2.Redis中zset实现排行榜,分数相同时,按照时间降序,如何处理?
02.Redis 如何实现排行榜?
a.简介
Redis 实现排行榜主要依赖于其有序集合zset(Sorted Set)数据结构
zset中可以存储不重复的元素集合,并为每个元素关联一个浮点数分数(score),Redis 会根据这个分数自动对集合中的元素进行排序
下面给大家演示下如何使用zset来实现排行榜的功能
b.用户积分列表
下面表格是用户积分的数据,我们来演示如何将其添加到redis中,然后实现积分排行榜功能
-----------------------------------------------------------------------------------------------------
| 用户id | 积分 |
| ------ | ---- |
| user1 | 100 |
| user2 | 200 |
| user3 | 150 |
c.使用有序集合-添加元素
可以使用 ZADD 命令来向有序集合中添加元素,将上面列表中:用户id作为元素、积分作为分数
-----------------------------------------------------------------------------------------------------
192.168.216.128:6379> zadd user:ranking 100 user1
(integer) 1
192.168.216.128:6379> zadd user:ranking 200 user2
(integer) 1
192.168.216.128:6379> zadd user:ranking 150 user3
(integer) 1
-----------------------------------------------------------------------------------------------------
上面命令中user:ranking是有序集合的名称,100、200、150 是每个用户的积分,user1、user2、user3 是用户的id
d.获取用户积分排行
使用 ZREVRANGE 命令(从高到低排序)或 ZRANGE 命令(从低到高排序)来获取排行榜的前几名
-----------------------------------------------------------------------------------------------------
# 获取用户积分排行榜前3名(分数从高到低)
192.168.216.128:6379> ZREVRANGE user:ranking 0 2 WITHSCORES
1) "user2"
2) "200"
3) "user3"
4) "150"
5) "user1"
6) "100"
03.积分相同时,如何处理?
a.问题描述
如下表,当用户积分相同时,要求按最后更新时间升序
| 用户id | 积分 | 最后更新时间时间戳(毫秒) |
| ------ | ---- | ------------------------ |
| user1 | 100 | 1720663200002 |
| user2 | 100 | 1720663200001 |
| user3 | 150 | 1720663200000 |
b.说明
按照:积分 desc,最后更新时间 asc,排名后,顺序应该是:user3、user2、user1,但是redis中的zset只能score进行排序,怎么解决呢?
04.积分相同时,按最后更新时间升序,解决思路
a.思路
可以将zset中的score设置为一个浮点数,其中整数部分为积分,小数部分为最后更新时间时间戳,算法如下
b.算法
score = 积分 + 时间戳/10的13次方
这里为什么要除以10的13次方?由于时间戳的长度是13位,除以10的13次方,可以将其移到小数点的右边
对上面表格,处理之后,变成了下面这样
-----------------------------------------------------------------------------------------------------
| 用户id | 积分 | 最后更新时间时间戳(毫秒) | score |
| ------ | ---- | ------------------------ | ----------------- |
| user1 | 100 | 1720663200002 | 100.1720663200002 |
| user2 | 100 | 1720663200001 | 100.1720663200001 |
| user3 | 150 | 1720663200000 | 150.1720663200000 |
-----------------------------------------------------------------------------------------------------
按score降序排序后,是:user3 (150.1720663200000) > user1 (100.1720663200002) > user2( 100.1720663200001)
和预期的不一样,user2的最后更新时间是小于user1的,user2应该排在user1之前,怎么办呢?
需要再做一次转换
c.转换
score = 积分 + (1 - 时间戳/10的13次方)
处理后,表格变成了下面这样
-----------------------------------------------------------------------------------------------------
| 用户id | 积分 | 最后更新时间时间戳(毫秒) | score |
| ------ | ---- | ------------------------ | ----------------- |
| user1 | 100 | 1720663200002 | 100.8279336799998 |
| user2 | 100 | 1720663200001 | 100.8279336799999 |
| user3 | 150 | 1720663200000 | 150.8279336800000 |
-----------------------------------------------------------------------------------------------------
按降序排序后,是:user3 (150.8279336800000) > user2 (100.8279336799999) > user1(100.8279336799998)
这样就达到了预期的目的
05.SpringBoot代码实现
a.引入maven配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
b.提供:录入用户数据、查询排行榜接口
a.源码如下,有2个方法
addUserPoint:批量将用户积分数据写入到redis的zset中
userRankings:获取用户积分排行榜接口
b.lesson065/src/main/java/com/itsoku/lesson065/controller/UserRankingController.java
package com.itsoku.lesson065.controller;
import com.itsoku.lesson065.dto.UserRanking;
import com.itsoku.lesson065.dto.UserPointsReq;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.ZSetOperations;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/7/18 20:23 <br>
* <b>author</b>:ready [email protected]
*/
@RestController
public class UserRankingController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 用户积分批量插入到redis
*
* @param userPointsReqList
* @return
*/
@PostMapping("/addUserPoint")
public boolean addUserPoint(@RequestBody List<UserPointsReq> userPointsReqList) {
String key = "user:ranking";
for (UserPointsReq userPointsReq : userPointsReqList) {
String userId = userPointsReq.getUserId();
//先按积分降序,积分相同时按照最后更新时间升序,score = 积分 + (1 - 时间戳/10的13次方)
double score = userPointsReq.getPoints() + (1 - userPointsReq.getUpdateTime() / 1e13);
this.stringRedisTemplate.opsForZSet().add(key, userId, score);
}
return true;
}
/**
* 获取用户积分排行榜(倒序)
*
* @param topN 前多少名
* @return
*/
@GetMapping("/userRankings")
public List<UserRanking> userRankings(@RequestParam("topN") int topN) {
String key = "user:ranking";
Set<ZSetOperations.TypedTuple<String>> typedTuples = this.stringRedisTemplate.opsForZSet().reverseRangeWithScores(key, 0, topN - 1);
List<UserRanking> userRankingList = new ArrayList<>();
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
UserRanking userRanking = new UserRanking();
userRanking.setUserId(typedTuple.getValue());
userRanking.setRedisScore(typedTuple.getScore());
userRankingList.add(userRanking);
}
return userRankingList;
}
}
c.UserPointsReq
@Data
public class UserPointsReq {
//用户id
private String userId;
//积分
private Integer points;
//最后更新时间(时间戳毫秒)
private Long updateTime;
}
d.UserRanking
@Data
public class UserRanking {
private String userId;
private double redisScore;
}
e.lesson065/src/test/resources/UserRankingController.http
### 1.批量将用户积分丢到redis中zset中
POST http://localhost:8080/addUserPoint
Accept: application/json
Content-Type: application/json
[
{
"userId": "user1",
"points": 100,
"updateTime": 1720663200002
},
{
"userId": "user2",
"points": 100,
"updateTime": 1720663200001
},
{
"userId": "user3",
"points": 150,
"updateTime": 1720763100000
}
]
### 2.获取排名前3的用户列表,按积分倒序,积分相同时,按最后更新时间升序
GET http://localhost:8080/userRankings?topN=3
Accept: application/json
7.6 SpringBoot中,Redis如何实现查找附近的人功能
01.先看效果
UserLocationController.http
02.核心代码
com.itsoku.lesson066.controller.UserLocationController
03.原理
a.说明
附近的人是使用Redis中的Geo(Geospatial)数据结构实现的
Redis的Geo功能允许我们存储地理位置信息,并提供了根据地理位置查询数据的各种功能,比如本文中的查询附近的人功能
b.添加地理位置数据
首先,先geoadd命令,将用户位置信息添加到redis中,如下
-----------------------------------------------------------------------------------------------------
GEOADD users:locations 121.245996 31.114995 user1
GEOADD users:locations 121.241343 31.113264 user2
GEOADD users:locations 121.356703 31.161321 user3
...
c.查询附近的人
使用`GEORADIUS`命令来查询指定范围内的用户
-----------------------------------------------------------------------------------------------------
GEORADIUS users:locations 121.2439 31.114678 1000 m WITHDIST WITHCOORD COUNT 10 ASC
-----------------------------------------------------------------------------------------------------
上面这条命令:查找以(116.405285, 39.904989)为中心,半径为1000米内的最近的10个用户,并返回用户ID、距离、和坐标
04.源码
a.com.itsoku.lesson066.controller.UserLocationController
package com.itsoku.lesson066.controller;
import com.itsoku.lesson066.dto.NearbyUserDto;
import com.itsoku.lesson066.dto.AddUserLocationReq;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.geo.*;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.domain.geo.Metrics;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/7/18 20:23 <br>
* <b>author</b>:ready [email protected]
*/
@RestController
public class UserLocationController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 批量将用户地理位置信息添加到redis中(实际工作中,大家可以提供一个用户地理位置上报的接口,客户端可以每隔10秒,上报一下地理位置坐标,将其丢到redis中)
*
* @param userLocationReqList
* @return
*/
@PostMapping("/addUserLocation")
public boolean addUserLocation(@RequestBody List<AddUserLocationReq> userLocationReqList) {
String key = "users:locations";
for (AddUserLocationReq userLocationReq : userLocationReqList) {
String userId = userLocationReq.getUserId();
Double longitude = userLocationReq.getLongitude();
Double latitude = userLocationReq.getLatitude();
this.stringRedisTemplate.opsForGeo().add(key, new Point(longitude, latitude), userId);
}
return true;
}
/**
* 获取附近的人列表,以(longitude,latitude)为圆心,以 radius 为半径,获取count个用户
*
* @param longitude 进度
* @param latitude 纬度
* @param radius 圆的半径(米)
* @param count 获取用户的数量
* @return
*/
@GetMapping("/findNearbyUserList")
public List<NearbyUserDto> findNearbyUserList(@RequestParam("longitude") double longitude,
@RequestParam("latitude") double latitude,
@RequestParam("radius") double radius,
@RequestParam("count") int count) {
List<NearbyUserDto> nearbyUserDtoList = new ArrayList<>();
//从redis中获取附近的用户列表
String key = "users:locations";
Circle circle = new Circle(new Point(longitude, latitude), new Distance(radius, Metrics.METERS));
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs
.newGeoRadiusArgs()
.includeCoordinates()
.includeDistance()
.sortAscending().limit(count);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = stringRedisTemplate.opsForGeo().radius(key, circle, args);
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> content = geoResults.getContent();
for (GeoResult<RedisGeoCommands.GeoLocation<String>> geoResultGeoResult : content) {
RedisGeoCommands.GeoLocation<String> geoLocation = geoResultGeoResult.getContent();
Point point = geoLocation.getPoint();
String userId = geoLocation.getName();
//拿到用于的id、经纬度、距离
NearbyUserDto nearbyUserDto = new NearbyUserDto();
nearbyUserDto.setUserId(userId);
nearbyUserDto.setLongitude(point.getX());
nearbyUserDto.setLatitude(point.getY());
nearbyUserDto.setDistance(geoResultGeoResult.getDistance().getValue());
nearbyUserDtoList.add(nearbyUserDto);
}
return nearbyUserDtoList;
}
}
7.7 SpringBoot中,接口签名,通用方案,一次性搞懂
01.本文内容
1.接口为什么要签名?
2.如何签名?
3.什么是请求重放?
4.如何避免请求重放?
5.接口签名使用场景
6.SpringBoot实现接口签名实战
02.先来看一个接口:转账接口
a.假如咱们开发了一个转账接口,如下,用于从一个账户转账到另外一个账户
@RequestMapping("/account/transfer")
public Result<String> transfer(@RequestBody TransferRequest request) {
log.info("转账成功:{}", JSONUtil.toJsonStr(request));
return ResultUtils.success("转账成功");
}
public class TransferRequest {
//付款人账户id
private String fromAccountId;
//收款人账号id
private String toAccountId;
//转账金额
private BigDecimal transferPrice;
}
b.比如张三给李四转账100元,请求如下
POST http://localhost:8080/account/transfer
Content-Type: application/json
{
"fromAccountId": "张三",
"toAccountId": "李四",
"transferPrice": 100
}
03.请求伪造
a.说明
上面这个请求没有任何安全限制。
王五知道有这个接口,然后就可以通过这个接口偷偷给自己转账:比如下面这样,王五将张三的钱转到了自己的账户
b.代码
POST http://localhost:8080/account/transfer
Content-Type: application/json
{
"fromAccountId": "张三",
"toAccountId": "王五",
"transferPrice": 100
}
c.说明
这就是请求伪造,会导致严重的后果
04.如何防止请求伪造呢?签名(sign)
a.双方引入秘钥(secretKey)
接口调用方和接口提供方,双方需要一个相同的秘钥(secretKey),这个秘钥不能让第三方知道
秘钥就是一个普通的字符串,如下:
-----------------------------------------------------------------------------------------------------
secretKey = b0e8668b-bcf2-4d73-abd4-893bbc1c6079
b.接口调用方:利用秘钥对请求进行签名(sign)
可以通过一些算法对请求进行签名。
比如下面的算法,通过秘钥和请求体生成签名
-----------------------------------------------------------------------------------------------------
sign = md5(secretKey + http请求体)
-----------------------------------------------------------------------------------------------------
注意:当secretKey或http请求体有任何变化的时候,sign都会发生改变,这点很关键
c.接口调用方:携带签名发送请求
POST http://localhost:8080/account/transfer
Content-Type: application/json
X-Sign: 签名
{
"fromAccountId": "张三",
"toAccountId": "李四",
"transferPrice": 100
}
d.服务端:校验签名
服务端接收到请求后,对签名进行校验,服务端知道秘钥,然后拿到请求体,计算出签名,和请求方传递的签名进行对比
若不一致,表示请求被篡改了,说明这个请求是被伪造的
-----------------------------------------------------------------------------------------------------
伪代码如下:
//请求体字符串
String body = http请求体;
//签名
String sign = request.getHeader("X-Sign");
//计算签名
String expectSign = md5(秘钥 + body);
//校验签名
if(!expectSign.equals(sign)){
//签名有误,非法请求
}
e.已杜绝请求伪造
由于请求伪造方是不知道秘钥的,当请求伪造方,将请求体改变了,那么签名校验是无法通过的,所以请求无法伪造
05.新的问题:请求重放
a.步骤1:张三给李四转账100
POST http://localhost:8080/account/transfer
Content-Type: application/json
X-Sign: 签名
{
"fromAccountId": "张三",
"toAccountId": "李四",
"transferPrice": 100
}
b.步骤2:李四再次发起这个请求
李四将上面的请求拦截了,拿到了请求完整的数据,他便可以再次发送这个请求,会导致张三给李四转账多次
06.如何防止请求重放呢?(随机字符串nonce+时间戳timestamp)
a.前端引入随机字符串(nonce)
可以在请求头中添加一个新的随机字符串(nonce),每次发送请求,nonce都是一个新的值
-----------------------------------------------------------------------------------------------------
POST http://localhost:8080/account/transfer
Content-Type: application/json
X-Sign: 签名
X-Nonce: 随机字符串
{
"fromAccountId": "张三",
"toAccountId": "李四",
"transferPrice": 100
}
-----------------------------------------------------------------------------------------------------
签名的算法也需要改变,如下,将nonce也加入到签名的算法中,当参与计算的任何一个变量发生变化,则签名都会发生变化
-----------------------------------------------------------------------------------------------------
sign = md5(secretKey + nonce + http请求体)
b.后端确保同一个nonce只会被处理一次
请求过来后,先看一下redis中是否存在这个nonce,如果存在,则返回:nonce无效,否则,后端可以将nonce保存到redis中,有效期20分钟
-----------------------------------------------------------------------------------------------------
伪代码如下:
@Autowired
private RedisTemplate<String, String> redisTemplate;
String nonceKey = "SignatureVerificationFilter:nonce:" + nonce;
if (!this.redisTemplate.opsForValue().setIfAbsent(nonceKey, "1", 20, TimeUnit.MINUTES)) {
this.write(response, "nonce无效");
return false;
}
c.新的问题:20分钟后,请求还是能够被重放
上面代码中,nonce被存储在redis中,有效期是20分钟,这样只能确保同一个请求在20分钟内无法重放
但是20钟后,redis中的数据已经过期了,同一个请求再次到达后端时,后端会认为这个nonce没有被使用过
会认为是新的请求,会导致请求再次被处理,这样就导致请求被重放了
还是未解决请求重放的问题,这个时候我们需要引入一个时间戳了,向下看
d.引入时间戳(timestamp)
前端发送请求是,将当前的时间戳(秒),也加入到请求头中
-----------------------------------------------------------------------------------------------------
POST http://localhost:8080/account/transfer
Content-Type: application/json
X-Sign: 签名
X-Nonce: 随机字符串
X-Timestamp: 当前时间戳
{
"fromAccountId": "张三",
"toAccountId": "李四",
"transferPrice": 100
}
-----------------------------------------------------------------------------------------------------
签名的算法也需要改变
-----------------------------------------------------------------------------------------------------
sign = md5(secretKey + nonce + 当前时间戳 + http请求体)
e.后端对请求进行限制:请求10分钟内有效
将服务器当前时间和请求头中时间戳(timestamp)进行对比,绝对值在10分钟内,请求才算有效,否则,请求无效
-----------------------------------------------------------------------------------------------------
//timestamp 10分钟内有效
long timestamp = Long.parseLong(前端请求头中的时间戳);
long currentTimestamp = System.currentTimeMillis() / 1000;
if (Math.abs(currentTimestamp - timestamp) > 600) {
//请求已过期
}
f.此时已杜绝请求重放
10分钟内请求被重放:由于nonce的有效期是20分钟,请求到达后端后,发现nonce已被使用,则请求无法重放
20分钟后请求被重放:由于时间戳timestamp的有效期是10分钟,请求到达后端后,发现timestamp已过期,则请求无法重放
07.使用场景
接口签名不是给前端用的,主要是作为后端接口安全验证的一种手段,比如后端和后端之间相互调用,或者为第三方提供一些安全接口等
08.SpringBoot版本代码落地
a.引入maven配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.2</version>
</dependency>
<!-- Apache Lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
b.application.yml
spring:
redis:
host: 192.168.216.128
secret-key: b0e8668b-bcf2-4d73-abd4-893bbc1c6079
c.SignatureVerificationFilter:签名校验拦截器
package com.itsoku.lesson067.sign;
import cn.hutool.crypto.digest.DigestUtil;
import cn.hutool.json.JSONUtil;
import com.itsoku.lesson067.common.ResultUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.util.StreamUtils;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.TimeUnit;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/7/26 20:17 <br>
* <b>author</b>:ready [email protected]
*/
@Order(Ordered.HIGHEST_PRECEDENCE)
@WebFilter(urlPatterns = "/**", filterName = "SignatureVerificationFilter")
@Component
public class SignatureVerificationFilter extends OncePerRequestFilter {
public static Logger logger = LoggerFactory.getLogger(SignatureVerificationFilter.class);
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
//对request进行包装,支持重复读取body
ReusableBodyRequestWrapper requestWrapper = new ReusableBodyRequestWrapper(request);
//校验签名
if (this.verifySignature(requestWrapper, response)) {
filterChain.doFilter(requestWrapper, response);
}
}
@Autowired
private RedisTemplate<String, String> redisTemplate;
//签名秘钥
@Value("${secretKey:b0e8668b-bcf2-4d73-abd4-893bbc1c6079}")
private String secretKey;
/**
* 校验签名
*
* @param request
* @param response
* @return
* @throws IOException
*/
public boolean verifySignature(HttpServletRequest request, HttpServletResponse response) throws IOException {
//签名
String sign = request.getHeader("X-Sign");
//随机数
String nonce = request.getHeader("X-Nonce");
//时间戳
String timestampStr = request.getHeader("X-Timestamp");
if (StringUtils.isBlank(sign) || StringUtils.isBlank(nonce) || StringUtils.isBlank(timestampStr)) {
this.write(response, "参数错误");
return false;
}
//timestamp 10分钟内有效
long timestamp = Long.parseLong(timestampStr);
long currentTimestamp = System.currentTimeMillis() / 1000;
if (Math.abs(currentTimestamp - timestamp) > 600) {
this.write(response, "请求已过期");
return false;
}
//防止请求重放,nonce只能用一次,放在redis中,有效期 20分钟
String nonceKey = "SignatureVerificationFilter:nonce:" + nonce;
if (!this.redisTemplate.opsForValue().setIfAbsent(nonceKey, "1", 20, TimeUnit.MINUTES)) {
this.write(response, "nonce无效");
return false;
}
//请求体
String body = StreamUtils.copyToString(request.getInputStream(), StandardCharsets.UTF_8);
//需要签名的数据:secretKey+noce+timestampStr+body
//校验签名
String data = String.format("%s%s%s%s", this.secretKey, nonce, timestampStr, body);
if (!DigestUtil.md5Hex(data).equals(sign)) {
write(response, "签名有误");
return false;
}
return true;
}
private void write(HttpServletResponse response, String msg) throws IOException {
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error(msg)));
}
}
d.测试效果
1.启动springboot应用
2.运行测试用例:SignTest#transfer
7.8 SpringBoot中,接口加解密,通用方案实战
01.背景
数据敏感度高的接口中,为了防止数据在传输过程中被窃取,可以采用密文传输。这样即使数据被窃取,获取到的也是密文,无法解密,没有意义
调用方发送请求前,先对明文加密,然后发送密文。被调用方收到数据后,先进行解密,再进行处理
返回的结果同样可以加密,被调用方将需要返回的数据加密后,将密文返回给调用方,调用方收到后,再进行解密得到明文
02.案例1:接口入参自动解密
com.itsoku.lesson068.controller.TestController#decryptTest
03.案例2:接口返回值自动加密
com.itsoku.lesson068.controller.TestController#encryptTest
04.案例3:请求和返回值同时加密
com.itsoku.lesson068.controller.TestController#secureTest
05.原理
a.统一加解密
加密和解密对接口来说属于通用功能,可以从业务代码中剥离出来,进行统一处理
请求解密:通过拦截器拦截所有需要解密的请求,将密文解密为明文,然后由接口处理
返回值加密:通过拦截器拦截所有需要加密的返回值,将明文加密为密文,然后返回给客户端
b.请求自动解密:@Decrypt + DecryptRequestBodyAdvice
a.若请求是密文,则需要在接口的方法上加上 @Decrypt 注解
@Decrypt
@PostMapping("/decryptTest")
public List<String> decryptTest(@RequestBody List<String> body) {
log.info("参数加密测试,请求参数:{}", body);
return body;
}
b.请求到达controller中的方法之前,会拦截标注有 @Decrypt 注解的方法,负责将原始请求中的密文转换为明文
源码:com.itsoku.lesson068.secure.DecryptRequestBodyAdvice
c.返回值自动加密:@Encrypt + EncryptResponseBodyAdvice
a.若返回值需要加密,则需要在方法上添加 @Encrypt 注解
@Encrypt
@GetMapping("/encryptTest")
public String encryptTest() {
return "高并发 & 微服务 & 性能调优实战案例 100 讲";
}
b.在结果返回给调用者之前,会拦截标注有@Encrypt 注解的方法,对接口的返回值进行处理,将其转换为密文
源码:com.itsoku.lesson068.secure.EncryptResponseBodyAdvice
7.9 分库、分表、分库分表,如何选择?
