1 Thread
1.1 [1]并发
00.JUC,Java Util Concurrent,JDK5引入
1.线程池
2.原子操作
3.通信工具类
4.条件和协调
5.ThreadLocal
6.线程池
7.任务执行
8.并发集合
01.锁机制
synchronized Java内置关键字,用于方法或代码块的同步
ReentrantLock 可重入锁,提供更灵活的锁控制 公平锁/非公平锁(默认)
ReentrantReadWriteLock 读写锁,允许多个读线程并发访问,写线程独占锁 读锁/写锁
StampedLock 时间戳锁,比ReentrantReadWriteLock性能高,JDK8引入 读锁/写锁/乐观锁
02.原子操作
AtomicBoolean 基本类型:布尔值
AtomicInteger 基本类型:整数
AtomicLong 基本类型:长整数
AtomicIntegerArray 数组类型:整数数组的元素
AtomicLongArray 数组类型:长整数数组的元素
AtomicReferenceArray 数组类型:对象引用数组的元素
AtomicMarkableReference 引用类型:对象引用和标记,解决【ABA问题】
AtomicStampedReference 引用类型:对象引用和标记,解决【ABA问题】
AtomicReference 引用类型:对象引用
AtomicIntegerFieldUpdater 属性更新类型:对象的int字段
AtomicLongFieldUpdater 属性更新类型:对象的long字段
AtomicReferenceFieldUpdater 属性更新类型:对象的引用字段
DoubleAccumulator 累加器:双精度浮点数,高并发环境
DoubleAdder 累加器:双精度浮点数,高并发环境
LongAccumulator 累加器:长整数,高并发环境
LongAdder 累加器:长整数,高并发环境
03.通信工具类
CountDownLatch 倒计时锁存器,线程等待直到计数器减为0时开始工作
CyclicBarrier 循环栅栏,作用跟CountDownLatch类似,但是可以重复使用
Semaphore 信号量,限制线程的数量
Exchanger 交换器,两个线程交换数据
Phaser 阶段器,增强的CyclicBarrier
04.条件和协调
Condition 用于与Lock结合,实现线程间的等待和通知机制
LockSupport 线程阻塞唤醒类,底层依赖Unsafe类
05.线程局部变量
ThreadLocal 为每个线程提供独立的变量副本,避免线程间共享
06.线程池
ForkJoinPool 支持任务分治和并行执行的线程池
ThreadPoolExecutor 管理和复用线程的线程池实现
07.任务执行
FutureTask 可取消的异步任务,支持获取结果
CompletableFuture 支持异步任务执行和组合的工具
08.并发集合
ConcurrentHashMap 线程安全的哈希表,支持高并发读写
CopyOnWriteArrayList 线程安全的列表,适用于读多写少的场景
BlockingQueue 支持阻塞操作的队列,如ArrayBlockingQueue、LinkedBlockingQueue
1.2 [1]并发、并行
00.回答
a.并发
多个任务在同一时间段内交替执行,通常在【单核CPU】上通过【时间片轮转】实现
并发主要是通过任务切换来实现“同时”运行
b.并行
多个任务在同一时间点上同时执行,通常在【多核CPU上】实现
并行是通过多个处理器或多个核心同时处理多个任务来实现真正的同时运行
c.并发不是并行
并发主要由切换时间片来实现"同时"运行,并行则是直接利用多核实现多线程的运行
01.并发
定义:多线程程序在一个核的CPU上运行,就是并发
特点:通过切换时间片来实现“同时”运行
示例:在单核 CPU 上运行多个线程
02.并行
定义:多线程程序在多个核的CPU上运行,就是并行
特点:直接利用多核实现多线程的运行
示例:在多核 CPU 上运行多个线程
1.3 [1]线程、进程
00.回答
【进程】进一步【细分为线程】
一个程序至少有一个进程,一个进程至少有一个线程
进程是程序运行的实例,线程是进程的执行实体
01.进程
定义:应用程序的执行实例,有独立的内存空间和系统资源
特点:进程拥有独立的内存空间和系统资源
示例:QQ是一个进程,运行一个Java程序的实质就是启动一个Java虚拟机进程
02.线程
定义:将进程进一步细分为线程,是CPU调度和分派的最小单位
特点:线程共享进程的内存空间和资源
示例:QQ可以细分为多个功能(接收消息、发送消息),每个功能都可以通过一个线程来实现
1.4 [1]线程、线程守护
00.汇总
a.生命周期
普通线程:普通线程的生命周期独立于其他线程,除非显式地被终止,否则会一直运行
Daemon线程:Daemon线程的生命周期依赖于用户线程,当所有用户线程结束时,Daemon线程也会自动终止
b.用途
普通线程:用于执行程序中的主要任务
Daemon线程:用于在后台提供通用服务,如垃圾回收、日志记录等
c.设置方式
普通线程:默认情况下,所有线程都是普通线程
Daemon线程:必须在线程启动之前调用setDaemon(true)方法,将线程设置为Daemon线程
d.总结
Daemon线程的生命周期依赖于用户线程。当所有用户线程结束时,JVM会自动终止所有的Daemon线程并退出
因此,Daemon线程不会阻止JVM的退出。只要有任何用户线程在运行,Daemon线程就会继续运行
要将一个线程设置为Daemon线程,必须在线程启动之前调用setDaemon(true)方法
典型的Daemon线程包括:1.JVM的垃圾回收线程;2.Finalizer线程
01.线程(普通线程)
a.定义
线程是进程的一个执行实体,是CPU调度和分派的基本单位。普通线程在程序中执行具体的任务
b.特点
线程共享进程的内存空间和资源
线程的生命周期独立于其他线程,除非显式地被终止,否则会一直运行
线程可以是用户线程或守护线程(Daemon线程)
c.代码
public class UserThreadExample {
public static void main(String[] args) {
Thread userThread = new Thread(() -> {
System.out.println("User thread is running");
});
userThread.start();
}
}
02.Daemon线程(守护线程)
a.定义
Daemon线程是程序运行时在后台提供通用服务的线程,这个线程并不属于程序中不可或缺的部分
b.特点
当所有的非Daemon线程(用户线程)结束时,程序也就终止,同时会杀死进程中的所有Daemon线程
必须在线程启动之前调用setDaemon(true) 方法,才能把它设置为Daemon线程
Daemon线程在不执行finally子句的情况下就会终止其run()方法
c.分类1:JVM的垃圾回收线程
定义:垃圾回收线程是JVM中负责自动回收不再使用的对象的线程
特点:垃圾回收线程是一个Daemon线程,它在后台运行,不会阻止JVM终止
作用:通过回收不再使用的对象,释放内存空间,防止内存泄漏
d.分类2:Finalizer线程
定义:Finalizer线程是JVM中负责调用对象的finalize()方法的线程
特点:Finalizer线程也是一个Daemon线程,它在后台运行,不会阻止JVM终止
作用:在对象被垃圾回收之前,执行一些清理操作,如关闭文件、释放资源等
e.代码
public class DaemonThreadExample {
public static void main(String[] args) {
Thread daemonThread = new Thread(() -> {
while (true) {
System.out.println("Daemon thread is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
daemonThread.setDaemon(true);
daemonThread.start();
// 主线程休眠一段时间后结束
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Main thread is ending");
}
}
1.5 [1]线程、协程
00.回答
协程是一个比【线程轻量级】的执行单位
01.协程
定义:协程是一个比线程轻量级的执行单位,独立的栈空间,共享堆空间,调度由用户自己控制
特点:类似于用户级线程,调度由用户实现
示例:一个线程上可以跑多个协程,协程是轻量级的线程
02.线程
定义:线程是进程的一个执行实体,是 CPU 调度和分派的基本单位
特点:线程共享进程的内存空间和资源
示例:一个进程可以创建和撤销多个线程
1.6 [1]线程、协程、goroutine
00.回答
goroutine是Go语言对【协程的一种实现】
01.goroutine
a.定义
goroutine是Go语言中的一种轻量级线程,由Go语言官方实现的超级“线程池”
b.特点
每个goroutine实例占用4~5KB的栈内存
创建和销毁开销较小
goroutine 奉行通过通信来共享内存,而不是共享内存来通信
02.协程
a.定义
协程(Coroutine)是一个比线程轻量级的执行单位,独立的栈空间,共享堆空间,调度由用户自己控制
b.特点
协程是程序调度的基本单位
线程可以包含多个协程,协程可以在单个线程中运行,也可以在多个线程之间共享
协程的调度由用户实现,通常是非抢占式的
03.线程
a.定义
线程是进程的一个执行实体,是CPU调度和分派的基本单位
b.特点
线程共享进程的内存空间和资源
线程的调度由操作系统内核实现,通常是抢占式的
1.7 [1]线程组、线程优先级
00.总结
特性 线程组(ThreadGroup) 线程优先级(Thread Priority)
定义 用于管理一组线程的类 用于控制线程调度的属性
组织结构 树状结构 无组织结构
批量操作 支持批量操作线程 不支持批量操作
优先级范围 无 1 到 10,默认优先级为 5
典型应用场景 组织和管理多个线程,批量操作线程 控制线程调度,资源竞争
01.线程组
a.定义
线程组(ThreadGroup)是一个用于管理一组线程的类
线程组可以包含线程和其他线程组,从而形成一个树状结构。线程组提供了一种机制来组织和管理多个线程
b.原理
线程组通过树状结构组织线程和子线程组
每个线程组都有一个父线程组,根线程组是系统线程组
线程组可以用于批量操作线程,如批量中断、批量设置优先级等
c.常用API
a.构造方法
ThreadGroup(String name): 创建一个具有指定名称的新线程组
ThreadGroup(ThreadGroup parent, String name): 创建一个具有指定名称的新线程组,并将其作为指定父线程组的子线程组
b.线程组操作
String getName(): 返回线程组的名称
ThreadGroup getParent(): 返回线程组的父线程组
int activeCount(): 返回线程组中活动线程的估计数
int activeGroupCount(): 返回线程组中活动子线程组的估计数
void list(): 将线程组及其子线程组中的信息打印到标准输出
void interrupt(): 中断线程组中的所有线程
void setMaxPriority(int pri): 设置线程组中所有线程的最大优先级
d.详情
树状结构:线程组通过树状结构组织线程和子线程组
批量操作:线程组提供了批量操作线程的机制,如批量中断、批量设置优先级等
管理线程:线程组提供了一种机制来组织和管理多个线程
e.应用场景
组织线程:在需要组织和管理多个线程的场景中,线程组提供了一种有效的机制
批量操作:在需要批量操作线程的场景中,线程组提供了方便的操作方法
f.代码示例
public class ThreadGroupExample {
public static void main(String[] args) {
ThreadGroup group = new ThreadGroup("MyThreadGroup");
Thread thread1 = new Thread(group, () -> {
System.out.println("Thread 1 is running");
});
Thread thread2 = new Thread(group, () -> {
System.out.println("Thread 2 is running");
});
thread1.start();
thread2.start();
System.out.println("Active threads in group: " + group.activeCount());
group.list();
}
}
-----------------------------------------------------------------------------------------------------
在这个示例中,我们创建了一个线程组,并将两个线程添加到该线程组中
然后,我们启动这两个线程,并打印线程组中的活动线程数和线程组的信息
02.线程优先级
a.定义
线程优先级(Thread Priority)是一个用于控制线程调度的属性
线程优先级是一个整数值,范围从 Thread.MIN_PRIORITY(1)到 Thread.MAX_PRIORITY(10),默认优先级为 Thread.NORM_PRIORITY(5)
b.原理
线程优先级用于提示线程调度器应该优先调度哪些线程
具有较高优先级的线程通常会比具有较低优先级的线程获得更多的 CPU 时间
然而,线程优先级只是一个提示,具体的调度行为依赖于操作系统的线程调度器
c.常用API
a.设置和获取线程优先级
void setPriority(int newPriority): 设置线程的优先级
int getPriority(): 返回线程的优先级
b.优先级常量
Thread.MIN_PRIORITY: 最低优先级(1)
Thread.NORM_PRIORITY: 默认优先级(5)
Thread.MAX_PRIORITY: 最高优先级(10)
d.详情
优先级范围:线程优先级的范围从 1 到 10,默认优先级为 5
调度提示:线程优先级用于提示线程调度器应该优先调度哪些线程,但具体行为依赖于操作系统的线程调度器
影响调度:具有较高优先级的线程通常会比具有较低优先级的线程获得更多的 CPU 时间
e.应用场景
控制线程调度:在需要控制线程调度的场景中,可以通过设置线程优先级来提示线程调度器优先调度某些线程
资源竞争:在多个线程竞争资源的场景中,可以通过设置线程优先级来控制资源的分配
f.代码示例
public class ThreadPriorityExample {
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
System.out.println("Thread 1 is running with priority: " + Thread.currentThread().getPriority());
});
Thread thread2 = new Thread(() -> {
System.out.println("Thread 2 is running with priority: " + Thread.currentThread().getPriority());
});
thread1.setPriority(Thread.MIN_PRIORITY);
thread2.setPriority(Thread.MAX_PRIORITY);
thread1.start();
thread2.start();
}
}
-----------------------------------------------------------------------------------------------------
在这个示例中,我们创建了两个线程,并分别设置它们的优先级。然后,我们启动这两个线程,并打印它们的优先级
1.8 [2]进程通信
01.进程之间是怎么通信的?
进程之间的通信(Inter--Process Communication,IPC)比较复杂,因为它们有各自独立的内存空间
02.进程通信方式
a.管道(Pipes)
单向通信机制,数据以字节流的形式从一个进程传递到另一个进程。在Uix/iux系统中常用,如命令行中的管道
b.命名管道(Named Pipes,FIFO)
类似于管道,但具有名称,可以在不相关的进程之间通信。跨网络的通信也可以使用命名管道
c.消息队列(Message Queues)
通过消息传递进行进程间通信,允许进程以消息的形式发送和接收数据
d.共享内存(Shared Memory)
多个进程共享同一块内存区域,实现高速通信。注意需要同步机制(如信号量)来防止数据竞争
e.信号量(Semaphores)
一种用于进程同步的计数器,控制多个进程对共享资源的访问
f.套接字(Sockets)
通过网络进行进程间通信,支持本地和远程进程通信
1.9 [2]线程通信
01.线程之间如何进行通信?
线程之间的通信(Inter-Thread Communication,ITC)主要依赖于共享内存
由于线程共享同一个进程的内存空间,因此可以直接通过共享变量进行通信
02.线程通信方式
a.共享变量
线程可以通过访问共享内存变量来交换信息(需要注意同步问题,防止数据竞争和不一致)
共享的也可以是文件,例如写入同一个文件来进行通信
b.同步机制
信号量
Lock:Java中的java.util.concurrent.locks包提供了更灵活的锁机制,如ReentrantLock
volatile:Java中的关键字,确保变量的可见性,防止指令重排
synchronized:Java中的同步关键字,用于确保同一时刻只有一个线程可以访问共享资源
c.等待/通知机制
wait():使线程进入等待状态,释放锁
notify():唤醒单个等待线程
notifyAll():唤醒所有等待线程
1.10 [2]线程通讯、线程编排
00.回答
线程通讯:专注于底层的【数据交互和同步】细节
线程任务:编排侧重于【高层次的执行计划和流程控制】
01.线程通讯
a.介绍
Object 类下的 wait()、notify() 和 notifyAll() 方法
Condition 类下的 await()、signal() 和 signalAll() 方法
LockSupport 类下的 park() 和 unpark() 方法
b.说明
线程通讯则是指在多线程环境中,线程之间传递信息和协调工作的机制
当多个线程需要共享数据或协同完成某项任务时
它们需要通过某种方式进行沟通,以确保数据的正确性和任务的同步执行
它的重点在于解决线程间的同步问题和数据一致性问题
02.线程任务编排
a.介绍
a.FutureTask
诞生于 JDK 1.5,它实现了 Future 接口和 Runnable 接口,设计初衷是为了支持可取消的异步计算
它既可以承载 Runnable 任务(通过包装成 RunnableAdapter),也可以承载 Callable 任务
从而能够返回计算结果,使用它可以实现简单的异步任务执行和结果的等待
b.CompletableFuture
诞生于 JDK 8,它不仅实现了 Future 接口,还实现了 CompletionStage 接口
CompletionStage 是对 Future 的扩展,提供了丰富的链式异步编程模型,支持函数式编程风格,
可以更加灵活地处理异步操作的组合和依赖回调等
b.说明
线程任务编排主要关注的是如何组织和管理线程执行的任务序列,确保任务按照预定的逻辑和顺序执行,
包括任务的启动、停止、依赖管理、执行策略(如并行、串行)以及错误处理等。它是关于如何有效地规划
线程的工作流程,以达成高效和正确的程序执行目标
1.11 [2]可中断性、可重入性
00.总结
可中断性:允许线程在等待锁时被中断,增强了程序的灵活性和响应能力
可重入性:允许同一线程多次获取同一把锁,确保在递归调用或多次请求锁时的安全性
01.可中断性(Interruptibility)
a.定义
可中断性指的是一个线程在等待获取锁或执行某个操作时,可以被其他线程中断的能力。
在Java中,使用ReentrantLock的lockInterruptibly()方法可以实现可中断的锁获取。
b.特点
如果一个线程在等待锁时被中断,它会抛出InterruptedException,允许线程响应中断请求。
可中断性提高了程序的灵活性,允许线程在等待期间做出响应,避免长时间阻塞。
c.示例
import java.util.concurrent.locks.ReentrantLock;
public class InterruptibleLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void method() {
try {
lock.lockInterruptibly(); // 可中断的锁获取
// 执行临界区代码
} catch (InterruptedException e) {
// 处理线程被中断的情况
Thread.currentThread().interrupt(); // 恢复中断状态
} finally {
lock.unlock();
}
}
}
02.可重入性(Reentrancy)
a.定义
可重入性指的是同一线程可以多次获取同一把锁而不会发生死锁的能力。
在Java中,synchronized关键字和ReentrantLock都支持可重入性。
b.特点
当一个线程已经持有锁时,它可以再次获取该锁,而不会被阻塞。
可重入性确保了在递归调用或同一线程多次请求锁时的安全性。
c.示例
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void outerMethod() {
lock.lock(); // 获取锁
try {
innerMethod(); // 同一线程可以再次获取锁
} finally {
lock.unlock(); // 释放锁
}
}
public void innerMethod() {
lock.lock(); // 再次获取锁
try {
// 执行代码
} finally {
lock.unlock(); // 释放锁
}
}
}
1.12 [3]为什么要重写run方法?默认普通方法
01.为什么要重写run方法?
默认的run()方法不会做任何事情
02.为了让线程执行一些实际的任务,我们需要提供自己的run()方法实现,这就需要重写run()方法
public class MyThread extends Thread {
public void run() {
System.out.println("MyThread running");
}
}
当我们创建并启动这个线程的实例时,它就会打印出这条消息
1.13 [3]Thread.sleep(0) 作用:暂时出让CPU
01.Thread.sleep(0)的作用是什么?
看起来Thread.sleep(O)很奇怪,让线程睡眠0毫秒?那不是等于没睡眠吗?
是的,确实没有睡眠,但是调用了Thread.sleep(O)当前的线程会【暂时出让CPU,这使得CPU的资源短暂的空闲出来别的线程有机会得到CPU资源】。
所以,在一些大循环场景,如果害怕这段逻辑一直占用CPU资源,则可以调用Thread.sleep(O)让别的线程有机会使用CPU.
实际上Thread.yield这个命令也可以让当前线程主动放弃CPU使用权,使得其他线程有机会使用CPU。
1.14 [3]核心线程数为0时,线程池如何执行?创建新线程
00.总结
【当核心线程数为 0 时,当来了一个任务之后,会先将任务添加到任务队列,
同时也会判断当前工作的线程数是否为 0,如果为 0,则会创建线程来执行线程池的任务】
---------------------------------------------------------------------------------------------------------
在线程池的使用过程中,最大线程数必须大于等于核心线程数,否则程序执行会报错
01.正常情况下(核心线程数不为 0 的情况下)线程池的执行流程如下:
1.判断核心线程数:先判断当前工作线程数是否大于核心线程数,如果结果为 false,则新建线程并执行任务。
2.判断任务队列:如果大于核心线程数,则判断任务队列是否已满?如果结果为 false,则把任务添加到任务队列中等待线程执行。
3.判断最大线程数:如果任务队列已满,则判断当前线程数量是否超过最大线程数?如果结果为 false,则新建线程执行此任务。
4.判断是否要执行拒绝策略:如果超过最大线程数,则将执行线程池的拒绝策略。
02.核心线程数 VS 最大线程数
核心线程数(corePoolSize)和最大线程数(maximumPoolSize)都是线程池中的两个重要参数,其中:
核心线程数定义了线程池中最小线程数量,即使这些线程处于空闲状态,也不会被销毁。
最大线程数定义了线程池中允许的最大线程数量,最大线程数等于核心线程数 + 临时线程数,
最大线程数主要是提供了一种机制来应对突发的高并发请求,当有大量任务的时候,可以创建线程数量的上线。
1.15 [3]一个线程被两次调用start()方法,会发生什么?会报错!
01.如果一个线程被两次调用start()方法,会发生什么?
线程生命周期:
新建(New)
运行(Runnable)
阻塞(Blocked)
无限期等待(Waiting)
限期等待(Time Waiting)
结束(Terminated)
---------------------------------------------------------------------------------------------------------
会报错!因为在Java中,一个线程只能被启动一次!所以尝试第二次调用start(0方法时,会抛出llegalThreadStateException异常。
这是因为一旦线程已经开始执行,它的状态不能再回到初始状态。线程的生命周期不允许它从终止状态回到可运行状态。
1.16 [3]是否所有的线程都是通过start()启动?不是,main()
01.是否所有的线程都是通过start()启动?
a.回答
不是,main()
b.其他
强制执行join:强制执行调用join()的线程,阻塞当前正在执行的线程
线程的礼让yeild: 礼让仅仅是一种尽可能事件,并不一定会100%执行
1.17 [4]wait和notify为什么要放在synchronized代码块中?安全
00.回答
为了确保线程安全、遵循监视器规则、避免死锁
01.监视器规则
a.说明1
Java 规定,wait() 和 notify() 必须在拥有对象监视器的线程中调用
换句话说,调用这些方法的线程必须首先获得对象的锁(通过 synchronized)
b.说明2
如果线程没有持有对象的锁,调用 wait() 将会抛出 IllegalMonitorStateException 异常
因此,必须在同步代码块中调用这些方法,以确保当前线程持有正确的锁
02.线程安全
a.说明1
wait() 和 notify() 必然是成对出现的,如果一个线程被 wait() 方法阻塞
那么必然需要通过 notify() 方法来唤醒这个被阻塞的线程,从而实现多线程之间的通信
b.说明2
因此需要保证 wait() 和 notify() 操作需要保证原子性,即在同一时刻只能有一个线程执行这些操作
synchronized 关键字确保了这一点,因为它会锁定对象或类的监视器,防止多个线程同时进入临界区
c.说明3
如果不在同步代码块中,多个线程可能会同时调用 wait() 或 notify(),导致不可预测的行为和数据不一致
03.避免 lost wake up 问题
a.说明1
Java 强制要求 wait() 和 notify() 必须在同步块中调用,以避免 lost wake up 问题
这种问题发生在多个线程竞争同一个锁时,可能会导致某些线程的唤醒信号丢失
04.锁的管理
a.说明1
wait() 和 notify() 方法需要操作对象的监视器锁(monitor lock)
b.说明2
当一个线程调用 wait() 方法时,它会释放当前持有的监视器锁,并进入等待状态
直到其他线程调用 notify() 或 notifyAll() 方法来唤醒它
c.说明3
同样,notify() 和 notifyAll() 方法也会释放监视器锁,以便等待的线程可以重新获取锁并继续执行
d.说明4
因此,这些方法必须在同步代码块中调用,以确保线程能够正确地获取和释放锁
05.示例代码
public class Example {
private final Object lock = new Object();
public void doSomething() {
synchronized (lock) {
try {
while (/* condition not met */) {
lock.wait(); // 等待条件满足
}
// 执行相关操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
public void notifySomething() {
synchronized (lock) {
// 修改条件
lock.notifyAll(); // 通知等待的线程
}
}
}
1.18 [4]主线程结束了,子线程是否可以正常运行
01.主线程结束了,子线程是否可以正常运行
在 Java 中,默认情况下,主线程结束了,如果子线程是用户线程还会继续运行
如果子线程都是守护线程,那么当主线程结束时,没有其它的用户线程,守护线程也会自动结束,JVM 也会退出
但如果子线程中有用户线程,那么即使主线程结束了,用户线程仍会继续执行,直到所有的用户线程执行完毕,程序才会完全结束
02.用户线程
a.说明
如果子线程是用户线程(User Thread)(即没有被设置为守护线程),用户线程则不依赖创建它的线程
那么当主线程结束时,子线程会继续运行,直到它们自然结束或被显式终止
主线程与子线程是完全独立的生命周期,主线程的结束不会影响到子线程的执行状态
b.代码示例
a.说明
用户线程在主线程结束后继续运行
b.代码
public class MainThreadEndsExample {
public static void main(String[] args) {
Thread userThread = new Thread(() -> {
try {
for (int i = 0; i < 5; i++) {
System.out.println("用户线程运行: " + i);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
userThread.start();
try {
Thread.sleep(2000); // 让子线程有时间运行
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("主线程结束");
}
}
c.说明
在这个例子中,主线程在 2 秒后结束,用户线程仍然会继续运行直到完成它的任务
03.守护线程
a.说明
守护线程的设计初衷是为了节省资源,通常用于执行一些后台任务,如垃圾回收、监控等
-----------------------------------------------------------------------------------------------------
可以通过 setDaemon(true) 方法,将线程设置为守护线程,但需要注意的是
设置守护线程必须在线程启动之前进行,否则会抛出 IllegalThreadStateException 异常
-----------------------------------------------------------------------------------------------------
如果子线程被设置为守护线程,那么当主线程结束时,如果 JVM 中,还有其他的用户线程,JVM 将等待这些用户线程结束
在这个过程中,守护线程将继续执行,直到所有用户线程结束,守护线程也会自动结束,JVM 也会退出
b.代码
a.说明
演示了守护线程和用户线程的行为
b.代码
public class DaemonThreadExample {
public static void main(String[] args) {
// 创建并启动一个守护线程
Thread daemonThread = new Thread(() -> {
System.out.println("守护线程启动");
try {
while (true) {
// 模拟后台任务
System.out.println("守护线程运行中");
Thread.sleep(1000);
}
} catch (InterruptedException e) {
System.out.println("守护线程被中断");
}
});
daemonThread.setDaemon(true); // 设置为守护线程
daemonThread.start();
// 创建并启动一个用户线程
Thread userThread = new Thread(() -> {
System.out.println("用户线程启动");
try {
for (int i = 0; i < 5; i++) {
System.out.println("用户线程运行: " + i);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.out.println("用户线程被中断");
}
System.out.println("用户线程结束");
});
userThread.start();
// 主线程立即结束
System.out.println("主线程结束");
}
}
c.说明
在这个例子中,尽管主线程很快结束,守护线程和用户线程都继续运行
用户线程在完成其任务后结束,随后守护线程也被中断和终止,JVM随之退出
这表明守护线程不会阻止JVM退出,它们会在所有用户线程结束后自动终止
1.19 [4]使用wait ()方法时使用if还是while?while
00.汇总
wait() 方法通常放在 while 循环中而不是 if 语句中,主要是为了解决下面的问题:
1.防止虚假唤醒
2.确保线程被唤醒时满足条件,避免因条件变化导致线程继续执行错误的操作
01.什么是虚假唤醒(Spurious Wakeups)
虚假唤醒是指线程在没有被显式唤醒(例如通过notify()或notifyAll())的情况下,仍然从wait()状态中恢复执行的现象
这种情况可能因为操作系统的线程调度或其他线程的干扰而发生
02.使用while循环的原因
a.防止虚假唤醒
Java中的wait()方法可能会出现“虚假唤醒”现象。如果不在循环中检查等待条件,程序可能在没有满足结束条件的情况下退出
使用while循环可以确保在每次从wait()方法返回后,都会重新检查条件是否满足,从而避免因虚假唤醒而导致的错误
b.确保条件满足
当线程被唤醒时,它需要重新检查等待的条件是否仍然满足。如果条件不满足,线程应该再次进入等待状态
通过在while循环中调用wait(),可以确保线程在每次唤醒后都重新检查条件,从而避免因条件变化而导致的错误行为
c.避免条件变化
在多线程环境中,其他线程可能会在当前线程进入等待状态后修改条件
如果wait()方法放在if语句中,当线程被唤醒时,可能无法及时检测到条件的变化,从而导致线程继续执行错误的操作
03.典型使用场景
a.说明
如何在while循环中使用wait()方法
b.代码
synchronized (monitor) {
while (!condition) {
try {
monitor.wait();
} catch (InterruptedException e) {
// 处理中断异常
Thread.currentThread().interrupt(); // 恢复中断状态
}
}
// 条件满足,继续执行
}
c.说明
monitor:是一个对象,用于同步和等待
condition:是一个布尔条件,决定线程是否需要继续等待
while循环:确保线程在每次唤醒后都重新检查条件
try-catch块:用于处理InterruptedException,并在捕获异常后恢复线程的中断状态
1.20 [4]多线程并不是越多越好?占内存
01.多线程并不是越多越好?
每开启一个线程会占用1M左右的内存,因此太多的线程会占用大量的内存资源
1.21 [5]核心线程数会被回收吗?不会
00.回答
核心线程数默认是不会被回收的
01.说明
如果需要回收核心线程数,需要调用下面的方法:
allowCoreThreadTimeOut该值默认为 false
设置为true就会回收核心线程
1.22 [5]线程池中线程异常后:销毁还是复用?
00.说明
a.回答
看使用的是execute方法还是submit方法
b.execute方法
会抛出异常,然后移除抛出异常的线程,创建新的线程放入到线程池中
遇到未处理的异常,线程会崩溃,并打印异常信息
c.submit方法
不会抛出异常,不会创建新的线程
遇到未处理的异常,线程本身不会受到影响(线程可以复用),只是将异常信息封装到返回的对象 Future 中
01.execute方法遇到未处理异常
a.代码
import java.util.concurrent.*;
public class ThreadPoolExecutorExceptionTest {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1,
1,
1000,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(100));
// 添加任务一
executor.execute(() -> {
String tName = Thread.currentThread().getName();
System.out.println("线程名:" + tName);
throw new RuntimeException("抛出异常");
});
// 添加任务二
executor.execute(() -> {
String tName = Thread.currentThread().getName();
System.out.println("线程名:" + tName);
throw new RuntimeException("抛出异常");
});
}
}
b.执行结果
从上述结果可以看出,线程池中的核心和最大线程数都为 1 的情况下,到遇到未处理的异常时,执行任务的线程却不一样
当使用 execute 方法时,如果遇到未处理的异常,会抛出未捕获的异常,并将当前线程进行销毁
02.submit方法遇到未处理异常
a.代码
import java.util.concurrent.*;
public class ThreadPoolExecutorExceptionTest {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1,
1,
1000,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(100));
// 添加任务一
Future<?> future = executor.submit(() -> {
String tName = Thread.currentThread().getName();
System.out.println("线程名:" + tName);
throw new RuntimeException("抛出异常");
});
// 添加任务二
Future<?> future2 =executor.submit(() -> {
String tName = Thread.currentThread().getName();
System.out.println("线程名:" + tName);
throw new RuntimeException("抛出异常");
});
try {
future.get();
} catch (Exception e) {
System.out.println("遇到异常:"+e.getMessage());
}
try {
future2.get();
} catch (Exception e) {
System.out.println("遇到异常:"+e.getMessage());
}
}
}
b.执行结果
从上述结果可以看出,submit 方法遇到未处理的异常时,并将该异常封装在 Future 的 get 方法中
而不会直接影响执行任务的线程,这样线程就可以继续复用了
1.23 [5]线程池请求队列满了,有新的请求进来怎么办?设置拒绝执行处理程序
00.回答
ThreadPoolExecutor类实现了setRejectedExecutionHandler方法,设置拒绝执行处理程序
目前JDK8一共有四种拒绝策略,也对应入参RejectedExecutionHandler的四种子类实现
01.四种策略
AbortPolicy:默认的拒绝策略,直接抛出RejectedExecutionException异常
CallerRunsPolicy:直接在execute方法的调用线程中运行被拒绝的任务
DiscardPolicy:直接丢弃被拒绝的任务
DiscardOldestPolicy:丢弃最旧的未处理请求,然后重试execute
02.注意事项
如果线程池拒绝策略设置为DiscardOldestPolicy,线程池的请求队列类型最好不要设置为优先级队列PriorityBlockingQueue
因为该拒绝策略是丢弃最旧的请求,也就意味着丢弃优先级最高的请求
1.24 [6]不要把锁加在事务内
00.汇总
为了避免并发,增加分布式锁,并且会采用一锁、二判、三更新的方式实现一个幂等的逻辑
01.锁加在事务内
a.代码
@Transactional(rollbackFor = Exception.class)
public boolean register(Request request) {
RLock lock = redisson.getLock(request.getIdentifier());
try {
//一锁
lock.lock();
//二查
User user = userMapper.find(request.getIdentifier());
if (user != null) {
return false;
}
//三更新,保存订单数据
userMapper.insertOrder(request);
} finally {
lock.unlock();
}
return true;
}
b.按照这个顺序执行的
进入事务
加锁
解锁
事务提交
c.出现问题
这时候就会出现一种情况,在第三步和第四步中间,如果有一个其他的线程也调用这个 register 方法了
那么就会出现一个问题,锁已经释放了,但是事务还没提交。这时候其他的线程在并发请求过来的时候:
一锁:拿锁可以拿到,因为锁被释放了
二查:查询数据也查不到,因为这时候之前的那个事务可能还没提交,未提交的数据,新的事务是看不到的
三更新:执行更新操作,导致数据重复或者报错
d.解决问题
a.说明
这就是我们需要解决的问题,那么看上去就是事务的切面执行顺序的问题,我们应该让锁的粒度大于事务的粒度就能解决了这个问题了
那么,就想办法让分布式锁的注解的切面先执行
解决办法就是借助@Order注解,可以直接用在切面类上,用于指定切面的执行顺序。值越小,优先级越高,切面会越早执行
b.修改后的分布式锁的切面类如下
@Aspect
@Component
// 新增 Order 注解,把他的优先级设置为最小值,即优先级最高,最先开始执行即可
@Order(Integer.MIN_VALUE)
public class DistributeLockAspect {
private RedissonClientt redissonClient
c.总结
在使用分布式锁的时候,习惯性的尽量缩小同步代码块的范围
-----------------------------------------------------------------------------------------------------
但是如果数据库隔离级别是可重复读,这种情况下不要把分布式锁加在@Transactional注解的事务方法内部
因为可能会出现这种情况:
线程1开启事务A后获取分布式锁,执行业务代码后在事务内释放了分布式锁
这时候线程1开启了事务B获取到了线程1释放的分布式锁,执行查询操作时查到的数据就可能出现问题
因为此时事务A是在事务内释放了锁,事务A本身还没有完成提交
02.锁加在事务外
a.说明
锁和事务的顺序可能导致并发问题,因为锁在事务提交之前就已经释放了
为了避免这种情况,可以考虑将锁的范围扩大到事务的外部,这样可以确保在事务提交之前,其他线程无法获取锁
b.代码
@Transactional(rollbackFor = Exception.class)
public boolean register(Request request) {
RLock lock = redisson.getLock(request.getIdentifier());
// 一锁:在事务外部加锁
lock.lock();
try {
// 事务在方法开始时已经开启
// 二查:在事务内查询
User user = userMapper.find(request.getIdentifier());
if (user != null) {
return false;
}
// 三更新:在事务内更新
userMapper.insertOrder(request);
} finally {
// 解锁:在事务外部解锁
lock.unlock();
}
// 事务在方法正常返回时提交
return true;
}
c.说明
@Transactional 注解用于声明方法或类的事务性
事务的开始和结束是由 Spring 的事务管理器来控制的,而不是由 try-catch 块来决定的
因此,即使锁的获取是在 try 块之外,事务仍然会在方法调用时开始,并在方法返回或抛出异常时结束
d.事务的控制
事务开始:当方法被调用时,Spring 的事务管理器会在方法执行之前开启一个事务
事务提交:如果方法正常返回(没有抛出异常),事务管理器会提交事务
事务回滚:如果方法抛出一个被 rollbackFor 属性指定的异常,事务管理器会回滚事务
e.代码说明
在你的代码中,事务的控制与锁的控制是独立的:
锁的控制:通过 RLock 来实现,锁的获取和释放是由 lock.lock() 和 lock.unlock() 控制的
事务的控制:由 @Transactional 注解控制,事务在方法开始时开启,在方法结束时提交或回滚
f.注意事项
锁的获取和释放:确保在 try-finally 块中正确地获取和释放锁,以避免死锁
事务的传播属性:如果方法被其他事务性方法调用,事务的传播属性可能会影响事务的行为
异常处理:确保 rollbackFor 属性正确配置,以便在需要时回滚事务
1.25 [6]T1、T2、T3线程顺序执行
00.汇总
join()
CountDownLatch
LockSupport
CompletableFuture
Semaphore
单线程池
synchronized
01.join()
a.说明
可以在每个线程内部使用 join() 方法来等待前一个线程执行完成
具体操作是在线程 T2 的 run() 方法中调用 T1.join(),在线程 T3 的 run() 方法中调用 T2.join()
这样可以确保 T1 在 T2 之前执行,T2 在 T3 之前执行
b.代码
Thread T1 = new Thread(() -> {
// 线程 T1 的任务
});
Thread T2 = new Thread(() -> {
try {
T1.join(); // 等待 T1 执行完成
} catch (InterruptedException e) {
e.printStackTrace();
}
// 线程 T2 的任务
});
Thread T3 = new Thread(() -> {
try {
T2.join(); // 等待 T2 执行完成
} catch (InterruptedException e) {
e.printStackTrace();
}
// 线程 T3 的任务
});
T1.start();
T2.start();
T3.start();
c.代码
Thread t1 = new Thread(() -> {
// 线程T1的任务
});
Thread t2 = new Thread(() -> {
// 线程T2的任务
});
Thread t3 = new Thread(() -> {
// 线程T3的任务
});
t1.start();
t1.join(); // 等待t1完成
t2.start();
t2.join(); // 等待t2完成
t3.start();
t3.join(); // 等待t3完成
02.CountDownLatch
a.说明
可以使用 CountDownLatch 来控制线程的执行顺序。创建一个 CountDownLatch 对象,设置初始计数为 2
分别在 T1 和 T2 的线程内等待计数器减少到 0,然后释放 T3 线程
b.代码
CountDownLatch latch1 = new CountDownLatch(1);
CountDownLatch latch2 = new CountDownLatch(1);
Thread t1 = new Thread(() -> {
System.out.println("T1 running.");
latch1.countDown(); // T1 执行完后释放 latch1
});
Thread t2 = new Thread(() -> {
try {
latch1.await(); // 等待 latch1 的释放
System.out.println("T2 running.");
latch2.countDown(); // T2 执行完后释放 latch2
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t3 = new Thread(() -> {
try {
latch2.await(); // 等待 latch2 的释放
System.out.println("T3 running.");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
t3.start();
03.LockSupport
a.说明
使用LockSupport的park和unpark来控制线程的执行顺序
b.代码
public class Test {
private static Thread t1;
private static Thread t2;
private static Thread t3;
public static void main(String[] args) {
t1 = new Thread(() -> {
System.out.println("T1 is running.");
LockSupport.unpark(t2); // 唤醒线程T2
});
t2 = new Thread(() -> {
LockSupport.park(); // 阻塞线程T2
System.out.println("T2 is running.");
LockSupport.unpark(t3); // 唤醒线程T3
});
t3 = new Thread(() -> {
LockSupport.park(); // 阻塞线程T3
System.out.println("T3 is running.");
});
t1.start();
t2.start();
t3.start();
}
}
04.CompletableFuture
a.说明
假设我们现在有三个任务T1、T2、T3需要按序执行
b.代码
CompletableFuture.runAsync(()->{do t1 sth})
.thenRun(()->{do t2 sth})
.thenRun(()->{do t3 sth});
c.代码
import java.util.concurrent.CompletableFuture;
public class CompletableFutureSequentialExecution {
public static void main(String[] args) {
// 创建第一个任务T1
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("T1 is running on thread: " + Thread.currentThread().getName());
// 模拟任务运行
sleep(1000);
});
// 链接任务T2到T1之后
future = future.thenRunAsync(() -> {
System.out.println("T2 is running on thread: " + Thread.currentThread().getName());
sleep(1000);
});
// 链接任务T3到T2之后
future = future.thenRunAsync(() -> {
System.out.println("T3 is running on thread: " + Thread.currentThread().getName());
sleep(1000);
});
// 等待所有任务完成
future.join();
}
// 辅助方法用于模拟延迟
private static void sleep(long milliseconds) {
try {
Thread.sleep(milliseconds);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
05.Semaphore
a.说明
Semaphore通过一个计数器来管理许可,计数器的初始值由构造函数指定,表示可用许可的数量
线程可以通过调用acquire()方法请求许可,如果许可可用则授予访问权限,否则线程将阻塞
使用完资源后,线程调用release()方法释放许可,从而允许其他阻塞的线程获取许可
b.代码
Semaphore semaphore1 = new Semaphore(0);
Semaphore semaphore2 = new Semaphore(0);
Thread t1 = new Thread(() -> {
// 线程T1的任务
semaphore1.release(); // 释放一个许可
});
Thread t2 = new Thread(() -> {
try {
semaphore1.acquire(); // 获取许可,等待T1完成
// 线程T2的任务
semaphore2.release(); // 释放一个许可
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread t3 = new Thread(() -> {
try {
semaphore2.acquire(); // 获取许可,等待T2完成
// 线程T3的任务
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
t1.start();
t2.start();
t3.start();
c.说明
Semaphore(int permits) :构造一个具有给定许可数的Semaphore
Semaphore(int permits, boolean fair) :构造一个具有给定许可数的Semaphore,并指定是否是公平的。公平性指的是线程获取许可的顺序是否是先到先得
void acquire() :获取一个许可,如果没有可用许可,则阻塞直到有许可可用
void acquire(int permits) :获取指定数量的许可
void release() :释放一个许可
void release(int permits) :释放指定数量的许可
int availablePermits() :返回当前可用的许可数量
boolean tryAcquire() :尝试获取一个许可,立即返回true或false
boolean tryAcquire(long timeout, TimeUnit unit) :在给定的时间内尝试获取一个许可
06.单线程池
a.说明
单线程池(Executors.newSingleThreadExecutor())可以确保任务按提交顺序依次执行
所有任务都会在同一个线程中运行,保证了顺序性
b.代码
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(new T1());
executor.submit(new T2());
executor.submit(new T3());
executor.shutdown();
07.synchronized
a.说明
synchronized 是Java中的一个关键字,用于实现线程同步,确保多个线程对共享资源的访问是互斥的
它通过锁机制来保证同一时刻只有一个线程可以执行被Synchronized保护的代码块,从而避免数据不一致和线程安全问题
b.代码
class Task {
synchronized void executeTask(String taskName) {
System.out.println(taskName + " 执行");
}
}
public class Main {
public static void main(String[] args) {
Task task = new Task();
new Thread(() -> task.executeTask("T1")).start();
new Thread(() -> task.executeTask("T2")).start();
new Thread(() -> task.executeTask("T3")).start();
}
}
1.26 [6]为什么要使用Executor线程池?
