1 大模型
1.1 阶段
01.大模型演变与概念
a.人工智能
人工智能是一个广泛的领域,涵盖了多种技术和方法
包括机器学习、自然语言处理、计算机视觉、专家系统、机器人学等
其目标是创建能够模拟人类智能行为的系统或软件,具备感知、推理、学习、决策和语言理解等能力
深度学习是机器学习的一个分支,机器学习是人工智能的一个核心领域
b.机器学习是人工智能的一个核心子领域,专注于开发算法和模型,使计算机能够从数据中自动学习和改进
a.监督学习
通过标注好的数据教计算机学习规律
例如:教计算机识别猫和狗的图片
b.无监督学习
让计算机自己探索数据,找出其中的模式和规律
例如:分析顾客的购买习惯
c.强化学习
通过试错和奖励机制让计算机学习
例如:教小狗学会“坐下”动作
c.深度学习通过多层神经网络来处理数据,模仿人脑的工作方式
自动学习:计算机自己从数据中学习规律
多层结构:逐步提取数据中的复杂特征
强大的能力:处理复杂问题,如识别各种形状和颜色的水果
d.生成式人工智能通过学习大量数据,创造出全新的内容
应用:写文章、画图、作曲等
核心能力:模仿+创新
02.大模型训练
a.预训练
学习海量文本,掌握语言的通用规律
形成基础模型,具备基础能力
b.监督微调
用标注数据教模型完成具体任务
具备专业能力
c.基于人类反馈的强化学习
通过人类反馈优化模型输出
输出更人性化
03.分类
a.大语言模型(LLMs)
专注于文本模态,具备文本生成、理解、推理能力
应用:内容生成、智能交互、知识服务
b.多模态模型(LMMs)
处理多种数据模态,实现信息融合与协同推理
应用:医疗诊断、智能驾驶、内容创作
04.工作流程
a.分词化(Tokenization)
将文本拆解为最小语义单元(Token)
方法:基于词典、统计、规则、混合、子词粒度分词
b.词表映射(Vocabulary Mapping)
将Token映射为唯一整数ID
词向量嵌入:将ID转换为稠密向量
c.大模型文本生成过程
自回归:根据当前句子预测下一个词
经验值:通过海量数据学习合理的词序
自我修正:优化表达,生成连贯的文本
1.2 参数
01.参数
a.介绍
DeepSeek-R1 1.5b、7b、8b、14b、32b、70b、671b
在大模型以前的时代,也有一些比较小模型,单位一般都是M(百万)为计算单位
LLM出现之后,基本模型参数数量基本是以亿为基本单位
b.说明
1.5b 15亿个参数
7b 70亿个参数
8b 80亿个参数
14b 140亿个参数
32b 320亿个参数
70b 700亿个参数
671b 6710亿个参数
c.比较
参数越大:代表模型越聪明,对复杂问题的处理能力越强,但对算力和硬件的要求也越高
参数越小:代表模型越轻量化,对算力和硬件的要求越低,适合资源受限的设备
1.3 RAG
00.什么是RAG
a.定义
RAG,英文全称是 Retrieval-Augmented Generation,中文我们一般叫做检索增强生成,这是一种结合信息检索技术与生成式大语言模型(LLM)的框架
b.核心思想
在生成答案前,先从外部知识库中检索相关信息,并将这些信息作为上下文输入大模型,从而提升生成内容的准确性和时效性
c.简单解释
由于大模型知识比较陈旧,当我们提问时,我们可以利用搜索工具在互联网上搜索我们问题的答案,并且将搜索到的答案和我们原本的问题一起发给大模型,由大模型进行处理
d.示例
想象一下:你有一个特别聪明的朋友,但他有个毛病——喜欢“不懂装懂”。比如你问他:“最近有什么好看的科幻电影?”
他可能会瞎编:“《星际穿越2》上周刚上映,评分 9.8!”(其实根本没这部电影)。
这时候你会说:“等等,你先去豆瓣查一下再回答!”这个“先查资料再回答”的过程,就是 RAG(检索增强生成)的核心!
01.为什么要用RAG
a.防止 AI 胡说八道
比如你问“华为手机最新款多少钱”,AI 如果不知道,可能乱报价格。但 RAG 会先查华为官网的数据,回答更靠谱
b.回答最新信息
AI 的知识停留在训练的时候(比如只学到 2023 年),但 RAG 能查 2025 年的新闻,比如“比亚迪全民智驾发布会”
c.保护隐私
比如医院的 AI 只用内部病历资料回答,不会泄露病人信息到网上
d.示例
场景:你问 AI 客服:“退货需要带什么?”
没用 RAG 的 AI:可能说“带身份证和购物小票”(其实我们公司规定只要手机订单截图)
用了 RAG 的 AI:立刻查公司最新的《退货政策文档》,回答:“您好!请出示手机订单截图即可”
e.优势
减少幻觉:LLM 可能生成看似合理但缺乏事实依据的内容,而 RAG 通过引用权威数据源降低错误率
突破知识时效性限制:大模型训练数据存在截止日期,RAG 可实时更新知识库
数据安全与隐私:企业敏感数据无需上传至公有模型,仅通过本地知识库增强回答
降低微调成本:无需频繁重新训练模型,仅更新外部知识库即可适应新需求
02.如何实现RAG
a.数据准备阶段
a.文档分块(Documents → Chunked Texts)
将长文档(如 PDF、网页、手册)切割为短文本块,便于后续处理和检索
具体切块的方法可以按固定长度(如每段 512 字)或语义边界(段落/标题)分割,常用工具包括 LangChain 的 TextSplitter
b.生成嵌入(Generate Embeddings)
生成嵌入的核心目的是让计算机能像人类一样“理解”复杂的数据,比如文字、图片甚至用户行为
嵌入模型(如 Word2Vec、BERT)通过大量数据自动学习,无需人工标记
在具体实践中,可以使用一些成熟的嵌入模型,如 OpenAI 的 text-embedding-3-small、开源的 BAAI/bge 系列等将文本块转换为高维向量,捕捉语义信息
c.存储向量数据库(Vector DB)
向量数据库的核心作用是专门处理图片、文字、语音等非结构化数据,把它们变成“数字指纹”,再通过“指纹”快速匹配相似内容
常见的向量数据库有 Milvus、腾讯云 VectorDB、Pinecone、Faiss、Annoy 等
b.问答生成阶段
a.用户提问
当用户问“巴黎奥运会在哪举办?”时,系统先用嵌入模型把问题转成向量坐标,并自动推测隐藏信息(例如补充“2024年”的时间限定)
b.检索阶段
用数学公式比对问题向量和知识库所有向量,找出角度最接近的坐标(角度越小越相关)
c.生成答案
把检索到的 3-5 个相关段落和用户问题一起喂给大模型,通过Prompt 工程指定回答风格,避免专业术语堆砌,并通过后处理模块检查是否存在编造内容
d.示例
如何给手机充电?
检索层找到知识库中的《电子设备维护指南》段落:“使用原装充电器,避免过度放电”
生成层将其转化为:“亲,建议您使用手机配套的充电器哦~电量低于 20% 就及时充电,对电池更好呢!(来源:XX 产品手册)”
修正层自动删除原文的专业术语“锂离子电池循环寿命”,替换为口语化表达
03.RAG优势
a.对比维度
知识更新:传统搜索引擎需人工维护,RAG 系统更新知识库即可
回答质量:传统搜索引擎提供碎片化链接,RAG 系统提供结构化总结
安全可控:传统搜索引擎有数据外流风险,RAG 系统本地存储知识库
b.流程特点(从设计视角)
模块化架构:数据准备与生成阶段解耦,支持独立优化
关键路径可视化:蓝色突出核心流程,灰色背景降低视觉干扰
实时性体现:向量数据库支持动态更新,可实时同步新知识
04.典型应用场景
a.企业知识库问答
员工提问“报销流程” → 检索内部制度文档 → 生成步骤化指引
b.学术研究辅助
输入“量子计算最新进展” → 检索 arXiv 论文摘要 → 生成综述性回答
c.个性化推荐
用户询问“适合夏天的轻薄外套” → 检索商品特征库 → 生成推荐理由+链接
05.RAG的局限性
a.检索质量依赖性强
若知识库包含错误或无关信息,生成的答案可能受影响
b.计算资源与效率
检索+生成的双阶段流程增加响应时间,难以满足高实时性场景
c.领域适配成本高
专业领域需构建高质量知识库,数据清洗和标注成本较高
d.优化方向
混合检索:结合关键词、向量、图谱等多模态检索提升查全率
动态评估与迭代:通过用户反馈和 A/B 测试持续优化检索策略
06.总结
a.流程图
Source 就是各种格式的原文档
Load 则是文档加载器加载文档
Transform 则是我们对文档进行分块处理等操作
Embed 就是向量化
Store 存储向量化的数据
Retrieve 检索
1.4 mcp、a2a
00.汇总
a.对比
A2A:Agent-to-Agent Protocol,让智能体能用上各种工具(就像人类使用锤子、电脑等工具一样)
MCP:Model Context Protocol,让不同智能体能够相互交流合作(就像人类之间通过语言交流一样)
b.说明
未来,随着这两种技术的完善,我们的生活将出现越来越多由智能体提供服务的场景,
比如智能助手帮你预约医生并自动安排日程,或者多个专业智能体协作完成复杂的设计任务等。
从 MCP 到 A2A 是一个从单体架构迁移到云原生架构,并实现应用之间高效通信和集成的过程。
MCP 关注的是如何将单体应用拆分为微服务,并部署到云平台上;A2A 关注的是如何实现不同应用之间的通信和集成。
两者结合,可以构建一个灵活、高效、可扩展的分布式系统。
01.历史发展
a.MCP:智能体与外部世界的桥梁
在讨论智能体协作之前,我们首先需要理解单个智能体如何与外部世界交互
MCP(Model Context Protocol)是我们之前已经介绍过的开放协议,它解决了智能体与外部工具、资源和API之间的连接问题
简单回顾一下,MCP为智能体提供了标准化的方式来访问外部能力,增强自身功能。
MCP通过标准化接口、工具注册与发现、安全机制和资源管理等核心功能,使智能体能够突破训练数据的限制,访问实时信息和执行特定操作。
它解决了智能体能力有限、工具使用标准化缺失和安全隐患等关键问题。
b.MCP的局限性
尽管MCP解决了智能体与外部工具的连接问题,但它仍然存在明显的局限性。
MCP主要关注单个智能体与外部工具的连接,却没有解决多个智能体之间如何协作的问题。
同时,不同智能体之间的通信缺乏标准化的协议,导致它们难以有效地交换信息和协调行动。
更重要的是,MCP缺乏一种机制来管理复杂的多智能体工作流,无法有效处理任务分配、进度跟踪和结果整合等协作需求。
c.A2A的必要性
A2A协议应运而生,弥补MCP在智能体协作方面的不足,专注于智能体间通信与协作。
A2A协议弥补了MCP在智能体协作方面的不足,解决了多个MCP未能解决的关键问题, 比如 Agent 发现、Agent 身份认证、Agent 协作等。
标准化的通信协议和任务管理机制,实现了智能体间的无缝协作,使不同智能体能够协同工作完成复杂任务。
智能体卡片(Agent Card)机制,使智能体能够发布自己的能力并发现其他智能体的技能,支持开放**发现、精选发现和私有发现等多种方式。可能以后的爬虫,可以爬网站的agent 列表. (google 提供的path是 https://DOMAIN/.well-known/agent.json)。
文本、文件和结构化数据等多种类型的信息交换,并提供流式传输功能。
身份认证机制和多身份联合认证支持,对于不同厂家的Agent 如何认证的问题,A2A提供了灵活的解决方案。
复杂工作流程管理,包括任务分配、状态跟踪和结果整合,使复杂任务能够被有效分解和执行。
d.多智能体协作:Google A2A示例应用
Google的A2A示例应用简洁展示了智能体协作的实际应用, 包括 前端web界面、主机智能体、远端智能体。
主机智能体可以通过 AgentCard 动态添加新的智能体,并分配任务给专业智能体。而在远端智能体,通过MCP协议可以与外部的工具和资源进行连接。
e.未来展望:MCP与A2A的发展趋势
随着AI技术发展,MCP和A2A协议将持续演进,
主要体现在四个方面:标准生态建设,更多组织参与标准制定,降低开发门槛;专业化智能体在法律、医疗、金融等领域蓬勃发展;
企业级应用将MCP和A2A作为业务流程自动化的核心组件;安全与互操作能力不断增强,支持多平台协作并保障数据安全。
这些趋势将共同推动智能体生态系统的完善与创新。
02.MCP(Monolithic to Cloud-native Platform)
a.定义
MCP 是指将传统的单体架构应用迁移到云原生平台的过程。云原生平台通常包括容器化、微服务架构、DevOps 实践等。
b.特点
a.单体架构
所有功能模块在一个应用中,部署和扩展较为简单,但随着应用规模增长,维护和扩展变得困难。
b.云原生架构
应用被拆分为多个独立的微服务,每个微服务可以独立部署和扩展,具有更高的灵活性和可维护性。
c.迁移步骤
a.评估现有系统
分析现有单体应用的架构、依赖关系和性能瓶颈。
b.定义迁移策略
确定迁移的优先级和步骤,可以选择逐步迁移或一次性迁移。
c.拆分微服务
将单体应用拆分为多个微服务,每个微服务负责特定的业务功能。
d.容器化
使用 Docker 等容器技术将微服务打包,确保一致的运行环境。
e.部署到云平台
使用 Kubernetes 等容器编排工具,将微服务部署到云平台。
f.实施 DevOps 实践
引入 CI/CD 流水线,自动化构建、测试和部署流程。
g.监控和优化
使用 Prometheus、Grafana 等工具监控微服务的运行状态,及时发现和解决问题。
d.优点
a.灵活性
微服务可以独立部署和扩展,适应业务需求的变化。
b.可维护性
每个微服务代码库较小,维护和更新更加容易。
c.高可用性
微服务之间相互独立,一个服务的故障不会影响其他服务。
e.挑战
a.复杂性增加
微服务数量增加,服务间通信和数据一致性管理变得复杂。
b.运维难度
需要引入容器编排、服务发现、配置管理等工具,增加了运维难度。
c.性能问题
服务间通信通常通过网络进行,可能带来性能开销。
03.A2A(Application to Application)
a.定义
A2A 是指应用程序之间的通信和集成,通常用于描述不同应用之间的数据交换和功能调用。
b.特点
a.异构系统集成
不同技术栈、不同平台的应用之间进行集成。
b.实时通信
应用之间进行实时的数据交换和功能调用。
c.松耦合
应用之间通过标准接口进行通信,减少相互依赖。
c.集成方式
a.API 网关
通过 API 网关统一管理和暴露应用的接口,提供认证、限流、监控等功能。
b.消息队列
使用 Kafka、RabbitMQ 等消息队列实现异步通信,解耦应用之间的依赖。
c.服务总线(ESB)
使用企业服务总线(如 Apache Camel)进行应用集成,提供路由、转换、协议适配等功能。
d.RPC 框架
使用 gRPC、Thrift 等 RPC 框架实现高性能的远程过程调用。
d.优点
a.灵活性
应用之间通过标准接口进行通信,易于扩展和替换。
b.可靠性
使用消息队列等机制实现异步通信,提高系统的可靠性。
c.可维护性
应用之间松耦合,维护和更新更加容易。
e.挑战
a.接口管理
需要统一管理和维护应用之间的接口,确保接口的一致性和兼容性。
b.数据一致性
应用之间的数据同步和一致性管理变得复杂。
c.安全性
需要确保应用之间通信的安全性,防止数据泄露和未授权访问。
2 mcp
2.1 basic
01.概述
a.定义
Model Context Protocol (MCP) 是一个开放的通信协议,它就像一个"万能转换器"
让 AI 模型能够轻松地使用各种现实世界的工具和资源
通过标准化的接口定义和灵活的扩展机制,MCP 正在重新定义 AI 与外部世界的交互方式
MCP就像是AI应用的USB-C接口,就像USB-C为设备提供了一种标准化的连接方式,使其可以连接到各种配件,
MCP标准化了AI应用如何连接到不同的数据源和工具
b.核心组件
主机(Host):运行LLM的应用程序(如Claude Desktop),负责发起与MCP服务器的连接
客户端(Client):在主机应用程序内部运行,与MCP服务器建立1:1连接
服务器(Server):提供对外部数据源和工具的访问,响应客户端的请求
LLM:大型语言模型,通过MCP获取上下文并生成输出
c.Function Tool与MCP对比
类别 MCP (Model Context Protocol) Function Calling
性质 协议 功能
范围 通用(多数据源、多功能) 特定场景(单一数据源或功能)
目标 统一接口,实现互操作 扩展模型能力
实现 基于标准协议 依赖于特定模型实现
开发复杂度 低:通过统一协议实现多源兼容 高:需要为每个任务单独开发函数
复用性 高:一次开发,可多场景使用 低:函数通常为特定任务设计
灵活性 高:支持动态适配和扩展 低:功能扩展需要额外开发
常见场景 复杂场景,如跨平台数据访问与整合 简单任务,如实现查询、统计等一些基础功能
d.服务器
社区MCP服务器:https://glama.ai/mcp/servers
官方MCP服务器:https://github.com/modelcontextprotocol/servers
02.典型的MCP服务
a.智能助手
a.通用AI Agent
Manus 革命性的 AI Agent 产品,全面的智能助手功能
Cline 智能命令行工具,简化终端操作
UnifAI 动态工具调用,灵活适应不同场景
b.专业领域
EduBase 智能教育平台,个性化学习体验
Audiense 智能营销分析,精准用户洞察
Grafana 数据可视化助手,直观展示分析结果
b.数据处理
a.搜索引擎
Meilisearch 高性能全文搜索,支持多语言
Kagi 智能网络搜索,注重隐私保护
Tavily 专为 AI 优化的搜索引擎
b.数据分析
BigQuery 强大的大数据查询分析
ClickHouse 高效的列式存储系统
Vectorize 先进的向量检索技术
c.开发工具
a.代码编辑
Cursor IDE AI 驱动的智能代码补全和重构
JetBrains 专业 IDE 工具集成
VSCode 灵活的编辑器扩展
Git 智能版本控制集成
b.数据库
PostgreSQL 功能丰富的关系型数据库
MongoDB 灵活的文档数据库
Redis 高性能缓存系统
Neo4j 强大的图数据库
d.云服务
a.云平台
AWS 全面的云资源管理
Azure 企业级云服务
Cloudflare 高效的 CDN 和边缘计算
b.API服务
OpenAPI 标准化 API 管理
GraphQL 灵活的查询语言支持
REST 通用接口调用规范
03.工作流程说明
a.工具发现
MCP Client 获取可用工具列表及其功能描述
b.查询处理
Client 将工具转换为标准格式并发送给 LLM
{
"name":"search_weather",
"description":"获取指定城市的天气信息",
"parameters":{
"city":"城市名称",
"days":"天数预报(1-7天)"
}
}
c.决策分析
LLM 根据用户需求选择合适的工具
d.工具调用
通过 MCP Server 执行工具调用并获取结果
e.结果处理
将工具执行结果返回给 LLM 进行分析
f.响应生成
LLM 生成自然语言响应
g.结果展示
向用户展示结果并维护对话上下文
04.应用场景:日本旅行规划助手
a.工作流程
a.需求理解
收集用户的旅行需求(时间、预算、偏好)
b.信息获取
搜索景点、住宿、交通、美食等信息
c.方案规划
设计行程、安排路线、预估费用