01.背景
分库、分表以及分库分表是数据库架构设计中常见的优化手段,它们各自适用于不同的场景
本文将带大家了解这3种方案各自的适合的场景,帮助大家精准决策
02.分库-适用场景
a.场景1:并发量太大
数据库连接数,受物理机器的影响,是有上限的,当并发量上来后,这块会成为系统瓶颈
对于高并发写的场景:可以考虑分库,分摊db压力,比如:电商系统中订单库,可以将其拆分为多个订单库,每个库中的表结构还是一样的,多个库可以抗更多并发量
对于高并发读的场景:若单库写没有压力,但是扛不住高并发读的请求,可以考虑一主多从,读写分离策略,主库负责写,从库负责读;这种情况并不是分库,而是读写分离
b.场景2:业务隔离需求
在业务复杂、模块众多的系统中,不同业务模块之间的数据访问和存储需求可能存在差异
为了实现业务隔离和减少相互之间的干扰,可以将不同的业务模块分别存储在不同的数据库中
比如我们熟悉的微服务中,每个微服务负责各自的业务,相互隔离,数据库也是相互独立的
03.分表-适用场景
a.场景1:单表数据量过大
当单表数据量超过500万时,通过优化索引或者其他优化方案,无法有效提升查询性能时,建议考虑分表
将单个表的数据分散到多个表中,减少单个表的数据量,提高查询效率
b.场景2:高并发访问
在高并发场景下,大量请求同时访问同一个表可能会导致性能瓶颈,通过分表可以将请求分散到多个表中,降低单个表的负载,提高系统的并发处理能力
04.分库分表-适用场景
a.场景:数据库并发量高 + 单表数据量大
高并发情况下,连接数会遇到瓶颈,且单表数据量太大导致查询缓慢的时候,此时可以考虑分库+分表
比如下面电商中订单库,假如单库可以抗1000并发、单表500万数据,但是业务要求能抗2000并发、支撑4000万订单,那么可以拆分成2个db,每个库4张表
05.如何确定分库分表的数量?
a.说明
分表数量 = (年增长量 * 支撑年限)/ 2000万,结果向上取2的幂
分库数量 = 分表数量 / 8
比如每年增加1亿数据,要支撑10年
分表数量 = 1亿 * 10 / 2000万 = 50,向上取2的幂,也就是 64 张表
b.这里为什么要取2的幂呢,是为了方便扩容时数据迁移,这个后面的文章会进行介绍
库数量 = 64/8 = 8
最终,8个库,每个库8张表
06.总结
1.分库:适合写并发量比较大的场景;如果只是读的并发量比较大,可以采用一主多从策略(读写分离)
2.分表:适合单表数量太大导致查询慢的场景
3.分库分表:适合并发量大 + 单表数据量大的场景
7.10 分库分表:分表字段如何选择?
01.背景
分库分表中有一个非常关键的问题,分表字段如何选择?
本文以电商中的订单表为例,来分析下分表字段如何选择
看完之后,面对分库分表的场景,基本上可以轻松应对
02.订单分表时,需考虑几个问题
1.买家如何查询自己的订单列表?
2.买家如何查询某个订单明细?
3.卖家如何查询订单列表?
4.卖家如何查询某个订单明细?
5.遇到纠纷,平台需根据订单id,如何查询某个订单?
6.分表后,订单更新流程
7.没有分片字段的查询,如何解决?
03.订单表:根据买家id分表
根据买家id分表,可以确保同一个买家的所有订单都落在同一张表中
这样买家查询订单列表或者查看某个订单明细的时候,会带上买家id,便可以路由到具体的表
假如有订单表有4张,分别是:t_order_buyer_001、t_order_buyer_002、t_order_buyer_003、t_order_buyer_004
分表算法:t_order_buyer_((买家id-1)%表数量+1)
---------------------------------------------------------------------------------------------------------
| 订单id | 买家id | 表 |
| ------------- | ------ | ----------- |
| 1000000000001 | 1 | t_order_001 |
| 1000000000002 | 2 | t_order_002 |
| 1000000000003 | 3 | t_order_003 |
| 1000000000004 | 4 | t_order_004 |
| 1000000000005 | 5 | t_order_001 |
| 1000000000006 | 6 | t_order_002 |
| 1000000000007 | 7 | t_order_003 |
| 1000000000008 | 8 | t_order_004 |
04.卖家怎么查询?
根据买家id分表后,同一个商户,会有很多买家下单,同一个商户的订单可能会落在多张表中
比如下表,此时是无法知道商户的订单具体在哪些表中,那么商户查询订单的时候,就需要查询所有的订单表,查询效率会特别的低
---------------------------------------------------------------------------------------------------------
| 订单id | 商家id | 买家id | 表 |
| ------------- | ------ | ------ | ----------- |
| 1000000000001 | 1 | 1 | t_order_001 |
| 1000000000002 | 2 | 2 | t_order_002 |
| 1000000000003 | 1 | 3 | t_order_003 |
| 1000000000004 | 2 | 4 | t_order_004 |
| 1000000000005 | 1 | 5 | t_order_001 |
| 1000000000006 | 2 | 6 | t_order_002 |
| 1000000000007 | 2 | 7 | t_order_003 |
| 1000000000008 | 2 | 8 | t_order_004 |
-----------------------------------------------------------------------------------------------------
可以采用数据冗余,解决这个问题,向下看
05.冗余订单数据:根据卖家id进行分表
我们可以再存储一份订单数据,这份订单数据根据卖家id进行分表
根据买家id分表存储一份,方便买家查询,表名以`t_order_buyer_`开头
根据卖家id分表也存储一份,方便卖家查询,表名以`t_order_seller_`开头
06.平台根据订单id如何查询?
a.基因法
根据买家id,是可以快速找到订单所在的表,那么买家下单的时候,生成订单号时,可以将买家id放到订单号中去,比如订单号后10位表示用户id
-----------------------------------------------------------------------------------------------------
根据订单号查询订单的过程
截取订单后10位,得到用户id
根据用户id,定位到具体的订单表
根据订单id查询订单
b.冗余法
可以再冗余一份订单数据,这份订单数据根据订单id进行分表
07.订单数据如何更新?
现在订单表数据存储了2份,一份根据买家id分表存储的,一份根据卖家id分表存储的,有3个需求需要考虑
1.用户下单,写入数据的流程
2.用户更新订单,写入数据的流程
3.商户更新订单,写入数据的流程
08.用户下单流程
将订单数据写入买家订单表
将买家订单表信息同步到卖家订单表(若所有的表都在同一个库,可以同步操作,若不在同一个库,可以通过mq或者binlog异步同步)
09.买家更新订单流程
买家直接根据用户id路由到具体的买家订单表
更新买家订单信息
异步将买家订单表信息同步到卖家订单表
10.卖家更新订单流程
a.卖家订单表只负责读的操作,若卖家需要更新订单,则走下面流程
1.根据订单id,定位到买家订单表
2.更新买家订单信息
3.将买家订单表信息同步到卖家订单表(若所有的表都在同一个库,可以同步操作,若不在同一个库,可以通过mq或者binlog异步同步)
b.这里大家可思考下,如果卖家这边更新订单时,采用下面流程
1.先去更新卖家订单表
2.将卖家订单表同步到买家订单表
c.说明
这样就会出现两边数据互相同步的场景,让问题变的特别复杂,这个情况要避免
不管是买家还是卖家,更新订单信息都走同样流程:先更新买家订单表,然后信息同步到卖家订单表
11.其他查询怎么解决?
对于没有用户id、卖家id、订单id,这种情况,是无法知道订单数据具体在哪张表,只能去查询所有的表,效率非常低
对于这种需求,建议将订单数据同步到es,这些查询通过es解决
12.总结
通过本文,大家应该了解了,分表字段如何选择的问题,具体应该从需求出发,基于需求驱动设计
1.通过用户id分表,解决了买家查询的的问题
2.通过数据容冗余,冗余了一份根据卖家id分表的订单数据,方便卖家角度查询订单
3.对于订单数据的更新,采用单向数据更新,先更新用户订单数据,然后将数据同步到卖家订单表,这样大大简化了问题
4.引入es,解决其他查询问题
了解了这些之后,大家在面对分表的时候,便可轻松应对
8 part07
8.1 分表数量为什么建议是2的n次方?
01.背景
相信很多朋友听说过,分表的时候,建议将表的数量设置为2的n次方
比如:2、4、8、16、32、64、128,扩容时也是按照2的n次方进行扩容
大家有想过为什么要这么做么?
02.主要2个好处
1.定位表的速度更快
2.扩容时,数据迁移成本更低
03.好处1:定位表的速度更快
a.说明
通常我们会采用取模算法,来进行分表,当表的数量是2的n次方的时候,取模运算,可以简化成位运算,速度更快
b.举个例子
电商系统中,有4张订单表:t_order_0,t_order_1,t_order_2,t_order_3
分片健:订单id
表路由算法:t_order_(订单Id % 表的数量)
如果表的数量是2的n次方的时候,取模运算,可以简化成位运算,位运算速度更快
表的路由算法 = 订单Id % 表的数量 = 订单id & (表的数量-1)
-----------------------------------------------------------------------------------------------------
| 订单id | 订单id%4 | 订单id & (4-1) | 表 |
| ------ | -------- | ----------------------- | --------- |
| 1 | 1 | 1 & 3 = 0001 & 0011 = 1 | t_order_1 |
| 2 | 2 | 2 & 3 = 0010 & 0011 = 2 | t_order_2 |
| 3 | 3 | 3 & 3 = 0011 & 0011 = 3 | t_order_3 |
| 4 | 0 | 4 & 3 = 0100 & 0011 = 0 | t_order_0 |
| 5 | 1 | 5 & 3 = 0101 & 0011 = 1 | t_order_1 |
04.扩容案例:2张表-扩容到4张表:只需迁移一半数据
a.说明
扩容前,2张订单表:t_order_0,t_order_1
分表算法:t_order_((订单id - 1)%表的数量)
扩容,将表的数量翻倍,变成4张表:t_order_0,t_order_1,t_order_2,t_order_3
b.下面列了一些数据,大家重点看先,扩容前后,数据所在表的一个变化
| 订单id | 扩容前-所在表 | 扩容后-所在表 |
| ------ | ------------- | ------------- |
| 1 | t_order_0 | t_order_0 |
| 2 | t_order_1 | t_order_1 |
| 3 | t_order_0 | t_order_2 |
| 4 | t_order_1 | t_order_3 |
| 5 | t_order_0 | t_order_0 |
| 6 | t_order_1 | t_order_1 |
| 7 | t_order_0 | t_order_2 |
| 8 | t_order_1 | t_order_3 |
c.从表中可以看出
t_order_0中有一半数据不需要动(order_id:[1,5]),有一半的数据需要迁移到 t_order_2 表(order_id = [3,7])
t_order_1中有一半数据不需要动(order_id:[2,6]),有一半的数据需要迁移到 t_order_3 表(order_id = [4,8])
d.结论
表翻倍扩容,原表的数据只需要迁移一半到新表,迁移速度会更快
05.扩容案例:2张表 - 扩容到5张表,需迁移更多数据
a.说明
扩容前,2张订单表:t_order_0,t_order_1
分表算法:t_order_((订单id - 1)%表的数量)
扩容成5张表:t_order_0,t_order_1,t_order_2,t_order_3,t_order_4
b.下面列了一些数据,大家重点看先,扩容前后,数据所在表的一个变化
| 订单id | 扩容前-所在表 | 扩容后所在表 |
| ------ | ------------- | ------------ |
| 1 | t_order_0 | t_order_0 |
| 2 | t_order_1 | t_order_1 |
| 3 | t_order_0 | t_order_2 |
| 4 | t_order_1 | t_order_3 |
| 5 | t_order_0 | t_order_4 |
| 6 | t_order_1 | t_order_0 |
| 7 | t_order_0 | t_order_1 |
| 8 | t_order_1 | t_order_2 |
c.从表中可以看出
2张表扩容到5张表后,只有前2条订单,扩容前后是同一个表,其他的扩容前后不在同一张表了,这样带来了更高的数据迁移成本
大家可以试下,如果2张表直接扩容到8张表,则原表需要迁移2/3的数据,还是有一大部分数据是不用动的
06.总结
分库分表中,表的数量通常会设置为2的n次方,主要有2个好处
1.定位表的速度更快,主要是取模运算可以转换为位运算,位运算对于计算机来说速度更快
2.迁移数据成本更低,只需迁移部分数据
8.2 分库分表-如何平滑迁移数据?
01.背景
假如我们做了一个电商系统,刚开始只有一个订单表,后面由于业务量暴增,单表数据量太多遇到性能瓶颈,需要对订单表进行分表来缓解压力
比如1个表扩容成32张表,扩容中需要考虑一个非常关键的问题:数据迁移
02.扩容:如何做数据迁移?
方案1.停机迁移数据
方案2.不停机+操作日志法,平滑迁移数据
方案3.不停机+双写法,平滑迁移数据
03.方案1:停机-数据迁移
1.发布停机升级公告
2.开发数据迁移工具,将旧表数据迁移到新表
3.开发数据校验工具,确保新表和旧表数据是一致的
4.升级系统,所有业务逻辑使用新表
5.升级完毕,对外提供服务
04.方案2:不停机+操作日志法,平滑迁移数据
a.step1:升级代码,记录旧表操作日志,发布上线
对代码进行升级,需要创建一张操作日志表(t_order_log),对旧表中任意记录的增删改(insert、delete、update)操作
都需要写一条记录到操作日志表,这个日志主要是记录旧表中哪些数据发生了变化
-----------------------------------------------------------------------------------------------------
日志表主要有2个字段,如下,这里并不需要记录具体是什么操作,只需要知道哪条数据发生了变化就可以了
log_id:主键id,自动增长
order_id:当前操作的订单id
-----------------------------------------------------------------------------------------------------
此时依旧是旧表对外提供服务。
b.step2:将旧表所有数据迁移到新表
开发一个数据迁移程序,将旧表的所有数据,迁移到新表,伪代码如下
-----------------------------------------------------------------------------------------------------
// 查询旧订单表:最小订单id
int minOrderId = select min(order_id) from t_order_old;
minOrderId = minOrderId - 1;
//循环将旧表订单数据,迁移到新表,按照订单号升序的方式,依次进行迁移
while(true){
// 从旧表中获取一批订单,将其迁移到新表
List<Order> oldOrderList = select * from 旧订单表 where order_id > #{minOrderId} limit 100 order by order_id asc;
// 若没有数据,直接退出
if(oldOrderList.isEmpty()){
break;
}
//将 orderList 写入新表
for(Order oldOrder in oldOrderList){
//将旧表订单记录写入新表
insert 新订单表 values (订单信息oldOrder);
}
// 将minOrderId设置为oldOrderList最后一条记录的订单id
minOrderId = oldOrderList.get(oldOrderList.size() - 1).orderId;
}
c.step3:新表中重放旧表操作日志
step2执行的过程中,系统依旧在运行,所有操作依旧是在旧的订单表上,这个过程中,旧表的数据会发生变化
所有发生变化的记录都会被记录在step1中的日志表中。
此时只需在新表上重放所有操作日志就可以了,便可将发生变化的旧记录同步到新表中,处理逻辑如下
-----------------------------------------------------------------------------------------------------
// 查询日志表:最小操作日志
int minLogId = select min(log_id) from t_order_log;
minLogId = minLogId - 1;
// 将日志在新的订单表进行重放
while(true){
// 从日志表拉取一批数据(按日志id升序拉取大于 minLogId 的100条记录),在新的订单表进行处理
List<OrderLog> logList = select log_id as logId, order_id as orderId from 操作日志表t_order_log where log_id > #{minLogId} limit 100 order by log_id asc;
// 若没有数据,可以休眠一会继续,休眠这个过程中,可能有新的日志进来了
if(logList.isEmpty()){
//比如:休眠1秒
sleep(1000);
}
//将 logList 写入新表
for(OrderLog log in logList){
//根据日志记录中的订单id,去旧表查询订单记录
Order oldOrder = select * from 旧订单表 where order_id = #{log.orderId};
//旧表订单记录不存在,说明被删除了
if(oldOrder==null){
//将订单从新表删除
delete from 新订单表 where order_id = #{log.orderId};
}else{
//更新操作相当于 delete + insert
//先将订单从新表删除
delete from 新订单表 where order_id = #{log.orderId};
//将订单记录重新写入新表
insert 新订单表 values (订单信息oldOrder);
}
//将日志从日志表删除
delete from t_order_log where log_id = #{log.logId};
}
// 将minLogId设置为logList最后一条记录的id
minLogId = logList.get(logList.size() - 1).logId;
}
-----------------------------------------------------------------------------------------------------
日志重放的过程中,线上业务一直在执行,又会产生新的操作日志,这样会出现一个问题
新表的数据永远无法和旧表完全一致,只能是无限接近;在某个时刻,日志全部被处理或者近乎处理完毕时,立即进入step4
d.step4:禁止旧订单表写入数据(包括:insert、delete、update)
可以在程序中或者在db层,禁止旧的订单表写入数据(insert、delete、update)
然后将日志中的记录在新表重放完毕,此时新表和旧表数据完全一致,然后进入step5
e.step5:通过开关将流量切到新表
step1中升级的代码中,要包含兼容新表的代码,但是在step1发布上线时,这个功能可以通过一个开关控制着,属于关闭状态
此时,两边数据一致了,将开关打开,会执行新的代码,所有订单请求将被路由到新表,完成迁移
05.方案3:不停机+双写,平滑迁移数据
a.step1:升级程序,开启双写
对旧表任何写操作(包含insert、delete、update),同时也要在新表执行同样的操作
---------------------------------------------------------------------------------------------------------
insert 操作,2边都会成功
delete操作,旧表成功,新表中数据有可能不存在,执行delete也没关系
update操作,旧表更新成功,被更新的记录可能在新表不存在,也没关系
---------------------------------------------------------------------------------------------------------
此时依旧是旧表对外提供服务。
b.step2:将旧表所有数据迁移到新表
开发一个数据迁移程序,将旧表的所有数据,迁移到新表,伪代码如下
---------------------------------------------------------------------------------------------------------
// 旧订单表:最小订单id
int minOrderId = select min(order_id) from t_order_old;
minOrderId = minOrderId - 1;
//循环将旧表订单数据,迁移到新表,按照订单号升序的方式,依次进行迁移
while(true){
// 从旧表中获取一批订单,将其迁移到新表
List<Order> orderList = select * from 旧订单表 where order_id > #{minOrderId} limit 100 order by order_id asc;
// 若没有数据,直接退出
if(orderList.isEmpty()){
break;
}
//将 orderList 写入新表
for(Order order in orderList){
开启事务;
//从旧表读取订单记录,需要对旧的订单记录进行上锁,避免在同步当前记录的时候,旧数据被修改,导致同步到新表的数据和旧表不一致,这里使用for update对旧记录上锁,此时其他线程是无法修改当前旧的订单记录
Order oldOrder = select * from 旧订单表 where order_id = #{order.orderId} for update;
//订单记录可能在新表已经存在了,不管是否存在,都可以通过 delete + insert 解决
//先将订单从新表删除
delete from 新订单表 where order_id = #{log.orderId};
//将oldOrder写入新表
insert 新的订单表 values (订单信息oldOrder);
提交事务;
}
// 将minOrderId设置为orderList最后一条记录的id
minOrderId = orderList.get(orderList.size() - 1).orderId;
}
---------------------------------------------------------------------------------------------------------
这里面有个关键点,大伙需要注意,将某一条旧的订单记录同步到新的表,有2个步骤
1.第1步查询旧的记录
2 第2步将旧的记录插入新表
---------------------------------------------------------------------------------------------------------
这个过程中容易出问题:假如刚好第1步执行后,第2步还未执行时,旧表的数据被某个请求修改了
那么此时同步到新表的数据和旧表数据会出现不一致,为了避免这个问题,上面从旧表查询数据的时候
使用了for update对旧的记录进行加锁,可确保事务提交前被加锁(for update)的记录是无法被其他线程修改
c.step3:校验两边数据一致性
需开发一套程序,对新表和旧表数据一致性进行校验,看下两边订单记录的数据是否是一致的,若不一致,则找到原因进行修复,重新同步
若没有问题,进入step4
d.step4:将流量切换到新表
可以在程序中通过开关控制,停止旧表对外提供服务,开启新表对外提供服务
8.3 并发编程有多难?值得反复研究的一个案例
01.超卖场景演示
a.2个线程下单过程
2个线程,按照下面的顺序下单,都下单20个,会出现超卖
| thread1 | thread2 |
| -------------------------------- | -------------------------------- |
| 开启事务 | |
| 获取分布式锁成功 | |
| 看到的库存是20 | |
| 扣减20个库存,stock = stock - 20 | |
| 更新库存 | |
| 插入订单,num = 20 | |
| 释放锁 | 开启事务 |
| | 获取分布式锁成功 |
| | 看到的库存也是20 |
| 提交事务 | 扣减20个库存,stock = stock - 20 |
| | 更新库存 |
| | 插入订单,num = 20 |
| | 释放锁 |
| | 提交事务 |
b.说明
最终,商品原本只有20个,但是2个线程都下单了20个商品,都成功了,超卖了20个
02.总结
a.并发编程的难度
并发编程确实比较难,需要大家多思考,多总结经验
b.如何避免超卖
关于如何避免超卖:请看第 4 节
c.分布式锁的可靠性
分布式锁,并非100%可靠,使用分布式主要是可以为我们挡住大部分不合理的请求,但是还需要有兜底的方案,比如超卖,还是得靠数据库来兜底
d.分布式的介绍
关于分布式的介绍:请看第 39 节,有详细的介绍
8.4 使用Redis Pipeline,接口性能提升10倍
00.汇总
当需要用redis执行多个命令,且多个命令之间没有相互依赖的时,可采用pipeline,大幅提升性能,可以用来优化接口性能
01.使用redis执行N个命令
a.做法
假如我们有 N 个命令,需要让redis去执行
常见的做法,如下图,先发送第1个命令给redis,拿到响应后,再发送下一个命令,来来回回,需和redis交互N次
b.说明
如果有1000个命令,每个命令耗时10毫秒,那么需要和redis来回交互1000次,差不多耗时10秒左右,效率非常低,有没有更好的办法呢?