01.为什么要使用Executor线程池框架呢?
a.性能和资源利用
每次执行任务都通过new Thread()去创建线程,比较消耗性能,创建一个线程是比较耗时、耗资源的
线程池通过复用线程来减少频繁创建和销毁线程的开销,提高性能和资源利用率
b.线程管理
调用new Thread()创建的线程缺乏管理,可以无限制地创建,线程之间的相互竞争会导致过多占用系统资源而导致系统瘫痪
线程池可以限制同时运行的线程数量,避免系统资源被过多的线程占用,提高系统的稳定性
c.扩展性
直接使用new Thread()启动的线程不利于扩展,比如定时执行、定期执行、定时定期执行、线程中断等都不好实现
Executor框架提供了丰富的功能,如定时执行、定期执行、延迟执行、任务取消等,方便开发者实现复杂的并发任务
1.27 [6]线程池异步拒绝异常RejectedExecutionException
00.总结
a.根本原因
线程池队列容量不足,导致任务被拒绝
b.最直接的解决方案
增大 queueCapacity
c.更优的解决方案
使用 Semaphore 限制并发任务数
按批次执行,避免瞬间提交大量任务
01.问题描述
a.测试环境报错
使用 ThreadPoolExecutor 执行异步任务时,测试环境报错:
java.util.concurrent.RejectedExecutionException: task java.util.concurrent.FutureTask@1e19e316 rejected
from java.util.concurrent.ThreadPoolExecutor@647b9364[running, pool size = 12, active threads = 12,
queued tasks = 32, completed tasks = 44]
b.本地运行正常
本地运行正常,但测试环境会抛出 RejectedExecutionException
02.原因分析
a.代码分析
List<List<String>> partitionedIds = Lists.partition(externalUserIds, 100);
List<CompletableFuture<List<ExternalUserRecord>>> futureList = partitionedIds.stream()
.map(batch -> CompletableFuture.supplyAsync(
() -> externalUserRecordService.batchGetExternalUserRecord(batch), executor))
.collect(Collectors.toList());
b.导致问题的核心点
externalUserIds 被 按 100 个一组 分批
例如 externalUserIds 有 5000 条数据,则会被拆分成 50 组
每一组都会提交一个异步任务,导致线程池可能同时提交 50 个任务
线程池的队列默认最大是 32,一旦超出,则会抛 RejectedExecutionException
c.本地与测试环境的区别
本地数据量小(如 externalUserIds 只有 300 条,分批后仅 3 组任务)
测试环境数据量大(可能 externalUserIds 有上万条数据,任务数远超 32)
03.解决方案
a.方案 1:增加队列容量(当前采用的解决方案)
在 ThreadPoolExecutor 配置中,将 queueCapacity 从 32 提高到 10000:
-----------------------------------------------------------------------------------------------------
private static final int QUEUE_CAPACITY = 10000;
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(CORE_POOL_SIZE);
threadPoolTaskExecutor.setMaxPoolSize(MAX_POOL_SIZE);
threadPoolTaskExecutor.setKeepAliveSeconds(KEEP_ALIVE_SECONDS);
threadPoolTaskExecutor.setQueueCapacity(QUEUE_CAPACITY);
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolTaskExecutor.setThreadFactory(new CustomizableThreadFactory("excellent-mall-pool-thread-"));
threadPoolTaskExecutor.initialize();
return threadPoolTaskExecutor;
}
-----------------------------------------------------------------------------------------------------
优点:避免任务被拒绝,保证所有任务都能执行
缺点:任务全部排队,可能导致等待时间过长
b.方案 2:限制并发任务数
使用 Semaphore 控制 同时执行的任务数,避免一次性提交过多任务:
-----------------------------------------------------------------------------------------------------
Semaphore semaphore = new Semaphore(10); // 限制最大并发任务数
List<CompletableFuture<List<ExternalUserRecord>>> futureList = partitionedIds.stream()
.map(batch -> CompletableFuture.supplyAsync(() -> {
try {
semaphore.acquire(); // 获取许可
return externalUserRecordService.batchGetExternalUserRecord(batch);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return Collections.emptyList();
} finally {
semaphore.release(); // 释放许可
}
}, executor))
.collect(Collectors.toList());
-----------------------------------------------------------------------------------------------------
优点:控制最大并发任务数,防止线程池超负荷
缺点:如果任务过多,可能会影响整体执行速度
c.方案 3:分批执行,避免一次性提交所有任务
改为 按批次执行,等待前一批执行完,再提交下一批:
-----------------------------------------------------------------------------------------------------
for (List<String> batch : partitionedIds) {
List<CompletableFuture<List<ExternalUserRecord>>> futureList = batch.stream()
.map(ids -> CompletableFuture.supplyAsync(
() -> externalUserRecordService.batchGetExternalUserRecord(ids), executor))
.collect(Collectors.toList());
// 等待本批任务执行完再提交下一批
futureList.forEach(CompletableFuture::join);
}
-----------------------------------------------------------------------------------------------------
优点:不会一次性提交所有任务,降低线程池压力
缺点:任务可能整体执行时间稍长
2 Thread
2.1 [1]周期:5个
01.转换图
a.图示
«New» 新创建
└── 1. 调用start()方法
└── «Runnable» 可运行/就绪
├── 2. 线程获得CPU时间片
│ └── «Running» 运行中
│ ├── 3. 线程没有运行完run方法,CPU时间片用完
│ └── 6. 线程运行完run方法
│ └── «Dead» 死亡
└── 5. 等待结束
└── «Blocked» 等待/阻塞/睡眠
├── 4. 阻塞等待锁,等待用户输入,调用sleep()方法,调用join等待其他线程等情况
└── 返回«Runnable» 可运行/就绪
b.说明
1.新建,New
2.运行,Runnable
3.阻塞,Blocked
4.无限期等待,Waiting
5.限期等待,Time Waiting
6.结束,Terminated
02.生命周期
a.说明
1.创建
2.就绪 只缺CPU资源 一切准备就绪,只等CPU分配
3.运行 不仅有CPU资源,而且有其他资源,此时会发生四种状态
①正常死亡
②缺少某个硬件资源·>阻塞·>归还硬件资源,回到“就绪状态”
③要访问的某个变量/方法被上锁->对象锁池中的阻塞·>放行,回到“就绪状态”
④被调用wait0睡眠->对象等待池的阻塞->notifyl睡醒发现排队->放行,回到“就绪状态”
4.阻塞 不仅缺CPU资源,而且缺其他资源
5.死亡
b.线程阻塞:3种
等待阻塞:Object.wait -> 等待队列
同步阻塞:lock -> 锁池
其他阻塞:sleep/join
c.线程死亡:3种
正常结束
异常结束
调用stop()
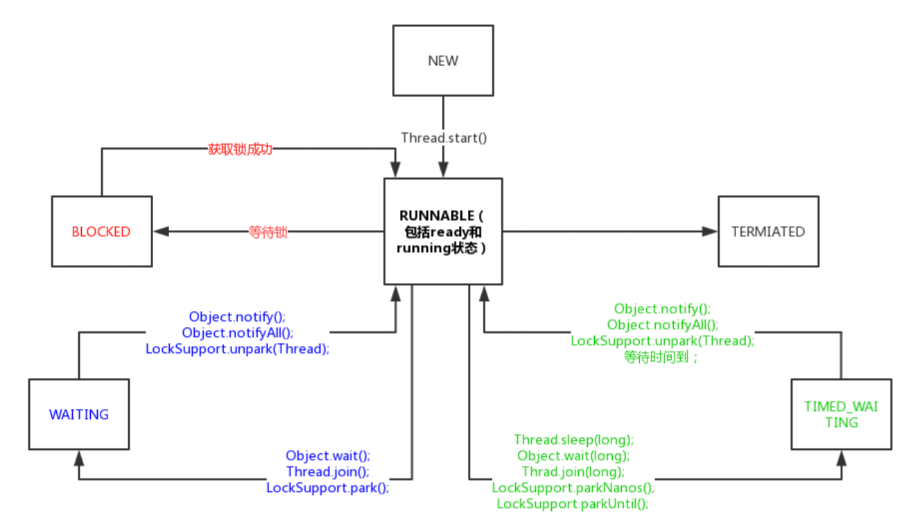
2.2 [1]状态:6个
00.汇总
NEW 新建 创建线程,但还未调用 start() 方法
RUNNABLE 可运行 就绪和运行两种状态统称 “运行中”
BLOCKED 阻塞 表示线程阻塞于锁
WAITING 无限期等待 线程进行等待状态,进入该状态表示当前线程需要等待其他线程做出通知或中断
TIME_WAITING 限期等待 不同于WAITING,经过指定时间后可以自行返回
TERMINATED 死亡 表示线程执行完毕
01.NEW
a.介绍
初始状态
b.说明
当一个线程对象被创建时,它处于NEW状态。此时线程尚未开始执行,start()方法尚未被调用。
02.RUNNABLE
a.介绍
可执行状态
b.说明
线程处于RUNNABLE状态时,表示它可以被执行
此状态包括“就绪ready”和“运行running”两种状态,线程可能正在运行,也可能在等待CPU调度
03.BLOCKED
a.介绍
阻塞状态
b.说明
当一个线程试图获取一个已经被其他线程持有的锁时,它会进入BLOCKED状态。此时线程无法继续执行,直到获得锁
c.例子
假如今天你下班后准备去食堂吃饭。你来到食堂仅有的一个窗口,发现前面已经有个人在窗口前了,此时你必须得等前面的人从窗口离开才行
假设你是线程 t2,你前面的那个人是线程 t1。此时 t1 占有了锁(食堂唯一的窗口),t2 正在等待锁的释放,所以此时 t2 就处于 BLOCKED 状态
04.WAITING
a.介绍
等待状态
b.说明
线程进入WAITING状态时,表示它正在等待其他线程的通知或中断。
此状态通常通过调用Object.wait()、Thread.join()或LockSupport.park()等方法进入
c.调用下面这3个方法会使线程进入等待状态
Object.wait():使当前线程处于等待状态直到另一个线程唤醒它
Thread.join():等待线程执行完毕,底层调用的是 Object 的 wait 方法
LockSupport.park():除非获得调用许可,否则禁用当前线程进行线程调度
05.TIME_WAITING
a.介绍
超时等待状态
b.说明
与WAITING状态不同,TIME_WAITING状态的线程在经过指定的时间后会自动返回
线程可以通过调用Thread.sleep(millis)、Object.wait(millis)或Thread.join(millis)等方法进入此状态
c.调用如下方法会使线程进入超时等待状态
Thread.sleep(long millis):使当前线程睡眠指定时间
Object.wait(long timeout):线程休眠指定时间,等待期间可以通过notify()/notifyAll()唤醒
Thread.join(long millis):等待当前线程最多执行 millis 毫秒,如果 millis 为 0,则会一直执行
LockSupport.parkNanos(long nanos): 除非获得调用许可,否则禁用当前线程进行线程调度指定时间
LockSupport.parkUntil(long deadline):同上,也是禁止线程进行调度指定时间
06.TERMINATED
a.介绍
终止状态
b.说明
当线程的run()方法执行完毕,或者由于异常终止时,线程进入TERMINATED状态
此时线程已经完成了所有的工作,无法再被启动
2.3 [1]状态:转换
01.BLOCKED、RUNNABLE
a.BLOCKED 到 RUNNABLE
当一个线程试图进入一个被其他线程持有的同步块或同步方法时,它会进入 BLOCKED 状态
一旦持有锁的线程释放锁,BLOCKED 状态的线程将被唤醒并进入 RUNNABLE 状态,等待 CPU 调度执行
b.RUNNABLE 到 BLOCKED
当一个线程试图进入一个被其他线程持有的同步块或同步方法时,它会从 RUNNABLE 状态转换到 BLOCKED 状态
02.WAITING、RUNNABLE
a.WAITING 到 RUNNABLE
当其他线程调用 Object.notify() 或 Object.notifyAll() 方法,或者调用 Thread.interrupt() 方法中断该线程时,WAITING 状态的线程将被唤醒并进入 RUNNABLE 状态
b.RUNNABLE 到 WAITING
当一个线程调用 Object.wait()、Thread.join() 或 LockSupport.park() 方法时,它会从 RUNNABLE 状态转换到 WAITING 状态
03.TIMED_WAITING、RUNNABLE
a.TIMED_WAITING 到 RUNNABLE
当超时时间到达,或者其他线程调用 Object.notify()、Object.notifyAll() 方法,或者调用 Thread.interrupt() 方法中断该线程时,TIMED_WAITING 状态的线程将被唤醒并进入 RUNNABLE 状态
b.RUNNABLE 到 TIMED_WAITING
当一个线程调用带有超时参数的 Object.wait(long timeout)、Thread.join(long millis) 或 LockSupport.parkNanos(long nanos)、LockSupport.parkUntil(long deadline) 方法时,它会进入 TIMED_WAITING 状态
04.线程中断
a.介绍
线程中断是指通过调用 Thread.interrupt() 方法来请求中断一个线程
中断机制允许一个线程请求另一个线程停止其当前的操作并尽快退出
b.中断标志
每个线程都有一个中断标志,用于表示线程是否被中断
调用 Thread.interrupt() 方法会设置线程的中断标志
c.检查中断状态
Thread.interrupted(): 检查当前线程的中断状态,并清除中断标志
Thread.isInterrupted(): 检查线程的中断状态,但不清除中断标志
d.处理中断
当一个线程在调用 Object.wait()、Thread.join() 或 Thread.sleep() 方法时被中断,会抛出 InterruptedException 异常
线程可以在捕获 InterruptedException 异常时进行适当的处理,如清理资源、记录日志等
2.4 [1]常用API:3类
01.基本属性和状态管理
getId 获取线程的唯一标识符(ID)
getName 和 setName 获取和设置线程的名称
getPriority 和 setPriority 获取和设置线程的优先级,范围从1到10,默认值为5
setDaemon 和 isDaemon 设置线程是否为守护线程和判断线程是否是守护线程。守护线程在所有非守护线程结束时自动终止
getState 获取线程的当前状态(NEW、RUNNABLE、BLOCKED、WAITING、TIME_WAITING、TERMINATED)
isAlive 判断线程是否还在运行
02.线程控制和中断
join 等待线程终止,调用线程会等待被调用线程执行完毕后再继续执行
interrupt 和 isInterrupted 中断线程和判断线程是否被中断
interrupted 静态方法,检查当前线程是否被中断,并清除中断状态
sleep 静态方法,使当前线程休眠指定的毫秒数
yield 静态方法,让当前线程让出CPU时间片,使其他线程有机会执行
03.线程上下文和异常处理
currentThread 静态方法,获取当前正在执行的线程对象
getContextClassLoader 获取线程的上下文类加载器
setContextClassLoader 设置线程的上下文类加载器
getUncaughtExceptionHandler 获取线程的未捕获异常处理器
setUncaughtExceptionHandler 设置线程的未捕获异常处理器
checkAccess 检查当前线程是否有权限修改该线程
04.代码示例
public class ThreadAttributesDemo {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
System.out.println("Thread is running.");
});
// 设置线程名称
thread.setName("DemoThread");
System.out.println("Thread Name: " + thread.getName());
// 设置线程优先级
thread.setPriority(Thread.MAX_PRIORITY);
System.out.println("Thread Priority: " + thread.getPriority());
// 设置守护线程
thread.setDaemon(true);
System.out.println("Is Daemon: " + thread.isDaemon());
// 获取线程ID
System.out.println("Thread ID: " + thread.getId());
// 获取线程状态
System.out.println("Thread State: " + thread.getState());
// 启动线程
thread.start();
// 检查线程是否存活
System.out.println("Is Alive: " + thread.isAlive());
// 等待线程终止
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取线程状态
System.out.println("Thread State after join: " + thread.getState());
}
}
2.5 [1]start/run、yield/join、wait/notify/notifyAll、sleep/wait、setDaemon、interrupted
01.start、run
a.start
start()方法:启动线程,真正实现多线程运行
启动线程,然后由JVM调用此线程的run()方法
调用start()后,线程进入就绪状态,等待CPU调度。一旦被调度,线程会在后台执行run()方法中的代码,无需等待其他线程的执行完成
b.run
run()方法:线程体,线程执行的实际代码
封装线程执行的代码,直接调用相当于调用普通方法
如果直接调用run()方法,不会创建新线程,线程将在当前线程中执行,进入运行状态,直到run()方法结束,线程终止,CPU再调度其他线程
c.为什么重写run方法
默认的run()方法不会做任何事情
02.yield、join
a.yield,静态方法
a.调用
让当前线程交出CPU权限,让CPU去执行其他的线程
仅仅是一种尽可能事件,并不一定会100%执行
b.代码
class YieldExample {
public static void main(String[] args) {
Thread thread1 = new Thread(YieldExample::printNumbers, "刘备");
Thread thread2 = new Thread(YieldExample::printNumbers, "关羽");
thread1.start();
thread2.start();
}
private static void printNumbers() {
for (int i = 1; i <= 5; i++) {
System.out.println(Thread.currentThread().getName() + ": " + i);
// 当 i 是偶数时,当前线程暂停执行
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + " 让出控制权...");
Thread.yield();
}
}
}
}
b.join
a.调用
会等待被调用线程执行完毕,阻塞当前正在执行的线程,实际上调用join()方法是调用了Object的wait()方法
等待这个线程执行完才会轮到后续线程得到cpu的执行权,使用这个也要捕获异常
b.代码
//创建MyRunnable类
MyRunnable mr = new MyRunnable();
//创建Thread类的有参构造,并设置线程名
Thread t1 = new Thread(mr, "张飞");
Thread t2 = new Thread(mr, "貂蝉");
Thread t3 = new Thread(mr, "吕布");
//启动线程
t1.start();
try {
t1.join(); //等待t1执行完才会轮到t2,t3抢
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
t3.start();
03.wait、notify、notifyAll
a.相同点
必须都在synchronized中定义
b.不同点
wait【自己】:使当前线程进入等待状态(阻塞),直到其他线程调用此对象的 notify 或 notifyAll 方法
notify【别人】:唤醒一个正在等待的线程;如果有多个线程正在等待,则随机唤醒一个
notifyAll【别人】:唤醒全部正在等待的线程
04.sleep、wait/yield/join
a.sleep、wait
a.sleep
属于 Thread 类
在调用 sleep() 方法的过程中,线程不会释放对象锁
暂停执行指定的时间,让出 CPU 给其他线程,但其监控状态依然保持,在指定的时间过后会自动恢复运行状态
a.wait
属于 Object 类
在调用 wait() 方法的过程中,线程会释放对象锁,直到其他线程调用此对象的 notify 或 notifyAll 方法
线程进入等待状态,暂停执行,直到被唤醒
b.sleep、wait
a.从名称上来讲
awit:等待
sleep:休眠
b.从属关系上来讲
awit:awit这个方法是在对象上,只要是对象,就有这个方法
sleep:sleep是在Thread上,它是在线程上,是一个静态方法
c.使用方式上来讲
awit:只能够在同步代码中去使用
sleep:可以在任意的地方中去使
d.从阻塞时间上来讲
awit:需要等待别人。如果别人没有执行完,它是不能够干其他的事情的。它会有一个超时时间,什么是超时时间呢?我等待的时间太长了,时间太长了, 我就不能够再等待了。这个时候就会发生异常。会有异常
sleep:它会有一个休眠时间,这个休眠时间不会有任何的问题。休眠完一定的时间,它自己就会醒过来。不会有异常
e.同步处理
awit:如果执行awit方法,其他线程会有机会执行当前的同步操作
sleep:如果执行sleep方法,那么其他线程没有机会执行当前的同步操作
c.sleep、yield
sleep() 方法给其他线程运行机会时不考虑线程的优先级;yield() 方法只会给相同优先级或更高优先级的线程运行的机会
sleep() 方法声明抛出 InterruptedException;yield() 方法没有声明抛出异常
线程执行 sleep() 方法后进入超时等待状态;线程执行 yield() 方法转入就绪状态,可能马上又得得到执行
sleep() 方法需要指定时间参数;yield() 方法出让 CPU 的执行权时间由 JVM 控制
d.sleep、join
JDK1.8 sleep() join() 均需要捕获 InterruptedException 异常
sleep()是Thread的静态本地方法,join()是Thread的普通方法
sleep()不会释放锁资源,join()底层是wait方法,会释放锁
05.setDaemon
a.说明
将此线程标记为守护线程,准确来说,就是服务其他的线程,像Java中的垃圾回收线程,就是典型的守护线程
b.代码
//创建MyRunnable类
MyRunnable mr = new MyRunnable();
//创建Thread类的有参构造,并设置线程名
Thread t1 = new Thread(mr, "张飞");
Thread t2 = new Thread(mr, "貂蝉");
Thread t3 = new Thread(mr, "吕布");
t1.setDaemon(true);
t2.setDaemon(true);
//启动线程
t1.start();
t2.start();
t3.start();
c.分析
如果其他线程都执行完毕,main 方法(主线程)也执行完毕,JVM 就会退出,也就是停止运行
如果 JVM 都停止运行了,守护线程自然也就停止了
06.interrupted
a.说明
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作
那么调用线程的 interrupt() 方法就无法使线程提前结束
b.注意
调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true
因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程
99.代码示例
a.代码
class SharedResource {
private final Object lock = new Object();
private boolean isNotified = false;
public void waitForNotification() {
synchronized (lock) {
while (!isNotified) {
try {
System.out.println(Thread.currentThread().getName() + " is waiting.");
lock.wait(); // 线程进入等待状态
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
System.out.println(Thread.currentThread().getName() + " is notified.");
isNotified = false; // 重置状态
}
}
public void notifyOne() {
synchronized (lock) {
isNotified = true;
lock.notify(); // 唤醒一个等待的线程
System.out.println(Thread.currentThread().getName() + " notified one thread.");
}
}
public void notifyAllThreads() {
synchronized (lock) {
isNotified = true;
lock.notifyAll(); // 唤醒所有等待的线程
System.out.println(Thread.currentThread().getName() + " notified all threads.");
}
}
}
class WorkerThread extends Thread {
private final SharedResource resource;
public WorkerThread(SharedResource resource) {
this.resource = resource;
}
@Override
public void run() {
// 使用yield()方法
if (Thread.currentThread().getName().equals("Thread-1")) {
System.out.println(Thread.currentThread().getName() + " is yielding.");
Thread.yield(); // 让出CPU
}
// 使用wait()方法
resource.waitForNotification();
// 使用sleep()方法
try {
System.out.println(Thread.currentThread().getName() + " is sleeping for 2 seconds.");
Thread.sleep(2000); // 休眠2秒
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
System.out.println(Thread.currentThread().getName() + " has finished execution.");
}
}
public class ThreadDemo {
public static void main(String[] args) throws InterruptedException {
SharedResource resource = new SharedResource();
WorkerThread thread1 = new WorkerThread(resource);
WorkerThread thread2 = new WorkerThread(resource);
WorkerThread thread3 = new WorkerThread(resource);
thread1.start(); // 启动线程1
thread2.start(); // 启动线程2
thread3.start(); // 启动线程3
// 使用join()方法
thread1.join(); // 等待线程1完成
thread2.join(); // 等待线程2完成
thread3.join(); // 等待线程3完成
// 使用notify()和notifyAll()方法
resource.notifyAllThreads(); // 唤醒所有等待的线程
}
}
b.说明
a.SharedResource类:包含一个锁对象和一个状态标志,用于管理线程的等待和通知
waitForNotification() 方法使用 wait() 使当前线程进入等待状态,直到被其他线程唤醒
notifyOne() 和 notifyAllThreads() 方法分别用于唤醒一个或所有等待的线程
n.WorkerThread类:继承自 Thread,在 run() 方法中实现了线程的主要逻辑
使用 yield() 方法让出CPU
调用 waitForNotification() 方法等待通知
使用 sleep() 方法暂停执行2秒
c.ThreadDemo类:主类,创建多个 WorkerThread 实例并启动它们
使用 join() 方法等待所有线程完成
最后调用 notifyAllThreads() 方法唤醒所有等待的线程
2.6 [1]volatile、synchronized、reentrantLock
00.汇总
a.图示
| 特性/功能 | volatile | synchronized | ReentrantLock
|------------|---------------------|-------------------------------|--------------------------------
| 作用 | 保证变量的可见性 | 保证代码块或方法的原子性和可见性 | 保证代码块的原子性和可见性
| 使用级别 | 变量级别 | 变量、方法、类级别 | 代码块级别
| 原子性 | 不保证 | 保证 | 保证
| 可见性 | 保证 | 保证 | 保证
| 线程阻塞 | 不会 | 可能会导致线程阻塞 | 可能会导致线程阻塞
| 锁机制 | 无锁 | 内置锁(JVM实现) | 显式锁(需手动获取和释放)
| 重入性 | 不适用 | 支持 | 支持
| 超时获取锁 | 不适用 | 不支持 | 支持
| 公平性 | 不适用 | 非公平 | 支持公平锁和非公平锁
| 中断响应 | 不适用 | 不可中断 | 可中断
| 条件变量 | 不适用 | 不支持 | 支持条件变量
| 性能 | 较高(无锁开销) | 较高(现代JVM优化后) | 较高(灵活控制)
| 适用场景 | 简单状态标志或配置项 | 简单同步需求 | 复杂同步需求,需高级功能
b.说明
volatile:适用于简单的状态标志,保证可见性,不保证原子性
synchronized:适用于简单的同步需求,保证原子性和可见性,自动管理锁
ReentrantLock:适用于复杂的同步需求,提供更多高级功能,手动管理锁
c.说明
volatile 1.【保证变量可见性】
2.【防止局部重排序】
synchronized 1.【保证代码块或方法的原子性和可见性】
2.【保证同一时刻只有一个线程能执行被 synchronized 修饰的代码块或方法】
ReentrantLock 1.【显式锁】,需要【手动获取和释放锁】,支持【可重入】
01.volatile
a.定义
1.【保证变量可见性】
2.【防止局部重排序】
b.特性
不保证原子性,不会引起线程阻塞
c.使用场景
适用于状态标志等简单的读写操作,不适用于复合操作(如自增、自减)
d.性能
开销较小,因为不会引起线程上下文切换
e.示例
public class VolatileExample {
private volatile boolean flag = true;
public void setFlag(boolean flag) {
this.flag = flag;
}
public boolean getFlag() {
return flag;
}
}
02.synchronized
a.定义
1.【保证代码块或方法的原子性和可见性】
2.【保证同一时刻只有一个线程能执行被 synchronized 修饰的代码块或方法】
b.作用范围
synchronize作用于成员变量和非静态方法时,锁住的是对象的实例,即this对象
synchronize作用于静态方法时,锁住的是Class实例
synchronize作用于一个代码块时,锁住的是所有代码块中配置的对象
c.实现原理
Synchronized的原理其实就是基于一个锁对象和锁对象相关联的一个monitor对象。
在偏向锁和轻量级锁的时候只需要利用CAS来操控锁对象头即可完成加解锁动作。
在升级为重量级锁之后还需要利用monitor对象,利用CAS和mutex来作为底层实现。
monitor对象题部会有等待队列和条件等待队列,未竞争到锁的线程存储到等待队列中,获得锁的线程调用wit后便存放在条件等待队列中,解锁和
notify都会唤醒相应队列中的等待线程来争抢锁。
然后由于阻塞和唤醒依赖于底层的操作系统实现,系统调用存在用户态与内核态之间的切换,所以有较高的开销,因此称之为重量级锁。
所以才会有偏向锁和轻量级锁的优化,并且引入自适应自旋机制,来提高锁的性能。
d.特性
是Java内置的锁机制,自动释放锁,支持可重入
e.使用场景
适用于需要确保线程安全的代码块或方法,适合简单的同步需求
f.性能
开销较大,因为会引起线程上下文切换,适用于竞争不激烈的场景
g.示例
public class SynchronizedExample {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
03.ReentrantLock
a.作用
提供与synchronized相同的锁功能,但更灵活
显式锁,需要【手动获取和释放锁】,支持可重入,提供了更多高级功能(如公平锁、可中断锁、条件变量)
b.场景
适用于需要高级功能的复杂同步需求,如需要尝试获取锁、超时获取锁、多个条件变量等
c.性能
开销较大,但在高竞争场景下性能优于 synchronized,因为提供了更细粒度的控制
d.示例
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
2.7 [2]创建:4类
00.汇总
1.继承Thread类
2.实现Runnable接口
3.实现Callable接口并结合Future
4.使用Lambda表达式(匿名内部类)
01.继承Thread类
a.说明
通过继承 Thread 类,并重写它的 run 方法,我们就可以创建一个线程
首先定义一个类来继承 Thread 类,重写 run 方法
然后创建这个子类对象,并调用 start 方法启动线程
b.代码
Thread thread1 = new Thread() {
@Override
public void run() {
System.out.println("Thread is running...");
}
};
thread1.start();
02.实现Runnable接口
a.说明
通过实现 Runnable ,并实现 run 方法,也可以创建一个线程。
首先定义一个类实现 Runnable 接口,并实现 run 方法。
然后创建 Runnable 实现类对象,并把它作为 target 传入 Thread 的构造函数中
最后调用 start 方法启动线程。
用lambda表达式实现Runnable接口的run()方法
b.代码
Runnable myRunnable = new Runnable() {
@Override
public void run() {
System.out.println("Runnable is running...");
}
};
Thread thread2 = new Thread(myRunnable);
thread2.start();
04.实现Callable接口并结合Future
a.说明
首先定义一个 Callable 的实现类,并实现 call 方法。call 方法是带返回值的。
然后通过 FutureTask 的构造方法,把这个 Callable 实现类传进去。
把 FutureTask 作为 Thread 类的 target ,创建 Thread 线程对象。
通过 FutureTask 的 get 方法获取线程的执行结果。
b.代码
Callable<Integer> callableTask = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
System.out.println("Callable is running...");
// 模拟计算任务
Thread.sleep(1000);
return 42; // 返回值
}
};
// 包装 Callable 为 FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(callableTask);
Thread thread4 = new Thread(futureTask);
thread4.start();
try {
// 获取线程的执行结果
Integer result = futureTask.get();
System.out.println("Callable returned: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
04.使用Lambda表达式(匿名内部类)
a.说明
略
b.代码
Thread thread3 = new Thread(() -> {
System.out.println("Lambda thread is running...");
});
thread3.start();
2.8 [2]提交:2类
00.总结
a.说明
submit方法通过封装任务为FutureTask,封装过程中也会把Runable包装成为Callable类型
结合线程池的调度机制,实现了异步任务的提交、执行和结果管理
执行的时候就会执行FutureTask的run方法,在run方法中,会调用callable.call方法
这里面会执行最原始任务的run方法,并返回result
(如果原始任务是Runable,则result是null,若原始任务是Callable,则result为对应的泛型)
b.返回值
方法 返回值类型 说明
execute(Runnable) void 无返回值
submit(Runnable) Future<?> 返回一个 Future 对象(结果为 null)
submit(Callable<T>) Future<T> 返回一个包含实际结果的 Future 对象
b.支持的任务类型
方法 支持的任务类型
execute() 仅 Runnable
submit() Runnable 和 Callable
c.异常处理
方法异常 处理机制
execute() 任务中的异常会直接抛出到线程池,可能终止线程
submit() 异常被封装在 Future 中,需通过 Future.get() 捕获
01.代码对比
a.使用 execute()
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.execute(() -> {
System.out.println("任务执行中");
// 如果这里抛出异常,线程可能终止
});
b.使用 submit()
ExecutorService executor = Executors.newFixedThreadPool(2);
Future<?> future = executor.submit(() -> {
System.out.println("任务执行中");
return "结果"; // 可以是 Callable 的返回值
});
// 获取结果(或捕获异常)
try {
String result = (String) future.get();
} catch (ExecutionException e) {
// 处理任务中的异常
e.getCause().printStackTrace();
}
c.实际应用选择
a.execute()
当任务无需返回值且不关心异常细节时(例如日志记录、异步通知)
b.submit()
当需要以下功能时:
获取任务结果(Callable)
捕获任务中的异常
取消任务(future.cancel(true))
判断任务是否完成(future.isDone())
02.submit方法分析
a.submit方法的定义与重载
ExecutorService接口定义了三个submit方法重载:
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
-----------------------------------------------------------------------------------------------------
这些方法允许提交Runnable或Callable任务,并返回Future对象以跟踪任务状态和结果
b.源码实现(以AbstractExecutorService为例)
AbstractExecutorService是ExecutorService的抽象实现类,提供了submit方法的默认实现
-----------------------------------------------------------------------------------------------------
示例:submit(Runnable task)
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
-----------------------------------------------------------------------------------------------------
关键步骤解析:
任务封装:通过newTaskFor将Runnable或Callable封装为RunnableFuture(即FutureTask)
任务提交:调用线程池的execute(ftask)方法将任务加入执行队列。可以看到,这里其实还是调用了execute方法,所以submit方法其实是对execute方法的包装和增强
返回Future:返回FutureTask对象,用于后续结果获取或任务取消
c.newTaskFor方法
newTaskFor方法将任务包装成FutureTask,它是RunnableFuture的实现类,兼具Runnable和Future的功能。
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
-----------------------------------------------------------------------------------------------------
因为任务分为Runable和Callable两种,所以封装方法也是多态的,具体实现如下
Runnable封装:传入Runnable和一个默认结果value(通常为null),最终通过Callable适配器RunnableAdapter转换为Callable
Callable直接封装:直接使用Callable的逻辑
d.FutureTask分析
a.状态管理
FutureTask维护以下状态(通过volatile int state):
NEW:初始状态。
COMPLETING:任务执行中。
NORMAL:任务正常完成。
EXCEPTIONAL:任务抛出异常。
CANCELLED:任务被取消。
INTERRUPTING:中断中。
INTERRUPTED:已中断。
b.执行流程
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
-------------------------------------------------------------------------------------------------
线程池调用FutureTask.run()
执行内部Callable或适配后的Runnable逻辑
结果存储:
- 成功:调用set(result)保存结果
- 异常:调用setException(ex)保存异常
唤醒所有等待结果的线程(通过LockSupport.unpark)
可以看到, submit()提交的任务,异常被封装在Future中,调用Future.get()时抛出ExecutionException,需通过e.getCause()获取原始异常
e.关键设计思想
统一任务抽象:通过FutureTask将Runnable和Callable统一为可管理的异步任务
状态与结果隔离:FutureTask通过状态机管理任务生命周期,确保线程安全
资源控制:线程池通过队列和拒绝策略防止资源耗尽
03.execute方法
a.概述
execute 方法用于提交一个不需要返回值的任务给线程池执行,它接收一个 Runnable 类型的参数,并且不返回任何结果
b.示例代码
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExecuteDemo {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
// 使用 execute 方法提交任务
executor.execute(new Runnable() {
@Override
public void run() {
System.out.println("Task running in " + Thread.currentThread().getName());
try {
// 模拟任务执行
Thread.sleep(2000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.err.println("Task was interrupted");
}
System.out.println("Task finished");
}
});
// 关闭线程池
executor.shutdown();
}
}
04.submit方法
a.概述
submit 方法用于提交一个需要返回值的任务(Callable 对象),或者不需要返回值但希望获取任务状态的任务(Runnable 对象)
它接收一个 Callable 或 Runnable 类型的参数,并返回一个 Future 对象,通过该对象可以获取任务的执行结果或检查任务的状态
b.提交Callable任务
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class SubmitCallableDemo {
public static void main(String[] args) {
// 创建一个固定大小的线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 提交一个 Callable 任务给线程池执行
Future<String> future = executorService.submit(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(2000); // 模拟任务执行时间
return "Task's execution result";
}
});
try {
// 获取任务的执行结果
String result = future.get();
System.out.println("Task result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
// 关闭线程池
executorService.shutdown();
}
}
c.提交Runnable任务
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class SubmitRunnableDemo {
public static void main(String[] args) {
// 创建一个固定大小的线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 提交一个 Runnable 任务给线程池执行,并获取一个 Future 对象
Future<?> future = executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("Task is running in thread: " + Thread.currentThread().getName());
}
});
// 检查任务是否完成(这里只是为了示例,实际使用中可能不需要这样做)
if (future.isDone()) {
System.out.println("Task is done");
} else {
System.out.println("Task is not done yet");
}
// 关闭线程池
executorService.shutdown();
}
}
2.9 [2]监控:4类
01.线程池状态监控方法
a.getCompletedTaskCount()
介绍:返回线程池中已完成的任务数量。这个方法可以帮助开发者了解线程池的工作量
使用场景:用于监控任务的完成情况,评估线程池的处理能力
b.getLargestPoolSize()
介绍:返回线程池中曾经达到的最大线程数。这个值可以用来判断线程池是否曾经达到过最大容量
使用场景:用于分析线程池的负载情况,判断是否需要调整线程池的大小
c.getActiveCount()
介绍:返回当前正在执行任务的线程数量。这个方法可以帮助开发者了解线程池的实时负载
使用场景:用于监控线程池的实时活动情况,判断是否有线程长时间占用资源
d.getPoolSize()
介绍:返回当前线程池中的线程数量。这个方法可以帮助开发者了解线程池的规模
使用场景:用于监控线程池的规模变化,判断是否需要调整线程池的配置
02.扩展方法
a.beforeExecute(Thread t, Runnable r)
介绍:在任务执行之前调用。可以用于记录日志、初始化资源等
使用场景:用于在任务执行前进行一些准备工作或监控
b.afterExecute(Runnable r, Throwable t)
介绍:在任务执行之后调用。可以用于记录日志、释放资源、处理异常等
使用场景:用于在任务执行后进行清理工作或异常处理
c.terminated()
介绍:在线程池终止后调用。可以用于执行一些清理操作
使用场景:用于在线程池关闭后进行资源释放或记录日志
2.10 [2]保活:4种
00.总结
线程池中的线程分为核心线程与非核心线程
核心线程默认不回收,可以通过设置allowCoreThreadTimeOut为true 来回收
非核心线程在获取任务为空且空闲时间超过一定时间之后进行回收
线程池的保活策略通过阻塞队列的阻塞特性实现,poll 方法实现可以指定超时时间的阻塞,take 方法实现阻塞直到获取到任务
当线程异常之后,通过新增线程的方式实现线程的补救,保证线程池的运行
01.线程池中线程的保活和回收
a.线程池中执行任务的位置
任务执行:线程池中的任务是由工作线程执行的。每个工作线程从任务队列中获取任务并执行
工作线程:线程池在初始化时创建一定数量的核心线程,这些线程会在任务到来时执行任务
b.getTask获取任务方法
任务获取:ThreadPoolExecutor使用getTask()方法从任务队列中获取任务。该方法会阻塞直到有任务可用或线程池关闭
任务队列:任务队列用于存储等待执行的任务,常见的队列类型包括LinkedBlockingQueue、ArrayBlockingQueue等
c.核心线程的保活机制
核心线程:核心线程是线程池中始终保持活跃的线程数量。即使它们空闲,也不会被回收
保活时间:对于非核心线程,线程池使用keepAliveTime来决定线程的保活时间。当非核心线程空闲时间超过keepAliveTime时,它们会被终止
核心线程保活:通过调用allowCoreThreadTimeOut(true),可以让核心线程也受keepAliveTime的限制,从而在空闲时被回收
d.线程异常后的保活
异常处理:如果线程在执行任务时抛出异常,线程池会捕获异常并处理。默认情况下,线程池会终止该线程并创建一个新线程来替代它
异常保活:通过实现ThreadPoolExecutor的afterExecute方法,可以自定义异常处理逻辑,确保线程在异常后继续保活
02.代码示例
a.代码
import java.util.concurrent.*;
public class ThreadPoolExample {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // corePoolSize
4, // maximumPoolSize
10, // keepAliveTime
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10) // workQueue
);
// Allow core threads to time out
executor.allowCoreThreadTimeOut(true);
for (int i = 0; i < 10; i++) {
executor.execute(new Task(i));
}
executor.shutdown();
}
static class Task implements Runnable {
private final int taskId;
Task(int taskId) {
this.taskId = taskId;
}
@Override
public void run() {
try {
System.out.println("Executing task " + taskId);
if (taskId == 5) {
throw new RuntimeException("Exception in task " + taskId);
}
Thread.sleep(2000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (RuntimeException e) {
System.out.println(e.getMessage());
}
}
}
}
b.说明
核心线程和最大线程:线程池初始化时创建核心线程,当任务超过核心线程数时,创建非核心线程
保活时间:非核心线程在空闲超过keepAliveTime后被回收。通过allowCoreThreadTimeOut(true),核心线程也可以被回收
异常处理:任务执行时抛出的异常被捕获并处理,线程池会创建新线程来替代异常线程
2.11 [2]返回:3类
00.汇总
接口实现 Runnable Callable Future RunnableFuture
返回值 无 有 有 有
异常处理 无 可以抛出异常 可以抛出异常 可以抛出异常
任务状态 无 无 可以检查任务状态 可以检查任务状态
任务取消 无 无 可以取消任务 可以取消任务
应用场景 简单任务、后台任务 复杂任务、计算任务 异步任务、任务管理 异步任务、任务管理、组合任务
01.Runnable:无返回值的任务
a.定义
Runnable 是一个表示任务的接口,任务不返回结果也不抛出检查异常
它通常用于定义需要在单独线程中执行的任务
b.原理
Runnable 接口只有一个方法 run(),该方法不接受参数,也不返回结果
任务执行时,run() 方法中的代码会在新线程中运行
c.常用API
void run(): 执行任务的代码
d.详情
无返回值:Runnable 任务不返回结果
无异常处理:Runnable 任务不抛出检查异常
简单易用:适用于不需要返回结果的简单任务
e.应用场景
简单任务:适用于不需要返回结果的简单任务
后台任务:适用于需要在后台执行的任务,如定时任务、日志记录等
f.代码示例
public class RunnableExample {
public static void main(String[] args) {
Runnable task = () -> System.out.println("Task executed");
Thread thread = new Thread(task);
thread.start();
}
}
02.Callable:有返回值的任务
a.定义
Callable 是一个表示任务的接口,任务返回结果并且可能抛出异常
它通常用于定义需要在单独线程中执行并返回结果的任务
b.原理
Callable 接口只有一个方法 call(),该方法不接受参数,但返回一个结果,并且可以抛出异常
任务执行时,call() 方法中的代码会在新线程中运行
c.常用API
V call() throws Exception: 执行任务的代码,并返回结果
d.详情
有返回值:Callable 任务返回结果
异常处理:Callable 任务可以抛出异常
灵活性:适用于需要返回结果的复杂任务
e.应用场景
复杂任务:适用于需要返回结果的复杂任务
计算任务:适用于需要在后台执行的计算任务,如数据处理、文件读取等
f.代码示例
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class CallableExample {
public static void main(String[] args) {
Callable<Integer> task = () -> {
Thread.sleep(1000);
return 123;
};
ExecutorService executor = Executors.newFixedThreadPool(1);
Future<Integer> future = executor.submit(task);
try {
Integer result = future.get();
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}
03.Future:异步计算结果
a.定义
Future 是一个表示异步计算结果的接口。它提供了检查计算是否完成、等待计算完成以及获取计算结果的方法
b.原理
Future 接口提供了多个方法来检查任务的状态、获取任务的结果以及取消任务
任务执行时,Future 对象可以用于获取任务的结果或取消任务
c.常用API
boolean cancel(boolean mayInterruptIfRunning): 尝试取消任务
boolean isCancelled(): 如果任务在完成前被取消,则返回 true
boolean isDone(): 如果任务已完成,则返回 true
V get() throws InterruptedException, ExecutionException: 获取任务的结果,阻塞直到任务完成
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException: 获取任务的结果,阻塞直到任务完成或超时
d.详情
异步计算:Future 表示异步计算结果
任务状态:可以检查任务是否完成、是否被取消
获取结果:可以阻塞等待任务完成并获取结果
e.应用场景
异步任务:适用于需要异步执行并获取结果的任务
任务管理:适用于需要管理任务状态和结果的场景
f.代码示例
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class FutureExample {
public static void main(String[] args) {
Callable<Integer> task = () -> {
Thread.sleep(1000);
return 123;
};
ExecutorService executor = Executors.newFixedThreadPool(1);
Future<Integer> future = executor.submit(task);
try {
if (!future.isDone()) {
System.out.println("Task is not completed yet...");
}
Integer result = future.get();
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}
04.FutureTask:异步计算结果的实现类
a.定义
FutureTask 是 RunnableFuture 接口的实现类,表示可取消的异步计算
它既可以作为 Runnable 被执行,也可以作为 Future 获取结果
b.原理
FutureTask 实现了 Runnable 和 Future 接口
任务执行时,可以将 FutureTask 对象提交给 ExecutorService 执行,或者在单独的线程中执行
任务完成后,可以通过 Future 接口的方法获取结果
c.常用API
FutureTask(Callable<V> callable): 使用指定的 Callable 创建 FutureTask
FutureTask(Runnable runnable, V result): 使用指定的 Runnable 和结果创建 FutureTask
boolean cancel(boolean mayInterruptIfRunning): 尝试取消任务
boolean isCancelled(): 如果任务在完成前被取消,则返回 true
boolean isDone(): 如果任务已完成,则返回 true
V get() throws InterruptedException, ExecutionException: 获取任务的结果,阻塞直到任务完成
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException: 获取任务的结果,阻塞直到任务完成或超时
void run(): 执行任务的代码
d.详情
多功能:FutureTask 既可以作为 Runnable 被执行,也可以作为 Future 获取结果
任务状态:可以检查任务是否完成、是否被取消
获取结果:可以阻塞等待任务完成并获取结果
e.应用场景
异步任务:适用于需要异步执行并获取结果的任务
任务管理:适用于需要管理任务状态和结果的场景
组合任务:适用于需要将 Runnable 和 Callable 任务组合在一起的场景
f.代码示例
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
public class FutureTaskExample {
public static void main(String[] args) {
Callable<Integer> callable = () -> {
Thread.sleep(1000);
return 123;
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
ExecutorService executor = Executors.newFixedThreadPool(1);
executor.execute(futureTask);
try {
if (!futureTask.isDone()) {
System.out.println("Task is not completed yet...");
}
Integer result = futureTask.get();
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}
2.12 [2]关闭:2类
00.总结
a.任务处理
shutdown():允许已提交的任务完成
shutdownNow():试图立即停止所有任务
b.新任务提交
shutdown():不接受新任务
shutdownNow():不接受新任务
c.任务中断
shutdown():不主动中断正在执行的任务
shutdownNow():尝试中断正在执行的任务
d.返回值
shutdown():无返回值
shutdownNow():返回未执行的任务列表
e.优雅关闭线程池
shutdown()+awaitTermination(long timeout, TimeUnit unit)
01.shutdown()
a.介绍
shutdown()方法用于启动线程池的有序关闭过程。在调用shutdown()后,
线程池将不再接受新的任务,但会继续执行已经提交的任务(包括在队列中等待的任务)
线程池中的所有任务完成后,线程池将正常关闭。
b.使用场景
当你希望线程池完成所有已提交任务后再关闭时,使用shutdown()是合适的选择
适用于需要确保所有任务都被执行完毕的场景
c.示例
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.submit(() -> {
// Task 1
});
executor.submit(() -> {
// Task 2
});
// Initiate an orderly shutdown
executor.shutdown();
// Wait for all tasks to complete
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
02.shutdownNow()
a.介绍
shutdownNow() 方法试图立即停止所有正在执行的任务,并返回等待执行的任务列表
它会尝试中断正在执行的任务,并清空任务队列
由于中断是通过 Thread.interrupt() 实现的,因此任务必须支持中断才能被成功停止
b.使用场景
当你需要立即停止线程池的所有活动任务,并不关心未完成任务时,使用 shutdownNow() 是合适的选择
适用于需要快速停止任务执行的场景,例如在应用程序关闭或发生严重错误时
c.示例
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.submit(() -> {
// Task 1
});
executor.submit(() -> {
// Task 2
});
// Attempt to stop all actively executing tasks
List<Runnable> notExecutedTasks = executor.shutdownNow();
// Handle tasks that were not executed
for (Runnable task : notExecutedTasks) {
// Process or log the task
}
03.优雅关闭线程池:shutdown()+awaitTermination(long timeout, TimeUnit unit)
a.思路
awaitTermination(long timeout, TimeUnit unit)是可以允许我们在调用shutdown方法后,再设置一个等待时间
如设置为5秒,则表示shutdown后5秒内线程池彻底终止,返回true,否则返回false;
-----------------------------------------------------------------------------------------------------
这种方式里,我们将shutdown()结合awaitTermination(long timeout, TimeUnit unit)方法去使用
注意在调用 awaitTermination() 方法时,应该设置合理的超时时间,以避免程序长时间阻塞而导致性能问题
而且由于这个方法在超时后也会抛出异常,因此,我们在使用的时候要捕获并处理异常!
b.代码
public class TestService{
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池,设置等待超时时间 3 秒
System.out.println("设置线程池关闭,等待 3 秒...");
threadPool.shutdown();
try {
boolean isTermination = threadPool.awaitTermination(3, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池未停止");
} catch (InterruptedException e) {
e.printStackTrace();
}
//再等待超时时间 20 秒
System.out.println("再等待 20 秒...");
try {
boolean isTermination = threadPool.awaitTermination(20, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池仍未停止,请检查!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
c.输出
设置线程池关闭,等待 3 秒...