d.文档生成
制作行程手册、交通指南、注意事项
b.所需MCP服务
服务类型 具体服务 用途
搜索服务 Tavily 获取旅游景点和美食信息
地图服务 Google Maps 路线规划和交通信息
天气服务 OpenWeather 获取目的地天气预报
文档服务 Markdown 生成旅行手册和指南
翻译服务 DeepL 多语言内容翻译
数据分析 BigQuery 路线优化和预算分析
05.五大能力
a.Sequential Thinking——AI 的"深度思考"模式
a.说明
这是受欢迎程度最高的 MCP 服务,本质上是给 AI 模型增加深度思考能力
当我使用 Claude 3.7 测试时,它能够通过多轮思考,逐步拆解复杂问题,最终给出全面的解决方案
b.说明
拿一个项目试一下,提示词是: """ 使用思考能力,帮我想一下在当前项目中加入数学公式,需要做什么工作 """
然后它先是大致查看并理解了我的项目文件(这是 Cursor 自己的能力),然后调用这个 MCP,并且进行了好几个轮次的调用:
c.说明
可以看到,每一轮调用都会有一个 thought 字段,通过每一步的拆解和深度思考,来最终完成任务目标
最后想的非常全面,甚至想到了微信公众号不支持数学公式的情况。如果直接用 Claude 去做的话,可能就会深陷其中无法自拔了
这个 MCP 还蛮实用的,当我们碰到复杂的问题,或者比较艰巨的任务的时候,不妨试试这个工具,主动使用“深度思考”、“reasoning 模式”等关键词,就可以触发这个 MCP 服务的调用
b.Brave Search + Fetch——信息检索的"黄金组合"
a.说明
Brave Search MCP 使用 Brave Search API 进行信息检索。当然你得先去 Brave Search 的控制台去生成一个 API Key,才能使用这个 MCP
经过实测,Brave Search 比 Cursor 自带的 Search 效果要好,比如我用同样的提示词:Cursor 最新版本是多少
b.说明
如果是普通的检索,返回的是不正确的结果
然后我直接让它用 brave 来检索,就会经过非常多轮的验证和查证
在需要网络检索的情况下,可以尽可能使用 brave api
另外,fetch 这个 MCP 服务可以抓取网页上的内容,以 markdown 的格式返回,比如上面访问各种网页就用到了 fetch 的能力
c.说明
可以看到 fetch 返回的就是页面 markdown 内容,通过 brave+fetch 这样的精准组合,就能获取最新且最准确的信息
同样的手段还可以运用在查询 API 文档或最新资讯方面
应用场景:查询最新 API 文档、技术资讯、开源项目更新等
c.Magic MCP——前端开发的"魔法师"
a.说明
Magic MCP 支持直接创建前端组件,所有组件均来自 21st.dev。使用"/ui"指令,就能快速创建各种 UI 界面
b.说明
它的使用方式是用“/ui”指令,比如,我让它来创建一个博客的项目:
/ui 帮我创建一个好看的个人博客项目
可以看到,它会先访问 magic 服务来请求相关的组件
d.Github MCP——开发者社区的无缝连接
a.说明
Github MCP 允许直接调用 Github 的 OpenAI 能力,甚至可以直接提交 issue
我刚好在使用 TaskManager、Playwright 这两个 MCP 服务的时候,遇到异常
于是顺手就用 Github 的 MCP 提交了一个 issue
b.说明
最终的 issue 效果如下,是不是既方便又专业
这种无缝连接开发者社区的能力,大大提升了协作效率和问题解决速度
e.Playwright MCP——自动化测试的"魔术师"
a.说明
Playwright MCP 是一个强大的自动化测试工具,它能够帮助开发者在多种浏览器环境中进行端到端测试,大大简化了测试流程,提高了测试效率和准确性
b.说明
比如,我让它直接访问 qq.com,他会自动访问页面,并生成一张截图
你可以让它处理复杂的页面交互,如表单提交、AJAX 请求、页面导航等
确保 Web 应用在各种环境下都能正常工作。很适合直接在编码的过程中做自动化测试
2.2 frame
00.关键概念
MCP Hosts:主机程序,比如Claude Desktop、集成开发环境(IDEs)或者人工智能工具(AI tools)。这些程序希望通过MCP来访问数据。MCP Hosts充当用户界面或者前端,用户通过它们与MCP系统交互
MCP Clients:协议客户端,它们与服务器保持着一对一(1:1)的连接。MCP Clients负责与MCP Servers通信,发送请求并接收数据
MCP Servers:轻量级的程序,每个都通过标准化的Model Context Protocol暴露特定的功能。MCP Servers是后端服务,它们处理来自MCP Clients的请求,并提供所需的数据或服务
Local Data Sources:这些是你的计算机上的文件、数据库和服务,MCP服务器可以安全地访问它们。这些是本地数据源,MCP Servers可以直接与之交互,以获取或存储数据
Remote Services:这些是可以通过互联网访问的外部系统(例如,通过APIs)。MCP服务器可以连接到这些远程服务,以获取数据或执行操作
01.核心组件
a.协议层
a.说明
协议层处理消息帧、请求/响应链接以及高级通信模式
b.代码
class Protocol<Request, Notification, Result> {
// 处理传入的请求
setRequestHandler<T>(schema: T, handler: (request: T, extra: RequestHandlerExtra) => Promise<Result>): void
// 处理传入的通知
setNotificationHandler<T>(schema: T, handler: (notification: T) => Promise<void>): void
// 发送请求并等待响应
request<T>(request: Request, schema: T, options?: RequestOptions): Promise<T>
// 发送单向通知
notification(notification: Notification): Promise<void>
}
c.说明
关键类包括:
Protocol
Client
Server
b.传输层
a.说明
传输层处理客户端和服务器之间的实际通信
b.MCP支持多种传输机制
a.Stdio 传输
使用标准输入/输出进行通信
适用于本地进程
b.HTTP with SSE 传输
使用 Server-Sent Events 进行服务器到客户端的消息传递
使用 HTTP POST 进行客户端到服务器的消息传递
c.说明
所有传输都使用 JSON-RPC 2.0 来交换消息
c.消息类型
a.请求 期望从对方获得响应
interface Request {
method: string;
params?: { ... };
}
b.结果 是请求的成功响应
interface Result {
[key: string]: unknown;
}
c.错误 表示请求失败
interface Error {
code: number;
message: string;
data?: unknown;
}
d.通知 是单向消息,不期望响应
interface Notification {
method: string;
params?: { ... };
}
02.生命周期
a.初始化
客户端发送带有协议版本和功能的 initialize 请求
服务器响应其协议版本和功能
客户端发送 initialized 通知作为确认
正常消息交换开始
b.消息交换
初始化后,支持以下模式:
请求-响应:客户端或服务器发送请求,对方响应
通知:任一方发送单向消息
c.终止
任一方都可以终止连接:
通过 close() 进行干净关闭
传输断开
错误条件
错误处理
03.错误处理
a.MCP定义了以下标准错误代码
enum ErrorCode {
// 标准 JSON-RPC 错误代码
ParseError = -32700,
InvalidRequest = -32600,
MethodNotFound = -32601,
InvalidParams = -32602,
InternalError = -32603
}
-----------------------------------------------------------------------------------------------------
SDK 和应用程序可以在 -32000 以上定义自己的错误代码
b.错误通过以下方式传播
对请求的错误响应
传输上的错误事件
协议级错误处理程序
04.通信方式
a.说明
传输层处理客户端和服务器之间的实际通信,MCP 支持多种传输机制,并且所有传输都使用 JSON-RPC 2.0 来交换消息
b.标准输入/输出 (stdio)
stdio 传输支持通过标准输入和输出流进行通信。这对于本地集成和命令行工具特别有用。以下情况使用;
构建命令行工具
本地集成
简单的通信
使用 shell 脚本
b.SSE
SSE 传输支持使用 HTTP POST 请求进行服务器到客户端流式处理,以实现客户端到服务器的通信。以下情况使用;
需要服务端到客户端的流式传输
网络受限
c.自定义传输协议
MCP 可以根据特定需求自定义传输,只需要实现 Transport 接口即可。一般在自定义网络协议、性能优化等场景下自定义
05.通信协议 JSON-RPC
a.说明
MCP 使用 JSON-RPC 2.0 作为其传输格式
传输层负责将 MCP 协议消息转换为 JSON-RPC 格式进行传输,并将收到的 JSON-RPC 消息转换回 MCP 协议消息
b.使用三种类型的 JSON-RPC消息
a.请求
{
jsonrpc: "2.0",
id: number | string,
method: string,
params?: object
}
b.响应
{
jsonrpc: "2.0",
id: number | string,
result?: object,
error?: {
code: number,
message: string,
data?: unknown
}
}
c.通知
{
jsonrpc: "2.0",
method: string,
params?: object
}
06.MCP 消息类型
a.请求消息
interface Request {
method: string; // 请求方式
params?: { ... }; // 请求参数
}
b.响应消息:对请求消息的成功响应
interface Result {
[key: string]: unknown; // 响应内容
}
c.错误消息:当请求 MCP Server 发生错误时,则返回错误消息
interface Error {
code: number; // 错误码
message: string; // 错误信息
data?: unknown; // 返回数据
}
d.通知消息:通知消息是不需要请求的单向消息,一般是由于服务端的工具、资源或者提示词有变更,需要通知到客户端的消息
interface Notification {
method: string;
params?: { ... };
}
00.介绍
Tools 是 Model Context Protocol (MCP) 中的一个强大基础元素,它使服务器能够向客户端暴露可执行的功能
通过 Tools,LLMs 可以与外部系统交互、执行计算并在现实世界中采取行动
01.概述
a.定义
MCP 中的 Tools 允许服务器暴露可执行的函数,客户端可以调用这些函数,并由 LLMs 使用来执行操作
b.关键方面
发现: 客户端可以通过 tools/list 端点列出可用的 Tools
调用: Tools 通过 tools/call 端点调用,服务器执行请求的操作并返回结果
灵活性: Tools 可以从简单的计算到复杂的 API 交互
c.说明
与 resources 类似,Tools 通过唯一的名称进行标识,并且可以包含描述以指导其使用
然而,与 resources 不同,Tools 表示可以修改状态或与外部系统交互的动态操作
02.使用
a.Tool定义结构
{
name: string; // Tool 的唯一标识符
description?: string; // 人类可读的描述
inputSchema: { // Tool 参数的 JSON Schema
type: "object",
properties: { ... } // Tool 特定的参数
}
}
b.实现 Tools
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {
tools: {}
}
});
// 定义可用的 Tools
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [{
name: "calculate_sum",
description: "Add two numbers together",
inputSchema: {
type: "object",
properties: {
a: { type: "number" },
b: { type: "number" }
},
required: ["a", "b"]
}
}]
};
});
// 处理 Tool 执行
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "calculate_sum") {
const { a, b } = request.params.arguments;
return {
content: [
{
type: "text",
text: String(a + b)
}
]
};
}
throw new Error("Tool not found");
});
c.示例 Tool 模式
a.系统操作:与本地系统交互的 Tools
{
name: "execute_command",
description: "Run a shell command",
inputSchema: {
type: "object",
properties: {
command: { type: "string" },
args: { type: "array", items: { type: "string" } }
}
}
}
b.API 集成:封装外部 API 的 Tools
{
name: "github_create_issue",
description: "Create a GitHub issue",
inputSchema: {
type: "object",
properties: {
title: { type: "string" },
body: { type: "string" },
labels: { type: "array", items: { type: "string" } }
}
}
}
c.数据处理:转换或分析数据的 Tools
{
name: "analyze_csv",
description: "Analyze a CSV file",
inputSchema: {
type: "object",
properties: {
filepath: { type: "string" },
operations: {
type: "array",
items: {
enum: ["sum", "average", "count"]
}
}
}
}
}
03.最佳实践
在实现 Tools 时:
提供清晰、描述性的名称和描述
使用详细的 JSON Schema 定义参数
在 Tool 描述中包含示例,以演示模型应如何使用它们
实现适当的错误处理和验证
对长时间操作使用进度报告
保持 Tool 操作专注且原子化
记录预期的返回值结构
实现适当的超时
考虑对资源密集型操作进行速率限制
记录 Tool 使用情况以便调试和监控
04.安全考虑
a.输入验证
根据 Schema 验证所有参数
清理文件路径和系统命令
验证 URL 和外部标识符
检查参数大小和范围
防止命令注入
b.访问控制
在需要时实施身份验证
使用适当的授权检查
审核 Tool 使用情况
限制请求速率
监控滥用行为
c.错误处理
不要向客户端暴露内部错误
记录与安全相关的错误
适当处理超时
在错误后清理资源
验证返回值
05.Tool 发现和更新
a.MCP 支持动态 Tool 发现
客户端可以随时列出可用的 Tools
服务器可以使用 notifications/tools/list_changed 通知客户端 Tools 的变化
Tools 可以在运行时添加或删除
Tool 定义可以更新(尽管应谨慎进行)
06.错误处理
a.说明
Tool 错误应在结果对象中报告,而不是作为 MCP 协议级别的错误,这允许 LLM 查看并可能处理错误
b.当 Tool 遇到错误时
在结果中将 isError 设置为 true
在 content 数组中包含错误详细信息
c.正确处理 Tool 错误的示例
try {
// Tool 操作
const result = performOperation();
return {
content: [
{
type: "text",
text: `Operation successful: ${result}`
}
]
};
} catch (error) {
return {
isError: true,
content: [
{
type: "text",
text: `Error: ${error.message}`
}
]
};
}
-----------------------------------------------------------------------------------------------------
这种方法允许 LLM 看到发生了错误,并可能采取纠正措施或请求人工干预
07.测试 Tools
功能测试: 验证 Tools 在有效输入下正确执行,并正确处理无效输入
集成测试: 使用真实和模拟的依赖项测试 Tool 与外部系统的交互
安全测试: 验证身份验证、授权、输入清理和速率限制
性能测试: 检查负载下的行为、超时处理和资源清理
错误处理: 确保 Tools 通过 MCP 协议正确报告错误并清理资源
2.4 roots
00.介绍
Roots 是 MCP 中的一个概念,用于定义服务器可以操作的边界
它们提供了一种方式,让客户端能够告知服务器相关的资源及其位置
01.概述
a.定义
Root 是客户端建议服务器应关注的 URI。当客户端连接到服务器时,它会声明服务器应处理哪些 roots
虽然主要用于文件系统路径,但 roots 可以是任何有效的 URI,包括 HTTP URL
b.例如,roots 可以是:
file:///home/user/projects/myapp
https://api.example.com/v1
02.为什么使用 Roots?