Redis Pipeline 可以解决这个问题
02.使用redis Pipeline 执行N个命令
a.Redis Pipeline技术
Redis中的Pipeline技术,可以将多个命令一次性打包发给redis,然后redis按顺序执行每个命令
然后将所有命令的执行结果打包一次性返回给客户端
b.说明
N个命令来回只需交互一次就可以了,性能大幅提升
图片说明:使用Redis Pipeline执行N个命令的示意图
03.带大家看下效果
a.概述
3个案例,重点看案例1和案例2,案例1使用循环执行100个redis命令
案例2使用pipeline执行同样的100个命令,然后对比下性能,会让大家惊讶
b.案例1:使用循环执行100个命令,看性能
com.itsoku.lesson074.Lesson074ApplicationTest#test1
-----------------------------------------------------------------------------------------------------
大概耗时60毫秒左右
c.案例2:使用pipeline执行100个命令,看性能
com.itsoku.lesson074.Lesson074ApplicationTest#test2
-----------------------------------------------------------------------------------------------------
大概耗时6秒左右,相对于案例1,性能提升了10倍
这里演示了100个命令,性能提升了10倍,如果命令更多,性能提升更明显,大家可以自己试试
d.案例3:pipeline中可以批量执行任何命令
com.itsoku.lesson074.Lesson074ApplicationTest#test3
8.5 电商中,重复支付如何解决?
00.汇总
重复支付,极端情况下,难以避免,推荐的做法是:出现这种问题后,将资金原路返回到用户的支付账户,就可以了
不管是依靠人工处理还是程序自动处理,都可以
01.什么是重复支付
同一笔订单,用户付了两次款,且两次都成功了
02.重复支付演示
美团外面APP,可以重现这个问题,流程如下:
1.准备2部手机,手机1、手机2
2.2部手机登录同一个美团账号
3.手机1:随便找一个店铺,下一笔订单,将订单提交,先别支付,此时订单待支付
4.手机1:对这笔订单,发起微信支付,此时会跳转到微信,先别支付
5.手机2:也能看到这笔订单,对这笔订单发起支付宝支付,此时会跳转到支付宝,然后输入支付密码,支付成功
6.回到手机1:输入微信支付密码,支付成功
此时就出现了同一笔订单,成功支付了2次,一次微信支付、一次支付宝支付;不过稍后会收到美团的一笔退款
03.出现重复支付,怎么处理?
支付,涉及到和第三方支付进行交互,里面涉及到网络问题,数据一致性的问题,单靠商户端很难避免重复支付,大部分app是允许重复支付发生的
那我们只需要考虑,若出现了重复支付的问题,怎么解决就可以了
比如去包子店买包子,用手机支付了2次,那么只需要和老板核对下,老板确认后,会将第二笔支付金额退还给我们
同样,电商系统也可以借鉴这个思路,当订单出现重复支付的时,只保留第一笔成功的支付记录,其他支付成功的记录原路退回给用户就可以了
04.代码应该如何落地?
a.需要2张表
一张订单表,一张订单支付记录表,他们是一对多的关系,一个订单可能有多条支付记录,下面来看下这2张表,这里只列出关键的一些字段
b.订单表(t_order)
id:订单
price:订单金额
status:0:待支付;100:已支付
用户下单的时候,会向这张表写入一条数据,状态为`待支付`
c.订单支付记录表(t_order_pay)
id:支付记录
order_id:订单id,指向(t_order表中的id)
price:支付金额
status:状态,0:支付中,100:支付成功,200:退款中,300:退款成功
当用户对某一笔订单进行支付的时候,会向该表插入一条记录,状态为`支付中`
d.支付流程
先带大家熟悉下支付流程,熟悉后,解决重复支付就很容易了。
图片说明:电商重复支付的处理流程示意图
e.处理支付回调:含重复支付处理
下面是支付回调的伪代码,里面包含了重复支付的处理,对于重复支付,只保留第一笔成功的支付记录,其他的成功支付记录将原路退款
-----------------------------------------------------------------------------------------------------
/**
* outOrderNo:电商这边订单支付记录id
* paySuccess:支付结果,true:支付成功,false:支付失败
**/
public boolean payCallBack(String outOrderNo, boolean paySuccess) {
//1、先根据outOrderNo找到支付记录
OrderPay orderPay = select * from t_order_pay where id = #{outOrderNo} ;
//2、若支付订单不是待支付,说明已处理过了
if (orderPay != 待支付) {
return true;
}
//3、为了避免并发问题,这里对同一笔订单加分布式锁,确保同一笔订单,并发收到多个通知时,排队执行
String orderId = orderPay.orderId;
distributeLock.lock("order-" + orderId);
try {
//4、支付失败
if (!paySuccess) {
//将支付订单改成支付失败状态
update t_order_pay set status = 支付失败 where id = #{outOrderNo} ;
return true;
}
/**
*支付成功的逻辑,如下
**/
//5、根据订单id,查询成功的支付记录
OrderPay successOrderPay = select * from t_order_pay where id = #{orderId} and status = 支付成功 limit 1;
//6、不存在成功的记录,说明还未成功支付过
if (successOrderPay == null) {
//6.1、则将outOrderNo这笔支付记录置为支付成功
update t_order_pay set status = 支付成功 where id = #{outOrderNo} ;
//6.2、将关联的订单状态支付支付成功
update t_order set status = 支付成功 where id = #{orderId} ;
return true;
}
//7、若存在已支付成功的记录,且id和outOrderNo不一样,说明重复支付了,则要对outOrderNo这边支付记录发起退款
if (!successOrderPay.id.equals(outOrderNo)) {
//7.1、对outOrderNo这笔支付记录发起退款,状态置为:退款中
update t_order_pay set status = 退款中 where id = #{outOrderNo} ;
//7.2、调用微信支付发起退款,这里需要注意,退款结果可能是异步的
发起微信退款,原路退款;
//7.3、将outOrderNo这笔支付记录,状态置为:退款成功
update t_order_pay set status = 退款成功 where id = #{outOrderNo} ;
return ture;
}
} finally {
//8、释放分布式锁
distributeLock.unlock();
}
//返回成功
return ture;
}
8.6 千万级数据,全表update的正确姿势
01.准备千万数据
a.创建测试表
create table t_demo (
id bigint auto_increment PRIMARY key,
c1 bigint
);
b.下面对代码会向t_demo表插入1000万数据,可能需要稍等会
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class BatchInsertExample {
public static void main(String[] args) throws SQLException {
String jdbcUrl = "jdbc:mysql://localhost:3306/luren?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8";
String username = "root";
String password = "root123";
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
// 建立数据库连接
connection = DriverManager.getConnection(jdbcUrl, username, password);
// SQL插入语句,使用占位符来防止SQL注入
String sql = "INSERT INTO t_demo(c1) VALUES (?)";
// 创建PreparedStatement对象,并设置为批处理模式
preparedStatement = connection.prepareStatement(sql);
for (int j = 0; j < 2000; j++) {
connection.setAutoCommit(false); // 设置为手动提交
long c1 = System.currentTimeMillis();
// 循环添加多个批处理操作
for (int i = 0; i < 5000; i++) {
// 设置占位符的值
preparedStatement.setLong(1, c1 + 1);
// 添加到批处理中
preparedStatement.addBatch();
}
// 执行批处理
int[] batchResults = preparedStatement.executeBatch();
System.out.println(batchResults.length);
// 手动提交事务
connection.commit();
}
} catch (SQLException e) {
e.printStackTrace();
// 发生异常时回滚事务
if (connection != null) {
connection.rollback();
}
} finally {
// 关闭PreparedStatement和Connection
if (preparedStatement != null) {
preparedStatement.close();
}
if (connection != null) {
connection.close();
}
}
}
}
c.千万数据准备完毕
mysql> select count(*) from t_demo;
+----------+
| count(*) |
+----------+
| 10075001 |
+----------+
1 row in set (1.92 sec)
02.千万数据全表更新存在的问题
a.影响系统性能
执行时间长:全表更新是一个极其耗时的操作,因为数据库需要遍历表中的每一条记录并进行更新,对于千万级的数据表,这个过程可能需要数小时甚至更长时间
资源消耗大:全表更新会大量消耗数据库服务器的CPU、内存和I/O资源,导致服务器性能下降,可能影响其他数据库操作的响应时间和吞吐量
锁表问题:在更新过程中,数据库可能会对表进行锁定,以防止数据不一致,这会导致其他用户或进程无法访问该表,从而影响业务的正常运行
b.导致主从同步延迟严重
全表更新会一次性在主库上产生大量binlog日志,而主从同步是依靠binlog来完成的,此时就会导致主从同步延迟特别严重
比如系统采用了读写分离,某个用户在界面上更新了一个数据,操作完成后,去另外一个页面查看操作结果,而这个页面的数据是从从库获取的,由于主从延迟严重,用户此时看到的结果和期望的不一致,会感觉莫名其妙
c.可能导致系统崩溃
更新过程中会导致锁表,此时如果有大量其他请求也去更新此表的数据,都会被阻塞,进而可能会耗光tomcat的线程,导致系统无法继续对外提供服务,引起连锁反应,导致整个系统崩溃
03.演示下全表更新:会锁表,耗时特别久
a.窗口1中
全表更新千万数据,此操作执行过程中,会对整个表的数据上锁
update t_demo set c1 = c1 + 1;
b.窗口2中
按主键更新1条数据,由于窗口1中对全表上锁了,窗口2中这个操作会被阻塞
update t_demo set c1 = c1+1 where id = 1;
04.正确的更新姿势
//获取表中最小的id
long minId = select min(id) from t_demo;
//循环批量更新数据
while(true){
//查询出1000条需要更新的记录的id,注意查询条件(id>=#{minId}),这个查询会走主键索引,查询会特别快,毫秒级别
List<Long> idList = select id from t_demo where id>=#{minId} limit 1000;
//如果数据为空,说明没有需要更新的数据了,跳出循环
if(idList为空){
break;
}
//根据id批量更新数据,这里更新1000条数据,也会非常快,事务也很小,也是毫秒级别
update t_demo set 更新的字段 where id in (#{idList[0]},#{idList[1]},...,#{idList[n]});
//minId = idList最后一条记录的id
minId = idList.get(idList.size()-1);
}
8.7 优雅实现树形菜单,适用于所有树,太好用了
01.背景
树形菜单,经常会用到,通常后端需要给前端提供接口,返回树形json数据,前端将其渲染成树结构
hutool中给我们提供了一个通用的树工具类:TreeUtil,里面提供了很多好的用法,比如用来构建树的方法,非常好用
02.先带大家看下效果
a.说明
启动SpringBoot应用`com.itsoku.lesson077.Lesson077Application`
浏览器中访问:http://localhost:8080/menuTree
b.返回下面json数据,是树形结构的,前端拿到后,便可轻松处理
[
{
"id": "1",
"name": "菜单1",
"parentId": null,
"weight": 1,
"url": "url1",
"children": [
{
"id": "101",
"name": "菜单101",
"parentId": "1",
"weight": 1,
"url": "url101"
},
{
"id": "102",
"name": "菜单102",
"parentId": "1",
"weight": 1,
"url": "url102"
}
]
},
{
"id": "2",
"name": "菜单2",
"parentId": null,
"weight": 1,
"url": "url2",
"children": [
{
"id": "201",
"name": "菜单201",
"parentId": "2",
"weight": 1,
"url": "url201"
},
{
"id": "202",
"name": "菜单202",
"parentId": "2",
"weight": 2,
"url": "url202"
}
]
}
]
c.说明
上面json数据,对应下面这2棵树
03.代码解析
a.引入hutool maven配置
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.2</version>
</dependency>
b.案例代码
package com.itsoku.lesson077;
import cn.hutool.core.lang.tree.Tree;
import cn.hutool.core.lang.tree.TreeUtil;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/8/22 21:01 <br>
* <b>author</b>:ready [email protected]
*/
@RestController
public class MenuController {
/**
* 获取树形菜单
*
* @return
*/
@GetMapping("/menuTree")
public List<Tree<String>> menuTree() {
//菜单列表,放在一个menuPOList中,我们用的时候这个数据可以从 db 中去获取
List<MenuPO> menuPOList = new ArrayList<>();
menuPOList.add(MenuPO.builder().id("1").name("菜单1").pid(null).theSort(1).url("url1").build());
menuPOList.add(MenuPO.builder().id("101").name("菜单101").pid("1").theSort(1).url("url101").build());
menuPOList.add(MenuPO.builder().id("102").name("菜单102").pid("1").theSort(1).url("url102").build());
menuPOList.add(MenuPO.builder().id("2").name("菜单2").pid(null).theSort(1).url("url2").build());
menuPOList.add(MenuPO.builder().id("201").name("菜单201").pid("2").theSort(1).url("url201").build());
menuPOList.add(MenuPO.builder().id("202").name("菜单202").pid("2").theSort(2).url("url202").build());
/**
* 下面通过 hutool 提供的工具类 TreeUtil.build,将上面的菜单列表转换为树
* 3个参数
* 参数1:数据源,即要被转换为树的原始数据,本案例中就是上面的 menuPOList
* 参数2:根节点id
* 参数3:转换器,数据源的数据可以是各种类型的,但是hutool不能识别,所以这里需要一个转换器,
* 将第一个参数中的元素转换为 hutool可以识别的类型:Tree类(hutool对树节点的一个抽象),
* Tree表示树的一个节点,里面包含了这个节点所有的信息
*/
List<Tree<String>> treeList = TreeUtil.build(menuPOList, null, (MenuPO menuPo, Tree<String> treeNode) -> {
//树节点id
treeNode.setId(menuPo.getId());
//树节点名称
treeNode.setName(menuPo.getName());
//父节点id
treeNode.setParentId(menuPo.getPid());
//权重,相当于同级节点的顺序,同级会按升序排序
treeNode.setWeight(menuPo.getTheSort());
//节点扩展数据,可以通过put方法,放入任意个扩展数据
treeNode.put("url", menuPo.getUrl());
});
return treeList;
}
}
8.8 接口调用利器:RestTemplate,吃透它
01.RestTemplate概述
发送http请求,估计很多人用过 httpclient 和 okhttp,确实挺好用的
而 Spring 中的 RestTemplate 和这俩的功能类似,也是用来发送http请求的,不过用法上面比前面的2位要容易很多
本文给大家上 17 个案例,基本上涵盖了RestTemplate所有的用法
02.发送Get请求
a.普通请求
a.接口代码
@GetMapping("/test/get")
@ResponseBody
public BookDto get() {
return new BookDto(1, "高并发 & 微服务 & 性能调优实战案例 100 讲");
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class BookDto {
private Integer id;
private String name;
}
b.使用RestTemplate调用上面这个接口,通常有2种写法,如下
@Test
public void test1() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/get";
//getForObject方法,获取响应体,将其转换为第二个参数指定的类型
BookDto bookDto = restTemplate.getForObject(url, BookDto.class);
System.out.println(bookDto);
}
@Test
public void test2() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/get";
//getForEntity方法,返回值为ResponseEntity类型
// ResponseEntity中包含了响应结果中的所有信息,比如头、状态、body
ResponseEntity<BookDto> responseEntity = restTemplate.getForEntity(url, BookDto.class);
//状态码
System.out.println(responseEntity.getStatusCode());
//获取头
System.out.println("头:" + responseEntity.getHeaders());
//获取body
BookDto bookDto = responseEntity.getBody();
System.out.println(bookDto);
}
c.test1输出
BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}
d.test2输出
200 OK
头:[Content-Type:"application/json;charset=UTF-8", Transfer-Encoding:"chunked", Date:"Sat, 02 Oct 2021 07:05:15 GMT", Keep-Alive:"timeout=20", Connection:"keep-alive"]
BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}
b.url中含有动态参数
a.接口代码
@GetMapping("/test/get/{id}/{name}")
@ResponseBody
public BookDto get(@PathVariable("id") Integer id, @PathVariable("name") String name) {
return new BookDto(id, name);
}
b.使用RestTemplate调用上面这个接口,通常有2种写法,如下
@Test
public void test3() {
RestTemplate restTemplate = new RestTemplate();
//url中有动态参数
String url = "http://localhost:8080/test/get/{id}/{name}";
Map<String, String> uriVariables = new HashMap<>();
uriVariables.put("id", "1");
uriVariables.put("name", "高并发 & 微服务 & 性能调优实战案例 100 讲");
//使用getForObject或者getForEntity方法
BookDto bookDto = restTemplate.getForObject(url, BookDto.class, uriVariables);
System.out.println(bookDto);
}
@Test
public void test4() {
RestTemplate restTemplate = new RestTemplate();
//url中有动态参数
String url = "http://localhost:8080/test/get/{id}/{name}";
Map<String, String> uriVariables = new HashMap<>();
uriVariables.put("id", "1");
uriVariables.put("name", "高并发 & 微服务 & 性能调优实战案例 100 讲");
//getForEntity方法
ResponseEntity<BookDto> responseEntity = restTemplate.getForEntity(url, BookDto.class, uriVariables);
BookDto bookDto = responseEntity.getBody();
System.out.println(bookDto);
}
c.test3输出
BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}
d.test4输出
BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}
c.接口返回值为泛型
a.接口代码
@GetMapping("/test/getList")
@ResponseBody
public List<BookDto> getList() {
return Arrays.asList(
new BookDto(1, "Spring高手系列"),
new BookDto(2, "高并发 & 微服务 & 性能调优实战案例 100 讲")
);
}
b.当接口的返回值为泛型的时候,这种情况比较特殊
使用RestTemplate调用上面这个接口,代码如下,需要用到restTemplate.exchange的方法
这个方法中有个参数是ParameterizedTypeReference类型,通过这个参数类指定泛型类型
-------------------------------------------------------------------------------------------------
@Test
public void test5() {
RestTemplate restTemplate = new RestTemplate();
//返回值为泛型
String url = "http://localhost:8080/test/getList";
//若返回结果是泛型类型的,需要使用到exchange方法,
//这个方法中有个参数是ParameterizedTypeReference类型,通过这个参数类指定泛型类型
ResponseEntity<List<BookDto>> responseEntity =
restTemplate.exchange(url,
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<BookDto>>() {
});
List<BookDto> bookDtoList = responseEntity.getBody();
System.out.println(bookDtoList);
}
c.输出
[BookDto{id=1, name='Spring高手系列'}, BookDto{id=2, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}]
d.下载小文件
a.接口代码如下,这个接口会下载服务器端的1.txt文件
/**
* 下载文件
*
* @return
*/
@GetMapping("/test/downFile")
@ResponseBody
public HttpEntity<InputStreamResource> downFile() {
//将文件流封装为InputStreamResource对象
InputStream inputStream = this.getClass().getResourceAsStream("/1.txt");
InputStreamResource inputStreamResource = new InputStreamResource(inputStream);
//设置header
MultiValueMap<String, String> headers = new HttpHeaders();
headers.add(HttpHeaders.CONTENT_DISPOSITION, "attachment;filename=1.txt");
HttpEntity<InputStreamResource> httpEntity = new HttpEntity<>(inputStreamResource);
return httpEntity;
}
b.使用RestTemplate调用这个接口,代码如下,目前这个文件的内容比较少,可以直接得到一个数组
@Test
public void test6() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/downFile";
//文件比较小的情况,直接返回字节数组
ResponseEntity<byte[]> responseEntity = restTemplate.getForEntity(url, byte[].class);
//获取文件的内容
byte[] body = responseEntity.getBody();
String content = new String(body);
System.out.println(content);
}
c.注意
如果文件大的时候,这种方式就有问题了,会导致oom,要用下面的方式了
e.下载大文件
a.接口代码,继续使用上面下载1.txt的代码
/**
* 下载文件
*
* @return
*/
@GetMapping("/test/downFile")
@ResponseBody
public HttpEntity<InputStreamResource> downFile() {
//将文件流封装为InputStreamResource对象
InputStream inputStream = this.getClass().getResourceAsStream("/1.txt");
InputStreamResource inputStreamResource = new InputStreamResource(inputStream);
//设置header
MultiValueMap<String, String> headers = new HttpHeaders();
headers.add(HttpHeaders.CONTENT_DISPOSITION, "attachment;filename=1.txt");
HttpEntity<InputStreamResource> httpEntity = new HttpEntity<>(inputStreamResource);
return httpEntity;
}
b.此时使用RestTemplate调用这个接口,代码如下
文件比较大的时候,比如好几个G,就不能返回字节数组了,会把内存撑爆,导致OOM
需要使用execute方法了,这个方法中有个ResponseExtractor类型的参数
restTemplate拿到结果之后,会回调{@link ResponseExtractor#extractData}这个方法
在这个方法中可以拿到响应流,然后进行处理,这个过程就是变读边处理,不会导致内存溢出
-------------------------------------------------------------------------------------------------
@Test
public void test7() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/downFile";
/**
* 文件比较大的时候,比如好几个G,就不能返回字节数组了,会把内存撑爆,导致OOM
* 需要这么玩:
* 需要使用execute方法了,这个方法中有个ResponseExtractor类型的参数,
* restTemplate拿到结果之后,会回调{@link ResponseExtractor#extractData}这个方法,
* 在这个方法中可以拿到响应流,然后进行处理,这个过程就是变读边处理,不会导致内存溢出
*/
String result = restTemplate.execute(url,
HttpMethod.GET,
null,
new ResponseExtractor<String>() {
@Override
public String extractData(ClientHttpResponse response) throws IOException {
System.out.println("状态:"+response.getStatusCode());
System.out.println("头:"+response.getHeaders());
//获取响应体流
InputStream body = response.getBody();
//处理响应体流
String content = IOUtils.toString(body, "UTF-8");
return content;
}
}, new HashMap<>());
System.out.println(result);
}
f.传递头
a.接口代码
@GetMapping("/test/header")
@ResponseBody
public Map<String, List<String>> header(HttpServletRequest request) {
Map<String, List<String>> header = new LinkedHashMap<>();
Enumeration<String> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
Enumeration<String> values = request.getHeaders(name);
List<String> list = new ArrayList<>();
while (values.hasMoreElements()) {
list.add(values.nextElement());
}
header.put(name, list);
}
return header;
}
-------------------------------------------------------------------------------------------------
b.使用RestTemplate调用接口,请求头中传递数据,代码如下,注意代码①和②,这两处是关键,用到了HttpHeaders和RequestEntity
请求头放在HttpHeaders对象中
RequestEntity:请求实体,请求的所有信息都可以放在RequestEntity中,比如body部分、头、请求方式、url等信息
-------------------------------------------------------------------------------------------------
@Test
public void test8() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/header";
//①:请求头放在HttpHeaders对象中
MultiValueMap<String, String> headers = new HttpHeaders();
headers.add("header-1", "V1");
headers.add("header-2", "Spring");