正在执行任务 1
正在执行任务 2
正在执行任务 3
正在执行任务 4
正在执行任务 5
线程池未停止
再等待 20 秒...
正在执行任务 6
正在执行任务 7
正在执行任务 8
正在执行任务 9
正在执行任务 10
线程池已停止
d.结论
从输出中我们可以看到,通过将两种方法结合使用,我们监控了整个线程池关闭的全流程,实现了优雅的关闭!
2.13 [2]判断:执行完成
00.汇总
isTerminated() 方法:适合在需要关闭线程池的场景中使用
Future.get() 方法:适合需要获取任务结果的场景,但会阻塞直到任务完成
CountDownLatch:适合需要等待多个任务完成的场景,灵活性较高
01.使用 isTerminated() 方法
a.原理
isTerminated() 方法用于判断线程池是否已经终止
只有在调用 shutdown() 或 shutdownNow() 方法后,并且所有任务都已完成时,isTerminated() 才会返回 true
b.局限性
需要主动调用 shutdown() 方法,这在某些业务场景中可能不适用
c.代码
ExecutorService executorService = Executors.newFixedThreadPool(10);
// 提交任务
executorService.shutdown();
while (!executorService.isTerminated()) {
// 等待所有任务完成
}
System.out.println("所有任务已完成");
02.使用 Future 的 get() 方法
a.原理
通过 submit() 方法提交任务时,会返回一个 Future 对象。调用 future.get() 会阻塞当前线程,直到任务完成
b.适用性
适用于需要获取任务结果的场景
c.代码
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<?> future = executorService.submit(() -> {
// 执行任务
});
try {
future.get(); // 阻塞直到任务完成
System.out.println("任务已完成");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
03.使用 CountDownLatch
a.原理
CountDownLatch 是一个同步辅助类,用于在完成一组正在其他线程中执行的操作之前,允许一个或多个线程一直等待
b.适用性
适用于需要等待多个任务完成的场景
c.代码
int taskCount = 10;
CountDownLatch latch = new CountDownLatch(taskCount);
ExecutorService executorService = Executors.newFixedThreadPool(taskCount);
for (int i = 0; i < taskCount; i++) {
executorService.submit(() -> {
try {
// 执行任务
} finally {
latch.countDown(); // 任务完成,计数器减一
}
});
}
try {
latch.await(); // 阻塞直到计数器为零
System.out.println("所有任务已完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
executorService.shutdown();
2.14 [2]扩展:线程组
01.概述
在 Java 中,ThreadGroup 是一种用于组织线程的机制
ThreadGroup 可以包含一组相关的线程,并且可以对这组线程进行集中管理
02.ThreadGroup 类提供的功能
a.线程组的创建和销毁
可以通过 ThreadGroup 构造函数创建 ThreadGroup 对象,并使用 destroy() 方法销毁线程组
b.添加和移除线程
添加通过Thread构造函数指定ThreadGroup,线程结束后会自动移除
c.获取线程组信息
可以使用 getName() 方法获取线程组的名称,使用 getParent() 方法获取父线程组,使用 activeCount() 方法获取活动线程的数量,使用 enumerate(Thread[]) 方法获取线程组中的线程列表等
d.处理未捕获异常
可以使用 uncaughtException(Thread, Throwable) 方法在发生未捕获异常时进行处理
e.设置线程组的优先级
可以使用 setMaxPriority(int) 方法设置线程组的最大优先级
f.调用线程组中所有线程的 interrupt() 方法
可以使用 interrupt() 方法中断线程组中的所有线程
03.线程组的创建和销毁
a.创建线程组
// 通过调用 ThreadGroup 的构造函数,可以创建一个名为 "MyThreadGroup" 的线程组
ThreadGroup group = new ThreadGroup("MyThreadGroup");
b.销毁线程组
// 可以使用 ThreadGroup 的 `destroy()` 方法来销毁线程组
// 销毁线程组会自动停止该线程组内所有的线程,并且无法再添加新的线程
group.destroy();
-----------------------------------------------------------------------------------------------------
需要注意的是,销毁线程组时,该线程组必须没有任何活动线程
如果线程组中还有活动线程,那么调用 destroy() 方法会抛出 IllegalThreadStateException 异常
c.示例代码
public class ThreadGroupExample {
public static void main(String[] args) {
ThreadGroup group = new ThreadGroup("MyThreadGroup");
Thread t1 = new Thread(group, () -> {
System.out.println("Thread 1 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(group, () -> {
System.out.println("Thread 2 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
// 假设线程执行一段时间后,线程组中没有活动线程了
group.destroy();
}
}
-----------------------------------------------------------------------------------------------------
需要注意的是,销毁线程组是一种较为激进的操作,通常在确保线程组中没有活动线程时进行,以避免出现异常情况
从JDK16开始,这个接口已经过时,并且在将来的jdk版本中会被移除
04.添加和移除线程
a.自动添加和移除
从 JDK 1.5 开始,Java 引入了 ThreadGroup 的垃圾回收机制改进,不再需要显式地添加或移除线程
可以通过创建线程时指定线程组来自动将线程添加到相应的线程组中,并且当线程终止后,它会自动从线程组中移除
b.示例代码
package engineer.concurrent.battle.igroup;
public class ThreadGroupAddExample {
public static void main(String[] args) throws InterruptedException {
ThreadGroup group = new ThreadGroup("MyThreadGroup");
Thread t1 = new Thread(group, () -> {
System.out.println("Thread 1 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(group, () -> {
System.out.println("Thread 2 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("All threads are finished");
// 打印线程列表
Thread[] tArr = new Thread[2];
group.enumerate(tArr);
for (int i = 0; i < tArr.length; i++) {
if(tArr[i]!=null){
System.out.println(tArr[i].getName());
}else{
System.out.println("thread exit.");
}
}
}
}
-----------------------------------------------------------------------------------------------------
输出结果如下:
Thread 1 is running
Thread 2 is running
All threads are finished
thread exit.
thread exit.
05.获取线程组信息
a.常用方法
getName(): 获取线程组的名称
getParent(): 获取父线程组
activeCount(): 获取当前活跃线程数
activeGroupCount(): 获取当前活跃子线程组数
enumerate(Thread[] threads): 将线程组及其子组中的所有活跃线程复制到指定的线程数组中
enumerate(ThreadGroup[] groups): 将线程组及其子组中的所有活跃子线程组复制到指定的线程组数组中
b.示例代码
package engineer.concurrent.battle.igroup;
public class ThreadGroupInfoDemo {
public static void main(String[] args) {
ThreadGroup group = new ThreadGroup("MyThreadGroup");
Thread t1 = new Thread(group, () -> {
System.out.println("Thread 1 is running");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(group, () -> {
System.out.println("Thread 2 is running");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
// 获取线程组的信息
System.out.println("线程组名称:" + group.getName());
System.out.println("父线程组:" + group.getParent());
System.out.println("活跃线程数:" + group.activeCount());
System.out.println("活跃子线程组数:" + group.activeGroupCount());
Thread[] threads = new Thread[group.activeCount()];
group.enumerate(threads);
System.out.println("活跃线程列表:");
for (Thread thread : threads) {
System.out.println(thread);
}
ThreadGroup[] subGroups = new ThreadGroup[group.activeGroupCount()];
group.enumerate(subGroups);
System.out.println("活跃子线程组列表:");
for (ThreadGroup subGroup : subGroups) {
System.out.println(subGroup);
}
}
}
-----------------------------------------------------------------------------------------------------
输出可能类似于以下内容:
线程组名称:MyThreadGroup
父线程组:java.lang.ThreadGroup[name=main,maxpri=10]
活跃线程数:2
活跃子线程组数:0
活跃线程列表:
Thread[Thread-0,5,MyThreadGroup]
Thread[Thread-1,5,MyThreadGroup]
活跃子线程组列表:
06.处理未捕获异常
a.概述
可以使用 ThreadGroup 类来处理线程组中未捕获的异常
当一个线程抛出一个未捕获的异常时,如果该线程是属于一个线程组的
那么这个异常就会被传播到其所属线程组中的 uncaughtException(Thread t, Throwable e) 方法中进行处理
b.示例代码
public class ThreadGroupExceptionDemo {
public static void main(String[] args) {
// 创建一个线程组,并重写 uncaughtException 方法来处理未捕获的异常
ThreadGroup group = new ThreadGroup("MyThreadGroup") {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("Thread " + t.getName() + " throws exception: " + e.getMessage());
}
};
// 在线程组中启动一个线程
Thread t = new Thread(group, () -> {
throw new RuntimeException("Test Exception");
});
t.start();
}
}
-----------------------------------------------------------------------------------------------------
输出可能类似于以下内容:
Thread Thread-0 throws exception: Test Exception
07.设置线程组的优先级
a.概述
可以使用 ThreadGroup 类的 setMaxPriority(int priority) 方法来设置线程组的优先级
这个方法可以将线程组中所有线程的优先级限制为指定的值,如果线程拥有更高的优先级则不受重新设置优先级
b.示例代码
public class ThreadGroupPriorityExample {
public static void main(String[] args) {
// 创建一个线程组,并将其优先级设置为 5
ThreadGroup group = new ThreadGroup("MyThreadGroup");
group.setMaxPriority(5);
// 在线程组中启动两个线程
Thread t1 = new Thread(group, () -> {
System.out.println("Thread 1 priority: " + Thread.currentThread().getPriority());
});
Thread t2 = new Thread(group, () -> {
System.out.println("Thread 2 priority: " + Thread.currentThread().getPriority());
});
t1.start();
t2.start();
}
}
-----------------------------------------------------------------------------------------------------
输出可能类似于以下内容:
Thread 1 priority: 5
Thread 2 priority: 5
08.中断线程组中的所有线程
a.概述
可以使用 ThreadGroup 类的 interrupt() 方法来中断线程组中的所有线程
这个方法会向线程组中的所有线程发送中断信号,使它们停止正在执行的任务并抛出 InterruptedException 异常
b.示例代码
package engineer.concurrent.battle.igroup;
import java.util.concurrent.TimeUnit;
public class ThreadGroupInterruptExample {
public static void main(String[] args) throws InterruptedException {
// 创建一个线程组,并启动两个线程
ThreadGroup group = new ThreadGroup("MyThreadGroup");
Thread t1 = new Thread(group, () -> {
while (!Thread.interrupted()) {
System.out.println("Thread 1 is running...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
// 捕获中断异常并退出线程
System.out.println("Thread 1 is interrupted!");
return;
}
}
});
Thread t2 = new Thread(group, () -> {
while (!Thread.interrupted()) {
System.out.println("Thread 2 is running...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
// 捕获中断异常并退出线程
System.out.println("Thread 2 is interrupted!");
return;
}
}
});
t1.start();
t2.start();
TimeUnit.SECONDS.sleep(3);
// 中断线程组中的所有线程
group.interrupt();
}
}
-----------------------------------------------------------------------------------------------------
输出可能类似于以下内容:
Thread 1 is running...
Thread 2 is running...
Thread 1 is interrupted!
Thread 2 is interrupted!
c.源码分析
java.lang.ThreadGroup#interrupt 的源码如下,可以看到synchronized加锁后对当前线程组一个个遍历发起interrupt
-----------------------------------------------------------------------------------------------------
public final void interrupt() {
int ngroupsSnapshot;
ThreadGroup[] groupsSnapshot;
synchronized (this) {
checkAccess();
for (int i = 0 ; i < nthreads ; i++) {
threads[i].interrupt();
}
ngroupsSnapshot = ngroups;
if (groups != null) {
groupsSnapshot = Arrays.copyOf(groups, ngroupsSnapshot);
} else {
groupsSnapshot = null;
}
}
for (int i = 0 ; i < ngroupsSnapshot ; i++) {
groupsSnapshot[i].interrupt();
}
}
09.其它接口信息
a.java.lang.ThreadGroup#setDaemon
设置守护线程的属性,true的话在所有线程执行完成后会调用java.lang.ThreadGroup#destroy方法,这两个接口是过时的
摧毁 ThreadGroup 的 API 和机制本质上存在缺陷。在未来的版本中,将删除显式或自动销毁线程组的功能,以及守护线程组的概念
b.java.lang.ThreadGroup#resume或suspend
这两个接口已被弃用,因为它天生容易发生死锁.
2.15 [2]优化:线程守护
01.何为守护线程
a.线程分类
Java中的线程分为2种:用户线程和守护线程
用户线程又叫普通线程,是我们驱动业务逻辑运转的核心;而守护线程,顾名思义,是守护用户线程的一种线程
运行在后台提供通用服务,因此也叫后台线程或者精灵线程。
b.守护线程的使用场景
a.GC垃圾回收线程
这是JVM中非常经典的一个守护线程,它始终以低级别状态运行,用于实时监控和管理系统中的可回收资源
一旦我们的系统没有任何运行的用户线程时,程序也就不会再产生垃圾,这时,无事可做的垃圾回收线程会自动结束
b.应用指标统计
部分服务可以通过守护线程来采取应用指标,服务结束则停止采集
02.怎么设置守护线程
a.设置方法
我们可以通过在 start 线程之前调用线程的 setDaemon(true) 方法,将一个线程设置为守护线程
b.代码实例
public class Test {
public static void main(String[] args) {
Thread thread1 = new Thread("守护线程"){
@Override
public void run() {
int i = 0;
while (i <= 4){
i++;
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+i);
}
super.run();
}
};
Thread thread2 = new Thread("用户线程"){
@Override
public void run() {
int i = 0;
while (i < 2){
i++;
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+i);
}
super.run();
}
};
//setDaemon, 不设置则默认false
thread1.setDaemon(true);//设置thread1为守护线程
thread2.setDaemon(false);//设置thread2为普通线程
thread1.start();
thread2.start();
}
}
-----------------------------------------------------------------------------------------------------
输出:
守护线程:1
用户线程:1
用户线程:2
守护线程:2
-----------------------------------------------------------------------------------------------------
这段测试代码中,我们通过thread1.setDaemon(true)将线程1设置成了一个守护线程(false为普通线程)
用户线程的循环次数为2,用户线程的循环次数为4,但当程序中的用户线程运行完之后
守护线程并没有继续向下循环,而是随着用户线程的结束而自我终止了
03.守护线程的优先级
a.优先级测试
看到网上很多博文提到了守护线程的优先级问题,都说守护线程的优先级比较低,那我们通过一段测试用例看一下真实情况
b.代码实例2
public class Test {
public static void main(String[] args) {
Thread thread1 = new Thread("守护线程"){
@Override
public void run() {
int i = 0;
while (i <= 4){
i++;
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+i+"-优先级:" +Thread.currentThread().getPriority());
}
super.run();
}
};
Thread thread2 = new Thread("用户线程"){
@Override
public void run() {
int i = 0;
while (i < 2){
i++;
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+i+"-优先级:" +Thread.currentThread().getPriority());
}
super.run();
}
};
//setDaemon, 不设置则默认false
thread1.setDaemon(true);//设置thread1为守护线程
thread2.setDaemon(false);//设置thread2为普通线程
thread1.start();
thread2.start();
for (int i = 0; i <5 ; i++) {
System.out.println("主线程:"+i+"-优先级:" +Thread.currentThread().getPriority());
}
}
}
-----------------------------------------------------------------------------------------------------
输出:
主线程:0-优先级:5
主线程:1-优先级:5
主线程:2-优先级:5
主线程:3-优先级:5
主线程:4-优先级:5
用户线程:1-优先级:5
守护线程:1-优先级:5
用户线程:2-优先级:5
守护线程:2-优先级:5
-----------------------------------------------------------------------------------------------------
这个测试结果是不是出乎意料?无论是主线程还是普通的用户线程,又或者说守护线程,他们的优先级都是5,优先级竟然都一样!
我们知道所谓的线程就是CPU 调度和分派的基本单位,根据优先级不同,来决定获取CPU时间片的先后顺序,因为主线程启动时,其他线程还没有启动,所以这时候它最先获得CPU调度权限;
又因为其他线程存在休眠时间,这个时间段上足够主线程执行完毕。主线程执行完后,用户线程和守护线程互相抢占CPU资源,交错执行,直至程序中没有普通线程为止!若没有休眠时间,且循环次数足够多时,我们可以看到主线程、守护线程、用户线程都竞争CPU时间片,呈现交错执行的结果!
04.注意事项
a.设置守护线程的注意事项
在设置线程为守护线程的时候要注意一个事情,那就是当 start(); 放到 setDaemon(true); 之前,程序抛出IllegalThreadStateException。
原因是 setDaemon(true)源码中,有一个isAlive()的判断,判断当前线程的状态是否为活跃线程,若是则抛出异常,我们不能修改一个正在运行中的线程!
b.源码解析
public final void setDaemon(boolean on) {
checkAccess();
//线程已经启动后,不可修改,否则抛出非法线程状态异常
if (isAlive()) {
throw new IllegalThreadStateException();
}
daemon = on;
}
2.16 [2]优化:线程安全
00.汇总
1.无状态
2.不可变
3.无修改权限
3.synchronized
4.Lock
5.分布式锁
6.volatile
7.ThreadLocal
8.线程安全集合
9.CAS
10.数据隔离
00.无状态
a.概述
只有多个线程访问公共资源时,才可能出现数据安全问题。如果没有公共资源,则没有这个问题。
b.示例
public class NoStatusService {
public void add(String status) {
System.out.println("add status:" + status);
}
public void update(String status) {
System.out.println("update status:" + status);
}
}
-----------------------------------------------------------------------------------------------------
NoStatusService没有定义公共资源,是无状态的,因此是线程安全的。
01.不可变
a.概述
如果多个线程访问的公共资源是不可变的,也不会出现数据的安全性问题。
b.示例
public class NoChangeService {
public static final String DEFAULT_NAME = "abc";
public void add(String status) {
System.out.println(DEFAULT_NAME);
}
}
-----------------------------------------------------------------------------------------------------
DEFAULT_NAME被定义成了static final的常量,在多线程中不会被修改,因此线程安全。
02.无修改权限
a.概述
如果公共资源只暴露了读取权限,没有暴露修改权限,也是线程安全的。
b.示例
public class SafePublishService {
private String name;
public String getName() {
return name;
}
public void add(String status) {
System.out.println("add status:" + status);
}
}
-----------------------------------------------------------------------------------------------------
没有对外暴露修改name字段的入口,因此线程安全。
03.synchronized
a.概述
使用JDK内部提供的同步机制,包括同步方法和同步代码块。
b.示例
public class SyncService {
private int age = 1;
private Object object = new Object();
//同步方法
public synchronized void add(int i) {
age = age + i;
System.out.println("age:" + age);
}
//同步代码块,对象锁
public void update(int i) {
synchronized (object) {
age = age + i;
System.out.println("age:" + age);
}
}
//同步代码块,类锁
public void update(int i) {
synchronized (SyncService.class) {
age = age + i;
System.out.println("age:" + age);
}
}
}
04.Lock
a.概述
使用Lock接口实现同步功能,通常使用ReentrantLock。
b.示例
---
public class LockService {
private ReentrantLock reentrantLock = new ReentrantLock();
public int age = 1;
public void add(int i) {
try {
reentrantLock.lock();
age = age + i;
System.out.println("age:" + age);
} finally {
reentrantLock.unlock();
}
}
}
05.分布式锁
a.概述
在分布式环境中,需要使用分布式锁来保证线程安全。
b.示例
使用redis分布式锁的伪代码:
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
06.volatile
a.概述
使用volatile关键字保证多个线程间的可见性。
b.示例
@Service
public CanalService {
private volatile boolean running = false;
private Thread thread;
@Autowired
private CanalConnector canalConnector;
public void handle() {
while(running) {
//业务处理
}
}
public void start() {
thread = new Thread(this::handle, "name");
running = true;
thread.start();
}
public void stop() {
if(!running) {
return;
}
running = false;
}
}
07.ThreadLocal
a.概述
使用ThreadLocal为每个线程提供一个独立的变量副本。
b.示例
public class ThreadLocalService {
private ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public void add(int i) {
Integer integer = threadLocal.get();
threadLocal.set(integer == null ? 0 : integer + i);
}
}
08.线程安全集合
a.概述
使用线程安全的集合类,如ConcurrentHashMap。
b.示例
public class HashMapTest {
private static ConcurrentHashMap<String, Object> hashMap = new ConcurrentHashMap<>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
hashMap.put("key1", "value1");
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
hashMap.put("key2", "value2");
}
}).start();
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(hashMap);
}
}
09.CAS
a.概述
使用CAS机制保证线程安全。
b.示例
public class AtomicService {
private AtomicInteger atomicInteger = new AtomicInteger();
public int add(int i) {
return atomicInteger.getAndAdd(i);
}
}
10.数据隔离
a.概述
通过数据隔离来保证线程安全。
b.示例
public class ThreadPoolTest {
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(8, 10, 60, TimeUnit.SECONDS, new ArrayBlockingQueue(500), new ThreadPoolExecutor.CallerRunsPolicy());
List<User> userList = Lists.newArrayList(
new User(1L, "苏三", 18, "成都"),
new User(2L, "苏三说技术", 20, "四川"),
new User(3L, "技术", 25, "云南"));
for (User user : userList) {
threadPool.submit(new Work(user));
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(userList);
}
static class Work implements Runnable {
private User user;
public Work(User user) {
this.user = user;
}
@Override
public void run() {
user.setName(user.getName() + "测试");
}
}
}
2.17 [3]线程池:5种
00.汇总
1.newFixedThreadPool(固定线程池) Executors的5个静态工厂方法
2.newWorkStealingPool(工作窃取线程池) Executors的5个静态工厂方法
3.newSingleThreadExecutor(单线程池) Executors的5个静态工厂方法
4.newCachedThreadPool(缓存线程池) Executors的5个静态工厂方法
5.newScheduledThreadPool(定时任务线程池) Executors的5个静态工厂方法
01.newFixedThreadPool(固定线程池)
a.特点
线程池中有固定数量的线程。
当线程数达到上限时,任务会在队列中等待。
适合任务数量已知且线程数需要固定的场景。
b.示例
System.out.println("Starting FixedThreadPool Example:");
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3); // 固定大小线程池
for (int i = 1; i <= 6; i++) {
int taskId = i;
fixedThreadPool.execute(() -> {
System.out.println("Task " + taskId + " is running by " + Thread.currentThread().getName());
});
}
fixedThreadPool.shutdown();
Thread.sleep(1000); // 等待任务执行完成
02.newWorkStealingPool(工作窃取线程池)
a.特点
创建一个工作窃取线程池,利用多核性能,适合大规模并行任务。
线程池的大小等于当前设备的可用处理器数量(Runtime.getRuntime().availableProcessors())。
使用工作窃取算法(ForkJoinPool),任务之间可相互窃取以提高效率。
b.示例
System.out.println("\nStarting WorkStealingPool Example:");
ExecutorService workStealingPool = Executors.newWorkStealingPool();
for (int i = 1; i <= 6; i++) {
int taskId = i;
workStealingPool.execute(() -> {
System.out.println("Task " + taskId + " is running by " + Thread.currentThread().getName());
});
}
// 注意:WorkStealingPool需要等待后台任务完成再终止主程序
Thread.sleep(2000); // 等待任务执行完成
workStealingPool.shutdown();
03.newSingleThreadExecutor(单线程池)
a.特点
线程池中始终只有一个线程。
所有任务会按照提交的顺序(FIFO, LIFO, 优先级)执行。
适合需要顺序执行任务的场景,比如写日志。
b.示例
System.out.println("\nStarting SingleThreadExecutor Example:");
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor(); // 单线程池
for (int i = 1; i <= 5; i++) {
int taskId = i;
singleThreadExecutor.execute(() -> {
System.out.println("Task " + taskId + " is running by " + Thread.currentThread().getName());
});
}
singleThreadExecutor.shutdown();
Thread.sleep(1000); // 等待任务执行完成
04.CachedThreadPool(缓存线程池)
a.特点
线程数量没有固定上限,会根据任务数量动态创建线程。
空闲线程会被回收(默认空闲时间 60 秒)。
适合执行大量短期任务且任务数量不确定的场景。
a.示例
ExecutorService cachedThreadPool = Executors.newCachedThreadPool(); // 缓存线程池
for (int i = 1; i <= 10; i++) {
int taskId = i;
cachedThreadPool.execute(() -> {
System.out.println("Task " + taskId + " is running by " + Thread.currentThread().getName());
});
}
cachedThreadPool.shutdown();
Thread.sleep(1000); // 等待任务执行完成
05.ScheduledThreadPool(定时任务线程池)
a.特点
用于执行定时任务或周期性任务。
可以延迟执行任务或以固定的周期重复执行任务。
适合需要定时处理或周期性执行任务的场景。
b.示例
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2); // 定时任务线程池
// 延迟 2 秒执行一次任务
scheduledThreadPool.schedule(() -> {
System.out.println("Delayed task executed by " + Thread.currentThread().getName());
}, 2, TimeUnit.SECONDS);
// 每隔 1 秒执行一次任务,初始延迟为 1 秒
scheduledThreadPool.scheduleAtFixedRate(() -> {
System.out.println("Periodic task executed by " + Thread.currentThread().getName());
}, 1, 1, TimeUnit.SECONDS);
// 运行一段时间后关闭线程池
Thread.sleep(5000); // 等待任务执行一定时间
scheduledThreadPool.shutdown();
2.18 [3]线程池:优点
01.线程池优点
a.提高性能和资源利用率
减少线程创建和销毁的开销:每次执行任务都通过new Thread()去创建线程,比较消耗性能。线程池通过复用线程来减少频繁创建和销毁线程的开销
更好的资源管理:线程池可以限制同时运行的线程数量,避免系统资源被过多的线程占用,从而提高系统的稳定性和性能
b.更好的线程管理
线程复用:线程池中的线程可以被重复使用,避免了频繁创建和销毁线程的开销
任务排队和调度:线程池可以管理任务的排队和调度,确保任务按顺序执行,并且可以根据需要调整线程的数量
c.提高系统稳定性
防止资源耗尽:通过限制线程的最大数量,线程池可以防止系统资源被耗尽,避免系统崩溃
避免线程竞争:通过合理的线程管理,线程池可以减少线程之间的竞争,提高系统的稳定性
d.简化并发编程
统一的接口:Executor框架提供了统一的接口,简化了并发编程的复杂性,使得开发者可以更容易地管理和调度任务
丰富的功能:Executor框架提供了丰富的功能,如定时执行、定期执行、延迟执行、任务取消等,方便开发者实现复杂的并发任务
e.灵活的配置
可配置的线程池:Executor框架提供了多种类型的线程池(如固定线程池、缓存线程池、单线程池、调度线程池等),开发者可以根据具体需求选择合适的线程池类型
动态调整:线程池可以动态调整线程的数量和任务队列的大小,适应不同的工作负载
2.19 [3]线程池:原理
01.工作流程
a.任务到来
默认情况下,线程池不会预创建线程,任务到来时才会创建线程(可以通过prestartAllCoreThreads预创建核心线程)
b.核心线程处理任务
如果当前活动的线程数少于核心线程数,线程池会创建新的核心线程来处理任务
c.任务入队
当核心线程数已满时,新的任务会被放入工作队列中等待执行
d.创建非核心线程
如果工作队列已满,线程池会创建新的线程来处理任务,直到线程数达到最大线程数
e.执行拒绝策略
如果工作队列已满且线程数已达到最大线程数,新的任务将被拒绝,并执行相应的拒绝策略
f.回收空闲线程
如果线程空闲时间超过空闲存活时间,并且当前线程数大于核心线程数,则会销毁线程,直到线程数等于核心线程数(可以通过allowCoreThreadTimeOut回收核心线程)
02.工作流程
线程数 < 核心线程数(corePoolSize):创建新线程执行任务
线程数达到核心线程数,任务进入任务队列,等待执行
任务队列已满,且线程数小于最大线程数(maximumPoolSize):创建新线程执行任务
线程数达到 maximumPoolSize 且任务队列已满:执行拒绝策略

2.20 [3]线程池:数量
00.最佳线程数
a.经验值
a.IO密集型
配置线程数经验值是:2N,其中N代表CPU核数。
b.CPU密集型
配置线程数经验值是:N + 1,其中N代表CPU核数。
c.获取N的值
int availableProcessors = Runtime.getRuntime().availableProcessors();
b.最佳线程数目算法
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
虽说最佳线程数目算法更准确,但是线程等待时间和线程CPU时间不好测量,实际情况使用得比较少,一般用经验值就差不多了。
01.线程池示例
a.示例代码
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("MyCallable call");
return "success";
}
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try {
Future<String> future = threadPool.submit(new MyCallable());
System.out.println(future.get());
} catch (Exception e) {
System.out.println(e);
} finally {
threadPool.shutdown();
}
}
}
b.功能描述
这个类的功能就是使用Executors类的newSingleThreadExecutor方法创建了的一个单线程池
他里面会执行Callable线程任务
02.Executors类提供的创建线程池的方法
a.newCachedThreadPool可缓冲线程池
它的核心线程数是0,最大线程数是integer的最大值,每隔60秒回收一次空闲线程,使用SynchronousQueue队列
b.newFixedThreadPool固定大小线程池
它的核心线程数 和 最大线程数是一样,都是nThreads变量的值,该变量由用户自己决定,所以说是固定大小线程池
c.newScheduledThreadPool定时任务线程池
它的核心线程数是corePoolSize变量,需要用户自己决定,最大线程数是integer的最大值
d.newSingleThreadExecutor单个线程池
跟newFixedThreadPool是一样的,核心线程数 和 最大线程数 都是1
e.newSingleThreadScheduledExecutor单线程定时任务线程池
该线程池是对ScheduledThreadPoolExecutor定时任务线程池的简单封装,核心线程数固定是1
f.newWorkStealingPool窃取线程池
它是JDK1.8增加的新线程池,底层是通过ForkJoinPool类来实现的
03.使用示例
a.newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor 和 newWorkStealingPool
public class MyWorker implements Runnable {
@Override
public void run() {
System.out.println("MyWorker run");
}
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(8);
try {
threadPool.execute(new MyWorker());
} catch (Exception e) {
System.out.println(e);
} finally {
threadPool.shutdown();
}
}
}
b.newScheduledThreadPool 和 newSingleThreadScheduledExecutor
public class MyTask implements Runnable {
@Override
public void run() {
System.out.println("MyTask call");
}
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(8);
try {
scheduledExecutorService.schedule(new MyRunnable(), 60, TimeUnit.SECONDS);
} finally {
scheduledExecutorService.shutdown();
}
}
}
03.自定义线程池
a.问题描述
阿里巴巴开发规范中明确规定不要使用Executors类创建线程池。
b.原因
a.newCachedThreadPool
它的最大线程数是integer的最大值,意味着使用它创建的线程池,可以创建非常多的线程,可能会出现内存溢出的问题。
b.newFixedThreadPool和newSingleThreadExecutor
它的队列使用的LinkedBlockingQueue,默认大小是integer的最大值,意味着可以往该队列中加非常多的任务,可能会出现内存溢出的问题。
c.建议
使用ThreadPoolExecutor类创建线程池。
d.参数说明
corePoolSize:核心线程数
maximumPoolSize:最大线程数
keepAliveTime:空闲线程回收时间间隔
unit:空闲线程回收时间间隔单位
workQueue:提交任务的队列
threadFactory:线程工厂
handler:表示当拒绝处理任务时的策略
e.示例代码
public class MyThreadPool implements Runnable {
private static final ExecutorService executorService = new ThreadPoolExecutor(
8,
10,
30,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(500),
new ThreadPoolExecutor.AbortPolicy());
@Override
public void run() {
System.out.println("MyThreadPool run");
}
public static void main(String[] args) {
int availableProcessors = Runtime.getRuntime().availableProcessors();
try {
executorService.execute(new MyThreadPool());
} catch (Exception e) {
System.out.println(e);
} finally {
executorService.shutdown();
}
}
}
2.21 [3]线程池:坑点
00.汇总
1.直接使用Executors创建线程池
2.错误配置线程数
3.忽略任务队列的选择
4.忘记关闭线程池
5.忽略拒绝策略
6.任务中未处理异常
7.阻塞任务占用线程池
8.滥用线程池
9.未监控线程池状态
10.动态调整线程池参数
01.直接使用 Executors 创建线程池
a.问题所在
A.无界队列
newFixedThreadPool 使用的队列是 LinkedBlockingQueue,它是无界队列,任务堆积可能会导致内存溢出
B.线程无限增长
newCachedThreadPool 会无限创建线程,在任务量激增时可能耗尽系统资源。
b.示例:内存溢出的风险
ExecutorService executor = Executors.newFixedThreadPool(2);
for (int i = 0; i < 1000000; i++) {
executor.submit(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
-----------------------------------------------------------------------------------------------------
任务数远大于线程数,导致任务无限堆积在队列中,最终可能导致 OutOfMemoryError
c.解决办法
使用 ThreadPoolExecutor,并明确指定参数:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2,
4,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100), // 有界队列
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
);
02.错误配置线程数
a.问题所在
很多人随意配置线程池参数,比如核心线程数 10,最大线程数 100,看起来没问题,但这可能导致性能问题或资源浪费
b.示例:错误配置导致的线程过载
ThreadPoolExecutor executor = new ThreadPoolExecutor(
10, // 核心线程数
100, // 最大线程数
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10)
);
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
try {
Thread.sleep(5000); // 模拟耗时任务
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
-----------------------------------------------------------------------------------------------------
这种配置在任务激增时,会创建大量线程,系统资源被耗尽
c.正确配置方式
根据任务类型选择合理的线程数:
CPU 密集型:线程数建议设置为 CPU 核心数 + 1
IO 密集型:线程数建议设置为 2 * CPU 核心数
d.示例
---
int cpuCores = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor = new ThreadPoolExecutor(
cpuCores + 1,
cpuCores + 1,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50)
);
03.忽略任务队列的选择
a.问题所在
任务队列直接影响线程池的行为。如果选错队列类型,会带来很多隐患
b.常见队列的坑
无界队列:任务无限堆积
有界队列:队列满了会触发拒绝策略
优先级队列:容易导致高优先级任务频繁抢占低优先级任务
c.示例:任务堆积导致问题
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2,
4,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);
for (int i = 0; i < 100000; i++) {
executor.submit(() -> System.out.println(Thread.currentThread().getName()));
}
d.改进方法
用有界队列,避免任务无限堆积
new ArrayBlockingQueue<>(100);
04.忘记关闭线程池
a.问题所在
有些小伙伴用完线程池后,忘记调用 shutdown(),导致程序无法正常退出
b.示例:线程池未关闭
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(() -> System.out.println("任务执行中..."));
// 线程池未关闭,程序一直运行
c.正确关闭方式
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
05.忽略拒绝策略
a.问题所在
当任务队列满时,线程池会触发拒绝策略,很多人不知道默认策略(AbortPolicy)会直接抛异常
b.示例:任务被拒绝
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1,
1,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2),
new ThreadPoolExecutor.AbortPolicy() // 默认策略
);
for (int i = 0; i < 10; i++) {
executor.submit(() -> System.out.println("任务"));
}
-----------------------------------------------------------------------------------------------------
执行到第四个任务时会抛出 RejectedExecutionException。
c.改进:选择合适的策略
CallerRunsPolicy:提交任务的线程自己执行
DiscardPolicy:直接丢弃新任务
DiscardOldestPolicy:丢弃最老的任务
06.任务中未处理异常
a.问题所在
线程池中的任务抛出异常时,线程池不会直接抛出,导致很多问题被忽略
b.示例:异常被忽略
executor.submit(() -> {
throw new RuntimeException("任务异常");
});
c.解决方法
a.捕获任务内部异常
executor.submit(() -> {
try {
throw new RuntimeException("任务异常");
} catch (Exception e) {
System.err.println("捕获异常:" + e.getMessage());
}
});
b.自定义线程工厂
ThreadFactory factory = r -> {
Thread t = new Thread(r);
t.setUncaughtExceptionHandler((thread, e) -> {
System.err.println("线程异常:" + e.getMessage());
});
return t;
};
07.阻塞任务占用线程池
a.问题所在
如果线程池中的任务是阻塞的(如文件读写、网络请求),核心线程会被占满,影响性能
b.示例:阻塞任务拖垮线程池
executor.submit(() -> {
Thread.sleep(10000); // 模拟阻塞任务
});
c.改进方法
- 减少任务的阻塞时间。
- 增加核心线程数。
- 使用异步非阻塞方式(如 NIO)。
08.滥用线程池
a.问题所在
线程池不是万能的,某些场景直接使用 new Thread() 更简单
b.示例:过度使用线程池
一个简单的短期任务:
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> System.out.println("执行任务"));
executor.shutdown();
-----------------------------------------------------------------------------------------------------
这种情况下,用线程池反而复杂。
c.改进方式
new Thread(() -> System.out.println("执行任务")).start();
09.未监控线程池状态
a.问题所在
很多人用线程池后,不监控其状态,导致任务堆积、线程耗尽的问题被忽略
b.示例:监控线程池状态
System.out.println("核心线程数:" + executor.getCorePoolSize());
System.out.println("队列大小:" + executor.getQueue().size());
System.out.println("已完成任务数:" + executor.getCompletedTaskCount());
-----------------------------------------------------------------------------------------------------
结合监控工具(如 JMX、Prometheus),实现实时监控。
10.动态调整线程池参数
a.问题所在
有些人在线程池设计时忽略了参数调整的必要性,导致后期性能优化困难
b.示例:动态调整核心线程数
executor.setCorePoolSize(20);
executor.setMaximumPoolSize(50);
-----------------------------------------------------------------------------------------------------
实时调整线程池参数,能适应业务的动态变化
2.22 [3]线程池:6个概念
01.默认情况下线程不会预创建
默认情况下,线程池不会预先创建线程,而是等到有任务到来时才创建线程
可以通过设置prestartAllCoreThreads方法来预创建核心线程
02.核心线程数
核心线程数(corePoolSize):这是线程池中始终保持活动的线程数量,即使它们处于空闲状态
当任务到来时,如果当前活动的线程数少于核心线程数,线程池会创建一个新的线程来处理任务
03.工作队列
工作队列(BlockingQueue):当核心线程数已满时,新的任务会被放入工作队列中等待执行
常见的工作队列类型包括:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue等
04.最大线程数
最大线程数(maximumPoolSize):这是线程池中允许的最大线程数量
当核心线程数已满且工作队列也已满时,线程池会创建新的线程来处理任务,直到线程数达到最大线程数
05.拒绝策略
当工作队列已满且线程数已达到最大线程数时,新的任务将被拒绝
线程池提供了几种默认的拒绝策略
1.AbortPolicy:抛出RejectedExecutionException,这是默认策略
2.CallerRunsPolicy:由调用线程处理该任务
3.DiscardPolicy:直接丢弃任务,不予处理
4.DiscardOldestPolicy:丢弃队列中最旧的未处理任务,然后尝试重新提交任务
06.空闲存活时间
空闲存活时间(keepAliveTime):这是线程池中空闲线程在终止之前等待新任务的最长时间
如果线程空闲时间超过空闲存活时间,并且当前线程数大于核心线程数,则会销毁线程,直到线程数等于核心线程数
可以通过设置allowCoreThreadTimeOut方法来允许回收核心线程
2.23 [3]线程池:异常捕获
01.问题描述
a.说明
线程执行任务时,没有添加异常处理。导致任务内部发生异常时,内部错误无法被记录下来
b.代码
Thread thread =new Thread(()->{
if (1 == 1) {
log.error("error");
throw new RuntimeException("异常了");
}
});
thread.start();
-----------------------------------------------------------------------------------------------------
可以看到,异常不会打印日志,而是输出在控制台上了
02.异常去了哪里?