a.Roots 有几个重要的用途:
指导:它们告知服务器相关的资源和位置
清晰:Roots 明确了哪些资源属于你的工作区
组织:多个 roots 允许你同时处理不同的资源
03.Roots 如何工作?
a.当客户端支持 roots 时,它会:
在连接期间声明 roots 能力
向服务器提供建议的 roots 列表
在 roots 发生变化时通知服务器(如果支持)
b.虽然 roots 是信息性的,并不强制执行,但服务器应:
尊重提供的 roots
使用 root URI 来定位和访问资源
优先处理 root 边界内的操作
04.常见用例
a.Roots 通常用于定义:
项目目录
仓库位置
API 端点
配置位置
资源边界
最佳实践
05.最佳实践
a.在使用 roots 时:
仅建议必要的资源
使用清晰、描述性的名称来命名 roots
监控 root 的可访问性
优雅地处理 root 的变化
06.示例
a.说明
一个典型的 MCP 客户端如何暴露 roots 的示例
b.代码
{
"roots": [
{
"uri": "file:///home/user/projects/frontend",
"name": "Frontend Repository"
},
{
"uri": "https://api.example.com/v1",
"name": "API Endpoint"
}
]
}
-----------------------------------------------------------------------------------------------------
此配置建议服务器同时关注本地仓库和 API 端点,并在逻辑上保持它们的分离
2.5 resource1
00.介绍
资源是Model Context Protocol (MCP)中的基本元素,允许服务器暴露数据和内容,供客户端读取并用作LLM交互的上下文
01.概述
资源表示MCP服务器希望向客户端提供的任何类型的数据,这可以包括:
文件内容
数据库记录
API响应
实时系统数据
截图和图像
日志文件
以及其他
每个资源由唯一的URI标识,可以包含文本或二进制数据
02.资源URI
资源使用以下格式的URI进行标识:
[protocol]://[host]/[path]
---------------------------------------------------------------------------------------------------------
例如:
file:///home/user/documents/report.pdf
postgres://database/customers/schema
screen://localhost/display1
协议和路径结构由MCP服务器实现定义。服务器可以定义自己的自定义URI方案
03.资源类型
a.文本资源
文本资源包含UTF-8编码的文本数据,适用于
源代码
配置文件
日志文件
JSON/XML数据
纯文本
b.二进制资源
二进制资源包含base64编码的原始二进制数据,适用于
图像
PDF
音频文件
视频文件
其他非文本格式
04.资源发现
a.直接资源
服务器通过resources/list端点暴露具体资源列表,每个资源包括
{
uri: string; // 资源的唯一标识符
name: string; // 人类可读的名称
description?: string; // 可选描述
mimeType?: string; // 可选的MIME类型
}
b.资源模板
对于动态资源,服务器可以暴露URI模板,客户端可以使用这些模板构建有效的资源URI
{
uriTemplate: string; // 遵循RFC 6570的URI模板
name: string; // 此类资源的人类可读名称
description?: string; // 可选描述
mimeType?: string; // 所有匹配资源的可选MIME类型
}
05.读取资源
a.说明
要读取资源,客户端使用资源URI发出resources/read请求
b.服务器响应资源内容列表
{
contents: [
{
uri: string; // 资源的URI
mimeType?: string; // 可选的MIME类型
// 以下之一:
text?: string; // 用于文本资源
blob?: string; // 用于二进制资源(base64编码)
}
]
}
c.提示
服务器可能会在一次resources/read请求中返回多个资源。例如,当读取目录时,可以返回目录中的文件列表
06.资源更新
a.列表更改
服务器可以通过notifications/resources/list_changed通知客户端可用资源列表的变化
b.内容更改
客户端可以订阅特定资源的更新
客户端发送带有资源URI的resources/subscribe
当资源发生变化时,服务器发送notifications/resources/updated
客户端可以使用resources/read获取最新内容
客户端可以使用resources/unsubscribe取消订阅
07.示例实现
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {
resources: {}
}
});
// 列出可用资源
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [
{
uri: "file:///logs/app.log",
name: "Application Logs",
mimeType: "text/plain"
}
]
};
});
// 读取资源内容
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
const uri = request.params.uri;
if (uri === "file:///logs/app.log") {
const logContents = await readLogFile();
return {
contents: [
{
uri,
mimeType: "text/plain",
text: logContents
}
]
};
}
throw new Error("Resource not found");
});
08.最佳实践
在实现资源支持时:
使用清晰、描述性的资源名称和URI
包含有用的描述以指导LLM理解
在已知时设置适当的MIME类型
为动态内容实现资源模板
对频繁变化的资源使用订阅
使用清晰的错误消息优雅地处理错误
考虑对大型资源列表进行分页
在适当时缓存资源内容
在处理前验证URI
记录自定义URI方案
09.安全考虑
在暴露资源时:
验证所有资源URI
实施适当的访问控制
清理文件路径以防止目录遍历
谨慎处理二进制数据
考虑对资源读取进行速率限制
审计资源访问
在传输中加密敏感数据
验证MIME类型
对长时间运行的读取实施超时
适当地处理资源清理
2.6 resource2
00.介绍
a.说明1
资源是模型上下文协议 (MCP) 中的核心基元,它允许服务器公开可由客户端读取并用作LLM交互上下文的数据和内容
b.说明2
资源被设计为 application-controlled。这就意味着客户端应用程序可以决定如何以及何时使用它们
不同的客户端对资源的处理采用不同的方式
c.说明3
MCP Server 提供不同类型的数据给 MCP Client,每种资源都由唯一的 URI 标识,并且可以包含文本或者二进制数据
可能包括;文件/数据库/API 响应/实时系统数据/日志文件/...
01.资源 URI
a.定义资源 URI 标准格式
[protocol]://[host]/[path] 协议://域名/路径
b.例如
file:///home/user/documents/report.pdf
postgres://database/customers/schema
screen://localhost/display1
c.说明
协议和路径结构由 MCP 服务器实现定义,服务器可以自定义 URI 方案
02.资源类型
a.文本资源,包含 UTF-8 编码的文本数据,适应于:
源代码
配置文件
日志文件
Json/xml 数据
纯文本
b.二进制资源,包含 base64 编码的原始二进制数据,适应于:
图像/图片
PDF 文件
音视频文件
其它非文本格式
03.资源发现
a.说明
资源发现主要发生在 MCP Client
b.主要通过两种方式发现可用资源
a.直接资源,服务器通过 resources/list 端点公开具体资源的列表,每个资源包含
{
uri: string; // 资源唯一标识
name: string; // 资源名称,必须人类可读,可理解
description?: string; // 资源描述(可选)
mimeType?: string; // 资源的 MIME 类型 (可选)
}
b.资源模板,针对于动态资源,服务器可以公开 URI 模板,客户端可以根据模板构造有效的资源 URI
{
uriTemplate: string; // URI 模版,遵循 RFC 6570标准
name: string; // URI 模版名称 必须人类可读,可理解
description?: string; // 资源描述(可选)
mimeType?: string; // 资源的 MIME 类型 (可选)
}
04.读取资源
a.说明
MCP Client 通过使用资源 URI发出 resources/read 读取资源,服务器使用资源内容列表进行响应
b.代码
{
contents: [
{
uri: string; // 资源的 URI
mimeType?: string; // 资源 MIME 类型 (可选)
// One of: 根据不同的资源二选一
text?: string; // 资源文本内容
blob?: string; // 资源的 Base64 编码的二进制文件
}
]
}
-----------------------------------------------------------------------------------------------------
一个资源读取请求,服务端可能会返回多个资源,例如:读取文件夹下的文件列表
05.资源更新
a.MCP 通过两种机制支持资源的实时更新
a.资源列表变更
当 MCP Client 端的可用资源列表发生变更时
MCP Server 可以通过 /notifications/resources/list_changed 通知 MCP Client
b.资源内容变更
MCP Client 可以订阅特定资源的更新:
客户端使用资源 URI 发送 resources/subscribe 订阅订阅
服务器在资源变更时,发送 notifications/resources/updated
客户端使用 resources/read 获取最新的内容
客户端使用 resources/unsubscribe 取消订阅
2.7 prompts1
00.介绍Prompts
Prompts 使服务器能够定义可重用的提示模板和工作流,客户端可以轻松地向用户和 LLM 公开这些模板
它们提供了一种强大的方式来标准化和共享常见的 LLM 交互
01.概述
MCP(Model Context Protocol)中的 Prompts 是预定义的模板,可用于
接受动态参数
包含资源中的上下文
链接多个交互
引导特定的工作流
作为 UI 元素(如斜杠命令)展示
02.Prompt结构
{
name: string; // Prompt 的唯一标识符
description?: string; // 人类可读的描述
arguments?: [ // 可选参数列表
{
name: string; // 参数标识符
description?: string; // 参数描述
required?: boolean; // 该参数是否必填
}
]
}
03.发现Prompts
a.说明
客户端可以通过 prompts/list 端点获取可用的 Prompts
b.代码
// 请求
{
method: "prompts/list"
}
// 响应
{
prompts: [
{
name: "analyze-code",
description: "分析代码以寻找潜在的改进点",
arguments: [
{
name: "language",
description: "编程语言",
required: true
}
]
}
]
}
04.使用Prompts
a.说明
客户端可以通过 prompts/get 请求使用 Prompt
b.代码
// 请求
{
method: "prompts/get",
params: {
name: "analyze-code",
arguments: {
language: "python"
}
}
}
// 响应
{
description: "分析 Python 代码以寻找潜在的改进点",
messages: [
{
role: "user",
content: {
type: "text",
text: "请分析以下 Python 代码并提出改进建议:\n\n```python\ndef calculate_sum(numbers):\n total = 0\n for num in numbers:\n total = total + num\n return total\n\nresult = calculate_sum([1, 2, 3, 4, 5])\nprint(result)\n```"
}
}
]
}
05.动态Prompts
a.嵌入资源上下文
{
"name": "analyze-project",
"description": "分析项目日志和代码",
"arguments": [
{
"name": "timeframe",
"description": "要分析日志的时间范围",
"required": true
},
{
"name": "fileUri",
"description": "要审查的代码文件 URI",
"required": true
}
]
}
-----------------------------------------------------------------------------------------------------
当处理 prompts/get 请求时
{
"messages": [
{
"role": "user",
"content": {
"type": "text",
"text": "分析这些系统日志和代码文件中的问题:"
}
},
{
"role": "user",
"content": {
"type": "resource",
"resource": {
"uri": "logs://recent?timeframe=1h",
"text": "[2024-03-14 15:32:11] ERROR: Connection timeout in network.py:127\n[2024-03-14 15:32:15] WARN: Retrying connection (attempt 2/3)\n[2024-03-14 15:32:20] ERROR: Max retries exceeded",
"mimeType": "text/plain"
}
}
},
{
"role": "user",
"content": {
"type": "resource",
"resource": {
"uri": "file:///path/to/code.py",
"text": "def connect_to_service(timeout=30):\n retries = 3\n for attempt in range(retries):\n try:\n return establish_connection(timeout)\n except TimeoutError:\n if attempt == retries - 1:\n raise\n time.sleep(5)\n\ndef establish_connection(timeout):\n # 连接实现\n pass",
"mimeType": "text/x-python"
}
}
}
]
}
b.多步骤工作流
typescript
复制编辑
const debugWorkflow = {
name: "debug-error",
async getMessages(error: string) {
return [
{
role: "user",
content: {
type: "text",
text: `我遇到了一个错误:${error}`
}
},
{
role: "assistant",
content: {
type: "text",
text: "我会帮助分析这个错误。你尝试过什么方法?"