headers.add("header-2", "SpringBoot");
//②:RequestEntity:请求实体,请求的所有信息都可以放在RequestEntity中,比如body部分、头、请求方式、url等信息
RequestEntity requestEntity = new RequestEntity(
null, //body部分数据
headers, //头
HttpMethod.GET,//请求方法
URI.create(url) //地址
);
ResponseEntity<Map<String, List<String>>> responseEntity = restTemplate.exchange(requestEntity,
new ParameterizedTypeReference<Map<String, List<String>>>() {
});
Map<String, List<String>> result = responseEntity.getBody();
System.out.println(result);
}
c.输出
{accept=[application/json, application/*+json], header-1=[V1], header-2=[Spring, SpringBoot], user-agent=[Java/1.8.0_121], host=[localhost:8080], connection=[keep-alive]}
g.综合案例:含头、url动态参数
a.接口
@GetMapping("/test/getAll/{path1}/{path2}")
@ResponseBody
public Map<String, Object> getAll(@PathVariable("path1") String path1,
@PathVariable("path2") String path2,
HttpServletRequest request) {
Map<String, Object> result = new LinkedHashMap<>();
result.put("path1", path1);
result.put("path2", path2);
//头
Map<String, List<String>> header = new LinkedHashMap<>();
Enumeration<String> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
Enumeration<String> values = request.getHeaders(name);
List<String> list = new ArrayList<>();
while (values.hasMoreElements()) {
list.add(values.nextElement());
}
header.put(name, list);
}
result.put("header", header);
return result;
}
b.如下,使用RestTemplate调用接口,GET方式、传递header、path中动态参数
@Test
public void test9() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/getAll/{path1}/{path2}";
//①:请求头
MultiValueMap<String, String> headers = new HttpHeaders();
headers.add("header-1", "V1");
headers.add("header-2", "Spring");
headers.add("header-2", "SpringBoot");
//②:url中的2个参数
Map<String, String> uriVariables = new HashMap<>();
uriVariables.put("path1", "v1");
uriVariables.put("path2", "v2");
//③:HttpEntity:HTTP实体,内部包含了请求头和请求体
HttpEntity requestEntity = new HttpEntity(
null,//body部分,get请求没有body,所以为null
headers //头
);
//④:使用exchange发送请求
ResponseEntity<Map<String, Object>> responseEntity = restTemplate.exchange(
url, //url
HttpMethod.GET, //请求方式
requestEntity, //请求实体(头、body)
new ParameterizedTypeReference<Map<String, Object>>() {
},//返回的结果类型
uriVariables //url中的占位符对应的值
);
Map<String, Object> result = responseEntity.getBody();
System.out.println(result);
}
c.输出
{path1=v1, path2=v2, header={accept=[application/json, application/*+json], header-1=[V1], header-2=[Spring, SpringBoot], user-agent=[Java/1.8.0_121], host=[localhost:8080], connection=[keep-alive]}}
03.发送POST请求
a.POST 请求常见的3种类型
| Content-Type | 说明
| --------------------------------- | ------------------------------------------------------------
| application/x-www-form-urlencoded | 页面中普通的form表单提交时就是这种类型,表单中的元素会按照名称和值拼接好,然后之间用&连接,格式如:p1=v1&p2=v2&p3=v3<br />然后通过urlencoded编码之后丢在body中发送
| multipart/form-data | 页面中表单上传文件的时候,用到的就是这种格式
| application/json | 将发送的数据转换为json格式,丢在http请求的body中发送,后端接口通常用@RequestBody配合对象来接收。
下面看则种方式的案例。
b.普通表单请求
a.普通表单默认为application/x-www-form-urlencoded类型的请求
@PostMapping("/test/form1")
@ResponseBody
public BookDto form1(BookDto bookDto) {
return bookDto;
}
b.使用RestTemplate调用接口
@Test
public void test10() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form1";
//①:表单信息,需要放在MultiValueMap中,MultiValueMap相当于Map<String,List<String>>
MultiValueMap<String, String> body = new LinkedMultiValueMap<>();
//调用add方法填充表单数据(表单名称:值)
body.add("id","1");
body.add("name","高并发 & 微服务 & 性能调优实战案例 100 讲");
//②:发送请求(url,请求体,返回值需要转换的类型)
BookDto result = restTemplate.postForObject(url, body, BookDto.class);
System.out.println(result);
}
c.如果想携带头信息,代码如下
@Test
public void test11() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form1";
//①:表单信息,需要放在MultiValueMap中,MultiValueMap相当于Map<String,List<String>>
MultiValueMap<String, String> body = new LinkedMultiValueMap<>();
//调用add方法放入表单元素(表单名称:值)
body.add("id","1");
body.add("name","高并发 & 微服务 & 性能调优实战案例 100 讲");
//②:请求头
HttpHeaders headers = new HttpHeaders();
//调用set方法放入请求头
headers.set(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_FORM_URLENCODED_VALUE);
//③:请求实体:包含了请求体和请求头
HttpEntity<MultiValueMap<String, String>> httpEntity = new HttpEntity<>(body, headers);
//④:发送请求(url,请求实体,返回值需要转换的类型)
BookDto result = restTemplate.postForObject(url, httpEntity, BookDto.class);
System.out.println(result);
}
c.上传本地文件
a.上传文件Content-Type为multipart/form-data 类型
接口如下,上传上传单个文件,返回值为一个Map类型,是泛型类型
-------------------------------------------------------------------------------------------------
@PostMapping(value = "/test/form2")
@ResponseBody
public Map<String, String> form2(@RequestParam("file1") MultipartFile file1) {
Map<String, String> fileMetadata = new LinkedHashMap<>();
fileMetadata.put("文件名", file1.getOriginalFilename());
fileMetadata.put("文件类型", file1.getContentType());
fileMetadata.put("文件大小(byte)", String.valueOf(file1.getSize()));
return fileMetadata;
}
b.使用RestTemplate调用接口
主要下面代码②上传的文件需要包装为org.springframework.core.io.Resource
常用的有3中[FileSystemResource、InputStreamResource、ByteArrayResource]
这里案例中我们用到的是FileSystemResource来上传本地文件
另外2种(InputStreamResource、ByteArrayResource)用法就比较特殊了,见下个案例
-------------------------------------------------------------------------------------------------
@Test
public void test12() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form2";
//①:表单信息,需要放在MultiValueMap中,MultiValueMap相当于Map<String,List<String>>
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
//调用add方法放入表单元素(表单名称:值)
//②:文件对应的类型,需要是org.springframework.core.io.Resource类型的,常见的有[InputStreamResource,ByteArrayResource]
String filePath = ".\\lesson078\\src\\main\\java\\com\\itsoku\\lesson078\\dto\\UserDto.java";
body.add("file1", new FileSystemResource(filePath));
//③:头
HttpHeaders headers = new HttpHeaders();
headers.add("header1", "v1");
headers.add("header2", "v2");
//④:请求实体
RequestEntity<MultiValueMap<String, Object>> requestEntity = new RequestEntity<>(body, headers, HttpMethod.POST, URI.create(url));
//⑤:发送请求(请求实体,返回值需要转换的类型)
ResponseEntity<Map<String, String>> responseEntity = restTemplate.exchange(
requestEntity,
new ParameterizedTypeReference<Map<String, String>>() {
});
Map<String, String> result = responseEntity.getBody();
System.out.println(result);
}
d.通过流或字节数组的方式上传文件
a.有时候,上传的文件是通过流的方式或者字节数组的方式,那么就需要用到InputStreamResource、ByteArrayResource这俩了
注意:使用这俩的时候,需要重写2个方法,否则会上传失败
getFilename:文件名称
contentLength:长度
-----------------------------------------------------------------------------------------------------
@Test
public void test13() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form2";
//①:表单信息,需要放在MultiValueMap中,MultiValueMap相当于Map<String,List<String>>
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
/**
* ②:通过流的方式上传文件,流的方式需要用到InputStreamResource类,需要重写2个方法
* getFilename:文件名称
* contentLength:长度
*/
InputStream inputStream = RestTemplateTest.class.getResourceAsStream("/1.txt");
InputStreamResource inputStreamResource = new InputStreamResource(inputStream) {
@Override
public String getFilename() {
return "1.txt";
}
@Override
public long contentLength() throws IOException {
return inputStream.available();
}
};
body.add("file1", inputStreamResource);
//③:头
HttpHeaders headers = new HttpHeaders();
headers.add("header1", "v1");
headers.add("header2", "v2");
//④:请求实体
RequestEntity<MultiValueMap<String, Object>> requestEntity = new RequestEntity<>(body, headers, HttpMethod.POST, URI.create(url));
//⑤:发送请求(请求实体,返回值需要转换的类型)
ResponseEntity<Map<String, String>> responseEntity = restTemplate.exchange(
requestEntity,
new ParameterizedTypeReference<Map<String, String>>() {
});
Map<String, String> result = responseEntity.getBody();
System.out.println(result);
}
e.复杂表单:多个普通元素+多文件上传
a.接口
/**
* 复杂的表单:包含了普通元素、多文件
*
* @param userDto
* @return
*/
@PostMapping("/test/form3")
@ResponseBody
public Map<String, String> form3(UserDto userDto) {
Map<String, String> result = new LinkedHashMap<>();
result.put("name", userDto.getName());
result.put("headImg", userDto.getHeadImg().getOriginalFilename());
result.put("idImgList", Arrays.toString(userDto.getIdImgList().stream().
map(MultipartFile::getOriginalFilename).toArray()));
return result;
}
b.UserDto:包含了多个元素(姓名、头像、多张证件照),这种可以模拟复杂的表单
@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserDto {
//姓名
private String name;
//头像
private MultipartFile headImg;
//多张证件照
private List<MultipartFile> idImgList;
}
c.用RestTemplate调用这个接口,代码如下
@Test
public void test14() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form3";
//①:表单信息,需要放在MultiValueMap中,MultiValueMap相当于Map<String,List<String>>
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
body.add("name", "路人");
body.add("headImg", new FileSystemResource(".\\lesson078\\src\\main\\resources\\1.jpg"));
//来2张证件照,元素名称一样
body.add("idImgList", new FileSystemResource(".\\lesson078\\src\\main\\resources\\2.jpg"));
body.add("idImgList", new FileSystemResource(".\\lesson078\\src\\main\\resources\\3.jpg"));
//③:头
HttpHeaders headers = new HttpHeaders();
headers.add("header1", "v1");
headers.add("header2", "v2");
//④:请求实体
RequestEntity<MultiValueMap<String, Object>> requestEntity = new RequestEntity<>(body, headers, HttpMethod.POST, URI.create(url));
//⑤:发送请求(请求实体,返回值需要转换的类型)
ResponseEntity<Map<String, String>> responseEntity = restTemplate.exchange(
requestEntity,
new ParameterizedTypeReference<Map<String, String>>() {
});
Map<String, String> result = responseEntity.getBody();
System.out.println(result);
}
d.输出
{name=路人, headImg=1.jpg, idImgList=[2.jpg, 3.jpg]}
f.发送json格式数据:传递java对象
a.接口
/**
* body中json格式的数据,返回值非泛型
*
* @param bookDto
* @return
*/
@PostMapping("/test/form4")
@ResponseBody
public BookDto form4(@RequestBody BookDto bookDto) {
return bookDto;
}
b.RestTemplate调用接口
@Test
public void test15() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form4";
BookDto body = new BookDto(1, "高并发 & 微服务 & 性能调优实战案例 100 讲");
BookDto result = restTemplate.postForObject(url, body, BookDto.class);
System.out.println(result);
}
c.输出
BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}
g.发送json格式数据:传递java对象,返回值为泛型
a.接口
/**
* body中json格式的数据,返回值为泛型
*
* @param bookDtoList
* @return
*/
@PostMapping("/test/form5")
@ResponseBody
public List<BookDto> form5(@RequestBody List<BookDto> bookDtoList) {
return bookDtoList;
}
b.用RestTemplate调用这个接口,代码如下
@Test
public void test16() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form5";
//①:请求体,发送的时候会被转换为json格式数据
List<BookDto> body = Arrays.asList(
new BookDto(1, "高并发 & 微服务 & 性能调优实战案例 100 讲"),
new BookDto(2, "MySQL系列"));
//②:头
HttpHeaders headers = new HttpHeaders();
headers.add("header1", "v1");
headers.add("header2", "v2");
//③:请求实体
RequestEntity requestEntity = new RequestEntity(body, headers, HttpMethod.POST, URI.create(url));
//④:发送请求(请求实体,返回值需要转换的类型)
ResponseEntity<List<BookDto>> responseEntity = restTemplate.exchange(
requestEntity,
new ParameterizedTypeReference<List<BookDto>>() {
});
//⑤:获取结果
List<BookDto> result = responseEntity.getBody();
System.out.println(result);
}
c.输出
[BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}, BookDto{id=2, name='MySQL系列'}]
h.发送json字符串格式数据
a.上面2个json案例body都是java对象,RestTemplate默认自动配上Content-Type=application/json
但是如果body的值是json格式字符串的时候,调用的时候需要在头中明确指定Content-Type=application/json,写法如下:
-------------------------------------------------------------------------------------------------
@Test
public void test17() {
RestTemplate restTemplate = new RestTemplate();
String url = "http://localhost:8080/test/form5";
//①:请求体为一个json格式的字符串
String body = "[{\"id\":1,\"name\":\"高并发 & 微服务 & 性能调优实战案例 100 讲\"},{\"id\":2,\"name\":\"MySQL系列\"}]";
/**
* ②:若请求体为json字符串的时候,需要在头中设置Content-Type=application/json;
* 若body是普通的java类的时候,无需指定这个,RestTemplate默认自动配上Content-Type=application/json
*/
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
//③:请求实体(body,头、请求方式,uri)
RequestEntity requestEntity = new RequestEntity(body, headers, HttpMethod.POST, URI.create(url));
//④:发送请求(请求实体,返回值需要转换的类型)
ResponseEntity<List<BookDto>> responseEntity = restTemplate.exchange(
requestEntity,
new ParameterizedTypeReference<List<BookDto>>() {
});
//⑤:获取结果
List<BookDto> result = responseEntity.getBody();
System.out.println(result);
}
b.输出
[BookDto{id=1, name='高并发 & 微服务 & 性能调优实战案例 100 讲'}, BookDto{id=2, name='MySQL系列'}]
04.DELETE、PUT、OPTION请求
a.DELETE请求
public void delete(String url, Object... uriVariables);
public void delete(String url, Map<String, ?> uriVariables);
public void delete(URI url);
b.PUT请求
PUT请求和POST请求类似,将类型改为PUT就可以了
c.OPTIONS请求
public Set<HttpMethod> optionsForAllow(String url, Object... uriVariables);
public Set<HttpMethod> optionsForAllow(String url, Map<String, ?> uriVariables);
public Set<HttpMethod> optionsForAllow(URI url);
8.9 微服务跨库查询,如何解决?一次性搞懂
00.汇总
a.方案1
通过跨服务多次查询,解决问题
b.方案2
通过数据冗余的方式,解决问题;不过需要考虑数据同步的问题,关于数据同步的
大家可以将上面的数据同步方案多看几遍,如果大家工作中遇到数据同步的方案,也可以采用这种方式
01.背景
a.微服务与数据库
大家都比较熟悉微服务,通常每个服务都有自己单独的数据库
b.电商系统
假如我们有个电商系统,里面有2个核心的服务
用户服务和订单服务
用户服务对应用户库
订单服务对应订单库
2个服务之间通过接口进行交互,比如要获取对方db中数据,也只能通过接口进行操作
c.用户库-有个用户表(t_user)
| 字段 | 说明
| --------- | ------------
| user_id | 用户id,主键
| user_name | 用户名
| mobile | 手机号
d.订单库-有个订单表(t_order)
只列出了本文需要的字段,其他字段省略了
| 字段 | 说明
| -------- | ----------------------------
| order_id | 订单号,主键
| user_id | 用户id,来源于用户表(t_user)
02.需求1:如何通过手机号查询订单列表?
a.方案1:跨服务多次查询
a.step1:先调用用户服务接口,去用户表,根据手机号查询到用户id
String userId = select user_id from t_user where mobile = '手机号'
b.step2:然后调用订单服务,去订单表,根据用户id便可查询用户的订单列表
List<Order> orderList = select * from t_order where user_id = #{user_id}
c.step3:将结果返回
b.方案2:数据冗余的方式
a.step1:在订单表,冗余手机号字段:user_mobile,如下,生成订单的时候,将用户手机号写入到订单表
| 字段 | 说明
| ----------- | ----------------------------
| order_id | 订单号,主键
| user_id | 用户id,来源于用户表(t_user)
| user_mobile | 用户手机号
-------------------------------------------------------------------------------------------------
insert into t_order (order_id,user_id,user_mobile) values (订单id, 用户id,用户手机号)
b.step2:此时通过手机号查询订单列表,只需走订单服务,查询订单表便可得到结果
List<Order> orderList = select * from t_order where user_mobile = '手机号'
03.需求2:如何通过手机号模糊查询订单列表?
a.方案1:跨服务多次查询
a.step1:先调用用户服务接口,去用户表,根据手机号模糊查询得到用户id列表:userIdList
List userIdLIst = select user_id from t_user where mobile like '%手机号%';
b.step2:然后调用订单服务,去订单表,根据userIdList便可查询用户的订单列表
List orderList = select * from t_order where user_id in (userIdList)
c.step3:将结果返回
b.方案1:可能存在问题
假如根据手机号模糊匹配的用户特别多,比如有上千个或者更多,那么这种方式性能上存在问题
此时建议采用方案2:数据冗余的方式
c.方案2:数据冗余的方式
a.step1:在订单表,冗余手机号字段:user_mobile,如下,生成订单的时候,将用户手机号写入到订单表
| 字段 | 说明
| ----------- | ----------------------------
| order_id | 订单号,主键
| user_id | 用户id,来源于用户表(t_user)
| user_mobile | 用户手机号
b.step2:此时通过手机号查询订单列表,只需走订单服务,查询订单表便可得到结果
List orderList = select * from t_order where user_mobile like '%手机号%';
04.数据冗余方式存在问题:数据一致性问题
a.订单表冗余了用户手机号
假如用户通过用户服务修改了手机号,此时用户表手机号是最新的,而订单表还是用户旧的手机号
就出现了数据不一致的问题:用户库用户表中的手机号和订单库订单表中的手机号不一致
如何解决?向下看。
05.冗余方案中,数据不一致如何解决?
a.订单库添加冗余表:t_user_copy
可以在订单库创建一个用户冗余表,专门用来冗余用户的数据,表名可以叫:t_user_copy
如下,这个表的字段需要根据需求来,需要看下订单库需要用到用户表那些字段,把需要用到的字段冗余过来就可以了
没必要将用户表所有的字段都给拿过来
-----------------------------------------------------------------------------------------------------
| 字段 | 说明 |
| --------- | ------------ |
| user_id | 用户id,主键 |
| user_name | 用户名 |
| mobile | 手机号 |
b.将用户库中的用户表数据,同步到订单库的冗余表
1.刚创建订单库的冗余表(t_user_copy)的时候,上线后,可以通过程序全量从用户库的用户表同步一份过来
2.然后开启增量同步:后期用户表数据发生变化后,比如用户表发生了insert、delete、update
可以通过MQ广播一条用户数变更记录,订单服务监听这个消息
然后将变化的同步到t_user_copy这个冗余表就可以了,下面来看下增量同步的具体步骤
c.增量同步具体步骤
a.说明
用户表只能通过用户服务进行操作,用户表发生了任何 `insert、delete、update`
用户服务通过mq广播一条消息,如下,消息中只需要用户的id就可以了,不需要知道这条消息具体是什么操作引起的
-------------------------------------------------------------------------------------------------
{"userId":"本次发生变化的用户id"}
b.订单服务订阅这种消息,收到消息后,做如下处理
//1.从消息中拿到用户id
String userId = msg.userId;
//2.上分布式锁,锁的key:UserCopy:用户id;这里为了避免数据一致性,要确保同一个userId
//若来了多条消息,需要排队消费,所以上了分布式锁
//若不上锁,假如同一个userId,发生多次update操作,会产生多条消息
//可能会出现并发消费,最终同步过来的数据可能和用户表中的数据不一致
String lockKey = "UserCopy:"+userId;
lock(lockKey);
//3、携带userId,调用用户服务提供的接口,拿到用户信息
User user = 根据userId调用用户服务提供的接口,获取用户信息;
//4、从冗余表先删除用户信息
delete from t_user_copy where user_id = #{userId};
//5、若user不为空,则插入到订单库冗余表,user=null;说明这个用户被删了
if(user!=null){
insert into (t_user_copy) values (#{user});
}
//6、释放分布式锁
unlock(lockKey);
-------------------------------------------------------------------------------------------------
增量同步这个方案,建议大家多看几遍,消化下
8.10 逻辑删除与唯一约束冲突,如何解决?