a.正常来说,如果我们进行了异常捕获,是可以看到日志信息的
Thread thread = new Thread(()->{
try{
log.info("hello");
throw new RuntimeException("运行时异常了");
}catch (Exception e){
log.error("异常发生",e);
}
});
thread.start();
b.未捕获的异常
如果一个异常未被捕获,从线程中抛了出来,JVM会回调Thread类中dispatchUncaughtException方法
在这方法中,就是获取一个默认的异常的处理器
可以看到这里,他不会记录日志信息,而是将异常抛到了控制台中
03.解决方案
a.定义一个异常处理器
/**
* 自定义异常处理器(将异常时控制台输出,装变成日志输出)
*/
@Slf4j
public class MyUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread t, Throwable e) {
log.error("Exception Thread",e);
}
}
b.设置异常处理器
Thread thread =new Thread(()->{
if (1 == 1) {
log.error("error");
throw new RuntimeException("异常了");
}
});
// 设置异常处理器
thread.setUncaughtExceptionHandler(new MyUncaughtExceptionHandler());
thread.start();
-----------------------------------------------------------------------------------------------------
可以看到即使没有获取异常,抛出的异常,我们也记录在日志中
04.线程池如何进行异常处理
a.自定义线程工厂
保持原有线程工厂的能力,然后额外的配置我们自己自定义的异常处理器
-----------------------------------------------------------------------------------------------------
public class MyThreadFactory implements ThreadFactory {
private static final MyUncaughtExceptionHandler UNCAUGHT_EXCEPTION_HANDLER = new MyUncaughtExceptionHandler();
private ThreadFactory originalThreadFactory;
public MyThreadFactory(ThreadFactory originalThreadFactory) {
this.originalThreadFactory = originalThreadFactory;
}
@Override
public Thread newThread(Runnable r) {
Thread thread = originalThreadFactory.newThread(r);
// 设置我们自定义的异常处理器
thread.setUncaughtExceptionHandler(UNCAUGHT_EXCEPTION_HANDLER);
return thread;
}
}
b.在线程池中配置我们的线程池工厂
使用Spring提供的线程池
-----------------------------------------------------------------------------------------------------
@Configuration
public class ThreadPoolConfig {
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("MyExecutor-");
executor.setThreadFactory(new MyThreadFactory(executor));
executor.initialize();
return executor;
}
}
-----------------------------------------------------------------------------------------------------
new MyThreadFactory() 这里为什么可以传入这个线程池类,因为Spring中这个类本身就是一个线程工厂的类
2.24 [3]线程池:拒绝策略,4种
00.汇总
AbortPolicy 抛出异常,阻止任务继续执行
CallerRunsPolicy 由调用线程执行任务,减缓任务提交速度
DiscardPolicy 直接丢弃任务,不予处理
DiscardOldestPolicy 丢弃最旧的任务,重新尝试提交新任务
01.AbortPolicy
a.描述
直接抛出RejectedExecutionException异常,阻止系统正常工作
b.用途
这是默认的拒绝策略,适用于不希望任务被丢弃或由调用线程处理的情况
c.示例
new ThreadPoolExecutor.AbortPolicy();
02.CallerRunsPolicy
a.描述
由调用线程(提交任务的线程)来运行被拒绝的任务
b.用途
适用于希望任务不被丢弃,但可以接受任务执行速度减慢的情况
c.示例
new ThreadPoolExecutor.CallerRunsPolicy();
03.DiscardPolicy
a.描述
直接丢弃被拒绝的任务,不予处理,也不抛出异常
b.用途
适用于可以接受任务丢失的情况,例如日志记录或统计信息等非关键任务
c.示例
new ThreadPoolExecutor.DiscardPolicy();
04.DiscardOldestPolicy
a.描述
丢弃队列中最旧的未处理任务,然后重新尝试提交被拒绝的任务
b.用途
适用于希望优先处理新任务而可以接受丢弃旧任务的情况
c.示例
new ThreadPoolExecutor.DiscardOldestPolicy();
2.25 [3]线程池:回收机制,2阶段
01.两阶段回收机制
a.核心线程(corePoolSize 内的线程)
核心线程默认情况下是长期存活的,除非显式调用 allowCoreThreadTimeOut(true)
才会在空闲超过 keepAliveTime 后被回收
executor.allowCoreThreadTimeOut(true);
b.非核心线程(超过 corePoolSize 的线程)
非核心线程会在空闲超过 keepAliveTime 后自动销毁,防止资源浪费
2.26 [3]线程池:构建方法,7个参数
01.构造方法(7 个参数)
a.代码
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)
b.说明
参数名 说明
corePoolSize 核心线程数,线程池始终保持的最小线程数量
maximumPoolSize 最大线程数,线程池可创建的最大线程数
keepAliveTime 非核心线程空闲超过该时间会被销毁
unit keepAliveTime的时间单位
workQueue 用于存放等待执行的任务
threadFactory 创建新线程的工厂,可自定义线程属性
handler 当线程池无法接收新任务时的拒绝策略
02.示例:创建线程池
a.代码
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
b.说明
核心线程数为 2,最大线程数为 4
多余线程在空闲 60 秒后销毁
任务队列最多容纳 10 个任务
使用默认线程工厂创建线程
拒绝策略为 AbortPolicy,即直接抛出异常
2.27 [4]nacos动态线程池
01.依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2021.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>2021.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
02.配置yml文件
a.bootstrap.yml
server:
port: 8010
spring:
application:
name: order-service
cloud:
nacos:
discovery:
namespace: public
server-addr: 192.168.174.129:8848
config:
server-addr: 192.168.174.129:8848
file-extension: yml
b.application.yml
spring:
profiles:
active: dev
c.为什么要配置两个yml文件?
springboot中配置文件的加载是存在优先级顺序的,bootstrap优先级高于application
nacos在项目初始化时,要保证先从配置中心进行配置拉取,拉取配置之后才能保证项目的正常启动
03.nacos配置
登录到nacos管理页面,新建配置
注意Data ID的命名格式为
${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
在本文中,Data ID的名字就是order-service-dev.yml
这里我们只配置了两个参数,核心线程数量和最大线程数
04.线程池配置和nacos配置变更监听
@RefreshScope
@Configuration
public class DynamicThreadPool implements InitializingBean {
@Value("${core.size}")
private String coreSize;
@Value("${max.size}")
private String maxSize;
private static ThreadPoolExecutor threadPoolExecutor;
@Autowired
private NacosConfigManager nacosConfigManager;
@Autowired
private NacosConfigProperties nacosConfigProperties;
@Override
public void afterPropertiesSet() throws Exception {
threadPoolExecutor = new ThreadPoolExecutor(Integer.parseInt(coreSize), Integer.parseInt(maxSize), 10L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("c_t_%d").build(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("rejected!");
}
});
nacosConfigManager.getConfigService().addListener("order-service-dev.yml", nacosConfigProperties.getGroup(),
new Listener() {
@Override
public Executor getExecutor() {
return null;
}
@Override
public void receiveConfigInfo(String configInfo) {
System.out.println(configInfo);
changeThreadPoolConfig(Integer.parseInt(coreSize), Integer.parseInt(maxSize));
}
});
}
public String printThreadPoolStatus() {
return String.format("core_size:%s,thread_current_size:%s;" +
"thread_max_size:%s;queue_current_size:%s,total_task_count:%s", threadPoolExecutor.getCorePoolSize(),
threadPoolExecutor.getActiveCount(), threadPoolExecutor.getMaximumPoolSize(), threadPoolExecutor.getQueue().size(),
threadPoolExecutor.getTaskCount());
}
public void dynamicThreadPoolAddTask(int count) {
for (int i = 0; i < count; i++) {
int finalI = i;
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(finalI);
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
private void changeThreadPoolConfig(int coreSize, int maxSize) {
threadPoolExecutor.setCorePoolSize(coreSize);
threadPoolExecutor.setMaximumPoolSize(maxSize);
}
}
---------------------------------------------------------------------------------------------------------
这个代码就是实现动态线程池和核心了,需要说明的是:
@RefreshScope:这个注解用来支持nacos的动态刷新功能
@Value("${max.size}"),@Value("${core.size}"):这两个注解用来读取我们上一步在nacos配置的具体信息;同时,nacos配置变更时,能够实时读取到变更后的内容
nacosConfigManager.getConfigService().addListener:配置监听,nacos配置变更时实时修改线程池的配置
05.controller
为了观察线程池动态变更的效果,增加Controller类
---------------------------------------------------------------------------------------------------------
@RestController
@RequestMapping("/threadpool")
public class ThreadPoolController {
@Autowired
private DynamicThreadPool dynamicThreadPool;
@GetMapping("/print")
public String printThreadPoolStatus() {
return dynamicThreadPool.printThreadPoolStatus();
}
@GetMapping("/add")
public String dynamicThreadPoolAddTask(int count) {
dynamicThreadPool.dynamicThreadPoolAddTask(count);
return String.valueOf(count);
}
}
06.测试
启动项目,访问http://localhost:8010/threadpool/print打印当前线程池的配置
可以看到,这个就是我们之前在nacos配置的线程数
访问http://localhost:8010/threadpool/add?count=20增加20个任务,重新打印线程池配置
可以看到已经有线程在排队了
为了能够看到效果,我们多访问几次/add接口,增加任务数,在控制台出现拒绝信息时调整nacos配置
此时,执行/add命令时,所有的线程都会提示rejected
调整nacos配置,将核心线程数调整为50,最大线程数调整为100
重新多次访问/add接口增加任务,发现没有拒绝信息了。这时,打印具体的线程状态,发现线程池参数修改成功
2.28 [4]Hippo4j动态线程池
01.Maven依赖
<dependency>
<groupId>org.hippo4j</groupId>
<artifactId>hippo4j-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
02.application.yml
hippo4j:
core:
thread-pool:
default:
core-pool-size: 5
maximum-pool-size: 10
keep-alive-time: 60
queue-capacity: 100
03.创建一个简单的任务并提交到线程池
import org.hippo4j.core.executor.ExecutorServiceFactory;
import org.hippo4j.core.executor.HippoThreadPoolExecutor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.concurrent.ExecutorService;
@Service
public class TaskService {
@Autowired
private ExecutorServiceFactory executorServiceFactory;
public void executeTask() {
ExecutorService executorService = executorServiceFactory.create("default");
executorService.submit(() -> {
System.out.println("Task is running in thread: " + Thread.currentThread().getName());
});
}
}
2.29 [4]Dynamic-TP动态线程池
01.Maven依赖
<dependency>
<groupId>com.github.dynamic-tp</groupId>
<artifactId>dynamic-tp-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
02.application.yml
dynamic:
tp:
default:
core-pool-size: 5
maximum-pool-size: 10
keep-alive-time: 60
queue-capacity: 100
03.创建一个简单的任务并提交到线程池
import com.github.dynamic.tp.core.DynamicThreadPool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class TaskService {
@Autowired
private DynamicThreadPool dynamicThreadPool;
public void executeTask() {
dynamicThreadPool.execute(() -> {
System.out.println("Task is running in thread: " + Thread.currentThread().getName());
});
}
}
2.30 [4]PriorityBlockingQueue优先级线程池
01.思路
使用PriorityBlockingQueue作为任务队列
PriorityBlockingQueue是一个支持优先级排序的阻塞队列,它可以确保优先级高的任务先被线程池执行
02.实现步骤
定义任务类:实现Runnable接口,并实现Comparable接口,以便在PriorityBlockingQueue中进行优先级排序
使用PriorityBlockingQueue:创建一个PriorityBlockingQueue实例作为线程池的任务队列
创建线程池:使用ThreadPoolExecutor并将PriorityBlockingQueue作为其任务队列
提交任务:将任务提交到线程池,任务会根据优先级进行排序和执行
03.代码示例
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.PriorityBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class PriorityThreadPool {
public static void main(String[] args) {
// 创建优先级队列
BlockingQueue<Runnable> queue = new PriorityBlockingQueue<>();
// 创建线程池,使用优先级队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // 核心线程数
4, // 最大线程数
0L, // 空闲线程存活时间
TimeUnit.SECONDS,
queue // 使用优先级队列
);
// 提交任务到线程池
for (int i = 0; i < 10; i++) {
int priority = 10 - i; // 优先级:数字越小优先级越高
executor.execute(new PriorityTask(priority, "Task " + i));
}
// 关闭线程池
executor.shutdown();
}
// 定义优先级任务类
static class PriorityTask implements Runnable, Comparable<PriorityTask> {
private final int priority;
private final String name;
public PriorityTask(int priority, String name) {
this.priority = priority;
this.name = name;
}
@Override
public void run() {
System.out.println("Executing " + name + " with priority " + priority);
}
@Override
public int compareTo(PriorityTask other) {
// 优先级高的任务应该排在前面(数字越小优先级越大)
return Integer.compare(this.priority, other.priority);
}
}
}
04.说明
PriorityBlockingQueue:用于存储任务的优先级队列,任务会根据优先级进行排序
PriorityTask:实现了Runnable和Comparable接口,compareTo方法用于定义任务的优先级排序规则
ThreadPoolExecutor:使用PriorityBlockingQueue作为任务队列,确保任务按优先级执行
2.31 [4]DynamicThreadPool动态调整线程池
01.说明
根据系统负载动态调整线程池的参数
02.代码
public class DynamicThreadPool extends ThreadPoolExecutor {
private final ReentrantLock lock = new ReentrantLock();
public DynamicThreadPool(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public void adjustThreadPool(int corePoolSize, int maximumPoolSize) {
lock.lock();
try {
if (corePoolSize > maximumPoolSize) {
throw new IllegalArgumentException("Core pool size cannot be larger than maximum pool size");
}
super.setCorePoolSize(corePoolSize);
super.setMaximumPoolSize(maximumPoolSize);
} finally {
lock.unlock();
}
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
// 任务执行前的钩子
super.beforeExecute(t, r);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
// 任务执行后的钩子
super.afterExecute(r, t);
}
}
2.32 [4]CustomThreadFactory自定义线程工厂
01.说明
默认的线程工厂虽然能满足基本需求,但在生产环境中,我们往往需要更多的控制和监控能力
02.代码
public class CustomThreadFactory implements ThreadFactory {
private final String namePrefix;
private final AtomicInteger threadNumber = new AtomicInteger(1);
public CustomThreadFactory(String poolName) {
this.namePrefix = poolName + "-thread-";
}
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, namePrefix + threadNumber.getAndIncrement());
// 设置为守护线程
thread.setDaemon(true);
// 设置线程优先级
thread.setPriority(Thread.NORM_PRIORITY);
// 设置异常处理器
thread.setUncaughtExceptionHandler((t, e) -> {
System.err.println("Thread " + t.getName() + " threw exception: " + e.getMessage());
e.printStackTrace();
});
return thread;
}
}
00.汇总
1.ThreadUtil
2.ExecutorBuilder
3.ConcurrencyTester,简单的并发测试类
01.ThreadUtil
a.定义
Hutool使用GlobalThreadPool持有一个全局的线程池,默认所有异步方法在这个线程池中执行。
b.方法
ThreadUtil.execute:直接在公共线程池中执行线程
ThreadUtil.newExecutor:获得一个新的线程池
ThreadUtil.execAsync:执行异步方法
ThreadUtil.newCompletionService:创建CompletionService,调用其submit方法可以异步执行多个任务,最后调用take方法按照完成的顺序获得其结果。若未完成,则会阻塞。
ThreadUtil.newCountDownLatch:新建一个CountDownLatch,一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
ThreadUtil.sleep:挂起当前线程,是Thread.sleep的封装,通过返回boolean值表示是否被打断,而不是抛出异常。
ThreadUtil.safeSleep方法是一个保证挂起足够时间的方法,当给定一个挂起时间,使用此方法可以保证挂起的时间大于或等于给定时间,解决Thread.sleep挂起时间不足问题,此方法在Hutool-cron的定时器中使用保证定时任务执行的准确性。
ThreadUtil.getStackTrace:getStackTrace 获得堆栈列表、getStackTraceElement 获得堆栈项
c.方法
createThreadLocal 创建本地线程对象
interupt 结束线程,调用此方法后,线程将抛出InterruptedException异常
waitForDie 等待线程结束. 调用 Thread.join() 并忽略 InterruptedException
getThreads 获取JVM中与当前线程同组的所有线程
getMainThread 获取进程的主线程
02.ExecutorBuilder
a.定义
在JDK中,提供了Executors用于创建自定义的线程池对象ExecutorService,但是考虑到线程池中存在众多概念,
这些概念通过不同的搭配实现灵活的线程管理策略,单独使用Executors无法满足需求,构建了ExecutorBuilder。
b.概念
corePoolSize 初始池大小
maxPoolSize 最大池大小(允许同时执行的最大线程数)
workQueue 队列,用于存在未执行的线程
handler 当线程阻塞(block)时的异常处理器,所谓线程阻塞即线程池和等待队列已满,无法处理线程时采取的策略
c.线程池对待线程的策略
如果池中任务数 < corePoolSize -> 放入立即执行
如果池中任务数 > corePoolSize -> 放入队列等待
队列满 -> 新建线程立即执行
执行中的线程 > maxPoolSize -> 触发handler(RejectedExecutionHandler)异常
d.workQueue线程池策略
SynchronousQueue:它将任务直接提交给线程而不保持它们。当运行线程小于maxPoolSize时会创建新线程,否则触发异常策略
LinkedBlockingQueue:默认无界队列,当运行线程大于corePoolSize时始终放入此队列,此时maxPoolSize无效。当构造LinkedBlockingQueue对象时传入参数,变为有界队列,队列满时,运行线程小于maxPoolSize时会创建新线程,否则触发异常策略
ArrayBlockingQueue:有界队列,相对无界队列有利于控制队列大小,队列满时,运行线程小于maxPoolSize时会创建新线程,否则触发异常策略
e.配置参数
setCorePoolSize(int corePoolSize):设置线程池的核心线程数(corePoolSize)。线程池中至少会保持这个数量的线程。
setMaxPoolSize(int maxPoolSize):设置线程池的最大线程数(maximumPoolSize)。如果任务数量超过了核心线程数,并且队列已满时,会创建新的线程直到达到最大线程数。
setKeepAliveTime(long keepAliveTime):设置空闲线程的最大存活时间(keepAliveTime),即线程空闲多长时间后可以被销毁。
setKeepAliveTime(long keepAliveTime, TimeUnit unit):和上面类似,但允许同时设置时间单位(例如:秒、分钟等)。
setWorkQueue(BlockingQueue<Runnable> workQueue):设置线程池的工作队列(workQueue),用于存储待执行的任务。常用的队列类型有:
LinkedBlockingQueue(默认队列,无界队列)
ArrayBlockingQueue(有界队列)
SynchronousQueue(没有存储功能,任务直接交给线程执行)
setThreadFactory(ThreadFactory threadFactory):设置线程工厂,用于创建新线程。线程工厂可以帮助你为线程池创建自定义线程。
setRejectedExecutionHandler(RejectedExecutionHandler handler):不支持直接设置拒绝策略
设置线程池的拒绝策略(rejectedExecutionHandler),用于当线程池无法执行任务时采取的措施。常见的拒绝策略有:
AbortPolicy(默认):任务会抛出异常。
CallerRunsPolicy:任务由调用者线程执行。
DiscardPolicy:任务会被丢弃。
DiscardOldestPolicy:丢弃最旧的任务。
useSynchronousQueue():使用 SynchronousQueue 作为工作队列。此队列每个插入操作都必须等待一个线程来获取任务。
setAllowCoreThreadTimeOut(boolean allowCoreThreadTimeOut):设置是否允许核心线程在空闲时超时退出。默认为 false,即核心线程不会被回收。设置为 true 时,核心线程也会在空闲超时后被销毁。
build():完成配置并返回构建的线程池实例。
03.ConcurrencyTester-简单的并发测试类
a.定义
很多时候,我们需要简单模拟N个线程调用某个业务测试其并发状况,于是Hutool提供了一个简单的并发测试类——ConcurrencyTester。
b.代码
ConcurrencyTester tester = ThreadUtil.concurrencyTest(100, () -> {
// 测试的逻辑内容
long delay = RandomUtil.randomLong(100, 1000);
ThreadUtil.sleep(delay);
Console.log("{} test finished, delay: {}", Thread.currentThread().getName(), delay);
});
// 获取总的执行时间,单位毫秒
Console.log(tester.getInterval());
2.34 [4]Spring线程池:ThreadPoolTaskExecutor
01.Spring默认线程池:org.springframework.scheduling.concurrent.ThreadPoolTaskExecuton
a.依赖
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.26</version> <!-- 请根据实际情况选择版本 -->
</dependency>
b.配置
/**
* Spring线程池
*/
@Configuration
public class ThreadPoolConfig {
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数
// +1原因:保证线程执行完成后,第一时间有任务能补上去,最大程度利用CPU资源
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors() + 1);
// 最大线程数
// * 2 + 1原因:建议为 核心线程数的1.5倍,或者1倍
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 2 + 1);
// 任务队列
// 根据业务场景提量,设置3倍以上
executor.setQueueCapacity(100000);
// 执行自定义拒绝策略
executor.setRejectedExecutionHandler(new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 1.保存拒绝任务
// 2.通知相关负责人进行手动处理
}
});
executor.initialize();
return executor;
}
}
c.使用
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class MyService {
@Resource(name = "threadPoolTaskExecutor") // 注入线程池
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
public void executeTasks() {
for (int i = 0; i < 10; i++) {
final int taskId = i;
threadPoolTaskExecutor.execute(() -> {
String threadName = Thread.currentThread().getName();
System.out.println("线程 " + threadName + " 正在执行任务:" + taskId);
try {
Thread.sleep(2000); // 模拟任务耗时操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
System.out.println("线程 " + threadName + " 完成任务:" + taskId);
});
}
}
}
2.35 [4]ForkJoinPool线程池:分而治之
01.定义
ForkJoinPool 是一个特殊的线程池,专门用于执行 ForkJoinTask 类型的任务
ForkJoinTask 是一个抽象类,常用的子类有 RecursiveTask(用于有返回值的任务)和 RecursiveAction(用于无返回值的任务)
充分利用多核处理器的能力,通过递归地将任务分解为更小的子任务,并将这些子任务分配到多个线程中并行执行。
02.核心特点
任务分治:将一个大任务分解为多个小任务,再递归拆分,最终汇总结果。
工作窃取:如果某个线程空闲,它会尝试从其他繁忙线程的任务队列中窃取任务来执行。
支持大规模并行:适合 CPU 密集型任务。
默认线程数:等于设备的可用处理器数(Runtime.getRuntime().availableProcessors())。
03.原理
ForkJoinPool 的核心思想是“分而治之”(Divide and Conquer)
任务被分解成更小的子任务,直到子任务足够简单,可以直接解决。每个子任务可以进一步分解,形成一个任务树
ForkJoinPool 使用工作窃取算法(Work-Stealing Algorithm),即空闲的线程会从其他忙碌线程的任务队列中窃取任务,以提高 CPU 的利用率
04.常用API
a.ForkJoinPool类
ForkJoinPool(int parallelism): 创建一个具有指定并行级别的 ForkJoinPool
invoke(ForkJoinTask<V> task): 提交一个任务并等待其完成
execute(ForkJoinTask<?> task): 提交一个任务但不等待其完成
submit(ForkJoinTask<V> task): 提交一个任务并返回一个 Future 对象
b.ForkJoinTask类
fork(): 异步执行任务
join(): 等待任务完成并返回结果
invoke(): 同步执行任务并返回结果
compute(): 子类需要实现的方法,定义任务的逻辑
05.使用步骤
a.创建 ForkJoinPool
可以通过默认构造或自定义线程数创建
b.定义任务类
继承 RecursiveTask<V>(有返回值)或 RecursiveAction(无返回值)
实现 compute() 方法,在其中定义拆分逻辑
c.提交任务
使用 ForkJoinPool.invoke() 或 ForkJoinPool.submit()
d.处理结果
如果任务有返回值,通过 join() 获取
06.应用场景
a.大规模数据处理
a.说明
在需要处理大量数据的情况下,可以使用 ForkJoinPool 来并行处理数据。例如,计算一个大数组的元素之和
b.代码
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.ForkJoinPool;
class SumTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 1000;
private final int[] array;
private final int start;
private final int end;
public SumTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
long sum = 0;
for (int i = start; i < end; i++) {
sum += array[i];
}
return sum;
} else {
int mid = (start + end) / 2;
SumTask leftTask = new SumTask(array, start, mid);
SumTask rightTask = new SumTask(array, mid, end);
leftTask.fork();
long rightResult = rightTask.compute();
long leftResult = leftTask.join();
return leftResult + rightResult;
}
}
}
public class ForkJoinExample {
public static void main(String[] args) {
int[] array = new int[10000];
for (int i = 0; i < array.length; i++) {
array[i] = i;
}
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(array, 0, array.length);
long result = pool.invoke(task);
System.out.println("Sum: " + result);
}
}
b.图像处理
a.说明
在图像处理领域,可以使用 ForkJoinPool 来并行处理图像的不同部分。例如,应用滤镜或调整亮度
b.代码
import java.awt.image.BufferedImage;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;
class ImageTask extends RecursiveAction {
private static final int THRESHOLD = 100;
private final BufferedImage image;
private final int start;
private final int end;
public ImageTask(BufferedImage image, int start, int end) {
this.image = image;
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if (end - start <= THRESHOLD) {
for (int i = start; i < end; i++) {
for (int j = 0; j < image.getWidth(); j++) {
int rgb = image.getRGB(j, i);
int red = (rgb >> 16) & 0xFF;
int green = (rgb >> 8) & 0xFF;
int blue = rgb & 0xFF;
int gray = (red + green + blue) / 3;
int newRgb = (gray << 16) | (gray << 8) | gray;
image.setRGB(j, i, newRgb);
}
}
} else {
int mid = (start + end) / 2;
ImageTask topTask = new ImageTask(image, start, mid);
ImageTask bottomTask = new ImageTask(image, mid, end);
invokeAll(topTask, bottomTask);
}
}
}
public class ImageProcessingExample {
public static void main(String[] args) {
BufferedImage image = // Load your image here
ForkJoinPool pool = new ForkJoinPool();
ImageTask task = new ImageTask(image, 0, image.getHeight());
pool.invoke(task);
// Save or display the processed image
}
}
c.快速排序
a.说明
ForkJoinPool 可以用于实现并行版本的快速排序
b.代码
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;
class QuickSortTask extends RecursiveAction {
private final int[] array;
private final int start;
private final int end;
public QuickSortTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if (start < end) {
int pivotIndex = partition(array, start, end);
QuickSortTask leftTask = new QuickSortTask(array, start, pivotIndex - 1);
QuickSortTask rightTask = new QuickSortTask(array, pivotIndex + 1, end);
invokeAll(leftTask, rightTask);
}
}
private int partition(int[] array, int start, int end) {
int pivot = array[end];
int i = start - 1;
for (int j = start; j < end; j++) {
if (array[j] <= pivot) {
i++;
swap(array, i, j);
}
}
swap(array, i + 1, end);
return i + 1;
}
private void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
public class QuickSortExample {
public static void main(String[] args) {
int[] array = {3, 5, 1, 2, 4, 8, 7, 6};
ForkJoinPool pool = new ForkJoinPool();
QuickSortTask task = new QuickSortTask(array, 0, array.length - 1);
pool.invoke(task);
for (int num : array) {
System.out.print(num + " ");
}
}
}
2.36 [4]ThreadPoolExecutor线程池:阿里规约推荐
01.定义
ThreadPoolExecutor是Java中的一种线程池实现,
它继承自 ExecutorService 接口,用于管理一组线程,重复执行多个任务
线程池可以有效地减少线程创建和销毁的开销,并且通过控制线程数来避免过多线程导致的资源浪费
02.工作原理
线程池维护了一组工作线程,任务通过 execute() 或 submit() 方法提交到线程池
线程池会根据任务数和配置的参数,动态地调整工作线程的数量,以适应任务的处理
03.常见API
b.构造函数
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
其他构造函数允许指定 ThreadFactory 和 RejectedExecutionHandler
c.方法
execute(Runnable command): 提交一个任务用于执行
submit(Callable<T> task): 提交一个返回值的任务,并返回一个 Future
shutdown(): 启动有序关闭,不再接受新任务
shutdownNow(): 试图停止所有正在执行的任务,并返回等待执行的任务列表
getPoolSize(): 返回线程池中当前线程的数量
getActiveCount(): 返回正在执行任务的线程的数量
04.重要说明
a.核心参数
corePoolSize: 线程池中保持活动的最小线程数
maximumPoolSize: 线程池中允许的最大线程数
keepAliveTime: 当线程池中的线程数量超过 corePoolSize 时,空闲线程存活的最大时间
workQueue: 用于保存待执行任务的队列。例如:ArrayBlockingQueue,LinkedBlockingQueue 等
ThreadFactory: 用于创建新的线程
RejectedExecutionHandler: 当线程池无法处理任务时的处理策略,例如:拒绝任务
b.拒绝策略
AbortPolicy(默认策略):如果线程池无法处理任务,会抛出 RejectedExecutionException
CallerRunsPolicy:如果线程池无法处理任务,调用者线程会执行这个任务。可以用来降低提交任务的速度
DiscardPolicy:如果线程池无法处理任务,直接丢弃这个任务,不抛出异常
DiscardOldestPolicy:如果线程池无法处理任务,丢弃任务队列中最老的任务,并尝试提交当前任务
05.使用步骤
a.创建线程池
根据需求配置 ThreadPoolExecutor 的参数
b.提交任务
使用 execute() 或 submit() 方法提交任务
c.管理线程池
根据需要调用 shutdown() 或 shutdownNow() 关闭线程
06.应用场景
a.简单任务执行
a.说明
在需要执行大量短时间任务的情况下,可以使用 ThreadPoolExecutor 来管理线程的创建和销
b.代码
import java.util.concurrent.*;
public class SimpleTaskExample {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
for (int i = 0; i < 10; i++) {
executor.execute(() -> {
System.out.println("Task executed by " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
}
b.处理带返回值的任务
a.说明
使用 submit() 方法可以提交 Callable 任务,并获取返回值
b.代码
import java.util.concurrent.*;
public class CallableTaskExample {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
Future<Integer> future = executor.submit(() -> {
Thread.sleep(1000);
return 42;
});
System.out.println("Result: " + future.get());
executor.shutdown();
}
}
c.自定义拒绝策略
a.说明
当任务无法被执行时,可以自定义拒绝策略
b.代码
import java.util.concurrent.*;
public class RejectionPolicyExample {
public static void main(String[] args) {
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(2), handler);
for (int i = 0; i < 10; i++) {
executor.execute(() -> {
System.out.println("Task executed by " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
}
d.定时任务执行
a.说明
虽然 ThreadPoolExecutor 本身不支持定时任务,但可以结合 ScheduledThreadPoolExecutor 来实现
b.代码
import java.util.concurrent.*;
public class ScheduledTaskExample {
public static void main(String[] args) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
executor.scheduleAtFixedRate(() -> {
System.out.println("Scheduled task executed by " + Thread.currentThread().getName());
}, 0, 1, TimeUnit.SECONDS);
// 运行一段时间后关闭
executor.schedule(() -> executor.shutdown(), 10, TimeUnit.SECONDS);
}
}
07.应用场景2
a.示例
public class Demo04 {
public static void main(String[] args) {
// 创建一个线程池,核心池大小为 2,最大池大小为 4,空闲线程最多存活 60 秒,任务队列为无界队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // corePoolSize
4, // maximumPoolSize
60, // keepAliveTime
TimeUnit.SECONDS, // 时间单位
new LinkedBlockingQueue<>(), // 工作队列
Executors.defaultThreadFactory(), // 线程工厂
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:由调用者线程执行任务
);
// 提交 6 个任务,超过核心线程数,部分任务会被分配到空闲线程上
for (int i = 0; i < 6; i++) {
int taskId = i;
executor.execute(() -> {
System.out.println("Task " + taskId + " is being processed by " + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 提交 6 个任务,超过核心线程数,部分任务会被分配到空闲线程上
for (int i = 0; i < 6; i++) {
int taskId = i;
// 使用 submit 提交一个 Callable 任务
Future<Integer> future = executor.submit(() -> {
System.out.println("Task " + taskId + " is being processed by " + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 返回任务的结果
return taskId * 2;
});
try {
// 获取任务的执行结果
Integer result = future.get();
System.out.println("Task " + taskId + " completed with result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
// 关闭线程池
executor.shutdown();
}
}
-----------------------------------------------------------------------------------------------------
该示例创建了一个线程池 ThreadPoolExecutor,核心池大小为 2,最大池大小为 4。线程池中的线程最多空闲 60 秒,任务队列是一个 LinkedBlockingQueue(默认是无界的)。
提交了 6 个任务,线程池首先会启动 2 个线程来执行任务,剩余任务会被放入任务队列中,等待空闲线程来处理。如果有线程空闲,线程池会创建新线程(最多 4 个线程)来处理任务。
任务执行过程中,每个任务都会打印任务 ID 和当前处理任务的线程名字。
使用 shutdown() 方法关闭线程池。
b.示例
package com.ruoyi.exam3.thread;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
// ThreadPoolExecutor,阿里规约要求使用该线程池来创建
public class Demo03 {
public void testMethodExecution() {
// 创建线程池来并行请求分页数据
ThreadPoolExecutor executorService = new ThreadPoolExecutor(
2, // 核心线程数
2, // 最大线程数
30, // 空闲线程的存活时间
TimeUnit.SECONDS, // 时间单位
new ArrayBlockingQueue<>(5), // 工作队列
Executors.defaultThreadFactory(), // 默认线程工厂
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
CountDownLatch latch = new CountDownLatch(2); // 计数器,等待两个线程完成
for (int i = 0; i < 2; i++) {
executorService.execute(() -> {
try {
sayHi("submit");
} catch (RuntimeException e) {
System.err.println("线程执行异常: " + e.getMessage());
} finally {
latch.countDown();
}
});
}
try {
// 等待所有线程完成
latch.await();
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 恢复线程的中断状态
System.err.println("主线程等待被中断: " + e.getMessage());
} finally {
// 关闭线程池
executorService.shutdown();
}
}
private static void sayHi(String name) {
String printStr = "【thread-name:" + Thread.currentThread().getName() + ", 执行方式:" + name + "】";
System.out.println(printStr);
// 模拟异常,可以根据实际需求开启
throw new RuntimeException(printStr + ", 我异常啦!哈哈哈!");
}
public static void main(String[] args) {
Demo03 main = new Demo03();
main.testMethodExecution();
}
}
-----------------------------------------------------------------------------------------------------
ThreadPoolExecutor 是 Java 中的一个线程池实现,用于管理一组线程。
核心线程数 (corePoolSize):设定线程池的核心线程数为 2,即线程池至少保持两个线程处于运行状态,除非线程池被关闭。
最大线程数 (maximumPoolSize):设定线程池能够创建的最大线程数为 2,表示线程池最多可以创建两个线程来处理任务。此时,线程池的线程数不能超过 2,并且没有动态扩容。
空闲线程存活时间 (keepAliveTime):如果线程池中的线程数超过核心线程数且空闲超过 30 秒,它将被销毁。这里线程池的大小不会超出 2,所以空闲线程的销毁策略在本例中不会起作用。
时间单位 (TimeUnit):30 秒为空闲线程存活时间的单位。
工作队列 (workQueue):ArrayBlockingQueue<>(5) 是一个容量为 5 的阻塞队列,用于保存待执行的任务。如果线程池中没有空闲线程,并且工作队列已满,那么提交的任务会被拒绝,具体拒绝策略由 CallerRunsPolicy 决定。
线程工厂 (ThreadFactory):这里使用 Executors.defaultThreadFactory(),这是一个默认的线程工厂,它会为每个新创建的线程分配一个默认的线程名。
拒绝策略 (RejectedExecutionHandler):CallerRunsPolicy 表示当线程池拒绝执行任务时,任务会由提交任务的线程来执行。这种策略会导致当前线程执行该任务,而不是丢弃任务或抛出异常。
-----------------------------------------------------------------------------------------------------
CountDownLatch 的使用
CountDownLatch latch = new CountDownLatch(2); // 计数器,等待两个线程完成
CountDownLatch 用于控制主线程等待其他线程的完成。在这个例子中,CountDownLatch 被设置为 2,即等待两个子线程完成任务后,主线程才会继续执行。
latch.countDown() 在每个线程执行完毕后调用,减少计数。
latch.await() 在主线程中调用,它会让主线程等待,直到计数器变为 0(即所有任务完成)。
-----------------------------------------------------------------------------------------------------
提交任务到线程池
通过 executorService.execute() 提交两个任务,每个任务都会执行 sayHi("submit") 方法。
任务执行时,打印当前线程的名字,并且执行 sayHi 方法。该方法模拟抛出异常。
如果任务执行过程中出现异常,会被 catch 块捕获并打印异常信息。
最后,不论任务是否成功执行,都会调用 latch.countDown() 来减少计数。
-----------------------------------------------------------------------------------------------------
主线程等待所有线程完成
主线程通过调用 latch.await() 等待 CountDownLatch 的计数器减到 0,即等待两个子线程执行完毕。
如果主线程在等待过程中被中断,会捕获 InterruptedException 并恢复中断状态。
最后,不论任务是否完成,都会调用 executorService.shutdown() 来关闭线程池。
2.37 [5]FutureTask编排线程
01.定义
它实现了 Runnable 和 Future 接口,因此可以被用作任务提交给 ExecutorService 执行,也可以直接在一个线程中运行
它可以用于异步计算,并提供了检查任务是否完成、等待任务完成、取消任务等功能
02.原理
FutureTask 的核心原理是将任务的执行与结果的获取分离
任务可以在一个线程中执行,而结果可以在另一个线程中获取
FutureTask 内部维护了任务的状态(如未开始、正在运行、已完成、已取消等)
并通过同步机制确保任务结果的安全获取
03.常用API
a.构造函数
FutureTask(Callable<V> callable): 使用 Callable 创建一个 FutureTask
FutureTask(Runnable runnable, V result): 使用 Runnable 创建一个 FutureTask,并指定返回结果
b.方法
run(): 执行任务
get(): 获取任务的结果,阻塞直到任务完成
get(long timeout, TimeUnit unit): 在指定时间内获取任务的结果
cancel(boolean mayInterruptIfRunning): 取消任务
isDone(): 检查任务是否已完成
isCancelled(): 检查任务是否已取消
04.使用步骤
a.创建任务
使用 Callable 或 Runnable 创建 FutureTask 实例
b.执行任务
将 FutureTask 提交给 ExecutorService 或在一个线程中执行
c.获取结果
使用 get() 方法获取任务结果
d.取消任务
根据需要调用 cancel() 方法取消任务
05.应用场景及代码示例
a.使用 Callable 创建异步任务:使用 FutureTask 包装 Callable,并在单独的线程中执行
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<Integer> callable = () -> {
Thread.sleep(1000);
return 42;
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread thread = new Thread(futureTask);
thread.start();
System.out.println("Result: " + futureTask.get());
}
}
b.使用 Runnable 创建异步任务:使用 FutureTask 包装 Runnable,并在 ExecutorService 中执行
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
public class RunnableExample {
public static void main(String[] args) throws Exception {
Runnable runnable = () -> {
try {
Thread.sleep(1000);