}
},
{
role: "user",
content: {
type: "text",
text: "我尝试了重启服务,但错误仍然存在。"
}
}
];
}
};
06.代码实现
typescript
复制编辑
import { Server } from "@modelcontextprotocol/sdk/server";
import {
ListPromptsRequestSchema,
GetPromptRequestSchema
} from "@modelcontextprotocol/sdk/types";
const PROMPTS = {
"git-commit": {
name: "git-commit",
description: "生成 Git 提交信息",
arguments: [
{
name: "changes",
description: "Git diff 或更改描述",
required: true
}
]
},
"explain-code": {
name: "explain-code",
description: "解释代码的工作原理",
arguments: [
{
name: "code",
description: "要解释的代码",
required: true
},
{
name: "language",
description: "编程语言",
required: false
}
]
}
};
const server = new Server({
name: "example-prompts-server",
version: "1.0.0"
}, {
capabilities: {
prompts: {}
}
});
server.setRequestHandler(ListPromptsRequestSchema, async () => {
return {
prompts: Object.values(PROMPTS)
};
});
server.setRequestHandler(GetPromptRequestSchema, async (request) => {
const prompt = PROMPTS[request.params.name];
if (!prompt) {
throw new Error(`未找到 Prompt:${request.params.name}`);
}
if (request.params.name === "git-commit") {
return {
messages: [
{
role: "user",
content: {
type: "text",
text: `为以下更改生成简洁但描述性的提交信息:\n\n${request.params.arguments?.changes}`
}
}
]
};
}
if (request.params.name === "explain-code") {
const language = request.params.arguments?.language || "未知";
return {
messages: [
{
role: "user",
content: {
type: "text",
text: `解释这段 ${language} 代码的工作原理:\n\n${request.params.arguments?.code}`
}
}
]
};
}
throw new Error("未找到 Prompt 实现");
});
07.UI界面
Prompts可以在客户端UI中以以下方式展示:
斜杠命令
快捷操作
右键菜单项
命令面板入口
指导性工作流
交互式表单
2.8 prompts2
00.介绍
提示词设计为 user-controlled,这意味着提示词由服务器向客户端公开,由用户自由选择使用
01.提示词结构
a.定义提示词的标准结构如下
{
name: string; // 提示词的唯一标识
description?: string; // 提示词的描述,必须清晰、可理解
arguments?: [ // 参数 (可选)
{
name: string; // 参数名称
description?: string; // 参数的描述,也必须清晰、可理解
required?: boolean; // 参数是否必填
}
]
}
02.获取提示词
a.客户端可以通过 prompts/list 端点获取可用的提示词模板
// 请求结构
{
method: "prompts/list"
}
// 返回结构
{
prompts: [
{
name: "analyze-code",
description: "Analyze code for potential improvements",
arguments: [
{
name: "language",
description: "Programming language",
required: true
}
]
}
]
}
03.如何使用提示词
a.客户端端可以通过 prompts/get 请求获取提示词模板。请求以及响应如下
// 请求
{
method: "prompts/get", // 请求url
params: {
name: "analyze-code", // 提示词模板名称
arguments: { // 参数
language: "python"
}
}
}
// 返回提示词模板
{
description: "Analyze Python code for potential improvements", // 描述,MCP Server定义
messages: [ // 消息
{
role: "user", // 消息类型
content: { // 内容
type: "text", // 内容类型
text: "Please analyze the following Python code for potential improvements:\n\n```python\ndef calculate_sum(numbers):\n total = 0\n for num in numbers:\n total = total + num\n return total\n\nresult = calculate_sum([1, 2, 3, 4, 5])\nprint(result)\n```"
}
}
]
}
04.动态提示词
a.说明
提示词不仅是静态的,而且也可以设置为动态的,比如可以嵌入用户的一些上下文信息
嵌入资源上下文
多步骤工作流
b.说明
动态提示词模板可以动态填入变量,比如代码片段、错误信息,生成针对性的输出。在实际的业务场景下使用也是非常多的
2.9 sampling
00.介绍
Sampling 是 MCP 的一个强大功能,它允许服务器通过客户端请求 LLM 补全
从而实现复杂的代理行为,同时保持安全性和隐私性
01.How sampling works
a.采样流程遵循以下步骤:
服务器向客户端发送 sampling/createMessage 请求
客户端审查请求并可以修改它
客户端从 LLM 中采样
客户端审查补全
客户端将结果返回给服务器
这种“人在回路”的设计确保用户对 LLM 看到和生成的内容保持控制
02.Message format
a.采样请求使用标准化的消息格式
{
messages: [
{
role: "user" | "assistant",
content: {
type: "text" | "image",
// For text:
text?: string,
// For images:
data?: string, // base64 encoded
mimeType?: string
}
}
],
modelPreferences?: {
hints?: [{
name?: string // Suggested model name/family
}],
costPriority?: number, // 0-1, importance of minimizing cost
speedPriority?: number, // 0-1, importance of low latency
intelligencePriority?: number // 0-1, importance of capabilities
},
systemPrompt?: string,
includeContext?: "none" | "thisServer" | "allServers",
temperature?: number,
maxTokens: number,
stopSequences?: string[],
metadata?: Record<string, unknown>
}
03.Request parameters
a.Messages
messages 数组包含要发送给 LLM 的对话历史。每条消息包含:
role: 可以是 “user” 或 “assistant”
content: 消息内容,可以是:
带有 text 字段的文本内容
带有 data(base64)和 mimeType 字段的图像内容
b.Model preferences
modelPreferences 对象允许服务器指定其模型选择偏好:
hints: 模型名称建议数组,客户端可以使用这些建议来选择适当的模型:
name: 可以匹配完整或部分模型名称的字符串(例如 “claude-3”, “sonnet”)
客户端可以将提示映射到不同提供商的等效模型
多个提示按优先顺序评估
优先级值(0-1 标准化):
costPriority: 最小化成本的重要性
speedPriority: 低延迟响应的重要性
intelligencePriority: 高级模型能力的重要性
客户端根据这些偏好和可用模型做出最终的模型选择
c.System prompt
可选的 systemPrompt 字段允许服务器请求特定的系统提示。客户端可以修改或忽略此提示
d.Context inclusion
includeContext 参数指定要包含的 MCP 上下文:
"none": 不包含额外的上下文
"thisServer": 包含来自请求服务器的上下文
"allServers": 包含来自所有连接的 MCP 服务器的上下文
客户端控制实际包含的上下文
e.Sampling parameters
通过以下参数微调 LLM 采样:
temperature: 控制随机性(0.0 到 1.0)
maxTokens: 生成的最大 token 数
stopSequences: 停止生成的序列数组
metadata: 额外的提供商特定参数
04.Response format
a.客户端返回补全结果
{
model: string, // Name of the model used
stopReason?: "endTurn" | "stopSequence" | "maxTokens" | string,
role: "user" | "assistant",
content: {
type: "text" | "image",
text?: string,
data?: string,
mimeType?: string
}
}
05.Example request
a.向客户端请求采样的示例
{
"method": "sampling/createMessage",
"params": {
"messages": [
{
"role": "user",
"content": {
"type": "text",
"text": "What files are in the current directory?"
}
}
],
"systemPrompt": "You are a helpful file system assistant.",
"includeContext": "thisServer",
"maxTokens": 100
}
}
06.Best practices
a.在实现采样时
始终提供清晰、结构良好的提示
正确处理文本和图像内容
设置合理的 token 限制
通过 includeContext 包含相关上下文
在使用前验证响应
优雅地处理错误
考虑对采样请求进行速率限制
记录预期的采样行为
使用各种模型参数进行测试
监控采样成本
07.Human in the loop controls
a.说明
采样设计时考虑了人工监督
b.For prompts
客户端应向用户显示提议的提示
用户应能够修改或拒绝提示
系统提示可以被过滤或修改
上下文包含由客户端控制
c.For completions
客户端应向用户显示补全
用户应能够修改或拒绝补全
客户端可以过滤或修改补全
用户控制使用哪个模型
08.Security considerations
a.在实现采样时
验证所有消息内容
清理敏感信息
实施适当的速率限制
监控采样使用情况
加密传输中的数据
处理用户数据隐私
审计采样请求
控制成本暴露
实施超时
优雅地处理模型错误
09.Common patterns
a.Agentic workflows
采样支持以下代理模式:
读取和分析资源
根据上下文做出决策
生成结构化数据
处理多步骤任务
提供交互式帮助
b.Context management
上下文的最佳实践:
请求最小必要的上下文
清晰地构建上下文
处理上下文大小限制
根据需要更新上下文
清理过时的上下文
c.Error handling
稳健的错误处理应:
捕获采样失败
处理超时错误
管理速率限制
验证响应
提供后备行为
适当记录错误
10.Limitations
a.请注意以下限制
采样取决于客户端的能力
用户控制采样行为
上下文大小有限制
可能适用速率限制
应考虑成本
模型可用性不同
响应时间不同
并非所有内容类型都支持
2.10 transports
00.介绍
在 Model Context Protocol (MCP) 中,Transports 提供了客户端和服务器之间通信的基础
Transport 负责处理消息发送和接收的底层机制
01.Message Format
a.定义
MCP 使用 JSON-RPC 2.0 作为其传输格式
Transport 层负责将 MCP 协议消息转换为 JSON-RPC 格式进行传输并将接收到的 JSON-RPC 消息转换回 MCP 协议消息
b.有三种类型的 JSON-RPC 消息
a.Requests
{
jsonrpc: "2.0",
id: number | string,
method: string,
params?: object
}
b.Responses
{
jsonrpc: "2.0",
id: number | string,
result?: object,
error?: {
code: number,
message: string,
data?: unknown
}
}
c.Notifications
{
jsonrpc: "2.0",
method: string,
params?: object
}
02.Built-in Transport Types
a.说明
MCP 包含两种标准的 Transport 实现
b.Standard Input/Output (stdio)
a.说明
stdio Transport 通过标准输入和输出流进行通信。这对于本地集成和命令行工具特别有用
b.使用 stdio 的场景:
构建命令行工具
实现本地集成
需要简单的进程通信
使用 shell 脚本
c.代码
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {}
});
const transport = new StdioServerTransport();
await server.connect(transport);
c.Server-Sent Events (SSE)
a.说明
SSE Transport 通过 HTTP POST 请求实现客户端到服务器的通信,并通过服务器到客户端的流进行通信
b.使用 SSE 的场景
仅需要服务器到客户端的流
在受限网络中工作
实现简单的更新
c.代码
import express from "express";
const app = express();
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {}
});
let transport: SSEServerTransport | null = null;
app.get("/sse", (req, res) => {
transport = new SSEServerTransport("/messages", res);
server.connect(transport);
});
app.post("/messages", (req, res) => {
if (transport) {
transport.handlePostMessage(req, res);
}
});
app.listen(3000);
03.Custom Transports
a.说明
MCP 使得为特定需求实现自定义 Transport 变得容易。任何 Transport 实现只需要符合 Transport 接口
b.使用
你可以为以下场景实现自定义 Transport:
自定义网络协议
专用通信通道
与现有系统集成
性能优化
c.代码
interface Transport {
// Start processing messages
start(): Promise<void>;
// Send a JSON-RPC message
send(message: JSONRPCMessage): Promise<void>;
// Close the connection
close(): Promise<void>;
// Callbacks
onclose?: () => void;
onerror?: (error: Error) => void;
onmessage?: (message: JSONRPCMessage) => void;
}
04.Error Handling
a.Transport 实现应处理各种错误场景
连接错误
消息解析错误
协议错误
网络超时
资源清理
b.示例错误处理
class ExampleTransport implements Transport {
async start() {
try {
// Connection logic
} catch (error) {
this.onerror?.(new Error(`Failed to connect: ${error}`));
throw error;
}
}
async send(message: JSONRPCMessage) {
try {
// Sending logic
} catch (error) {
this.onerror?.(new Error(`Failed to send message: ${error}`));
throw error;
}
}
}
05.Best Practices
在实现或使用 MCP Transport 时:
正确处理连接生命周期
实现适当的错误处理
在连接关闭时清理资源
使用适当的超时
在发送前验证消息
记录 Transport 事件以便调试
在适当的情况下实现重连逻辑
处理消息队列中的背压
监控连接健康状态
实施适当的安全措施
06.Security Considerations
a.Authentication and Authorization
实施适当的认证机制
验证客户端凭据
使用安全的令牌处理
实施授权检查
b.Data Security
使用 TLS 进行网络传输
加密敏感数据
验证消息完整性
实施消息大小限制
清理输入数据
c.Network Security
实施速率限制
使用适当的超时
处理拒绝服务场景
监控异常模式
实施适当的防火墙规则
07.Debugging Transport
a.调试 Transport 问题的技巧
启用调试日志
监控消息流
检查连接状态
验证消息格式
测试错误场景
使用网络分析工具
实施健康检查
监控资源使用情况
测试边缘情况
使用适当的错误跟踪
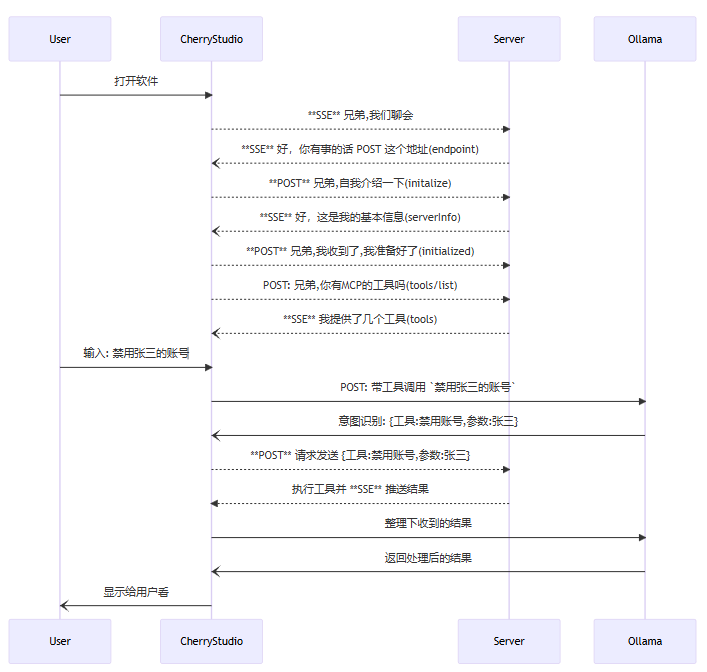
2.11 附:基础结构
00.基于注解的封装
a.代码
@McpMethod("modifyEmailByName")
@Description("modify user new email by name")
public String modifyEmailByName(
@Description("the name of user, e.g. 凌小云")
String name,
@Description("the new email of user, e.g. [email protected]")
String email
) {
List<UserEntity> userList = filter(new UserEntity().setNickname(name));
DATA_NOT_FOUND.when(userList.isEmpty(), "没有叫 " + name + " 的用户");
userList.forEach(user -> {
updateToDatabase(get(user.getId()).setEmail(email));
});
return "已经将 " + userList.size() + " 个叫 " + name + " 的用户邮箱修改为 " + email;
}
b.说明
只要标记了 @McpMethod 注解, MCP 服务器就会自动注册这个方法
01.MCP基础数据结构
a.基础结构
{
"id": 0,
"jsonrpc": "2.0"
}
b.请求结构 extends 基础结构
a.所有发送给 MCP 服务器的请求都是这个结构
interface Request {
// 请求的ID
id: number
// 请求的协议 固定2.0
jsonrpc: "2.0";
// 请求的方法
method: string;
// 请求的参数
params?: { ... };
}
b.例如:方法 initalize 的请求结构
{
"id": 0,
"jsonrpc": "2.0",
"method": "initalize",
"params": {
// 客户端的一些能力
"capabilities": {},
"clientInfo": {
// 一些客户端信息,比如名称、版本等
}
}
}
c.例如:函数调用的 请求结构
{
"id": 1,
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "disableUserByName",
"arguments": {
"name": "张三"
}
}
}
c.响应结构 extends 基础结构
a.所有通过 SSE 推送给客户端的响应都是这个结构
interface Response {
id: 0;
jsonrpc: "2.0";
result: {
// 一些数据信息
};
error: {
// 一些错误信息
};
}
d.SSE 服务
a.SpringBoot 下开启一个 SSE 服务
public final static ConcurrentHashMap<String, SseEmitter> EMITTERS = new ConcurrentHashMap<>();
@GetMapping(value = "sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter connect() throws IOException {
String uuid = UUID.randomUUID().toString();
SseEmitter emitter = new SseEmitter();
sseEmitter.send(SseEmitter.event()
.name("endpoint")
.data("/mcp/messages?sessionId=" + uuid)
.build()
);
EMITTERS.put(uuid, emitter);
// 可以加点心跳
emitter.onCompletion(() -> EMITTERS.remove(uuid));
emitter.onTimeout(() -> EMITTERS.remove(uuid));
return emitter;
return sseEmitter;
}
b.说明
MCP 要求连接上后必须发送一次消息,内容是 MCP 服务用于接受 POST 请求的 URL
e.Message POST API
a.POST请求
@PostMapping("messages")
public Json messages(HttpServletRequest request, @RequestBody McpRequest mcpRequest) {
String uuid = request.getParameter("sessionId");
if (Objects.isNull(uuid)) {
return Json.error("sessionId is required");
}
String method = mcpRequest.getMethod();
switch(method){
case "initalize":
// 这个请求是初始化请求,需要返回一些服务器信息给客户端
break;
case "tools/call":
// 这个请求是工具调用请求,需要返回执行结果给客户端
break;
case "tools/list":
// 这个请求是工具列表请求,需要返回一些工具列表给客户端
break;
default:
}
}
b.initalize 初始化:初始化请求需要响应给客户端的是服务器的一些基本信息
{
id: id,
jsonrpc: "2.0",
result: {
// 一些服务能力
capabilities: {},
serverInfo: {
name: "服务器名称",
version: "1.0.0"
}
}
}
c.请求工具列表:SSE 服务器收到到请求后,需要响应给客户端的是工具列表
{
"id": 0,
"jsonrpc": "2.0",
"result": {
"tools": [
{
"name": "disableUserByName",
"description": "禁用一个用户的账号",
"inputSchema": {
"type": "object",
"properties": {
"nickname": {
"type": "string",
"description": "名称"
}
},
"required": ["nickname"]
}
}
]
}
}
d.执行工具:SSE 服务器需要执行工具时,会得到这个结构体
{
"id": 1,
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "disableUserByName",
"arguments": {
"name": "张三"
}
}
}
-------------------------------------------------------------------------------------------------
你可以在执行一些代码后,返回下面的结构体:
{
"id": 1,
"jsonrpc": "2.0",
"result": {
"content": [
{
"type": "text",
"text": "好,张三被我干掉了"
}
]
}
}
3 mcp
3.1 bio
01.MCP客户端
客户端 | Resources | Prompts | Tools | Sampling | Roots | 说明
----------------------|-------------|----------|--------|------------|--------|----------------------------------------------------------
Claude Desktop App | ✅ | ✅ | ✅ | ❌ | ❌ | 完全支持 MCP 所有特性
5ire | ❌ | ❌ | ✅ | ❌ | ❌ | 支持工具。
BeeAI Framework | ❌ | ❌ | ✅ | ❌ | ❌ | 支持代理工作流中的工具。
Cline | ✅ | ❌ | ✅ | ❌ | ❌ | 支持工具和资源。
Continue | ✅ | ✅ | ✅ | ❌ | ❌ | 完全支持 MCP 所有特性
Cursor | ❌ | ❌ | ✅ | ❌ | ❌ | 支持工具。
Emacs Mcp | ❌ | ❌ | ✅ | ❌ | ❌ | 支持 Emacs 中的工具。
Firebase Genkit | ⚠️ | ✅ | ✅ | ❌ | ❌ | 支持通过工具进行资源列表和查找。