00.当逻辑删除遇到唯一约束的时候,解决方案如下
1.添加is_delete字段,逻辑删除标记,0:未删除,1:已删除,默认值为0
2.添加delete_time字段,用于记录数据被逻辑删除的时间,默认值为0
3.需要添加组合字段唯一索引:( `业务上需要确保唯一的业务字段`,` delete_time` )
4.数据删除逻辑,如下:将 is_delete 置为 1, delete_time 置为当前时间戳,便可解决问题
update t_user set is_delete = 1, delete_time = UNIX_TIMESTAMP(now()) where id = 1;
01.先来看一个需求
a.假如系统中有个用户表(t_user),产品要求用户信息,需要满足下面几个条件
1.用户名必须唯一
2.用户数据不要物理删除,需要留痕,删除的时候可以对这条记录打个删除标记,标记这条记录被删除了
b.这个表应该如何设计呢?
先来看此表的第一个版本
02.用户表:第1个版本
a.表结构
| 字段 | 说明
| --------- | ------------------------------------------------------
| id | 用户id,主键
| user_name | 用户名,需添加唯一索引,确保用户名唯一
| is_delete | 逻辑删除标记,用于标记当前记录是否已删除,0:否,1:是
-----------------------------------------------------------------------------------------------------
什么是逻辑删除?
执行删除时,物理上不删除数据,只是在数据上打个标记,标记该记录已删除
比如将 is_delete 字段的值置为 1,表示该记录已删除,实际上记录并不会从表中真实删掉
如果有查询操作,需要在查询条件上加上is_delete=0,过滤出未被删除的数据
b.建表脚本
DROP TABLE IF EXISTS `t_user`;
-- 创建用户表:t_user
CREATE TABLE IF NOT EXISTS `t_user` (
`id` VARCHAR (32) NOT NULL PRIMARY KEY COMMENT '用户id',
`user_name` VARCHAR (64) NOT NULL COMMENT '用户名,唯一',
`is_delete` SMALLINT NOT NULL DEFAULT 0 COMMENT '逻辑删除标记,用于标记当前记录是否已删除,0:否,1:是',
UNIQUE KEY `uq_user_name` (`user_name`)
) COMMENT = '用户表';
c.验证是否可以满足需求
-- 插入一条记录,id为1,用户名:路人
insert into t_user (id, user_name) values ('1','路人');
-- 将路人这条记录逻辑删除:is_delete 设置为 1
update t_user set is_delete = 1 where id = 1;
-- 再次插入用户名:路人,看下是否可以插入成功
insert into t_user (id, user_name) values ('2','路人');
d.执行结果
[SQL] -- 插入一条记录,id为1,用户名:路人
insert into t_user (id, user_name) values ('1','路人');
受影响的行: 1
时间: 0.003s
-----------------------------------------------------------------------------------------------------
[SQL]
-- 将路人这条记录逻辑删除:is_delete 设置为 1
update t_user set is_delete = 1 where id = 1;
受影响的行: 1
时间: 0.002s
-----------------------------------------------------------------------------------------------------
[SQL]
-- 再次插入用户名:路人,看下是否可以插入成功
insert into t_user (id, user_name) values ('2','路人');
[Err] 1062 - Duplicate entry '路人' for key 'uq_user_name'
e.结果分析
从结果中可以看到,刚开始插入了`('1','路人')` 这条记录,稍后逻辑删除了
然后又插入了一条叫`路人`的记录,但是报错了,如下,违法了唯一约束
-----------------------------------------------------------------------------------------------------
[Err] 1062 - Duplicate entry '路人' for key 'uq_user_name'
-----------------------------------------------------------------------------------------------------
业务上看用户id为1这条`路人`已经被删除了,此时再次插入id为2用户名为`路人`的记录,按说应该成功,是不是?但是却没有成功
此时就出现了:**逻辑删除和唯一约束冲突了**,当前这种设计无法满足需求
下面来看下如何解决
03.解决方案
a.设计上需调整,主要2点
a.添加一个字段
delete_time,用来记录当前记录被逻辑删除的时间,默认值为0
当记录被逻辑删除的时候,即is_delete被设置为1的时候,将delete_time设置为当前时间戳
b.需要用到组合唯一索引
在 (user_name, delete_time) 这两个字段上添加唯一索引
b.建表脚本
DROP TABLE IF EXISTS `t_user`;
-- 创建用户表:t_user
CREATE TABLE IF NOT EXISTS `t_user` (
`id` VARCHAR (32) NOT NULL PRIMARY KEY COMMENT '用户id',
`user_name` VARCHAR (64) NOT NULL COMMENT '用户名,唯一',
`is_delete` SMALLINT NOT NULL DEFAULT 0 COMMENT '逻辑删除标记,用于标记当前记录是否已删除,0:否,1:是',
`delete_time` BIGINT NOT NULL DEFAULT 0 COMMENT '逻辑删除时间,默认为0,当is_delete被置为1的时候,将此字段设置为当前时间戳',
UNIQUE KEY `uq_user_name_delete_time` (`user_name`, `delete_time`)
) COMMENT = '用户表';
c.验证是否可以满足需求
-- 插入一条记录,id为1,用户名:路人
insert into t_user (id, user_name) values ('1','路人');
-- 将路人这条记录逻辑删除:is_delete 设置为 1, delete_time 设置为当前时间时间戳秒
update t_user set is_delete = 1, delete_time = UNIX_TIMESTAMP(now()) where id = 1;
-- 再次插入用户名:路人,插入成功
insert into t_user (id, user_name) values ('2','路人');
-- 再次插入用户名:路人,插入失败
insert into t_user (id, user_name) values ('3','路人');
d.执行结果
[SQL] -- 插入一条记录,id为1,用户名:路人
insert into t_user (id, user_name) values ('1','路人');
受影响的行: 1
时间: 0.003s
-----------------------------------------------------------------------------------------------------
[SQL]
-- 将路人这条记录逻辑删除:is_delete 设置为 1, delete_time 设置为当前时间时间戳秒
update t_user set is_delete = 1, delete_time = UNIX_TIMESTAMP(now()) where id = 1;
受影响的行: 1
时间: 0.002s
-----------------------------------------------------------------------------------------------------
[SQL]
-- 再次插入用户名:路人,插入成功
insert into t_user (id, user_name) values ('2','路人');
受影响的行: 1
时间: 0.002s
-----------------------------------------------------------------------------------------------------
[SQL]
-- 再次插入用户名:路人,插入失败
insert into t_user (id, user_name) values ('3','路人');
[Err] 1062 - Duplicate entry '路人-0' for key 'uq_user_name_delete_time'
-----------------------------------------------------------------------------------------------------
此时表中数据如下
mysql> select * from t_user;
+----+-----------+-----------+-------------+
| id | user_name | is_delete | delete_time |
+----+-----------+-----------+-------------+
| 1 | 路人 | 1 | 1724642691 |
| 2 | 路人 | 0 | 0 |
+----+-----------+-----------+-------------+
e.结果分析
从上面看,这样设计已满足需求
9 part08
9.1 评论系统如何设计,一次性给你讲清楚
01.前言
评论功能,属于非常常见的功能
本文从评论功能的需求出发,来看下评论表如何设计,以及通过此表,如何实现评论中各种功能
非常硬核,大家慢慢看
02.先来了解需求
a.说明
假如我们开发了一个短视频的网站,用户可以对视频进行评论,要实现二级评论的功能
先来看下什么是一级评论和二级评论
b.一级评论
对视频直接发表的评论,属于一级评论,如下图,下面这2条记录都是一级评论,评论列表默认只显示一级评论,支持分页
c.二级评论
一级评论下面挂的所有的评论属于二级评论,如下图
包含了对一级评论的回复
以及对一级评论下面回复的回复
03.评论表设计(t_comment)
a.表结构
| 字段 | 描述 |
| ------------------- | ------------------------------------------------------------ |
| comment_id | 评论记录id,主键 |
| video_id | 被评论的视频id |
| user_id | 评论者用户id |
| root_comment_id | 根评论id,如果是一级评论,则为0,如果是二级评论,则为一级评论的id |
| reply_to_comment_id | 指向被回复的评论id,如果是一级评论,则为0 |
| reply_to_user_id | 指向被回复的用户id,如果是一级评论,则为null;这个属于冗余字段,便于查询 |
| content | 评论的内容 |
| create_time | 评论时间 |
| count | 一级评论下二级评论数量,当前记录是一级评论时,此值才有意义,当前记录是二级评论,此值为0 |
b.表语句
drop table if exists t_comment;
CREATE TABLE t_comment (
comment_id BIGINT NOT NULL PRIMARY KEY COMMENT '评论id,主键',
video_id BIGINT NOT NULL COMMENT '被评论的视频id',
user_id varchar(32) NOT NULL COMMENT '评论者用户id',
root_comment_id BIGINT NOT NULL DEFAULT 0 COMMENT '根评论id,如果是一级评论,则为0,如果是二级评论,则为一级评论的id',
reply_to_comment_id BIGINT NOT NULL DEFAULT 0 COMMENT '指向被回复的评论id,如果是一级评论,则为0',
reply_to_user_id varchar(32) COMMENT '指向被回复的用户id,如果是一级评论,则为null;这个属于冗余字段,便于查询',
content TEXT NOT NULL COMMENT '评论的内容',
create_time datetime NOT NULL COMMENT '评论时间',
count BIGINT NOT NULL DEFAULT 0 COMMENT '一级评论下二级评论数量,当前记录是一级评论时,此值才有意义,当前记录是二级评论,此值为0'
);
04.功能演示:通过此表实现各种功能
a.说明
假如视频id是1
b.功能1:对视频发表一级评论
入参
user_id:用户id
video_id:视频id
content:评论内容
-----------------------------------------------------------------------------------------------------
假如:user_id = 用户a, video_id = 1, content = 很好看啊
-----------------------------------------------------------------------------------------------------
sql脚本如下:
insert t_comment
(comment_id, video_id, user_id, root_comment_id, reply_to_comment_id, reply_to_user_id, content, create_time, count)
values
(1, 1, '用户a', 0, 0, null, '很好看啊', NOW(), 0);
-----------------------------------------------------------------------------------------------------
评论表当前数据
select * from t_comment;
c.功能2:分页查询一级评论列表
入参
video_id:视频id
page:第几页,从1开始,1表示第1页
page_size:每页大小,默认为10
-----------------------------------------------------------------------------------------------------
查询sql
假如:video_id = 1, page = 1, page_size = 10
-----------------------------------------------------------------------------------------------------
SELECT
*
FROM
t_comment
WHERE
video_id = 1
AND root_comment_id = 0
ORDER BY
create_time DESC
LIMIT 0, 10
-----------------------------------------------------------------------------------------------------
关键点:root_comment_id = 0,表示查询的是一级评论
添加索引优化性能
目前表中没有添加索引,所以上面这个sql查询比较慢,我们可以添加一个组合索引,3个字段:(video_id, root_comment_id, create_time)
这样上面这个查询条件中的2个字段可以用到这个索引,且排序条件也可以用到这个索引进行排序,效率高
-----------------------------------------------------------------------------------------------------
创建索引脚本如下
create index idx_video_id on t_comment (video_id, root_comment_id, create_time);
d.功能3:对一级评论进行回复
用户b需要对用户a下面这条1级评论进行回复,回复内容:剧情很精彩啊
-----------------------------------------------------------------------------------------------------
sql脚本如下
-- 对一级评论进行回复
insert t_comment
(comment_id, video_id, user_id, root_comment_id, reply_to_comment_id, reply_to_user_id, content, create_time, count)
values
(2, 1, '用户b', 1, 1, '用户a', '剧情很精彩啊', NOW(), 0);
-- 更新一级评论中二级评论的数量,count+1
update t_comment set count = count + 1 where comment_id = 1;
-----------------------------------------------------------------------------------------------------
查看下评论表当前数据:`select * from t_comment;`
e.功能4:对二级评论进行回复
用户c,对刚才上面用户b发表的二级评论(comment_id=2)进行回复,回复内容:确实,演员的演技也都在线
-----------------------------------------------------------------------------------------------------
sql脚本如下
-- 对二级评论进行回复
insert t_comment
(comment_id, video_id, user_id, root_comment_id, reply_to_comment_id, reply_to_user_id, content, create_time, count)
values
(3, 1, '用户c', 1, 2, '用户b', '确实,演员的演技也都在线', NOW(), 0);
-- 更新一级评论中二级评论的数量,count+1
update t_comment set count = count + 1 where comment_id = 1;
-----------------------------------------------------------------------------------------------------
查看下评论表当前数据:`select * from t_comment;`
f.功能5:分页查询二级评论列表
查询条件
video_id:视频id
root_comment_id:一级评论id
page:当前页码,从1开始,1表示第1页
page_size:每页大小,默认为10
-----------------------------------------------------------------------------------------------------
假如:video_id = 1, root_comment_id = 1, page = 1, page_size = 10
-----------------------------------------------------------------------------------------------------
查询sql如下
SELECT
*
FROM
t_comment
WHERE
video_id = 1
AND root_comment_id = 1
ORDER BY
create_time DESC
LIMIT 0, 10
-----------------------------------------------------------------------------------------------------
由于,评论表中有个组合索引:(video_id, root_comment_id, create_time),所以这个查询会命中这个索引,会很快
g.功能6:发表评论的接口
不管是发表一级评论,还是对一级评论进行回复,还是对二级评论进行回复,还是对回复进行回复,可以共用一个接口
-----------------------------------------------------------------------------------------------------
下面看下这个接口如何设计,伪代码如下
/**
* 发表评论或对评论进行回复
* @param user_id 评论者id
* @param content 评论内容
* @param video_id 视频id
* @param reply_to_comment_id 被回复的评论id,如果发表一级评论,则此参数为null,如果是二级评论,则此参数为被回复的评论id
*/
@Transactional(rollbackFor = Exception.class)
public void addComment(String user_id, String content,Long video_id, Long reply_to_comment_id){
//1、评论id(可以通过分布式id生成工具生成);
Long comment_id = 评论id;
//2、若 reply_to_comment_id 为空,表示发表的是一级评论
if(reply_to_comment_id==null){
//2.1、插入评论
insert t_comment
(comment_id, video_id, user_id, root_comment_id, reply_to_comment_id, reply_to_user_id, content, create_time, count)
values
(#{comment_id}, #{video_id}, #{user_id}, 0, 0, null, #{content}, NOW(), 0);
}else{
//3、reply_to_comment_id 不为空,表示是对评论进行回复
//3.1、根据 reply_to_comment_id 获取被回复的评论记录
Comment comment = select * from t_comment where comment_id = #{reply_to_comment_id};
//3.2、获取一级评论id
Long root_comment_id = comment.root_comment_id;
// 被回复的用户id
String reply_to_user_id = comment.user_id;
//3.3、插入评论
insert t_comment
(comment_id, video_id, user_id, root_comment_id, reply_to_comment_id, reply_to_user_id, content, create_time, count)
values
(#{comment_id}, #{video_id}, #{user_id}, #{root_comment_id}, #{reply_to_comment_id}, #{reply_to_user_id}, #{content}, NOW(), 0);
//3.4、更新一级评论的count = count + 1
update t_comment set count = count + 1 where comment_id = #{root_comment_id};
}
}
h.功能7:根据评论id,删除评论
delete from t_comment where comment_id = #{评论id}
-----------------------------------------------------------------------------------------------------
这个sql根据主键删除记录,很快
i.功能8:用户查询自己的评论列表
评论者可能需要查看自己的评论列表,可以通过下面这个sql实现
-----------------------------------------------------------------------------------------------------
select * from t_comment where user_id = #{用户id} order by create_time desc
-----------------------------------------------------------------------------------------------------
可以添加一个组合索引:(user_id, create_time),来提升这个sql的查询性能。
-----------------------------------------------------------------------------------------------------
create index idx_user_id on t_comment (user_id, create_time);
05.拓展:数据量大了怎么办?
a.导致查询缓慢
当评论表中的数据量太大,会导致下面2个查询比较慢
1.用户查询某个视频下面的评论列表,主要检索条件:视频id
2.用户查询自己发表的评论列表,主要检索条件:用户id
b.如何解决?分表
具体怎么分表呢?评论数据可以保存2份,2份采用不同的分表键,来解决上面2中查询慢的场景
1.根据视频id进行分表,表名以t_comment_video开头,比如创建128张表,这个可以解决根据视频id查询评论列表缓慢的问题
2.根据用户id进行分表,表名以t_comment_user开头,比如创建128张表,这个可以解决用户查询自己发表的评论列表慢的问题
c.分表后如何写入数据
此时发表评论会向2个表中写入数据:t_comment_video、t_comment_user
有2种方式
1.方式1:同时写入2张表
2.方式2:异步的方式,先写t_comment_video,然后通过mq异步写到t_comment_user表,更新或删除也是一样的,先操作t_comment_video,然后通过mq,同步到t_comment_user表;这种方式性能可能更高一些,复杂性上升了
9.2 SpringBoot下载文件的几种方式,一次性搞懂
01.前言
a.说明
文件下载,常用的一个功能,比较简单
b.但是有可能会遇到一些问题:
1.文件太大,若写法上有问题,可能会导致内存溢出。
2.文件中文名称乱码问题。
c.说明
本文将给大家展示SpringBoot中下载文件常见的几种方式,顺便解决这些问题
02.小文件下载
a.方式1:HttpServletResponse.write
代码如下,直接将文件一次性读取到内存中,然后通过response将文件内容输出到客户端
这种方式适合小文件,若文件比较大的时候,将文件一次性加载到内存中会导致OOM,这点需要注意
-----------------------------------------------------------------------------------------------------
@GetMapping("/download1")
public void download1(HttpServletResponse response) throws IOException {
// 指定要下载的文件
File file = ResourceUtils.getFile("classpath:文件1.txt");
// 文件转成字节数组
byte[] fileBytes = Files.readAllBytes(file.toPath());
//文件名编码,防止中文乱码
String filename = URLEncoder.encode(file.getName(), "UTF-8");
// 设置响应头信息
response.setHeader("Content-Disposition", "attachment; filename=\"" + filename + "\"");
// 内容类型为通用类型,表示二进制数据流
response.setContentType("application/octet-stream");
//输出文件内容
try (OutputStream os = response.getOutputStream()) {
os.write(fileBytes);
}
}
-----------------------------------------------------------------------------------------------------
乱码的解决,主要靠下面这几行代码
-----------------------------------------------------------------------------------------------------
//文件名编码,防止中文乱码
String filename = URLEncoder.encode(file.getName(), "UTF-8");
// 设置响应头信息
response.setHeader("Content-Disposition", "attachment; filename=\"" + filename + "\"");
-----------------------------------------------------------------------------------------------------
启动系统,看下效果,浏览器中访问:http://localhost:8080/download1
b.方式2:ResponseEntity<byte[]>
代码如下,方法需要返回ResponseEntity类型的对象,这个类是SpringBoot中自带的
是对http响应结果的一种封装,可以用来构建http响应结果:包含状态码、头、响应体等信息
-----------------------------------------------------------------------------------------------------
@GetMapping("/download2")
public ResponseEntity<byte[]> download2() throws IOException {
// 指定要下载的文件
File file = ResourceUtils.getFile("classpath:文件1.txt");
// 文件转成字节数组
byte[] fileBytes = Files.readAllBytes(file.toPath());
//文件名编码,防止中文乱码
String filename = URLEncoder.encode(file.getName(), "UTF-8");
//构建响应实体:ResponseEntity,ResponseEntity中包含了http请求的响应信息,比如状态码、头、body
ResponseEntity<byte[]> responseEntity = ResponseEntity.ok()
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + filename + "\"")
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_OCTET_STREAM_VALUE)
.body(fileBytes);
return responseEntity;
}
-----------------------------------------------------------------------------------------------------
看下效果,浏览器中访问:http://localhost:8080/download2
上面的2种方式,都是先将文件读取到字节数组,然后再返回给客户端,如果文件太大,将文件内容读取到内存,可能会导致oom
所以,上面2种方式,大家了解就行了,不建议使用
03.通用方案(适合任何大小文件),建议采用
a.方式1:边读取+边输出
@GetMapping("/download3")
public void download3(HttpServletResponse response) throws IOException {
// 指定要下载的文件
File file = ResourceUtils.getFile("classpath:文件1.txt");
//文件名编码,防止中文乱码
String filename = URLEncoder.encode(file.getName(), "UTF-8");
// 设置响应头信息
response.setHeader("Content-Disposition", "attachment; filename=\"" + filename + "\"");
// 内容类型为通用类型,表示二进制数据流
response.setContentType("application/octet-stream");
// 循环,边读取边输出,可避免大文件时OOM
try (InputStream inputStream = new FileInputStream(file);
OutputStream os = response.getOutputStream()) {
byte[] bytes = new byte[1024];
int readLength;
while ((readLength = inputStream.read(bytes)) != -1) {
os.write(bytes, 0, readLength);
}
}
}
-----------------------------------------------------------------------------------------------------
看下效果,浏览器中访问:http://localhost:8080/download3
b.方式2:返回 ResponseEntity<Resource>
@GetMapping("/download4")
public ResponseEntity<Resource> download4() throws IOException {
/**
* 通过 ResponseEntity 下载文件,body 为 org.springframework.core.io.Resource 类型
* Resource是spring中的一个资源接口,是对资源的一种抽象,常见的几个实现类
* ClassPathResource:classpath下面的文件资源
* FileSystemResource:文件系统资源
* InputStreamResource:流资源
* ByteArrayResource:字节数组资源
*/
Resource resource = new ClassPathResource("文件1.txt");
//文件名编码,防止中文乱码
String filename = URLEncoder.encode("文件1.txt", "UTF-8");
//构建响应实体:ResponseEntity,ResponseEntity中包含了http请求的响应信息,比如状态码、头、body
ResponseEntity<Resource> responseEntity = ResponseEntity.ok()
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + filename + "\"")
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_OCTET_STREAM_VALUE)
.body(resource);
return responseEntity;
}
-----------------------------------------------------------------------------------------------------
图片说明:ResponseEntity<Resource>示意图
看下效果,浏览器中访问:http://localhost:8080/download4
04.中文乱码
a.问题描述
有些朋友可能遇到过,文件名中如果有中文,下载下来后文件名称是乱码。
解决代码如下,需要对文件名称进行编码,具体大家可以看看上面的案例代码。
-----------------------------------------------------------------------------------------------------
//文件名编码,防止中文乱码
String filename = URLEncoder.encode(file.getName(), "UTF-8");
05.案例完整代码
a.源码
源码在 lesson082 这个模块中,上面接口代码都在下面这个controller中
com.itsoku.lesson082.FileController
9.3 订单超时自动取消,最常见的方案
01.前言
订单下单后,15分钟未支付,自动取消,如何解决?