System.out.println("Task completed");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
};
FutureTask<Void> futureTask = new FutureTask<>(runnable, null);
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(futureTask);
futureTask.get(); // Wait for the task to complete
executor.shutdown();
}
}
c.取消一个正在执行的任务
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class CancelTaskExample {
public static void main(String[] args) {
Callable<Integer> callable = () -> {
Thread.sleep(2000);
return 42;
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(500); // Simulate some delay
boolean cancelled = futureTask.cancel(true);
System.out.println("Task cancelled: " + cancelled);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
d.检查任务是否完成或取消
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class TaskStatusExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<Integer> callable = () -> {
Thread.sleep(1000);
return 42;
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread thread = new Thread(futureTask);
thread.start();
while (!futureTask.isDone()) {
System.out.println("Task is not done yet...");
Thread.sleep(200);
}
System.out.println("Task completed with result: " + futureTask.get());
}
}
3 CompletableFuture
3.1 [1]介绍
01.定义
它是 Future 接口的增强版,提供了更强大的功能来处理异步编程和并发任务
支持非阻塞的异步操作,并提供了丰富的 API 来组合多个异步任务
一个可以显式完成的 Future,它不仅可以用于表示异步计算的结果,还可以用于构建复杂的异步任务流水线。
02.原理
CompletableFuture 的核心思想是通过回调机制来处理异步任务
它允许在任务完成时自动触发后续操作,而无需显式地等待任务完成
CompletableFuture 提供了多种方法来组合和处理多个异步任务,包括串行执行、并行执行、异常处理等
03.特点
异步编程:能够非阻塞地执行任务,不会阻塞主线程
回调机制:支持注册多个回调(thenApply, thenAccept, thenRun 等),当异步任务完成时自动执行回调
链式调用:能够对异步操作结果进行进一步处理,支持操作结果的组合
组合多个 CompletableFuture:可以将多个异步任务组合成一个复杂的任务
等待结果:支持使用 join() 或 get() 等方法等待计算结果
04.常用API
a.创建和完成
supplyAsync(Supplier<U> supplier): 异步执行一个返回结果的任务
runAsync(Runnable runnable): 异步执行一个不返回结果的任务
complete(T value): 手动完成 CompletableFuture 并设置结果
completeExceptionally(Throwable ex): 手动完成 CompletableFuture 并设置异常
b.组合和处理
thenApply(Function<? super T,? extends U> fn): 任务完成后应用函数并返回新的 CompletableFuture
thenAccept(Consumer<? super T> action): 任务完成后执行操作,不返回结果
thenRun(Runnable action): 任务完成后执行操作,不关心结果
thenCombine(CompletableFuture<? extends U> other, BiFunction<? super T,? super U,? extends V> fn): 组合两个 CompletableFuture 的结果
thenCompose(Function<? super T,? extends CompletionStage<U>> fn): 任务完成后应用函数并返回新的 CompletableFuture
c.异常处理
exceptionally(Function<Throwable,? extends T> fn): 处理异常并返回默认值
handle(BiFunction<? super T,Throwable,? extends U> fn): 处理正常结果或异常
05.使用步骤
a.创建异步任务
使用 supplyAsync() 或 runAsync() 方法创建异步任务
b.组合和处理任务
使用 thenApply()、thenAccept() 等方法组合和处理任务
c.处理异常
使用 exceptionally() 或 handle() 方法处理可能的异常
d.获取结果
使用 get() 或 join() 方法获取任务结果
06.应用场景及代码示例
a.异步计算
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class AsyncCalculationExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new IllegalStateException(e);
}
return 42;
});
System.out.println("Result: " + future.get());
}
}
b.组合多个异步任务
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class TaskCombinationExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> 10);
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> 20);
CompletableFuture<Integer> combinedFuture = future1.thenCombine(future2, Integer::sum);
System.out.println("Combined Result: " + combinedFuture.get());
}
}
c.处理异步任务中的异常
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ExceptionHandlingExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
if (true) {
throw new RuntimeException("Exception occurred!");
}
return 42;
}).exceptionally(ex -> {
System.out.println("Exception: " + ex.getMessage());
return 0;
});
System.out.println("Result: " + future.get());
}
}
d.串行执行多个异步任务
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class SerialTaskExecutionExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> "Hello")
.thenApply(result -> result + " World")
.thenAccept(System.out::println);
future.get();
}
}
e.并行执行多个异步任务并等待所有任务完成
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ParallelTaskExecutionExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000);
System.out.println("Task 1 completed");
} catch (InterruptedException e) {
throw new IllegalStateException(e);
}
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(500);
System.out.println("Task 2 completed");
} catch (InterruptedException e) {
throw new IllegalStateException(e);
}
});
CompletableFuture<Void> allOf = CompletableFuture.allOf(future1, future2);
allOf.get();
}
}
3.2 [1]工具类:异步请求
01.场景
构建一个处理HTTP请求的异步框架。这个框架要能处理大量并发请求,还得优雅地处理超时和错误情况
02.代码
public class AsyncHttpClient {
private final ExecutorService executor;
private final int timeout;
public AsyncHttpClient(int threadPoolSize, int timeoutSeconds) {
this.executor = Executors.newFixedThreadPool(threadPoolSize);
this.timeout = timeoutSeconds;
}
public CompletableFuture<String> asyncGet(String url) {
return CompletableFuture.supplyAsync(() -> {
try {
// 模拟HTTP请求
if (Math.random() < 0.1) { // 10%概率模拟超时
Thread.sleep(timeout * 1000 + 1000);
}
return "Response from " + url;
} catch (InterruptedException e) {
throw new CompletionException(e);
}
}, executor)
.orTimeout(timeout, TimeUnit.SECONDS)
.exceptionally(throwable -> {
if (throwable instanceof TimeoutException) {
return "请求超时了:" + url;
}
return "请求出错:" + throwable.getMessage();
});
}
// 批量处理请求
public List<String> batchGet(List<String> urls) {
List<CompletableFuture<String>> futures = urls.stream()
.map(this::asyncGet)
.collect(Collectors.toList());
return futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
public void shutdown() {
executor.shutdown();
}
}
03.测试类
AsyncHttpClient client = new AsyncHttpClient(10, 5); // 10个线程,5秒超时
List<String> urls = Arrays.asList(
"http://api1.example.com",
"http://api2.example.com",
"http://api3.example.com"
);
// 异步处理多个请求
List<String> results = client.batchGet(urls);
results.forEach(System.out::println);
client.shutdown();
04.说明
使用线程池管理并发请求
统一的超时处理机制
优雅的错误处理
支持批量请求处理
资源可控,不会造成内存泄露
3.3 [1]工具类:枚举 + CompletableFuture + 自定义线程池
00.设计
枚举 + CompletableFuture + 自定义线程池
01.工具类
package com.pilot.meterage.web.utils;
import cn.hutool.core.date.LocalDateTimeUtil;
import cn.hutool.core.util.ObjectUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.annotation.Nonnull;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.function.Supplier;
import java.util.stream.Collectors;
/**
* 使用 CompletableFuture 实现简单的线程池
*
* @author yangp
*/
public enum CompletableFutureSimpleThreadPool {
/**
* 单例对象
*/
INSTANCE;
/**
* 自定义线程池,用于执行任务
*/
private final ThreadPoolExecutor singleThreadPool;
/**
* 初始化线程池,并设置线程池参数
*/
CompletableFutureSimpleThreadPool() {
// 初始化线程池,核心线程数为15,最大线程数为20,线程空闲超时时间为30秒
singleThreadPool = new ThreadPoolExecutor(
15, 20,
30L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
r -> new Thread(r, "CompletableFutureUtils - " + r.hashCode())
);
}
private static final Logger log = LoggerFactory.getLogger(CompletableFutureSimpleThreadPool.class);
// JVM 关闭时自动关闭线程池
static {
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
log.info("[线程池] JVM 关闭前自动关闭线程池...");
INSTANCE.shutdown();
}));
}
/**
* 执行多个任务(无返回值)
*
* @param tasks 任务数组
*/
public static void executeTasks(@Nonnull Runnable... tasks) {
if (ObjectUtil.isEmpty(tasks)) {
logCheckTaskIsEmpty();
return;
}
long start = logTaskStart();
// 使用线程池并行执行多个任务
CompletableFuture<?>[] futures = Arrays.stream(tasks)
.map(task -> CompletableFuture.runAsync(() -> {
try {
task.run();
} catch (Exception e) {
log.error("任务执行失败", e);
}
}, INSTANCE.singleThreadPool))
.toArray(CompletableFuture[]::new);
// 打印线程池状态
logThreadPoolStatus();
// 等待所有任务执行完成
CompletableFuture.allOf(futures).join();
logTaskEnd(start);
}
/**
* 执行多个任务(有返回值,使用 CompletableFuture 作为任务)
*
* @param tasks 任务数组
* @return 任务执行结果的列表
*/
@SafeVarargs
public static <T> List<T> executeCompletableFutures(@Nonnull CompletableFuture<T>... tasks) {
List<T> results;
if (ObjectUtil.isEmpty(tasks)) {
logCheckTaskIsEmpty();
return Collections.emptyList();
}
long start = logTaskStart();
// 使用 allOf 等待所有任务完成
CompletableFuture<Void> allOf = CompletableFuture.allOf(tasks);
allOf.join();
// 收集任务结果
results = Arrays.stream(tasks)
.map(CompletableFuture::join)
.collect(Collectors.toList());
logTaskEnd(start);
return results;
}
/**
* 执行多个任务(有返回值,使用 Supplier 作为任务)
*
* @param tasks 任务数组
* @return 任务执行结果的列表
*/
@SafeVarargs
public static <T> List<T> executeSuppliers(@Nonnull Supplier<T>... tasks) {
List<T> results;
if (ObjectUtil.isEmpty(tasks)) {
logCheckTaskIsEmpty();
return Collections.emptyList();
}
long start = logTaskStart();
// 执行多个任务并收集结果
List<CompletableFuture<T>> futures = Arrays.stream(tasks)
.map(task -> CompletableFuture.supplyAsync(() -> {
try {
return task.get();
} catch (Exception e) {
log.error("任务执行失败", e);
return null; // 或者可以选择抛出 RuntimeException
}
}, INSTANCE.singleThreadPool))
.collect(Collectors.toList());
// 打印线程池状态
logThreadPoolStatus();
// 获取所有任务的执行结果
results = futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
logTaskEnd(start);
return results;
}
/**
* 记录线程池当前的状态,包括当前线程池大小和任务数量
*/
private static void logThreadPoolStatus() {
log.info("[线程池状态] 池大小:{},活跃线程数:{},排队任务数:{},总任务数:{},完成任务数:{}",
INSTANCE.singleThreadPool.getPoolSize(),
INSTANCE.singleThreadPool.getActiveCount(),
INSTANCE.singleThreadPool.getQueue().size(),
INSTANCE.singleThreadPool.getTaskCount(),
INSTANCE.singleThreadPool.getCompletedTaskCount());
}
/**
* 记录任务为空的情况
*/
private static void logCheckTaskIsEmpty() {
log.error("[线程池][执行任务] 任务为空");
}
/**
* 记录任务开始执行
*/
private static long logTaskStart() {
long startTime = System.currentTimeMillis();
log.info("[线程池][执行任务] 开始时间:{},开始执行任务", LocalDateTimeUtil.now());
return startTime;
}
/**
* 记录任务执行结束
*/
private static void logTaskEnd(long start) {
log.info("[线程池][执行任务] 结束时间:{},执行任务结束,耗时:{}ms", LocalDateTimeUtil.now(), System.currentTimeMillis() - start);
}
/**
* 关闭线程池(单例线程池应该在 JVM 关闭时才被终止)
*/
public void shutdown() {
log.info("[线程池] 正在关闭线程池...");
singleThreadPool.shutdown();
try {
if (!singleThreadPool.awaitTermination(SHUTDOWN_TIMEOUT_SECONDS, TimeUnit.SECONDS)) {
log.warn("[线程池] 线程池未在规定时间内关闭,强制关闭");
singleThreadPool.shutdownNow();
}
log.info("[线程池] 线程池已关闭");
} catch (InterruptedException e) {
log.error("[线程池] 线程池关闭时被中断", e);
singleThreadPool.shutdownNow();
Thread.currentThread().interrupt();
}
}
/**
* 线程池关闭超时时间(单位:秒)
*/
public static final long SHUTDOWN_TIMEOUT_SECONDS = 60;
}
02.测试类
package com.pilot.meterage;
import com.pilot.meterage.web.MainApplication;
import com.pilot.meterage.web.utils.CompletableFutureSimpleThreadPool;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
import java.util.concurrent.CompletableFuture;
/**
* @Author: yangp
* @Date: 2024/11/12 14:41
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = MainApplication.class)
public class CompletableFutureTest {
@Test
public void test02() {
Runnable run1 = () -> {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("run1");
};
Runnable run2 = () -> {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("run2");
};
Runnable run3 = () -> {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("run3");
};
Runnable run4 = () -> {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("run4");
};
CompletableFutureSimpleThreadPool.executeTasks(run1, run2, run3, run4);
System.out.println("test02 执行完毕");
}
@Test
public void test03() {
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(CompletableFutureTest::getData1);
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(CompletableFutureTest::getData2);
CompletableFuture<String> future3 = CompletableFuture.supplyAsync(CompletableFutureTest::getData3);
List<String> res = CompletableFutureSimpleThreadPool.executeCompletableFutures(future1, future2, future3);
System.out.println(res);
System.out.println("test03 执行完毕");
}
@Test
public void test04() {
List<String> res = CompletableFutureSimpleThreadPool.executeSuppliers(CompletableFutureTest::getData1, CompletableFutureTest::getData2, CompletableFutureTest::getData3);
System.out.println(res);
System.out.println("test04 执行完毕");
}
public static String getData1() {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("data1执行完毕");
return "data1";
}
public static String getData2() {
// 模拟耗时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("data2执行完毕");
return "data2";
}
public static String getData3() {
// 模拟耗时
try {
Thread.sleep(6000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("data3执行完毕");
return "data3";
}
}
3.4 [1]关键字:get/join、handle、runAsync/supplyAsync、whenComplete/exceptionally、thenCompose /thenCombine、thenAccept/thenApply、thenApply/thenApplyAsync
00.汇总
对于不需要返回结果的任务,使用 runAsync
对于需要返回结果的任务,使用 supplyAsync
在任务完成后,无论是否成功,都要执行某些操作时,使用 whenComplete 或 whenCompleteAsync
仅在任务发生异常时处理异常并提供替代结果,使用 exceptionally
处理任务结果但不返回新值时,使用 thenAccept
处理任务结果并返回新值时,使用 thenApply 或 thenApplyAsync。根据是否需要异步执行选择同步或异步版本
01.get/join
a.get
a.get()
等待CompletableFuture执行完成并获取其具体执行结果,可能会抛出异常,需要代码调用的地方手动try...catch进行处理
b.get(long, TimeUnit)
与get()相同,只是允许设定阻塞等待超时时间,如果等待超过设定时间,则会抛出异常终止阻塞等待
b.join
a.join()
等待CompletableFuture执行完成并获取其具体执行结果,可能会抛出运行时异常,无需代码调用的地方手动try...catch进行处理
02.handle()
a.说明
handle() 方法允许你在任务完成(无论正常完成还是出现异常)后对结果进行处理
它接受一个 BiFunction 参数,该函数会在任务完成时被调用,可以处理结果或异常
不会将异常外抛
b.代码
CompletableFuture<Integer> divide(int a, int b) {
return CompletableFuture.supplyAsync(() -> a / b)
.handle((result, ex) -> {
if (ex != null) {
System.out.println(ex.getMessage());
return 0;
} else {
return result;
}
});
}
try {
System.out.println("成功结果:" + divide(6, 3).get());
System.out.println("异常结果:" + divide(6, 0).get());
} catch (Exception exception) {
System.out.println("捕获到异常:" + exception.getMessage());
}
c.输出
成功结果:2
java.lang.ArithmeticException: / by zero
异常结果:0
03.runAsync/supplyAsync
a.runAsync
runAsync 方法用于启动一个没有返回值的异步任务
该方法通常用于那些不需要返回结果的任务,例如记录日志、发送通知等
b.supplyAsync
supplyAsync 方法用于启动一个有返回值的异步任务
该方法通常用于需要返回结果的任务,例如计算结果、获取数据等
c.代码
public class Demo01 {
public static void main(String[] args) throws Exception {
supplyAsync();
System.out.println("main来了");
SleepUtils.sleep(3);
}
//发起一个异步请求
public static void runAsync() {
CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"你好runAsync");
SleepUtils.sleep(10);
}
});
}
//发起一个异步请求
public static void supplyAsync() throws Exception {
CompletableFuture<String> supplyFuture = CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
System.out.println(Thread.currentThread().getName() + "你好supplyAsync");
SleepUtils.sleep(2);
return "java0518";
}
});
//这是一个阻塞方法
System.out.println(Thread.currentThread().getName()+"--->:"+supplyFuture.get());
}
}
04.whenComplete/exceptionally
a.whenComplete()
a.说明
whenComplete() 方法允许你访问当前 CompletableFuture 的结果和异常作为参数,并执行你想要的操作
它不会转换完成的结果,但会在内部处理异常
b.代码
CompletableFuture<Integer> whenComplete(int a, int b) {
return CompletableFuture.supplyAsync(() -> a / b)
.whenComplete((result, ex) -> {
if (ex != null) {
System.out.println("whenComplete 处理异常:" + ex.getMessage());
}
});
}
try {
System.out.println("成功结果:" + whenComplete(6, 3).get());
System.out.println("异常结果:" + whenComplete(6, 0).get());
} catch (Exception exception) {
System.out.println("捕获到异常:" + exception.getMessage());
}
c.输出
成功结果:2
whenComplete 处理异常:java.lang.ArithmeticException: / by zero
b.exceptionally()
a.说明
exceptionally() 方法仅处理异常情况,即发生异常时执行
如果可完成的未来成功完成,内部逻辑将被跳过,不会将内部异常抛出
b.代码
CompletableFuture<Integer> exceptionally(int a, int b) {
return CompletableFuture.supplyAsync(() -> a / b)
.exceptionally(ex -> {
System.out.println("exceptionally 处理异常:" + ex.getMessage());
return 0;
});
}
try {
System.out.println("成功结果:" + exceptionally(6, 3).get());
System.out.println("异常结果:" + exceptionally(6, 0).get());
} catch (Exception exception) {
System.out.println("捕获到异常:" + exception.getMessage());
}
c.输出
成功结果:2
exceptionally 处理异常:java.lang.ArithmeticException: / by zero
05.thenCompose /thenCombine
a.thenCompose
a.说明
使用 thenCompose 连接异步任务时,通常用于处理异步任务的返回值作为下一个任务的输入
b.代码
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> divide(int a, int b) {
return CompletableFuture.supplyAsync(() -> a / b)
.thenCompose(result -> CompletableFuture.supplyAsync(() -> {
// Perform additional processing using the result
return result * 2;
}));
}
System.out.println("Result for 6 / 3: " + divide(6, 3).get());
}
b.thenCombine
a.说明
使用 thenCombine 合并两个任务的结果时,不考虑先后顺序,而是并行执行并合并结果
b.代码
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Dept> getDept = CompletableFuture.supplyAsync(() -> getDeptById(1));
CompletableFuture<User> getUser = CompletableFuture.supplyAsync(() -> getUserById(1));
CompletableFuture<User> combinedResult = getDept.thenCombine(getUser, (dept, user) -> {
// Combine results from both tasks
user.setDeptId(dept.getId());
user.setDeptName(dept.getName());
return user;
});
System.out.println("Combined result: " + combinedResult.get());
}
06.thenAccept/thenApply
a.说明
thenAccept:用于处理异步任务的结果,但不返回新的值。适合用于打印日志、执行操作等场景
thenApply:用于处理异步任务的结果,并返回新的值。适合用于转换数据、链式处理等场景
b.代码
public class Demo04 {
public static void main(String[] args) throws Exception {
supplyAsync();
System.out.println("main来了");
SleepUtils.sleep(8);
}
//发起一个异步请求
public static void supplyAsync() throws Exception {
CompletableFuture<String> supplyFuture = CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
System.out.println(Thread.currentThread().getName() + "你好supplyAsync");
SleepUtils.sleep(2);
return "java0518";
}
});
supplyFuture.thenAccept(new Consumer<String>() {
@Override
public void accept(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName()+"第一个accept接受到的值"+acceptVal);
}
});
supplyFuture.thenAccept(new Consumer<String>() {
@Override
public void accept(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName()+"第二个accept接受到的值"+acceptVal);
}
});
}
}
c.代码
public class Demo05 {
public static void main(String[] args) throws Exception {
supplyAsync();
System.out.println("main来了");
SleepUtils.sleep(8);
}
//发起一个异步请求
public static void supplyAsync() throws Exception {
CompletableFuture<String> supplyFuture = CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
System.out.println(Thread.currentThread().getName() + "你好supplyAsync");
SleepUtils.sleep(2);
return "java0518";
}
});
CompletableFuture<String> thenApply1 = supplyFuture.thenApply(new Function<String, String>() {
@Override
public String apply(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName() + "第一个thenApply接受到的值" + acceptVal);
return "apply1" + acceptVal;
}
});
CompletableFuture<String> thenApply2 = supplyFuture.thenApply(new Function<String, String>() {
@Override
public String apply(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName() + "第二个thenApply接受到的值" + acceptVal);
return "apply2" + acceptVal;
}
});
System.out.println(thenApply1.get());
System.out.println(thenApply2.get());
}
}
07.thenApply/thenApplyAsync
a.thenApply
使用调用它的 CompletableFuture 的同一个线程或完成该 CompletableFuture 的线程来执行处理函数
如果前面的阶段已经完成,处理函数可能会在调用线程中被同步执行
适用于对执行时间要求不严格且处理时间较短的任务
b.thenApplyAsync
使用 ForkJoinPool.commonPool() 或者自定义的线程池来异步执行处理函数
总是异步地执行处理函数,不管前面的阶段是否已经完成
适用于需要异步执行、处理时间较长或需要非阻塞执行的任务
执行上下文:thenApply 在同一个线程或调用线程中同步执行,而 thenApplyAsync 总是异步地执行,使用公共线程池或自定义的线程池
适用场景:thenApply 适用于对执行时间要求不严格的短任务,thenApplyAsync 适用于需要非阻塞异步执行的长任务或需要使用特定线程池的任务
c.代码
public class Demo06 {
public static void main(String[] args) throws Exception {
supplyAsync();
System.out.println("main来了");
SleepUtils.sleep(8);
}
//发起一个异步请求
public static void supplyAsync() throws Exception {
CompletableFuture<String> supplyFuture = CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
System.out.println(Thread.currentThread().getName() + "你好supplyAsync");
SleepUtils.sleep(2);
return "java0518";
}
});
CompletableFuture<String> thenApply1 = supplyFuture.thenApplyAsync(new Function<String, String>() {
@Override
public String apply(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName() + "第一个thenApply接受到的值" + acceptVal);
return "apply1" + acceptVal;
}
});
CompletableFuture<String> thenApply2 = supplyFuture.thenApplyAsync(new Function<String, String>() {
@Override
public String apply(String acceptVal) {
SleepUtils.sleep(2);
System.out.println(Thread.currentThread().getName() + "第二个thenApply接受到的值" + acceptVal);
return "apply2" + acceptVal;
}
});
System.out.println(thenApply1.get());
System.out.println(thenApply2.get());
}
}
3.5 [2]普通请求:thenApply、thenCompose
00.汇总
thenApply 是做转换用的,比如把 A 转成 B
thenCompose 是用来组合另一个异步操作的,避免Future套Future
01.代码
// 错误示范:用 thenApply 导致嵌套的 Future
CompletableFuture<CompletableFuture<String>> nested =
CompletableFuture.supplyAsync(() -> "Hello")
.thenApply(s -> CompletableFuture.supplyAsync(() -> s + " World"));
// 正确做法:用 thenCompose 保持链式调用
CompletableFuture<String> better =
CompletableFuture.supplyAsync(() -> "Hello")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + " World"));
02.总结
如果你的转换函数返回的是另一个 CompletableFuture
那就用 thenCompose,否则用 thenApply。这样代码就不会陷入"套娃"地狱了
3.6 [2]并发请求:allof、anyof
00.汇总
allOf:等待所有任务完成
anyOf:只要有一个任务完成
01.处理多个异步任务
在实际开发中,我们经常需要处理多个异步任务。有时候需要等所有任务都完成,有时候只要其中一个完成就行
02.allOf:等待所有任务-完成
a.说明
先了解一下CompletableFuture.allOf()的基本用法
它接收多个CompletableFuture作为参数,返回一个新的CompletableFuture
这个新的Future会在所有任务都完成时才完成
b.代码
CompletableFuture<Void> allOf = CompletableFuture.allOf(
future1, future2, future3
);
c.说明
听起来有点抽象?举个例子来理解。
比方说你在准备一顿丰盛的午饭。你需要煮饭、炒菜、煲汤,这些任务可以同时进行,但午饭必须等所有菜品都准备好才能开始。
用代码来表达就是:
d.代码
CompletableFuture<String> cookRice = CompletableFuture
.supplyAsync(() -> {
// 模拟煮饭
sleep(1000);
return "饭已就位";
});
CompletableFuture<String> stirFry = CompletableFuture
.supplyAsync(() -> {
// 模拟炒菜
sleep(2000);
return "炒完了";
});
CompletableFuture<String> makeSoup = CompletableFuture
.supplyAsync(() -> {
// 模拟煲汤
sleep(3000);
return "汤煮好了";
});
// 等待所有任务完成
CompletableFuture.allOf(cookRice, stirFry, makeSoup)
.thenRun(() -> {
System.out.println("所有准备工作已完成,可以开始吃饭了!");
});
e.说明
每个任务都是独立的CompletableFuture
通过allOf()将它们组合在一起
thenRun()是在所有任务完成后,执行回调
三个任务是并行执行的,总耗时则取决于最慢的那个任务
03.anyOf:只要有一个任务完成
a.说明
而CompletableFuture.anyOf()则是另一种场景:只要有一个任务完成就可以继续
b.代码
CompletableFuture<Object> anyOf = CompletableFuture.anyOf(
future1, future2, future3
);
c.说明
这就像什么呢?设想你在等网约车,同时打开了滴滴、高德和美团三个平台叫车
只要有一个平台接单了,你就可以出发。这就是CompletableFuture.anyOf()的典型场景
d.代码
CompletableFuture<Object> taxi = CompletableFuture.anyOf(
callDidi(), // 叫滴滴
callGaode(), // 叫高德
callMeituan() // 叫美团
);
taxi.thenAccept(platform -> System.out.println(platform + "接单了,出发!"));
-----------------------------------------------------------------------------------------------------
通过anyOf()接收多个CompletableFuture后,返回最先完成的任务结果,虽然其他任务可能仍在继续执行,但结果会被忽略
c.实战案例:并行请求多个微服务
a.场景
理解了基本概念,让我们来看一个比较典型的业务场景:商品详情页。
假设你正在开发一个电商平台的商品详情页,需要同时获取:
商品基本信息
库存数据
价格信息
用户评价
这些数据分别来自不同的微服务。如果串行请求这些服务,页面加载会非常慢
如果使用CompletableFuture,就可以优雅地实现并行请求
b.代码
public ProductDetailVO getProductDetail(Long productId) {
// 1. 创建多个异步任务
CompletableFuture<ProductInfo> productFuture = CompletableFuture
.supplyAsync(() -> productService.getProductInfo(productId));
CompletableFuture<Stock> stockFuture = CompletableFuture
.supplyAsync(() -> stockService.getStock(productId));
CompletableFuture<Price> priceFuture = CompletableFuture
.supplyAsync(() -> priceService.getPrice(productId));
CompletableFuture<List<Review>> reviewsFuture = CompletableFuture
.supplyAsync(() -> reviewService.getReviews(productId));
// 2. 等待所有数据都准备好
return CompletableFuture.allOf(
productFuture, stockFuture, priceFuture, reviewsFuture)
.thenApply(v -> {
// 3. 组装最终结果
return new ProductDetailVO(
productFuture.join(), // 获取每个任务的结果
stockFuture.join(),
priceFuture.join(),
reviewsFuture.join()
);
}).join(); // 4. 等待最终结果
}
c.说明
让我们解读一下上面这段代码:
首先,我们为每个微服务调用创建了一个异步任务
使用allOf()等待所有任务完成
用thenApply()组装最终结果
最后用join()获取组装好的完整的商品数据
-------------------------------------------------------------------------------------------------
这样做的好处是显而易见的:
四个请求并行执行,减少了总耗时
代码结构清晰,易于维护
异常处理可以统一管理
扩展性好,随时可以添加新的数据源
d.小贴士
a.说明
在实际项目中,记得加上超时控制和异常处理
毕竟在分布式环境下,网络请求随时可能失败
可以使用orTimeout()或completeOnTimeout()来优雅地处理超时情况
b.代码
// 为每个请求添加3秒超时
CompletableFuture<ProductInfo> productFuture = CompletableFuture
.supplyAsync(() -> productService.getProductInfo(productId))
.orTimeout(3, TimeUnit.SECONDS) // 超时控制
.exceptionally(ex -> {
log.error("获取商品信息失败", ex);
return new ProductInfo(); // 返回默认值
});
c.说明
这样,即使某个服务出现问题,也不会影响整个页面的展示
3.7 [2]并发请求:请求多个微服务
01.场景
假设你正在开发一个电商平台的商品详情页,需要同时获取:
商品基本信息
库存数据
价格信息
用户评价
这些数据分别来自不同的微服务
02.如果串行请求这些服务,页面加载会非常慢,如果使用CompletableFuture,就可以优雅地实现并行请求
public ProductDetailVO getProductDetail(Long productId) {
// 1. 创建多个异步任务
CompletableFuture<ProductInfo> productFuture = CompletableFuture
.supplyAsync(() -> productService.getProductInfo(productId));
CompletableFuture<Stock> stockFuture = CompletableFuture
.supplyAsync(() -> stockService.getStock(productId));
CompletableFuture<Price> priceFuture = CompletableFuture
.supplyAsync(() -> priceService.getPrice(productId));
CompletableFuture<List<Review>> reviewsFuture = CompletableFuture
.supplyAsync(() -> reviewService.getReviews(productId));
// 2. 等待所有数据都准备好
return CompletableFuture.allOf(
productFuture, stockFuture, priceFuture, reviewsFuture)
.thenApply(v -> {
// 3. 组装最终结果
return new ProductDetailVO(
productFuture.join(), // 获取每个任务的结果
stockFuture.join(),
priceFuture.join(),
reviewsFuture.join()
);
}).join(); // 4. 等待最终结果
}
03.说明
首先,我们为每个微服务调用创建了一个异步任务
使用allOf()等待所有任务完成
用thenApply()组装最终结果
最后用join()获取组装好的完整的商品数据
04.优点
四个请求并行执行,减少了总耗时
代码结构清晰,易于维护
异常处理可以统一管理
扩展性好,随时可以添加新的数据源
3.8 [2]取消请求:cancel
01.场景
假设你正在点外卖。下单后,外卖小哥已经接单开始配送,这时你突然接到老板的紧急电话,说要马上去客户那里开会
没办法,只能忍痛取消订单了。这就很像我们在程序中需要取消一个正在执行的异步任务的情况
02.代码
// 不推荐的写法 - 没有合理的取消处理
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(5000); // 假装在做一些耗时的事情
return "任务完成";
} catch (InterruptedException e) {
return "任务被中断";
}
});
// 推荐的写法 - 优雅地处理取消操作
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
for (int i = 0; i < 5; i++) {
// 随时检查是否被要求停止
if (Thread.currentThread().isInterrupted()) {
throw new CompletionException(new InterruptedException("任务被取消"));
}
Thread.sleep(1000);
}
return "任务完成";
} catch (InterruptedException e) {
throw new CompletionException(e);
}
});
// 发出取消指令
boolean cancelled = future.cancel(true);
03.说明
cancel(boolean mayInterruptIfRunning) 方法返回boolean值,表示取消是否成功
一旦任务被取消,就像泼出去的水,覆水难收,后面的所有操作都不会执行了
所以在写任务的时候,一定要好好处理 InterruptedException,不然可能会留下隐患
3.9 [2]捕获异常:exceptionally
01.定义
CompletableFuture提供了一种优雅的方式来处理异步任务的结果和异常
通过使用CompletableFuture,主线程可以捕获和处理子线程中发生的自定义异常
02.实现步骤
创建CompletableFuture:使用CompletableFuture.supplyAsync()或CompletableFuture.runAsync()来启动异步任务
处理异常:使用exceptionally()方法来处理异步任务中发生的异常
获取结果:使用join()或get()方法来获取异步任务的结果或处理异常
03.代码示例
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class CompletableFutureExceptionHandling {
public static void main(String[] args) {
// 创建一个CompletableFuture,执行异步任务
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// 模拟子线程中的任务
if (Math.random() > 0.5) {
throw new CustomException("An error occurred in the async task");
}
return "Task completed successfully";
});
// 处理异步任务中的异常
CompletableFuture<String> handledFuture = future.exceptionally(ex -> {
System.out.println("Exception caught: " + ex.getMessage());
return "Default result due to exception";
});
// 获取结果
try {
String result = handledFuture.get();
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
// 自定义异常类
static class CustomException extends RuntimeException {
public CustomException(String message) {
super(message);
}
}
}
04.说明
CompletableFuture.supplyAsync():用于启动一个异步任务,该任务返回一个结果
exceptionally():用于处理异步任务中发生的异常。可以在此方法中记录异常信息并返回一个默认结果
get():用于获取异步任务的结果。如果任务抛出异常,get()方法会抛出ExecutionException
自定义异常:CustomException是一个自定义异常类,用于模拟子线程中的异常情况
3.10 [3]坑点:6个
00.汇总
1.默认线程池的坑
2.异常处理的坑
3.超时处理的坑
4.线程上下文传递的坑
5.回调地狱的坑
6.任务编排,执行顺序混乱的坑
00.示例
a.场景
假设我们有两个任务服务,一个查询用户基本信息,一个是查询用户勋章信息
b.代码
public class FutureTest {
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
UserInfoService userInfoService = new UserInfoService();
MedalService medalService = new MedalService();
long userId =666L;
long startTime = System.currentTimeMillis();
//调用用户服务获取用户基本信息
CompletableFuture<UserInfo> completableUserInfoFuture = CompletableFuture.supplyAsync(() -> userInfoService.getUserInfo(userId));
Thread.sleep(300); //模拟主线程其它操作耗时
CompletableFuture<MedalInfo> completableMedalInfoFuture = CompletableFuture.supplyAsync(() -> medalService.getMedalInfo(userId));
UserInfo userInfo = completableUserInfoFuture.get(2,TimeUnit.SECONDS);//获取个人信息结果
MedalInfo medalInfo = completableMedalInfoFuture.get();//获取勋章信息结果
System.out.println("总共用时" + (System.currentTimeMillis() - startTime) + "ms");
}
}
01.默认线程池的坑
a.说明
CompletableFuture默认使用ForkJoinPool.commonPool() 作为线程池
如果任务阻塞或执行时间过长,可能会导致线程池耗尽,影响其他任务的执行
b.反例
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// 模拟长时间任务
try {
Thread.sleep(10000);
System.out.println("捡田螺的小男孩666");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
future.join();
c.正例
手动创建线程池(核心参数可配置化)
-----------------------------------------------------------------------------------------------------
int corePoolSize = 10; // 核心线程数
int maxPoolSize = 10; // 最大线程数(固定大小)
long keepAliveTime = 0L; // 非核心线程空闲存活时间(固定线程池可设为0)
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(100); // 有界队列(容量100)
RejectedExecutionHandler rejectionHandler = new ThreadPoolExecutor.AbortPolicy(); // 拒绝策略
ExecutorService customExecutor = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
keepAliveTime,
TimeUnit.MILLISECONDS,
workQueue,
rejectionHandler
);
// 提交异步任务
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(10000); // 模拟耗时任务
System.out.println("捡田螺的小男孩666");
System.out.println("Task completed");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, customExecutor);
// 阻塞等待任务完成
future.join();
02.异常处理的坑
a.说明
如果CompletableFuture 中的任务抛出异常,跟我们使用的传统try...catch有点不一样。
使用 exceptionally 或 handle 方法来处理异常。
b.代码
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException("田螺测试异常!");
});
future.exceptionally(ex -> {
System.err.println("异常: " + ex.getMessage());
return -1; // 返回默认值
}).join();
c.运行结果
异常: java.lang.RuntimeException: 田螺测试异常!