GenAIScript | ❌ | ❌ | ✅ | ❌ | ❌ | 支持工具。
Goose | ❌ | ❌ | ✅ | ❌ | ❌ | 支持工具。
LibreChat | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools for Agents
mcp-agent | ❌ | ❌ | ✅ | ⚠️ | ❌ | 支持工具、服务器连接管理和代理工作流程。
Roo Code | ✅ | ❌ | ✅ | ❌ | ❌ | 支持工具和资源。
Sourcegraph Cody | ✅ | ❌ | ❌ | ❌ | ❌ | 通过 OpenCTX 支持资源
Superinterface | ❌ | ❌ | ✅ | ❌ | ❌ | 支持工具
TheiaAI/TheiaIDE | ❌ | ❌ | ✅ | ❌ | ❌ | 支持 Theia AI 和 AI 驱动的 Theia IDE 中的 Agent 工具
Windsurf Editor | ❌ | ❌ | ✅ | ❌ | ❌ | 支持带有 AI Flow 的工具以进行协作开发。
Zed | ❌ | ✅ | ❌ | ❌ | ❌ | Prompts appear as slash commands 提示符显示为斜杠命令
OpenSumi | ❌ | ❌ | ✅ | ❌ | ❌ | 支持 OpenSumi 中的工具
02.Cursor
进入 Cursor 设置 > Features > MCP
点击"+Add New MCP Server"按钮
填写服务器配置信息(URL、名称等)
保存并开始使用
3.2 install
01.MCP-Playwright
a.说明
让 LLM 具备浏览器自动化能力:通过 MCP 连接 LLM,让 AI 能够直接操作网页
适用于 Claude、GPT-4o、DeepSeek 等大语言模型
支持与网页交互:支持常见的网页操作,包括点击按钮、填写表单、滚动页面等
截取网页截图:可以通过 Playwright MCP Server 获取网页的屏幕截图,分析当前页面的 UI 和内容
执行 JavaScript 代码:支持在浏览器环境中运行 JavaScript,与网页进行更复杂的交互
集成便捷工具:支持 Smithery 和 mcp-get 等工具,简化安装和配置过程
b.安装
a.克隆项目
git clone https://github.com/executeautomation/mcp-playwright.git
b.安装依赖
npm install
c.构建代码
npm run build
npm link
d.配置Claude Desktop,打开 claude-desktop-config.json 文件
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"--directory",
"/your-playwright-mcp-server-clone-directory",
"run",
"@modelcontextprotocol/playwright-mcp-server"
]
}
}
}
03.chatmcp
a.说明
ChatMCP 是基于模型上下文协议(MCP)的 AI 聊天客户端
支持与各种大型语言模型(LLM)如 OpenAI、Claude 和 OLLama 等进行交互
它具备自动化安装 MCP 服务器、SSE 传输支持、自动选择服务器、聊天记录管理等功能
提供 MCP 服务器市场实现与不同数据源的聊天
b.安装
a.确保系统中已安装 uvx 或 npx
brew install uv
brew install node
b.下载
git clone https://github.com/daodao97/chatmcp.git
cd chatmcp
flutter pub get
flutter run -d macos
c.配置
在设置页面配置 LLM API 密钥和端点
从 MCP 服务器页面安装 MCP 服务器
开始与 MCP 服务器聊天
d.调试
日志文件:~/Library/Application Support/run.daodao.chatmcp/logs
聊天记录数据库:~/Documents/chatmcp.db
MCP 服务器配置文件:~/Documents/mcp_server.json
e.重置应用
rm -rf ~/Library/Application\ Support/run.daodao.chatmcp
rm -rf ~/Documents/chatmcp.db
rm -rf ~/Documents/mcp_server.json
3.3 java
00.说明
MCP 官方支持四种语言的 SDK, Python、TypeScript、Java、Kotlin,并有其对应实现的SDK
Python SDK
TypeScript SDK
Java SDK
Kotlin SDK
01.Mcp Server
Claude Desktop App
02.Mcp Client
a.依赖
<dependencies>
<dependency>
<groupId>io.modelcontextprotocol.sdk</groupId>
<artifactId>mcp</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.modelcontextprotocol.sdk</groupId>
<artifactId>mcp-bom</artifactId>
<version>0.7.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
b.示例
package com.ivy.mcp;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.modelcontextprotocol.client.McpClient;
import io.modelcontextprotocol.client.McpSyncClient;
import io.modelcontextprotocol.client.transport.ServerParameters;
import io.modelcontextprotocol.client.transport.StdioClientTransport;
import io.modelcontextprotocol.spec.McpSchema;
import java.time.Duration;
import java.util.Map;
public class McpClientExample {
public static void main(String[] args) {
StdioClientTransport transport = new StdioClientTransport(
ServerParameters.builder("npx")
.args("-y",
"@modelcontextprotocol/server-filesystem",
"/Users/fangjie33/jdcs/mcp-client-examples")
.build(),
new ObjectMapper()
);
try (McpSyncClient client = McpClient.sync(transport)
.clientInfo(
new McpSchema.Implementation("my-client", "1.0.0")
)
.capabilities(
McpSchema.ClientCapabilities.builder().roots(true).sampling().build()
)
.requestTimeout(Duration.ofSeconds(60))
.build()) {
McpSchema.InitializeResult initialize = client.initialize();
System.out.println("client initialized: " + initialize);
tools(client); // 打印 MCP 工具列表
createDirectory(client); // 创建目录
createFile(client); // 创建文件
}
}
public static void tools (McpSyncClient client) {
McpSchema.ListToolsResult listToolsResult = client.listTools();
listToolsResult.tools().forEach(System.out::println);
}
public static void createDirectory(McpSyncClient client) {
McpSchema.CallToolRequest callToolRequest = new McpSchema.CallToolRequest(
"create_directory",
Map.of("path", "mcp")
);
McpSchema.CallToolResult callToolResult = client.callTool(callToolRequest);
System.out.println(callToolResult.content());
}
public static void createFile(McpSyncClient client) {
McpSchema.CallToolRequest callToolRequest = new McpSchema.CallToolRequest(
"write_file",
Map.of("path", "mcp/test.txt", "content", "hello world")
);
McpSchema.CallToolResult callToolResult = client.callTool(callToolRequest);
System.out.println(callToolResult.content());
}
}
3.4 spring
00.Spring AI MCP采用模块化架构,包括以下组件
Spring AI应用程序:使用Spring AI框架构建想要通过MCP访问数据的生成式AI应用程序
Spring MCP客户端:MCP协议的Spring AI实现,与服务器保持1:1连接
MCP服务器:轻量级程序,每个程序都通过标准化的模型上下文协议公开特定的功能
本地数据源:MCP服务器可以安全访问的计算机文件、数据库和服务
远程服务:MCP服务器可以通过互联网(例如,通过API)连接到的外部系统
01.基础使用
a.依赖
<dependency>
<groupId>org.springframework.experimental</groupId>
<artifactId>spring-ai-mcp</artifactId>
<version>0.2.0</version>
</dependency>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/libs-milestone-local</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
b.McpClient:注册MCPBrave服务和ChatClient
var stdioParams = ServerParameters.builder("npx")
.args("-y", "@modelcontextprotocol/server-brave-search")
.addEnvVar("BRAVE_API_KEY", System.getenv("BRAVE_API_KEY"))
.build();
var mcpClient = McpClient.using(new StdioClientTransport(stdioParams)).sync();
var init = mcpClient.initialize();
var chatClient = chatClientBuilder
.defaultFunctions(mcpClient.listTools(null)
.tools()
.stream()
.map(tool -> new McpFunctionCallback(mcpClient, tool))
.toArray(McpFunctionCallback[]::new))
.build();
String response = chatClient
.prompt("Does Spring AI supports the Model Context Protocol? Please provide some references.")
.call().content();
c.说明
在上述代码中,首先通过npx命令启动一个独立的进程,运行@modelcontextprotocol/server-brave-search服务
并指定Brave API密钥。然后创建一个基于stdio的传输层,与MCP server进行通信。最后初始化与MCP服务器的连接
要使用McpClient,需要将McpClient注入到Spring AI的ChatClient中,从而让LLM调用MCP server
在Spring AI中,可以通过Function Callbacks的方式将MCP工具转换为Spring AI的Function,从而让LLM调用
最后,通过ChatClient与LLM进行交互,并使用McpClient与MCP server进行通信,获取最终的返回结果
02.案例1:使用Spring AI MCP 访问本地文件系统
a.运行示例
a.前提条件
a.安装npx
npm install -g npx
b.下载示例源码
git clone https://github.com/springaialibaba/spring-ai-alibaba-examples.git
cd spring-ai-alibaba-examples/spring-ai-alibaba-mcp-example/filesystem
c.设置环境变量
# 通义大模型 Dashscope API-KEY
export AI_DASHSCOPE_API_KEY=${your-api-key-here}
b.构建示例
./mvnw clean install
c.运行示例应用
./mvnw spring-boot:run
运行示例,智能体将向模型发起提问(源码中包含预置问题,可通过源码查看),可通过控制台查看输出结果
如果您是在 IDE 中运行示例,并且遇到 filesystem mcp server 返回的文件访问权限问题,请确保指定当前进程工作目录为 spring-ai-alibaba-mcp-example/filesystem 目录
b.示例架构(源码说明)
a.声明 ChatClient
// List<McpFunctionCallback> functionCallbacks;
var chatClient = chatClientBuilder.defaultFunctions(functionCallbacks).build();
-------------------------------------------------------------------------------------------------
和开发之前的 Spring AI 应用一样,先定义一个 ChatClient Bean,用于与大模型交互的代理
为 ChatClient 注入的 functions 是通过 MCP 组件(McpFunctionCallback)创建的
b.声明 MCP Function Callbacks
通过 mcpClient与 MCP server 交互,将 MCP 工具通过 McpFunctionCallback 适配为标准的 Spring AI function
发现 MCP server 中可用的工具 tool(Spring AI 中叫做 function) 列表
依次将每个 tool 转换成 Spring AI function callback
最终将这些 McpFunctionCallback 注册到 ChatClient 使用
-------------------------------------------------------------------------------------------------
@Bean
public List<McpFunctionCallback> functionCallbacks(McpSyncClient mcpClient) {
return mcpClient.listTools(null)
.tools()
.stream()
.map(tool -> new McpFunctionCallback(mcpClient, tool))
.toList();
}
c.初始化McpClient
该智能体应用使用同步 MCP 客户端与本地运行的文件系统 MCP server 通信
-------------------------------------------------------------------------------------------------
@Bean(destroyMethod = "close")
public McpSyncClient mcpClient() {
var stdioParams = ServerParameters.builder("npx")
.args("-y", "@modelcontextprotocol/server-filesystem", "path))
.build(); // 1
var mcpClient = McpClient.sync(new StdioServerTransport(stdioParams),
Duration.ofSeconds(10), new ObjectMapper()); //2
var init = mcpClient.initialize(); // 3
System.out.println("MCP Initialized: " + init);
return mcpClient;
}
-------------------------------------------------------------------------------------------------
配置 MCP server 启动命令与参数
初始化 McpClient:关联 MCP server、指定超时时间等
Spring AI 会使用 npx -y @modelcontextprotocol/server-filesystem "/path/to/file"在本地机器创建一个独立的子进程(代表本地 Mcp server),Spring AI 与 McpClient 通信,McpClient 进而通过与 Mcp server 的连接操作本地文件
03.案例2:使用Spring AI MCP 访问SQLite数据库
a.运行示例
a.前提条件
a.安装uvx
请参考 UV安装文档
b.下载示例源码
git clone https://github.com/springaialibaba/spring-ai-alibaba-examples.git
cd spring-ai-alibaba-examples/spring-ai-alibaba-mcp-example/chatbot
c.设置环境变量
# 通义大模型 Dashscope API-KEY
export AI_DASHSCOPE_API_KEY=${your-api-key-here}
b.构建示例
./mvnw clean install
c.运行示例应用
./mvnw spring-boot:run
-------------------------------------------------------------------------------------------------
输入想要查询的内容,进行数据库的查询
USER: 所有商品的价格总和是多少
ASSISTANT: 所有商品的价格总和是1642.8元
-------------------------------------------------------------------------------------------------
还可以支持更复杂的查询
USER: 告诉我价格高于平均值的商品
ASSISTANT:
-------------------------------------------------------------------------------------------------
以下是价格高于平均值的商品:
1.Smart Watch,价格为 199.99 元
2.Wireless Earbuds,价格为 89.99 元
3.Mini Drone,价格为 299.99 元
4.Keyboard,价格为 129.99 元
5.Gaming Headset,价格为 159.99 元
6.Fitness Tracker,价格为 119.99 元
7.Portable SSD,价格为 179.99 元
b.示例架构(源码说明)
a.初始化McpClient
通过uvx包管理工具,创建一个独立的进程,运行 mcp-server-sqlite 服务
创建一个基于 stdio 的传输层,与 uvx 运行的 MCP 服务器进行通信
指定 SQLite 作为后端数据库及其位置,设置操作的超时时间为 10 秒,使用 Jackson 进行 JSON 序列化
最后初始化与 MCP 服务器的连接
-------------------------------------------------------------------------------------------------
@Bean(destroyMethod = "close")
public McpSyncClient mcpClient() {
var stdioParams = ServerParameters.builder("uvx")
.args("mcp-server-sqlite", "--db-path", getDbPath())
.build();
var mcpClient = McpClient.sync(new StdioServerTransport(stdioParams),
Duration.ofSeconds(10), new ObjectMapper());
var init = mcpClient.initialize();
System.out.println("MCP Initialized: " + init);
return mcpClient;
}
b.Function Callbacks
通过 Spring AI 注册 MCP 工具
-------------------------------------------------------------------------------------------------
@Bean
public List<McpFunctionCallback> functionCallbacks(McpSyncClient mcpClient) {
return mcpClient.listTools(null)
.tools()
.stream()
.map(tool -> new McpFunctionCallback(mcpClient, tool))
.toList();
}
-------------------------------------------------------------------------------------------------
通过 mcpClient 获取 MCP 可用客户端
将MCP客户端转换为为 Spring AI 的Function Callbacks
将这些Function Callbacks注册到 ChatClient 中
04.案例3:使用Spring AI MCP 访问本地文件系统
a.开发MCPserver 需要引入SpringAI下面三种依赖中的一种,取决于你打算使用什么通信方式
<!--标准IO通信类型的MCP服务端,适合命令行形式的桌面工具,例如之前的案例中的文件助手 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId>
</dependency>
<!--基于Http协议通信类型的MCP服务端 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-webmvc-spring-boot-starter</artifactId>
</dependency>
<!--基于SSE通信类型的MCP服务端 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-webflux-spring-boot-starter</artifactId>
</dependency>
b.一个标准的MCP服务端程序需要包含三个主要信息分别为Tools、Prompts、Resources
a.资源(Resources)
资源是AI可以读取的数据,比如文件内容、数据库查询结果或API的响应
例如,AI可能通过资源获取你的日历事件列表
b.工具(Tools)
工具是AI可以调用的函数,用于执行特定操作
比如添加新任务或发送邮件,使用工具时,通常需要用户先批准,以确保安全
c.提示词(Prompts)
提示词是服务器提供给AI的预写消息或模板,帮助AI理解如何使用资源和工具
例如,服务器可能告诉AI:“你可以添加任务,试试说‘添加任务:买牛奶’”
从而帮助用户更轻松地完成任务。提示词虽然直接提供给AI
但实际上是通过AI间接帮助用户,比如AI会根据提示词告诉用户如何操作
c.这三个要素在SpringAI中对应的API如下
a.说明
BookService 可以是你自己写的一个服务,比如可以执行查询DB或者调用其他微服务等代码实现
b.代码
package com.ahucoding.rocket.mcpserver.cfg;
import com.ahucoding.rocket.mcpserver.service.BookService;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.modelcontextprotocol.server.McpServerFeatures;
import io.modelcontextprotocol.spec.McpSchema;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.List;
import java.util.Map;
import java.util.function.Consumer;
/**
* @author 影子(关注公众号:硬核的子牙和周瑜;获取资料)
* 2025/03/18/下午8:02
*/
@Configuration
@EnableWebMvc
public class McpServerConfig implements WebMvcConfigurer {
@Bean
public ToolCallbackProvider openLibraryTools(BookService bookService) {
// 构建一个MethodToolCallbackProvider实例,用于处理工具对象
// 这里使用builder模式来构造对象,以提高代码的可读性和易用性
return MethodToolCallbackProvider.builder().toolObjects(bookService).build();
}
@Bean
public List<McpServerFeatures.SyncResourceRegistration> resourceRegistrations() {
// Create a resource registration for system information
// 创建一个代表系统信息资源的对象
var systemInfoResource = new McpSchema.Resource(
"system://info",
"System Information",
"Provides basic system information including Java version, OS, etc.",
"application/json", null
);
// 定义一个系统信息资源的同步注册对象
var resourceRegistration = new McpServerFeatures.SyncResourceRegistration(systemInfoResource, (request) -> {