本文给大家介绍 2种 最常见的方案
02.方案1:定时器轮询数据库
a.实现方式
while(true){
//查询出超时未支付的订单,可以一次性查出100条,然后对其进行取消
List<Order> orderList = select * from t_order where create_time<当前时间 - 15分钟 and status = 待支付 limit 100;
if(orderList为空){
//退出循环
break;
}
for(Order order : orderList){
//将订单取消
orderCancel(order);
}
}
b.优点
实现简单,容易理解和维护
c.缺点
对数据库压力大,尤其是在订单量大的情况下,比如有分库分表的时候,需要轮询所有的表,效率比较低
存在延迟,定时任务的执行间隔决定了超时检测的最小延迟
比如下单后15分钟未支付,则取消订单,定时器每1分钟跑一次
而刚好订单在下单后14:50秒的时候,job执行了,这次此订单就处理不到
要等到job下次执行的时候才会被扫到,相当于在15:50秒的时候才被处理,延迟了50秒
若要解决此问题,job的执行频率要设置的比较高
03.方案2:MQ延迟消息
a.实现方式
使用RocketMQ、RabbitMQ等消息队列的延时消息功能
订单创建时,发送延时消息到MQ,15分钟后,消费者才会收到此消息,然后取消订单;延迟时间未到之前,消息待在MQ中
b.优点
高效、好扩展,支持大批量订单
c.缺点
引入了新的技术组件,增加了系统复杂度
9.4 责任链模式优化代码,太好用了
01.需求
后端需要提供一个文章发布的接口,接口中需要先对文章内容进行如下校验,校验通过后才能发布
1.文章长度不能超过1万个字符
2.不能有敏感词
3.文章中图片需要合规
02.先来看第一个版
a.代码入口
com.itsoku.lesson084.controller.ArticleController#publish
b.分析
这种算是最常见的写法,写法简单,但是不够优雅,不方便扩展
可以用责任链模式对其进行优化
03.什么是责任链模式
a.概述
一种设计模式
b.说明
责任链相当于一个链条一样,链条上有很多节点,节点与节点之间形成了一个单向的链表
每个节点相当于一个处理步骤,一个任务过来后,会交给链条上第一个节点进行处理
第一个节点处理后再传递给下一个节点,下一个节点处理完成后,继续向后传递
04.使用责任链对代码进行优化
a.概述
目前文章发布中的校验有下面3个步骤,每个步骤相当于责任链上一个节点,每个步骤对应一个类
如果要进行扩展,只需要添加一个类,然后调整下链表的顺序便可
图片说明:使用责任链模式优化文章发布校验的示意图
b.责任链版代码入口
com.itsoku.lesson084.controller.ArticleController#publishNew
c.测试效果
测试看下效果
再给大家演示,增加一个新的验证步骤:比如每天只允许发布5篇文章;只需要添加一个新的实现类,调整下责任链组装代码便可
责任链有很多版本的实现,本文只是其中一种,还有很多其他的版本,大家可以去了解
9.5 CompletableFuture 实现异步任务编排,太好用了
01.实现一个需求
a.后端需要给前端提供一个接口:根据商品id查询商品详情的接口,里面需要包含
step1:商品基本信息
step2:商品折扣信息
step3:商品描述信息
b.这3个信息都需要调用不同的接口获取
step2需要依赖step1
step3和step1、step2之间没有依赖关系
c.关系图如下,我们可以使用线程池来并行执行,提升这个接口的性能
step1和step3可以并行执行
step2需要等待step1执行后才能执行
等到3个步骤都完成后,将结果返回
02.版本1:使用线程池+Future实现需求
a.代码
@Test
public void test1() throws ExecutionException, InterruptedException {
long startTime = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(10);
//使用线程池异步执行step1
Future<String> step1 = executorService.submit(() -> {
sleep(500);
return "获取商品基本信息";
});
//使用线程池异步执行step2
Future<String> step2 = executorService.submit(() -> {
//这里需要等到step1执行完毕
step1.get();
sleep(500);
return "获取商品折扣信息";
});
//使用线程池异步执行step3
Future<String> step3 = executorService.submit(() -> {
sleep(500);
return "获取商品描述信息";
});
//这里需要等到3个步骤都执行完成,这里可以不用写step1.get(),因为step2依赖于step1
step2.get();
step3.get();
System.out.println("耗时(ms):" + (System.currentTimeMillis() - startTime));
}
private static void sleep(long timeout) {
try {
TimeUnit.MILLISECONDS.sleep(timeout);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
b.说明
上面这种写法不是太优雅,step2对step1有依赖,需要在step2中调用step1.get()等到step1执行结束
如果任务之间的依赖关系非常复杂的时候,写法上就比较复杂了
比如下面这个图,有6个任务,任务之间有并行关系,有依赖关系,使用线程池+Future实现,写法上就比较复杂了
更好的办法,使用CompletableFuture ;CompletableFuture 可以解决异步任务任意编排的问题
03.版本2:线程池+CompletableFuture 实现需求
a.异步任务编排
异步任务编排就是让多个可以并行的任务按照预定的逻辑和顺序高效执行的过程
说的更简单点:就是任务之间可以随意组合,按照任意的逻辑进行组合,重点在于逻辑二字,任务之间可以是:并行关系、依赖关系、AND关系、OR关系
CompletableFuture 就是异步任务编排的一种实现,非常好用,它实现了Future接口,所以Future可以干的事情,CompletableFuture 都可以干,且功能更强大
b.代码
@Test
public void test2() throws ExecutionException, InterruptedException {
long startTime = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(10);
//使用线程池异步执行step1
CompletableFuture<String> step1 = CompletableFuture.supplyAsync(() -> {
sleep(500);
return "获取商品基本信息";
}, executorService);
//使用线程池异步执行step2
CompletableFuture<String> step2 = step1.thenApplyAsync((goodsInfo) -> {
sleep(500);
return "获取商品折扣信息";
}, executorService);
//使用线程池异步执行step3
CompletableFuture<String> step3 = CompletableFuture.supplyAsync(() -> {
sleep(500);
return "获取商品描述信息";
}, executorService);
//这里需要等到3个步骤都执行完成,这里可以不用写step1,因为step2依赖于step1
CompletableFuture.allOf(step2, step3).get();
System.out.println("耗时(ms):" + (System.currentTimeMillis() - startTime));
}
private static void sleep(long timeout) {
try {
TimeUnit.MILLISECONDS.sleep(timeout);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
9.6 idea中的必备debug技巧,高手必备
01.背景
开发过程中,难免会遇到一些问题,通常我们会使用debug来帮我们排查问题,所以,如果debug玩的好,排查问题的效率将大幅提升
本文将给大家分享几个特别实用的debug技巧,掌握后,排查问题效率大幅提升
02.技巧
1.条件断点
2.单次断点
3.异常断点
4.强制返回
5.抛出异常
6.ResetFrame
9.7 Java动态生成word,太强大了
01.poi-tl
官网:https://deepoove.com/poi-tl
poi-tl(poi template language)是Word模板引擎,使用模板和数据创建很棒的Word文档
可以生成任何动态的word,官网上有详细的使用教程,我们一起来看下
9.8 海量据量统计,如何提升性能?
02.方案1:实时统计
a.实现方式
当用户访问页面的时候,实时去计算
比如播放量,可以在db中创建一个播放记录表,用户每次播放视频,会插入一条播放记录
那么这个播放量就可以通过这个表count得到
b.问题
有些up,一个视频上百万播放,count一下,可能需要几十秒,用户肯定是受不了的,还有数据库也是扛不住的,多个up同时访问,系统直接崩溃了
所以这种方案自己玩玩可以,对于数据量稍微大一点的,不能这么玩
03.方案2:提前将数据聚合好
a.实现方式
可以创建一张表,专门用来记录这个页面需要用到的数据,如下表
此表会将这个页面的数据提前计算好,用户访问页面的时候,直接从此表拿数据,而不需要再次进行计算
-----------------------------------------------------------------------------------------------------
| 日期 | up主 | 播放量 | 空间访客 | 净增粉丝 | 点赞量 | 收藏量 | 评论数量 | 分享量 | 投币数量 | 充电量
| 20240907 | 程序员路人 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100
| 20240908 | 程序员路人 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100
b.优势
当用户访问某个视频的时候,在此表,找到对应的记录,然后将播放量+1,就可以了。
对于b站这种,可以将这些数据丢到redis中,访问会更快,也能抗住高并发。
9.9 MyBatis模糊查询,千万不要再用${}了,容易搞出大事故
00.汇总
MyBatis中使用模糊查询的时候,千万不要使用`${}`这种写法了,请使用`#{}`这种写法
01.来看个需求
a.我们这边有个博客表,如下,3个字段,目前有5条数据,用户1的数据有2条
id:主键
user_id:作者id
title:博客标题
b.图片说明:博客表示例数据
假如,我们要给前端提供一个接口,根据title模糊检索当前用户博客列表,这个需求怎么实现?
算是一个非常简单的需求吧
02.版本1:MyBatis+${}实现
a.代码实现
<select id="findMyArticles1" resultType="com.itsoku.lesson089.po.ArticlePO">
SELECT
id,
user_id AS userId,
title
FROM
t_article_lesson089
WHERE
user_id = #{userId}
AND title LIKE '%${keywords}%'
</select>
b.测试效果
测试下效果,启动应用`com.itsoku.lesson089.Lesson089Application`
浏览器中访问:http://localhost:8080/findMyArticles1?myUserId=1&keywords=java
-----------------------------------------------------------------------------------------------------
查询用户1,标题中带有java的,文章列表,查询结果如下,结果符合预期
[
{
"id": 1,
"userId": 1,
"title": "Java 高并发"
},
{
"id": 2,
"userId": 1,
"title": "Java 微服务"
}
]
-----------------------------------------------------------------------------------------------------
控制台sql输出如下
原本sql中的<font color='red' style='font-weight:bold'>title LIKE '%${keywords}%'</font>
被替换成了 <font color='red' style='font-weight:bold'>title LIKE '%java%'</font>
MyBatis中的`${}`在SQL 解析阶段会替换成变量原本的值
-----------------------------------------------------------------------------------------------------
10:08:56 - ==> Preparing: SELECT id, user_id AS userId, title FROM t_article_lesson089 WHERE user_id = ? AND title LIKE '%java%'
10:08:56 - ==> Parameters: 1(Long)
10:08:56 - <== Total: 2
03.版本1:${}问题演示
a.问题演示
在浏览器中访问下面地址,重点看下keywords参数的值
http://localhost:8080/findMyArticles1?myUserId=1&keywords=' or 1=1 or '
-----------------------------------------------------------------------------------------------------
浏览器输出如下,将表中所有数据都撸出来了,不符合预期
[
{
"id": 1,
"userId": 1,
"title": "Java 高并发"
},
{
"id": 2,
"userId": 1,
"title": "Java 微服务"
},
{
"id": 3,
"userId": 2,
"title": "Java 性能调优"
},
{
"id": 4,
"userId": 2,
"title": "Java 从入门到精通"
},
{
"id": 5,
"userId": 3,
"title": "Java Web开发"
}
]
-----------------------------------------------------------------------------------------------------
再看下控制台的sql,如下:
10:14:30 - ==> Preparing: SELECT id, user_id AS userId, title FROM t_article_lesson089 WHERE user_id = ? AND title LIKE '%' or 1=1 or '%'
10:14:30 - ==> Parameters: 1(Long)
10:14:30 - <== Total: 5
-----------------------------------------------------------------------------------------------------
整个表的数据都被撸出来了,产生了严重的事故
用户1查看到了不属于自己的数据,若这些是敏感数据,直接导致数据泄露
若表数据库非常大,直接导致数据库或业务系统崩溃
-----------------------------------------------------------------------------------------------------
这也是常说的sql注入,mybatis中${}这种写法存在sql注入的风险
如何解决呢?请看方案2
04.方案2:使用#{}替换${}
a.新的写法
新的写法如下,使用#{}替换${}, \#{ } 被解析为一个参数占位符 ,不存在sql注入
-----------------------------------------------------------------------------------------------------
<select id="findMyArticles2" resultType="com.itsoku.lesson089.po.ArticlePO">
SELECT
id,
user_id AS userId,
title
FROM
t_article_lesson089
WHERE
user_id = #{userId}
AND title LIKE #{keywords}
</select>
b.测试效果
来看下效果,浏览器中访问
http://localhost:8080/findMyArticles2?myUserId=1&keywords=java
-----------------------------------------------------------------------------------------------------
浏览器输出如下,结果符合预期
[
{
"id": 1,
"userId": 1,
"title": "Java 高并发"
},
{
"id": 2,
"userId": 1,
"title": "Java 微服务"
}
]
-----------------------------------------------------------------------------------------------------
控制台sql如下,也没问题
10:22:41 - ==> Preparing: SELECT id, user_id AS userId, title FROM t_article_lesson089 WHERE user_id = ? AND title LIKE ?
10:22:41 - ==> Parameters: 1(Long), %java%(String)
10:22:41 - <== Total: 2
-----------------------------------------------------------------------------------------------------
浏览器中再访问下下面这个地址,看看会不会出问题
http://localhost:8080/findMyArticles2?myUserId=1&keywords=' or 1=1 or '
-----------------------------------------------------------------------------------------------------
浏览器中输出如下,没有查询到任何数据,符合预期
[]
-----------------------------------------------------------------------------------------------------
再来看下控制台sql如下,也没问题
10:24:00 - ==> Preparing: SELECT id, user_id AS userId, title FROM t_article_lesson089 WHERE user_id = ? AND title LIKE ?
10:24:00 - ==> Parameters: 1(Long), %' or 1=1 or '%(String)
10:24:00 - <== Total: 0
-----------------------------------------------------------------------------------------------------
问题已解决
9.10 Spring事务失效,常见的几种场景,带你精通Spring事务
01.本文主要3块内容
1.Spring事务失效常见的4种场景
2.事务失效问题如何排查?
3.如何精通Spring事务?
02.事务失效场景1:通过this调用自身@Transactional方法
a.案例代码
如下代码,外部调用m1方法,m1方法中调用m2方法,虽然m2方法上加了事务@Transactional注解,但是事务不会生效
-----------------------------------------------------------------------------------------------------
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void m1() {
this.m2("1", "m1");
}
@Transactional
public void m2(String id, String name) {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId(id);
userPO.setName(name);
this.userMapper.insert(userPO);
//抛出异常,看看事务是否会回滚
throw new RuntimeException("故意失败,看下事务是否会回滚");
}
}
-----------------------------------------------------------------------------------------------------
运行看下效果,虽然报异常了,但是数据插入成功了。
b.原因
Spring中的@Transactional事务,是通过aop生成代理对象实现的,所以通过代理对象访问目标方法的时候,事务才会起效
而上面的m1方法中通过this调用的m2方法,而this并不是代理对象,所以事务是无效的
解决方案,这里给大家介绍3种
c.解决方案1:注入了自己
@Service
public class UserService {
//注入自己,articleService就是被AOP包装后的代理对象
@Autowired
private UserService userService;
public void m3() {
//通过userService访问m2,事务会生效
this.userService.m2("3", "m3");
}
@Transactional
public void m2(String id, String name) {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId(id);
userPO.setName(name);
this.userMapper.insert(userPO);
//抛出异常,看看事务是否会回滚
throw new RuntimeException("故意失败,看下事务是否会回滚");
}
}
d.解决方案2:编程式事务
@Service
public class UserService {
@Autowired
private TransactionTemplate transactionTemplate;
public void m4() {
this.transactionTemplate.executeWithoutResult(action -> {
this.m2("4", "m4");
});
}
@Transactional
public void m2(String id, String name) {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId(id);
userPO.setName(name);
this.userMapper.insert(userPO);
//抛出异常,看看事务是否会回滚
throw new RuntimeException("故意失败,看下事务是否会回滚");
}
}
f.解决方案3:AopContext.currentProxy()
@Service
public class UserService {
public void m5() {
//通过Spring提供的工具类AopContext.currentProxy(),可以获取当前代理对象,将类型强制转换为UserService,然后调用m2方法,事务也会生效
UserService as = (UserService) AopContext.currentProxy();
as.m2("5", "m5");
}
@Transactional
public void m2(String id, String name) {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId(id);
userPO.setName(name);
this.userMapper.insert(userPO);
//抛出异常,看看事务是否会回滚
throw new RuntimeException("故意失败,看下事务是否会回滚");
}
}
03.事务失效场景2:异常类型不匹配
a.说明
Spring事务回滚的机制:会拦截@Transactional标注的方法,当方法抛出指定的异常时,被Spring捕获到了,事务才会进行回滚
那么问题来了,哪些异常spring会回滚事务呢?
并不是任何异常Spring都会回滚事务,默认情况下,RuntimeException和Error的情况下,spring事务才会回滚
也可以通过@Transactional中的rollbackFor属性指定要回滚的异常类型:
@Transactional(rollbackFor = {异常类型列表})
b.说明
当方法抛出的异常是这些异常、或者是这些异常的子类的时候,事务才会回滚
比如下面这个案例代码,rollbackFor指定的是 RuntimeException异常,而方法内部抛出的是 Exception异常,不符合上面的条件,所以事务不会回滚
c.代码
@Transactional(rollbackFor = RuntimeException.class)
public void m6() throws Exception {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId("6");
userPO.setName("m6");
this.userMapper.insert(userPO);
//抛出一个Exception异常,看看事务是否会回滚
throw new Exception("抛出Exception异常");
}
d.说明
运行看下效果,确实没有回滚
04.事务失效场景3:异常被吞了
a.说明
当业务方法抛出异常,spring感知到异常的时候,才会做事务回滚的操作,若方法内部将异常给吞了,那么spring事务无法感知到异常了,事务就不会回滚了
如下代码,发生了异常,但是被捕获了,spring无法感知到异常,此时事务并不会被回滚
b.代码
@Transactional(rollbackFor = Exception.class)
public void m7() throws Exception {
try {
//向用户表插入一条记录
UserPO userPO = new UserPO();
userPO.setId("7");
userPO.setName("m7");
this.userMapper.insert(userPO);
//抛出一个Exception异常,
throw new RuntimeException("抛出Exception异常");
} catch (Exception e) {
e.printStackTrace();
}
}
05.事务失效场景4:不同的线程事务无法共享
a.代码
@Transactional
public void m1() {
// 事务操作1....
new Thread() {
//事务操作2....