03.超时处理的坑
a.说明
CompletableFuture 本身不支持超时处理,如果任务长时间不完成,可能会导致程序一直等待
b.反例
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(10000); //模拟任务耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
});
future.join(); // 程序会一直等待
c.正例
如果你是JDK8,使用 get() 方法并捕获 TimeoutException
-----------------------------------------------------------------------------------------------------
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
});
future.join(); // 程序会一直等待
try {
Integer result = future.get(3, TimeUnit.SECONDS); // 设置超时时间为1秒
System.out.println("田螺等待3秒之后:"+result);
} catch (TimeoutException e) {
System.out.println("Task timed out");
future.cancel(true); // 取消任务
} catch (Exception e) {
e.printStackTrace();
}
-----------------------------------------------------------------------------------------------------
如果你是Java 9 或更高版本,可以直接使用 orTimeout 和 completeOnTimeout 方法:
-----------------------------------------------------------------------------------------------------
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
}).orTimeout(3, TimeUnit.SECONDS); // 3秒超时
future.exceptionally(ex -> {
System.err.println("Timeout: " + ex.getMessage());
return -1;
}).join();
04.线程上下文传递的坑
A.说明
CompletableFuture 默认不会传递线程上下文(如 ThreadLocal),这可能导致上下文丢失
b.反例
ThreadLocal<String> threadLocal = new ThreadLocal<>();
threadLocal.set("田螺主线程");
CompletableFuture.runAsync(() -> {
System.out.println(threadLocal.get()); // 输出 null
}).join();
c.正例
使用CompletableFuture 的supplyAsync 或 runAsync时,手动传递上下文。
---
ThreadLocal<String> threadLocal = new ThreadLocal<>();
threadLocal.set("田螺主线程");
ExecutorService executor = Executors.newFixedThreadPool(1);
CompletableFuture.runAsync(() -> {
threadLocal.set("田螺子线程");
System.out.println(threadLocal.get()); // 输出田螺子线程
}, executor).join();
05.回调地狱的坑
a.说明
CompletableFuture 的回调地狱指的是在异步编程中
过度依赖回调方法(如 thenApply、thenAccept 等)导致代码嵌套过深、难以维护的现象
b.反例
CompletableFuture.supplyAsync(() -> 1)
.thenApply(result -> {
System.out.println("Step 1: " + result);
return result + 1;
})
.thenApply(result -> {
System.out.println("Step 2: " + result);
return result + 1;
})
.thenAccept(result -> {
System.out.println("Step 3: " + result);
});
c.正例
通过链式调用和方法拆分,保持代码简洁:
-----------------------------------------------------------------------------------------------------
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> 1)
.thenApply(this::step1)
.thenApply(this::step2);
future.thenAccept(this::step3);
// 拆分逻辑到单独方法
private int step1(int result) {
System.out.println("Step 1: " + result);
return result + 1;
}
private int step2(int result) {
System.out.println("Step 2: " + result);
return result + 1;
}
private void step3(int result) {
System.out.println("Step 3: " + result);
}
06.任务编排,执行顺序混乱的坑
a.说明
任务编排时,如果任务之间有依赖关系,可能会导致任务无法按预期顺序执行
b.反例
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> 1);
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> 2);
CompletableFuture<Integer> result = future1.thenCombine(future2, (a, b) -> a + b);
result.join(); // 可能不会按预期顺序执行
c.正例
使用 thenCompose 或 thenApply 来确保任务顺序
-----------------------------------------------------------------------------------------------------
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> 1);
CompletableFuture<Integer> future2 = future1.thenApply(a -> a + 2);
future2.join(); // 确保顺序执行
3.11 [3]坑点:死锁预防
01.场景
这里的死锁和数据库的死锁概念不太一样,举个简单的例子:两个I人在微信上聊天,但是互相都在等对方先发消息
结果两个人都一直在等,谁也不主动,这就陷入了死锁
02.代码
// 容易产生死锁的写法
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
try {
return future2.get(); // 等待future2的结果
} catch (Exception e) {
return "error";
}
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
try {
return future1.get(); // 等待future1的结果
} catch (Exception e) {
return "error";
}
});
03.说明
两个future互相等待,不可避免的产生了死锁问题。
要解决这个问题,最简单的办法就是设置一个等待超时时间。
04.代码
// 推荐的写法 - 使用超时机制
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
try {
return future2.get(1, TimeUnit.SECONDS); // 设置超时时间
} catch (TimeoutException e) {
return "超时";
} catch (Exception e) {
return "error";
}
});
05.总结
别让任务互相等待对方,也就是避免循环依赖
设置合理的超时时间
用 thenCompose 来代替直接 get()
合理规划任务执行顺序,提前想好任务该怎么排队执行
3.12 [3]坑点:默认线程池
00.把线程池交给一个专门的管理类
public class AsyncExecutor implements AutoCloseable {
private final ExecutorService executor;
public AsyncExecutor(int threadCount) {
this.executor = Executors.newFixedThreadPool(threadCount);
}
public <T> CompletableFuture<T> submit(Supplier<T> task) {
return CompletableFuture.supplyAsync(task, executor);
}
@Override
public void close() {
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
}
}
01.默认线程池的问题
a.代码
// 不推荐:使用默认的ForkJoinPool
// 问题:共享的ForkJoinPool可能被其他任务占满,导致你的任务无法及时执行
CompletableFuture.supplyAsync(() -> doSomething());
// 推荐:指定自定义线程池
// 优势:可控的线程数量,避免资源争抢,便于监控和管理
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletableFuture.supplyAsync(() -> doSomething(), executor);
b.说明
默认的ForkJoinPool是JVM级别共享的,线程数通常等于CPU核心数-1
在高并发场景下,如果有大量CPU密集型任务,可能会导致线程饥饿
c.代码
// 实际案例:模拟订单处理系统
public class OrderProcessor {
// 错误示范
public CompletableFuture<OrderResult> processOrder(Order order) {
return CompletableFuture.supplyAsync(() -> validateOrder(order))
.thenApply(this::calculatePrice)
.thenApply(this::applyDiscount);
}
// 优化版本
private final ExecutorService orderExecutor = Executors.newFixedThreadPool(
20,
new ThreadFactoryBuilder()
.setNameFormat("order-processor-%d")
.setDaemon(true)
.build()
);
public CompletableFuture<OrderResult> processOrder(Order order) {
return CompletableFuture.supplyAsync(() -> validateOrder(order), orderExecutor)
.thenApply(this::calculatePrice)
.thenApply(this::applyDiscount);
}
}
3.13 [3]坑点:线程池切换
01.避免不必要的线程切换
a.代码
// 反模式:过度使用异步转换
CompletableFuture.supplyAsync(() -> fetchUserData()) // 线程A
.thenApply(user -> enrichUserData(user)) // 可能切换到线程B
.thenApply(user -> formatUserData(user)) // 可能切换到线程C
.thenAccept(user -> saveToCache(user)); // 可能切换到线程D
// 最佳实践:合理规划异步边界
CompletableFuture.supplyAsync(() -> fetchUserData(), ioExecutor) // IO操作使用IO线程池
.thenApplyAsync(user -> {
// 计算密集型操作使用计算线程池
user = enrichUserData(user);
user = formatUserData(user);
return user;
}, computeExecutor)
.thenAccept(user -> saveToCache(user)); // 与上游使用相同线程
b.说明
每次线程切换都会带来上下文切换开销,包括:
保存当前线程的执行状态
加载新线程的执行状态
可能的CPU缓存失效
线程调度开销
3.14 [3]坑点:主子线程退出
01.事情的根本原因
a.问题描述
主线程退出时,异步线程被强制中断了
由于没有对异步任务进行适当的生命周期管理,主线程在完成初步的任务后直接退出
导致与主线程相关联的所有异步线程也被强制终止
b.影响
异步线程在进行数据处理和外部 API 调用时被中断,导致未完成的任务丢失,数据处理中断,API 请求未能完成
c.原因
没有充分理解 CompletableFuture 和线程池管理的关键区别,特别是线程池管理下
异步任务的生命周期不受主线程的影响,而直接使用 CompletableFuture.runAsync()启动的任务依赖于主线程的生命周期
02.异步线程与主线程的生命周期关系
a.Java 中的线程类型
a.用户线程(User Thread)
用户线程是默认的线程类型,所有普通线程都属于用户线程。用户线程的生命周期由 JVM 管理
只要有一个用户线程在运行,JVM 就不会退出
b.守护线程(Daemon Thread)
守护线程是由开发者手动设置的线程类型。守护线程的生命周期依赖于非守护线程
当所有非守护线程执行完毕时,JVM 会自动退出并终止所有守护线程
b.主线程退出时,异步线程的行为
在没有线程池管理的情况下,Java 启动的异步线程会被视为用户线程
如果主线程退出时,JVM 会检查是否还有其他活跃的用户线程
如果没有,JVM 会终止进程,强制终止所有用户线程,包括异步线程
c.问题展示
使用 CompletableFuture.runAsync() 启动异步线程时
如果主线程未调用 join() 或其他显式阻塞操作,且未使用线程池管理异步线程
主线程可能会提前退出,导致异步线程被强制中断
03.如何确保异步线程在主线程退出后继续执行
a.使用守护线程
将异步线程设置为守护线程。守护线程的生命周期不依赖于主线程,只要有用户线程存在,守护线程就会继续执行
CompletableFuture.runAsync(() -> {
Thread.currentThread().setDaemon(true); // 设置当前线程为守护线程
try {
Thread.sleep(5000);
System.out.println("异步任务完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
b.使用线程池(ExecutorService)
使用线程池可以更细致地控制线程的生命周期。线程池中的线程不受主线程的控制,它们会根据任务的完成情况独立退出
import java.util.concurrent.*;
public class AsyncTestWithExecutor {
private static ExecutorService executorService = Executors.newSingleThreadExecutor(); // 使用线程池
public static void main(String[] args) throws InterruptedException {
CompletableFuture<Void> usbDetectionFuture = CompletableFuture.runAsync(() -> startUsbListening("someConfig"), executorService)
.thenRun(() -> System.out.println("USB 监听任务完成"));
System.out.println("主线程退出,但异步任务仍在后台运行...");
Thread.sleep(5000); // 模拟主线程退出
executorService.shutdownNow(); // 停止线程池
}
public static void startUsbListening(String configValue) {
System.out.println("初始化 startUsbListening");
while (true) {
System.out.println("获取设备列表中...");
try {
Thread.sleep(2000); // 每 2 秒检测一次设备变化
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}
c.显式阻塞主线程
显式地阻塞主线程,直到异步任务执行完成。通过 join() 等方法,可以确保主线程等待所有异步任务完成后再退出
CompletableFuture<Void> usbDetectionFuture = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(5000);
System.out.println("异步任务完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
usbDetectionFuture.join(); // 阻塞主线程,等待异步任务完成
04.教训与反思
a.反思
对于异步编程,尤其是 CompletableFuture 等并发工具的使用,必须理解其背后的线程管理机制
特别是在主线程退出时,异步线程的生命周期是如何受到影响的
b.改进
学会更加谨慎地管理线程的生命周期,避免直接依赖于主线程的退出
在线上环境中,任何看似简单的并发操作,都需要通过线程池进行细粒度的控制,确保任务的正确执行
3.15 [3]坑点:合理处理异常
01.合理处理异常
a.代码
// 不推荐:简单的异常处理
completableFuture.exceptionally(ex -> {
log.error("操作失败", ex);
return null; // 丢失了异常上下文
});
// 最佳实践:结构化的异常处理
public class Result<T> {
private final T data;
private final boolean success;
private final String errorCode;
private final String errorMessage;
// ... 构造方法和访问器
}
CompletableFuture<Result<UserData>> future = CompletableFuture
.supplyAsync(() -> fetchUserData())
.handle((data, ex) -> {
if (ex != null) {
log.error("获取用户数据失败", ex);
if (ex instanceof TimeoutException) {
return Result.error("TIMEOUT", "服务调用超时");
} else if (ex instanceof IllegalArgumentException) {
return Result.error("INVALID_PARAM", "参数错误");
}
return Result.error("SYSTEM_ERROR", "系统异常");
}
return Result.success(data);
});
02.异常处理的误区
a.说明
实话,异常处理可能是用 CompletableFuture 最容易翻车的地方了
很多开发者习惯了传统的 try-catch 模式,在使用 CompletableFuture 时容易忽略专门的异常处理
b.最常见的问题是异常被静默吞掉
// 错误示范
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
if (true) throw new RuntimeException("糟糕,出错了!");
return "成功";
});
future.thenAccept(System.out::println); // 这里异常被吞掉了,什么都看不到
c.这种情况下,如果发生异常,我们在日志中完全看不到任何错误信息,这对问题排查非常不利,正确的做法是要始终添加异常处理
future
.thenAccept(System.out::println)
.exceptionally(throwable -> {
System.err.println("捕获到异常:" + throwable.getMessage());
return null;
});
3.16 [3]坑点:不要迭代阻塞
00.建议
a.allFastFail
实际上是最常使用的任务编排策略,很多业务上的allOf,实际上都是allFastFail
推荐使用 CFFU 开源类库实现相关功能
b.使用异步任务拓展库CFFU 和原生实现组合多个异步操作
确保它们并行执行并非阻塞地等待所有操作完成
c.避免在迭代过程中调用阻塞方法
join()、get()
d.只有在最终处理结果时才进行必要的阻塞操作
例如调用 join() 以返回最终结果
01.代码示例
a.代码
Integer size = req.getPageSize();
Integer num = req.getCurrentPage();
String redisKey = StringUtils.join(req.getSearchIds(), ",") + "--timeCycle:" + req.getTimeCycle();
String redisCache = (String) redisUniteUtil.get(redisKey);
if (Objects.nonNull(redisCache)) {
List<String> cacheOptions = JSONObject.parseArray(redisCache, String.class);
return getOptionsVO(cacheOptions, num, size);
}
List<String> options = req.getSearchIds().stream()
.map(id -> new QueryOptionReq().setDataSource(req.getDataSource()).setFieldName(req.getFieldName())
.setSearchId(id).setTableName(req.getTableName())
.setTimeCycle(req.getTimeCycle()).setSearchIds(req.getSearchIds()))
.map(newReq -> CompletableFuture.supplyAsync(() -> queryOneOptions(newReq), almQueryThreadPool))
.collect(Collectors.toList())
.stream()
.map(CompletableFuture::join)
.map(OptionsVO::getOptionList)
.flatMap(Collection::stream)
.distinct()
.collect(Collectors.toList());
redisUniteUtil.set(redisKey, JSON.toJSONString(options), 90L, TimeUnit.SECONDS);
return getOptionsVO(options, num, size);
b.说明
a.参数 size,num 可以 inline
技巧是 Replace Temp with Query
b.Redis 缓存处理硬编码
可以抽取出方法,比如 CacheUtils#queryOptions:(ids, timeCycle) -> Optional<List<String>> 使用Optional可以提示用户处理缓存为空的情况, CacheUtils#saveOptions 方便后续可能更改失效时间
c.Objects.nonNull
改成 xxx != null
d.流处理中间调用了 toList
可以新增一个临时变量 cfs 表示。这里必须要先终止流,因为要先创建所有的 CompletableFuture
e.使用 builder 模式实现对象创建
Setter 可以改成 wither
03.不要在迭代中使用阻塞方法
a.问题描述
在迭代中使用阻塞方法(例如 CompletableFuture::join)会导致失去异步编程的优势
b.问题分析
a.阻塞主线程,失去异步的好处
join() 会阻塞当前线程,直到异步任务完成
如果在迭代中使用 join(),即使用的是异步方法,实际上仍然会一个接一个地等待每个任务完成
-------------------------------------------------------------------------------------------------
searchIds.stream()
.map(id -> CompletableFuture.supplyAsync(() -> query(id)))
.map(future -> future.join()) // 这里阻塞了
.collect(Collectors.toList());
b.无法充分利用并行性
异步操作的好处之一是它可以释放主线程,让它继续执行其他任务
使用 join() 或其他阻塞方法后,主线程就无法进行其他有意义的工作
c.死锁风险
在复杂的依赖链中使用 join(),可能会引发死锁
例如,两个线程可能在等待彼此的完成,导致程序陷入僵局
c.正确的做法:非阻塞组合结果
可以通过 CompletableFuture.allOf() 等方式等待所有异步任务完成
并使用 thenApply 或 thenCompose 来处理结果,而不是在每个任务完成时同步等待
04.任务编排策略
a.概述
Java 原生提供了两种并发任务编排策略,allOf 和 anyOf,实际上指的是allCompleteOf 和 anyCompleteOf
异常也视为值,应用了函数式编程的思想
b.缺点
无法有效使用返回值,返回类型分别是 CompletableFuture<Void> , CompletableFuture<Object>
c.CFFU 开源类库实现的方法
a.allSuccess
所有任务均正常返回结果,若其中一个任务异常完成,方法结果设置为默认值
b.anySuccess
任一任务返回正常结果时,返回其结果;若所有任务异常完成,则返回异常结果
c.allFastFail
当任务异常时,方法返回结果为异常
d.mostSuccess
同 allSuccess类似,加入了超时时间
d.方法签名
public static <T> CompletableFuture<List<T>> mSupplyAllSuccessAsync(@Nullable T valueIfFailed, Supplier<? extends T>... suppliers);
public static <T> CompletableFuture<List<T>> mSupplyFastFailAsync(Supplier<? extends T>... suppliers);
public static <T> CompletableFuture<List<T>> mSupplyMostSuccessAsync(
@Nullable T valueIfNotSuccess, long timeout, TimeUnit unit, Supplier<? extends T>... suppliers);
public static <T> CompletableFuture<T> mSupplyAnySuccessAsync(Supplier<? extends T>... suppliers);
05.重构代码
a.重构后的代码:添加了异常处理,仅在最后需要时使用join
Optional<OptionsVO> result = CacheUtils.queryOptions(req.getSearchIds(), req.getTimeCycle())
.map(options -> getOptionsVO(options, req.getNum(), req.getSize()));
if (result.isPresent()) return result.get();
CompletableFuture<List<String>>[] cfs = req.getSearchIds().stream()
.map(id -> QueryOptionReq.builder()
.dataSource(req.getDataSource())
.fieldName(req.getFieldName())
.searchId(id)
.tableName(req.getTableName())
.timeCycle(req.getTimeCycle())
.searchIds(req.getSearchIds())
.build())
.map(newReq -> supplyAsync(() -> queryOneOptions(newReq), almQueryThreadPool)
.exceptionally(ex -> {
// 处理异常,打印日志或执行其他处理
log.error("Error fetching options for searchId {}", newReq.getSearchId(), ex);
return Collections.<String>emptyList(); // 这里处理成返回空列表, allSuccess 策略。需要根据业务要求处理异常。
}))
.toArray(CompletableFuture[]::new);
List<String> options = CompletableFuture.allOf(cfs)
.thenApplyAsync(__ -> Arrays.stream(cfs)
.map(CompletableFuture::join)
.map(OptionsVO::getOptionList)
.flatMap(Collection::stream)
.distinct()
.collect(toList()), almQueryThreadPool)
.join();
RedisUtils.saveOptionsCache(options);
return getOptionsVO(options, req.getNum(), req.getSize());
b.在方法最后使用join
// implB: 最后使用join
return CompletableFuture.allOf(cfs)
.thenApplyAsync(__ -> Arrays.stream(cfs)
.map(CompletableFuture::join)
.map(OptionsVO::getOptionList)
.flatMap(Collection::stream)
.distinct()
.collect(toList()), almQueryThreadPool)
.thenApplyAsync(options -> {
RedisUtils.saveOptionsCache(options);
return getOptionsVO(options, req.getNum(), req.getSize())
}, almQueryThreadPool)
.join();
06.CFFU实现
a.代码
Supplier<List<String>[] suppliers = req.getSearchIds().stream()
.map(id -> QueryOptionReq.builder()
.dataSource(req.getDataSource())
.fieldName(req.getFieldName())
.searchId(id)
.tableName(req.getTableName())
.timeCycle(req.getTimeCycle())
.searchIds(req.getSearchIds())
.build())
// 这里注意需要指定类型
.<Supplier<List<String>>>map(newReq -> () -> queryOneOptions(newReq))
.toArray(Supplier[]::new);
CompletableFuture<List<List<String>>> cfs = CompletableFutureUtils.mSupplyAllSuccessAsync(emptyList(), almQueryThreadPool, suppliers); // 这里为了演示返回类型创建了临时变量cfs,实践中不需要
List<String> options = cfs
.thenApplyAsync(list -> list.stream()
.flatMap(Collection::stream)
.distinct()
.collect(toList()), almQueryThreadPool)
.join(); // 后续操作略
b.说明
若想实现 快速失败策略
直接更改方法 CompletableFutureUtils#mSupplyAllSuccessAsync 为 mSupplyFastFailAsync 即可
3.17 [4]优化:批量任务
01.场景
在实际业务场景中,我们经常需要并行处理大量任务,比如批量发送消息、批量处理订单等
但简单地将所有任务转换为CompletableFuture并行执行可能会带来以下问题:
线程资源消耗过快,甚至耗尽
内存压力过大
系统CPU占用过高,负载陡增
02.这里提供一个BatchProcessor作为参考
// 不推荐:直接转换为CompletableFuture列表
List<CompletableFuture<Result>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> task.execute()))
.collect(Collectors.toList());
// 推荐:控制并发度
public class BatchProcessor {
private final ExecutorService executor;
private final int maxConcurrency;
// 优化版本:带有限流和监控的批处理执行器
public <T> List<T> executeBatch(List<Supplier<T>> tasks) {
Semaphore semaphore = new Semaphore(maxConcurrency);
AtomicInteger activeTaskCount = new AtomicInteger(0);
AtomicInteger completedTaskCount = new AtomicInteger(0);
List<CompletableFuture<T>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> {
try {
semaphore.acquire();
activeTaskCount.incrementAndGet();
return task.get();
} catch (Exception e) {
throw new CompletionException(e);
} finally {
semaphore.release();
activeTaskCount.decrementAndGet();
completedTaskCount.incrementAndGet();
}
}, executor))
.collect(Collectors.toList());
// 添加批处理进度监控
CompletableFuture.runAsync(() -> {
while (completedTaskCount.get() < tasks.size()) {
log.info("批处理进度: {}/{}, 当前活动任务数: {}",
completedTaskCount.get(), tasks.size(), activeTaskCount.get());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
});
return futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
}
03.优点
通过Semaphore实现最大并发数限制,避免线程资源被用完
通过计数器实时跟踪活动的任务数量和完成进度
当系统负载较高时,通过信号量自动降低并发度
提供简单的处理进度日志,便于问题定位和后续的诊断
3.18 [4]优化:超时控制
01.场景
在分布式系统中,超时控制是保证系统稳定性的关键。但简单的超时策略有时也会有些问题,比如下面这些:
无法应对网络抖动
缺乏重试的机制
固定的超时时间,不够灵活
缺乏降级机制
02.这里提供一个TimeoutHandler作为优化方向的参考
// 原始的写法:基础的超时控制
CompletableFuture<Result> future = CompletableFuture
.supplyAsync(() -> doSomething())
.orTimeout(3, TimeUnit.SECONDS);
public class TimeoutHandler {
// 带有动态超时和重试的处理器
public <T> CompletableFuture<T> executeWithSmartTimeout(
Supplier<T> task,
long timeout,
TimeUnit unit,
int maxRetries) {
AtomicInteger retryCount = new AtomicInteger(0);
CompletableFuture<T> future = new CompletableFuture<>();
CompletableFuture.supplyAsync(() -> {
while (retryCount.get() < maxRetries) {
try {
CompletableFuture<T> attempt = CompletableFuture
.supplyAsync(task)
.orTimeout(timeout, unit);
return attempt.get();
} catch (TimeoutException e) {
log.warn("第{}次尝试超时", retryCount.incrementAndGet());
// 指数退避
Thread.sleep(Math.min(1000 * (1 << retryCount.get()), 10000));
} catch (Exception e) {
throw new CompletionException(e);
}
}
throw new TimeoutException("重试次数耗尽");
}).handle((result, ex) -> {
if (ex != null) {
future.completeExceptionally(ex);
} else {
future.complete(result);
}
return null;
});
return future;
}
}
03.测试类
TimeoutHandler handler = new TimeoutHandler();
CompletableFuture<UserProfile> future = handler.executeWithSmartTimeout(
() -> remoteService.getUserProfile(userId),
500, // 500ms超时
TimeUnit.MILLISECONDS,
3 // 最多重试3次
);
04.优点
支持配置最大重试次数
采用指数退避算法,避免立即重试对系统造成冲击
每次重试都有独立的超时控制,实现了基础的隔离
支持自定义降级策略,可以对结果进行降级处理
3.19 [4]优化:资源释放
01.场景
这其实是个老生常谈的问题,与CompletableFuture关联不大,是整个异步编程领域都要面临的问题,这里也就扯一些闲篇
在处理涉及数据库连接、网络连接等资源的异步任务时,常见问题包括:
资源泄露
释放时机不当
异常情况下资源未释放
缺乏统一的资源管理方案
02.代码
针对上述问题,我们也提供一个ResourceAwareCompletableFuture,但也和上一节的参考类一致
这些优化都是抛砖引玉,不能一股脑用到生产上,也可能并一定适用于你的真实场景
必须要针对不同的业务去进行调整与修改
---------------------------------------------------------------------------------------------------------
public class ResourceAwareCompletableFuture<T> implements AutoCloseable {
private final CompletableFuture<T> future;
private final ExecutorService executor;
private final List<AutoCloseable> resources;
public ResourceAwareCompletableFuture(
Supplier<T> supplier,
ExecutorService executor,
List<AutoCloseable> resources) {
this.executor = executor;
this.resources = resources;
this.future = CompletableFuture.supplyAsync(() -> {
try {
return supplier.get();
} finally {
// 确保资源在任务完成后释放
closeResources();
}
}, executor);
}
private void closeResources() {
resources.forEach(resource -> {
try {
resource.close();
} catch (Exception e) {
log.error("关闭资源失败", e);
}
});
}
@Override
public void close() {
closeResources();
if (!executor.isShutdown()) {
executor.shutdown();
}
}
}
03.测试类
try (ResourceAwareCompletableFuture<Data> future = new ResourceAwareCompletableFuture<>(
() -> processWithConnection(connection),
executor,
Arrays.asList(connection, tempFile))) {
Data result = future.get(5, TimeUnit.SECONDS);
// 资源会在这里自动释放
}
04.好处
实现AutoCloseable接口,支持try-with-resources语法
在任务完成后自动释放资源
异常安全,即使发生异常也能保证资源释放
具备良好的可扩展性,支持管理多个相关资源
3.20 [5]实现:StructuredScope
01.定义
StructuredScope是Java的一种并发控制机制,旨在提供一种结构化的方式来管理并发任务的生命周期
它确保在一个作用域内启动的所有任务在作用域结束时都能正确地完成或取消
在Java中,StructuredScope并不是标准库的一部分,而是一个概念,通常需要通过第三方库或自定义实现来使用
Java的标准库中并没有直接提供StructuredScope类,因此你需要自己实现或者使用支持结构化并发的库。
02.原理
StructuredScope通过定义一个作用域,在该作用域内启动的所有任务都受到管理
它确保所有任务在作用域结束时都能正确地完成或被取消,从而避免资源泄漏和不确定的任务状态
03.常用API
由于StructuredScope是一个概念而不是Java标准库的一部分,具体的API可能依赖于第三方库或自定义实现
StructuredScope.start(Runnable task): 启动一个新的任务
StructuredScope.join(): 等待所有任务完成
StructuredScope.cancel(): 取消所有未完成的任务
StructuredScope.close(): 关闭作用域,确保所有任务已完成或取消
04.使用步骤
创建作用域:定义一个StructuredScope实例
启动任务:在作用域内启动并发任务
管理任务:使用join或cancel方法管理任务的完成或取消
关闭作用域:确保所有任务在作用域结束时正确地完成或取消
05.场景及代码示例
a.场景1:管理多个并发任务
public class StructuredScopeExample {
public static void main(String[] args) {
try (StructuredScope scope = new StructuredScope()) {
scope.start(() -> {
// Task 1
System.out.println("Task 1 running");
});
scope.start(() -> {
// Task 2
System.out.println("Task 2 running");
});
scope.join(); // Wait for all tasks to complete
} catch (Exception e) {
e.printStackTrace();
}
}
}
说明:在StructuredScope内启动两个任务,并等待它们完成
b.场景2:取消未完成的任务
public class StructuredScopeExample {
public static void main(String[] args) {
try (StructuredScope scope = new StructuredScope()) {
scope.start(() -> {
// Task 1
try {
Thread.sleep(5000); // Simulate long-running task
} catch (InterruptedException e) {
System.out.println("Task 1 interrupted");
}
});
scope.start(() -> {
// Task 2
System.out.println("Task 2 running");
});
scope.cancel(); // Cancel all tasks
} catch (Exception e) {
e.printStackTrace();
}
}
}
说明:在StructuredScope内启动两个任务,并在作用域结束时取消所有任务
c.场景3:处理任务异常
public class StructuredScopeExample {
public static void main(String[] args) {
try (StructuredScope scope = new StructuredScope()) {
scope.start(() -> {
// Task 1
throw new RuntimeException("Task 1 failed");
});
scope.start(() -> {
// Task 2
System.out.println("Task 2 running");
});
scope.join(); // Wait for all tasks to complete
} catch (Exception e) {
System.out.println("Exception caught: " + e.getMessage());
}
}
}
说明:在StructuredScope内启动两个任务,其中一个任务抛出异常,并在作用域结束时处理异常
06.自定义实现
a.工具类
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StructuredScope implements AutoCloseable {
private final ExecutorService executor = Executors.newCachedThreadPool();
private final List<CompletableFuture<Void>> tasks = new ArrayList<>();
public void start(Runnable task) {
CompletableFuture<Void> future = CompletableFuture.runAsync(task, executor);
tasks.add(future);
}
public void join() {
tasks.forEach(CompletableFuture::join);
}
public void cancel() {
tasks.forEach(task -> task.cancel(true));
}
@Override
public void close() {
join();
executor.shutdown();
}
}
b.使用示例
public class StructuredScopeExample {
public static void main(String[] args) {
try (StructuredScope scope = new StructuredScope()) {
scope.start(() -> {
// Task 1
System.out.println("Task 1 running");
});
scope.start(() -> {
// Task 2
System.out.println("Task 2 running");
});
scope.join(); // Wait for all tasks to complete
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.21 [6]场景:发票信息的数据组合
01.主要思想
把发票的每一块数据分别进行异步查询,最终阻塞等待完成所有模块的查询后,进行数据的最终组装
02.使用注意
一定要使用get()方法来阻塞所有异步操作,否则数据会直接返回null。因为CompletableFuture是异步执行的
所以thenRun里面的代码在方法返回时可能还没有执行,导致goodsOrderInvoiceNewVO的属性没有被正确设置
03.代码示例
a.同步写法的代码
public GoodsOrderInvoiceNewVO getInvoiceByOrderCode(String orderCode) {
GoodsOrderInvoiceNewVO goodsOrderInvoiceNewVO = new GoodsOrderInvoiceNewVO();
// 1.直接调用方法查询发票的基本信息
GoodsOrderInvoiceNewVO invoiceInfo = goodsOrderInvoiceMapper.getInvoiceByOrderCode(orderCode);
// 2.直接调用方法获取发票资料
List<GoodsOrderInvoiceHistoryDTO> invoiceHistoryList = getInvoiceHistoryByOrderCode(orderCode);
// 3.直接调用方法获取操作信息
List<GoodsOrderInvoiceLifecycle> invoiceLifecycleList = getInvoiceLifecycleByOrderCode(orderCode);
// 4.组合数据
if (invoiceInfo != null) {
BeanUtils.copyProperties(invoiceInfo, goodsOrderInvoiceNewVO);
}
goodsOrderInvoiceNewVO.setOrderInvoiceHistoryDTOList(invoiceHistoryList);
goodsOrderInvoiceNewVO.setOrderInvoiceLifecycleList(invoiceLifecycleList);
return goodsOrderInvoiceNewVO;
}
b.异步写法的代码
@Override
public GoodsOrderInvoiceNewVO getInvoiceByOrderCodeAsync(String orderCode) {
GoodsOrderInvoiceNewVO goodsOrderInvoiceNewVO = new GoodsOrderInvoiceNewVO();
// 打算采用异步组合式写法 CompletableFuture
CompletableFuture<GoodsOrderInvoiceNewVO> future1 = CompletableFuture.supplyAsync(() -> {
//1.异步 先查询发票的基本信息(开票资料、订单资料)
return goodsOrderInvoiceMapper.getInvoiceByOrderCode(orderCode);
});
// 2.异步调用获取发票资料
CompletableFuture<List<GoodsOrderInvoiceHistoryDTO>> future2 = CompletableFuture.supplyAsync(
() -> getInvoiceHistoryByOrderCode(orderCode));
// 3.异步调用获取操作信息
CompletableFuture<List<GoodsOrderInvoiceLifecycle>> future3 = CompletableFuture.supplyAsync(
() -> getInvoiceLifecycleByOrderCode(orderCode));
//4. 组合数据返回
CompletableFuture<Void> allFutures = CompletableFuture.allOf(future1, future2, future3);
allFutures.thenRun(() -> {
try {
GoodsOrderInvoiceNewVO goodsOrderInvoiceNewVOTemp = future1.get();
List<GoodsOrderInvoiceHistoryDTO> invoiceHistoryDTOList = future2.get();
List<GoodsOrderInvoiceLifecycle> invoiceLifecycleList = future3.get();
BeanUtils.copyProperties(goodsOrderInvoiceNewVOTemp, goodsOrderInvoiceNewVO);
goodsOrderInvoiceNewVO.setOrderInvoiceHistoryDTOList(invoiceHistoryDTOList);
goodsOrderInvoiceNewVO.setOrderInvoiceLifecycleList(invoiceLifecycleList);
} catch (InterruptedException | ExecutionException e) {
log.error("组合用户发票信息异常");
throw new RuntimeException(e);
}
});
// 等待所有的future完成
try {
allFutures.get();
} catch (InterruptedException | ExecutionException e) {
log.error("等待异步任务完成时发生异常", e);
throw new RuntimeException(e);
}
return goodsOrderInvoiceNewVO;
}
04.效率提升
同步情况下rt在(70+,110+)的范围内,异步的情况下RT在(50,70+)之间,平均提升效率40%以上
3.22 [6]场景:组装商品详情页数据
01.主要思想
将串行化处理转变化并行化处理,提升数据的加载性能
02.代码示例
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ProductDetailLoader {
// 假设的类,需要你根据实际情况定义
class ProductDetail {
// 产品详情字段
}
class InventoryStatus {
// 库存状态字段
}
class UserReview {
// 用户评论字段
}
// 声明所有的子调用方法
// 假设的方法,这些通常会在服务层中实现
CompletableFuture<ProductDetail> getProductDetails(String productId) {
// 异步获取产品详细信息
return CompletableFuture.supplyAsync(() -> {
// 模拟远程服务调用
return new ProductDetail(productId, "Product Description", "Product Category");
});
}
CompletableFuture<InventoryStatus> getInventoryStatus(String productId) {
// 异步获取库存状态
return CompletableFuture.supplyAsync(() -> {
// 模拟远程服务调用
return new InventoryStatus(productId, true); // 假设库存可用
});
}
CompletableFuture<Double> getPrice(String productId) {
// 异步获取价格
return CompletableFuture.supplyAsync(() -> {
// 模拟远程服务调用
return 99.99; // 假设价格
});
}
CompletableFuture<List<UserReview>> getUserReviews(String productId) {
// 异步获取用户评论
return CompletableFuture.supplyAsync(() -> {
// 模拟远程服务调用
return Arrays.asList(new UserReview(productId, "Review 1", 5),
new UserReview(productId, "Review 2", 4));
});
}
// 组合所有的子调用方法
// 加载产品详情页面的方法
public void loadProductDetailsPage(String productId) throws ExecutionException, InterruptedException {
CompletableFuture<ProductDetail> productDetailsFuture = getProductDetails(productId);
CompletableFuture<InventoryStatus> inventoryStatusFuture = getInventoryStatus(productId);
CompletableFuture<Double> priceFuture = getPrice(productId);
CompletableFuture<List<UserReview>> reviewsFuture = getUserReviews(productId);
// 等待所有 CompletableFuture 完成
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
productDetailsFuture,
inventoryStatusFuture,
priceFuture,
reviewsFuture
);
// 当所有的 CompletableFuture 完成后执行
allFutures.thenRun(() -> {
try {
// 获取并使用结果
ProductDetail productDetails = productDetailsFuture.get();
InventoryStatus inventoryStatus = inventoryStatusFuture.get();
Double price = priceFuture.get();
List<UserReview> reviews = reviewsFuture.get();
// 在这里,你可以组合并显示这些信息
// 例如,发送给前端或处理其他业务逻辑
displayProductPage(productDetails, inventoryStatus, price, reviews);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}).get(); // 阻塞等待所有任务完成
}
// 假设的显示方法
void displayProductPage(ProductDetail productDetails, InventoryStatus inventoryStatus, Double price, List<UserReview> reviews) {
// 实现展示逻辑
System.out.println("Product Details: " + productDetails);
System.out.println("Inventory Status: " + inventoryStatus);
System.out.println("Price: " + price);
System.out.println("User Reviews: " + reviews);
}
// 示例使用
public static void main(String[] args) throws ExecutionException, InterruptedException {
new ProductDetailLoader().loadProductDetailsPage("product123");
}
}
03.使用注意
a.异常处理
如果不做特殊的处理,在CompletableFuture 的调用链中出现的错误,会一直保留到链路调用结束才会最后抛出异常
导致整个调用都无法继续执行thenAccept, thenApply的后续执行方法;且也导致中间链路被多余调用,浪费了资源
-----------------------------------------------------------------------------------------------------
import java.util.concurrent.CompletableFuture;
// 可以使用exceptionally,来在调用的链路中间提前处理异常
public class CompletableFutureExceptionHandlingIntermediate {
public static void main(String[] args) {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// 模拟一个抛出异常的操作
throw new RuntimeException("任务失败了");
});
CompletableFuture<Integer> handledFuture = future.exceptionally(ex -> {
System.err.println("任务发生异常: " + ex.getMessage());
return 0; // 处理异常并返回默认值
});
handledFuture.thenAccept(result -> {
System.out.println("处理异常后的结果:" + result);
});
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
-----------------------------------------------------------------------------------------------------
在上面的示例中,exceptionally 方法捕获了前一个阶段中的异常,并返回了一个默认值,然后继续执行后续操作
b.线程池的使用
CompletableFuture在执行时,容易出现长时间的阻塞情况,会出现对线程资源的占用
所以要谨慎选择使用其装配的线程池,尽量不要使用默认的线程池,forkJoinPool
而是通过executer来创建自定义的线程池
4 ThreadLocal:线程局部变量
4.1 [1]定义
01.定义
ThreadLocal是Java提供的一种机制,用于创建线程本地变量
为了通过【本地化资源】来避免共享,避免了【多线程竞争导致的锁】等消耗
这种变量在线程生命周期内其作用,减少同一个线程内多个方法或组件间一些公共变量的传递的复杂度
每个线程都有自己的独立变量副本,避免了线程间的共享和竞争,从而确保线程安全
02.优点
对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量
一个线程持有一个链接,该连接对象可以在不同给的方法之间进行线程传递,线程之间不共享同一个连接
让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据
03.缺点
hash冲突用的是线性探测法,效率低
04.说明
ThreadLocal是JDK包提供的,它提供了线程本地变量,也就说当你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地副本
当多个线程操作这个变量时,实际操作的是自己本地内存里面的变量,从而避免了线程安全问题
创建一个ThreadLocal变量后,每个线程都会复制一个变量到自己的本地内存
4.2 [1]原理
00.原理
a.线程本地存储
ThreadLocal 为每个线程提供一个独立的变量副本,存储在线程内部的 ThreadLocalMap 中
b.ThreadLocalMap
每个线程(Thread 对象)内部维护一个 ThreadLocalMap 实例。ThreadLocal 对象作为键,值为线程的本地变量
c.变量隔离
当线程调用 ThreadLocal 的 set() 方法时,值存储在当前线程的 ThreadLocalMap 中;
调用 get() 方法时,从 ThreadLocalMap 中获取值。不同线程之间的变量相互隔离
01.线程本地存储
a.定义
ThreadLocal 为每个线程提供一个独立的变量副本,存储在线程内部的 ThreadLocalMap 中
这意味着每个线程都有自己的变量副本,避免了线程间的共享和竞争
b.示例代码
public class ThreadLocalStorageExample {
private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
Runnable task = () -> {
int initialValue = threadLocal.get();
System.out.println(Thread.currentThread().getName() + " - Initial Value: " + initialValue);
threadLocal.set(initialValue + 1);
System.out.println(Thread.currentThread().getName() + " - Updated Value: " + threadLocal.get());
};
Thread thread1 = new Thread(task, "Thread-1");
Thread thread2 = new Thread(task, "Thread-2");
thread1.start();
thread2.start();
}
}
02.ThreadLocalMap
a.定义
每个线程(Thread 对象)内部维护一个 ThreadLocalMap 实例
ThreadLocal 对象作为键,值为线程的本地变量。这种结构确保了每个线程都有自己的变量副本
b.示例代码
public class ThreadLocalMapExample {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
threadLocal.set("ThreadLocal Value");
Runnable task = () -> {
String value = threadLocal.get();
System.out.println(Thread.currentThread().getName() + " - Value: " + value);
};
Thread thread1 = new Thread(task, "Thread-1");
Thread thread2 = new Thread(task, "Thread-2");
thread1.start();
thread2.start();
}
}
-----------------------------------------------------------------------------------------------------
虽然 ThreadLocalMap 是 ThreadLocal 的内部实现细节,不能直接访问
但可以通过 ThreadLocal 的使用间接理解其工作原理
03.变量隔离
a.定义
当线程调用 ThreadLocal 的 set() 方法时,值存储在当前线程的 ThreadLocalMap 中
调用 get() 方法时,从 ThreadLocalMap 中获取值。不同线程之间的变量相互隔离
b.示例代码
public class VariableIsolationExample {
private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
Runnable task = () -> {
int value = threadLocal.get();
System.out.println(Thread.currentThread().getName() + " - Initial Value: " + value);
threadLocal.set(value + 10);
System.out.println(Thread.currentThread().getName() + " - Updated Value: " + threadLocal.get());
};
Thread thread1 = new Thread(task, "Thread-1");
Thread thread2 = new Thread(task, "Thread-2");
thread1.start();
thread2.start();
}
}
4.3 [1]优点:线程安全
01.为什么使用ThreadLocal
为了通过本地化资源来避免共享,避免了多线程竞争导致的锁等消耗
02.主要有以下方面
a.线程安全,避免共享
在多线程环境中,多个线程可能会同时访问和修改同一个变量,导致数据不一致和线程安全问题
ThreadLocal 为每个线程提供独立的变量副本,避免了线程间的共享,从而确保线程安全
b.简化代码,减少同步
使用 ThreadLocal 可以避免显式的同步操作(如 synchronized),从而简化代码逻辑
每个线程都有自己的变量副本,不需要担心其他线程的干扰
c.提高性能,减少锁竞争
通过为每个线程提供独立的变量副本,ThreadLocal 可以减少线程间的锁竞争,提高程序的并发性能
d.线程隔离,独立状态
ThreadLocal 允许每个线程维护自己的状态信息,而不影响其他线程
这对于需要在线程间保持独立状态的场景非常有用
4.4 [1]缺点:内存泄露,remove
00.汇总
使用ThreadLocal,在用完之后记得调用ThreadLocal的remove方法,不然会发生内存泄漏问题
01.定义
a.内存泄露
内存泄露为程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略
但内存泄露堆积后果很严重,无论多少内存,迟早会被占光
广义并通俗的说,就是:不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄露
b.ThreadLocal内存泄露
ThreadLocal 在没有外部强引用时,发生 GC 时会被回收
那么 ThreadLocalMap 中保存的 key 值就变成了 null,而 Entry 又被 threadLocalMap 对象引用
threadLocalMap 对象又被 Thread 对象所引用
那么当 Thread 一直不终结的话,value 对象就会一直存在于内存中,也就导致了内存泄漏
直至 Thread 被销毁后,才会被回收
c.解决ThreadLocal内存泄露
在使用完 ThreadLocal 变量后,需要我们手动 remove 掉
防止 ThreadLocalMap 中 Entry 一直保持对 value 的强引用,导致 value 不能被回收
02.主要原因
a.未及时清理数据
如果在线程执行完毕后没有调用remove()方法清理ThreadLocal中的数据
数据将一直保留在ThreadLocalMap中,直到线程结束
这在长生命周期的线程(如线程池中的线程)中尤其容易导致内存泄漏
b.线程池的使用
线程池中的线程会被重复使用,如果ThreadLocal中的数据没有被清理
后续使用该线程时,可能会意外访问到之前的残留数据,导致数据污染和内存泄漏
c.ThreadLocalMap的弱引用
ThreadLocalMap使用ThreadLocal对象的弱引用作为键
这意味着当ThreadLocal对象没有其他强引用时,垃圾回收器可以回收它
然而,值是强引用的,即使键被回收,值仍然可能存在,导致内存泄漏
d.不当的生命周期管理
如果ThreadLocal对象的生命周期管理不当
例如在不需要时仍然持有对ThreadLocal对象的引用,可能导致不必要的内存占用
03.预防措施
a.及时清理
在使用完ThreadLocal后,调用remove()方法清理数据
b.谨慎使用线程池
在使用线程池时,确保在每次任务完成后清理ThreadLocal中的数据
c.合理管理生命周期
确保ThreadLocal对象的生命周期与其使用场景相匹配,避免不必要的持有
4.5 [1]解析:搞懂线程私有变量
01.ThreadLocal 是啥?先讲个小故事
a.说明
以前我写多线程代码,总遇到这种情况:三个线程共用一个计数器变量,线程 A 刚把 count 改成 1,线程 B 一读还是 0,
线程 C 再改直接乱套。就像三个厨师抢一本菜谱,你写一句我划一句,最后做出黑暗料理。
直到师傅丢给我 ThreadLocal,说:「给每个线程发本独立的菜谱不就行了?」
b.ThreadLocal 的核心思想其实就这么简单:
每个线程干活时用自己的「专属变量副本」,改自己的副本不影响别人
同一个线程里,从方法 A 到方法 B 不用传参,直接就能拿到自己的副本
c.用大白话讲
ThreadLocal 让变量成了「线程专属财产」,线程 A 和线程 B 就算操作同一个 ThreadLocal 变量,也像住对门的邻居,各用各的东西,老死不相往来。
02.ThreadLocal 怎么工作的?像给线程发「专属背包」
a.说明
我以前以为 ThreadLocal 自己存数据,后来看源码才发现搞错了!其实数据根本不在 ThreadLocal 里,而是存在每个线程自己身上。
b.每个线程都背着一个「专属背包」
Java 里的 Thread 类有个特殊成员变量 threadLocals,它是 ThreadLocal 的静态内部类 ThreadLocalMap——你可以把它想象成每个线程背着的「背包」,专门装 ThreadLocal 变量:
public class Thread implements Runnable {
// 线程的专属背包,里面装着 ThreadLocal 变量
ThreadLocal.ThreadLocalMap threadLocals = null;
}
c.ThreadLocal 其实是「背包钥匙」
当我们用 threadLocal.set(value) 存东西时,流程是这样的:
先找到当前线程的「背包」(ThreadLocalMap)
用 ThreadLocal 实例当「钥匙」,把 value 放进背包
下次 threadLocal.get() 时,还是用这把钥匙从自己的背包里取
就像你用家门钥匙(ThreadLocal)打开自己家的门(当前线程的 ThreadLocalMap),放进去的东西只有你能拿到。别人就算有同款钥匙(另一个 ThreadLocal 实例),开的也是他家的门,拿不到你的东西。
03.用 ThreadLocal 管理数据库连接
a.最经典的 ThreadLocal 用法就是管理数据库连接。
以前我不懂,多个线程共用一个 Connection,结果线程 A 刚打开事务,线程 B 直接把连接关了,数据全乱了!
b.解决方案:给每个线程发「专属服务员」
后来我用 ThreadLocal 重构了代码,每个线程都拿到自己的 Connection,就像每个顾客有专属服务员,再也不会抢来抢去:
public class ConnectionUtil {
// 创建一把「钥匙」,专门用来存 Connection
private static ThreadLocal<Connection> connKey = new ThreadLocal<>();
// 数据库连接池(相当于服务员排班表)
private static DataSource dataSource = createDataSource();
// 获取当前线程的「专属服务员」
public static Connection getConnection() {
Connection conn = connKey.get(); // 用钥匙从线程背包里取
try {
if (conn == null || conn.isClosed()) {
conn = dataSource.getConnection(); // 从连接池叫个新服务员
connKey.set(conn); // 用钥匙锁进线程背包
}
} catch (SQLException e) {
throw new RuntimeException("数据库连接炸了!", e);
}
return conn;
}
// 用完记得「解雇服务员」
public static void closeConnection() {
Connection conn = connKey.get();
try {
if (conn != null && !conn.isClosed()) {
conn.close(); // 服务员下班(归还连接池)
connKey.remove(); // 把钥匙从背包拿走!重点!
}
} catch (SQLException e) {
throw new RuntimeException("关连接失败!", e);
}
}
}
c.为啥这么好用?
线程隔离:线程 A 的连接崩了,线程 B 完全不受影响
不用传参:Service 层调 Dao 层,直接 getConnection() 就能拿到自己的连接,不用在方法里传来传去
事务安全:同一个线程里,增删改查用的是同一个连接,事务能保证原子性
04.这些场景 ThreadLocal 简直是神器
a.保存用户登录信息(不用满方法传参了)
以前在 Web 项目里,用户登录后要把 User 对象从 Controller 传到 Service 再传到 Dao,参数列表长得像蜈蚣。现在用 ThreadLocal 存一次,线程里到处都能取:
public class UserContext {
private static ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
// 登录时存用户
public static void setUser(User user) {
userThreadLocal.set(user);
}
// 任何地方取当前登录用户
public static User getCurrentUser() {
return userThreadLocal.get();
}
}
b.分布式追踪(给日志打标记)
调用链追踪时,每个请求生成一个唯一 traceId,用 ThreadLocal 跟着线程跑,所有日志都带上这个 id,排查问题时能串起一整条链路:
public class TraceIdUtil {
private static ThreadLocal<String> traceIdThreadLocal = new ThreadLocal<>();
// 生成 traceId
public static void generateTraceId() {
traceIdThreadLocal.set(UUID.randomUUID().toString());
}
// 日志里带上 traceId
public static String getTraceId() {
return traceIdThreadLocal.get() == null ? "unknown" : traceIdThreadLocal.get();
}
}
05.ThreadLocal 的 3 个坑
a.内存泄漏:忘了 remove(),线程池里全是「垃圾」
有次在线程池里用 ThreadLocal,没调用 remove(),结果线程复用的时候,新任务居然拿到了上一个任务的旧数据!就像你去图书馆借书,发现上一个人没还的书还在座位上。
原因:线程池的线程不会销毁,ThreadLocal 存的值(value)是强引用,就算 ThreadLocal 实例被回收了,value 还挂在线程的 ThreadLocalMap 里,占着内存不释放。
正确做法:用完一定记得 remove(),最好放 finally 里:
java 体验AI代码助手 代码解读复制代码
try {
threadLocal.set(value);
// 业务逻辑
} finally {
threadLocal.remove(); // 用完就清,好习惯!
}
b.以为 ThreadLocal 是「线程安全」的银弹
我曾天真地以为 ThreadLocal 里的变量绝对安全,结果把一个 ArrayList 放进去,多个线程通过其他引用改了这个 ArrayList,数据还是乱了!