try {
// 构建包含系统信息的映射表
var systemInfo = Map.of(
"javaVersion", System.getProperty("java.version"),
"osName", System.getProperty("os.name"),
"osVersion", System.getProperty("os.version"),
"osArch", System.getProperty("os.arch"),
"processors", Runtime.getRuntime().availableProcessors(),
"timestamp", System.currentTimeMillis());
// 将系统信息映射表转换为JSON字符串
String jsonContent = new ObjectMapper().writeValueAsString(systemInfo);
// 返回包含系统信息JSON内容的资源读取结果
return new McpSchema.ReadResourceResult(
List.of(new McpSchema.TextResourceContents(request.uri(), "application/json", jsonContent)));
}
catch (Exception e) {
// 如果在生成系统信息时发生异常,则抛出运行时异常
throw new RuntimeException("Failed to generate system info", e);
}
});
// 返回包含资源注册对象的列表
return List.of(resourceRegistration);
}
@Bean
public List<McpServerFeatures.SyncPromptRegistration> promptRegistrations() {
// 创建一个名为"greeting"的提示对象,用于友好的问候语
// 包含一个名为"name"的参数,用于指定问候的对象
var prompt = new McpSchema.Prompt("greeting", "A friendly greeting prompt",
List.of(new McpSchema.PromptArgument("name", "The name to greet", true)));
// 创建一个提示注册对象,用于在服务器上同步注册上述提示
// 当收到该提示的请求时,执行以下逻辑
var promptRegistration = new McpServerFeatures.SyncPromptRegistration(prompt, getPromptRequest -> {
// 从请求参数中获取"name"的值,如果未提供,则默认为"friend"
String nameArgument = (String) getPromptRequest.arguments().get("name");
if (nameArgument == null) {
nameArgument = "friend";
}
// 构造一个用户角色的提示消息,包含个性化的问候语
var userMessage = new McpSchema.PromptMessage(McpSchema.Role.USER,
new McpSchema.TextContent("Hello " + nameArgument + "! How can I assist you today?"));
// 返回个性化的问候消息结果
return new McpSchema.GetPromptResult("A personalized greeting message", List.of(userMessage));
});
// 返回包含提示注册对象的列表
return List.of(promptRegistration);
}
@Bean
public Consumer<List<McpSchema.Root>> rootsChangeConsumer() {
// 返回一个消费型函数式接口的实现
// 该接口接受一个参数列表(roots),但不返回任何值
// 当接口方法被调用时,它会打印出"rootsChange",表明roots的值已经改变
return roots -> {
System.out.println("rootsChange");
};
}
}
c.配置
spring:
application:
name: mcp-server
# 定义AI模块的配置
ai:
# 配置MCP(Multi-Component Protocol)相关的参数
mcp:
# 指定MCP服务器的配置
server:
# 服务器的名称
name: webmvc-mcp-server
# 服务器的版本
version: 1.0.0
# 通信类型,这里配置为同步通信
type: SYNC
# 用于接收SSE(Server-Sent Events)消息的终点URL
sse-message-endpoint: /mcp/messages
3.5 springboot
00.MCP
a.说明
MCP就像是AI世界的"万能适配器"
想象你有很多不同类型的服务和数据库,每个都有自己独特的"说话方式"
AI需要和这些服务交流时就很麻烦,因为要学习每个服务的"语言"
b.MCP解决了这个问题
它就像一个统一的翻译官,让AI只需学一种"语言"就能和所有服务交流
这样开发者不用为每个服务单独开发连接方式,AI也能更容易获取它需要的信息
01.准备图书管理服务
a.图书实体字段
import jakarta.persistence.*;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.NotNull;
import jakarta.validation.constraints.PastOrPresent;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.LocalDate;
@Entity
@Table(name = "books")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "书名不能为空")
@Column(nullable = false)
private String title;
@NotBlank(message = "分类不能为空")
@Column(nullable = false)
private String category;
@NotBlank(message = "作者不能为空")
@Column(nullable = false)
private String author;
@NotNull(message = "出版日期不能为空")
@PastOrPresent(message = "出版日期不能是未来日期")
@Column(nullable = false)
private LocalDate publicationDate;
@NotBlank(message = "ISBN编码不能为空")
@Column(nullable = false, unique = true)
private String isbn;
}
b.2个测试方法
import com.example.entity.Book;
import java.util.List;
public interface BookService {
// 根据作者查询
List<Book> findBooksByAuthor(String author);
// 根据分类查询
List<Book> findBooksByCategory(String category);
}
02.改造接入MCP
a.导入依赖
a.依赖
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
</dependency>
<!-- Anthropic 模型支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-anthropic-spring-boot-starter</artifactId>
</dependency>
<!-- MCP 服务器支持 - WebMVC版本 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-webmvc-spring-boot-starter</artifactId>
</dependency>
b.目前这些依赖还是预览版本,所以在Maven中央仓库中是找不到的,需要我们额外引入仓库地址
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
c.配置代理
import jakarta.annotation.PostConstruct;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ProxyConfig {
// 代理设置
private final String PROXY_HOST = "127.0.0.1";
private final int PROXY_PORT = 10080;
@PostConstruct
public void setSystemProxy() {
// 设置系统代理属性,这会影响Spring Boot自动配置的HTTP客户端
System.setProperty("http.proxyHost", PROXY_HOST);
System.setProperty("http.proxyPort", String.valueOf(PROXY_PORT));
System.setProperty("https.proxyHost", PROXY_HOST);
System.setProperty("https.proxyPort", String.valueOf(PROXY_PORT));
System.out.println("System proxy configured: http://" + PROXY_HOST + ":" + PROXY_PORT);
}
}
b.引入配置
a.说明
将一个Spring服务改造成MCP服务,所以这里不需要进行客户端的配置
同理,在引入依赖的时候也不用引入客户端的依赖
b.配置
# Spring AI api-key
spring.ai.anthropic.api-key=这里换成你的api-key
# MCP服务端开启
spring.ai.mcp.server.enabled=true
# MCP服务端配置
spring.ai.mcp.server.name=book-management-server
spring.ai.mcp.server.version=1.0.0
spring.ai.mcp.server.type=SYNC
spring.ai.mcp.server.sse-message-endpoint=/mcp/message
c.改造原服务方法
a.服务的改造有两种思路
1.工具配置方式:在需要改造的实现类对需要改造的方法加上@Tool和@ToolParam注解分别标记方法和参数
2.函数Bean方式
b.方式1:工具配置方式
a.实现类
import com.example.entity.Book;
import com.example.repository.BookRepository;
import com.example.service.BookService;
import jakarta.annotation.Resource;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
@RequiredArgsConstructor
public class BookServiceImpl implements BookService {
@Resource
private BookRepository bookRepository;
@Override
@Tool(name = "findBooksByTitle", description = "根据书名模糊查询图书,支持部分标题匹配")
public List<Book> findBooksByTitle(@ToolParam(description = "书名关键词") String title) {
return bookRepository.findByTitleContaining(title);
}
@Override
@Tool(name = "findBooksByAuthor", description = "根据作者精确查询图书")
public List<Book> findBooksByAuthor(@ToolParam(description = "作者姓名") String author) {
return bookRepository.findByAuthor(author);
}
@Override
@Tool(name = "findBooksByCategory", description = "根据图书分类精确查询图书")
public List<Book> findBooksByCategory(@ToolParam(description = "图书分类")String category) {
return bookRepository.findByCategory(category);
}
}
b.将这个实现类注册到MCP服务器配置上
import com.example.service.BookService;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* MCP服务器配置类,负责注册MCP工具
*/
@Configuration
public class McpServerConfig {
/**
* 注册工具回调提供者,将BookService中的@Tool方法暴露为MCP工具
*
* @param bookService 图书服务
* @return 工具回调提供者
*/
@Bean
public ToolCallbackProvider bookToolCallbackProvider(BookService bookService) {
return MethodToolCallbackProvider.builder()
.toolObjects(bookService)
.build();
}
}
c.在聊天客户端配置引入注册工具
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 聊天客户端配置类
*/
@Configuration
public class ChatClientConfig {
@Autowired
private ToolCallbackProvider toolCallbackProvider;
/**
* 配置ChatClient,注册系统指令和工具函数
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem("你是一个图书管理助手,可以帮助用户查询图书信息。" +
"你可以根据书名模糊查询、根据作者查询和根据分类查询图书。" +
"回复时,请使用简洁友好的语言,并将图书信息整理为易读的格式。")
// 注册工具方法
.defaultTools(toolCallbackProvider)
.build();
}
}
c.方式2:函数Bean方式:声明一个类将查询方法作为函数Bean导出
a.代码
import com.example.entity.Book;
import com.example.service.BookService;
import jakarta.annotation.Resource;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.function.Function;
/**
* 图书查询服务,将查询方法作为函数Bean导出
*/
@Service
public class BookQueryService {
@Resource
private BookService bookService;
/**
* 根据书名查询图书的函数Bean
*/
@Bean
public Function<String, List<Book>> findBooksByTitle() {
return title -> bookService.findBooksByTitle(title);
}
/**
* 根据作者查询图书的函数Bean
*/
@Bean
public Function<String, List<Book>> findBooksByAuthor() {
return author -> bookService.findBooksByAuthor(author);
}
/**
* 根据分类查询图书的函数Bean
*/
@Bean
public Function<String, List<Book>> findBooksByCategory() {
return category -> bookService.findBooksByCategory(category);
}
}
b.采用这种方式在定义AI聊天客户端的时候需要显式地声明
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 聊天客户端配置类
*/
@Configuration
public class ChatClientConfig {
/**
* 配置ChatClient,注册系统指令和工具函数
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem("你是一个图书管理助手,可以帮助用户查询图书信息。" +
"你可以根据书名模糊查询、根据作者查询和根据分类查询图书。" +
"回复时,请使用简洁友好的语言,并将图书信息整理为易读的格式。")
// 注册工具方法,这里使用方法名称来引用Spring上下文中的函数Bean
.defaultTools(
"findBooksByTitle",
"findBooksByAuthor",
"findBooksByCategory"
)
.build();
}
}
d.接口测试
a.声明一个控制器对外暴露进行调用
import com.example.model.ChatRequest;
import com.example.model.ChatResponse;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
/**
* 聊天控制器,处理AI聊天请求
*/
@RestController
@RequestMapping("/api/chat")
public class ChatController {
@Resource
private ChatClient chatClient;
/**
* 处理聊天请求,使用AI和MCP工具进行响应
*
* @param request 聊天请求
* @return 包含AI回复的响应
*/
@PostMapping
public ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest request) {
try {
// 创建用户消息
String userMessage = request.getMessage();
// 使用流式API调用聊天
String content = chatClient.prompt()
.user(userMessage)
.call()
.content();
return ResponseEntity.ok(new ChatResponse(content));
} catch (Exception e) {
e.printStackTrace();
return ResponseEntity.ok(new ChatResponse("处理请求时出错: " + e.getMessage()));
}
}
}
b.为了方便测试,开发一个数据初始化器,通过实现CommandLineRunner接口,它会在我们的应用程序启动时自动向数据库中加载这些测试数据
import com.example.entity.Book;
import com.example.repository.BookRepository;
import jakarta.annotation.Resource;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import java.time.LocalDate;
import java.util.Arrays;
import java.util.List;
@Component
@RequiredArgsConstructor
public class DataInitializer implements CommandLineRunner {
@Resource
private BookRepository bookRepository;
@Override
public void run(String... args) throws Exception {
// 准备示例数据
List<Book> sampleBooks = Arrays.asList(
new Book(null, "Spring实战(第6版)", "编程", "Craig Walls",
LocalDate.of(2022, 1, 15), "9787115582247"),
new Book(null, "深入理解Java虚拟机", "编程", "周志明",
LocalDate.of(2019, 12, 1), "9787111641247"),
new Book(null, "Java编程思想(第4版)", "编程", "Bruce Eckel",
LocalDate.of(2007, 6, 1), "9787111213826"),
new Book(null, "算法(第4版)", "计算机科学", "Robert Sedgewick",
LocalDate.of(2012, 10, 1), "9787115293800"),
new Book(null, "云原生架构", "架构设计", "张三",
LocalDate.of(2023, 3, 15), "9781234567890"),
new Book(null, "微服务设计模式", "架构设计", "张三",
LocalDate.of(2021, 8, 20), "9789876543210"),
new Book(null, "领域驱动设计", "架构设计", "Eric Evans",
LocalDate.of(2010, 4, 10), "9787111214748"),
new Book(null, "高性能MySQL", "数据库", "Baron Schwartz",
LocalDate.of(2013, 5, 25), "9787111464747"),
new Book(null, "Redis实战", "数据库", "Josiah L. Carlson",
LocalDate.of(2015, 9, 30), "9787115419378"),
new Book(null, "深入浅出Docker", "容器技术", "李四",
LocalDate.of(2022, 11, 20), "9787123456789")
);
// 保存示例数据
bookRepository.saveAll(sampleBooks);
System.out.println("数据初始化完成,共加载 " + sampleBooks.size() + " 本图书");
}
}
c.调用
POST http://127.0.0.1:8080/api/chat
{
"message":"图书表上有哪些张三写的书?"
}
3.6 python1
01.MCPServer
a.先决条件
1.已安装 python 3.10 或更高
2.已安装 Claude for Desktop
b.安装uv,设置环境变量
a.打开 Powershell,输入如下命令
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
b.打开系统高级环境变量,在 Path 将uv路径添加进去
C:\Users\windows\.local\bin
c.重启 Powershell
d.在命令行输入 uv --version ,能返回版本信息就算安装成功了
c.创建和设置项目
a.打开 Powershell
cd 到你想要创建项目的目录位置
b.接着依次输入以下命令
# Create a new directory for our project
uv init weather
cd weather
# Create virtual environment and activate it
uv venv
.venv\Scripts\activate
# Install dependencies
uv add mcp[cli] httpx
# Create our server file。new-item 是powershell 命令,用于创建文件
new-item weather.py
d.添加weather.py
from typing import Any
import httpx
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("weather")
# Constants
NWS_API_BASE = "https://api.weather.gov"
USER_AGENT = "weather-app/1.0"
async def make_nws_request(url: str) -> dict[str, Any] | None:
"""Make a request to the NWS API with proper error handling."""
headers = {
"User-Agent": USER_AGENT,
"Accept": "application/geo+json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception:
return None
def format_alert(feature: dict) -> str:
"""Format an alert feature into a readable string."""
props = feature["properties"]
return f"""
Event: {props.get('event', 'Unknown')}
Area: {props.get('areaDesc', 'Unknown')}
Severity: {props.get('severity', 'Unknown')}
Description: {props.get('description', 'No description available')}
Instructions: {props.get('instruction', 'No specific instructions provided')}
"""
@mcp.tool()
async def get_alerts(state: str) -> str:
"""Get weather alerts for a US state.
Args: state: Two-letter US state code (e.g. CA, NY) """ url = f"{NWS_API_BASE}/alerts/active/area/{state}"
data = await make_nws_request(url)
if not data or "features" not in data:
return "Unable to fetch alerts or no alerts found."
if not data["features"]:
return "No active alerts for this state."
alerts = [format_alert(feature) for feature in data["features"]]
return "\n---\n".join(alerts)
@mcp.tool()
async def get_forecast(latitude: float, longitude: float) -> str:
"""Get weather forecast for a location.