}.start();
}
b.说明
原因:@Transactional标注的方法,在进入到这个方法前,spring会获取一个数据库的连接
通过这个连接开启事务,这个连接会放在ThreadLocal中,然后才会被dao层的mybatis、jdbctemplate共享
但是如果是不同的线程,他们用的不是同一个数据连接,无法共享事务
06.事务失效问题如何排查?
@Transaction标注的方法,调用时,会被下面这个拦截器处理,咱们可以在此方法中设置一个断点,通过debug,可以排查问题
org.springframework.transaction.interceptor.TransactionInterceptor#invoke
10 part09
10.1 idea多线程调试,非常实用的一个技巧,太好用了
00.汇总
自己查阅解决
10.2 MySQL排序分页,可能有坑,需要注意
01.问题演示
a.创建一个表test1
drop table if exists test1;
CREATE TABLE test1 (
a INT auto_increment PRIMARY KEY,
b INT
);
b.插入 8 条数据
insert into test1 (b) values (1),(2),(3),(4),(2),(2),(2),(2);
c.根据字段b排序,查询表中数据
select * from test1 order by b asc;
-----------------------------------------------------------------------------------------------------
结果如下
大家先看下上面这个结果,然后思考下:假如我们按照b排序,每页5条,第1页应该是什么数据?
是不是应该是下面这样?
-----------------------------------------------------------------------------------------------------
我们来实际测试下,看看是不是这样,执行下面sql
select * from test1 order by b asc limit 0,5;
-----------------------------------------------------------------------------------------------------
和上面我们期望的结果不一样啊,期望的是 a = 1、2、5、6、7 这5条记录,实际查出来的是 a = 1、2、8、7、5;说明顺序乱掉了
图片说明:实际结果示意图
-----------------------------------------------------------------------------------------------------
我们再来测试下,按照b排序,每页5条,第2页是什么数据,sql如下
select * from test1 order by b asc limit 5,5;
-----------------------------------------------------------------------------------------------------
执行后,结果如下
图片说明:第二页结果示意图
将第1页和第2页的结果对比下,发现出现了重复的数据,如下,a = 8 这条记录,在第一页和第二页中都出现了,说明目前的排序分页有问题
图片说明:重复数据示意图
02.原因
由于b字段存在相同的值,当排序过程中存在相同的值时,没有其他排序规则时,MySQL 懵了,不知道怎么排序了
所以,排序字段存在相同值的时候顺序可能会乱
03.如何解决这个问题?
a.说明
当排序字段存在相同的值时,需要再增加一些其他的排序规则,通过多个排序规则的组合,使排序结果不存在二义性
比如上面这个问题,可以再加上a字段作为排序规则,由于a是主键,具有唯一性,可以解决这个问题
b.sql如下,可以验证下
select * from test1 order by b asc, a asc;
select * from test1 order by b asc, a asc limit 0,5;
select * from test1 order by b asc, a asc limit 5,5;
10.3 涉及到钱的,千万不要用double,请用BigDecimal
01.金融系统不要用double,会有精度问题
a.问题示例
@Test
public void m1() {
double a = 4.015, b = 100.00;
System.out.println(a * b); // 期望结果:401.5
double c = 123.30, d = 100.00;
System.out.println(c / d); //期望结果:1.233
}
b.运行输出如下
401.49999999999994
1.2329999999999999
-----------------------------------------------------------------------------------------------------
和期望的结果不太一致
02.原因
是由于计算机存储double类型数据的时候,会产生精度问题;float类型同样也有精度问题
具体底层原理,大家可以查阅相关资料了解
如何解决这个问题呢?
03.使用BigDecimal,可解决问题
a.java为我们提供了一个类:BigDecimal,可以用来解决double、float这种浮点数的精度问题
@Test
public void m2() {
BigDecimal a = new BigDecimal("4.015");
BigDecimal b = new BigDecimal("100.00");
System.out.println(a.multiply(b));
BigDecimal c = new BigDecimal("123.30");
BigDecimal d = new BigDecimal("100.00");
System.out.println(c.divide(d));
}
b.运行输出
401.50000
1.233
04.如何构造BigDecimal对象?
a.正确做法
请使用字符串来构造BigDecimal对象,如下
BigDecimal bd = new BigDecimal("0.1");
b.错误做法
下面这种,使用double类型的参数构造BigDecimal,会有精度问题,不要使用
BigDecimal bd = new BigDecimal(0.1);
05.BigDecimal对象如何比较大小?
a.说明
需要用使用BigDecimal中的compareTo方法,如下,需传入另外一个BigDecimal对象,和当前对象比较大小
public int compareTo(BigDecimal val);
b.返回值有3种情况
-1:小于
0:相等
1:大于
c.案例
@Test
public void m3() {
System.out.println(new BigDecimal("0.1").compareTo(new BigDecimal("0.2")));
System.out.println(new BigDecimal("0.2").compareTo(new BigDecimal("0.1")));
System.out.println(new BigDecimal("0.123").compareTo(new BigDecimal("0.123000000")));
}
d.输出
-1
1
0
06.BigDecimal保留到分,如何处理?
a.说明
BigDecimal计算出的结果,小数位可能很长,此时就需要考虑保留几位小数,如何舍掉后面的位数。
金融系统中通常会将计算的结果采用四舍五入,保留到分,即2位小数,处理如下
b.代码
@Test
public void m4() {
System.out.println(new BigDecimal("0.12345678").setScale(2, BigDecimal.ROUND_HALF_UP));
System.out.println(new BigDecimal("0.45678910").setScale(2, BigDecimal.ROUND_HALF_UP));
}
c.输出
0.12
0.46
07.数据库中对应的类型:decimal
a.说明
BigDecimal中在db中也有对应的类型,MySQL中对应decimal类型,如下,保留2位小数,具体保留几位小数,大家可以根据业务来决定
b.代码
decimal(18,2)
08.给大家提供一个BigDecimal工具类
a.工具类
package com.itsoku.lesson093;
import java.math.BigDecimal;
import java.text.DecimalFormat;
/**
* <b>description</b>: Java高并发、微服务、性能优化实战案例100讲,视频号:程序员路人,源码 & 文档 & 技术支持,请加个人微信号:itsoku <br>
* <b>time</b>:2024/9/10 23:21 <br>
* <b>author</b>:ready [email protected]
*/
public class BigDecimalUtils {
/**
* 除法默认保留精度
*/
private static final int DEF_DIV_SCALE = 10;
/**
* 默认舍入模式(ROUND_HALF_UP:四舍五入)
*/
private static final int DEF_ROUNDING_MODE = BigDecimal.ROUND_HALF_UP;
private static final String FORMAT_1 = "#.##";
/**
* 将字符串转换为 BigDecimal
*
* @param value
* @return
*/
public static BigDecimal of(String value) {
return value == null ? null : new BigDecimal(value);
}
/**
* v1 + v2
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static BigDecimal add(BigDecimal v1, BigDecimal v2) {
return v1.add(v2);
}
/**
* args[0] + args[1] + ... + args[n]
*
* @param args
* @return
*/
public static BigDecimal add(BigDecimal... args) {
if (args == null || args.length <= 1) {
throw new IllegalArgumentException("args Contains at least two parameters");
}
BigDecimal result = args[0];
for (int i = 1; i < args.length; i++) {
result = add(result, args[i]);
}
return result;
}
/**
* v1 - v2
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static BigDecimal subtract(BigDecimal v1, BigDecimal v2) {
return v1.subtract(v2);
}
/**
* args[0] - args[1] - ... - args[n]
*
* @param args
* @return
*/
public static BigDecimal subtract(BigDecimal... args) {
if (args == null || args.length <= 1) {
throw new IllegalArgumentException("args Contains at least two parameters");
}
BigDecimal result = args[0];
for (int i = 1; i < args.length; i++) {
result = subtract(result, args[i]);
}
return result;
}
/**
* v1 * v2
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static BigDecimal multiply(BigDecimal v1, BigDecimal v2) {
return v1.multiply(v2);
}
/**
* args[0] * args[1] * ... * args[n]
*
* @return 两个参数的积
*/
public static BigDecimal multiply(BigDecimal... args) {
if (args == null || args.length <= 1) {
throw new IllegalArgumentException("args Contains at least two parameters");
}
BigDecimal result = args[0];
for (int i = 1; i < args.length; i++) {
result = multiply(result, args[i]);
}
return result;
}
/**
* v1 / v2
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static BigDecimal divide(BigDecimal v1, BigDecimal v2) {
return v1.divide(v2, DEF_DIV_SCALE, DEF_ROUNDING_MODE);
}
/**
* args[0] / args[1] / ... / args[n]
*
* @return 两个参数的积
*/
public static BigDecimal divide(BigDecimal... args) {
if (args == null || args.length <= 1) {
throw new IllegalArgumentException("args Contains at least two parameters");
}
BigDecimal result = args[0];
for (int i = 1; i < args.length; i++) {
result = divide(result, args[i]);
}
return result;
}
/**
* 四舍五入,保留两位小数
*
* @param d
* @return
*/
public static BigDecimal round(BigDecimal d) {
if (d == null) {
return null;
}
return d.setScale(2, BigDecimal.ROUND_HALF_UP);
}
/**
* v1>v2?
*
* @param v1
* @param v2
* @return
*/
public static boolean gt(BigDecimal v1, BigDecimal v2) {
return v1.compareTo(v2) > 0;
}
/**
* v1 == v2
*
* @param v1
* @param v2
* @return
*/
public static boolean eq(BigDecimal v1, BigDecimal v2) {
return v1.compareTo(v2) == 0;
}
/**
* 判断 values 是否等于 0?
*
* @param value
* @return
*/
public static boolean eq0(BigDecimal value) {
return BigDecimal.ZERO.compareTo(value) == 0;
}
/**
* v1>=v2?
*
* @param v1
* @param v2
* @return
*/
public static boolean ge(BigDecimal v1, BigDecimal v2) {
return v1.compareTo(v2) >= 0;
}
/**
* v1<v2?
*
* @param v1
* @param v2
* @return
*/
public static boolean lt(BigDecimal v1, BigDecimal v2) {
return v1.compareTo(v2) < 0;
}
/**
* 格式化,保留2为小数
*
* @param value
* @return
*/
public static String format(BigDecimal value) {
if (value == null) {
return null;
}
DecimalFormat df = new DecimalFormat(FORMAT_1);
return df.format(value);
}
/**
* 格式化
*
* @param value
* @param pattern 模式字符串,如:#.##
* @return
*/
public static String format(BigDecimal value, String pattern) {
if (value == null) {
return null;
}
DecimalFormat df = new DecimalFormat(pattern);
return df.format(value);
}
}
b.案例代码
@Test
public void m5() {
//1、通过字符串构造 BigDecimal
System.out.println(BigDecimalUtils.of("0.123"));
//2、加法
System.out.println(BigDecimalUtils.add(new BigDecimal("0.111"), new BigDecimal("0.123")));
//3、减法
System.out.println(BigDecimalUtils.subtract(new BigDecimal("0.111"), new BigDecimal("0.123")));
//4、乘法
System.out.println(BigDecimalUtils.multiply(new BigDecimal("0.111"), new BigDecimal("0.123")));
//5、除法
System.out.println(BigDecimalUtils.divide(new BigDecimal("0.111"), new BigDecimal("0.123")));
//6、四舍五入,结果保留2位小数,金融系统中通常会将计算的结果保留到分,此时就可以用这个方法
System.out.println(BigDecimalUtils.round(BigDecimalUtils.divide(new BigDecimal("0.111"), new BigDecimal("0.123"))));
//7、判断 v1<v2?
BigDecimal v1 = new BigDecimal("0.111");
BigDecimal v2 = new BigDecimal("0.123");
System.out.println(BigDecimalUtils.lt(v1, v2));
//8、判断2个数是否相等 0.111 == 0.11100000000,相等
System.out.println(BigDecimalUtils.eq(v1, new BigDecimal("0.11100000000"))); // true
//9、判断是否等于0
System.out.println(BigDecimalUtils.eq0(new BigDecimal("0"))); // true
System.out.println(BigDecimalUtils.eq0(new BigDecimal("0.000"))); // ture
System.out.println(BigDecimalUtils.eq0(new BigDecimal("0.001"))); // false
//10、格式化
System.out.println(BigDecimalUtils.format(BigDecimalUtils.of("123.45678"))); // 123.46
}
c.运行输出
0.123
0.234
-0.012
0.013653
0.9024390244
0.90
true
true
true
true
false
123.46
09.其他知识点
a.接口中,资金直接使用BigDecimal类型
@RequestMapping("/transfer")
public ResultDto<Boolean> transfer(@RequestBody TransferRequest request){
}
@Data
public class TransferRequest {
//付款人账户id
private String fromAccountId;
//收款人账号id
private String toAccountId;
//转账金额
private BigDecimal transferPrice;
}
b.PO中也使用BigDecimal类型
create table if not exists t_account
(
id varchar(32) not null primary key comment '用户id',
balance decimal(12, 2) not null comment '账户余额',
) comment '账户表';
-----------------------------------------------------------------------------------------------------
对应的po如下,balance用的是BigDecimal类型
@Data
public class AccountPO {
//用户id
private String id;
//账户余额
private BigDecimal balance;
}
10.4 MyBatis动态SQL不要乱用,容易搞出大事故
00.汇总
1.MyBatis中更新和删除操作,不要在条件中使用动态SQL,一不小心全表数据都被操作了
2.对于查询功能,条件部分是可以用动态SQL
3.尽量不要设计大而全的接口,想用一个接口满足所有功能,这种设计存在很大风险,且难以理解和维护,尽量杜绝
01.来看一个案例
a.说明
MyBatis写的一个更新用户信息的接口,字段可以动态更新:即用户传入的字段不为空的时候,才会被更新
b.代码
<!-- 更新用户信息 -->
<update id="update" parameterType="com.xxx.model.UserModel">
<![CDATA[ UPDATE `t_user` ]]>
<set>
<if test="username != null and username.toString() != ''">
<![CDATA[ `username` = #{username}, ]]>
</if>
<if test="email != null and email.toString() != ''">
<![CDATA[ `email` = #{email}, ]]>
</if>
</set>
<where>
<if test="user_id != null">
<![CDATA[ AND `user_id` = #{user_id} ]]>
</if>
</where>
</update>
c.对这段代码解释下
传入的参数是用户对象UserModel
set部分采用的是动态sql,字段不为空的时候,才会去更新,这块没问题,设计的很好
条件部分,用的是动态sql,这部分大家好好看看,存在很大的风险,当user_id不传入的时候,会导致全表数据被更新,产生大事故
d.如何解决这个问题?
更新的功能,条件部分不要用动态sql,调整后代码如下,更新的时候必须传入用户id,否则报错就可以了
<!-- 更新用户信息 -->
<update id="update" parameterType="com.itsoku.model.UserModel">
<![CDATA[ UPDATE `t_user` ]]>
<set>
<if test="username != null and username.toString() != ''">
<![CDATA[ `username` = #{username}, ]]>
</if>
<if test="email != null and email.toString() != ''">
<![CDATA[ `email` = #{email}, ]]>
</if>
</set>
where user_id = #{user_id}
</update>
02.再来看另外一个案例
a.说明
代码如下,用于删除用户记录,入参是Map对象,条件部分是动态sql
这么设计的初衷是:这种设计可以满足各种删除操作,比如需要根据其他条件删除,只需要在where部分添加一些动态条件就可以了
b.代码
<!-- 删除数据 -->
<delete id="delete" parameterType="map">
<![CDATA[
DELETE FROM `t_user`
]]>
<where>
<if test="user_id!=null">
<![CDATA[ AND `user_id` = #{user_id} ]]>
</if>
</where>
</delete>
c.说明
这段代码存在极大的风险:如果传入的map是空,把整个表的数据都给清空了,可能就要拎包走人了
这就是大而全接口的危害,希望一个接口能够满足所有操作
d.如何解决这个问题呢?
不要提供这种大而全的接口,可以将其调整成一个个小而明确的接口,比如需要根据用户id删除用户,可以写成下面这样,条件部分不要用动态sql
<!-- 根据用户id删除用户 -->
<delete id="deleteByUserId">
<![CDATA[
DELETE FROM `t_user` where `user_id` = #{user_id}
]]>
</delete>
10.5 MySQL数据如何同步到ES?靠谱方案
01.背景
本文以博客系统为例,来介绍下,如何将mysql中的博客数据同步到ElasticSearch
02.使用MQ实现
a.step1:投递mq消息
博客发生增删改(insert、update、delete)操作的时候,投递一条MQ消息,消息体如下
只需要带上博客id就行了,这里不需要知道具体是什么类型的操作,具体原因,大家看了后面的消费逻辑就清楚了
-----------------------------------------------------------------------------------------------------
{
"articleId": "博客id"
}
-----------------------------------------------------------------------------------------------------
最好采用事务消息,可以确保业务执行成功,消息一定投递成功,怎么投递事务消息?
可参考:30.MQ专题:SpringBoot中,手把手教你实现事务消息
b.step2:消费消息,将博客数据写入ES
String articleId = 消息中获取博客id;
//为了避免并发问题,这里对同一条博客记录加分布式锁,确保同一个articleId,并发收到多个消息时,排队执行,这样可以确保同步到es的数据最终和mysql是一致的
distributeLock.lock("es:article:" + articleId);
try{
// 从db中查询博客
ArticlePO articlePo = select * from t_article where id = #{articleId};
//从es中删除博客
es.delete(articleId);
//将博客写入es
if(articlePo != null){
es.insert(articlePo);
}
}finally{
//释放分布式锁
distributeLock.unlock();
}
-----------------------------------------------------------------------------------------------------
这里再给大家解释下,为什么要加分布式锁?
如果不加锁,用户短时间内,对同一个博客进行了2次修改
第1次将博客标题改成了:java
第2次将博客标题改成:java高并发
-----------------------------------------------------------------------------------------------------
这2次修改会产生2条消息,2条消息按照下面逻辑消费,最终es的数据和db中数据不一致,db中是博客的标题是:java高并发,而es中是:java
时间点 | 消费者1 | 消费者2
T1 | {"articleId":"1"} | {"articleId":"1"}
T2 | 从数据库读取博客内容,标题是:java | 从db中读取博客内容,标题是:java高并发
T3 | | 写入ES,此时es中博客的标题是:java高并发
T4 | 写入ES,此时es中博客的标题是:java |
-----------------------------------------------------------------------------------------------------
还有一点需要注意,如何确保消息一定消费成功呢?
可以参考:33.MQ专题:消息幂等消费 & 消费失败自动重试 通用方案
10.6 订单状态流转,代码优化,太优雅了
01.背景
电商系统中,订单属于比较核心的功能
本文会带大家看下订单状态流转这块的功能是如何实现的
顺便会对其进行优化,学完后应该可以收获不少
02.订单状态流转代码:第一个版本
a.代码示例
public class OrderService {
/**
* 订单支付
*
* @param orderModel
*/
public void pay(OrderModel orderModel) {
//验证订单状态,订单当前状态必须是待支付状态,即新创建的订单
if (!Objects.equals(orderModel.getStatus(), OrderStatus.INIT.getStatus())) {
throw new RuntimeException("订单状态不支持当前操作");
}
//将订单状态置为已支付状态
OrderStatus toStatus = OrderStatus.PAID;
orderModel.setStatus(toStatus.getStatus());
//todo: 其他操作,比如将订单数据保存到db
}
/**
* 卖家发货
*
* @param orderModel
*/
public void ship(OrderModel orderModel) {
//验证订单状态,订单当前状态必须是已支付状态
if (!Objects.equals(orderModel.getStatus(), OrderStatus.PAID.getStatus())) {
throw new RuntimeException("订单状态不支持当前操作");
}
//将订单状态置为已发货状态
OrderStatus toStatus = OrderStatus.SHIPPED;
orderModel.setStatus(toStatus.getStatus());
//todo: 其他操作,比如将订单数据保存到db
}
/**
* 买家确认收货
*
* @param orderModel
*/
public void deliver(OrderModel orderModel) {
//验证订单状态,订单当前状态必须是已支付状态
if (!Objects.equals(orderModel.getStatus(), OrderStatus.PAID.getStatus())) {
throw new RuntimeException("订单状态不支持当前操作");
}
//将订单状态置为已完成状态
OrderStatus toStatus = OrderStatus.FINISHED;
orderModel.setStatus(toStatus.getStatus());
//todo: 其他操作,比如将订单数据保存到db
}
}
b.代码分析
每个方法里面,都有订单状态校验的代码,校验订单当前状态是否支持当前操作,如果不支持则抛出异常;验证通过后,将订单状态置为下一个状态
这个代码大家感觉如何?