真相:ThreadLocal 只保证「变量副本的引用」在线程间隔离,如果你存的是个可变对象(比如 ArrayList),
其他线程拿到这个对象的引用照样能改里面的数据!它就像给每个线程发了一本笔记本,但笔记本里夹着的是同一把剪刀,
线程 A 用剪刀剪了纸,线程 B 打开笔记本看到的也是碎纸。
c.别用 ThreadLocal 存大对象
有次我把 10MB 的文件数据塞到 ThreadLocal 里,结果线程一多,内存直接飙高。每个线程都存一份大对象,
相当于 10 个线程就有 10 份 10MB 数据,内存吃不消啊!
06.ThreadLocal 就像「线程专属储物柜」
学了这么久,我总算把 ThreadLocal 搞明白了:
核心功能:给每个线程发「专属变量副本」,线程隔离 + 线程内共享
使用场景:数据库连接、用户会话、上下文传递(避免参数爆炸)
保命三招:用完 remove()、别存大对象、可变对象要小心
底层原理:线程背「背包」(ThreadLocalMap),ThreadLocal 当「钥匙」
以前觉得 ThreadLocal 高深莫测,现在发现它就是个「线程级别的全局变量」。虽然简单,但用对了能解决大问题,用错了能坑死自己。希望我的踩坑笔记能帮到和我一样的新手,咱们一起避开这些坑,写出更安全的并发代码!
4.6 [1]TL、ITL、TTL
00.汇总
ThreadLocal
InheritableThreadLocal
TransmittableThreadLocal
01.ThreadLocal
a.说明
用来存储当前线程的上下文信息的,但是在异步的情况下父子线程中子线程无法获取父线程的该信息
b.代码
@Test
public void test3() throws Exception {
//单一线程池
ExecutorService executorService = Executors.newSingleThreadExecutor();
//ThreadLocal存储
ThreadLocal<String> username = new ThreadLocal<>();
username.set("为了岩王帝君");
Thread.sleep(3000);
new Thread(()-> System.out.println(username.get()+" 1")).start();
for (int i = 0; i < 2; i++) {
CompletableFuture.runAsync(() -> System.out.println(username.get() + " 2"), executorService);
}
Thread.sleep(3000);
System.out.println(username.get()+" 3");
executorService.shutdown();
}
c.结果
不管是新创建的子线程还是线程池复用的子线程都获取不到父线程的上下文信息
02.InheritableThreadLocal
a.说明
ITL确实解决了父子线程间的信息传递,但是,如果我们使用的是线程池的方式,难免不会碰到线程的复用
这个时候就不一定能够实现父子线程间信息传递了,因为ITL的实现方式是在子线程初始化的时候把进行信息拷贝传递
如果使用了线程池,那些复用的线程已经被初始化了,就不会经过这个拷贝的过程
b.代码
@Test
public void test2() throws Exception {
//单一线程池
ExecutorService executorService = Executors.newSingleThreadExecutor();
//InheritableThreadLocal存储
InheritableThreadLocal<String> name = new InheritableThreadLocal<>();
for (int i = 0; i < 5; i++) {
name.set("为了岩王帝君"+i);
Thread.sleep(3000);
new Thread(()-> System.out.println(name.get()+" 斩尽牛杂")).start();
CompletableFuture.runAsync(()-> System.out.println(name.get()),executorService);
}
name.remove();
Thread.sleep(3000);
System.out.println("---------------");
CompletableFuture.runAsync(()-> System.out.println(name.get()+" 天动万象"),executorService);
executorService.shutdown();
}
c.结果
很明显这些新创建的子线程都继承了父线程的上下文信息,而复用的子线程却一直是第一次的信息
注意的是:这里父线程remove之后,第二个异步任务的子线程仍然能获取到,久而久之有内存泄漏风险
不过这里可以用try-finally包一下异步任务,在finally中手动remove一下。但是这种方式显然可能会忘记不优雅
03.TransmittableThreadLocal
a.说明
对ITL的扩展,它通过调用capture()方法捕获调用方的本地线程变量替换到线程池所对应获取到的线程的本地变量中
b.代码
@Test
public void test() throws Exception {
//单一线程池
ExecutorService executorService = Executors.newSingleThreadExecutor();
//需要使用TtlExecutors对线程池包装一下
executorService= TtlExecutors.getTtlExecutorService(executorService);
//TransmittableThreadLocal创建
TransmittableThreadLocal<String> name = new TransmittableThreadLocal<>();
for (int i = 0; i < 5; i++) {
name.set("🗡光如影"+i);
Thread.sleep(3000);
CompletableFuture.runAsync(()-> System.out.println(name.get()),executorService);
}
name.remove();
CompletableFuture.runAsync(()-> System.out.println(name.get()),executorService);
executorService.shutdown();
}
c.结果
很明显TTL能优雅的解决这一切。父线程remove后,子线程也不会有了
4.7 [1]ScopedValue:JDK21
01.ThreadLocal的缺点
a.代码
public class Test {
public static ThreadLocal<String> NAME = new ThreadLocal<>();
public static void main(String[] args) {
NAME.set("dadudu");
a();
}
public static void a() {
b();
System.out.println(NAME.get());
}
public static void b() {
System.out.println(NAME.get());
}
}
b.权限问题
第一个就是权限问题,也许我们只需要在main()方法中给ThreadLocal赋值,在其他方法中获取值就可以了
而上述代码中a()、b()方法都有权限给ThreadLocal赋值,ThreadLocal不能做权限控制
c.内存问题
第二个就是内存问题,ThreadLocal需要手动强制remove,也就是在用完ThreadLocal之后
比如b()方法中,应该调用其remove()方法,但是我们很容易忘记调用remove(),从而造成内存浪费
02.ScopedValue
a.解决ThreadLocal缺点
而JDK21中的新特性ScopedValue能不能解决这两个缺点呢?我们先来看一个ScopedValue的Demo:
package com.dadudu;
public class Test {
public static ScopedValue<String> NAME = ScopedValue.newInstance();
public static void main(String[] args) {
ScopedValue.runWhere(NAME, "dadudu", Test::a);
System.out.println("main: " + NAME.get());
}
public static void a() {
System.out.println("a: " + NAME.get());
b();
}
public static void b() {
System.out.println("b: " + NAME.get());
}
}
b.ScopedValue的使用
首先需要通过ScopedValue.newInstance()生成一个ScopedValue对象
然后通过ScopedValue.runWhere()方法给ScopedValue对象赋值
runWhere()的第三个参数是一个lambda表达式,表示作用域
比如上面代码就表示:给NAME绑定值为"dadudu",但是仅在调用a()方法时才生效
并且在执行runWhere()方法时就会执行lambda表达式
-----------------------------------------------------------------------------------------------------
比如上面代码的输出结果为:
a:dadudu
b:dadudu
Exception in thread "main" java.util.NoSuchElementException
at java.base/java.lang.ScopedValue.slowGet(ScopedValue.java:700)
at java.base/java.lang.ScopedValue.get(ScopedValue.java:693)
at com.dadudu.Test.main(Test.java:17)
-----------------------------------------------------------------------------------------------------
从结果可以看出在执行runWhere()时会执行a(),a()方法中执行b(),b()执行完之后返回到main()方法
执行runWhere()之后的代码,所以,在a()方法和b()方法中可以拿到ScopedValue对象所设置的值
但是在main()方法中是拿不到的(报错了),b()方法之所以能够拿到,是因为属于a()方法调用栈中
所以在给ScopedValue绑定值时都需要指定一个方法,这个方法就是所绑定值的作用域
只有在这个作用域中的方法才能拿到所绑定的值
c.重新开启新的作用域
ScopedValue也支持在某个方法中重新开启新的作用域并绑定值,比如:
-----------------------------------------------------------------------------------------------------
package com.dadudu;
public class Test {
public static ScopedValue<String> NAME = ScopedValue.newInstance();
public static void main(String[] args) {
ScopedValue.runWhere(NAME, "dadudu", Test::a);
System.out.println("main: " + NAME.get());
}
public static void a() {
System.out.println("a: " + NAME.get());
ScopedValue.runWhere(NAME, "xiaodudu", Test::c);
b();
}
public static void b() {
System.out.println("b: " + NAME.get());
}
public static void c() {
System.out.println("c: " + NAME.get());
}
}
-----------------------------------------------------------------------------------------------------
以上代码中,在a()方法中重新给ScopedValue绑定了一个新值“xiaodudu”,并指定了作用域为c()方法
所以c()方法中拿到的值为“xiaodudu”,但是b()中仍然拿到的是“dadudu”,并不会受到影响
-----------------------------------------------------------------------------------------------------
以上代码的输出结果为:
a:dadudu
C:xiaodudu
b:dadudu
Exception in thread"main" java.util.NoSuchElementException
at java.base/java.lang.ScopedValue.slowGet(ScopedValue.java:700)
at java.base/java.lang.ScopedValue.get(ScopedValue.java:693)
at com.dadudu.Test.main(Test.java:17)
-----------------------------------------------------------------------------------------------------
甚至如果把代码改成:
package com.dadudu;
public class Test {
public static ScopedValue<String> NAME = ScopedValue.newInstance();
public static void main(String[] args) {
ScopedValue.runWhere(NAME, "dadudu", Test::a);
System.out.println("main: " + NAME.get());
}
public static void a() {
System.out.println("a: " + NAME.get());
ScopedValue.runWhere(NAME, "xiaodudu", Test::c); // c1
b();
c(); // c2
}
public static void b() {
System.out.println("b: " + NAME.get());
}
public static void c() {
System.out.println("c: " + NAME.get());
}
}
-----------------------------------------------------------------------------------------------------
以上代码在a()方法中有两处调用了c()方法,我想大家能思考出c1和c2输出结果分别是什么:
a:dadudu
C:xiaodudu
b:dadudu
c:dadudu
Exception in thread "main" java.util.NoSuchElementException
at java.base/java.lang.ScopedValue.slowGet(ScopedValue.java:700)
at java.base/java.lang.ScopedValue.get(ScopedValue.java:693)
at com.dadudu.Test.main(Test.java:17)
-----------------------------------------------------------------------------------------------------
所以,从以上分析可以看到,ScopedValue有一定的权限控制:就算在同一个线程中也不能任意修改ScopedValue的值
就算修改了对当前作用域(方法)也是无效的。另外ScopedValue也不需要手动remove,关于这块就需要分析它的实现原理了
03.实现原理
a.代码分析
package com.dadudu;
public class Test {
public static ScopedValue<String> NAME = ScopedValue.newInstance();
public static void main(String[] args) {
ScopedValue.runWhere(NAME, "dadudu", Test::a); // 生成一个Snapshot对象1,prev=null
}
public static void a() {
ScopedValue.runWhere(NAME, "xiaodudu", Test::b); // 生成一个Snapshot对象2,prev=Snapshot对象1
System.out.println("a: " + NAME.get());
}
public static void b() {
ScopedValue.runWhere(NAME, "dudu", Test::c); // 生成一个Snapshot对象3,prev=Snapshot对象2
System.out.println("b: " + NAME.get());
}
public static void c() {
System.out.println("c: " + NAME.get());
}
}
-----------------------------------------------------------------------------------------------------
执行main()方法时,main线程执行过程中会执行runWhere()方法三次
而每次执行runWhere()时都会生成一个Snapshot对象,Snapshot对象中记录了所绑定的值
而Snapshot对象有一个prev属性指向上一次所生成的Snapshot对象
并且在Thread类中新增了一个属性scopedValueBindings,专门用来记录当前线程对应的Snapshot对象
b.Snapshot对象的生成
比如在执行main()方法中的runWhere()时:
会先生成Snapshot对象1,其prev为null
并将Snapshot对象1赋值给当前线程的scopedValueBindings属性,然后执行a()方法
在执行a()方法中的runWhere()时,会先生成Snapshot对象2,其prev为Snapshot对象1
并将Snapshot对象2赋值给当前线程的scopedValueBindings属性
使得在执行b()方法时能从当前线程拿到Snapshot对象2从而拿到所绑定的值
runWhere()内部在执行完b()方法后会取prev,从而取出Snapshot对象1
并将Snapshot对象1赋值给当前线程的scopedValueBindings属性
然后继续执行a()方法后续的逻辑,如果后续逻辑调用了get()方法
则会取当前线程的scopedValueBindings属性拿到Snapshot对象1
从Snapshot对象1中拿到所绑定的值就可以了,而对于Snapshot对象2由于没有引用则会被垃圾回收掉
c.无需手动remove
所以,在用ScopedValue时不需要手动remove
4.8 [1]FastThreadLocal:Netty
01.使用
a.基本使用
和 ThreadLocal 一样,我们可以在代码中直接通过构造器的方式使用它,就像下面这样:
-----------------------------------------------------------------------------------------------------
public class FastThreadLocalDemo02 {
public static void main(String[] args) {
// 创建 FastThreadLocal,带泛型
FastThreadLocal<String> fastThreadLocal = new FastThreadLocal<>();
fastThreadLocal.set("https://j3code.cn");
new Thread(() -> {
// 取不出来,一个 main 线程,一个 Thread-A 线程
System.out.println(fastThreadLocal.get());
},"Thread-A").start();
}
}
-----------------------------------------------------------------------------------------------------
虽然上面的使用没有什么问题,能达到多线程环境下安全的传递数据,但是你既然使用了 FastThreadLocal
那么就要按照 Netty 提供的使用方式来使用
直接使用 Thread 也能达到效果,但就是效率和 JDK 自带的没区别甚至可能还没 JDK 自带的高
b.具体使用事项
a.不要使用 JDK 自带的 Thread 线程来使用 FastThreadLocal
Netty 自定义了一个 FastThreadLocalThread ,是的你没看错,Netty 连 Thread 都自己定义了
b.底层包装
虽然 FastThreadLocalThread 构造器接收的是 Runnable 类型对象
但是底层会将其包装为 FastThreadLocalRunnable 类型
这个类重写了 run 方法(自动调用 remove 方法,防止内存泄漏 )
c.正确使用代码案例
public class FastThreadLocalDemo02 {
public static void main(String[] args) {
// 创建 FastThreadLocal,带泛型
FastThreadLocal<String> fastThreadLocal = new FastThreadLocal<>();
// 规范使用
FastThreadLocalThread fastThreadLocalThread = new FastThreadLocalThread(() -> {
fastThreadLocal.set("我是J3code,这是我的个人网站:https://j3code.cn");
System.out.println("fastThreadLocalThread线程存值成功!");
},"Thread-A");
fastThreadLocalThread.start();
LockSupport.parkNanos(1 * 1000 * 1000 * 1000L);
System.out.println("main线程获取值:" + fastThreadLocal.get());
}
}
d.线程工厂和线程执行器
a.说明
按理说介绍上述使用方法就够我们后面的源码分析了,但是我在多说一下 Netty 提供的通过线程工厂和线程执行器对象来使用 FastThreadLocal
我们知道 JDK 中有 Thread 线程,所以 JDK 就为此提供了一系列的线程工厂和对应的执行器,如:PrivilegedThreadFactory 线程工厂、ThreadPoolExecutor 执行器
所以,Netty 也一样为其自定义的线程 FastThreadLocalThread 提供了对应的线程工程和执行器,即:DefaultThreadFactory 线程工厂、ThreadPerTaskExecutor 执行器
b.下面是结合线程工程 + 执行器,实现的 FastThreadLocal 案例代码
public class FastThreadLocalDemo02 {
public static void main(String[] args) {
// 创建 FastThreadLocal,带泛型
FastThreadLocal<String> fastThreadLocal = new FastThreadLocal<>();
// 创建线程工厂(这个工厂是专门创建 FastThreadLocalThread 线程的,
// 将传入的 Runnable 对象包装成 FastThreadLocalRunnable 对象并传递给 FastThreadLocalThread 线程)
DefaultThreadFactory fastThreadLocalTest = new DefaultThreadFactory("fastThreadLocalTest");
// 创建 FastThreadLocalThread 线程的执行器,传入 FastThreadLocalThread 线程工厂
ThreadPerTaskExecutor threadPerTaskExecutor = new ThreadPerTaskExecutor(fastThreadLocalTest);
// 通过 FastThreadLocalThread 线程执行器执行 Runnable 对象
threadPerTaskExecutor.execute(
() -> {
fastThreadLocal.set("A");
System.out.println("fastThreadLocalTest-A: " + fastThreadLocal.get());
}
);
threadPerTaskExecutor.execute(
() -> {
System.out.println("fastThreadLocalTest-B: " + fastThreadLocal.get());
}
);
}
}
02.源码分析
a.构造器
a.代码
private final int index;
public FastThreadLocal() {
// 初始化 index 值
index = InternalThreadLocalMap.nextVariableIndex();
}
b.说明
在 FastThreadLocal 类中,有个 index 属性,可以看出该属性一旦赋值了就不能改变
其含义现在不解释,目前的话你可以理解为每个 FastThreadLocal 都唯一的对应一个 index 值
c.nextVariableIndex
private static final AtomicInteger nextIndex = new AtomicInteger();
// index 最大值
private static final int ARRAY_LIST_CAPACITY_EXPAND_THRESHOLD = 1 << 30;
public static int nextVariableIndex() {
// 获取原子类值并累加
int index = nextIndex.getAndIncrement();
// 如果大于最大值则报错
if (index >= ARRAY_LIST_CAPACITY_MAX_SIZE || index < 0) {
nextIndex.set(ARRAY_LIST_CAPACITY_MAX_SIZE);
throw new IllegalStateException("too many thread-local indexed variables");
}
// 返回对应的值
return index;
}
-------------------------------------------------------------------------------------------------
InternalThreadLocalMap 类中的一个公共静态方法,也即任何类都可以调用该方法
该方法通过原子整型类返回一个多线程环境下也能保证数据安全的 int 值(且唯一)
以下文章如果出现“map”字样,一律就是指 InternalThreadLocalMap
b.set 方法
public final void set(V value) {
// 判断设置的值是否为 UNSET 对象
if (value != InternalThreadLocalMap.UNSET) {
// value 不是 UNSET 对象,则获取 map 对象,并调用setKnownNotUnset方法进行设值
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();
setKnownNotUnset(threadLocalMap, value);
} else {
// 如果 set 的值是 UNSET ,则执行清理方法
remove();
}
}
-----------------------------------------------------------------------------------------------------
set 方法通过 value 类型分为两步:如果 value 不是 UNSET 则调用后续方法进行 set,反之则执行移除方法。
UNSET 是 InternalThreadLocalMap 类中的一个静态常量,用于填充 indexedVariables 数组,表示对应下标处还未赋值。
indexedVariables 后续会分析到。
c.InternalThreadLocalMap.get()
下面来看看 InternalThreadLocalMap.get() 方法:
是不是和 ThreadLocal 很类似,都是先获取一个 map 对象,然后通过 map 对象来操作值,这里也是一样。
-----------------------------------------------------------------------------------------------------
public static InternalThreadLocalMap get() {
// 获取当前线程对象
Thread thread = Thread.currentThread();
// 判断是否为 Netty 自定义线程类
if (thread instanceof FastThreadLocalThread) {
// 是,走快速获取 map 方法
return fastGet((FastThreadLocalThread) thread);
} else {
// 不是,表面是传统 Thread 类,走慢的获取 map 方法
return slowGet();
}
}
-----------------------------------------------------------------------------------------------------
从获取 InternalThreadLocalMap 对象方法就能看出,如果 FastThreadLocal 对象运行的环境是 Thread 则会走 slowGet() 方法;如果是 FastThreadLocalThread 则会走 fastGet() 方法,这也呼应了我一开始提到的使用的线程类不一样,对应的 FastThreadLocalThread 效果也会不一样。
d.fastGet
private static InternalThreadLocalMap fastGet(FastThreadLocalThread thread) {
// 从 FastThreadLocalThread 类中获取 InternalThreadLocalMap 属性变量
InternalThreadLocalMap threadLocalMap = thread.threadLocalMap();
// 如果为 null,则初始化
if (threadLocalMap == null) {
thread.setThreadLocalMap(threadLocalMap = new InternalThreadLocalMap());
}
// 不为空,直接返回
return threadLocalMap;
}
-----------------------------------------------------------------------------------------------------
要理解这个方法,我们要先看一下 FastThreadLocalThread 类中的一个属性
即每个 FastThreadLocalThread 类中都有一个 InternalThreadLocalMap 对象,用于存放数据,和 Thread 中的结构一样,只是类型不同。
理解了这点,那接下来就是初始化 InternalThreadLocalMap 对象并将值赋值给 FastThreadLocalThread 类中的属性了,我们来看看初始化的方法。
e.InternalThreadLocalMap 构造器
// 这个就是 InternalThreadLocalMap 类中存储数据的数组对象
private Object[] indexedVariables;
private InternalThreadLocalMap() {
// 给这个数组初始化
indexedVariables = newIndexedVariableTable();
}
-----------------------------------------------------------------------------------------------------
newIndexedVariableTable:
// 填充值,表示未使用,可以理解为占位符
public static final Object UNSET = new Object();
// 初始容量 32
private static final int INDEXED_VARIABLE_TABLE_INITIAL_SIZE = 32;
private static Object[] newIndexedVariableTable() {
// 创建一个容量为 32 的数组
Object[] array = new Object[INDEXED_VARIABLE_TABLE_INITIAL_SIZE];
// 调用 Arrays 的填充方法,将数组的所有值设置为 UNSET
Arrays.fill(array, UNSET);
// 返回数组
return array;
}
-----------------------------------------------------------------------------------------------------
InternalThreadLocalMap 的创建和初始化还是很简单的,就是创建出 InternalThreadLocalMap 对象之后,再给 indexedVariables 赋一个大小为 32 的 Object 数组,且数组值都用 UNSET 占位符填充。
到这里,大家应该知道 FastThreadLocal 底层是个啥了吧?
一个 InternalThreadLocalMap ,InternalThreadLocalMap 里面一个 Object 数组
大家再回想一下 ThreadLocal 底层是啥?
一个 ThreadLocalMap,ThreadLocalMap 里面是个 Entry 数组,Entry 里面是个 key(弱引用) 为 ThreadLocal ,value 为 值 的键值对。
f.slowGet
// 一个存储 InternalThreadLocalMap 对象的 ThreadLocal,这个属性是为了兼容直接通过 Thread 来
// 使用 FastThreadLocal 对象的情况
// 因为 FastThreadLocal 底层真正干活的是 InternalThreadLocalMap 而 Thread 中没有存储这个对象
// 的地方,所以只能绕个弯,通过 ThreadLocal 来缓存每个 Thread 对应的 InternalThreadLocalMap 对象
// 这样 Thread 类也能使用 FastThreadLocal 了。
private static final ThreadLocal<InternalThreadLocalMap> slowThreadLocalMap =
new ThreadLocal<InternalThreadLocalMap>();
private static InternalThreadLocalMap slowGet() {
// 通过 slowThreadLocalMap 获取 InternalThreadLocalMap 对象
InternalThreadLocalMap ret = slowThreadLocalMap.get();
if (ret == null) {
// 没有,则创建一个,并存入 slowThreadLocalMap 中
ret = new InternalThreadLocalMap();
slowThreadLocalMap.set(ret);
}
// 直接返回
return ret;
}
-----------------------------------------------------------------------------------------------------
这个方法通过一个 ThreadLocal 来获取 InternalThreadLocalMap 对象,这样做的目的就是为了兼顾 Thread 类使用 FastThreadLocal 。
方法注释中我也说了,FastThreadLocal 底层干活的是 InternalThreadLocalMap,那么 Thread 中就必须要拿到这个对象,而我们知道 Thread 是肯定没有该对象的,所以需要为 Thread 与 InternalThreadLocalMap 做一个一对一映射,且保证线程安全。
Netty 的做法是通过 ThreadLocal 为每个 Thread 缓存一个 InternalThreadLocalMap 对象,就达到了 Thread 使用 FastThreadLocal 的目的。
但不推荐这样做哈,我编写这篇内容以来,一直强调要按照 Netty 提供给我们的方式进行使用,而不是这种兼容、绕弯的方式(效率低下,XXX都不用)。
g.setKnownNotUnset()
private void setKnownNotUnset(InternalThreadLocalMap threadLocalMap, V value) {
// 根据 index 和获取到的 threadLocalMap 对象,直接通过下标设值
if (threadLocalMap.setIndexedVariable(index, value)) {
// true 则将当前 FastThreadLocal 对象存入 threadLocalMap 的第一个下标处
addToVariablesToRemove(threadLocalMap, this);
}
}
-----------------------------------------------------------------------------------------------------
可以看到设值的底层是直接通过 InternalThreadLocalMap 的 setIndexedVariable 方法完成的,之后如果方法返回 true 则执行后续逻辑。
下面来看看设值方法:
h.expandIndexedVariableTableAndSet
private void expandIndexedVariableTableAndSet(int index, Object value) {
// 局部变量
Object[] oldArray = indexedVariables;
final int oldCapacity = oldArray.length;
int newCapacity;
// 根据传进来的 index 计算最新的数组容量,也即最近一个大于 index 的 幂次方值
if (index < ARRAY_LIST_CAPACITY_EXPAND_THRESHOLD) {
// 看看是不是有点熟悉(HashMap)
newCapacity = index;
newCapacity |= newCapacity >>> 1;
newCapacity |= newCapacity >>> 2;
newCapacity |= newCapacity >>> 4;
newCapacity |= newCapacity >>> 8;
newCapacity |= newCapacity >>> 16;
newCapacity ++;
} else {
newCapacity = ARRAY_LIST_CAPACITY_MAX_SIZE;
}
// 调用 Arrays 方法创建一个新数组,并将旧值原封不动的移过去
Object[] newArray = Arrays.copyOf(oldArray, newCapacity);
// 没值的数组下标初始化为 UNSET
Arrays.fill(newArray, oldCapacity, newArray.length, UNSET);
// 将 value 设置到新数组中
newArray[index] = value;
// indexedVariables 指向新数组
indexedVariables = newArray;
}
-----------------------------------------------------------------------------------------------------
该方法先计算新数组的容量,然后通过 Arrays 生成新的数组并将旧值迁移到新数组中,接着将空下标值初始化为 UNSET ,最后在 index 处将 value 设值进去,最后将新数赋给 indexedVariables。
思考一下,通过 index 确定扩容后的数组大小,会不会存在浪费空间问题?
i.addToVariablesToRemove
// 类加载的时候就会执行 nextVariableIndex 方法,给 VARIABLES_TO_REMOVE_INDEX 赋值,为 0
public static final int VARIABLES_TO_REMOVE_INDEX = nextVariableIndex();
private static void addToVariablesToRemove(InternalThreadLocalMap threadLocalMap, FastThreadLocal<?> variable) {
// 根据下标获取值,VARIABLES_TO_REMOVE_INDEX 为常量 0
Object v = threadLocalMap.indexedVariable(VARIABLES_TO_REMOVE_INDEX);
// 定义一个 set 集合
Set<FastThreadLocal<?>> variablesToRemove;
// 如果 InternalThreadLocalMap 中下标为 0 的值为 UNSET 或者 null
if (v == InternalThreadLocalMap.UNSET || v == null) {
// 创建一个 set 类型集合
variablesToRemove = Collections.newSetFromMap(new IdentityHashMap<FastThreadLocal<?>, Boolean>());
// 将 set 集合类型设置到 indexedVariables 数组中的第一个位置
threadLocalMap.setIndexedVariable(VARIABLES_TO_REMOVE_INDEX, variablesToRemove);
} else {
// 下标为 0 处有值,强转为 set 类型
variablesToRemove = (Set<FastThreadLocal<?>>) v;
}
// 项 set 集合中添加当前 FastThreadLocal 对象
variablesToRemove.add(variable);
}
// 根据下标获取对应的值,如果下标超出数组长度返回 UNSET
public Object indexedVariable(int index) {
Object[] lookup = indexedVariables;
return index < lookup.length? lookup[index] : UNSET;
}
-----------------------------------------------------------------------------------------------------
该方法的作用是将 FastThreadLocalThread 中 InternalThreadLocalMap 对象中的 indexedVariables 数组下标为 0 的位置设置为 set 集合,并将当前 FastThreadLocal 对象存入进去。
现在就能解释 setIndexedVariable 方法返回 true/false 的原因了?
因为 FastThreadLocal 设值完值后,会将当前 FastThreadLocal 对象存入到 indexedVariables 数组下标为 0 的 set 集合中。如果 FastThreadLocal 第一次调用 set 方法,那么它肯定就不在数组下标为 0 处的 set 集合中,所以需要返回 true 将其添加进去;反之 FastThreadLocal 多次调用 set 方法,那么它肯定就在数组下标为 0 的 set 集合中,所以需要返回 false 无需重复将其放进去。
j.get 方法
public final V get() {
// 先获取当前线程的 map 对象
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();
// 根据当前 FastThreadLocal 对象的 index 获取对应数组下标值
Object v = threadLocalMap.indexedVariable(index);
if (v != InternalThreadLocalMap.UNSET) {
// 有值,强转返回出去
return (V) v;
}
// 否则初始化值,并返回一个初始值出去
return initialize(threadLocalMap);
}
-----------------------------------------------------------------------------------------------------
该方法比较简单,先获取线程对应的 map 然后根据下标取值,有值则返回没值则初始化。下面我们看看初始化值的方法:
k.initialize
private V initialize(InternalThreadLocalMap threadLocalMap) {
V v = null;
try {
// 调用待子类实现的初始值方法,为实现时为 null
v = initialValue();
if (v == InternalThreadLocalMap.UNSET) {
throw new IllegalArgumentException("InternalThreadLocalMap.UNSET can not be initial value.");
}
} catch (Exception e) {
PlatformDependent.throwException(e);
}
// 在对应下标处设值
threadLocalMap.setIndexedVariable(index, v);
// 将当前 FastThreadLocal 对象设置到 map 中数组下标为 0 的 set 集合中
addToVariablesToRemove(threadLocalMap, this);
// 返回初始化的值
return v;
}
// 空实现
protected V initialValue() throws Exception {
return null;
}
-----------------------------------------------------------------------------------------------------
get 方法比较简单,通过下标 index 去数组中获取值,时间复杂度为 O(1) ,比 JDK 提供的 ThreadLocal 效率高。当不存在值时,也和 JDK 提供的 ThreadLocal 类似,设置一个默认值进去(initialValue 方法提供的值)。
l.remove 方法
public final void remove() {
remove(InternalThreadLocalMap.getIfSet());
}
-----------------------------------------------------------------------------------------------------
这个方法先获取 FastThreadLocal 的 map 对象如果没有则设值一个,然后调用 remove 重载方法进行移除数据。
m.InternalThreadLocalMap.getIfSet()
public static InternalThreadLocalMap getIfSet() {
// 获取当前线程对象
Thread thread = Thread.currentThread();
if (thread instanceof FastThreadLocalThread) {
// 根据 FastThreadLocalThread 获取 map
return ((FastThreadLocalThread) thread).threadLocalMap();
}
// 因为是普通 Thread ,所以需要访问 map 中的 ThreadLocal 类型属性进行获取
return slowThreadLocalMap.get();
}
-----------------------------------------------------------------------------------------------------
可以看到,就是一个简单的获取,如果没有的话直接返回 null 出去。
n.remove()
public final void remove(InternalThreadLocalMap threadLocalMap) {
// map 为 null 就结束
if (threadLocalMap == null) {
return;
}
// 调用 removeIndexedVariable 移除 index 处的值,并返回
Object v = threadLocalMap.removeIndexedVariable(index);
if (v != InternalThreadLocalMap.UNSET) {
// 应为数组 index 处的值已经被移除了,所以缓存在 map 数组 0 位置 set 集合
// 中的 FastThreadLocal 对象也要移除
removeFromVariablesToRemove(threadLocalMap, this);
try {
// 子类实现,空方法
onRemoval((V) v);
} catch (Exception e) {
PlatformDependent.throwException(e);
}
}
}
protected void onRemoval(@SuppressWarnings("UnusedParameters") V value) throws Exception { }
-----------------------------------------------------------------------------------------------------
该方法先判断传入的 InternalThreadLocalMap 是否为空,如果为空则结束该方法。接着主要做了两件事情:
移除 map 中数组下标为 index 中的值
移除 map 中数组下标为 0 中 set 集合中的 FastThreadLocal 对象
下面来分别看看这两个方法:
o.removeIndexedVariable
public Object removeIndexedVariable(int index) {
// 获取数组,index 小于数组长度,则将数组 index 下标处的值赋为 UNSET,并将旧值返回
// index 大于数组长度,那就直接返回 UNSET
Object[] lookup = indexedVariables;
if (index < lookup.length) {
Object v = lookup[index];
lookup[index] = UNSET;
return v;
} else {
return UNSET;
}
}
-----------------------------------------------------------------------------------------------------
该方法很简单,看我注释即可。
p.removeFromVariablesToRemove
private static void removeFromVariablesToRemove(
InternalThreadLocalMap threadLocalMap, FastThreadLocal<?> variable) {
// 获取 map 中下标为 0 的值
Object v = threadLocalMap.indexedVariable(VARIABLES_TO_REMOVE_INDEX);
// 为空 直接结束
if (v == InternalThreadLocalMap.UNSET || v == null) {
return;
}
// 强转为 set 结合然后移除 FastThreadLocal 对象
@SuppressWarnings("unchecked")
Set<FastThreadLocal<?>> variablesToRemove = (Set<FastThreadLocal<?>>) v;
variablesToRemove.remove(variable);
}
-----------------------------------------------------------------------------------------------------
该方法也是很简单,先获取 map 中下标为 0 的 set 集合,如果不存在就直接结束
反之将值强转为 set 集合接着调用 set 的 remove 方法移除 FastThreadLocal 对象
q.removeAll()
public static void removeAll() {
// 获取当前线程的 map
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.getIfSet();
// 空就结束
if (threadLocalMap == null) {
return;
}
try {
// 获取 map 数组中下标为 0 的 set 集合
Object v = threadLocalMap.indexedVariable(VARIABLES_TO_REMOVE_INDEX);
if (v != null && v != InternalThreadLocalMap.UNSET) {
// 不为空,且不为 UNSET
@SuppressWarnings("unchecked")
// 强转为 set
Set<FastThreadLocal<?>> variablesToRemove = (Set<FastThreadLocal<?>>) v;
// 将 set 集合转为 FastThreadLocal 数组对象
FastThreadLocal<?>[] variablesToRemoveArray =
variablesToRemove.toArray(new FastThreadLocal[0]);
// 遍历
for (FastThreadLocal<?> tlv: variablesToRemoveArray) {
// 调用每个 FastThreadLocal 对象的 remove 方法(移除 index 下标值 + set 集合值)
tlv.remove(threadLocalMap);
}
}
} finally {
// 将当前线程中的 map 设为 null
InternalThreadLocalMap.remove();
}
}
-----------------------------------------------------------------------------------------------------
该方法会将当前线程中设置的所有 FastThreadLocal 对象设置的值都移除,并且最后会将 map 设为 null。
这里就体现了为啥需要将 map 中的数组对象下标为 0 的地方存为 set 集合了(存有当前线程的所有 FastThreadLocal 对象)
当一个线程完成了业务逻辑之后,需要移除该线程中设置的所有 FastThreadLocal 对象
而当前线程中的 map 对象数组属性如果都拿来存值就无法实现这一点,会造成内存泄漏
所以就将数组的 0 下标用来存该线程操作的所有 FastThreadLocal 对象结合
就可以实现这点。还有 FastThreadLocal 的 size 方法也有体现
获取当前线程中存入的 FastThreadLocal 数量也可以通过 map 下标为 0 的 set 集合提供的方法(O(1))得到
而不用通过遍历数组才能获得(O(n))
最后再来看看移除 map 方法:
r.InternalThreadLocalMap.remove()
public static void remove() {
// 获取当前线程对象
Thread thread = Thread.currentThread();
if (thread instanceof FastThreadLocalThread) {
// 将 FastThreadLocalThread 类中的 map 设为 null
((FastThreadLocalThread) thread).setThreadLocalMap(null);
} else {
// 移除 ThreadLocal 中 thread 与 map 的映射
slowThreadLocalMap.remove();
}
}
-----------------------------------------------------------------------------------------------------
方法很简单,如果为 FastThreadLocalThread 线程,那么直接将线程中的 map 属性设为 null
反之则移除 map 中 ThreadLocal 中 Thread 与 map 的映射关系即可(目的:让 Thread 找不到 map)
4.9 [2]常用API
01.常用API
a.ThreadLocal.get()
获取当前线程的本地变量值
b.ThreadLocal.set(T value)
设置当前线程的本地变量值
c.ThreadLocal.remove()
移除当前线程的本地变量值
d.ThreadLocal.initialValue()
返回当前线程本地变量的初始值,默认返回null,可以重写以提供初始值
01.ThreadLocal.get()
a.定义
获取当前线程的本地变量值
b.代码
public class ThreadLocalGetExample {
private static final ThreadLocal<String> threadLocal = ThreadLocal.withInitial(() -> "Default Value");
public static void main(String[] args) {
System.out.println("Initial Value: " + threadLocal.get()); // 输出: Default Value
threadLocal.set("New Value");
System.out.println("Updated Value: " + threadLocal.get()); // 输出: New Value
}
}
02.ThreadLocal.set(T value)
a.定义
设置当前线程的本地变量值
b.代码
public class ThreadLocalSetExample {
private static final ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
threadLocal.set(42);
System.out.println("Set Value: " + threadLocal.get()); // 输出: 42
}
}
03.ThreadLocal.remove()
a.定义
移除当前线程的本地变量值
b.代码
public class ThreadLocalRemoveExample {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
threadLocal.set("Temporary Value");
System.out.println("Before Remove: " + threadLocal.get()); // 输出: Temporary Value
threadLocal.remove();
System.out.println("After Remove: " + threadLocal.get()); // 输出: null
}
}
04.ThreadLocal.initialValue()
a.定义
返回当前线程本地变量的初始值,默认返回 null,可以重写以提供初始值
b.代码
public class ThreadLocalInitialValueExample {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<String>() {
@Override
protected String initialValue() {
return "Initial Value";
}
};
public static void main(String[] args) {
System.out.println("Initial Value: " + threadLocal.get()); // 输出: Initial Value
}
}
4.10 [2]应用场景
00.应用场景
a.多线程共享变量
第一个是加锁synchronized
第二个是使用ThreadLocal
b.用户会话管理
在Web应用中,可以使用ThreadLocal存储用户的会话信息
例如用户ID、用户角色等。这样每个请求处理线程可以安全地访问和修改当前用户的会话数据,而不会影响其他线程
c.数据库连接管理
可以使用ThreadLocal来管理数据库连接
例如,为每个线程提供一个数据库连接对象,这样就可以避免多线程情况下的连接冲突,提高并发性能
d.事务管理
在处理分布式事务或复杂业务逻辑时,可以使用 ThreadLocal 存储事务上下文信息
每个线程可以在本地获取到自己对应的事务信息,而不必通过全局上下文共享
e.对象状态管理
在一些需要保留状态的场景中,可以使用ThreadLocal来存储对象的状态信息
比如在实现某些设计模式(如单例模式)时,确保状态信息的线程安全性
f.日志上下文信息
在日志记录时,使用ThreadLocal存储日志上下文信息(如请求 ID、用户 ID 等)
可以方便地在日志中添加与当前线程相关的上下文信息
g.其他
在JDK8之前,为了解决SimpleDateFormat的线程安全问题
在spring事务中,保证一个线程下,一个事务的多个操作拿到的是一个Connection
01.多线程共享变量
a.场景
将创建一个线程安全的计数器,每个线程都有自己的计数副本。
b.代码
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadLocalExample {
// 定义一个 ThreadLocal 变量
private static ThreadLocal<Integer> threadLocalCounter = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3);
// 创建多个线程
for (int i = 0; i < 3; i++) {
final int threadId = i;
executor.execute(() -> {
// 每个线程都从 ThreadLocal 中获取计数器,并进行自增
for (int j = 0; j < 5; j++) {
int count = threadLocalCounter.get();
count++;
threadLocalCounter.set(count);
System.out.println("Thread " + threadId + ": " + count);
}
});
}
// 关闭线程池
executor.shutdown();
}
}
02.用户会话管理
a.场景
将模拟一个简单的用户会话管理系统,其中每个线程可以存取和修改当前用户的会话信息。
b.代码
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class UserSession {
private String userId;
private String userName;
public UserSession(String userId, String userName) {
this.userId = userId;
this.userName = userName;
}
public String getUserId() {
return userId;
}
public String getUserName() {
return userName;
}
}
public class ThreadLocalUserSessionExample {
// 定义一个 ThreadLocal 变量,用于存储用户会话
private static ThreadLocal<UserSession> userSessionThreadLocal = ThreadLocal.withInitial(() -> null);
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3);
// 模拟用户会话
for (int i = 1; i <= 3; i++) {
final int userId = i;
executor.execute(() -> {
// 创建并设置用户会话
UserSession userSession = new UserSession("User" + userId, "UserName" + userId);
userSessionThreadLocal.set(userSession);
// 模拟业务逻辑,打印当前线程的用户会话信息
printUserSession();
// 清理 ThreadLocal 变量
userSessionThreadLocal.remove();
});
}
// 关闭线程池
executor.shutdown();
}
private static void printUserSession() {
UserSession session = userSessionThreadLocal.get();
if (session != null) {
System.out.println("Thread ID: " + Thread.currentThread().getName() +
", User ID: " + session.getUserId() +
", User Name: " + session.getUserName());
} else {
System.out.println("Thread ID: " + Thread.currentThread().getName() +
", No user session found.");
}
}
}
c.代码
a.BaseContext类
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
public static void removeCurrentId() {
threadLocal.remove();
}
}
b.JwtTokenAdminInterceptor类
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// ...
String token = request.getHeader(jwtProperties.getAdminTokenName());
// 校验令牌
try {
// ...
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
BaseContext.setCurrentId(empId); // 设置当前线程的员工ID
// 通过,放行
return true;
} catch (Exception ex) {
// 不通过,响应401状态码
response.setStatus(401);
return false;
}
}
c.EmployeeServiceImpl类
@Override
public void insert(EmployeeDTO employeeDTO) {
// ...