Args: latitude: Latitude of the location longitude: Longitude of the location """ # First get the forecast grid endpoint
points_url = f"{NWS_API_BASE}/points/{latitude},{longitude}"
points_data = await make_nws_request(points_url)
if not points_data:
return "Unable to fetch forecast data for this location."
# Get the forecast URL from the points response
forecast_url = points_data["properties"]["forecast"]
forecast_data = await make_nws_request(forecast_url)
if not forecast_data:
return "Unable to fetch detailed forecast."
# Format the periods into a readable forecast
periods = forecast_data["properties"]["periods"]
forecasts = []
for period in periods[:5]: # Only show next 5 periods
forecast = f"""
{period['name']}:
Temperature: {period['temperature']}°{period['temperatureUnit']}
Wind: {period['windSpeed']} {period['windDirection']}
Forecast: {period['detailedForecast']}
"""
forecasts.append(forecast)
return "\n---\n".join(forecasts)
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')
e.运行服务
a.打开 Claude for Desktop
点击左上角菜单 —— File —— Settings —— Developer
b.点击 Edit Config
就会在 C:\Users\windows\AppData\Roaming\Claude 目录下自动创建 claude_desktop_config.json 文件
c.打开 claude_desktop_config.json, 添加如下代码:
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"T:\\PythonProject\\weather",
"run",
"weather.py"
]
}
}
}
-------------------------------------------------------------------------------------------------
其中路径为在上一步创建的weather目录, 使用绝对路径
这会告诉 Claude for Desktop ,我们的服务名叫 weather ,通过 uv --directory T:\\PythonProject\\weather run weather 来启动服务
d.保存文件
f.在Claude中使用服务
1.打开任务管理器,将 Claude 结束任务,彻底关掉
2.重新打开 Claude for Desktop
3.如果在Claude的对话框下看到了一把锤子,说明我们的MCP服务配置成功了
4.点击锤子能看到
5.在设置页显示如下
6.下面测试服务,在对话框输入:what's the weather in NY
02.MCP Client
a.说明
要使用Claude API, 需要充值购买credits
否则请求会报Error: Error code: 403 - {'error': {'type': 'forbidden', 'message': 'Request not allowed'}}
b.打开Powershell , cd 到python项目的目录下,依次输入如下命令
# Create project directory
uv init mcp-client
cd mcp-client
# Create virtual environment
uv venv
# Activate virtual environment
# On Windows:
.venv\Scripts\activate
# On Unix or MacOS:
source .venv/bin/activate
# Install required packages
uv add mcp anthropic python-dotenv
# Create our main file
new-item client.py
c.配置API_KEY
a.创建.env文件
new-item .env
b.打开.env文件,复制以下代码
ANTHROPIC_API_KEY=<your key here>
在Claude控制台创建KEY(需充值才能用),将API Key复制到.env (确保key的安全,不要分享出去!)
c.将.env文件添加到.gitignore , 在 powershell 输入以下命令
echo ".env" >> .gitignore
d.添加代码
import asyncio
from typing import Optional
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv() # load environment variables from .env
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.anthropic = Anthropic()
# methods will go here
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server
Args: server_script_path: Path to the server script (.py or .js) """ is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""Process a query using Claude and available tools"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in response.tools]
# Initial Claude API call
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
# Process response and handle tool calls
tool_results = []
final_text = []
assistant_message_content = []
for content in response.content:
if content.type == 'text':
final_text.append(content.text)
assistant_message_content.append(content)
elif content.type == 'tool_use':
tool_name = content.name
tool_args = content.input
# Execute tool call
result = await self.session.call_tool(tool_name, tool_args)
tool_results.append({"call": tool_name, "result": result})
final_text.append(f"[Calling tool {tool_name} with args {tool_args}]")
assistant_message_content.append(content)
messages.append({
"role": "assistant",
"content": assistant_message_content
})
messages.append({
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": content.id,
"content": result.content
}
]
})
# Get next response from Claude
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
final_text.append(response.content[0].text)
return "\n".join(final_text)
async def chat_loop(self):
"""Run an interactive chat loop"""
print("\nMCP Client Started!")
print("Type your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
async def cleanup(self):
"""Clean up resources"""
await self.exit_stack.aclose()
async def main():
if len(sys.argv) < 2:
print("Usage: python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
import sys
asyncio.run(main())
e.运行Client
这里我们使用上文创建的mcp服务weather
在powershell输入:uv run client.py T:/PythonProject/weather/weather.py
接着,我们就可以在 Query 输入问题了
3.7 python2
01.回声助手
a.准备工具
a.确保你有Python
略
b.安装MCP工具包
pip install mcp
b.写一个简单程序
a.新建一个文件,叫 server.py
from mcp import FastMCP, mcp
app = FastMCP("Echo Server") # 给你的服务起个名字
@app.tool() # 定义一个工具叫“echo”
async def echo(message: str) -> str:
return f"You said: {message}" # 收到啥,回啥
if __name__ == "__main__":
app.run() # 启动服务
b.保存文件,记好它的位置
桌面
c.连接到Claude
a.下载Claude桌面版
官网
b.找到配置文件
Mac用户:~/Library/Logs/Claude/claude_desktop_config.json
Windows用户:~\AppData\Roaming\Claude\claude_desktop_config.json
c.修改配置
{
"mcpServers": {
"echo": {
"command": "python",
"args": ["server.py"]
}
}
}
-------------------------------------------------------------------------------------------------
server.py 的路径要正确,比如放在桌面就写全路径
d.启动并测试
a.打开终端,进入 server.py 所在的文件夹,输入
mcp dev server.py
b.重启Claude桌面版
略
c.在Claude聊天框里
点右下角的小锤子图标,看看有没有 echo 工具
d.测试
输入:你好
输出:你好
02.查数据库
a.准备数据库
a.下载个SQLite工具
比如DB Browser for SQLite
b.新建一个 example.db 文件,在里面建个表
CREATE TABLE users (name TEXT, age INTEGER);
INSERT INTO users (name, age) VALUES ('小明', 20), ('小红', 25);
b.新建sqlite_server.py
import sqlite3
from mcp import FastMCP, mcp
app = FastMCP("SQLite Server") # 服务名叫SQLite
conn = sqlite3.connect("example.db") # 连上你的数据库
@app.tool() # 定义一个查数据的工具
async def query_database(sql: str) -> str:
cursor = conn.execute(sql) # 执行SQL
results = cursor.fetchall() # 拿到结果
return str(results) # 返回给AI
if __name__ == "__main__":
app.run() # 启动
c.配置Claude
略
{
"mcpServers": {
"sqlite": {
"command": "python",
"args": ["sqlite_server.py"]
}
}
}
d.运行
a.终端运行
mcp dev sqlite_server.py
b.重启Claude
输入:用query_database工具查 SELECT * FROM users;
输出:"[('小明', 20), ('小红', 25)]"
4 sdks
4.1 bio
01.Text-to-SQL
Vanna
02.Archon
a.说明
Pydantic AI 框架:用于智能体的代码生成和优化,支持框架无关的智能体生成
LangGraph 框架:用于多智能体工作流的规划和执行,提升系统的灵活性和效率
文档爬取与语义搜索:通过爬取文档并存储到向量数据库中,结合语义搜索功能,为智能体提供实时的知识支持
Streamlit Web 界面:简化用户与 Archon 的交互,提供直观的操作界面
b.安装
a.Docker(推荐)
a.克隆仓库
git clone https://github.com/coleam00/archon.git
cd archon
b.运行 Docker 安装脚本
python run_docker.py
c.访问 Streamlit UI
http://localhost:8501
b.本地 Python 安装
a.克隆仓库
git clone https://github.com/coleam00/archon.git
cd archon
b.安装依赖
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt
c.启动 Streamlit UI
streamlit run streamlit_ui.py
d.访问 Streamlit UI
http://localhost:8501
4.2 cline
01.概述
a.定义
Cline 是一个基于 VS Code 的智能助手插件,它通过 AI 技术为开发者提供智能化的任务处理能力
在现代软件开发中,开发者经常需要在多个工具间切换,处理大量重复性工作,同时还要维持对代码和业务的深入理解
这不仅降低了开发效率,还增加了认知负担
Cline 正是为解决这些问题而设计。它将 AI 能力与开发工具深度集成,提供了一个统一的智能化开发环境
通过智能理解开发者意图,自动化执行开发任务,并保持对项目上下文的持续理解,Cline 显著提升了开发效率和体验
b.核心组件
ClineProvider:负责状态管理和 UI 交互
Cline:核心业务逻辑处理
外部服务集成:包括 AI 服务、认证服务等
工具系统:提供文件操作、命令执行等能力
c.四个核心目标
a.工具统一
在 VS Code 中集成文件操作、命令执行、浏览器控制等能力
提供统一的界面来执行各种开发任务
减少工具切换带来的认知负担
b.智能自动化
通过 AI 理解开发者意图
自动完成重复性工作
智能化的代码理解和生成
c.上下文保持
维护对项目结构的持续理解
在任务执行过程中保持状态连贯
支持长时间运行的复杂任务
d.安全可控
提供操作确认机制
支持任务的暂停和恢复
实现关键操作的回滚能力
02.核心执行流程
a.任务执行流程
a.任务初始化
用户通过 Webview 界面输入任务
Webview 将消息传递给 ClineProvider
ClineProvider 创建和初始化 Cline 实例
b.任务执行循环
Cline 向 AI 服务发送请求
AI 服务返回响应和可能的工具调用
Cline 解析响应并执行相应的工具
需要用户确认的操作会请求用户确认
工具执行结果返回给 Cline
Cline 将结果返回给 AI 服务继续处理
c.任务完成
当所有必要的步骤都完成后
Cline 向用户返回最终结果
任务执行完成
b.工具执行流程
图示
03.核心组件实现
a.ClineProvider Cline 核心类
class ClineProvider implements vscode.WebviewViewProvider {
private cline?: Cline
private view?: vscode.WebviewView
private context: vscode.ExtensionContext
// 核心管理功能
async initClineWithTask(task?: string)
async handleMessage(message: Message)
async updateState(state: State)
// 定义全局文件名
export const GlobalFileNames = {
apiConversationHistory: "api_conversation_history.json", // API对话历史
uiMessages: "ui_messages.json", // UI消息
openRouterModels: "openrouter_models.json", // OpenRouter模型
mcpSettings: "cline_mcp_settings.json", // MCP设置
clineRules: ".clinerules", // Cline规则
}
}
-----------------------------------------------------------------------------------------------------
class ClineProvider {
constructor(context: vscode.ExtensionContext) {
this.context = context
this.cline = undefined // 延迟初始化
}
async initClineWithTask(task?: string) {
await this.clearTask() // 清理现有任务
// 获取配置
const config = await this.getState()
// 创建新实例
this.cline = new Cline(
this,
config.apiConfiguration,
config.autoApprovalSettings,
config.browserSettings,
config.chatSettings,
config.customInstructions
)
}
}
-----------------------------------------------------------------------------------------------------
export class Cline {
// 核心属性
readonly taskId: string;
api: ApiHandler;
private terminalManager: TerminalManager;
private urlContentFetcher: UrlContentFetcher;
browserSession: BrowserSession;
// 状态控制
private didEditFile: boolean = false;
private abort: boolean = false;
private consecutiveMistakeCount: number = 0;
// 历史记录
apiConversationHistory: Anthropic.MessageParam[] = [];
clineMessages: ClineMessage[] = [];
// 配置系统
autoApprovalSettings: AutoApprovalSettings;
private browserSettings: BrowserSettings;
private chatSettings: ChatSettings;
// 任务执行核心方法
async startTask(task?: string, images?: string[]): Promise<void> {
// 初始化状态
this.clineMessages = [];
this.apiConversationHistory = [];
// 更新界面
await this.providerRef.deref()?.postStateToWebview();
// 显示任务
await this.say("text", task, images);
// 标记初始化完成
this.isInitialized = true;
// 构建初始消息
let imageBlocks = formatResponse.imageBlocks(images);
// 启动任务循环
await this.initiateTaskLoop(
[{
type: "text",
text: `<task>\\n${task}\\n</task>`,
},
...imageBlocks],
true // isNewTask 标记
);
}
}
b.任务循环实现
private async initiateTaskLoop(
userContent: UserContent,
isNewTask: boolean
): Promise<void> {
let nextUserContent = userContent;
let includeFileDetails = true;
while (!this.abort) {
// 核心请求处理
const didEndLoop = await this.recursivelyMakeClineRequests(
nextUserContent,
includeFileDetails,
isNewTask
);
includeFileDetails = false;
if (didEndLoop) {
break;
} else {
// 处理未使用工具的情况
nextUserContent = [{
type: "text",
text: formatResponse.noToolsUsed(),
}];
this.consecutiveMistakeCount++;
}
}
}
c.任务结束的条件
// 1. this.abort 为 true 的情况:
- 用户手动中止
- 发生严重错误
- Cline 实例被销毁
// 2. didEndLoop 为 true 的情况:
- 任务成功完成(使用 attempt_completion 工具)
- 达到最大错误次数
- 任务被标记为完成
// 3. 其他终止条件:
- 连续错误次数过多
- API 调用失败
- 工具执行失败
04.请求处理系统
a.递归请求处理
private async recursivelyMakeClineRequests(
userContent: UserContent,
includeFileDetails: boolean,
isNewTask: boolean
): Promise<boolean> {
// 1. 错误检查
if (this.consecutiveMistakeCount >= MAX_CONSECUTIVE_MISTAKES) {
throw new Error("Too many consecutive mistakes")
}
try {
// 2. 准备消息
const messages = this.prepareMessages(userContent, includeFileDetails)
// 3. 发送 API 请求
const response = await this.api.sendRequest(messages)
// 4. 处理响应
if (response.type === "completion") {
return true // 任务完成
} else if (response.type === "tool_use") {
await this.handleToolUse(response.tool)
return false // 继续执行
}
} catch (error) {
this.handleError(error)
return true
}
}
b.消息准备
private prepareMessages(
userContent: UserContent,
includeFileDetails: boolean
): MessageParam[] {
// 1. 构建基础消息
const messages = [...this.apiConversationHistory]
// 2. 添加环境详情
if (includeFileDetails) {
messages.push({
type: "environment_details",
content: this.getEnvironmentDetails()
})
}
// 3. 添加用户内容
messages.push({
type: "user_content",
content: userContent
})
return messages
}
c.API通信系统
class ApiHandler {
async *attemptApiRequest(previousApiReqIndex: number) {
// 1. 系统提示准备
let systemPrompt = await SYSTEM_PROMPT(
cwd,
this.api.getModel().info.supportsComputerUse,
mcpHub,
this.browserSettings
);
// 2. 上下文预处理
const { truncatedHistory, deletedRange } = this.truncateHistoryToFitContext(
previousApiReqIndex
);
// 3. 流式通信
const stream = this.api.createMessage(systemPrompt, truncatedHistory);
yield* this.handleStreamResponse(stream);
}
private truncateHistoryToFitContext(previousIndex: number) {
const totalTokens = this.calculateTokensUsage();
switch (this.contextWindow) {
case 64_000: // deepseek models
this.maxAllowedSize = this.contextWindow - 27_000;
break;
case 128_000: // most models
this.maxAllowedSize = this.contextWindow - 30_000;
break;
}
if (totalTokens >= this.maxAllowedSize) {
return this.performTruncation();
}
return { truncatedHistory: this.history };
}
}
d.工具
export const toolUseNames = [
"execute_command",
"read_file",
"write_to_file",
"replace_in_file",
"search_files",
"list_files",