下面我们来看另外一个版本,优化后的
03.优化后的版本
a.代码示例
public class OrderServiceNew {
/**
* 订单状态转换列表,相当于订单的状态图存储在这个列表中了,
* 列表中每条记录对应状态图中一个流转步骤,(OrderStatusTransition:表述一个流转步骤,由(fromStatus、action、toStatus)组合而成)
*/
public static List<OrderStatusTransition> orderStatusTransitionList = new ArrayList<>();
static {
//下面根据订单状态图,将订单流转步骤添加到 orderStatusTransitionList 中
// 待支付 -- 支付 -->已支付
orderStatusTransitionList.add(OrderStatusTransition.builder()
.fromStatus(OrderStatus.INIT)
.action(OrderStatusChangeAction.PAY)
.toStatus(OrderStatus.PAID).build());
// 已支付 -- 发货 -->已发货
orderStatusTransitionList.add(OrderStatusTransition.builder()
.fromStatus(OrderStatus.PAID)
.action(OrderStatusChangeAction.SHIP)
.toStatus(OrderStatus.SHIPPED).build());
// 已发货 -- 买家收货 -->完成
orderStatusTransitionList.add(OrderStatusTransition.builder()
.fromStatus(OrderStatus.SHIPPED)
.action(OrderStatusChangeAction.DELIVER)
.toStatus(OrderStatus.FINISHED).build());
}
/**
* 触发订单状态转换
*
* @param orderModel 订单
* @param action 动作
*/
private void statusTransition(OrderModel orderModel, OrderStatusChangeAction action) {
//根据订单当前状态 & 动作,去 orderStatusTransitionList 中找,可以找到对应的记录,说明当前操作是允许的;否则抛出异常
OrderStatus fromStatus = OrderStatus.get(orderModel.getStatus());
Optional<OrderStatusTransition> first = orderStatusTransitionList.stream().
filter(orderStatusTransition -> orderStatusTransition.getFromStatus().equals(fromStatus) && orderStatusTransition.getAction().equals(action))
.findFirst();
if (!first.isPresent()) {
throw new RuntimeException("订单状态不支持当前操作");
}
OrderStatusTransition orderStatusTransition = first.get();
//切换订单状态
orderModel.setStatus(orderStatusTransition.getToStatus().getStatus());
}
/**
* 订单支付
*
* @param orderModel
*/
public void pay(OrderModel orderModel) {
// 订单状态转换
this.statusTransition(orderModel, OrderStatusChangeAction.PAY);
//todo: 其他操作,比如将订单数据保存到db
}
/**
* 卖家发货
*
* @param orderModel
*/
public void ship(OrderModel orderModel) {
// 订单状态转换
this.statusTransition(orderModel, OrderStatusChangeAction.SHIP);
//todo: 其他操作,比如将订单数据保存到db
}
/**
* 买家确认收货
*
* @param orderModel
*/
public void deliver(OrderModel orderModel) {
// 订单状态转换
this.statusTransition(orderModel, OrderStatusChangeAction.DELIVER);
//todo: 其他操作,比如将订单数据保存到db
}
}
b.代码分析
这种写法将订单状态流转集中处理,方便管理和维护
测试看下效果
10.7 线上问题排查思路
01.问题确认和信息收集
a.精准描述
准确捕捉问题的具体表现,如:接口超时、接口响应慢、服务不可用等
b.影响界定
清晰界定问题影响的范围,包括受影响的用户群体、具体功能模块或服务,以及问题的紧急程度
c.时间线梳理
详细记录问题发生的时间点、持续时间;是否是周期性的问题,还是偶发性的问题
d.环境快照
全面收集环境信息,如:服务器配置、操作系统版本、软件版本、应用版本等信息
02.快速响应与初步处理
a.紧急评估
评估问题的严重程度,基于对业务影响,快速对其分类:如“致命”、“严重”、“一般”或“轻微”问题
b.应急启动
若问题严重,立即启动应急响应计划,如紧急回滚,寻求更多资源支持等
03.分析问题 & 定位问题
a.日志分析
深入检查应用、系统及中间件的日志文件,重点分析错误日志、异常堆栈和警告信息
b.监控分析
通常是有监控系统的,可以查看CPU、内存、磁盘/O、网络等系统资源使用情况
c.JVM监控
分析GC日志、堆内存使用情况、线程状态等
d.应用性能监控
检查请求响应时间、吞吐量、错误率等指标
e.问题复现与模拟
最好能够在测试环境复现问题,定位问题
04.修复问题
找到问题后,制定针对性的解决方案,包括短期修复措施和长期优化计划,确保问题得到彻底解决并预防再次发生
05.验证与部署
a.严格测试
在测试环境中充分验证解决方案的有效性和稳定性,确保没有引入新的问题
b.谨慎部署
遵循部署流程,逐步将解决方案应用到生产环境,监控部署过程中的各项指标变化
06.持续监控与反馈
a.系统监控
部署后持续监控系统状态,确保问题得到彻底解决,并关注系统性能和稳定性指标
b.用户反馈
积极收集用户反馈,验证问题是否已解决,并根据反馈进行必要的调整
07.复盘与持续改进
a.详细报告
编写详细的问题分析报告,记录问题发现、分析、解决和验证的全过程
b.经验总结
总结问题排查过程中的经验教训,提炼最佳实践,更新相关文档和指南
c.持续改进
根据复盘结果,优化系统架构、监控体系、应急响应机制和开发流程,提升团队整体应对能力
10.8 经典并发案例分析,确实有点难,一起来挑战下
01.先来了解下业务
a.描述
如下图,我们有个视频网站,视频下方允许用户发表评论,用户还可以对别人的评论进行回复。
图片说明:视频网站评论示意图
b.评论表如下(t_comment),比较简单
| 字段 | 描述
| ------------------- | ------------------
| comment_id | 评论记录id,主键
| video_id | 被评论的视频id
| user_id | 评论者用户id
| reply_to_comment_id | 指向被回复的评论id
| content | 评论的内容
| create_time | 评论时间
02.产品提了2个需求,看下怎么实现?
1.用户删除评论的时候,需要删掉其所有子评论(也就是其下的回复)
2.用户对某个评论回复的时候,需要校验被回复的评论必须存在,不存在,则给个错误提示
03.方案1:第1个版本代码
a.删除评论的代码
/**
* 删除评论,顺便会删除所有的子评论
* @param commentId 评论id
*/
@Transactional
public void deleteComment(String commentId){
//删除主评论
delete from t_comment where id = #{commentId};
//删除子评论列表
delete from t_comment where repay_to_comment_id = #{commentId};
}
b.评论回复的代码
/**
* 对评论进行回复
* @param videoId 视频id
* @param userId 用户id
* @param content 评论内容
* @param repayToCommentId 被回复的评论id
*/
@Transactional
public void repay(String videoId, String userId, String content, String repayToCommentId){
//查看主评论是否存在
CommentPO repayToCommentPO = select * from t_comment where commentId = #{reapyToCommentId};
//主评论不存在
if(repayToCommentPO == null){
throw new RuntimeException("评论不存在");
}
//插入评论
insert t_comment (video_id, user_id, content, repay_to_comment_id)
values (#{videoId}, #{userId}, #{content}, #{repayToCommentId});
}
c.使用并发对代码进行验证
| 时间点 | 请求1:对评论1进行回复 | 请求2:删除评论1
| ------ | ---------------------- | -----------------------------------
| T1 | 开启事务 | 开启事务
| T2 | 查询主评论1,存在 |
| T3 | | 调用删除评论的方法,主评论1会被删掉
| T4 | | 删除评论1下面的所有子评论
| T5 | | 提交事务
| T6 | 插入子评论,插入成功 |
| T7 | 提交事务 |
-----------------------------------------------------------------------------------------------------
按照上面这个并发过程,最终的结果就是,评论1被删掉了,但是子评论却插入成功了
产品要求,主评论删除的时候,所有的子评论都需要删掉,上面这种方案并没有满足产品需求
怎么解决?见方案2
04.方案2:加互斥锁,让2个操作排队执行
a.方法如下
a.说明
删除评论和对评论进行回复的这两个方法,都会用到主评论id,可以对主评论记录加互斥锁,从而保证2个方法在并发情况下,操作同一个主评论的时候排队执行,便可以解决上面的问题
目前删除评论的时候,主评论已经加锁了(delete from t_comment where comment_id = #{commentId},数据库中对某一条记录执行delete、update、for update的时候会加互斥锁)
调整下评论回复的代码,查询主评论是否存在的时候,采用for update的方式对主评论加互斥锁:select * from t_comment where commentId = #{reapyToCommentId} for update
评论回复的代码,调整后如下,这样,在同一条主评论上面加了互斥锁,确保2个方法排队执行,就解决了上面的问题
b.代码
/**
* 对评论进行回复
* @param videoId 视频id
* @param userId 用户id
* @param content 评论内容
* @param repayToCommentId 被回复的评论id
*/
@Transactional
public void repay(String videoId, String userId, String content, String repayToCommentId){
//查看主评论是否存在,通过for update 对主评论加互斥锁,加互斥锁之后,这条记录执行修改、删除、
CommentPO repayToCommentPO = select * from t_comment where commentId = #{reapyToCommentId} for update;
// 剩下的代码。。。和方案1中是一样的
}
b.使用并发对代码进行验证
a.说明
| 时间点 | 请求1:对评论1进行回复 | 请求2:删除评论1
| ------ | --------------------------------------------------------------------------------------- | ------------------------------------------------------------
| T1 | 开启事务 |
| T2 | 查询主评论1:select * from t_comment where commentId = 1 for update,会对这条评论加互斥锁 | 开启事务
| T3 | | 删除评论1:delete from t_comment where comment_id = 1;由于请求1中对这条记录添加了互斥锁,这里会被阻塞,直到请求1事务结束
| T4 | 插入评论,评论插入成功 | 阻塞中
| T5 | 提交事务 | 阻塞中
| T6 | | 恢复了,删除子评论,此时请求1刚才发表的评论也会被删掉
| T7 | | 提交事务
b.说明
大家好好看看这个过程,此时问题解决了
c.又带来了新的问题,来看下
对同一条评论进行回复,变成串行了,有点追求的我们,肯定是无法接受的
我们期望,对于同一条评论记录,上面2个方法并发的时候排队执行,但是如果当前只有repay方法发生并发,要支持并行执行,不要排队
如何解决?见方案3
05.方案3:将repay方法中的互斥锁改成共享锁
a.MySQL互斥锁和共享锁
这里给大家普及一个知识点,mysql中有2种很重要的锁:互斥锁和共享锁
互斥锁:对记录执行update、delete、或者执行select ... for update的时候,会加互斥锁
共享锁:加锁语法:select * from 表名 where 查询条件 lock in share mode;
-----------------------------------------------------------------------------------------------------
看下下面这个表格,互斥锁和互斥锁不能共存,互斥锁和共享锁不能共存,共享锁和共享锁可以共存
| | 互斥锁 | 共享锁 |
| ------ | -------- | -------- |
| 互斥锁 | 不能共存 | 不能共存 |
| 共享锁 | 不能共存 | 可共存 |
-----------------------------------------------------------------------------------------------------
大家可以理解是什么意思么?给大家举个例子吧
请求1对记录1添加了互斥锁,请求2此时如果想对记录1添加互斥锁、或者共享锁,就需要等待,直到请求1释放锁
请求1对记录1添加了共享锁,请求2此时也可以对请求1添加共享锁;但是请求2此时如果想对记录1添加互斥锁,就需要等待,直到请求1释放锁
可能大家还是无法理解,带大家看下效果
b.效果1:验证互斥锁和互斥锁不能共存
准备数据
drop table if exists t_user;
create table t_user (id int primary key, name varchar(20));
insert into t_user values (1,'路人');
-----------------------------------------------------------------------------------------------------
| 窗口1 | 窗口2
| ------------------------------------------------------------ | ------------------------------------------------------------
| start transaction; |
| delete from t_user where id = 1; -- 对id=1这条记录添加互斥锁 |
| | start transaction;
| | delete from t_user where id = 1; --这里会被阻塞(原因:窗口1中对id=1这条记录添加了互斥锁)
| | 阻塞中
| rollback; -- 结束事务(commit或者rollback) | 唤醒了(原因:窗口1事务结束了,释放了互斥锁)
| | rollback; -- 结束事务(commit或者rollback)
c.效果2:验证互斥锁和共享锁不能共存
| 窗口1 | 窗口2
| ------------------------------------------------------------ | ------------------------------------------------------------
| start transaction; |
| delete from t_user where id = 1; -- 对id=1这条记录添加互斥锁 |
| | start transaction;
| | select * from t_user where id = 1 lock in share mode; --这里会被阻塞(原因:窗口1中对id=1这条记录添加了互斥锁)
| | 阻塞中
| rollback; -- 结束事务(commit或者rollback) | 唤醒了(原因:窗口1事务结束了,释放了互斥锁)
| | rollback; -- 结束事务(commit或者rollback)
d.效果3:验证共享锁和共享锁可以共存
| 窗口1 | 窗口2
| ------------------------------------------------------------ | ------------------------------------------------------------
| start transaction; | start transaction;
| select * from t_user where id = 1 lock in share mode; --对id=1这条记录添加了共享锁
| | select * from t_user where id = 1 lock in share mode; --对id=1这条记录添加了共享锁,共享锁可以共存,所以这里不会被阻塞
| rollback; -- 结束事务(commit或者rollback) | rollback; -- 结束事务(commit或者rollback)
-----------------------------------------------------------------------------------------------------
理解了这些之后,我们对repay方法进行调整,将互斥锁(for update) 调整成共享锁(lock in share model)就可以了
e.方案3,代码如下
图片说明:方案3代码示意图
10.9 如何优雅的处理,线程池内异常?
01.代码
package com.itsoku.lesson099;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.*;
public class ThreadTest {
private static final Logger LOGGER = LoggerFactory.getLogger(ThreadTest.class);
@Test
public void test1() throws InterruptedException {
Thread thread1 = new Thread(() -> {
LOGGER.info("线程中抛出异常测试");
throw new RuntimeException("异常啦");
}, "thread1");
thread1.start();
thread1.join();
}
@Test
public void test2() throws InterruptedException {
Thread thread1 = new Thread(() -> {
try {
LOGGER.info("线程中抛出异常测试");
throw new RuntimeException("异常啦");
} catch (RuntimeException e) {
LOGGER.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}, "thread1");
thread1.start();
thread1.join();
}
@Test
public void test3() throws InterruptedException {
Thread thread1 = new Thread(() -> {
LOGGER.info("线程中抛出异常测试");
throw new RuntimeException("异常啦");
}, "thread1");
thread1.setUncaughtExceptionHandler((Thread t, Throwable e) -> {
LOGGER.info("线程thread1发生异常时,会进来");
LOGGER.error(e.getMessage(), e);
});
thread1.start();
thread1.join();
}
@Test
public void test4() throws InterruptedException {
ThreadFactory threadFactory = Executors.defaultThreadFactory();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5,
5,
10,
TimeUnit.MINUTES, new ArrayBlockingQueue<>(1000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = threadFactory.newThread(r);
thread.setUncaughtExceptionHandler((Thread t, Throwable e) -> {
LOGGER.error(e.getMessage(), e);
});
return thread;
}
});
threadPoolExecutor.execute(() -> {
LOGGER.info("线程池执行任务,抛出异常测试");
throw new RuntimeException("线程池执行任务,异常啦");
});
threadPoolExecutor.shutdown();
threadPoolExecutor.awaitTermination(1, TimeUnit.MINUTES);
}
}
10.10 课程总结
01.并发与性能优化
a.分片上传:处理大文件上传的实战技巧
01.分片上传实战
b.并发处理工具类:通用并发处理工具类的实现与应用
02.通用并发处理工具类实战
c.接口性能压测:实现接口性能压测工具类
03.实现一个好用接口性能压测工具类
d.超卖问题:解决超卖问题的多种方案
04.超卖问题的4种解决方案,也是防止并发修改数据出错的通用方案
e.接口限流:使用Semaphore实现接口限流
05.Semaphore实现接口限流实战
f.并行查询:通过并行查询优化接口响应速度
06.并行查询,优化接口响应速度实战
12.并行查询,性能优化利器,可能有坑
g.大事务优化:解决大事务带来的性能问题
07.接口性能优化之大事务优化
h.动态线程池:手写线程池管理器及动态线程池的实现
09.手写线程池管理器,管理&监控所有线程池
10.动态线程池
02.分布式与微服务
a.动态Job:SpringBoot实现动态Job的实战
11.SpringBoot实现动态Job实战
b.幂等性:解决幂等性问题的多种方案
13.幂等的4种解决方案,吃透幂等性问题
43.接口幂等,通用方案 & 代码落地
c.分布式锁:分布式锁的实现与应用,包括Redisson等工具类
39.分布式锁详解
40.分享一个特别好用的Redissson分布式锁工具类
41.一个注解轻松搞定分布式锁
d.微服务架构:微服务中的公共参数传递、链路日志追踪等
19.通过AOP统一打印请求链路日志,排错效率飞升
42.微服务中如何传递公共参数?
44.微服务链路日志追踪实战
e.分布式事务
36.分布式事务-MQ最终一致性-实现跨库转账(案例+源码+文档)
37.分布式事务-MQ最终一致性-实现电商账户余额提现到微信钱包(案例+源码+文档)
38.分布式事务:通用的TCC分布式事务生产级代码落地实战
03.数据库与数据操作
a.数据一致性:确保MySql和Redis数据一致性的策略
22.MySql和Redis数据一致性
b.数据脱敏:SpringBoot中实现数据脱敏的优雅设计
23.SpringBoot数据脱敏优雅设计与实现
c.分库分表:分库分表的选择、设计、迁移等实战技巧
69.分库、分表、分库分表,如何选择?
70.分库分表:分表字段如何选择?
71.分库分表:分表数量为什么建议是2的n次方?
72.分库分表:如何平滑迁移数据?
d.高性能ID生成器:基于MySQL实现高性能分布式ID生成器
61.使用MySQL,实现一个高性能,分布式id生成器
e.数据同步:MySQL数据同步到ES的靠谱方案
95.MySQL数据如何同步到ES?靠谱方案
04.消息队列(MQ专题)
a.MQ使用场景
MQ的典型使用场景
b.消息可靠性
确保MQ消息可靠性的方法
c.事务消息
SpringBoot中实现事务消息的步骤
d.延迟消息
MQ延迟消息的通用方案
e.幂等消费与重试
MQ消息幂等消费及消费失败重试方案
f.顺序消息
MQ顺序消息的通用方案
g.消息积压
消息积压问题及解决思路
h.汇总
28.MQ专题-MQ典型的使用场景
29.MQ专题-如何确保消息的可靠性
30.MQ专题-SpringBoot中,手把手教你实现事务消息
31.手写一个好用的延迟任务处理工具类
32.MQ专题-MQ延迟消息通用方案实战
33.MQ消息幂等消费 & 消费失败衰减式重试通用方案 & 代码 & 文档
34.MQ专题:顺序消息通用方案实战 & 代码落地 & 文档
35.MQ专题:消息积压相关问题及解决思路
05.生产问题排查
a.日志管理:通过AOP统一打印请求链路日志
19.通过AOP统一打印请求链路日志,排错效率飞升
b.错误排查:接口报错快速定位日志、OOM排查、CPU飙升排查等
17.接口报错,如何快速定位日志?
54.性能调优:线程死锁相关问题
55.如何排查OOM?
56.cpu飙升,如何快速排查?
57.cpu飙升,使用Arthas,3秒定位问题
58.接口响应慢,使用Arthas,3秒定位问题代码
60.生产上,代码未生效,如何排查?
62.方法执行异常,使用arthas,快速定位问题
c.Debug技巧:IDEA中的必备debug技巧及多线程调试方法
86.idea中的必备debug技巧,高手必备
91.idea多线程调试,这个技巧也太棒了吧,你会么?
06.其他实战案例
14.接口通用返回值设计与实现
15.接口太多,各种dto、vo不计其数,如何命名?
16.一个业务太复杂了,方法太多,如何传参?
18.线程数据共享必学的3个工具类:ThreadLocal、InheritableThreadLocal、TransmittableThreadLocal
20.大批量任务处理常见的方案(模拟余额宝发放收益)
21.并发环境下,如何验证代码是否正常?
24.一行代码搞定系统操作日志
25.Aop简化MyBatis分页功能
26.ThreadLocal 遇到线程池有大坑 & 通用解决方案
27.SpringBoot读写分离实战(一个注解搞定读写分离 && 强制路由主库)
45.接口测试利器HTTP Client,不用Postman也可以
46.封装MyBatis,实现通用无SQL版CRUD功能ORM框架
47.MyBatisPlus 轻松实现多租户数据隔离
48.电商系统-资金账户表设计 及 应用实战
49.UML画图神器:PlantUML,画图效率飞升
50.多线程事务,3秒插入百万数据
51.SpringBoot中自动初始化数据库功能,非常好用
52.SpringBoot优雅停机
53.分享一个特好用的集合工具类,开发效率轻松翻倍
59.策略模式,轻松消除ifelse代码
63.扫码登录详解
64.使用hutool生成&解析二维码,太方便了
65.SpringBoot中,redis中实现排行榜
66.SpringBoot中,Redis如何实现查找附近的人功能?
67.SpringBoot中,接口签名,通用方案,一次性搞懂
68.SpringBoot中,接口加解密,通用方案实战
73.并发编程有多难?值得反复研究的一个案例
74.使用Redis Pipeline,接口性能提升10倍
75.电商中,重复支付如何解决?
76.千万级数据,全表update的正确姿势
77.优雅实现树形菜单,适用于所有树,太好用了
78.接口调用利器:RestTemplate,吃透它
79.微服务跨库查询,如何解决?一次性搞懂
80.逻辑删除与唯一约束冲突,如何解决?
81.评论系统如何设计,一次性给你讲清楚
82.SpringBoot下载文件的几种方式,一次性搞懂
83.订单超时自动取消,最常见的方案
84.责任链模式优化代码,太好用了
85.CompletableFuture 实现异步任务编排,太好用了
87.Java动态生成word,太强大了
88.海量据量统计,如何提升性能?
89.MyBatis模糊查询,千万不要再用${}了,容易搞出大事故
90.Spring事务失效,常见的几种场景,带你精通Spring事务
92.MySQL排序分页,可能有坑,需要注意
93.涉及到钱的,千万不要用double,请用BigDecimal
94.MyBatis动态SQL不要乱用
96.订单状态流转代码优化,确实优雅
97.线上问题排查思路
98.经典并发案例分析,确实有点难,一起来挑战下
99.如何优雅的处理线程池内异常?