// 设置当前记录创建人id和修改人id
employee.setCreateUser(BaseContext.getCurrentId()); // 获取当前线程的员工ID
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.insert(employee);
}
03.数据库连接管理
a.场景
ThreadLocal可以用于管理数据库连接,为每个线程提供一个独立的连接对象,避免多线程情况下的连接冲突,提高并发性能
b.代码
public class DatabaseConnectionExample {
private static final ThreadLocal<Connection> connectionHolder = new ThreadLocal<>();
public static Connection getConnection() {
Connection connection = connectionHolder.get();
if (connection == null) {
connection = createNewConnection();
connectionHolder.set(connection);
}
return connection;
}
private static Connection createNewConnection() {
// 创建新的数据库连接
return new Connection();
}
}
04.事务管理
a.场景
在处理分布式事务或复杂业务逻辑时,ThreadLocal 可以用于存储事务上下文信息,使每个线程能够在本地获取到自己对应的事务信息
b.代码
public class TransactionManager {
private static final ThreadLocal<Transaction> transactionHolder = new ThreadLocal<>();
public static void startTransaction() {
Transaction transaction = new Transaction();
transactionHolder.set(transaction);
}
public static Transaction getTransaction() {
return transactionHolder.get();
}
}
05.对象状态管理
a.场景
在需要保留状态的场景中,ThreadLocal 可以用于存储对象的状态信息,确保状态信息的线程安全性。
b.代码
public class ObjectStateExample {
private static final ThreadLocal<ObjectState> stateHolder = ThreadLocal.withInitial(ObjectState::new);
public static ObjectState getState() {
return stateHolder.get();
}
}
06.日志上下文信
a.场景
在日志记录时,ThreadLocal 可以用于存储日志上下文信息(如请求 ID、用户 ID 等),方便在日志中添加与当前线程相关的上下文信息
b.代码
public class LoggingContextExample {
private static final ThreadLocal<LoggingContext> loggingContextHolder = new ThreadLocal<>();
public static void setLoggingContext(LoggingContext context) {
loggingContextHolder.set(context);
}
public static LoggingContext getLoggingContext() {
return loggingContextHolder.get();
}
}
4.11 [2]应用场景:用户会话
01.定义
ThreadLocal是Java提供的一种机制,用于在同一线程中存储和访问数据
它为每个线程提供独立的变量副本,确保线程间数据隔离
02.原理
ThreadLocal通过为每个线程维护一个独立的变量副本,避免了线程间的数据共享问题
每个线程可以独立地设置和获取ThreadLocal变量,而不影响其他线程
03.常用API
ThreadLocal<T> threadLocal = new ThreadLocal<>(); 创建ThreadLocal对象
threadLocal.set(T value); 设置当前线程的ThreadLocal变量
T value = threadLocal.get(); 获取当前线程的ThreadLocal变量
threadLocal.remove(); 移除当前线程的ThreadLocal变量
04.使用步骤
创建ThreadLocal对象:定义一个ThreadLocal变量,用于存储用户状态信息
设置用户状态:在请求处理过程中,将用户状态信息存储到ThreadLocal中
获取用户状态:在需要的地方,通过ThreadLocal获取用户状态信息
清理ThreadLocal:在请求处理完毕后,清理ThreadLocal中的数据,避免内存泄漏
05.场景代码示例
a.场景1:创建ThreadLocal对象
public class UserContext {
private static final ThreadLocal<String> userThreadLocal = new ThreadLocal<>();
public static void setUser(String user) {
userThreadLocal.set(user);
}
public static String getUser() {
return userThreadLocal.get();
}
public static void clear() {
userThreadLocal.remove();
}
}
b.场景2:设置用户状态
// 在SpringMVC拦截器中设置用户状态
public class UserInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String user = request.getHeader("User");
UserContext.setUser(user);
return true;
}
}
c.场景3:获取用户状态
// 在业务逻辑中获取用户状态
public void someBusinessMethod() {
String user = UserContext.getUser();
System.out.println("Current user: " + user);
}
d.场景4:清理ThreadLocal
// 在SpringMVC拦截器后置处理方法中清理ThreadLocal
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
UserContext.clear();
}
4.12 [2]父子传递:InheritableThreadLocal
01.定义
InheritableThreadLocal 是 ThreadLocal 的一个子类
允许父线程在创建子线程时,将本地变量的值传递给子线程
它解决了标准 ThreadLocal 无法在父子线程间共享数据的问题
02.原理
a.继承机制
当父线程创建一个子线程时,InheritableThreadLocal 会将父线程的本地变量值复制到子线程中
b.ThreadLocalMap
与 ThreadLocal 类似,InheritableThreadLocal 也使用 ThreadLocalMap 来存储线程本地变量,
但在子线程创建时会从父线程的 ThreadLocalMap 中复制数据
03.常用API
InheritableThreadLocal.get():获取当前线程的本地变量值
InheritableThreadLocal.set(T value):设置当前线程的本地变量值
InheritableThreadLocal.remove():移除当前线程的本地变量值
04.详情
数据传递:在子线程创建时,InheritableThreadLocal 自动将父线程的变量值复制到子线程中
独立副本:子线程获得的是父线程变量的副本,之后的修改不会影响父线程的变量值
重写 childValue():可以通过重写 childValue(T parentValue) 方法,自定义子线程接收到的变量值
05.应用场景
上下文传递:在多线程环境中,需要在父子线程间传递上下文信息,如用户会话、事务上下文等
日志跟踪:在日志记录中,传递父线程的日志上下文信息到子线程,确保日志的完整性和一致性
任务调度:在任务调度系统中,传递父线程的调度信息到子线程,确保任务执行的正确性
06.代码示例
a.说明
父线程在创建子线程时,InheritableThreadLocal 将父线程的变量值传递给子线程
子线程可以读取和修改自己的副本,而不会影响父线程的变量值
通过这种方式,可以在父子线程间实现数据的传递和共享
b.代码
public class InheritableThreadLocalExample {
private static final InheritableThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
public static void main(String[] args) {
inheritableThreadLocal.set("Parent Thread Value");
Runnable task = () -> {
System.out.println(Thread.currentThread().getName() + " - Inherited Value: " + inheritableThreadLocal.get());
inheritableThreadLocal.set("Child Thread Value");
System.out.println(Thread.currentThread().getName() + " - Updated Value: " + inheritableThreadLocal.get());
};
Thread childThread = new Thread(task, "Child-Thread");
childThread.start();
// 父线程的值不受子线程修改的影响
System.out.println(Thread.currentThread().getName() + " - Parent Value: " + inheritableThreadLocal.get());
}
}
4.13 [3]ThreadLocal:11连问
00.汇总
1.为什么要用ThreadLocal?
2.ThreadLocal的原理是什么?
3.为什么用ThreadLocal做key?
4.Entry的key为什么设计成弱引|用?
5.ThreadLocal真的会导致内存泄露?
6.如何解决内存泄露问题?
7.ThreadLocal是如何定位数据的?
8.ThreadLocal是如何扩容的?
9.父子线程如何共享数据?
10.线程池中如何共享数据?
11.ThreadLocal有哪些用途?
01.为什么要用ThreadLocal?
a.背景
并发编程中,多个线程同时修改公共变量可能导致线程安全问题。JDK提供了synchronized或Lock来解决,但在高并发场景中可能导致锁竞争和系统响应变慢。
b.ThreadLocal的核心思想
共享变量在每个线程都有一个副本,每个线程操作的都是自己的副本,对其他线程没有影响。
c.示例
---
@Service
public class ThreadLocalService {
private static final ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public void add() {
threadLocal.set(1);
doSamething();
Integer integer = threadLocal.get();
}
}
02.ThreadLocal的原理是什么?
a.源码分析
ThreadLocal的内部有一个静态的内部类ThreadLocalMap。
public class ThreadLocal<T> {
...
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
static class ThreadLocalMap {
...
}
...
}
b.ThreadLocalMap的结构
ThreadLocalMap包含一个静态的内部类Entry,该类继承于WeakReference类,说明Entry是一个弱引用。
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
...
private Entry[] table;
...
}
c.引用关系
在每个Thread类中,都有一个ThreadLocalMap的成员变量,该变量包含了一个Entry数组,该数组保存了ThreadLocal类set的数据。
03.为什么用ThreadLocal做key?
a.原因
如果在应用中,一个线程中使用了多个ThreadLocal对象,使用Thread做key会导致无法区分不同的ThreadLocal对象。
b.示例
@Service
public class ThreadLocalService {
private static final ThreadLocal<Integer> threadLocal1 = new ThreadLocal<>();
private static final ThreadLocal<Integer> threadLocal2 = new ThreadLocal<>();
private static final ThreadLocal<Integer> threadLocal3 = new ThreadLocal<>();
}
c.解决方案
使用ThreadLocal对象做key,这样才能通过具体ThreadLocal对象的get方法获取到想要的ThreadLocal对象。
04.Entry的key为什么设计成弱引用?
a.原因
如果key对ThreadLocal对象是强引用,可能导致内存泄露。
b.设计
JDK的开发者们把Entry的key设计成了弱引用,弱引用的对象在GC做垃圾清理时会被自动回收。
c.示例
public static void main(String[] args) {
WeakReference<Object> weakReference0 = new WeakReference<>(new Object());
System.out.println(weakReference0.get());
System.gc();
System.out.println(weakReference0.get());
}
05.ThreadLocal真的会导致内存泄露?
a.问题
如果ThreadLocalMap中存在很多key为null的Entry
但后续程序没有调用有效的ThreadLocal的get、set或remove方法,可能导致内存泄露
06.如何解决内存泄露问题?
a.解决方案
调用ThreadLocal对象的remove方法,在使用完ThreadLocal对象之后。
b.示例
public class CurrentUser {
private static final ThreadLocal<UserInfo> THREA_LOCAL = new ThreadLocal();
public static void set(UserInfo userInfo) {
THREA_LOCAL.set(userInfo);
}
public static UserInfo get() {
THREA_LOCAL.get();
}
public static void remove() {
THREA_LOCAL.remove();
}
}
public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
try{
CurrentUser.set(userInfo);
...
UserInfo userInfo = CurrentUser.get();
...
} finally {
CurrentUser.remove();
}
}
07.ThreadLocal是如何定位数据的?
a.定位方法
ThreadLocal的get、set、remove方法中使用hash算法定位数据。
b.示例
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
08.ThreadLocal是如何扩容的?
a.扩容方法
在set方法中会调用rehash方法,扩容前先尝试回收一次key为null的值。
b.示例
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
09.父子线程如何共享数据?
a.问题
使用ThreadLocal无法在父子线程中共享数据。
b.解决方案
使用InheritableThreadLocal。
c.示例
public class ThreadLocalTest {
public static void main(String[] args) {
InheritableThreadLocal<Integer> threadLocal = new InheritableThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
new Thread(() -> {
System.out.println("子线程获取数据:" + threadLocal.get());
}).start();
}
}
10.线程池中如何共享数据?
a.问题
在线程池中使用ThreadLocal无法共享数据。
b.解决方案
使用TransmittableThreadLocal。
c.示例
private static void fun2() throws Exception {
TransmittableThreadLocal<Integer> threadLocal = new TransmittableThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
ExecutorService ttlExecutorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(1));
threadLocal.set(6);
ttlExecutorService.submit(() -> {
System.out.println("第一次从线程池中获取数据:" + threadLocal.get());
});
threadLocal.set(7);
ttlExecutorService.submit(() -> {
System.out.println("第二次从线程池中获取数据:" + threadLocal.get());
});
}
11.ThreadLocal有哪些用途?
a.用途
在spring事务中,保证一个线程下,一个事务的多个操作拿到的是一个Connection。
在hiberate中管理session。
在JDK8之前,为了解决SimpleDateFormat的线程安全问题。
获取当前登录用户上下文。
临时保存权限数据。
使用MDC保存日志信息。
4.14 [3]ThreadLocal、Thread
01.ThreadLocal和Thread的关系
数据实际上是存在ThreadLocalMap中的,ThreadLocalMap归Thread所持有
ThreadLocalMap内部使用的是K-V结构,Key是我们定义的ThreadLocal对象
ThreadLocalMap对ThreadLocal是弱引用关系
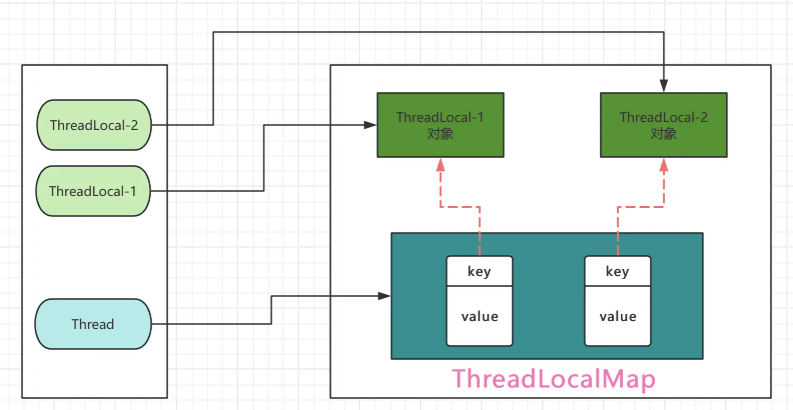
4.15 [3]ThreadLocal如何实现线程资源隔离
00.ThreadLocal如何实现线程资源隔离?
1.ThreadLocal类
2.Thread类中的ThreadLocalMap
3.变量隔离
01.ThreadLocal 类
a.功能
ThreadLocal 提供了 get() 和 set(T value) 方法,用于获取和设置当前线程的本地变量值
b.作用
通过这些方法,ThreadLocal 为每个线程提供了一个独立的变量副本,避免了线程间的共享和竞争
02.Thread类中的ThreadLocalMap
a.结构
每个线程(Thread 对象)内部维护一个 ThreadLocalMap 实例
ThreadLocalMap 是 ThreadLocal 类的静态内部类
b.键值对
在 ThreadLocalMap 中,每个 ThreadLocal 对象作为键,值为线程的本地变量
c.独立性
由于每个线程都有自己的 ThreadLocalMap,因此不同线程之间的变量是相互独立的
03.变量隔离
a.存储机制
当线程调用 ThreadLocal 的 set(T value) 方法时,实际上是将值存储在当前线程的 ThreadLocalMap 中
b.获取机制
当线程调用 get() 方法时,从当前线程的 ThreadLocalMap 中获取值
c.隔离性
因为每个线程都有独立的 ThreadLocalMap,所以不同线程之间的变量相互隔离,不会互相影响
04.示例代码
a.说明
独立副本:在这个示例中,每个线程都有自己的 ThreadLocal 变量副本,存储在各自的 ThreadLocalMap 中
变量隔离:通过 set() 和 get() 方法,线程可以独立地访问和修改自己的变量,而不会影响其他线程的变量
线程安全:这种机制确保了线程间的变量隔离和线程安全,避免了多线程环境中的共享和竞争问题
b.代码
public class ThreadLocalIsolationExample {
private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
Runnable task = () -> {
int value = threadLocal.get();
System.out.println(Thread.currentThread().getName() + " - Initial Value: " + value);
threadLocal.set(value + 1);
System.out.println(Thread.currentThread().getName() + " - Updated Value: " + threadLocal.get());
};
Thread thread1 = new Thread(task, "Thread-1");
Thread thread2 = new Thread(task, "Thread-2");
thread1.start();
thread2.start();
}
}
4.16 [3]为什么ThreadLocalMap里的Key是弱引用
01.说明
那为什么ThreadLocalMap里的Key是使用ThreadLocal呢?为什么又是弱引用呢?
这就不得不说JDK的设计者的思想非常精妙了,有3点妙处
02.JDK设计
a.设计1
一个线程要是存了多种数据,总得有个规则去找他们,那就根据定义的ThreadLocal对象去找吧
b.设计2
对于开发者来说,他只需要使用ThreadLocal去保存数据即可,无需关系底层结构
也就是说对外暴露简单的使用方式即可,对于不需要调用方知道的细节全部隐藏
c.设计3
一般情况下Thread的生命周期会很长,比如Web容器启动后,就会启动大量的线程丢到线程池中复用
所以ThreadLocalMap的生命周期也会很长。但是,ThreadLocal对象存在的周期不一定长
如果,ThreadLocalMap的Key对ThreadLocal是强引用的话
那么ThreadLocal对象就会一直存在于内存中得不到释放,最终会导致内存溢出,所以采用了弱引用。
4.17 [3]ThreadLocal为什么用弱引用来防止内存泄漏
00.为什么使用ThreadLocal时需要用弱引用来防止内存泄漏?
1.弱引用:允许ThreadLocal被垃圾回收,避免内存泄漏
2.自动清理:回收后,ThreadLocalMap可以清理相应的值,确保内存有效释放
01.ThreadLocalMap的结构
a.键的引用
在 ThreadLocalMap 中,ThreadLocal 对象作为键被存储为弱引用
这意味着如果没有其他强引用指向 ThreadLocal 对象,那么在垃圾回收时,ThreadLocal 对象可以被回收
b.值的引用
与键不同,ThreadLocalMap 中的值是强引用。这意味着只要键存在,值就会一直存在
02.弱引用的作用
a.防止内存泄漏
如果 ThreadLocal 对象被垃圾回收,那么对应的键会被自动清除
这样,ThreadLocalMap 中的条目就不会因为 ThreadLocal 对象的存在而导致内存泄漏
b.自动清理
当 ThreadLocal 对象被回收后,ThreadLocalMap 可以清理相应的值,确保内存有效释放
03.内存泄漏的风险
a.未清理的值
如果 ThreadLocal 对象被回收,但对应的值没有被及时清理,可能会导致内存泄漏
尤其是在长生命周期的线程中(如线程池中的线程)
b.解决方案
为了避免这种情况,建议在不再需要使用 ThreadLocal 时,显式调用 remove() 方法来清除当前线程的本地变量
4.18 [3]Netty为什么放弃使用ThreadLocal,而是自定义了一个FastThreadLocal
01.性能优化
a.减少内存访问延迟
FastThreadLocal 的实现比标准 ThreadLocal 更高效,减少了内存访问延迟
Netty 需要在高并发环境下处理大量的网络请求,因此对性能的要求非常高
b.降低锁的使用
FastThreadLocal 通过优化的内存管理策略,减少了锁的使用,从而提高了并发性能
02.内存管理
a.减少内存泄漏风险
FastThreadLocal 使用了优化的内存管理策略,减少了内存泄漏的风险和垃圾回收(GC)的开销
Netty 需要长时间运行,因此内存管理非常关键
b.自定义内存管理
通过自定义线程局部存储机制,FastThreadLocal 能够更好地控制内存的分配和回收,避免了标准 ThreadLocal 可能带来的内存泄漏问题
03.垃圾回收
a.更好的 GC 支持
FastThreadLocal 提供了更好的支持以避免垃圾回收中的内存泄漏,特别是在大量线程的环境中
Netty 需要处理大量的并发连接,因此需要更高效的垃圾回收机制
04.功能扩展
a.灵活的功能
FastThreadLocal 支持更灵活的功能,比如更高效的清理机制和更少的内存使用开销
这使得 Netty 能够在高性能网络应用中更好地满足需求
5 TransmittableThreadLocal:ThreadLocal增强版
5.1 定义
01.定义
TransmittableThreadLocal是ThreadLocal的增强版
支持在使用线程池等多线程框架时,父线程的上下文可以传递到子线程中
它解决了标准ThreadLocal在线程池环境下无法传递上下文的问题
5.2 原理
01.原理
上下文传递:通过 TtlRunnable 和 TtlCallable 对任务进行包装,确保上下文信息能够在任务执行时正确传递到子线程中
线程池增强:可以使用 TtlExecutors.getTtlExecutorService() 方法对线程池进行增强,自动处理上下文的传递
兼容性:TransmittableThreadLocal 可以与现有的线程池和多线程框架兼容使用,确保上下文的一致性
5.3 常用API
01.常用API
TransmittableThreadLocal.get():获取当前线程的本地变量值
TransmittableThreadLocal.set(T value):设置当前线程的本地变量值
TransmittableThreadLocal.remove():移除当前线程的本地变量值
TtlRunnable.get(Runnable task):包装 Runnable 任务,使其支持上下文传递
TtlCallable.get(Callable<T> task):包装 Callable 任务,使其支持上下文传递
5.4 项目使用
01.依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.12.5</version>
</dependency>
02.配置
TransmittableThreadLocal 不需要特别的配置,只需在代码中使用即可。它可以与现有的线程池和多线程框架兼容使用
使用 TransmittableThreadLocal 的步骤与 ThreadLocal 类似,但在使用线程池时,需要对任务进行包装,以确保上下文的传递
03.基本使用
import com.alibaba.ttl.TransmittableThreadLocal;
public class BasicUsageExample {
private static final TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
public static void main(String[] args) {
context.set("Parent Context");
Runnable task = () -> {
System.out.println(Thread.currentThread().getName() + " - Context: " + context.get());
};
Thread thread = new Thread(task);
thread.start();
}
}
04.在线程池中使用
import com.alibaba.ttl.TransmittableThreadLocal;
import com.alibaba.ttl.TtlRunnable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolUsageExample {
private static final TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
context.set("Parent Context");
Runnable task = () -> {
System.out.println(Thread.currentThread().getName() + " - Context: " + context.get());
};
// 使用 TtlRunnable 包装任务
executorService.submit(TtlRunnable.get(task));
context.set("Updated Parent Context");
// 使用 TtlRunnable 包装任务
executorService.submit(TtlRunnable.get(task));
executorService.shutdown();
}
}
05.使用TtlCallable
import com.alibaba.ttl.TransmittableThreadLocal;
import com.alibaba.ttl.TtlCallable;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class CallableUsageExample {
private static final TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(2);
context.set("Parent Context");
Callable<String> task = () -> {
return Thread.currentThread().getName() + " - Context: " + context.get();
};
// 使用 TtlCallable 包装任务
Future<String> future = executorService.submit(TtlCallable.get(task));
System.out.println(future.get());
executorService.shutdown();
}
}
06.自定义线程池
import com.alibaba.ttl.threadpool.TtlExecutors;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CustomThreadPoolExample {
private static final TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
public static void main(String[] args) {
ExecutorService executorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(2));
context.set("Parent Context");
Runnable task = () -> {
System.out.println(Thread.currentThread().getName() + " - Context: " + context.get());
};
executorService.submit(task);
context.set("Updated Parent Context");
executorService.submit(task);
executorService.shutdown();
}
}
5.5 不能移除remove操作
00.汇总
如果希望实现“自动remove”,正确的方向不是替换 `ThreadLocal` 的实现,
而是通过 Filter/Interceptor 模式在框架层面统一管理 `ThreadLocal` 的生命周期。
这种方式不仅解决了数据污染问题,还提升了代码的可维护性和安全性。
01.问题背景
在线程池环境下,`ThreadLocal` 数据传递和清理是一个常见问题。
用户希望通过将 `ThreadLocal` 替换为阿里巴巴的 `TransmittableThreadLocal` (TTL) 来实现自动调用 `remove()`,以避免数据污染问题。
02.`TransmittableThreadLocal` 的核心功能
a.解决痛点
原生 `ThreadLocal` 的问题:当父线程向线程池提交任务时,线程池中的子线程无法访问父线程设置的 `ThreadLocal` 值,导致上下文信息丢失。
`TransmittableThreadLocal` 的解决方案:通过对 `Runnable`、`Callable` 和线程池进行包装,TTL 可以在任务提交时捕获父线程的 `ThreadLocal` 值,并在子线程执行任务前回放这些值,任务执行完毕后再进行清理。
b.功能范围
TTL 的自动清理机制仅在它所包装的 `Runnable` 或 `Callable` 执行完毕后触发,与跨线程任务传递绑定。
03.为什么 TTL 无法自动清理?
a.场景分析
请求进入:一个Web请求进入,线程 T1 开始处理。
设置TTL值:在代码中调用 `setThreadDataSourceContext("jgdb")`,此时 `TransmittableThreadLocal` 在线程 T1 上设置了一个值。
请求结束:请求处理完毕,线程 T1 被归还到线程池。
在这个过程中,没有发生TTL所关心的“跨线程任务提交”,因此TTL的自动传递和清理逻辑没有被触发。
b.问题根源
线程 T1 被归还到线程池时,它携带的 `TransmittableThreadLocal` 变量和原生 `ThreadLocal` 一样,依然存在,未被清理。
当线程 T1 被用于处理下一个请求时,数据污染问题仍然会发生。
04.解决方案
a.结论
将 `ThreadLocal` 替换为 `TransmittableThreadLocal` 无法解决“自动remove”问题。
`try-finally` 模式依然是必须的,是保证资源正确释放的唯一可靠方式。
b.正确的技术方案:使用 Filter(过滤器)或 Interceptor(拦截器)统一管理 `ThreadLocal` 的生命周期。
a.伪代码示例
public class DataSourceContextFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
try {
// 根据请求动态设置数据源上下文
// String dataSourceName = resolveDataSourceFromRequest(request);
// if (dataSourceName != null) {
// DatabaseUtil41.DataSourceCore.setThreadDataSourceContext(dataSourceName);
// }
// 执行后续的请求处理链
chain.doFilter(request, response);
} finally {
// 请求结束前清理线程上下文
DatabaseUtil41.DataSourceCore.clearThreadDataSourceContext();
}
}
// ... init() and destroy() methods ...
}
b.优势
自动管理:框架层面统一完成数据源的设置和清理,开发人员无需关心。
代码干净:业务逻辑中不再有 `try-finally` 的模板代码,更加专注于业务本身。
绝对安全:从机制上杜绝忘记调用 `clear()` 方法的可能性。
6 ThreadVirtual:虚拟线程
6.1 定义
01.说明
a.版本
Java版本:Java 20.0.2 Oracle
SpringBoot版本:3.1.2
b.定义
虚拟线程是由JVM管理的轻量级线程,不直接映射到操作系统线程,一个操作系统线程可以调度成千上万个虚拟线程
c.优点
轻量级:虚拟线程的创建和销毁开销非常小
高并发:可以在单个JVM中运行数百万个虚拟线程
阻塞操作处理:虚拟线程可以在阻塞操作中挂起,而不阻塞底层操作系统线程
d.优点
阻塞操作处理:虚拟线程提供了类似于其他语言的async/await或suspend的优点,但无需复杂的代码重构
阻塞操作示例:Java中的阻塞操作如Thread.sleep(long)、InputStream.read和OutputStream.write会阻塞线程,虚拟线程可以在执行这些操作时将等待的代码从当前线程移出,待操作完成后再恢复执行
I/O密集型服务:虚拟线程特别适合I/O密集型服务,避免了线程因等待I/O操作而被浪费
02.与其他语言的对比
a.其他语言支持
Rust、Python、C#、TypeScript、JavaScript等语言支持async/await,Kotlin支持suspend
b.JavaScript示例
async function getCustomer() { /* call a database */ }
const result = await getCustomer();
c.async关键字的传播性
在其他语言中,async关键字具有传播性,要求调用链上的所有函数都必须是async,这可能导致代码复杂化
6.2 常用API
01.基本属性和状态管理
getId 获取虚拟线程的唯一标识符(ID)
getName 和 setName 获取和设置虚拟线程的名称
setDaemon 和 isDaemon 设置虚拟线程是否为守护线程和判断虚拟线程是否是守护线程。守护线程在所有非守护线程结束时自动终止
getState 获取虚拟线程的当前状态(NEW、RUNNABLE、BLOCKED、WAITING、TIME_WAITING、TERMINATED)
isAlive 判断虚拟线程是否还在运行
02.线程控制和中断
join 等待虚拟线程终止,调用线程会等待被调用虚拟线程执行完毕后再继续执行
interrupt 和 isInterrupted 中断虚拟线程和判断虚拟线程是否被中断
interrupted 静态方法,检查当前线程是否被中断,并清除中断状态
start 启动虚拟线程,使其开始执行
03.线程上下文和异常处理
currentThread: 静态方法,获取当前正在执行的线程对象
getContextClassLoader 获取虚拟线程的上下文类加载器
setContextClassLoader 设置虚拟线程的上下文类加载器
getUncaughtExceptionHandler 获取虚拟线程的未捕获异常处理器
getUncaughtExceptionHandler 设置虚拟线程的未捕获异常处理器
checkAccess 检查当前线程是否有权限修改该虚拟线程
6.3 代码示例
01.创建和启动虚拟线程
public class VirtualThreadExample {
public static void main(String[] args) {
Thread virtualThread = Thread.ofVirtual().start(() -> {
System.out.println("Hello from a virtual thread!");
});
try {
virtualThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Main thread finished.");
}
}
02.使用虚拟线程处理并发任务
import java.util.stream.IntStream;
public class VirtualThreadConcurrency {
public static void main(String[] args) {
IntStream.range(0, 10).forEach(i -> {
Thread.ofVirtual().start(() -> {
System.out.println("Task " + i + " is running in " + Thread.currentThread().getName());
});
});
System.out.println("All tasks submitted.");
}
}
03.虚拟线程与阻塞操作
public class VirtualThreadBlocking {
public static void main(String[] args) {
Thread virtualThread = Thread.ofVirtual().start(() -> {
try {
System.out.println("Virtual thread sleeping...");
Thread.sleep(2000); // 虚拟线程在此阻塞
System.out.println("Virtual thread awake!");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
virtualThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Main thread finished.");
}
}
6.4 性能对比
00.总结
a.IO密集型场景
虚拟线程在IO密集型场景中表现出色,因为线程大部分时间是在等待IO操作(如数据库、缓存、HTTP请求等)
在这种情况下,虚拟线程可以有效地利用系统资源,减少线程阻塞和上下文切换的开销
b.CPU密集型场景
在CPU密集型场景中,虚拟线程的优势可能不如IO密集型场景明显
因为CPU密集型任务主要依赖于计算能力,而不是IO操作
01.IO密集型任务:对比@Async
a.在SpringBoot中,可以通过配置来使用虚拟线程
@Configuration
@ConditionalOnProperty(prefix = "spring", name = "virtual-thread", havingValue = "true")
public class ThreadConfig {
@Bean
public AsyncTaskExecutor applicationTaskExecutor() {
return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor());
}
@Bean
public TomcatProtocolHandlerCustomizer<?> protocolHandlerCustomizer() {
return protocolHandler -> {
protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor());
};
}
}
b.@Async性能对比
@Service
public class AsyncService {
@Async
public void doSomething(CountDownLatch countDownLatch) throws InterruptedException {
Thread.sleep(50); // 模拟IO操作
countDownLatch.countDown();
}
}
c.性能测试:测试异步方法的执行时间
@Test
public void testAsync() throws InterruptedException {
long start = System.currentTimeMillis();
int n = 100000;
CountDownLatch countDownLatch = new CountDownLatch(n);
for (int i = 0; i < n; i++) {
asyncService.doSomething(countDownLatch);
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "ms");
}
d.结果
虚拟线程耗时:3.9秒
普通线程耗时:678秒左右
结论:虚拟线程在IO密集型任务中表现出接近200倍的性能提升
02.CPU密集型场景:对比HTTP请求
a.在SpringBoot中,可以通过配置来使用虚拟线程
@Configuration
@ConditionalOnProperty(prefix = "spring", name = "virtual-thread", havingValue = "true")
public class ThreadConfig {
@Bean
public AsyncTaskExecutor applicationTaskExecutor() {
return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor());
}
@Bean
public TomcatProtocolHandlerCustomizer<?> protocolHandlerCustomizer() {
return protocolHandler -> {
protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor());
};
}
}
b.HTTP请求示例:模拟IO操作的GET请求
@RequestMapping("/get")
public Object get() throws Exception {
Thread.sleep(50); // 模拟IO操作
return "ok";
}
c.性能测试
使用JMeter进行压力测试,500个并发线程,运行1万次
d.性能结果
普通线程:由于系统线程资源有限,导致请求等待时间较长,90/95/99线都大于150ms。
虚拟线程:即使在高并发下,最大耗时也保持在100ms以下,显著减少了线程等待时间。
7 生产者、消费者
7.1 汇总:3种
00.汇总
wait/notify 使用 synchronized 和 wait/notify 控制线程间通信,适合于简单的生产者-消费者模式
await/signalAll 使用 Lock 和 Condition 提供更灵活的线程间通信机制,适合于复杂的生产者-消费者模式
BlockingQueue 提供线程安全的阻塞队列,简化了生产者-消费者模式的实现,适合于大多数场景
7.2 [1]wait、notify
01.定义
wait/notify 是 Java 提供的用于线程间通信的机制,允许一个线程等待另一个线程的通知
02.原理
生产者在缓冲区满时调用 wait() 进入等待状态,消费者在缓冲区空时调用 wait() 进入等待状态
生产者在生产完数据后调用 notify() 唤醒等待的消费者,消费者在消费完数据后调用 notify() 唤醒等待的生产者
03.常用API
wait(): 使当前线程等待,直到被通知
notify(): 唤醒一个等待线程
notifyAll(): 唤醒所有等待线程
04.使用步骤
1.创建共享缓冲区和锁对象
2.在生产者中使用 wait() 和 notify() 控制生产和通知
3.在消费者中使用 wait() 和 notify() 控制消费和通知
05.代码示例
import java.util.LinkedList;
import java.util.Queue;
public class WaitNotifyExample {
private final Queue<Integer> buffer = new LinkedList<>();
private final int capacity = 5;
public void produce() throws InterruptedException {
int value = 0;
synchronized (buffer) {
while (true) {
while (buffer.size() == capacity) {
buffer.wait();
}
buffer.add(value);
System.out.println("Produced " + value);
value++;
buffer.notify();
Thread.sleep(1000);
}
}
}
public void consume() throws InterruptedException {
synchronized (buffer) {
while (true) {
while (buffer.isEmpty()) {
buffer.wait();
}
int value = buffer.poll();
System.out.println("Consumed " + value);
buffer.notify();
Thread.sleep(1000);
}
}
}
public static void main(String[] args) {
WaitNotifyExample example = new WaitNotifyExample();
Thread producer = new Thread(() -> {
try {
example.produce();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread consumer = new Thread(() -> {
try {
example.consume();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
producer.start();
consumer.start();
}
}
7.3 [3]await/signalAll
01.定义
await/signalAll 是 Condition 接口提供的用于线程间通信的机制,与 Lock 结合使用
02.原理
生产者在缓冲区满时调用 await() 进入等待状态,消费者在缓冲区空时调用 await() 进入等待状态
生产者在生产完数据后调用 signalAll() 唤醒等待的消费者,消费者在消费完数据后调用 signalAll() 唤醒等待的生产者
03.常用API
await(): 使当前线程等待,直到被通知
signal(): 唤醒一个等待线程
signalAll(): 唤醒所有等待线程
04.使用步骤
1.创建共享缓冲区和 Lock 对象
2.使用 Condition 创建条件变量
3.在生产者中使用 await() 和 signalAll() 控制生产和通知
4.在消费者中使用 await() 和 signalAll() 控制消费和通知
05.代码示例
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class AwaitSignalExample {
private final Queue<Integer> buffer = new LinkedList<>();
private final int capacity = 5;
private final Lock lock = new ReentrantLock();
private final Condition notFull = lock.newCondition();
private final Condition notEmpty = lock.newCondition();
public void produce() throws InterruptedException {
int value = 0;
lock.lock();
try {
while (true) {
while (buffer.size() == capacity) {
notFull.await();
}
buffer.add(value);
System.out.println("Produced " + value);
value++;
notEmpty.signalAll();
Thread.sleep(1000);
}
} finally {
lock.unlock();
}
}
public void consume() throws InterruptedException {
lock.lock();
try {
while (true) {
while (buffer.isEmpty()) {
notEmpty.await();
}
int value = buffer.poll();
System.out.println("Consumed " + value);
notFull.signalAll();
Thread.sleep(1000);
}
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
AwaitSignalExample example = new AwaitSignalExample();
Thread producer = new Thread(() -> {
try {
example.produce();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread consumer = new Thread(() -> {
try {
example.consume();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
producer.start();
consumer.start();
}
}
7.4 [4]BlockingQueue
01.定义
BlockingQueue 是 Java 提供的线程安全的队列,支持阻塞操作
02.原理
生产者在缓冲区满时自动阻塞,消费者在缓冲区空时自动阻塞
BlockingQueue 内部实现了线程安全的阻塞和唤醒机制
03.常用API
put(E e): 将元素放入队列,如果队列满则阻塞
take(): 从队列中取出元素,如果队列空则阻塞
04.使用步骤
1.创建 BlockingQueue 实例
2.在生产者中使用 put() 方法放入元素
3.在消费者中使用 take() 方法取出元素
05.代码示例
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class BlockingQueueExample {
private final BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(5);
public void produce() throws InterruptedException {
int value = 0;
while (true) {
queue.put(value);
System.out.println("Produced " + value);
value++;
Thread.sleep(1000);
}
}
public void consume() throws InterruptedException {
while (true) {
int value = queue.take();
System.out.println("Consumed " + value);
Thread.sleep(1000);
}
}
public static void main(String[] args) {
BlockingQueueExample example = new BlockingQueueExample();
Thread producer = new Thread(() -> {
try {
example.produce();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread consumer = new Thread(() -> {
try {
example.consume();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
producer.start();
consumer.start();
}
}
8 异步转为同步
8.1 汇总:5种
01.核心区别
同步调用:调用方阻塞等待结果返回
异步调用:调用方立即返回,通过回调/轮询等方式获取结果
02.5种方式
wait/notify + synchronized
ReentrantLock + Condition
Future:Callable + ExecutorService
CountDownLatch:多线程同步
CyclicBarrier:可重用同步屏障
03.图示
方法 适用场景 核心机制 扩展性
wait/notify 简单生产者-消费者模型 对象锁的等待/通知机制 低
ReentrantLock+Condition 需要多个条件变量 精细条件控制 中
Future 异步任务结果获取 任务提交与结果回调 高
CountDownLatch 多线程等待单一事件 计数器递减触发机制 中
CyclicBarrier 多阶段任务同步 可重置的屏障计数机制 高
04.建议
简单同步场景优先使用CountDownLatch
需要结果返回时使用Future
多条件或多阶段场景推荐CyclicBarrier
避免使用过时的Object.wait/notify直接控制
8.2 [1]wait/notify + synchronized
01.代码示例
public class ProducerConsumerExample {
private static final int BUFFER_SIZE = 5;
private final Object lock = new Object();
private int[] buffer = new int[BUFFER_SIZE];
private int count = 0;
// 生产者线程
public void produce() throws InterruptedException {
int value = 0;
while (true) {
synchronized (lock) {
while (count == BUFFER_SIZE) {
System.out.println("缓冲区已满,生产者等待...");
lock.wait();
}
buffer[count++] = value++;
System.out.println("生产数据: " + value + ",缓冲区数量: " + count);
lock.notify();
}
Thread.sleep(1000);
}
}
// 消费者线程
public void consume() throws InterruptedException {
while (true) {
synchronized (lock) {
while (count == 0) {
System.out.println("缓冲区为空,消费者等待...");
lock.wait();
}
int value = buffer[--count];
System.out.println("消费数据: " + value + ",缓冲区数量: " + count);
lock.notify();
}
Thread.sleep(1500);
}
}
public static void main(String[] args) {
ProducerConsumerExample example = new ProducerConsumerExample();
// 启动生产者和消费者线程
new Thread(example::produce).start();
new Thread(example::consume).start();
}
}
02.关键要点
a.共享资源保护
通过synchronized(lock)保证线程安全
b.条件判断
while循环而非if防止虚假唤醒
缓冲区满时生产者等待(wait())
缓冲区空时消费者等待(wait())
c.协作机制
每次操作后通过notify()唤醒等待线程
d.方法对比
notify():唤醒单个等待线程
notifyAll():唤醒所有等待线程(适用于多生产者场景)
8.3 [2]ReentrantLock + Condition
01.代码示例
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class TestReentrantLock4 {
static ReentrantLock lock = new ReentrantLock();
static Condition moneyCondition = lock.newCondition();
static Condition ticketCondition = lock.newCondition();
static boolean haveMoney = false;
static boolean haveTicket = false;
public static void main(String[] args) throws InterruptedException {
// 农民1(等钱)
new Thread(() -> {
lock.lock();
try {
while (!haveMoney) {
System.out.println("农民1等待资金...");
moneyCondition.await();
}
System.out.println("农民1获得资金,回家!");
} finally {
lock.unlock();
}
}, "Farmer1").start();
// 农民2(等票)
new Thread(() -> {
lock.lock();
try {
while (!haveTicket) {
System.out.println("农民2等待车票...");
ticketCondition.await();
}
System.out.println("农民2获得车票,回家!");
} finally {
lock.unlock();
}
}, "Farmer2").start();
// 主线程模拟发放条件
Thread.sleep(1000);
lock.lock();
try {
haveMoney = true;
moneyCondition.signal();
System.out.println("资金已发放!");
haveTicket = true;
ticketCondition.signal();
System.out.println("车票已发放!");
} finally {
lock.unlock();
}
}
}
02.关键要点
a.多条件支持
一个锁对象可绑定多个Condition(如moneyCondition/ticketCondition)
b.精准唤醒
await():释放锁并等待特定条件
signal():唤醒满足条件的等待线程
c.代码结构
必须在lock.lock()和finally unlock()之间操作
条件判断使用while循环防止虚假唤醒
8.4 [3]Future:Callable + ExecutorService
01.代码示例
import java.util.concurrent.*;
public class FutureExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<Integer> future = executor.submit(() -> {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
Thread.sleep(10);
}
return sum;
});
System.out.println("主线程执行其他任务...");
try {
Integer result = future.get(2, TimeUnit.SECONDS);
System.out.println("计算结果: 1+2+...+100 = " + result);
} catch (TimeoutException e) {
System.err.println("计算超时!");
future.cancel(true);
} catch (Exception e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}
02.关键要点
future.get() 阻塞获取结果(可设置超时)
future.cancel() 取消任务执行
isDone() 检查任务是否完成
03.执行流程
提交Callable任务到线程池
主线程继续执行其他操作
调用future.get()阻塞等待结果
处理可能出现的异常情况
最终关闭线程池资源
8.5 [4]CountDownLatch:多线程同步
01.代码示例
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
public class CountDownLatchExample {
private static final int RUNNERS = 5;
private static final CountDownLatch startSignal = new CountDownLatch(1);
private static final CountDownLatch readySignal = new CountDownLatch(RUNNERS);
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(RUNNERS);
for (int i = 1; i <= RUNNERS; i++) {
executor.execute(() -> {
try {
System.out.println("运动员" + i + "正在准备...");
TimeUnit.MILLISECONDS.sleep(300);
readySignal.countDown();
startSignal.await();
System.out.println("运动员" + i + "起跑!");
TimeUnit.MILLISECONDS.sleep((long)(Math.random() * 1000));
System.out.println("运动员" + i + "到达终点!");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
System.out.println("裁判等待运动员就位...");
readySignal.await();
System.out.println("\n所有运动员就位!");
TimeUnit.SECONDS.sleep(1);
System.out.println("发令枪响!");
startSignal.countDown();
executor.shutdown();
executor.awaitTermination(5, TimeUnit.SECONDS);
System.out.println("\n比赛结束!");
}
}
02.应用场景
多线程初始化后统一执行:如服务启动时等待所有组件就绪
并发测试控制:模拟固定数量请求同时发起
事件驱动编程:等待多个前置条件完成
8.6 [5]CyclicBarrier:可重用同步屏障
01.代码示例
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierExample {
private static final CyclicBarrier barrier =
new CyclicBarrier(3, () -> System.out.println("\n===== 进入下一阶段 ====="));
public static void main(String[] args) {
for (int i = 1; i <= 3; i++) {
new Thread(new TeamMember(i)).start();
}
}
static class TeamMember implements Runnable {
private int id;
public TeamMember(int id) {
this.id = id;
}
@Override
public void run() {
try {
doWork("需求分析", 1000);
barrier.await();
doWork("开发编码", 1500);
barrier.await();
doWork("测试部署", 800);
barrier.await();
} catch (Exception e) {
e.printStackTrace();
}
}
private void doWork(String phase, int baseTime) throws InterruptedException {
int time = baseTime + (int)(Math.random() * 500);
System.out.printf("%s 完成%s(%dms)\n",
Thread.currentThread().getName(), phase, time);
Thread.sleep(time);
}
}
}
02.核心特性
对比项 CountDownLatch CyclicBarrier
重用性 一次性使用 可重复触发
线程关系 主线程等待子线程 子线程相互等待
典型场景 线程初始化完成后执行 多阶段任务协作