"list_code_definition_names",
"browser_action",
"use_mcp_tool",
"access_mcp_resource",
"ask_followup_question",
"plan_mode_response",
"attempt_completion",
] as const
e.终端命令执行工具
async executeCommandTool(command: string): Promise<[boolean, ToolResponse]> {
// 1. 终端管理
const terminalInfo = await this.terminalManager.getOrCreateTerminal(cwd)
terminalInfo.terminal.show()
// 2. 执行命令
const process = this.terminalManager.runCommand(terminalInfo, command)
// 3. 输出处理
process.on("line", (line) => {
result += line + "\\n"
if (!didContinue) {
sendCommandOutput(line)
} else {
this.say("command_output", line)
}
})
// 4. 等待完成
await process
// 5. 返回结果
return [completed, formatResult(result)]
}
f.文件操作工具
class FileOperations implements Tool {
// 文件读取
async readFile(path: string): Promise<string> {
return fs.readFile(path, 'utf8');
}
// 文件写入
async writeFile(path: string, content: string): Promise<void> {
await this.ensureDirectoryExists(path);
await fs.writeFile(path, content);
}
// 文件替换
async replaceInFile(path: string, diff: string): Promise<void> {
const content = await this.readFile(path);
const newContent = await constructNewFileContent(diff, content);
await this.writeFile(path, newContent);
}
// 文件列表
async listFiles(path: string, recursive: boolean): Promise<string[]> {
if (recursive) {
return this.recursiveListFiles(path);
}
return fs.readdir(path);
}
}
05.安全机制实现
a.文件操作安全
class FileOperationApproval {
async checkFileAccess(operation: FileOperation): Promise<boolean> {
// 1. 路径安全检查
if (!this.isPathSafe(operation.path)) {
return false;
}
// 2. 操作权限检查
if (!this.hasPermission(operation.type)) {
return false;
}
// 3. 内容安全检查
if (operation.type === 'write' && !this.isContentSafe(operation.content)) {
return false;
}
return true;
}
private isPathSafe(path: string): boolean {
// 检查路径是否在工作目录内
// 防止目录遍历攻击
const normalizedPath = normalizePath(path);
return isWithinWorkspace(normalizedPath);
}
}
b.命令执行安全
class CommandSecurity {
private readonly restrictedCommands: Set<string> = new Set([
'rm -rf',
'format',
'shutdown',
// ... 其他危险命令
]);
async validateCommand(command: string): Promise<boolean> {
// 1. 检查是否是受限命令
if (this.isRestrictedCommand(command)) {
return false;
}
// 2. 检查命令权限
if (!await this.checkCommandPermissions(command)) {
return false;
}
// 3. 检查资源限制
if (!this.checkResourceLimits(command)) {
return false;
}
return true;
}
private isRestrictedCommand(command: string): boolean {
return Array.from(this.restrictedCommands).some(
restricted => command.includes(restricted)
);
}
}
c.检查点系统
a.三种情况
task(恢复任务消息)、workspace(恢复工作区文件)、taskAndWorkspace(同时恢复任务消息和工作区文件)
b.核心机制
ShadowGit(主仓库的变更不会影响到Shadow 仓库,shadow 仓库的变更会形成主仓库的未提交的更改)
c.核心流程
如果恢复 workspace 或 taskAndWorkspace,则会首先初始化 checkpointTracker,并通过 resetHead 直接将工作区恢复到指定 git commit
对于 task 或 taskAndWorkspace,我们还需要恢复 task 历史消息记录,同时记录回滚的 APi 资源消耗
-------------------------------------------------------------------------------------------------
class CheckpointSystem {
private checkpoints: Map<string, Checkpoint> = new Map();
// 创建检查点
async createCheckpoint(): Promise<string> {
const checkpoint = {
id: generateId(),
timestamp: Date.now(),
state: await this.captureCurrentState(),
files: await this.captureFileState()
};
this.checkpoints.set(checkpoint.id, checkpoint);
return checkpoint.id;
}
// 恢复检查点
async restoreCheckpoint(id: string): Promise<void> {
const checkpoint = this.checkpoints.get(id);
if (!checkpoint) {
throw new Error('Checkpoint not found');
}
await this.restoreState(checkpoint.state);
await this.restoreFiles(checkpoint.files);
}
}
06.文件存储
a.文件存储主要分为以下几类
Task对话流,配置文件(主要是 mcp服务器信息),mcp 服务端代码,自定义prompt(.clinerules)
b.Task 存储
~/Library/Application\ Support/Code/User/globalStorage/扩展名/tasks/任务ID
api_conversation_history.json:存储消息和上下文
ui_messages.json:存储 UI 上显示的信息
checkpoints:检查点信息
.git:存储记录检查点的影子仓库数据
c.配置信息存储
~/Library/Application\ Support/Code/User/globalStorage/扩展名/settings
cline_mcp_settings.json:存储 mcp 的信息,包括ID、参数,环境变量等信息
d.mcp服务端代码存储位置
~/Documents/Cline/MCP:这个文件夹存储 mcp 服务器的代码位置
4.3 langchain
01.概述
a.定义
LangChain是一个开源库,它致力于让开发基于LLM的AI应用更简单,它是一个AI开发领域的万能适配器。
它抽象化了与大语言模型(如OpenAI模型、文心模型等等)交互的复杂性
以及集成了周边的各种工具生态,让开发者可以专注于实现AI应用的逻辑和功能
LangChain提供了一系列易于使用的工具和抽象,使得与大语言模型的交互变得尽可能的简单明了
b.LangChainHub
提示词模板库:这些模板可以帮助你快速开始一个特定任务,比如生成特定格式的文本,或者进行一些复杂的逻辑处理
可重复使用的流程:如果你有常见的工作流,你可以在LangChainHub上找到现成的流程,或者将你的工作流分享给社区
最佳实践的共享:在 LangChainHub 上,开发者可以分享他们的经验教训和解决方案,帮助其他开发者避坑
02.代码示例
a.安装
pip install langchain
b.使用OpenAI的接口
from openai import OpenAI
# 实例化OpenAI模型
client = OpenAI(api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.aigc369.com/v1")
# 使用LangChain的接口与模型交互
messages = [
{
"role": "system",
"content": "请你作为我的生活小助手。"
},
{
"role": "user",
"content": "胳膊上起了红疹子怎么办?"
}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages= messages
)
content = response.choices[0].message.content
print(content)
c.使用LangChain的接口调用OpenAI的模型
from langchain_openai import ChatOpenAI
# 实例化OpenAI模型
model = ChatOpenAI(model="gpt-3.5-turbo",
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
openai_api_base="https://api.aigc369.com/v1")
# 使用LangChain的接口与模型交互
from langchain.schema.messages import HumanMessage, SystemMessage, AIMessage
messages = [
SystemMessage(content="请你作为我的生活小助手。"),
HumanMessage(content="胳膊上起了红疹子怎么办?"),
]
response = model.invoke(messages)
print(response.content)
03.提示词模板
a.说明
提示模板是 LangChain 的核心功能之一
Prompt提示词模板是在LangChain中使用,LangChain 中通过提示模板来构建最终的 Prompt
b.使用
from langchain_openai import ChatOpenAI
from langchain.prompts import (
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
system_template_text = "你是一位专业的翻译,能够将{input_language}翻译成{output_language}。请只输出翻译后的文本,不要有任何其它内容。"
system_prompt_template = SystemMessagePromptTemplate.from_template(system_template_text)
human_template_text = "文本:{text}"
human_prompt_template = HumanMessagePromptTemplate.from_template(human_template_text)
model = ChatOpenAI(model="gpt-3.5-turbo",
openai_api_key="sk-BuQK7SGbqCZP2i2z7fF267AeD0004eF095AbC78d2f79E019",
openai_api_base="https://api.aigc369.com/v1")
prompt_input_variables = [
{
"input_language": "中文",
"output_language": "英语",
"text": "我今天去超级买衣服",
},
{
"input_language": "中文",
"output_language": "法语",
"text": "我今天去超级买衣服",
},
{
"input_language": "中文",
"output_language": "俄语",
"text": "我今天去超级买衣服",
},
{
"input_language": "中文",
"output_language": "日语",
"text": "我今天去超级买衣服",
},
{
"input_language": "中文",
"output_language": "韩语",
"text": "我今天去超级买衣服",
},
{
"input_language": "中文",
"output_language": "意大利语",
"text": "我今天去超级买衣服",
}
]
for input in prompt_input_variables:
response = model.invoke([
system_prompt_template.format(input_language=input["input_language"], output_language=input["output_language"]),
human_prompt_template.format(text=input["text"])])
print(response.content)
c.说明
SystemMessagePromptTemplate代码系统模板,HumanMessagePromptTemplate代表是用户消息模板
{input_language}、{output_language}、{text}是变量,最终通过format方法,替换成实际的值来生成最终的Prompt
最终使用LangChain的大模型类执行Prompt即可
4.4 langchain4j
00.汇总
Easy RAG
Native RAG
Advanced RAG
01.Easy RAG
a.核心特点
优势:10 分钟内完成部署,适合验证性需求
局限:无法调整分块策略或更换嵌入模型
全自动化流程,无需配置即可实现文档解析、分块和嵌入
b.适用场景
快速验证概念、小型项目原型、新手学习
c.技术实现
自动文档解析(支持 PDF/TXT/Word 等格式)
默认分块策略(300 字符固定长度,30 字符重叠)
内置轻量级嵌入模型(如bge-small-en-v1.5)
内存型向量存储(InMemoryEmbeddingStore)
d.代码示例
// 加载文档并自动处理
List<Document> docs = FileSystemDocumentLoader.loadDocuments("/Users/youyou/javaboy/doc",new PDFDocumentParser());
EmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(docs, store); // 自动分块+嵌入
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(docs, embeddingStore);
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
.apiKey(API_KEY)
.model("glm-4")
.temperature(0.6)
.maxToken(1024)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
String answer = assistant.answer("江南一点雨为什么选择做开发?");
System.out.println("answer = " + answer);
02.Native RAG
a.核心特点
优势:支持优化分块策略(如医疗报告按章节拆分)
局限:需自行管理组件兼容性
灵活配置各组件,适配中等复杂度需求
b.适用场景
企业知识库、需定制分块规则的项目
c.可调参数
分块策略(按段落/句子/固定长度)
嵌入模型(支持本地 ONNX 或云端 API)
向量存储类型(Redis/Pinecone/Elasticsearch/Milvus 等)
d.代码示例
//1.读取文件
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler bodyContentHandler = new BodyContentHandler();
parser.parse(new FileInputStream("/Users/youyou/Desktop/jianying/松哥/思否有约访谈提纲 - 江南一点雨.docx"), bodyContentHandler, new Metadata());
Document document = Document.from(bodyContentHandler.toString());
//2.文件切分
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(150, 50);
List<TextSegment> textSegments = splitter.split(document);
//3.文件向量化
ZhipuAiEmbeddingModel embeddingModel = ZhipuAiEmbeddingModel.builder()
.apiKey(API_KEY)
.logRequests(true)
.logResponses(true)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Response<List<Embedding>> embedded = embeddingModel.embedAll(textSegments);
//4.向量存储
MilvusEmbeddingStore store = MilvusEmbeddingStore.builder()
.host("localhost")
.port(19530)
.collectionName("javaboy_collection_data_3")
.dimension(1024)
.indexType(IndexType.FLAT)
.metricType(MetricType.COSINE)
.username("username")
.password("password")
.consistencyLevel(ConsistencyLevelEnum.EVENTUALLY)
.autoFlushOnInsert(true)
.idFieldName("id")
.textFieldName("text")
.metadataFieldName("metadata")
.vectorFieldName("vector")
.build();
store.addAll(embedded.content(), textSegments);
//5. 搜索
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.5)
.build();
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
.apiKey(API_KEY)
.model("glm-4")
.temperature(0.6)
.maxToken(1024)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
String answer = assistant.answer("江南一点雨为什么选择做开发?");
System.out.println("answer = " + answer);
03.Advanced RAG
a.工作流程
a.用户发起问题
你提出一个问题(比如"如何做糖醋排骨"),就像向图书馆员提出查阅需求
b.问题加工处理
系统会将你的问题拆解成多个相关查询(如拆解为"糖醋排骨做法""火候控制技巧""酱料调配比例"),相当于图书馆员把复杂问题分解成多个检索关键词
c.智能分配查询
每个加工后的查询会被智能分配到不同的检索渠道(类似图书馆员同时查纸质菜谱书、美食视频库、厨师论坛等不同资源库)
d.多途径检索内容
每个渠道根据分配到的查询内容,查找相关度最高的信息片段(如图书馆员在不同资料库中找到对应的做法步骤、操作要点)
e.整合检索结果
把从各个渠道找到的信息汇总排序,去除重复内容,按相关度高低排列(类似图书馆员把找到的菜谱步骤、视频要点、专业技巧整理成有序清单)
f.组合信息与问题
将整理好的资料清单附加到原始问题中(相当于图书馆员把找到的资料复印件和你的原始问题装订在一起)
g.生成最终回答
把组合好的完整资料包交给AI大模型,让它基于这些资料给出具体回答(就像图书馆员带着资料包去请教专业厨师,厨师结合资料给出详细指导)
b.核心特点
优势:召回率提升 30% 以上
局限:开发复杂度高,需理解检索算法原理
支持复杂检索逻辑(混合搜索+重排序)
c.适用场景
金融风控、法律咨询等高精度需求场景
d.高级功能
多路召回:同时使用向量/关键词/语义检索
查询路由:根据问题类型选择检索路径(如技术类用向量,通用类用关键词)
重排序机制:通过 RRF 算法优化结果排序
4.5 deepseek4j
01.快速开始
a.添加依赖
<dependency>
<groupId>io.github.pig-mesh.ai</groupId>
<artifactId>deepseek-spring-boot-starter</artifactId>
<version>1.1.0</version>
</dependency>
b.配置参数
deepseek:
api-key:your-api-key-here
base-url:https://api.deepseek.com/v1 # 可选,默认为官方 API 地址,支持火山、gitee、硅基流动
c.基础使用
@Autowired
private DeepSeekClient deepSeekClient;
// sse 流式返回
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ChatCompletionResponse> chat(String prompt){
return deepSeekClient.chatFluxCompletion(prompt);
}
d.前端调试
双击运行根目录的 sse.html 文件,即可打开调试页面
在页面中输入后端 SSE 接口地址,点击发送后可实时查看推理过程和最终结果
页面提供了完整的前端实现代码,可作为集成参考
4.6 spring-ai-openai
00.两种方式
spring-ai-openai starter:伪装成 OpenAI,DeepSeek 提供了 OpenAI 兼容模式
spring-ai-ollama-spring-boot-starter:通过 Ollama 本地部署一个 DeepSeek R1 蒸馏版
01.spring-ai-openai starter:伪装成 OpenAI,DeepSeek 提供了 OpenAI 兼容模式
a.说明
DeepSeek 其实提供了 OpenAI 兼容模式,只要在请求头里加个api_key,就能假装自己在调 OpenAI
Spring AI 的 openai starter 本质上是通过 RestTemplate 发请求,我们只需要改改 URL 和认证方式
b.依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.8.1</version>
</dependency>
c.配置
spring:
ai:
openai:
base-url: https://api.deepseek.com/v1 # DeepSeek的OpenAI式端点
api-key: sk-your-deepseek-key-here
chat.options:
model: deepseek-chat # 指定DeepSeek的模型名称
d.代码调用
@RestController
@RequestMapping("/ai")
@Slf4j
public class ChatController {
private final ChatClient chatClient;
// 构造方法注入 ChatClient.Builder,用于构建 ChatClient 实例
public ChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/chat")
public String generate(@RequestParam(value = "message") String message) {
log.info("Generating response");
// 调用 ChatClient 的 prompt 方法生成响应
// 1. prompt(message): 创建一个包含用户输入消息的 Prompt 对象
// 2. call(): 调用 ChatClient 与 AI 模型交互以获取响应
// 3. content(): 提取响应的内容部分
return chatClient.prompt(message).call().content();
}
}
02.spring-ai-ollama-spring-boot-starter:通过 Ollama 本地部署一个 DeepSeek R1 蒸馏版
a.依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>0.8.1</version>
</dependency>
b.配置
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b # 与本地模型名称对应
c.代码调用
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
// 构造方法注入 ChatClient.Builder,用于构建 ChatClient 实例
public ChatController(ChatClient.Builder chatClient) {
this.chatClient = chatClient.build();
}
@GetMapping("/chat")
public ResponseEntity<Flux<String>> chat(@RequestParam(value = "message") String message) {
try {
// 调用 ChatClient 生成响应,并以 Flux<String>(响应流)形式返回
Flux<String> response = chatClient.prompt(message).stream().content();
return ResponseEntity.ok(response);
} catch (Exception e) {
return ResponseEntity.badRequest().build();
}
}
}